Linux文件的查找和打包以及压缩
文件的查找
文件查找的用处,在我们需要文件但却又不知道文件在哪里的时候
文件查找存在着三种类型的查找
1、which或whereis:查找命令的程序文件位置
2、locate:也是一种文件查找,但是基于数据库的查找
3、find:针对与文件名进行查找
查找文件的程序文件位置(which/whereis)
但我们使用命令时,其实系统是自动调用了关于其命令的程序,但为什么我们使用命令时,不需要输入路径而是直接输入命令呢?
因为在系统还有一个环境变量的存在,比如在使用ls时,环境变量就会帮助我们将ls补充为/usr/bin/ls
在shell编程中就可以将/usr/bin/ls作为ls程序的绝对路径,写在脚本中
但我们又怎么知道ls对应的是/usr/bin/ls呢?就是使用which或是whereis来查找的,语法:which 命令/whereis 命令
[root@localhost ~]#which ls
[root@localhost ~]#whereis ls
通过数据库来查找文件位置(locate)
在我们的系统当中,存在着一个专门存放文件位置的数据库,这个数据库会在开机的时候自动刷新来记录我们的文件的位置
这种通过数据库查找的方法还是需要依赖与"locate"命令,语法:locate 查找的大概文件名;如下
[root@localhost ~]#locate host

哎!突然发现会上图所示的报错,其原因已经很明显了,是因为没有”/var/lib/mlocate/mlocate.db“这个文件或者说是目录
因为locate是基于数据库来查询的,所以我们可以大胆的猜测一下是数据库没有更新的问题,使用数据库手动更新命令"updatedb"来进行更新,也可以直接重启系统
事实上,但我们创建一个新文件时,数据库中也是没有该新文件的信息的,同样需要手动更新数据库或重启系统来解决
如下,我们使用"updatedb"来手动更新数据库,并且来使用locate来查看数据中记录对与host的内容,因查看结果过多,我们将其产生的信息重定向到一个文件当中
[root@localhost ~]# updatedb
[root@localhost ~]# locate host > 1.txt
[root@localhost ~]#updatedb
产生如此多内容的原因是,在"locate host"输入的时候,系统会在数据库中检索host这个关键字,最后将路径带有host的文件全部列出来
在系统中,有一个极为特殊的目录/tmp,因为其目录性质是临时的。所以数据库是不会在这里面去寻找东西的;换句话说,一般情况下你是不会在垃圾桶里捡东西的
文件查找(find)
find工具是一个非常强大的文件查找工具
它可以支持按文件名查找、按文件大小查找、按文件对于在根目录的深度进行查找、按文件的属主属组进行查找、按文件类型进行查找等操作
并且我们还可以使用find对查找到的文件进行查找后的处理,如查找到之后删除等操作
我们可以将find工具理解为Windows中的查找工具
语法:find [path] [options] [expression] [action];path表示在哪个文件路径下查找;options表示查找对应的选项,如对应查找需求(文件名字、大小、属主等)
expression用来解释选项的内容、action在查找文件之后的动作
按照文件名查找(-name/-iname)
按文件名查找我们可以使用-name选项
如下,我们需要在/etc目录下对文件"hosts"进行查找,
[root@localhost ~]#find /etc -name "hosts"

但选项-name并不会对查找的文件区分大小写,并且Linux是大小写区分的系统,也就是说并不会查找如"Hosts"这种文件
但我们可以在这前面加一个选项"-i"成为"-iname",这样就可以在文件名大小不缺定的情况下进行查找,如下
[root@localhost ~]#find /etc -iname "hosts"

按照文件大小查找(-size)
环境准备,使用dd配合/dev/zero,在/etc/sysconfig目录下创建一个大小为121M的文件名为123.txt,然后使用-size选项查找出该文件
[root@localhost ~]#dd if=/dev/zero of=/etc/sysconfig/123.txt bs=1M count=121
/dev/zero是一个可以提供无限字节流的文件,经常用于我们的测试当中

紧接着我们就开始对该文件进行查找,使用find搭配-size选项,在/etc目录下查找文件大小大于120M的文件
[root@localhost ~]#find /etc -size +120M

