Kafka相关知识点(上)
为什么要使用消息队列?
使用消息队列的主要目的主要记住这几个关键词:解耦、异步、削峰填谷。
解耦: 在一个复杂的系统中,不同的模块或服务之间可能需要相互依赖,如果直接使用函数调用或者 API 调用的方式,会造成模块之间的耦合,当其中一个模块发生改变时,需要同时修改调用方和被调用方的代码。而使用消息队列作为中间件,不同的模块可以将消息发送到消息队列中,不需要知道具体的接收方是谁,接收方可以独立地消费消息,实现了模块之间的解耦。
异步: 有些操作比较耗时,例如发送邮件、生成报表等,如果使用同步的方式处理,会阻塞主线程或者进程,导致系统的性能下降。而使用消息队列,可以将这些操作封装成消息,放入消息队列中,异步地处理这些操作,不影响主流程的执行,提高了系统的性能和响应速度。
削峰填谷:削峰填谷是一种在高并发场景下平衡系统压力的技术,通常用于平衡系统在高峰期和低谷期的资源利用率,提高系统的吞吐量和响应速度。在削峰填谷的过程中,通常使用消息队列作为缓冲区,将请求放入消息队列中,然后在系统负载低的时候进行处理。这种方式可以将系统的峰值压力分散到较长的时间段内,减少瞬时压力对系统的影响,从而提高系统的稳定性和可靠性。
另外消息队列还有以下优点:
1**.可靠性高:**消息队列通常具有高可靠性,可以实现消息的持久化存储、消息的备份和故障恢复等功能,保证消息不会丢失。
2.**扩展性好:**通过增加消息队列实例或者添加消费者实例,可以实现消息队列的水平扩展,提高系统的处理能力。
**3.灵活性高:**消息队列通常支持多种消息传递模式,如点对点模式和发布/订阅模式,可以根据不同的业务场景选择不同的模式。
扩展知识
消息队列实现
市面上有很多成熟的消息队列中间件可以供我们使用,其中比较常用的有kafka、activeMQ、RabbitMQ和RocketMQ等。
Kafka、ActiveMQ、RabbitMQ和RocketMQ都有哪些区别?
典型回答
Kafka、ActiveMO、RabbitMQ和RocketMQ都是常见的消息中间件,它们都提供了高性能、高可用、可扩展的消息传递机制,但它们之间也有以下一些区别:
1.消息传递模型:Kafka主要支持发布-订阅模型,ActiveMQ、RabbitMQ和RocketMQ则同时支持点对点和发布-订阅两种模型。
2.性能和吞吐量:Kafka在数据处理和数据分发方面表现出色,可以处理每秒数百万条消息,而ActiveMQ、RabbitMQ和RocketMQ的吞吐量相对较低。
3.消息分区和负载均衡:Kafka将消息划分为多个分区,并分布在多个服务器上,实现负载均衡和高可用性。ActiveMQ、RabbitMQ和RocketMQ也支持消息分区和负载均衡,但实现方式不同,例如RabbitMQ使用了一种叫做Sharding的机制。
4.开发和部署复杂度:Kafka相对比较简单,易于使用和部署,但在实现一些高级功能时需要进行一些复杂的配置。ActiveMQ、RabbitMQ和RocketMQ则提供了更多的功能和选项,也更加灵活,但相应地会增加开发和部署的复杂度。
5.社区和生态:Kafka、ActiveMQ、RabbitMQ和RocketMQ都拥有庞大的社区和完善的生态系统,但Kafka和RocketMQ目前的发展势头比较迅猛,社区活跃度也相对较高。
6.功能支持:

