网络爬虫中的反爬虫技术:突破限制,获取数据
,网络爬虫已成为获取大量网络数据的重要工具。然而,随着爬虫技术的发展,许多网站也开始采用各种反爬虫措施来保护自己的数据。作为爬虫开发者,我们需要不断更新我们的技术,以应对这些反爬虫措施。本文将详细介绍一些常见的反反爬虫(反渗透)技术,帮助你更有效地获取所需数据。
1. 理解反爬虫机制
在讨论反反爬虫技术之前,我们首先需要了解常见的反爬虫机制:
- IP限制:限制单个IP的访问频率
- User-Agent检测:禁止非浏览器的访问
- Cookie/Session验证:要求登录或保持会话
- 动态内容:使用JavaScript动态加载内容
- 验证码:要求人工输入验证码
- 蜜罐陷阱:设置虚假链接诱导爬虫
2. 反爬虫技术
2.1 IP代理池
使用代理IP是绕过IP限制的有效方法。你可以构建一个代理IP池,并在每次请求时随机选择一个代理IP。
import requests
from random import choiceproxies = [{'http': 'http://1.2.3.4:80'},{'http': 'http://5.6.7.8:8080'},# 添加更多代理IP
]def get_random_proxy():return choice(proxies)url = 'https://example.com'
response = requests.get(url, proxies=get_random_proxy())
2.2 User-Agent轮换
许多网站会检查User-Agent来识别爬虫。通过随机切换User-Agent,我们可以模拟不同的浏览器访问。
import requests
from random import choiceuser_agents = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.1 Safari/605.1.15',# 添加更多User-Agent
]def get_random_ua():return choice(user_agents)url = 'https://example.com'
headers = {'User-Agent': get_random_ua()}
response = requests.get(url, headers=headers)
2.3 处理Cookie和Session
对于需要登录的网站,我们可以使用requests的Session对象来维护会话状态。
import requestssession = requests.Session()# 登录
login_data = {'username': 'your_username', 'password': 'your_password'}
session.post('https://example.com/login', data=login_data)# 访问需要登录的页面
response = session.get('https://example.com/protected_page')
2.4 处理动态内容
对于使用JavaScript动态加载内容的网站,我们可以使用Selenium等工具来模拟浏览器行为。
from selenium import webdriver
from selenium.webdriver.chrome.options import Optionschrome_options = Options()
chrome_options.add_argument("--headless") # 无头模式
driver = webdriver.Chrome(options=chrome_options)driver.get('https://example.com')
# 等待动态内容加载
driver.implicitly_wait(10)# 获取动态加载的内容
content = driver.find_element_by_id('dynamic-content').textdriver.quit()
2.5 验证码处理
对于简单的验证码,我们可以使用OCR技术进行识别。对于复杂的验证码,可能需要使用机器学习模型或人工识别服务。
import pytesseract
from PIL import Imagedef solve_captcha(image_path):image = Image.open(image_path)return pytesseract.image_to_string(image)captcha_text = solve_captcha('captcha.png')
2.6 处理蜜罐陷阱
为了避免陷入蜜罐陷阱,我们可以实现一个智能的URL过滤器,只访问与目标相关的URL。
import redef is_valid_url(url):# 使用正则表达式或其他逻辑来判断URL是否有效pattern = r'https://example\.com/valid/.*'return re.match(pattern, url) is not Noneurls_to_crawl = ['https://example.com/valid/page1','https://example.com/trap/fake_page','https://example.com/valid/page2',
]valid_urls = [url for url in urls_to_crawl if is_valid_url(url)]
3. 爬虫行为优化
除了上述技术,我们还应该注意优化爬虫的行为,以减少被检测的风险:
- 控制爬取速度:模拟人类的访问频率
- 遵守robots.txt:尊重网站的爬虫规则
- 错误处理:妥善处理各种异常情况
- 数据本地化:减少重复请求,降低服务器负担
4. 伦理和法律考虑
在开发和使用爬虫时,我们必须考虑伦理和法律问题:
- 尊重网站的服务条款
- 不爬取敏感或私密信息
- 合理使用获取的数据
- 注意数据版权问题
结语
反爬虫是一个持续evolving的过程。作为爬虫开发者,我们需要不断学习和更新技术,以应对新的反爬虫措施。同时,我们也应该尊重网站的利益,在技术和伦理之间找到平衡点。希望本文介绍的技术能够帮助你更好地开发和优化你的爬虫项目。
相关文章:

网络爬虫中的反爬虫技术:突破限制,获取数据
,网络爬虫已成为获取大量网络数据的重要工具。然而,随着爬虫技术的发展,许多网站也开始采用各种反爬虫措施来保护自己的数据。作为爬虫开发者,我们需要不断更新我们的技术,以应对这些反爬虫措施。本文将详细介绍一些常…...

【ROS2】cv_bridge:ROS图像消息和OpenCV的cv::Mat格式转换库
1、简述 cv_bridge可以实现ROS图像消息(sensor_msgs::msg::Image)和OpenCV的cv::Mat格式的转换。 cv_bridge支持各种常见的图像编码格式,包括JPEG、PNG、BMP等。 2、互转 1)cv::Mat转sensor_msgs::Image cv::Mat image; sensor_msgs::ImagePtr pMsg = cv_bridge::CvIma…...

【Web.路由】——URL生成
前几篇文章介绍了路由的相关知识,包括原理,模板和约束。围绕的一个点就是URL,那么URL是如何生成的呢? 在 ASP.NET CORE应用程序中,使用了一个叫 LinkGenerator的链接生成器来生成URL的。 LinkGenerator是一个中间件组件…...

使用 Java 实现从搜索引擎批量下载图片
在进行一些数据收集、图像处理或研究工作时,我们可能需要从网络上批量下载高质量的图片。本文将介绍如何使用 Java 和 Jsoup 库,从搜索引擎中抓取图片,解析详情页并过滤出高质量图片。通过以下几个步骤,您可以自动化这个图片收集的…...

基于Matlab GUI的说话人识别测试平台
基于Matlab GUI的说话人识别测试平台 摘 要:为了克服在Matlab中语音处理工具箱的不足,设计出基于Matlab图形用户界面(GUI)的说话人识别测试平台。系统框架设计:特征参数采用美尔倒谱系数及差分美尔倒谱系数,…...

Leetcode 热题100之二叉树2
1.二叉树的层序遍历 思路分析:层序遍历是逐层从左到右访问二叉树的所有节点,通常可以使用广度优先搜索(BFS)来实现。我们可以使用一个队列(FIFO)来存储每一层的节点,并逐层访问。 初始化队列&a…...

<项目代码>YOLOv8 煤矸石识别<目标检测>
YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN),YOLOv8具有更高的…...

GA/T1400视图库平台EasyCVR视频分析设备平台微信H5小程序:智能视频监控的新篇章
GA/T1400视图库平台EasyCVR是一款综合性的视频管理工具,它兼容Windows、Linux(包括CentOS和Ubuntu)以及国产操作系统。这个平台不仅能够接入多种协议,还能将不同格式的视频数据统一转换为标准化的视频流,通过无需插件的…...
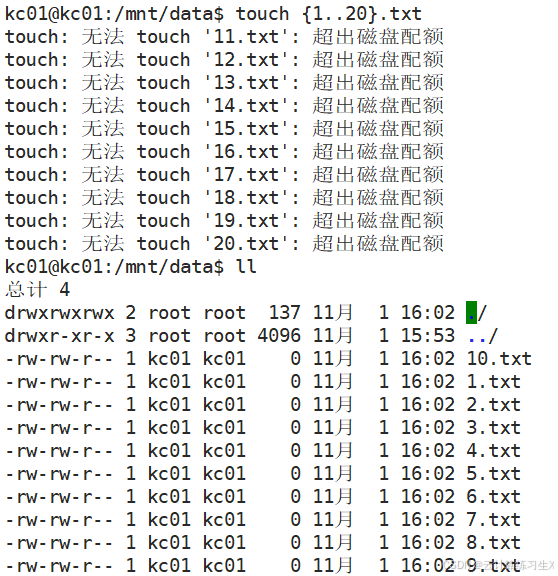
LVM与磁盘配额
文章目录 LVM与磁盘配额1 LVM概述1.1 名词解释1.2 LVM优势 2 LVM相关命令2.1 创建逻辑卷过程2.2 对逻辑卷扩容 3 磁盘配额3.1 磁盘配额的特点3.2 磁盘配额的命令3.3 查看配额使用情况3.4 验证磁盘配额3.5 实验 LVM与磁盘配额 1 LVM概述 1.1 名词解释 LVM:logical…...