反之,若是我们想查找小于120M的,则为"find /etc -size -120M";若是我们想查找刚刚好为120M的文件,则为"find /etc -size 120M"
按照目录的深度进行查找
目录的深度就是文件的层级,换句话说就是有多少个目录套目录,该方法可以限制其查找范围
我们已查找网卡的配置文件作为例子,网卡的配置文件为/etc/sysconfig/network-scripts/ifcfg-ens33
其层级逐步表示为"/"根目录表示为第一层,/etc表示为第二层,/etc/sysconfig表示为第三层,/etc/sysconfig/network-script表示为第四层
所以如果我们设置了查找目录深度为4的时,也就只能查看到"/etc/sysconfig/network-script"目录下的文件
在对目录的深度进行查找的时候,我们经常搭配着其他选项进行查找,如配合着"-name"进行查找,就可以查找指定目录范围的指定文件
想要同时使用两个选项查询,还要加上-a选项,才能同时使用两个选项进行查询,如下
[root@localhost ~]# find / -maxdepth 4 -a -name "ifcfg-ens33"

但若是将范围该为3,则代表只查询到/etc/sysconfig下的内容,所以必然是查询不到"ifcfg-ens33";图片如下

按照文件的属主和属组进行查找
环境准备:创建用户jack,创建组hr,在/home创建新文件text.txt,将text.txt的属主和属组分别该为jack和hr
[root@localhost ~]#useradd jack
[root@localhost ~]#groupadd hr
[root@localhost ~]#touch text.txt
[root@localhost ~]#chmod jack.hr text.txt
属主的选项为-user,与英译的意思是相同的;同样的属组的选项为-hr;如下
[root@localhost ~]#find . -user "jack" //在当前目录下查找所有属主为jack的文件
[root@localhost ~]#find . -group "hr" //在当前目录下查找所有属组为hr的文件
按照文件类型来查找
让我们来复习一下什么是文件类型
在使用"ll"或"ls -l"后,我们可以看到文件的详细信息,其中开头的第一列就表达的是文件类型
文件类型有很多种,如以"d"开头的是目录,"-"则是普通的文件,"b"开头的则是块文件用于表示磁盘的硬件
在按照文件类型来查找文件的时候,我们应该用的是选项是-type,英译过来正好是类型的意思,以此来方便记忆
但在-type后面 还要指定我们查找的是什么文件类型,如普通文件为"f",块文件为"b",目录为"d"以此类推;如下
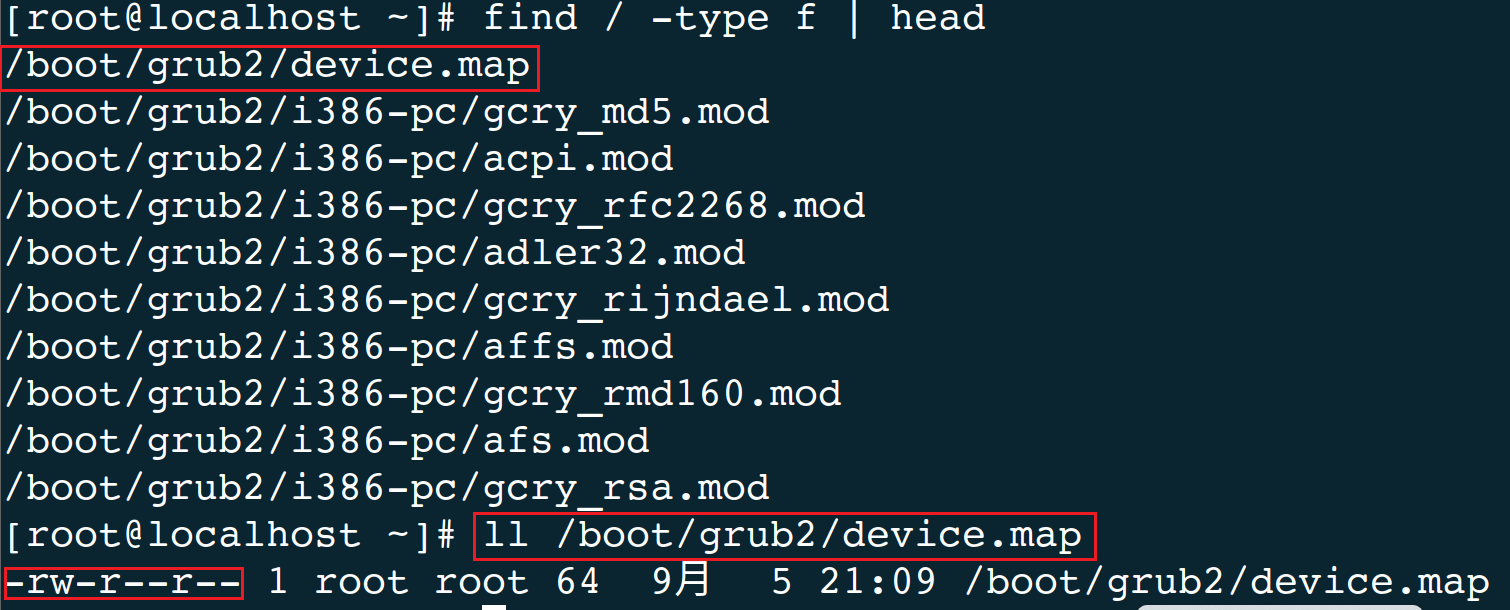
[root@localhost ~]#find / -type f | head //在根目录下查找文件类型为普通文件,并且只显示其前十行
[root@localhost ~]#ll /boot/grub2/device.map //验证是否正确
[root@localhost ~]#find / -type d | head //在根目录下查找文件类型为目录,并且只显示其前十行
按照文件的权限来查找
文件的权限有三种,属主、属组、其他人,其中可赋予的权限为可读可写可执行,分别用rwx来表示
我们通常数字来区分不同人(属主、属组、其他人)所拥有的权限,rwx分别对应的数字是421
如属主可读可写可执行,属组可读可写,其他人可读可写所表示的数字为766
而按照文件权限所查找的选项是-perm,其中permission为权限的意思;实例如下
[root@localhost ~]#find ./ -perm 666 //在当前目录下查找权限为666的文件
[root@localhost ~]#find ./ -perm 666 -ls //如果没有-ls选项,以文件详细的方式显示出来