总的来说,这些消息中间件都有自己的优缺点,选择哪一种取决于具体的业务需求和系统架构。
扩展知识
如何选型
在选择消息队列技术时,需要根据实际业务需求和系统特点来选择,以下是一些参考因素:
1.性能和吞吐量:如果需要处理海量数据,需要高性能和高吞吐量,那么Kafka是一个不错的选择
2.可靠性:如果需要保证消息传递的可靠性,包括数据不丢失和消息不重复投递,那么RocketMQ和RabbitMQ都提供了较好的可靠性保证。
3.消息传递模型:如果需要支持发布-订阅和点对点模型,那么RocketMQ和RabbitMQ是一个不错的选择。如果只需要发布-订阅模型,Kafka则是一个更好的选择
4.消息持久化:如果需要更快地持久化消息,并且支持高效的消息查询,那么Kafka是一个不错的选择。如果需要更加传统的消息持久化方式,那么RocketMO和RabbitMO可以满足需求
5.开发和部署复杂度:Kafka比较简单,易于使用和部署,但在实现一些高级功能时需要进行一些复杂的配置RocketMQ和RabbitMQ提供了更多的功能和选项,也更加灵活,但相应地会增加开发和部署的复杂度。
6.社区和生态:Kafka、RocketMQ和RabbitMQ都拥有庞大的社区和完善的生态系统,但Kafka和RocketMO目前的发展势头比较迅猛,社区活跃度也相对较高。
7.实现语言方面,kafka是基于scala和java开发的,rocketmg、activemg等都是基于iava语言的,rabbitmg是基于erlang的。
8.功能性,上面列举过一些功能,我们在选型的时候需要看哪个可以满足我们的需求,
需要根据具体情况来选择最适合的消息队列技术。如果有多个因素需要考虑,可以进行性能测试和功能评估来辅助选择。
Kafka 为什么这么快?
kafka是一个成熟的消息队列,一直以性能高著称,它之所以能够实现高吞吐量和低延迟,主要是由于以下几个方面的优化,我试着从发送端,存储端以及消费端分别介绍一下。
消息发送
1.批量发送:Kafka 通过将多个消息打包成一个批次,减少了网络传输和磁盘写入的次数,从而提高了消息的吞吐量和传输效率。
2.异步发送:生产者可以异步发送消息,不必等待每个消息的确认,这大大提高了消息发送的效率。
3.消息压缩:支持对消息进行压缩,减少网络传输的数据量。
4.并行发送:通过将数据分布在不同的分区(Partitions)中,生产者可以并行发送消息,从而提高了吞吐量。
消息存储
1.零拷贝技术:Kafka 使用零拷贝技术来避免了数据的拷贝操作,降低了内存和 CPU 的使用率,提高了系统的性能。

2.磁盘顺序写入:Kafka把消息存储在磁盘上,且以顺序的方式写入数据。顺序写入比随机写入速度快很多,因为它减少了磁头寻道时间。避免了随机读写带来的性能损耗,提高了磁盘的使用效率。
3.页缓存:Kafka 将其数据存储在磁盘中,但在访问数据时,它会先将数据加载到操作系统的页缓存中,并在页缓存中保留一份副本,从而实现快速的数据访问。
4.稀疏索引:Kafka 存储消息是通过分段的日志文件,每个分段都有自己的索引文件。这些索引文件中的条目不是对分段中的每条消息都建立索引,而是每隔一定数量的消息建立一个索引点,这就构成了稀疏索引。稀疏索引减少了索引大小,使得加载到内存中的索引更小,提高了查找特定消息的效率
5.分区和副本:Kafka 采用分区和副本的机制,可以将数据分散到多个节点上进行处理,从而实现了分布式的高可用性和负载均衡。
消息消费
1.消费者群组:通过消费者群组可以实现消息的负载均衡和容错处理
2.并行消费:不同的消费者可以独立地消费不同的分区,实现消费的并行处理。
3.批量拉取:Kafka支持批量拉取消息,可以一次性拉取多个消息进行消费。减少网络消耗,提升性能

Kafka的架构是怎么样的?
典型回答
Kafka 的整体架构比较简单,是显式分布式架构,主要由 Producer(生产者)、broker(Kafka集群)和consumer(消费者)组成

