Video-LLaMA论文解读和项目部署教程
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
相关工作
大型语言模型:
本文的工作基于这些LLM,并提供即插即用插件,使其能够理解视频中的视觉和听觉内容。
多模态大型语言模型:
现有的方法可以分为两大类。
第一类包括使用LLM作为控制器和利用现有的多模态模型作为工具。
当接收到用户的文本指令时,LLM识别出用户的注意力,并决定调用哪些工具。然后,它通过整合从这些现成的多模态模型中获得的结果,生成全面的响应。
第二类集中于训练基本的大规模多模态模型。
关键思想是将用于其他模态的预训练基础模型与文本LLM对齐。
本文的工作属于第二类,训练基本模型来理解视频中的视觉和听觉内容。

与之前专注于静态图像的视觉LLM不同,如(MiniGPT-4/LLaVA),Video-LLaMA主要解决了两个挑战
捕捉视觉场景中的时间变化:提出一种视频QFormer,将预训练的图像编码器组装到我们的视频编码器中,并引入视频到文本生成任务来学习视频语言对应关系。
整合视听信号:利用ImageBind,这是一种将多个模态对齐的通用嵌入模型,作为预训练的音频编码器,并在ImageBind之上引入音频Q-Former,以学习LLM模块的合理听觉查询嵌入。
为了使视觉和音频编码器的输入与LLM的嵌入空间对齐,使用大量指令调整(instruct-tuned)数据集训练Video-LLaMA。
视频语言模型: 由一个用于从视频帧中提取特征的冻结视觉encoder,一个用于将时间信息注入视频帧的位置嵌入曾,一个聚合帧表示的视频Q-Former和一个将输出视频表示映射到LLM的线性层。
如图1的左部所示,它包括
一个冻结的预训练图像编码器,用于从视频帧中提取特征;文章使用Blip-2中的视觉预训练组件作为冻结的视觉encoder来提取图像的特征,encoder包括一个Vit模型与一个预训练好的Q-former。
一个位置嵌入层,用于将时间信息注入视频帧;文章在分支中加入了位置嵌入层作为指示器来将时间信息注入视频帧。
来自冻结图像编码器的帧表示 是在不考虑任何时间信息的条件下进行计算的,因此需要加入位置嵌入作为帧的事件表示。然后将位置编码的帧表示送入视频Q-Former以获得维度为
的视频嵌入向量。给定N个帧组成视频,Visual Encoder首先将每个帧映射到
个图像嵌入向量中,产生视频帧表示为V = [v1,v2,v3,vN],其中
是对应于第i个帧的df维图像嵌入的集合。