找到后的处理的动作
通过前面从find查找练习,我们可以发现,我们平常查找之后的动作默认是-print,就是打印出来
但可以在查找后加上一些关于动作的选项,使得我们可以查找到文件后可以进行删除、复制等操作;如下
查找后删除
[root@localhost ~]#find ./ -perm 666 -delete //将当前目录下查找出来的权限为666的文件删除

查找后复制
我们先来看命令,然后在来逐个解析其意思
[root@localhost ~]#find ./ -perm 666 -ok cp -rvf {} /tmp \;
在上述命令中因为使用的cp的查找后动作,所以"find ./ -perm 666"的查找结果会被放到后面的"{}"内进行复制
-ok表示我们现在需要使用外接选项(如cp),同时表示在复制时我们要使用yes在确认复制,或使用no来使复制停止
-r表示递归复制即如果复制的是目录,将会使其的子目录一同复制
-v表示将复制过程显示出来,如果没有这个选项就不会有下图中"./text.txt -> /tmp/text.txt"的显示
-f表示cp这条命令不用进行确认可以直接复制
;是该命令的固定格式,必须要有才能成功执行该命令

文件的打包和压缩
文件的打包和解包
文件的打包
在我们对服务器进行管理时,通常会遇到需要转移多个文件的情况
这时,如果一个一个使用mv或cp命令进行转移会因为数量太多而导致太多麻烦
我们可以将我们需要的文件都组合起来,然后统一地打成一个包,方便我们进行多个文件的转移
在这里我们使用tar命令进行打包,同时所有使用tar命令打包后的包,都将会是以tar为后缀的;如下
[root@localhost ~]#tar -cf etc.tar /etc //将"/etc"打成一个tar包并存放在当前目录下
-c表示创建一个tar包(create创造),-f表示指定解包后的文件名

文件的解包
当我们打好的tar包被转移后,我们需要用到包里面的内容时,因为tar包的存在,所以是没办法直接使用的
这时,需要将tar包进行解包,里面的内容才能正常使用;如下
[root@localhost ~]#tar -xf etc.tar
在进行解包后,解包的内容会默认在当前目录下生成
解包与打包的选项不同在与解包的选项为"-xf",其中-f依旧是指定包的名称,而-x则表示解包