生产者(Producer):生产者负责将消息发布到Kafka集群中的一个或多个主题(Topic),每个Topic包含一个或多个分区(Partition)。
主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
消费者(Consumer):消费者负责从Kafka集群中的一个或多个主题消费消息,并将消费的偏移量(Offset)提交回Kafka以保证消息的顺序性和一致性。
偏移量:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
Kafka集群:Kafka集群是由多个Kafka节点(Broker)组成的分布式系统。每个节点都可以存储一个或多个主题(topic)的分区(partition)副本,以提供高可用性和容错能力。
如下图中,包含了 Broker1、Broker2和 Broker3组成了一个集群。用来提升高可用性。

**在集群中,每个分区(partition)都可以有多个副本。这些副本中包含了一个Leader(也可以叫做LeaderPartition 或者 Leader Replication)和多个Follower(也可以叫做Follower Partition 或者 FollowerReplication),****只有Leader 才能处理生产者和消费者的请求,而Follower 只是Leader 的备份,用于提供数据的冗余备份和容错能力。**如果 Leader 发生故障,Kafka 集群会自动将 Follower 提升为新的 Leader,从而实现高可用性和容错能力。
ZooKeeper:ZooKeeper是Kafka集群中使用的分布式协调服务,用于维护Kafka集群的状态和元数据信息,例如主题和分区的分配信息、消费者组和消费者偏移量等。
Kafka如何保证消息不丢失?
典型回答
Kafka作为一个消息中间件,他需要结合消息生产者和消费者一起才能工作,一次消息发送包含以下是三个过程
1)Producer 端发送消息给 Kafka Broker
2)Kafka Broker 将消息进行同步并持久化数据.
3)Consumer端从Kafka Broker 将消息拉取并进行消费,
Kafka只对已提交的消息做最大限度的持久化保证不丢失,但是没办法保证100%。
但是,Kafka还是提供了很多机制来保证消息不丢失的。要想知道Kafka如何保证消息不丢失,需要从生产者、消费者以及kafka集群三个方面来分析。
1、生产者:当我们采用异步发送的时候,可以设置一个回调函数,如果发送失败,会进行重试。并且使用acks机制,比如acks=-1,就必须保证消息写入了所有的同步副本才写入成功,否则就会重试。
2、Broker集群:①具有消息的持久化机制,当消息被写入消息队列后,会被持久化到磁盘。②有同步副本:每个分区都有多个副本,副本可以分布在不同的节点上。当一个节点宕机时,其他节点上的副本仍然可以提供服务,保证消息不丢失。
3、消费者:①消费者记录每个分区消息消费的偏移量,每次都会记录下来,为了保证消息不丢失,建议使用手动提交偏移量的方式,避免拉取了消息以后,业务逻辑没处理完,提交偏移量后但是消费者挂了的问题。②Kafka消费者还可以组成消费者组,每个消费者组可以同时消费多个分区。当一个消费者组中的消费者宕机或者不可用时,其他消费者仍然可以消费该组的分区,保证消息不丢失,
Producer
消息的生产者端,最怕的就是消息发送给Kafka集群的过程中失败,所以,我们需要有机制来确保消息能够发送成功,但是,因为存在网络问题,所以基本没有什么办法可以保证一次消息一定能成功。
所以,就需要有一个确认机制来告诉生产者这个消息是否有发送成功,如果没成功,需要重新发送直到成功。
我们通常使用Kafka发送消息的时候,通常使用的 producer.send(msg)其实是一种异步发送,发送消息的时候,方法会立即返回,但是并不代表消息一定能发送成功。(producer.send(msg).get() 是同步等待返回的。)
那么,为了保证消息不丢失,通常会建议**使用 producer.send(msg,callback)方法,**这个方法支持传入一个callback,我们可以在消息发送时进行重试。
同时,我们也可以通过给producer设置一些参数来提升发送成功率:
Broker
Kafka的集群有一些机制来保证消息的不丢失,比如复制机制、持久化存储机制以及ISR机制。
·持久化存储:Kafka使用持久化存储来存储消息。这意味着消息在写入Kafka时将被写入磁盘,这种方式可以防止消息因为节点宕机而丢失。
·ISR复制机制:Kafka使用ISR机制来确保消息不会丢失,Kafka使用复制机制来保证数据的可靠性。每个分区都有多个副本,副本可以分布在不同的节点上。当一个节点宕机时,其他节点上的副本仍然可以提供服务,保证消息不丢失。
在服务端,也有一些参数配置可以调节来避免消息丢失:

Consumer
作为Kafka的消费者端,只需要确保投递过来的消息能正常消费,并且不会胡乱的提交偏移量就行了。
Kafka消费者会跟踪每个分区的偏移量,消费者每次消费消息时,都会将偏移量向后移动。当消费者宕机或者不可用时,Kafka会将该消费者所消费的分区的偏移量保存下来,下次该消费者重新启动时,可以从上一次的偏移量开始消费消息。
另外,Kafka消费者还可以组成消费者组,每个消费者组可以同时消费多个分区。当一个消费者组中的消费者宕机或者不可用时,其他消费者仍然可以消费该组的分区,保证消息不丢失,
为了保证消息不丢失,建议使用手动提交偏移量的方式,避免拉取了消息以后,业务逻辑没处理完,提交偏移量后但是消费者挂了的问题:

Kafka怎么保证消费只消费一次的?(防止重复消费)
典型回答
Kafka消息只消费一次,这个需要从多方面回答,既包含Kafka自身的机制,也需要考虑客户端自己的重复处理。
可以从以下几个方面回答:
首先,在Kafka中,每个消费者都必须加入至少一个消费者组。同一个消费者组内的消费者可以共享消费者的负载。因此,如果一个消息被消费组中的任何一个消费者消费了,那么其他消费者就不会再收到这个消息了。
另外,消费者可以通过手动提交消费位移来控制消息的消费情况。通过手动提交位移,消费者可以跟踪自己已经消费的消息,确保不会重复消费同一消息。
还有就是客户端自己可以做一些幂等机制,防止消息的重复消费。
另外可以借助Kafka的Exactly-once消费语义,其实就是引入了事务,消费者使用事务来保证消息的消费和位移提交是原子的,而生产者可以使用事务来保证消息的生产和位移提交是原子的。Exactly-once消费语义则解决了重复问题,但需要更复杂的设置和配置。
回答:
1、首先kafka使用消费者组的机制,可以确保如果一个消息被消费组中的任何一个消费者消费了,那么其他消费者就不会再收到这个消息了。
2、使用kafka的消息语义Exactly-once,它是使用了事务来保证消息的消费和位移提交是原子的,不会说消费了消息但是位移提交失败,并且生产者使用事务来保证消息的生产和位移提交是原子的,不会重复发送消息。
3、客户端做一些幂等机制,使得消息即使重复消费了,最后的结果也是一样的。
扩展知识
Kafka的三种消息传递语义
在Kafka中,有三种常见的消息传递语义:At-least-once、At-most-once和Exactly-once。其中At-least-once和Exactly-once是最常用的。
At-least-once消费语义
At-least-once消费语义意味着消费者至少消费一次消息,但可能会重复消费同一消息。在At-least-once语义中,当消费者从Kafka服务器读取消息时,消息的偏移量会被记录下来。一旦消息被成功处理,消费者会将位移提交回Kafka服务器。如果消费消息成功但是提交位移失败,这意味着该消息将在下一次重试时再次被消费。
At-least-once语义通常用于实时数据处理或消费者不能容忍数据丢失的场景,例如金融交易或电信信令。
Exactly-once消费语义
Exactly-once消费语义意味着每个消息仅被消费一次,且不会被重复消费。在Exactly-once语义中,Kafka保证消息只被处理一次,同时保持消息的顺序性。为了实现Exactly-once语义,Kafka引入了一个新的概念:事务。
事务是一系列的读写操作,这些操作要么全部成功,要么全部失败。在Kafka中,生产者和消费者都可以使用事务,以保证消息的Exactly-once语义。具体来说,消费者可以使用事务来保证消息的消费和位移提交是原子的而生产者可以使用事务来保证消息的生产和位移提交是原子的。
在Kafka 0.11版本之前,实现Exactly-once语义需要一些特殊的配置和设置。但是,在Kafka 0.11版本之后Kafka提供了原生的Exactly-once支持,使得实现Exactly-once变得更加简单和可靠。
总之,At-least-once消费语义保证了数据的可靠性,但可能会导致数据重复。而Exactly-once消费语义则解决了重复问题,但需要更复杂的设置和配置。选择哪种消费语义取决于业务需求和数据可靠性要求。
相关文章:
Kafka相关知识点(上)
为什么要使用消息队列? 使用消息队列的主要目的主要记住这几个关键词:解耦、异步、削峰填谷。 解耦: 在一个复杂的系统中,不同的模块或服务之间可能需要相互依赖,如果直接使用函数调用或者 API 调用的方式,会造成模块之间的耦合…...