xmuoj [蒙德里安的梦想] 状压dp个人笔记
本题是状压dp经典题目,很多人都是通过这一题开始对状压dp有所了解。 在进行讲解之前,我们先通过几个问答大致了解状压dp。 一、问答 1. 问题:什么是状压dp? 回答:状压dp即为状态压缩动态规划,何为状态压缩&#x…...

ubuntu22安装搜狗输入法不能输入中文
关闭Wayland 在/etc/gdm3/custom.conf文件内,取消注释WaylandEnable cat /etc/gdm3/custom.conf | grep WaylandEnable WaylandEnablefalse 其它步骤参考搜狗官方教程 https://pinyin.sogou.com/linux/help.php...

HtmlAgilityPack 操作详解
目录 1.安装 HtmlAgilityPack 2. 示例 HTML 3. 使用 HtmlAgilityPack 进行 HTML 解析与操作 4. 代码详解 1.加载html文档 2.选择元素 3. 提取属性 4.修改属性 5.常用的几种获取元素的 XPath 写法 HtmlAgilityPack: 轻量且高效,适合进行常规的 H…...

基于SSM医院门诊互联电子病历管理系统的设计
管理员账户功能包括:系统首页,个人中心,用户管理,医生管理,项目分类管理,项目信息管理,预约信息管理,检查信息管理,系统管理 用户账号功能包括:系统首页&…...
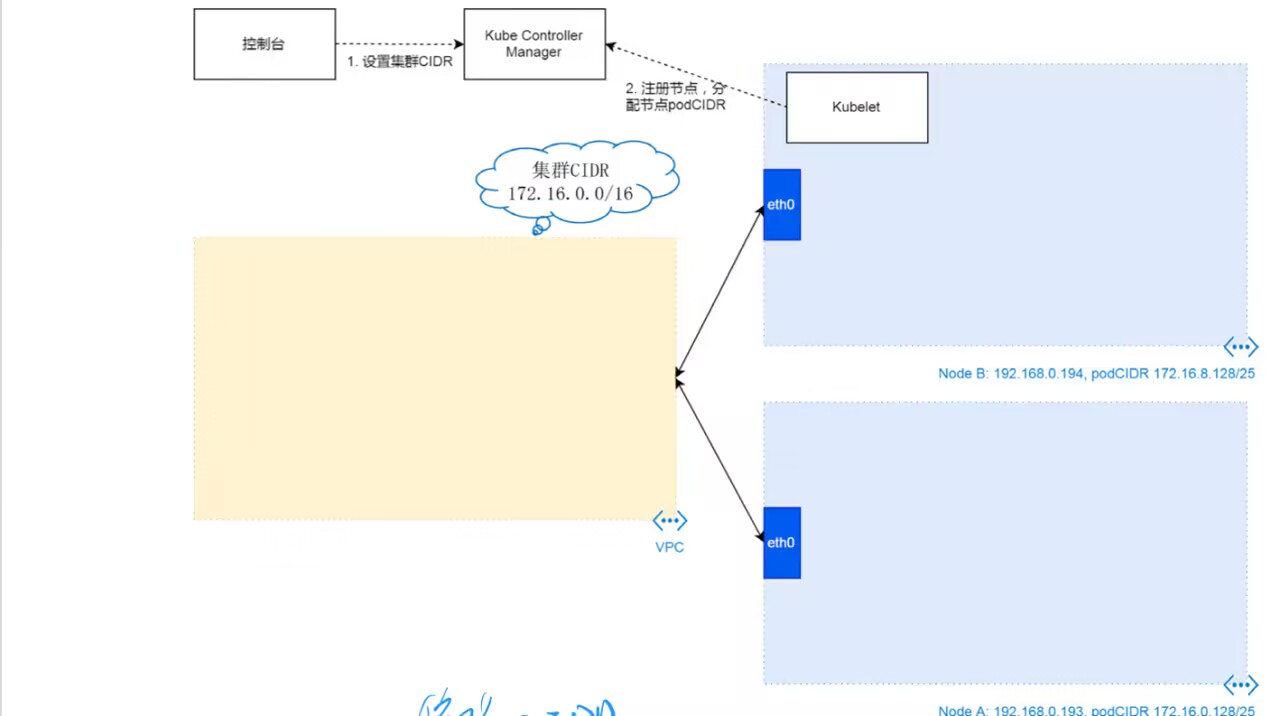
【读书笔记/深入理解K8S】集群网络
前言 上一章讲了集群控制器的一个大概的原理,这一章讲一下集群网络。网络是集群通信的载体,因为该书是阿里云团队出品的,所以也以阿里云的集群网络方案为例,其他云厂商的网络集群方案一般来说也大同小异。所以通过本章的学习&…...