文件的压缩和解压缩
文件的压缩
在上述的打包学习中,只是为将多个文件集中成一个包然后转移,可其包的容量与原目录的容量却没发生变化;如下
这容易导致一些无用的资源却占用着存储空间,所以我们的压缩就应运而生
压缩其实就是将原目录先打成一个包,然后使用压缩工具将该目录包的存储空间减少,从而达到减少存储空间负担的目的
而这样子产生包就叫做压缩包
压缩的工具有三种,分别是gz、bz、xz;这三个打包工具的不同我们在后面的实验中一一道来
首先就是命令选项的不同,但整体命令还是大致一样的;如下
[root@localhost ~]# tar -czvf etc.tar.gz /etc //gz的压缩包命令
[root@localhost ~]# tar -cjf etc.tar.bz /etc //bz的压缩包命令
[root@localhost ~]# tar -cJf tec.tar.xz /etc //xz的压缩包命令
由上述命令可以总结出来,-c和-f选项与打tar包命令含义相同
至于-v则表示在终端上显示压缩的全过程(在这里则是将/etc被打压缩包的内容全部显示出来)
而gz的选项则是-z,换句话说,-z就表示该压缩包打的是gz包,并且我们还看到"etc.tar.gz"压缩包的名字还是以gz为后缀的
以此类推,bz的打压缩包选项为-j(小写);xz的打压缩包选项为-J(大写)
以上是,gz、bz、xz的在命令上的区别,但其实它们三个不同的还不止于此
如果你亲自地去做一遍以上三种包的打压缩包过程,则会发现,三个打包方式所使用的时间将会有明显的不同,为什么呢?
我们使用ll查看这三种方式打出来的包的详细信息,如下

从上图可知,三种打包工具所产生的压缩包容量从大到小依次为gz、bz、xz
而在打包过程中,打gz包所使用的时间最快,其次则是bz,最慢则是xz
所以这相当与我们想要有更小压缩包的体积、更大的容量,势必要失去一些时间,而失去什么则取决不同的生产环境
综上所述,gz、bz、xz的容量与打包时间成反比,所以并不是容量越小越好,还要考虑时间成本的问题
文件的解压缩
在老的Linux版本中,我们解包还要根据gz、bz、xz等压缩包的类型来使用不同的命令选项,就像打压缩包一样,gz或bz的解压缩包的命令选项也是不同的
但在新的Linux版本中,只需要使用一条命令就可以通解所有类型的压缩包,那就是"-xf"通解一切压缩包;如下
[root@localhost ~]# tar -xf etc.tar.gz
[root@localhost ~]# tar -xf etc.tar.bz
[root@localhost ~]# tar -xf etc.tar.xz
以上三条命令都可以在当前目录下解压出一个名为etc的目录
相关文章:
Linux文件的查找和打包以及压缩
文件的查找 文件查找的用处,在我们需要文件但却又不知道文件在哪里的时候 文件查找存在着三种类型的查找 1、which或whereis:查找命令的程序文件位置 2、locate:也是一种文件查找,但是基于数据库的查找 3、find:针…...

专题十四_哈希表_算法专题详细解答
目录 哈希表简介 1. 两数之和(easy) 解析: 解法一:暴力: 解法二:哈希O(N) 总结: 2. 判断是否互为字符重排(easy) 解析: 哈希: 总结&…...

C++源码生成·序章
文章目录 C源码生成序章1 概述1.1 前言1.2 Python 易用性简介 2 使用 python 生成 c 源码2.1 运行脚本2.2 结果 3 项目启动3.1 项目概述3.2 环境准备3.3 克隆仓库3.4 查看标签(Tags)3.4 根据标签拉取代码3.5 后续步骤 C源码生成序章 1 概述 1.1 前言 …...

Android中的MVP模式
MVP(Model-View-Presenter)架构在 Android 开发中是一种流行的架构模式,它将业务逻辑和 UI 代码分离,通过 Presenter 来处理用户的操作和界面更新。MVP 提高了代码的可维护性和测试性,特别是 Presenter 中的逻辑可以单…...

kebuadm部署k8s集群
官方文档: Installing kubeadm | Kubernetes 切记要关闭防⽕墙、selinux、禁用交换空间, cpu核⼼数⾄少为2 内存4G kubeadm部署k8s⾼可用集群的官方文档: Creating Highly Available Clusters with kubeadm | Kubernetes 你需要在每台…...

Unity3D学习FPS游戏(2)简单场景、玩家移动控制
前言:上一篇的时候,我们已经导入了官方fps的素材,并且对三维模型有了一定了解。接下来我们要构建一个简单的场景让玩家能够有地方移动,然后写一个简单的玩家移动控制。 简单场景和玩家移动 简单场景玩家移动控制玩家模型视野-摄像…...

