数据结构与算法:高级数据结构与实际应用
目录
14.1 跳表
14.2 Trie树
14.3 B树与 B+树
14.4 其他高级数据结构
总结
数据结构与算法:高级数据结构与实际应用
本章将探讨一些高级数据结构,这些数据结构在提高数据存取效率和解决复杂问题上起到重要作用。这些高级数据结构包括跳表(Skip List)、Trie树、B树与B+树,以及其他具有特殊用途的数据结构。我们将深入了解这些数据结构的原理、实现以及它们在实际系统中的应用场景。
14.1 跳表
跳表是一种随机化的数据结构,通过增加多级索引来提高查找效率。跳表在平均情况下的时间复杂度为 O(log n),且实现简单,适合并发场景下的高效查找。
| 特性 | 跳表(Skip List) |
|---|---|
| 平均复杂度 | O(log n) |
| 最坏复杂度 | O(n) |
| 空间复杂度 | O(n log n) |
| 适用场景 | 数据库索引、缓存、并发访问 |
代码示例:跳表的基本实现
#include <stdio.h>
#include <stdlib.h>
#define MAX_LEVEL 3typedef struct Node {int key;struct Node* forward[MAX_LEVEL + 1];
} Node;Node* createNode(int key, int level) {Node* newNode = (Node*)malloc(sizeof(Node));newNode->key = key;for (int i = 0; i <= level; i++) {newNode->forward[i] = NULL;}return newNode;
}int randomLevel() {int level = 0;while (rand() % 2 && level < MAX_LEVEL) {level++;}return level;
}Node* createSkipList() {return createNode(-1, MAX_LEVEL);
}void insert(Node* header, int key) {Node* update[MAX_LEVEL + 1];Node* current = header;for (int i = MAX_LEVEL; i >= 0; i--) {while (current->forward[i] != NULL && current->forward[i]->key < key) {current = current->forward[i];}update[i] = current;}int level = randomLevel();Node* newNode = createNode(key, level);for (int i = 0; i <= level; i++) {newNode->forward[i] = update[i]->forward[i];update[i]->forward[i] = newNode;}
}void display(Node* header) {for (int i = MAX_LEVEL; i >= 0; i--) {Node* node = header->forward[i];printf("Level %d: ", i);while (node != NULL) {printf("%d -> ", node->key);node = node->forward[i];}printf("NULL\n");}
}int main() {Node* header = createSkipList();insert(header, 3);insert(header, 6);insert(header, 7);insert(header, 9);insert(header, 12);display(header);return 0;
}在上述代码中,展示了跳表的基本插入操作,利用多级指针加速了数据的查找和插入。
14.2 Trie树
Trie树,也称为前缀树,是一种用于高效存储和查找字符串的树状数据结构。Trie树特别适合用于自动补全、字符串匹配等应用场景。
| 特性 | Trie树 |
| 查找复杂度 | O(m),其中 m 为键长 |
| 空间复杂度 | O(n * m),其中 n 为节点数,m 为键长 |
| 适用场景 | 字符串查找、词典、前缀匹配 |
代码示例:Trie树的基本实现
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>#define ALPHABET_SIZE 26typedef struct TrieNode {struct TrieNode* children[ALPHABET_SIZE];bool isEndOfWord;
} TrieNode;TrieNode* createNode() {TrieNode* newNode = (TrieNode*)malloc(sizeof(TrieNode));newNode->isEndOfWord = false;for (int i = 0; i < ALPHABET_SIZE; i++) {newNode->children[i] = NULL;}return newNode;
