基于微博评论的自然语言处理情感分析
目录
一、项目概述
二、需要解决的问题
三、数据预处理
1、词汇表构建(vocab_creat.py)
2、数据集加载(load_dataset.py)
四、模型构建(TextRNN.py)
1、嵌入层(Embedding Layer)
2、长短期记忆网络层(LSTM)
3、全连接层(Fully Connected Layer)
五、模型训练与评估(train_eval_test.py)
1、训练过程(train 函数)
2、评估过程(evaluate 函数和 test 函数)
六、项目总结
本文将介绍一个基于自然语言处理技术对微博评论文本(simplifyweibo_4_moods.csv)进行情感分析的项目。
一、项目概述
本文将介绍一个基于自然语言处理技术对微博评论文本(simplifyweibo_4_moods.csv)进行情感分析的项目。
本项目旨在构建一个能够对微博评论进行情感分类的模型,将评论分为 “喜悦”、“愤怒”、“厌恶” 和 “低落” 四种情感类别。项目涵盖了从数据预处理、模型构建到训练和评估的完整流程。
项目任务:对微博评论信息的情感分析,建立模型,自动识别评论信息的情绪状态。
二、需要解决的问题
1、目标:将评论内容转换为词向量。
2、每个词/字转换为词向量长度(维度)200
3、每一次传入的词/字的个数是否就是评论的长度?
应该是固定长度,每次传入数据与图像相似。
例如选择长度为32。则传入的数据为32*200
4、一条评论如果超过32个词/字怎么处理?
直接删除后面的内容
5、一条评论如果没有32个词/字怎么处理?
缺少的内容,统一使用一个数字(非词/字的数字)替代。
6、如果语料库中的词/字太多是否可以压缩?
可以,某些词/字出现的频率比较低,可能训练不出特征。因此可以选择频率比较高的词来训练。例如选择4760个。
7、被压缩的词/字如何处理?
可以统一使用一个数字(非词/字的数字)替代。
三、数据预处理
1、词汇表构建(vocab_creat.py)
(1)、首先,通过自定义的分字函数tokenizer将每条评论内容分隔成单个字符。然后,统计每个字符在所有评论中出现的次数,形成一个字典vocab_dic。
(2)、为了控制词汇表的大小,只保留出现频率高于设定阈值(本项目中min_freq = 1)的字符,并按照出现次数从高到低排序,选取前MAX_VOCAB_SIZE = 4760个字符。
(3)、最后,将特殊字符<UNK>(未知字)和<PAD>(填充)添加到词汇表中,并将词汇表保存为pkl文件(simplifyweibo_4_moods.pkl),以便后续使用。
from tqdm import tqdm
import pickle as pklMAX_VOCAB_SIZE = 4760
UNK, PAD = '<UNK>', '<PAD>'def build_vocab(file_path, max_size, min_freq):tokenizer = lambda x: [y for y in x] # 定义一个分字函数vocab_dic = {}with open(file_path, 'r', encoding='UTF-8') as f:i = 0for line in tqdm(f): # 进度条if i == 0:i += 1continuelin = line[2:].strip() # 获取评论内容,删除标签if not lin: # 空行跳过continuefor word in tokenizer(lin):vocab_dic[word] = vocab_dic.get(word, 0) + 1 # 以字典保存每个字出现的次数vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] > min_freq], key=lambda x: x[1], reverse=True)[:max_size]vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)}vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1}) # UNK:4760, PAD:4761print(vocab_dic)pkl.dump(vocab_dic, open('simplifyweibo_4_moods.pkl', 'wb')) # one-hot编码print(f"Vocab size:{len(vocab_dic)}")return vocab_dicif __name__ == "__main__":vocab = build_vocab('simplifyweibo_4_moods.csv', MAX_VOCAB_SIZE, 1)print("vocab")
2、数据集加载(load_dataset.py)
(1)、从保存的词汇表文件中读取词汇信息。然后,对原始的微博评论文本数据进行处理。
(2)、对于每条评论,提取其情感标签(0,1,2,3),并将评论内容进行分字处理。根据设定的最大长度pad_size = 70,如果字符数少于 70,则用<PAD>填充;如果多于 70,则只取前 70 个字。
(3)、将每个字符转换为词汇表中的对应索引,最终将处理后的每条评论信息(包括字符索引列表、情感标签和实际长度)以元组形式存储在列表中。