网上的 AQS 文章让我很失望
一、AQS 很多人都没有讲明白 🤔 翻看了网上的 AQS(AbstractQueuedSynchronizer)文章,质量参差不齐,大多数都是在关键处跳过、含糊其词,美其名曰 “传播知识” 。 大多数都是进行大段的源码粘贴和注释&…...

滑动窗口子串
文章目录 滑动窗口一、无重复字符的最长子串二、找到字符串中所有字母异位词 子串三、和为 K 的子数组四、滑动窗口最大值五、最小覆盖子串 滑动窗口 一、无重复字符的最长子串 题目链接 (方法一:暴力枚举) (方法二ÿ…...

【windows11 提示“Microsoft Visual C++ Runtime Library Runtime Error】
windows11 提示“Microsoft Visual C++ Runtime Library Runtime Error” 问题描述解决方法郑重声明:本人原创博文,都是实战,均经过实际项目验证出货的 转载请标明出处:攻城狮2015 Platform: windows OS:windows11 问题描述 解决方法 下载VisualCppRedist_AIO_x86_x64.exe 安…...

【leetcode|哈希表、动态规划】最长连续序列、最大子数组和
目录 最长连续序列 解法一:暴力枚举 复杂度 解法二:优化解法一省去二层循环中不必要的遍历 复杂度 最大子数组和 解法一:暴力枚举 复杂度 解法二:贪心 复杂度 解法三:动态规划 复杂度 最长连续序列 输入输…...

【人工智能】掌握深度学习中的时间序列预测:深入解析RNN与LSTM的工作原理与应用
深度学习中的循环神经网络(RNN)和长短时记忆网络(LSTM)在处理时间序列数据方面具有重要作用。它们能够通过记忆前序信息,捕捉序列数据中的长期依赖性,广泛应用于金融市场预测、自然语言处理、语音识别等领域…...

今日开放!24下软考机考「模拟练习平台」操作指南来啦!
2024年下半年软考机考模拟练习平台今日开放,考生可以下载模拟作答系统并登录后进行模拟练习,熟悉答题流程及操作方法。 一、模拟练习时间 2024年下半年软考机考模拟练习平台开放时间为2024年10月23日9:00至11月6日17:00,共15天。 考生可以在…...

合并.md文档
需求:将多个.md文档合并成一个.md文档。 方法一:通过 type 命令 参考内容:多个md文件合并 步骤: 把需要合并的 .md 文档放入到一个文件夹内。修改需要合并的 .md 文档名,可以在文档名前加上 1.2.3 来表明顺序&#x…...

10月18日笔记(基于系统服务的权限提升)
系统内核漏洞提权 当目标系统存在该漏洞且没有更新安全补丁时,利用已知的系统内核漏洞进行提权,测试人员往往可以获得系统级别的访问权限。 查找系统潜在漏洞 手动寻找可用漏洞 在目标主机上执行以下命令,查看已安装的系统补丁。 system…...

【STM32 Blue Pill编程实例】-控制步进电机(ULN2003+28BYJ-48)
控制步进电机(ULN2003+28BYJ-48) 文章目录 控制步进电机(ULN2003+28BYJ-48)1、步进电机介绍2、ULN2003步进电机驱动模块3、硬件准备及接线4、模块配置3.1 定时器配置3.2 ULN2003输入引脚配置4、代码实现在本文中,我们将介使用 STM32Cube IDE 使用 ULN2003 电机驱动器来控制28B…...

监督学习、无监督学习、半监督学习、强化学习、迁移学习、集成学习分别是什么对应什么应用场景
将对监督学习、无监督学习、半监督学习、强化学习、迁移学习和集成学习进行全面而详细的解释,包括定义、应用场景以及具体的算法/模型示例。 1. 监督学习 (Supervised Learning) 定义:监督学习是一种机器学习方法,其中模型通过已知的输入数…...

WSL2 Linux子系统调整存储位置
WSL2 默认不支持修改Linux 安装路径,官方提供的方式,只有通过导出、导入的方式实现Linux子系统的迁移。 修改注册表的方式官方不推荐,没有尝试过,仅提供操作方式(自行评估风险,建议备份好数据) 1. 打开 **注册表编辑器…...