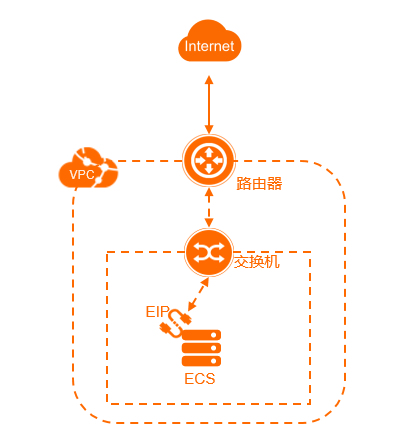
【专有网络VPC】连接公网
通过ECS实例固定公网IP、弹性公网IP、NAT网关、负载均衡使专有网络中的云资源可以访问公网(Internet)或被公网访问。 概述 专有网络是您自定义的云上私有网络。专有网络中的云资源默认无法访问公网,也无法被公网访问。您可以通过配置ECS实例…...

论文 | Legal Prompt Engineering for Multilingual Legal Judgement Prediction
这篇文章探讨了如何利用“法律提示工程”(LPE)来指导大型语言模型(LLM)进行多语言法律判决预测(LJP)。主要内容: LPE 的概念: LPE 是指通过设计特定的提示(promp…...

国科安芯抗辐照MCU和CANFD芯片发布
国科安芯科技有限公司近期发布了两款重要的芯片产品:抗辐照MCU芯片和抗辐照CANFD芯片。这两款芯片的发布标志着国科安芯在高性能、高安全性芯片产品研制方面取得了显著进展,特别是在抗辐照技术领域。 1. 抗辐照MCU芯片:国科安芯研发的AS32A4…...
)
C++ 并发专题 - 无锁数据结构(概述)
一:概述: 无锁数据结构是一种在多线程环境中实现线程安全的结构,它允许多个线程在没有传统锁机制的情况下并发访问和修改数据。这种设计的目标是提高程序的性能和响应性,避免锁竞争和上下文切换的开销。 二:原理&…...

NLP领域的经典算法和模型
在自然语言处理(NLP)领域,经典算法和模型众多,它们在不同任务中发挥着重要作用。以下是一些NLP领域的经典算法和模型的详细介绍: 一、基础模型 词袋模型(Bag of Words,BoW) 原理&a…...