(4)、接着,将整个数据集随机打乱,并按照 80%、10%、10% 的比例划分为训练集、验证集和测试集。
注:__next__方法用于按顺序获取数据
__getitem__方法通过索引获取数据
from tqdm import tqdm
import pickle as pkl
import random
import torchUNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号def load_dataset(path, pad_size=70): # path为文件地址,pad_size为单条评论字符的最大长度contents = [] # 用来存储转换为数值标号的句子vocab = pkl.load(open('simplifyweibo_4_moods.pkl', 'rb')) # 读取vocab词库文件,rb二进制只读tokenizer = lambda x: [y for y in x] # 自定义函数用来将字符串分隔成单个字符并存入列表with open(path, 'r', encoding='utf8') as f:i = 0for line in tqdm(f): # 遍历文件内容的每一行,同时展示进度条if i == 0: # 此处循环目的为了跳过第一行的无用内容i += 1continueif not line: # 筛选是不是空行,空行则跳过continuelabel = int(line[0]) # 返回当前行的标签content = line[2:].strip('\n') # 取出标签和逗号后的所有内容,同时去除前后的换行符(评论内容)words_line = []token = tokenizer(content) # 将每一行的内容进行分字,返回一个列表seq_len = len(token) # 获取一行实际内容的长度if pad_size:if len(token) < pad_size: # 如果一行的字符数少于70,则填充字符<PAD>,填充个数为少于的部分的个数token.extend([PAD] * (pad_size - len(token)))else: # 如果一行的字大于70,则只取前70个字token = token[:pad_size] # 如果一条评论种的宁大于或等于70个字,索引的切分seq_len = pad_size # 当前评论的长度# word to idfor word in token: # 遍历实际内容的每一个字符words_line.append(vocab.get(word, vocab.get(UNK))) # vocab为词库,其中为字典形式,# 使用get去获取遍历出来的字符的值,值可表示索引值,# 如果该字符不在词库中则将其值增加为字典中键UNK对应的值,# words_line中存放的是每一行的每一个字符对应的索引值contents.append((words_line, int(label), seq_len)) # 将每一行评论的字符对应的索引以及这一行评论的类别,还有当前评论的实际内容的长度,以元组的形式存入列表random.shuffle(contents) # 随机打乱每一行内容的顺序"""切分80%训练集、10%验证集、10%测试集"""train_data = contents[: int(len(contents) * 0.8)] # 前80%的评论数据作为训练集dev_data = contents[int(len(contents) * 0.8):int(len(contents) * 0.9)] # 把80%~90%的评论数据集作为验证数热test_data = contents[int(len(contents) * 0.9):] # 90%~最后的数据作为测试数据集return vocab, train_data, dev_data, test_data # 返回词库、训练集、验证集、测试集,数据集为列表中的元组形式class DatasetIterater(object):def __init__(self, batches, batch_size, device):self.batch_size = batch_sizeself.batches = batchesself.n_batches = len(batches) // batch_sizeself.residue = Falseif len(batches) % self.n_batches != 0: # 表示有余数self.residue = Trueself.index = 0self.device = devicedef _to_tensor(self, datas):x = torch.LongTensor([_[0] for _ in datas]).to(self.device) # 评论内容y = torch.LongTensor([_[1] for _ in datas]).to(self.device) # 评论情感# pad前的长度(超过pad_size的设为pad_size)seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)return (x, seq_len), y # (([23,34,..13],70),2)# __getitem__:是通过索引的方式获取数据对象中的内容。__next__ 是使用 for i in trgin iter:def __next__(self): # 用于定义迭代器对象的下一个元素。当一个对象实现了__next_方法时,它可以被用于创建迭代器对象。if self.residue and self.index == self.n_batches: # 当读取到数据的最后一个batch:batches = self.batches[self.index * self.batch_size: len(self.batches)]self.index += 1batches = self._to_tensor(batches) # 转换数据类型tensorreturn batcheselif self.index > self.n_batches: # 当读取完最后一个batch时:self.index = 0raise StopIteration # 为了防止迭代永远进行,我们可以使用StopIteration(停止迭代)语句else: # 当没有读取到最后一个batch时:batches = self.batches[self.index * self.batch_size:(self.index + 1) * self.batch_size] # 提取当前bathsize的数据量self.index += 1batches = self._to_tensor(batches)return batchesdef __iter__(self):return selfdef __len__(self):if self.residue:return self.n_batches + 1else:return self.n_batchesif __name__ == '__main__':vocab, train_data, dev_data, test_data = load_dataset('simplifyweibo_4_moods.csv')print(train_data, dev_data, test_data)print('结束')# 将train_data、dev_data、test_data数据内容保存为pkl文件,分别后面直接读取。# #当我们自己写一个函数的时候,调试,函数调试好,
四、模型构建(TextRNN.py)
本项目采用了 TextRNN 模型,它是一种基于循环神经网络(RNN)的架构,具有以下特点:
1、嵌入层(Embedding Layer)
(1)、如果有预训练的词嵌入向量(本项目中从embedding_Tencent.npz文件加载),则使用nn.Embedding.from_pretrained方法创建嵌入层;否则,使用nn.Embedding随机初始化词嵌入矩阵。
(2)、嵌入层的作用是将输入的字符索引转换为低维的向量表示,捕捉字符之间的语义关系。
2、长短期记忆网络层(LSTM)
(1)、采用多层双向 LSTM 结构(nn.LSTM),其中每层有 128 个隐藏单元,共 3 层。双向 LSTM 能够同时捕捉文本的正向和反向信息,更好地理解文本的语义。
(2)、通过设置batch_first = True,使输入数据的维度顺序符合批量优先的原则,方便后续的计算。同时,使用dropout = 0.3来防止过拟合。
3、全连接层(Linear)