一个视频Q-former,用于聚合帧级表示;视频Q-former被训练来得到含文本信息量最大的的视觉嵌入向量。
一个线性层,用于将输出视频表示投影到与LLM的文本嵌入相同的维度。为了使视频表示适应LLM的输入,文章添加了一个线性层,将不定长的视频嵌入向量转换为固定维数的视频查询向量。视频查询向量将被连接到输入文本嵌入中,作为视频软提示,引导冻结的LLM根据视频内容生成文本。 添加一个线性层,将视频嵌入转化为视频Query查询,Query查询向量与LLM文本嵌入维度相同,以便输入。在前向传递过程中,连接到输入文本嵌入作为视频prompt,引导冻结的LLM生成相关文本。利用BLIP-2(李等,2023b)的预训练视觉组件作为冻结视觉编码器,它包括来自EVA-CLIP(方等,2022)的ViT G/14和预训练Q-former。
音频语言模块:
如图1的右部所示,它包括
一个预训练的音频编码器,用于在给定一小段原始音频的情况下计算特征;文章使用ImageBind作为音频的encoder,ImageBind强大的多模态对齐能力可以使音频与语言对齐。
一个位置嵌入层,用于将时间信息注入音频段;
一个音频Q-former,用于融合不同音频段的特征;
一个线性层,用于将音频表示映射到LLMs的嵌入空间。
多分支跨模态训练-视频文本: 分别训练视觉与音频分支,第一阶段,使用大规模的视觉字幕数据集进行训练,第二阶段,使用高质量的指令跟随数据集进行微调。
阶段一:
目标:使用大数据,使视频特征包含尽可能多的视觉知识。
问题:视频表示使用冻结的LLMs生成的文本,不足以描述完整的视频。
原因:视频语义与视频文本语义并不完全一致
数据集:
Webvid-2M:短视频数据集
CC59K:CC3M过滤的图像字幕数据集
结果:能够生成视频信息内容,但遵循指令能力下降
-------------------------------------------------------------------------------------------------------------------------
阶段二:
目标:视觉文本对齐 指令跟随能力——>使用高质量数据集微调
数据集:
MiniGPT4:图像细节描述数据集
LLaVA:图像指令数据集
Video-chat: 视频指令数据集
结果:理解图像和视频方面表现出非凡的能力
多分支跨模态训练-音频文本
目的:将冻结音频编码器的输出嵌入与LLM的嵌入空间对准
问题:音频文本数据的稀缺
解决:变通思路
ImageBind音频编码器,具有将不同模态的beddings排列到一个公共空间的能力,在跨模态检索和生成任务中表现优秀。
鉴于音频文本数据的稀缺和视觉文本数据的丰富,使用视觉文本数据训练音频语言分支,遵循与视觉分支相同的数据和过程。
结果:由于ImageBind提供的共享嵌入空间,Video-LLaMA在推理过程中表现出理解音频的能力,即使音频接口从未在音频数据上训练过。
项目部署:
项目地址:Video-LLaMA:[EMNLP 2023 Demo] Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding - GitCode
论文链接:https://arxiv.org/pdf/2306.02858.pdf
代码链接:https://github.com/DAMO-NLP-SG/Video-LLaMA
展示样例:https://www.youtube.com/watch?v=RDNYs3Rswhc&feature=youtu.be
Video-LLaMA-main资源-CSDN文库
[2024年06月03日] 🚀🚀 我们正式推出了VideoLLaMA2,具有更强性能和更易用的代码库,快来尝试吧!
- [2023年11月14日] ⭐️ 当前的README文件仅适用于Video-LLaMA-2(使用LLaMA-2-Chat作为语言解码器),关于使用上一版本Video-LLaMA(使用Vicuna作为语言解码器)的说明,请参阅此处。
- [2023年08月03日] 🚀🚀 发布Video-LLaMA-2,采用Llama-2-7B/13B-Chat作为语言解码器
- 不再提供增量权重和单独的Q-形成器权重,运行Video-LLaMA所需的完整权重都在这里:[7B][13B]
- 支持从我们的预训练检查点开始进一步定制:[7B预训练][13B预训练]
- [2023年06月14日] 注意:当前在线互动演示主要用于英文聊天,提问中文问题可能不是最佳选择,因为Vicuna/LLaMA对中文文本的支持不够好。
- [2023年06月13日] 注意:目前音频支持仅限于Vicuna-7B,尽管我们有其他解码器的多个VL检查点可用。
- [2023年06月10日] 注意:我们尚未更新HF演示,因为整个框架(包括音频分支)在A10-24G上无法正常运行。当前运行的演示仍然是之前版本的Video-LLaMA,我们将会很快解决这个问题。