network HCIE认证
#1 ip地址设置 ip add 192.168.1.1 255.255.255.0 ip add 192.168.1.2 255.255.255.0 #2 DHCP 交换机上配置 system-view //进入系统配置 dhcp enable int g0/0/1 //接入接口管理 dhcp select interface //配置dncp选择接口 #3 DNS域名系统 int g0/0/1 dhcp server dn…...

造纸粉体分散机、改性包覆机、改性打散机
包覆改性机在造纸填料中的应用是近年来造纸行业技术创新的一个重要方向。通过包覆改性,可以改善填料的表面性质,提升其在纸张中的留着率和分布均匀性,进而增强纸张的性能,降低生产成本。以下是包覆改性机在造纸填料中的具体应用及…...

npm入门教程1:npm简介
一、基本概述 定义:npm是一个开源的JavaScript包管理器,它允许开发者下载、安装、发布和管理Node.js包。地位:npm是Node.js生态系统中不可或缺的一部分,为开发者提供了丰富的第三方库和工具。起源:npm由Isaac Z. Schl…...

Vue3使用AntV | X6绘制流程图:开箱即用
x6官方地址X6图编辑引擎 | AntV 官方文档仔细地介绍了很多丰富的功能,这里的demo可以满足基本的使用,具体拓展还需要仔细看文档内容 先上效果图 1、安装 通过 npm 或 yarn 命令安装 X6。 # npm npm install antv/x6 --save# yarn yarn add antv/x6 …...

grpc 快速入门
gRPC 是一个现代的远程过程调用(RPC)框架,由 Google 开发。它使用 HTTP/2 作为传输协议,并采用 Protocol Buffers(protobuf)作为接口描述语言(IDL)。gRPC 提供高效的通信、语言无关性…...

layui 实现 城市联动
<div class"layuimini-container"><form id"app-form" class"layui-form layuimini-form"><div class"layui-form-item"><label class"layui-form-label">标题</label><div class"la…...
- 常用数学函数 - 分类及比较 - 对给定的浮点值分类(std::fpclassify))
C++11标准模板(STL)- 常用数学函数 - 分类及比较 - 对给定的浮点值分类(std::fpclassify)
常用数学函数 对给定的浮点值分类 std::fpclassify 定义于头文件 <math.h> #define fpclassify(arg) /* implementation defined */ (C99 起) 归类浮点值 arg 到下列类别中:零、非正规、正规、无穷大、 NaN 或实现定义类别。该宏返回整数值。 忽略 FLT_EV…...

报错:npm : 无法加载文件 C:\Program Files\nodejs\npm.ps1,因为在此系统上禁止运行脚本。
报错场景 使用npm run dev 报错 npm : 无法加载文件 C:\Program Files\nodejs\npm.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 https:/go.microsoft.com/fwlink/?LinkID135170 中的 about_Execution_Policies。 所在位置 行:1 字符: 1 npm…...

OpenCV基本操作(python开发)——(7)实现图像校正
OpenCV基本操作(python开发)——(1) 读取图像、保存图像 OpenCV基本操作(python开发)——(2)图像色彩操作 OpenCV基本操作(python开发)——(3&…...