最后一层是全连接层(nn.Linear),它将 LSTM 层输出的特征向量映射到情感类别数量的维度上(本项目中为 4 种情感类别),从而得到每个类别的预测概率。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import sysclass Model(nn.Module):def __init__(self, embedding_pretrained, n_vocab, embed, num_classes):super(Model, self).__init__()if embedding_pretrained is not None:self.embedding = nn.Embedding.from_pretrained(embedding_pretrained, padding_idx=n_vocab - 1)else:self.embedding = nn.Embedding(n_vocab, embed, padding_idx=n_vocab - 1)self.lstm = nn.LSTM(embed, 128, 3, bidirectional=True, batch_first=True, dropout=0.3)self.fc = nn.Linear(128 * 2, num_classes)def forward(self, x):x, _ = xout = self.embedding(x)out, _ = self.lstm(out)out = self.fc(out[:, -1, :])return out
五、模型训练与评估(train_eval_test.py)
1、训练过程(train 函数)
(1)、在训练过程中,使用torch.optim.Adam优化器对模型参数进行更新,学习率设置为1e - 3。
(2)、每个训练轮次(epoch)中,遍历训练集的每个批次(batch)。对于每个批次的数据,计算模型的输出和损失(使用交叉熵损失函数F.cross_entropy),然后进行反向传播更新模型参数。
(3)、每 100 个批次,在训练集和验证集上评估模型的性能。计算准确率(accuracy)作为评估指标,如果验证集上的损失小于之前的最优损失,则保存当前模型为最优模型,并记录对应的批次编号。
(4)、如果在连续 10000 个批次中模型没有得到优化,则自动停止训练。
2、评估过程(evaluate 函数和 test 函数)
(1)、在评估阶段,关闭梯度计算(with torch.no_grad()),以节省内存和计算资源。
(2)、对于测试集或验证集的数据,计算模型的输出和损失,并将预测结果与真实标签进行比较。计算准确率和其他评估指标(如分类报告metrics.classification_report),以全面评估模型的性能。
import torch
import torch.nn.functional as F
import torch.nn as nn
import numpy as np
from sklearn import metrics
import timedef evaluate(class_list,model,data_iter,test=False):model.eval()loss_total=0predict_all = np.array([],dtype=int)labels_all = np.array([],dtype=int)with torch.no_grad(): # 一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的for texts,labels in data_iter:outputs = model(texts)loss = F.cross_entropy(outputs,labels)loss_total += losslabels = labels.data.cpu().numpy()predic = torch.max(outputs.data,1)[1].cpu().numpy()labels_all = np.append(labels_all,labels)predict_all = np.append(predict_all,predic)acc = metrics.accuracy_score(labels_all,predict_all)if test:report = metrics.classification_report(labels_all,predict_all,target_names=class_list,digits=4)return acc,loss_total/len(data_iter),reportreturn acc,loss_total/len(data_iter)def test(model,test_iter,class_list):model.load_state_dict(torch.load('TextRNN.skpt'))model.eval()start_time = time.time()test_acc,test_loss,test_report = evaluate(class_list,model,test_iter,test=True)msg = "Test Loss:{0:>5.2},Test Acc:{1:6.2%}"print(msg.format(test_loss,test_acc))print(test_report)passdef train(model,train_iter,dev_iter,test_iter,class_list):model.train()optimizer = torch.optim.Adam(model.parameters(),lr=1e-3)total_batch = 0dev_best_loss = float('inf')last_improve = 0flag = Falseepochs = 2for epoch in range(epochs):print('Epoch [{}/{}]'.format(epoch+1,epochs))for i,(trains,labels) in enumerate(train_iter):# 经过DatasetIterater中的to_tensor 返回的数据格式为:(x,seq_len),youtputs = model(trains)loss = F.cross_entropy(outputs,labels)model.zero_grad()loss.backward()optimizer.step()if total_batch % 100 == 0: # 每多少轮输出在训练集和验证集上的效果predic = torch.max(outputs.data,1)[1].cpu()train_acc = metrics.accuracy_score(labels.data.cpu(),predic)dev_acc,dev_loss = evaluate(class_list,model,dev_iter) # 将验证数据集传入模型,获得验证结果if dev_loss < dev_best_loss:dev_best_loss = dev_loss # 保存最优模型torch.save(model.state_dict(),'TextRNN.ckpt')last_improve = total_batch # 保存最优模型的batch值 800batchs 21000msg = 'Iter:{0:>6},Train Loss:{1:>5.2},Train Acc:{2:>6.2%},Val Loss:{3:>5.2},Val Acc:{4:>6.2%}'print(msg.format(total_batch,loss.item(), train_acc, dev_loss, dev_acc))model.train()total_batch += 1if total_batch - last_improve > 10000:print("No optimization for a long time,auto-stopping...")flag = Trueif flag:break# test(model,test_iter,class_list)六、项目总结
通过本项目,我们展示了一个完整的自然语言处理情感分析流程,从数据预处理到模型构建和训练评估。TextRNN 模型在微博评论文本的情感分类任务上取得了一定的效果。然而,自然语言处理是一个复杂的领域,还有很多可以改进和优化的地方。
相关文章:
基于微博评论的自然语言处理情感分析
目录 一、项目概述 二、需要解决的问题 三、数据预处理 1、词汇表构建(vocab_creat.py) 2、数据集加载(load_dataset.py) 四、模型构建(TextRNN.py) 1、嵌入层(Embedding Layerÿ…...