}void insert(TrieNode* root, const char* key) {TrieNode* current = root;for (int level = 0; key[level] != '\0'; level++) {int index = key[level] - 'a';if (!current->children[index]) {current->children[index] = createNode();}current = current->children[index];}current->isEndOfWord = true;
}bool search(TrieNode* root, const char* key) {TrieNode* current = root;for (int level = 0; key[level] != '\0'; level++) {int index = key[level] - 'a';if (!current->children[index]) {return false;}current = current->children[index];}return current != NULL && current->isEndOfWord;
}int main() {TrieNode* root = createNode();insert(root, "hello");insert(root, "world");printf("查找 'hello': %s\n", search(root, "hello") ? "找到" : "未找到");printf("查找 'trie': %s\n", search(root, "trie") ? "找到" : "未找到");return 0;
}在此代码中,Trie树用于高效存储字符串,并支持快速的查找操作。
14.3 B树与 B+树
B树和 B+树是常用于数据库和文件系统的平衡树结构,适用于大规模数据的高效存储和检索。
| 特性 | B树 | B+树 |
| 叶子节点 | 数据可在所有节点上存储 | 数据仅存储在叶子节点 |
| 查找效率 | O(log n) | O(log n) |
| 顺序访问 | 复杂,需要中序遍历 | 高效,通过叶子节点链表直接访问 |
| 适用场景 | 数据库索引 | 文件系统、数据库的范围查找 |
代码示例:B+树节点的基本结构
#include <stdio.h>
#include <stdlib.h>
#define MAX_KEYS 3typedef struct BPlusNode {int keys[MAX_KEYS];struct BPlusNode* children[MAX_KEYS + 1];int numKeys;int isLeaf;struct BPlusNode* next;
} BPlusNode;BPlusNode* createNode(int isLeaf) {BPlusNode* newNode = (BPlusNode*)malloc(sizeof(BPlusNode));newNode->isLeaf = isLeaf;newNode->numKeys = 0;newNode->next = NULL;for (int i = 0; i < MAX_KEYS + 1; i++) {newNode->children[i] = NULL;}return newNode;
}void insertInLeaf(BPlusNode* leaf, int key) {int i;for (i = leaf->numKeys - 1; i >= 0 && leaf->keys[i] > key; i--) {leaf->keys[i + 1] = leaf->keys[i];}leaf->keys[i + 1] = key;leaf->numKeys++;
}void display(BPlusNode* root) {if (root != NULL) {for (int i = 0; i < root->numKeys; i++) {printf("%d ", root->keys[i]);}printf("\n");if (!root->isLeaf) {for (int i = 0; i <= root->numKeys; i++) {display(root->children[i]);}}}
}int main() {BPlusNode* root = createNode(1);insertInLeaf(root, 10);insertInLeaf(root, 20);insertInLeaf(root, 5);display(root);return 0;
}在这个代码示例中,B+树用于实现高效的数据插入和查找,适合处理大量数据并保持平衡性。
14.4 其他高级数据结构
并查集与其高级应用:并查集是一种用于处理不相交集合的数据结构,适合用于连通性查询,例如网络连接、社交圈查询等。
特性 并查集 查找复杂度 近似 O(1),路径压缩优化 合并复杂度 近似 O(1),按秩合并优化 适用场景 连通性查询、网络、社交圈 稀疏表(Sparse Table)与快速查询:稀疏表是一种空间高效的数据结构,主要用于静态数组的区间查询,支持 O(1) 的最小值、最大值等操作。
布隆过滤器与其他概率数据结构:布隆过滤器是一种高效的空间优化结构,用于快速判断某个元素是否存在于集合中,但存在一定的误判率。适用于大规模数据集的查询优化,例如缓存系统。
总结
本章介绍了跳表、Trie树、B树与 B+树等高级数据结构,以及它们在实际系统中的应用。这些数据结构在提高查找效率、优化存储和加速特定任务方面具有不可替代的作用。通过深入理解这些结构及其特性,我们能够选择最合适的数据结构来应对复杂的实际问题。
在下一章中,我们将深入讨论并查集与线段树的高级应用,以及它们在图论和范围查询中的重要作用。