Shiro授权
一、定义与作用 授权(Authorization),也称为访问控制,是确定是否允许用户/主体做某事的过程。在Shiro安全框架中,授权是核心组件之一,它负责控制用户对系统资源的访问权限,确保用户只能访问其被…...
算法题总结(十五)——贪心算法(下)
1005、K 次取反后最大化的数组和 给你一个整数数组 nums 和一个整数 k ,按以下方法修改该数组: 选择某个下标 i 并将 nums[i] 替换为 -nums[i] 。 重复这个过程恰好 k 次。可以多次选择同一个下标 i 。 以这种方式修改数组后,返回数组 可…...

《深度学习》【项目】自然语言处理——情感分析 <下>
目录 一、了解项目 1、任务 2、文件内容 二、续接上篇内容 1、打包数据,转化Tensor类型 2、定义模型,前向传播函数 3、定义训练、测试函数 4、最终文件格式 5、定义主函数 运行结果: 一、了解项目 1、任务 对微博评论信息的情感分…...
)
别再只会用555了!用继电器搭建LED闪烁电路的3个隐藏知识点(附电路图)
继电器驱动LED闪烁电路:超越555的三大物理奥秘与实战设计 在电子爱好者的世界里,LED闪烁电路就像"Hello World"之于程序员,是入门必修的第一课。大多数教程会引导初学者使用555定时器这种"标准化方案",却很少…...

手机跑多模态也能快到飞起!面壁MiniCPM-V 4.6开源
大模型技术正快步从云端机房走入普通人的智能手机,让移动设备直接处理复杂的图文与视频任务成为现实。面壁智能最新开源的一款多模态模型,以极低的算力成本,超低的首Token延迟,成功打通当前三大主流手机操作系统。MiniCPM-V 4.6专…...

Xshell6启动报错0xc000007b:从DLL缺失到Visual C++库修复的完整排障指南
1. 当Xshell6突然罢工:0xc000007b报错初体验 那天早上我像往常一样双击Xshell6图标,准备连接服务器,结果突然弹出一个冰冷的错误窗口:"应用程序无法正常启动(0xc000007b)"。这种系统级错误代码对很多Windows用户来说就…...
)
小满nestjs(第八章 控制器参数解析实战:从装饰器到业务应用)
1. 控制器参数装饰器基础入门 刚开始接触NestJS时,最让我困惑的就是如何优雅地获取前端传递的参数。传统Express开发中我们需要手动从req对象里提取数据,而NestJS提供的一系列参数装饰器简直就像开了外挂。记得我第一次用Query()直接拿到URL参数时&#…...

基于SpringBoot的核酸检测与报告查询系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot框架的核酸检测与报告查询系统以解决当前核酸检测流程中存在的信息孤岛现象数据分散管理问题以及传统人工操作导致的效率低下…...

【Midjourney Sumi-e风格创作终极指南】:20年AI绘画专家亲授3大笔触控制法则、5类水墨失真避坑清单与实时渲染参数配置表
更多请点击: https://intelliparadigm.com 第一章:Sumi-e水墨美学与AI生成的本体论契合 留白即存在 水墨画中的“余白”并非空无,而是气韵流转的场域——这与生成式AI中隐空间(latent space)的拓扑结构惊人地同构。扩…...

3种高效方案:让Windows直接运行Android应用的全新体验手册
3种高效方案:让Windows直接运行Android应用的全新体验手册 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想象一下这样的场景:您需要在电脑上快…...

Linux 系统运行速度慢有哪些排查方法?
Linux 系统变慢通常是资源供需失衡导致的,建议按 CPU、内存、磁盘 I/O、网络的顺序依次排查,优先使用 top、free、iostat 等基础命令定位瓶颈。 先说结论:系统卡顿本质是核心资源被过度占用,需先定位具体瓶颈资源,再针…...
来了!)
一句话就能“劫持”你的AI?DZS 分层式自适应提示词注入攻击的防御机制框架 (HAA)来了!
本文所展示的提示词技术已在Research square 发表论文预印本。DOI:https://doi.org/10.21203/rs.3.rs-9653510/v1 作者“抖知书(douzhishu),涉及到相关测试数据是本人自行测试的,并未通过多专家评审,所以仅…...

基于python-telegram-bot的审批按钮系统设计与实现
1. 项目概述:一个为Telegram机器人设计的审批按钮系统如果你在团队协作、内容审核或者自动化流程中,经常需要通过Telegram机器人来处理“同意”或“拒绝”这类审批请求,那么你很可能遇到过这样的困扰:用户发来一条需要审核的消息&…...