MFEM( Modular Finite Element Methods)是一个灵活的、可扩展的、开源的有限元库
MFEM( Modular Finite Element Methods )是一个灵活的、可扩展的、开源的有限元库,主要用于求解偏微分方程(PDE)问题。MFEM的目标是通过模块化设计和强大的抽象能力,简化有限元方法的使用,并支持高效的并行计算,尤其是在复杂的几何形状和自适应网格细化的情况下。 核…...

在VMware上创建虚拟机以及安装Linux操作系统,使用ssh进行远程连接VMware安装注意点 (包含 v1,v8两张网卡如果没有的解决办法)
一,VMware上创建虚拟机 1.VMware下载 1)点击VMware官网进入官网 网址:VMware by Broadcom - Cloud Computing for the EnterpriseOptimize cloud infrastructure with VMware for app platforms, private cloud, edge, networking, and security.https…...

关于vue3中如何实现多个v-model的自定义组件
实现自定义组件<User v-model"userInfo" v-model:gender"gender"></User> User组件中更改数据可以同步更改父组件中的数据: 1 父组件: <User v-model"userInfo" v-model:gender"gender">&…...

【STM32项目_2_基于STM32的宠物喂食系统】
摘要:本文介绍一款基于 STM32 的宠物喂食系统资源。该系统以 STM32 为核心,集成多种传感器与设备,涵盖 DHT11、HX711、减速马达及 ESP8266 模块,具备环境监测、精准喂食、网络连接及数据存储功能。 🔜🔜&am…...