- [2023年06月08日] 🚀🚀 发布了带有音频支持的Video-LLaMA的检查点。文档和示例输出也已更新。
- [2023年05月22日] 🚀🚀 互动演示上线,在Hugging Face和ModelScope试试我们的Video-LLaMA(使用Vicuna-7B作为语言解码器)!
- [2023年05月22日] ⭐️ 发布基于Vicuna-7B构建的Video-LLaMA v2
- [2023年05月18日] 🚀🚀 支持中文的视频对话
- Video-LLaMA-BiLLA:我们引入了 BiLLa-7B-SFT作为语言解码器,并使用机器翻译的VideoChat指令来微调视频与语言对齐的模型(即阶段1模型)。
- Video-LLaMA-Ziya:类似于Video-LLaMA-BiLLA,但更换了语言解码器为Ziya-13B。
- [2023年05月18日] ⭐️ 创建了一个Hugging Face 仓库,以存储Video-LLaMA所有变体的模型权重。
- [2023年05月15日] ⭐️ 发布Video-LLaMA v2的检查点:利用VideoChat提供的训练数据,进一步增强了Video-LLaMA遵循指令的能力。
- [2023年05月07日] 发布Video-LLaMA的初始版本,包括其预训练和指令微调的检查点。
简介
- Video-LLaMA基于BLIP-2和MiniGPT-4构建,主要由两个核心组件构成:(1) 视觉-语言(VL)分支和(2) 音频-语言(AL)分支。
- VL分支(视觉编码器:ViT-G/14 + BLIP-2 Q-Former)
- 引入两层视频Q-Former及帧嵌入层,计算视频表示。
- 在Webvid-2M视频字幕数据集上训练VL分支,以执行视频到文本生成任务。同时,添加来自LLaVA的约59.5万个图像标题对到预训练数据中,以增强静态视觉概念的理解。
- 预训练后,我们使用来自MiniGPT-4、LLaVA和VideoChat的指令微调数据进一步细调我们的VL分支。
- AL分支(音频编码器:ImageBind-Huge)
- 引入两层音频Q-Former及音频段嵌入层,用于计算音频表示。
- 由于使用的音频编码器(即ImageBind)已在多种模态之间对齐,我们仅在视频/图像指令数据上训练AL分支,仅连接ImageBind的输出至语言解码器。
- 在跨模态训练期间,只有视频/音频Q-Former、位置嵌入层和线性层是可训练的。
使用方法
环境准备
首先,安装ffmpeg。
apt update apt install ffmpeg然后创建一个conda环境:
conda env create -f environment.yml conda activate videollama先决条件
不需要做任何事!
如何本地运行演示
首先,在eval_configs/video_llama_eval_withaudio.yaml中相应地设置
llama_model(语言解码器路径)、imagebind_ckpt_path(音频编码器路径)、ckpt(VL分支路径)和ckpt_2(AL分支路径)。接着运行脚本:python demo_audiovideo.py \--cfg-path eval_configs/video_llama_eval_withaudio.yaml \--model_type llama_v2 \ # 或者 vicuna--gpu-id 0
更改权重文件路径: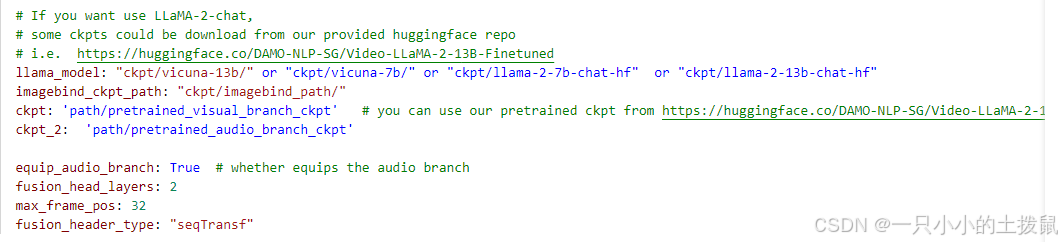
运行demo_audiovideo.py进行演示
遇到的问题:
下载:镜像网站比如modelscope就非常好用,魔搭社区网速非常快!
版本问题:video-llama由于快速迭代有一些依赖包的一些方法被弃用了,这导致你直接pip install -r requirements.txt所下载的东西无法使用!主要原因就是因为requirements.txt没有指定相应的版本号
tqdm
decord
timm
einops
opencv_python==4.8.0.74
torchvision==0.14.0
torch==1.13.0
bitsandbytes
omegaconf
iopath
webdataset
ftfy
SentencePiece
transformers==4.28.0
gradio==3.24.1
pytorchvideo
gradio-client==0.0.8
torchaudio运行结果:
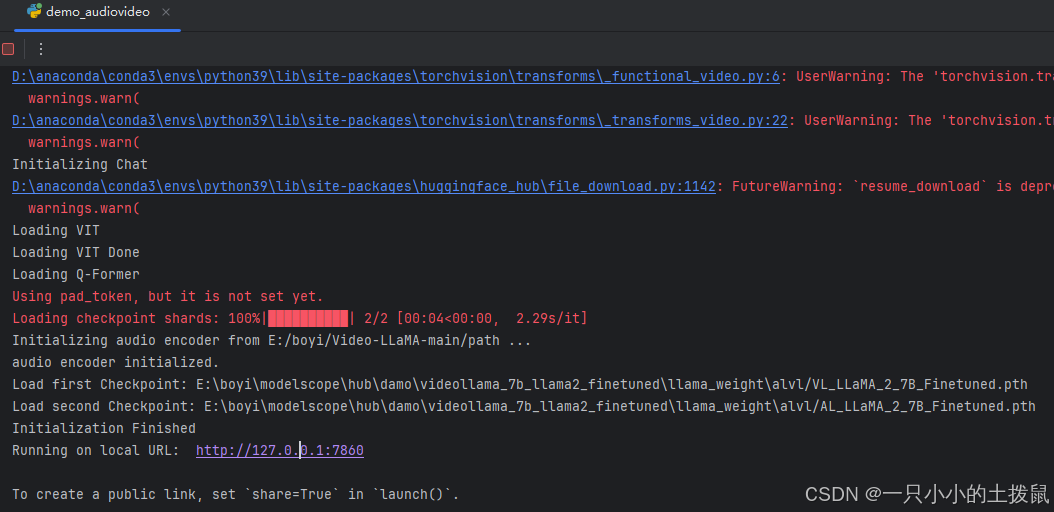
相关文章:
Video-LLaMA论文解读和项目部署教程
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding 相关工作 大型语言模型: 本文的工作基于这些LLM,并提供即插即用插件,使其能够理解视频中的视觉和听觉内容。 多模态大型语言模型: 现有…...