提升安全上网体验:Windows 11 启用 DOH(阿里公共DNS)
文章目录 阿里公共 DNS 介绍免费开通云解析 DNS 服务Windows 编辑 DNS 设置配置 IPv4配置 IPv6 路由器配置 DNS 阿里公共 DNS 介绍 https://alidns.com/ 免费开通云解析 DNS 服务 https://dnsnext.console.aliyun.com/pubDNS 开通服务后,获取 DOH 模板࿰…...

RoboMaster新手必看:CAN通讯驱动GM6020电机,从ID配置到线序接法的保姆级避坑指南
RoboMaster新手必看:CAN通讯驱动GM6020电机,从ID配置到线序接法的保姆级避坑指南 第一次接触RoboMaster比赛的新手们,面对CAN总线驱动GM6020这类电调电机一体式设备时,常常会遇到"明明发送了CAN包但电机就是不转"的困扰…...
)
别再只盯着动态功耗了!聊聊CMOS电路中那个‘静悄悄’的静态功耗(以反相器为例)
别再只盯着动态功耗了!聊聊CMOS电路中那个‘静悄悄’的静态功耗(以反相器为例) 在低功耗芯片设计领域,工程师们常常将注意力集中在动态功耗的优化上——时钟网络的精简、门控时钟的引入、电压域的划分,这些技术确实能显…...

怎样给照片去背景?2026 图片抠图方法对比|免费在线工具实测
在日常生活中,我们经常需要给照片去背景——无论是制作证件照、电商商品图、社交媒体头像,还是创意合成,去背景都是最基础的图像处理需求。但面对五花八门的工具和方法,很多人不知道如何选择。本文将从多个维度全面对比 2026 年主…...

Pandas 数据清洗与分析
第一部分:水果销售分析(入门篇)首先,我们有一个简单的水果销售列表。我们的任务是算出每种水果的总销量,以及每天的销售明细。1. 数据准备我们先造一点数据:import pandas as pd import numpy as npdata {…...

Perplexity股票信息检索失效?7类常见报错代码对照表,含官方文档未披露的Rate Limit绕行方案
更多请点击: https://kaifayun.com 第一章:Perplexity股票信息检索失效?7类常见报错代码对照表,含官方文档未披露的Rate Limit绕行方案 当调用 Perplexity API 查询实时股票信息(如 PXLY、 NVDA)时&…...

2025最权威的十大AI科研工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 学术研讨范畴正在历经深度的变动,人工智能论文工具现身,极大地提高了…...

别再只会用pandas了!用openpyxl的load_workbook处理Excel,这些坑我帮你踩过了
别再只会用pandas了!用openpyxl的load_workbook处理Excel,这些坑我帮你踩过了 当Python开发者需要处理Excel文件时,pandas往往是首选工具——它简单、高效,能快速完成数据导入导出。但当你面对复杂格式的Excel文件,比…...

Taskbar11完全指南:解锁Windows 11任务栏自定义的终极解决方案
Taskbar11完全指南:解锁Windows 11任务栏自定义的终极解决方案 【免费下载链接】Taskbar11 Change the position and size of the Taskbar in Windows 11 项目地址: https://gitcode.com/gh_mirrors/ta/Taskbar11 还在为Windows 11任务栏的严格限制感到困扰吗…...
)
别再手动reshape了!用einops.rearrange优雅处理PyTorch张量维度(附实战代码)
用einops.rearrange重塑PyTorch张量:告别混乱的维度操作 深度学习开发中最令人头疼的莫过于张量维度的变换。你是否曾在凌晨三点盯着屏幕,试图理解自己昨天写的permute和reshape组合到底在做什么?或者花费半小时调试一个维度不匹配的错误&…...
)
STM32 ADS1115接口文件(HAL库+硬件IIC)
STM32 ADS1115接口文件(HAL库硬件IIC) 【下载地址】STM32ADS1115接口文件HAL库硬件IIC 本资源包专为STM32系列微控制器设计,旨在简化通过HAL库利用硬件IIC接口与ADS1115高精度模拟到数字转换器(ADC)交互的过程。ADS1115是一款高性能的16位ΔΣ…...