商场楼宇室内导航系统
商场楼宇室内导航系统 本文所涉及所有资源均在传知代码平台可获取 文章目录 商场楼宇室内导航系统效果图导航效果图查看信息数据加载加载模型模型选型处理楼层模型绑定店铺创建店铺名称动态显示隐藏2d元素空气墙查看信息楼梯导航效果图 导航效果图 查看信息 数据加载 因为是一…...

2025全网最全计算机毕业设计选题推荐:计算机毕设选题指导及避坑指南√
博主介绍:✌全网粉丝50W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌ 技术范围:SpringBoot、Vue、SSM、HLM…...

Vision China 2024 | 移远通信以一体化的AI训练及部署能力,引领3C电子制造智能升级
10月14日,由机器视觉产业联盟(CMVU)主办的中国机器视觉展(Vision China)在深圳国际会展中心盛大开幕。作为全球领先的物联网整体解决方案供应商,移远通信应邀参加展会首日举办的“智造引领数质并进”3C电子制造自动化与数字化论坛。 论坛上,移…...

浏览器播放rtsp视频流解决方案
方案一: html5 websocket_rtsp_proxy 实现视频流直播 实现原理 实现步骤 服务器安装streamedian服务器 客户端通过video标签播放 <video id"test_video" controls autoplay></video><script src"free.player.1.8.4.js"></script&g…...

Ubuntu下查看指定文件大小
Ubuntu下查看指定文件大小 方法一:查看指定文件夹的总大小方法二:查看文件夹内各个子文件夹的大小方法三:查看指定深度的子文件夹大小方法四:使用ls命令查看单个文件的大小注意事项 在Ubuntu中查看指定文件夹的大小,你…...
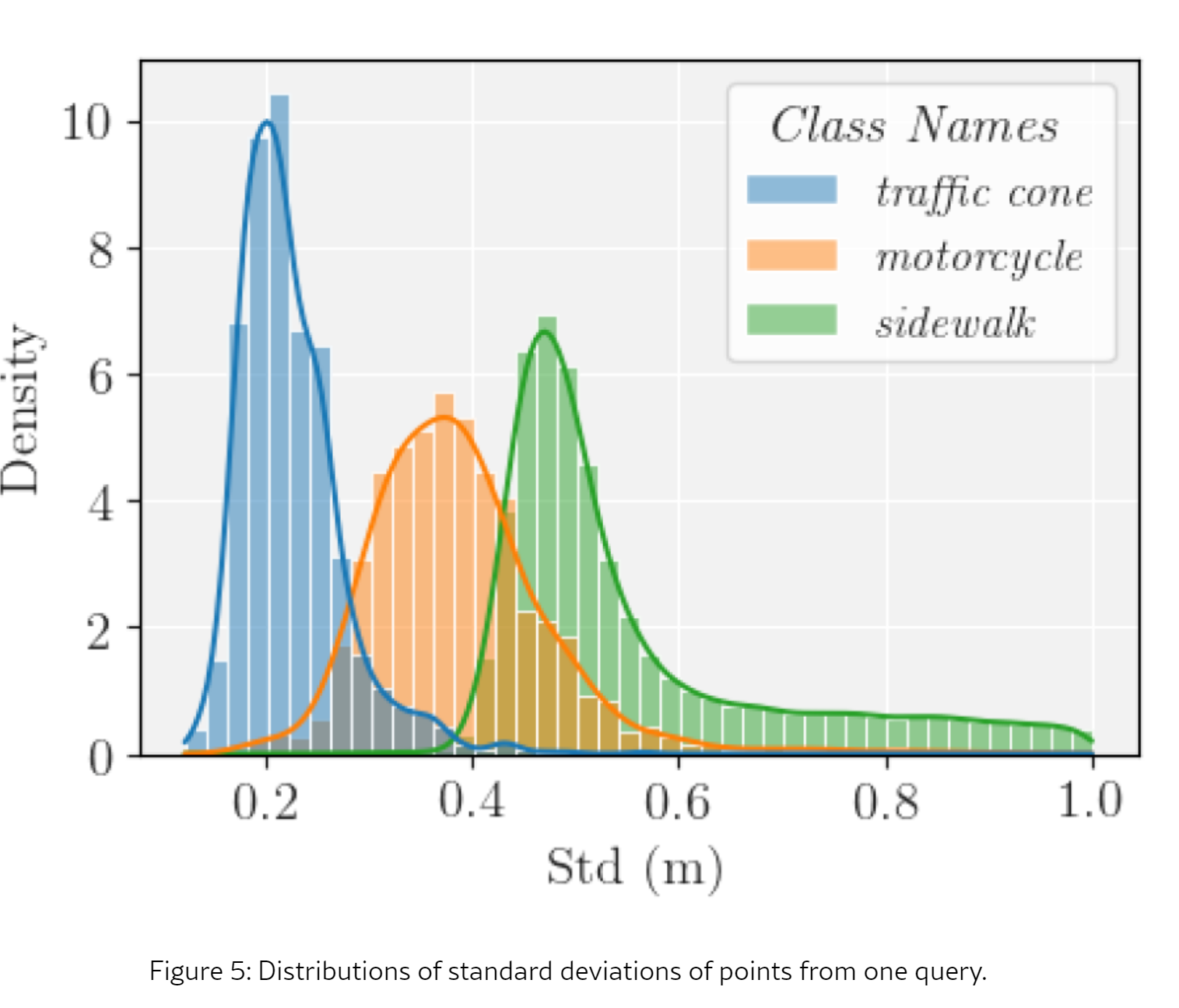
【南开X上海交大】OPUS:效率显著提升的OCC网络
1. 摘要 占据预测任务旨在预测体素化的3D环境中的占据状态,在自动驾驶领域中迅速获得了关注。主流的占据预测方法首先将3D环境离散化为体素网格,然后在这些密集网格上执行分类。然而,样本数据分析显示,大多数体素实际上是未占据的…...