[项目] C++基于多设计模式下的同步异步日志系统
[项目] C基于多设计模式下的同步&异步日志系统 文章目录 [项目] C基于多设计模式下的同步&异步日志系统日志系统1、项目介绍2、开发环境3、核心技术4、日志系统介绍4.1 日志系统的价值4.2 日志系统技术实现4.2.1 同步写日志4.2.2 异步写日志 5、相关技术知识5.1 不定参…...

Vue常用的修饰符有哪些?
修饰符(Modifiers)是用于指定以特殊方式绑定或处理Vue事件或指令的特殊符号。 事件修饰符 .stop: 阻止时间继续传播,相当于调用event.stopPropagation() .prevent: 阻止默认事件,相当于调用event.preventDefault() .capture: 使…...

AnatoMask的分层图像编码器-解码器
方法思想 采用多尺度编码器-解码器主干: 在编码器中,把CT图像分解成不同大小的图像块,从这些图像块中提取特征在解码器中,重建被掩盖图像时,考虑图像块的空间关系 输入D(深度Depth)张H&#x…...

面向对象编程的核心特性:封装、继承、多态与抽象
封装(Encapsulation): 定义:封装是面向对象编程中的一个基本原则,它指的是将对象的状态(属性)和行为(方法)捆绑在一起,并对外隐藏对象的内部实现细节…...

ubuntu openmpi安装(超简单)
openmpi安装 apt update apt install openmpi-bin openmpi-common libopenmpi-dev安装到此完毕 测试一下,success !...

Python中的SQL数据库管理:SQLAlchemy教程
Python中的SQL数据库管理:SQLAlchemy教程 在Python应用程序中,操作数据库是常见的需求之一。而 SQLAlchemy 是一个功能强大的数据库管理库,它提供了Pythonic的接口来管理和查询SQL数据库。SQLAlchemy 兼具 ORM(对象关系映射&…...

LeetCode --- 421周赛
题目列表 3334. 数组的最大因子得分 3335. 字符串转换后的长度 I 3336. 最大公约数相等的子序列数量 3337. 字符串转换后的长度 II 一、数组的最大因子得分 数据范围足够小,可以用暴力枚举移除的数字,得到答案,时间复杂度为O(n^2)&#…...

简单了解前缀树/字典树(Trie树)C++代码
介绍Trie树 Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补全和拼写检查。 前缀树也有一些其它的名称:字典…...

ubuntu安装与配置Nginx(2)
1. 配置 Nginx Nginx 的配置文件通常位于 /etc/nginx/nginx.conf,而虚拟主机的配置文件通常在 /etc/nginx/sites-available/ 和 /etc/nginx/sites-enabled/ 目录中。 在/etc/nginx/conf.d目录下新建xx.conf文件,配置文件, nginx -t 检查语法…...
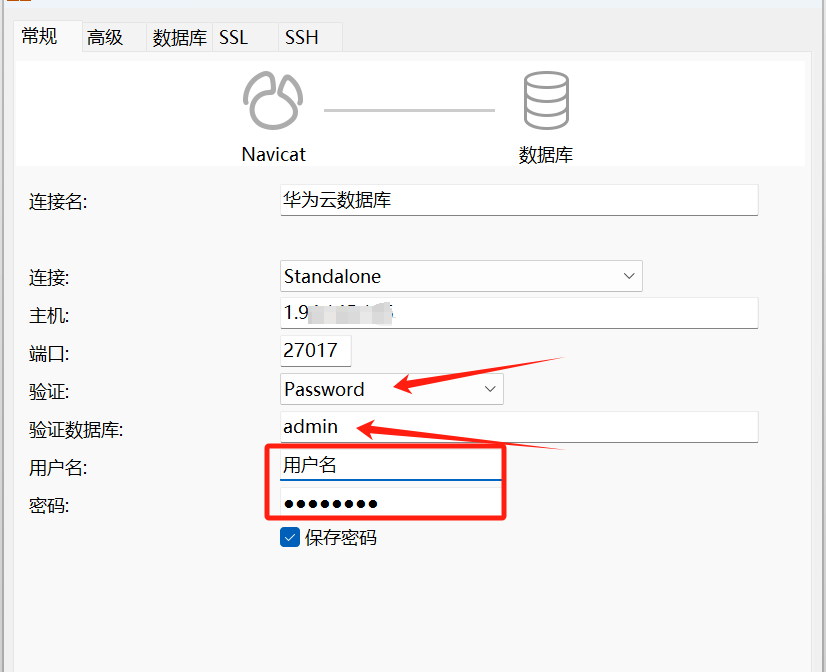
Linux环境下Mongodb部署
文章目录 一、系统环境二、MongoDb安装添加MongoDB官方库安装MongoDB配置MongoDB 三、MongoDB常见操作四、MongoDB用户管理创建用户修改密码删除用户 五、启用安全控制六、备份与还原1. 备份2. 恢复 七、外部工具连接MongoDB 一、系统环境 CentOS Stream 9 64bit 二、MongoD…...