Elasticsearch设置 X-Pack认证,设置账号和密码
前言 以下Elasticsearch版本:7.9.3 ES自带的X-Pack密码验证: X-Pack是elasticsearch的一个扩展包,将安全,警告,监视,图形和报告功能捆绑在一个易于安装的软件包中,所以我们想要开启账号密码验证…...

机器学习——量子机器学习(Quantum Machine Learning)
机器学习——量子机器学习(Quantum Machine Learning) 量子机器学习(Quantum Machine Learning)——未来的智能计算量子机器学习的核心概念使用Qiskit进行量子机器学习——代码示例代码解析量子机器学习的应用结论 量子机器学习&a…...

Android Studio 的 Gradle 任务列表只显示测试任务
问题现象如下: 问题原因: 这是因为Android Studio 设置中勾选了屏蔽其他gradle任务的选项。 解决方法: File -> Settings -> Experimental 取消勾选Only include test tasks in the Gradle task list generated during Gradle Sync&…...

Keepalived:高可用性的守护神
Keepalived:高可用性的守护神 在现代企业IT系统中,高可用性是确保业务连续性和服务质量的关键要素。系统面对硬件故障、软件错误、人为失误或自然灾害时,依然能保持正常运行,这样的能力对于企业来说至关重要。为此,业界开发了一系列高可用性解决方案,其中Keepalived以其…...

Golang笔记_day08
Go面试题(一) 1、空切片 和 nil 切片 区别 空切片: 空切片是指长度和容量都为0的切片。它不包含任何元素,但仍然具有切片的容量属性。在Go语言中,可以使用内置的make函数创建一个空切片,例如:…...

如何在 React 中更新状态对象的某个值
在 React 中,我们经常需要更新组件的状态来反映 UI 的变化。如果状态是一个复杂的对象,比如一个包含多个筛选条件的对象,我们希望只更新其中的某个键,而不是整个状态对象。今天,我将向大家展示如何在更新状态时保留已有…...

edge浏览器:你的连接不是专用连接
最近在使用edge浏览器打开github时,发现打不开了,提升你的连接不是专用连接。试了很多种方法甚至重装了浏览器,都没有用。 直到看到了这篇文章,才得到解决: 10 个修复此站点在 Windows Edge 上的连接不安全的问题htt…...