SqlUtils 使用
一、前言 随着 Solon 3.0 版本发布,新添加的 SqlUtils 接口,用于操作数据库,SqlUtils 是对 Jdbc 原始接口的封装。适合 SQL 极少或较复杂,或者 ORM 不适合的场景使用。 二、SqlUtils 使用 1、引入依赖 <dependency><…...
平面声波——一维Helmhotz波动方程
平面声波的一维Helmholtz波动方程是一种简化的声波传播模型,适用于在一维空间中传播的声波。 声波的基本物理过程---傅里叶变换---Helmholtz方程 一、声波的基本波动方程 在无源、无耗散、均匀介质中的一维声波的波动方程为: 其中: 表示位…...
深度学习 简易环境安装(不含Anaconda)
在Windows上安装深度学习环境而不使用Anaconda,下面是一个基于pip的安装指南: 1. 安装Python 确保你已经安装了Python。可以从Python官网下载Python,并在安装时勾选“Add Python to PATH”选项。 注意,Python 不要安装最新版的…...
)
Java缓存技术(java内置缓存,redis,Ehcache,Caffeine的基本使用方法及其介绍)
目录 摘要 1. Java缓存技术概述 1.1定义 1.2 优势 1.3 应用场景 2. Java中的内置缓存实现 2.1 通过通过HashMap和ConcurrentHashMap实现缓存 3. Java缓存框架 3.1 Redis 3.1.1 redis的简介 3.1.4 Redis的工作原理 3.1.5 总结 3.2 Ehcache 3.2.1 Eh…...

YoloV9改进策略:主干网络改进|DeBiFormer,可变形双级路由注意力|全网首发
摘要 在目标检测领域,YoloV9以其高效和准确的性能而闻名。然而,为了进一步提升其检测能力,我们引入了DeBiFormer作为YoloV9的主干网络。这个主干网络的计算量比较大,不过,上篇双级路由注意力的论文受到很大的关注,所以我也将这篇论文中的主干网络用来改进YoloV9,卡多的…...

【力扣 | SQL题 | 每日3题】力扣2988,569,1132,1158
1 hard 3mid,难度不是特别大。 1. 力扣2988:最大部门的经理 1.1 题目: 表: Employees ---------------------- | Column Name | Type | ---------------------- | emp_id | int | | emp_name | varchar | | de…...