终极指南:如何使用AppleRa1n工具安全绕过iOS 15-16激活锁
终极指南:如何使用AppleRa1n工具安全绕过iOS 15-16激活锁 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n iOS激活锁绕过是许多iPhone用户在设备所有权验证遇到困难时的迫切需求。AppleRa1n…...

如何实现Minecraft离线畅玩?PrismLauncher-Cracked完全指南
如何实现Minecraft离线畅玩?PrismLauncher-Cracked完全指南 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a functional Online Ac…...

利用 Taotoken 多模型能力为 AIGC 应用构建降级容灾方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 多模型能力为 AIGC 应用构建降级容灾方案 当你的 AIGC 应用从内部测试走向面向真实用户的生产环境时,服…...

终极指南:如何使用Legacy-iOS-Kit让旧iPhone重获新生
终极指南:如何使用Legacy-iOS-Kit让旧iPhone重获新生 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit 你…...

ESP32硬件IIC驱动SHT30:从零构建温湿度监测组件
1. ESP32与SHT30传感器入门指南 第一次接触ESP32和SHT30温湿度传感器时,我完全被各种专业术语搞晕了。后来在实际项目中摸爬滚打才发现,这套组合其实特别适合物联网开发新手。ESP32就像个全能型选手,自带Wi-Fi和蓝牙,而SHT30则是瑞…...
)
告别Xilinx思维:用Microsemi Libero为SmartFusion FPGA创建你的第一个工程(附资源清单)
告别Xilinx思维:用Microsemi Libero为SmartFusion FPGA创建你的第一个工程(附资源清单) 当习惯了Xilinx Vivado或Intel Quartus的工程师第一次打开Microsemi Libero时,那种感觉就像突然被扔进了一个陌生的城市——所有的路标都似…...

OAuth 2.0 and OIDC 三大安全机制对比:State vs Nonce vs PKCE
一、问题背景 OAuth 2.0 和 OpenID Connect 的授权流程依赖浏览器重定向,这天然暴露了多种攻击面: 攻击类型描述CSRF攻击者诱导用户的浏览器携带恶意授权码完成绑定Token 重放窃取的 id_token 被重复提交给客户端授权码劫持恶意应用在同一设备上拦截授…...

ArcSWAT建模踩坑记:你的土壤数据库参数算对了吗?聊聊SPAW的那些默认值和单位陷阱
ArcSWAT土壤参数校准实战:避开SPAW计算中的5个致命误区 当水文模拟结果与实测数据出现系统性偏差时,经验丰富的建模者会首先检查土壤参数——这个隐藏在界面背后的"沉默变量"往往是误差的最大来源。SPAW作为ArcSWAT推荐的土壤参数计算工具&…...

终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点
终极免费Switch模拟器yuzu:解决电脑玩任天堂游戏的5大痛点 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在电脑上畅玩Switch游戏却总是遇到各种问题?yuzu模拟器作为全球最受欢迎的开源任…...

如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南
如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用而犹豫…...