相关文章:
数据结构与算法:高级数据结构与实际应用
目录 14.1 跳表 14.2 Trie树 14.3 B树与 B树 14.4 其他高级数据结构 总结 数据结构与算法:高级数据结构与实际应用 本章将探讨一些高级数据结构,这些数据结构在提高数据存取效率和解决复杂问题上起到重要作用。这些高级数据结构包括跳表࿰…...

【win11】终端/命令提示符/powershell美化
文章目录 1.设置字体1.1. 打开win11的终端/命令提示符/powershell其中之一1.2. 打开终端设置,修改所有终端默认字体为新宋体 2. 修改powershell背景色为蓝色 win11的默认终端/命令提示符/powershell主题风格让人感觉与win10撕裂太大,尤其是字体、背景色&…...
详解)
三元损失(Triplet Loss)详解
文章目录 前言一、三元损失的核心思想二、数学公式三、损失函数的解释四、三元损失的优势五、应用场景前言 三元损失(Triplet Loss)是一种广泛应用于度量学习(Metric Learning)中的损失函数,尤其在人脸识别、图像检索等任务中表现优异。三元损失的基本思想是通过定义一个…...

1. 解读DLT698.45-2017通信规约--预连接响应
国家电网有限公司企业标准,面向对象的用电信息数据交换协议DLT698.45-2017 为提高用电信息采集系统的业务适应性、采集效率、安全性和数据溯源性,规范用电信息数据交换协议的通信架构、数据链路层、应用层、接口类与对象标识,制定本标准。 …...

基于小波图像去噪的MATLAB实现
论文背景 数字图像处理(Digital Image Processing,DIP)是指用计算机辅助技术对图像信号进行处理的过程。数字图像处理最早出现于 20世纪50年代,随着过去几十年来计算机、网络技术和通信的快速发展,为信号处理这个学科领域的发展奠定了基础&a…...

[数据结构]栈的实现与应用
文章目录 一、引言二、栈的基本概念1、栈是什么2、栈的实现方式对比3、函数栈帧 三、栈的实现1、结构体定义2、初始化3、销毁4、显示5、数据操作 四、分析栈1、优点2、缺点 五、总结1、练习题2、源代码 一、引言 栈,作为一种基础且重要的数据结构,在计算…...

ESP32-C3 入门笔记04:gpio_key 按键 (ESP-IDF + VSCode)
1.GPIO简介 ESP32-C3是QFN32封装,GPIO引脚一共有22个,从GPIO0到GPIO21。 理论上,所有的IO都可以复用为任何外设功能,但有些引脚用作连接芯片内部FLASH或者外部FLASH功能时,官方不建议用作其它用途。 通过开发板的原…...

C语言(函数)—函数栈帧的创建和销毁
目录 前言 补充知识 一、函数线帧是什么? 二、函数线帧的实现(举例说明) 两数之和代码 编辑两数之和 汇编代码分析 执行第一条语句 执行第二条语句 执行第三条语句 执行第四、五、六条语句 执行第七条语句 执行第八、九、十条语句 执行第十…...

点餐小程序实战教程20广告管理
目录 1 创建数据源2 添加轮播容器3 创建变量4 绑定变量5 预览应用总结 一般餐厅需要有一些宣传,在我们的点餐页面可以在顶部加载广告位。广告主要是用轮播图的形式进行展示,本节我们介绍一下如果显示广告。 1 创建数据源 打开控制台,点击应用…...

市场上几个跨平台开发框架?
跨平台桌面应用开发框架是一种工具或框架,它允许开发者使用一种统一的代码库或语言来创建能够在多个操作系统上运行的桌面应用程序。传统上,开发者需要为每个操作系统编写不同的代码,使用不同的开发工具和语言。而跨平台桌面应用开发框架通过…...

同步和异步、引用、变量声明、全局变量
同步和异步 如果计算机足够快,任何资源的访问速度都像Cache一样,没有异步的必要。 编程语言的同步和异步 越早期的编程语言,支持语言级别的异步越欠缺。 JS提供某些操作的同步和异步函数,例如文件读取,fs.readFile和fs…...