PDF 软件如何帮助您编辑、转换和保护文件
如何找到最好的 PDF 编辑器。 无论您是在为您的企业寻找更高效的 PDF 解决方案,还是尝试组织和编辑主文档,PDF 编辑器都可以在一个地方提供您需要的所有工具。市面上有很多 PDF 编辑器 — 在决定哪个最适合您时,请考虑这些因素。 1. 确定您的…...

如何使用Java爬虫处理API接口返回的JSON数据?
处理API接口返回的JSON数据是Java爬虫开发中的一个常见任务。在Java中,有多个库可以帮助我们解析JSON数据,其中最流行的是Jackson和Gson。以下是使用这两个库处理JSON数据的基本步骤和示例代码。 使用Jackson处理JSON Jackson是一个功能强大的JSON处理…...

Ajax是什么?
Ajax是什么? Ajax是创建交互式网页应用的网页开发技术。简单来说就是网页在不加载的情况下,可以跟服务器交换数据,并更新页面的内容。 原理: 1. 创建xhr(xmlHttpRequest)对象; 2, 通过xhr对象的open()方法和…...

技术方向简介
掌握 Java基础,包括OOP思想、集合、常用的设计模式;熟悉基本的数据结构和算法; 掌握JVM虚拟机和Java多线程并发编程,熟悉线程池、线程安全机制、锁的使用; 熟悉MySQL、Oracle等关系型数据库锁、事务、索引相关知识,了解DDL原理&…...

延迟队列实现及其原理详解
1.绪论 本文主要讲解常见的几种延迟队列的实现方式,以及其原理。 2.延迟队列的使用场景 延迟队列主要用于解决每个被调度的任务开始执行的时间不一致的场景,主要包含如下场景: 1.比如订单超过15分钟后,关闭未关闭的订单。 2.比如用户可以…...

web APIs
目录 Web APIs第一天Dom获取&属性操作Web API基本认知变量声明作用和分类什么是DOMDOM树DOM对象 获取Dom对象根据CSS选择器来获取DOM元素(重点)其他获取DOM元素方法(了解) 操作元素内容对象.innerText 属性对象.innerHTML 属性…...
【Web前端概述】
HTML 是用来描述网页的一种语言,全称是 Hyper-Text Markup Language,即超文本标记语言。我们浏览网页时看到的文字、按钮、图片、视频等元素,它们都是通过 HTML 书写并通过浏览器来呈现的。 一、HTML简史 1991年10月:一个非正式…...

文献阅读:一种基于艾伦脑图谱的空间表达数据可视化、空间异质性描绘和单细胞配准工具
::: block-1 文献介绍 文献题目: AllenDigger,一种基于艾伦脑图谱的空间表达数据可视化、空间异质性描绘和单细胞配准的工具 研究团队: 王晓群(北京师范大学) 发表时间: 2023-03-16 发表期刊:…...

Redis学习笔记(三)--Redis客户端
文章目录 一、命令行客户端二、图形界面客户端1、Redis Desktop Manager2、RedisPlus 三、java代码客户端 本文参考: Redis学习汇总(已完结) Redis超详细入门教程(基础篇) Redis视频从入门到高级,redis视频…...

面试知识梳理
一、vue篇章 1.vue2和vue3性能方面的提升最主要的原因是什么? 1、1响应式的系统优化: vue3使用了es6的proxy对象来实现响应式系统,取代了vue2中基于Object.defineProperty的方法。Proxy提供了更强大和灵活的拦截能力,可以更有效地…...

Unity3D ScrollView 滚动视图组件详解及代码实现
前言 在Unity3D中,ScrollView(滚动视图)是一种常用的UI组件,它允许用户通过滚动来查看超出当前视图范围的内容。ScrollView通常用于显示长列表、大量文本或图像等。本文将详细介绍Unity3D中的ScrollView组件,并提供代…...