移动网络知识
一、3G网络 TD-SCDMA(时分同步码分多址接入)、WCDMA(宽带码分多址)和CDMA2000三种不同的3G移动通信标准 TD-SCDMA(时分同步码分多址接入):中国自主开发的一种3G标准主要用于国内市场ÿ…...

CentOS系统Nginx的安装部署
CentOS系统Nginx的安装部署 安装包准备 在服务器上准备好nginx的安装包 nginx安装包下载地址为:https://nginx.org/en/download.html 解压 tar -zxvf nginx-1.26.1.tar.gz执行命令安装 # 第一步 cd nginx-1.26.1# 第二步 ./configure# 第三步 make# 第四步 mak…...

Leetcode 最长公共前缀
java solution class Solution {public String longestCommonPrefix(String[] strs) {if(strs null || strs.length 0) {return "";}//用第一个字符串作为模板,利用indexOf()方法匹配,由右至左逐渐缩短第一个字符串的长度String prefix strs[0];for(int i 1; i …...

ARM项目模板在嵌入式开发中的高效应用
1. ARM项目模板在嵌入式开发中的核心价值在嵌入式系统开发领域,ARM架构处理器凭借其优异的功耗性能比占据着主导地位。作为开发者,我们经常面临这样的困境:每个新项目都要重复搭建基础框架,配置编译工具链,设置调试环境…...

从4G到5G VoNR:对比VoLTE呼叫流程,聊聊核心网演进带来的那些变化
从4G到5G VoNR:核心网架构演进与语音业务的技术跃迁 当我们在4G时代习惯了高清语音通话(VoLTE)的清晰稳定,5G时代VoNR(Voice over New Radio)的商用正在悄然重塑移动通信的语音业务版图。这场技术演进绝非简单的网络升级,而是从核心网架构到业…...

DESIGN.md,让AI设计不跑偏
使用 AI 设计工具时,最烦人的问题之一,就是输出不稳定。你明明已经告诉它:颜色怎么用、字体怎么搭、按钮要什么风格。可它生成几次之后,还是会偷偷改一点,最后做出来的界面风格前后不一致。DESIGN.md 就是为了解决这个…...

DLT Viewer:面向汽车电子系统的分布式日志诊断与实时监控技术方案
DLT Viewer:面向汽车电子系统的分布式日志诊断与实时监控技术方案 【免费下载链接】dlt-viewer Diagnostic Log and Trace viewing program 项目地址: https://gitcode.com/gh_mirrors/dl/dlt-viewer DLT Viewer是一款基于COVESA标准的专业诊断日志分析工具&…...

终极指南:如何用NoFences桌面分区工具提升3倍工作效率
终极指南:如何用NoFences桌面分区工具提升3倍工作效率 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否厌倦了Windows桌面上杂乱无章的图标?每天…...

在模型广场中根据任务需求与预算选择合适的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在模型广场中根据任务需求与预算选择合适的模型 面对文本生成、代码编写、逻辑推理等多样化的任务,开发者常常需要从众…...

RIS辅助无人机通信的能效优化与深度强化学习应用
1. 项目概述:RIS辅助无人机通信的能效革命在应急救灾、偏远地区覆盖等场景中,无人机(UAV)通信系统常面临两大核心挑战:一是复杂地形导致的信号遮挡问题,二是无人机有限的续航能力制约了长期作业。传统解决方案如增加中继节点会引入…...

Proxmark3GUI图形化工具:5分钟学会RFID卡片分析与数据管理
Proxmark3GUI图形化工具:5分钟学会RFID卡片分析与数据管理 【免费下载链接】Proxmark3GUI A cross-platform GUI for Proxmark3 client | 为PM3设计的跨平台图形界面 项目地址: https://gitcode.com/gh_mirrors/pr/Proxmark3GUI Proxmark3GUI是一款为Proxmar…...

Windows本地部署Claude代码助手:架构解析与实战指南
1. 项目概述与核心价值 最近在GitHub上看到一个挺有意思的项目,叫“Claude-code-ChatInWindows”,作者是LKbaba。光看名字,你大概能猜到它想干什么:在Windows系统里,让Claude这个AI来帮你写代码。这听起来是不是挺酷的…...

Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程
Adobe-GenP终极指南:5分钟破解Adobe创意套件限制的完整教程 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾因为Adobe Creative Cloud高昂的订阅…...