2024年10月份实时获取地图边界数据方法,省市区县街道多级联动【附实时geoJson数据下载】
首先,来看下效果图 在线体验地址:https://geojson.hxkj.vip,并提供实时geoJson数据文件下载 可下载的数据包含省级geojson行政边界数据、市级geojson行政边界数据、区/县级geojson行政边界数据、省市区县街道行政编码四级联动数据࿰…...

@RequestMapping对不同参数的接收方式
1、简单参数 1、参数名与形参变量名相同,定义形参即可接收参数,且会自动进行类型转换。 RequestMapping("/simple")public String simpleParam(String name,int age){String username name;int userAge age;System.out.println(username&…...
算法_FaceBook_Location案例(附数据集下载链接))
机器学习_KNN(K近邻)算法_FaceBook_Location案例(附数据集下载链接)
Facebook_location_KNN 流程分析: 1.数据集获取(大型数据怎么获取? 放在电脑哪里? 算力怎么搞?) 2.基本数据处理(数据选取-确定特征值和目标值-分割数据集) 缩小数据范围 选择时间特征 去掉签到较少的地方 确定特征值和目标值 分割数据集 3.特征工程(特征预处理:标…...

【str_replace替换导致的绕过】
双写绕过 随便输入一个 usernameadmin&passwords 没有回显测试注入点 usernameadmin or 11%23&passwords 回显hello admin测试列数 usernameadmin order by 3%23&passwords测试回显位 usernameadmi union select 1,2,3%23&passwords 没有显示数据,推…...

如何用AI大模型提升挖洞速度
工具背景 越权漏洞在黑盒测试、SRC挖掘中几乎是必测的一项,但手工逐个测试越权漏洞往往会耗费大量时间,而自动化工具又存在大量误报, 基于此产生了AutorizePro, 那它是怎么提升效率一起来看看 AutorizePro 是一款专注于越权检测的 Burp 插件…...

两个数列问题
# 问题描述 给定长度分别为 n 和 m 的两个数列a[n]、b[m],和一个整数k。求|(a[i] - b[j])^2 - k^2|的最小值。 ## 输入格式 第一行有 2 个整数 n、m、k,分别表示数列 a、b 的长度,以及公式中的整数 k。 第二行有 n 个整数,表示…...
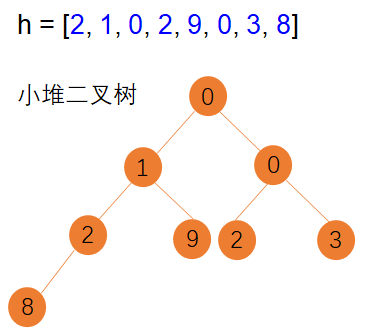
python中堆的用法
Python 堆(Headp) Python中堆是一种基于二叉树存储的数据结构。 主要应用场景: 对一个序列数据的操作基于排序的操作场景,例如序列数据基于最大值最小值进行的操作。 堆的数据结构: Python 中堆是一颗平衡二叉树&am…...

轮班管理新策略,提高效率与降低员工抱怨
良好轮班管理对企业关键,需提前计划、明确期望、保持灵活公平、加强沟通并利用轮班调度系统。ZohoPeople作为智能排班系统,提供轻松创建班次、自动更换、分配管理员、设置津贴及即时通知等功能,助力企业高效管理。 一、HR轮班管理的5大技巧 …...
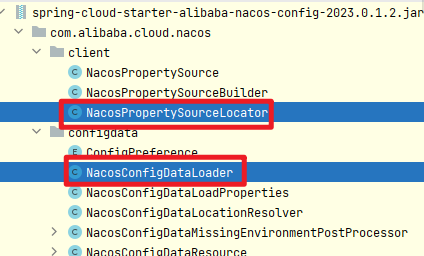
spring-cloud-alibaba-nacos-config2023.0.1.*启动打印配置文件内容
**背景:**在开发测试过程中如果可以打印出配置文件的内容,方便确认配置是否准确;那么如何才可以打印出来呢; spring-cloud-alibaba-nacos-config 调整日志级别 logging:level:com.alibaba.cloud.nacos.configdata.NacosConfigD…...