13.java面向对象:封装
java面向对象:封装 我们程序设计要追求“高内聚,低耦合”。高内聚就是类的内部数据操作细节自己完成,不允许外部干涉;低耦合:仅暴露少量的方法给外部使用。 封装(数据的隐藏)通常应禁止直接访问一个对象中…...

嵌入式系统错误处理策略与实现技术
1. 嵌入式系统中的错误处理概述在嵌入式软件开发中,错误处理是确保系统稳定性和可靠性的关键环节。与通用计算机系统不同,嵌入式系统往往运行在资源受限的环境中,且需要长时间不间断工作,这使得错误处理策略的选择尤为重要。嵌入式…...
)
手把手教你用WouoUI-PageVersion打造128*64 OLED炫酷UI(附Air001移植避坑指南)
嵌入式UI开发实战:WouoUI-PageVersion在128*64 OLED屏上的高效移植与优化 在资源受限的嵌入式设备上实现流畅的UI动画一直是个技术挑战。本文将带你深入探索如何利用WouoUI-PageVersion框架,在仅有4KB RAM和32KB Flash的Air001等微控制器上,打…...

hsjdvfjfgdhdydh
一、OpenAI 1.OpenAI是什么简单来说,OpenAI 大模型 是由美国人工智能公司 OpenAI 开发的一系列大型语言模型(LLMs) 。你可以把它们想象成拥有巨大“知识储备”和“学习能力”的超级大脑,它们被训练用来理解和生成人类语言…...
与factory.print()的实战应用)
UVM调试利器:print_topology()与factory.print()的实战应用
1. UVM调试利器:print_topology()与factory.print()的核心价值 在UVM验证环境中,调试就像是在迷宫里找路,而print_topology()和factory.print()就是你的手电筒和地图。这两个函数我用了快八年,每次遇到环境结构问题都能帮我省下至…...
HuggingFace Transformers库中Tokenizer与Model的高效实践指南
1. 为什么Tokenizer和Model是NLP项目的基石 第一次接触HuggingFace Transformers库时,我被Tokenizer和Model这两个组件的配合方式惊艳到了。想象一下,Tokenizer就像一位专业的翻译官,把人类能看懂的文字转换成计算机能理解的数字密码…...

Koikatu HF Patch终极指南:5分钟解锁完整游戏体验
Koikatu HF Patch终极指南:5分钟解锁完整游戏体验 【免费下载链接】KK-HF_Patch Automatically translate, uncensor and update Koikatu! and Koikatsu Party! 项目地址: https://gitcode.com/gh_mirrors/kk/KK-HF_Patch 还在为Koikatu游戏内容不完整而烦恼…...

第29章 2023真题作文
目录 题目2023.11-论边缘计算及其应用 题目2023.11-论多源数据集成及应用 题目2023.11-论面向对象的建模及应用 题目2023.11-论软件的可靠性评价 题目2023.11-论边缘计算及其应用 边缘计算是在靠近物或数据源头的网络边缘侧,融合网络、计算、存储、应用核心能力…...

避坑指南:n8n调用MinerU MCP时常见的3个配置错误及解决方法
避坑指南:n8n调用MinerU MCP时常见的3个配置错误及解决方法 当你第一次尝试将n8n与MinerU MCP结合使用时,可能会遇到一些令人头疼的配置问题。作为一位经历过无数次调试的老手,我想分享几个最常见的陷阱及其解决方案,希望能帮你节…...

实战指南:基于快马ai生成fpga图像处理系统,从算法到硬件实现
实战指南:基于快马AI生成FPGA图像处理系统,从算法到硬件实现 最近在做一个实时视频处理的项目,需要用到FPGA来实现图像灰度化和二值化处理。作为一个FPGA新手,我发现从算法到硬件实现的过程确实有不少坑要踩。好在使用了InsCode(…...

从零开始构建遗传图谱:QTL定位的关键技术与实践指南
1. 遗传图谱与QTL定位入门指南 第一次接触遗传图谱时,我和所有初学者一样充满困惑——这堆专业术语到底在说什么?简单来说,遗传图谱就像生物体的"基因地图",标记着不同基因在染色体上的相对位置。而QTL定位则是寻找控制…...