突破TIDAL音乐离线限制:tidal-dl-ng四象限应用指南
突破TIDAL音乐离线限制:tidal-dl-ng四象限应用指南 【免费下载链接】tidal-dl-ng TIDAL Media Downloader Next Generation! Up to HiRes / TIDAL MAX 24-bit, 192 kHz. 项目地址: https://gitcode.com/gh_mirrors/ti/tidal-dl-ng 场景痛点:当高品…...

省下99%内存!ESP32+TensorFlow Lite模型量化实战:让CNN在520KB RAM上跑起来
ESP32TensorFlow Lite模型量化实战:520KB RAM跑CNN的极限优化手册 当我在一个工业质检项目中首次尝试将CNN模型部署到ESP32时,开发板不断报出的内存不足错误让我意识到:在仅有520KB RAM的微控制器上跑深度学习,需要的不仅是技术实…...

Win11Debloat:简单三步彻底优化Windows系统,告别卡顿与隐私泄露
Win11Debloat:简单三步彻底优化Windows系统,告别卡顿与隐私泄露 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes…...

如何让老款RTX显卡免费获得AMD FSR3帧生成技术?5分钟完整解决方案
如何让老款RTX显卡免费获得AMD FSR3帧生成技术?5分钟完整解决方案 【免费下载链接】dlssg-to-fsr3 Adds AMD FSR 3 Frame Generation to games by replacing Nvidia DLSS Frame Generation (nvngx_dlssg). 项目地址: https://gitcode.com/gh_mirrors/dl/dlssg-to-…...

数字电路设计终极指南:用Logisim-Evolution从零搭建你的第一个逻辑系统
数字电路设计终极指南:用Logisim-Evolution从零搭建你的第一个逻辑系统 【免费下载链接】logisim-evolution Digital logic design tool and simulator 项目地址: https://gitcode.com/gh_mirrors/lo/logisim-evolution 数字电路设计与仿真是电子工程和计算机…...

iperf3 Windows预编译二进制深度解析:专业网络性能测试技术实践
iperf3 Windows预编译二进制深度解析:专业网络性能测试技术实践 【免费下载链接】iperf3-win-builds iperf3 binaries for Windows. Benchmark your network limits. 项目地址: https://gitcode.com/gh_mirrors/ip/iperf3-win-builds iperf3-win-builds是针对…...

快速验证域名跳转思路:用快马十分钟搭建jxx登录页检测工具原型
快速验证域名跳转思路:用快马十分钟搭建jxx登录页检测工具原型 最近注意到"jxx登录网页最新域名在哪"这个关键词搜索量突然增加,很多用户都在寻找特定网站的访问入口。这种需求其实很常见——当某个服务频繁更换域名时,普通用户很…...

seo网络排名优化如何选择关键词
SEO网络排名优化如何选择关键词 在当今数字化时代,搜索引擎优化(SEO)已经成为了每个网站和网络企业不可忽视的一部分。其中,关键词选择是影响网站排名的核心环节。如何选择最合适的关键词,以优化SEO网络排名呢&#x…...
)
根据DNI、角度、光伏板参数等计算24小时光伏功率输出并用matlab编写MPPT追踪算法研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

NCM格式解密终极指南:三分钟解锁网易云音乐加密文件
NCM格式解密终极指南:三分钟解锁网易云音乐加密文件 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的NCM格式文件无法在其他播放器使用而烦恼吗?ncmdump工具为你提供完整解决方案&#…...