【YOLO学习】YOLOv8改进举例
文章目录
- 1. ODConv
- 1.1 修改
- 1.2 原yaml文件
- 1.3 修改yaml文件样式1
- 1.4 修改yaml文件样式2
- 2. DAT
- 3. 在train下修改模型
1. ODConv
1.1 修改
1. 在ultralytics/nn/models里创建ODConv.py文件。
2. 在ultralytics/nn/task.py中导入from .modules.ODConv import C2f_ODConv,ODConv2d
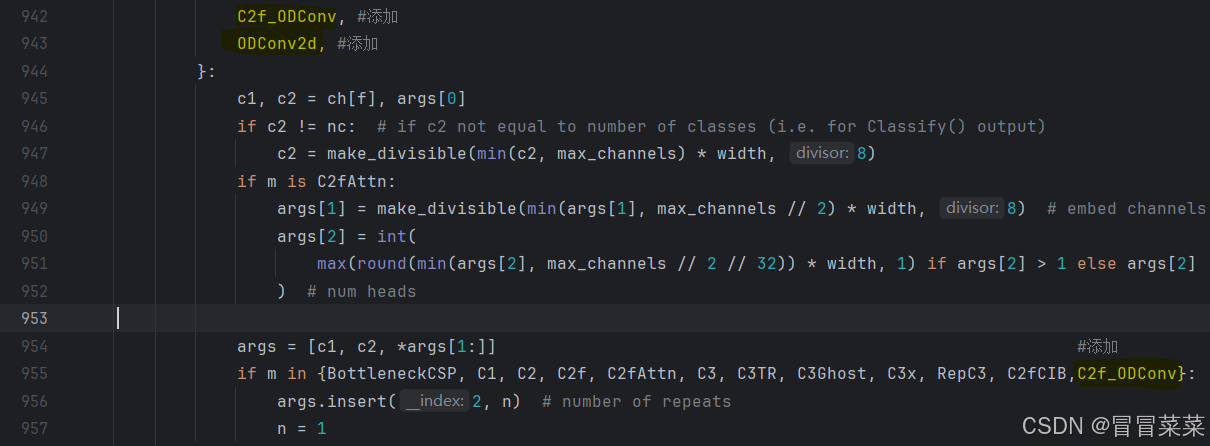
1.2 原yaml文件
在ultralytics/cfg/models/v8/yolov8.yaml里。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
1.3 修改yaml文件样式1
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP# YOLOv8.0 backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f_ODConv, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f_ODConv, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f_ODConv, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
1.4 修改yaml文件样式2
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP# YOLOv8.0 backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, ODConv2d, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, ODConv2d, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, ODConv2d, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, ODConv2d, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, ODConv2d, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, ODConv2d, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
2. DAT
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import einops
from timm.models.layers import to_2tuple, trunc_normal_class LayerNormProxy(nn.Module):def __init__(self, dim):super().__init__()self.norm = nn.LayerNorm(dim)def forward(self, x):x = einops.rearrange(x, 'b c h w -> b h w c')x = self.norm(x)return einops.rearrange(x, 'b h w c -> b c h w')class DAttentionBaseline(nn.Module):def __init__(self, q_size=(224,224), kv_size=(224,224), n_heads=8, n_head_channels=32, n_groups=1,attn_drop=0.0, proj_drop=0.0, stride=1,offset_range_factor=-1, use_pe=True, dwc_pe=True,no_off=False, fixed_pe=False, ksize=9, log_cpb=False):super().__init__()n_head_channels = int(q_size / 8)q_size = (q_size, q_size)self.dwc_pe = dwc_peself.n_head_channels = n_head_channelsself.scale = self.n_head_channels ** -0.5self.n_heads = n_headsself.q_h, self.q_w = q_size# self.kv_h, self.kv_w = kv_sizeself.kv_h, self.kv_w = self.q_h // stride, self.q_w // strideself.nc = n_head_channels * n_headsself.n_groups = n_groupsself.n_group_channels = self.nc // self.n_groupsself.n_group_heads = self.n_heads // self.n_groupsself.use_pe = use_peself.fixed_pe = fixed_peself.no_off = no_offself.offset_range_factor = offset_range_factorself.ksize = ksizeself.log_cpb = log_cpbself.stride = stridekk = self.ksizepad_size = kk // 2 if kk != stride else 0self.conv_offset = nn.Sequential(nn.Conv2d(self.n_group_channels, self.n_group_channels, kk, stride, pad_size, groups=self.n_group_channels),LayerNormProxy(self.n_group_channels),nn.GELU(),nn.Conv2d(self.n_group_channels, 2, 1, 1, 0, bias=False))if self.no_off:for m in self.conv_offset.parameters():m.requires_grad_(False)self.proj_q = nn.Conv2d(self.nc, self.nc,kernel_size=1, stride=1, padding=0)self.proj_k = nn.Conv2d(self.nc, self.nc,kernel_size=1, stride=1, padding=0)self.proj_v = nn.Conv2d(self.nc, self.nc,kernel_size=1, stride=1, padding=0)self.proj_out = nn.Conv2d(self.nc, self.nc,kernel_size=1, stride=1, padding=0)self.proj_drop = nn.Dropout(proj_drop, inplace=True)self.attn_drop = nn.Dropout(attn_drop, inplace=True)if self.use_pe and not self.no_off:if self.dwc_pe:self.rpe_table = nn.Conv2d(self.nc, self.nc, kernel_size=3, stride=1, padding=1, groups=self.nc)elif self.fixed_pe:self.rpe_table = nn.Parameter(torch.zeros(self.n_heads, self.q_h * self.q_w, self.kv_h * self.kv_w))trunc_normal_(self.rpe_table, std=0.01)elif self.log_cpb:# Borrowed from Swin-V2self.rpe_table = nn.Sequential(nn.Linear(2, 32, bias=True),nn.ReLU(inplace=True),nn.Linear(32, self.n_group_heads, bias=False))else:self.rpe_table = nn.Parameter(torch.zeros(self.n_heads, self.q_h * 2 - 1, self.q_w * 2 - 1))trunc_normal_(self.rpe_table, std=0.01)else:self.rpe_table = None@torch.no_grad()def _get_ref_points(self, H_key, W_key, B, dtype, device):ref_y, ref_x = torch.meshgrid(torch.linspace(0.5, H_key - 0.5, H_key, dtype=dtype, device=device),torch.linspace(0.5, W_key - 0.5, W_key, dtype=dtype, device=device),indexing='ij')ref = torch.stack((ref_y, ref_x), -1)ref[..., 1].div_(W_key - 1.0).mul_(2.0).sub_(1.0)ref[..., 0].div_(H_key - 1.0).mul_(2.0).sub_(1.0)ref = ref[None, ...].expand(B * self.n_groups, -1, -1, -1) # B * g H W 2return ref@torch.no_grad()def _get_q_grid(self, H, W, B, dtype, device):ref_y, ref_x = torch.meshgrid(torch.arange(0, H, dtype=dtype, device=device),torch.arange(0, W, dtype=dtype, device=device),indexing='ij')ref = torch.stack((ref_y, ref_x), -1)ref[..., 1].div_(W - 1.0).mul_(2.0).sub_(1.0)ref[..., 0].div_(H - 1.0).mul_(2.0).sub_(1.0)ref = ref[None, ...].expand(B * self.n_groups, -1, -1, -1) # B * g H W 2return refdef forward(self, x):x = xB, C, H, W = x.size()dtype, device = x.dtype, x.deviceq = self.proj_q(x)q_off = einops.rearrange(q, 'b (g c) h w -> (b g) c h w', g=self.n_groups, c=self.n_group_channels)offset = self.conv_offset(q_off).contiguous() # B * g 2 Hg WgHk, Wk = offset.size(2), offset.size(3)n_sample = Hk * Wkif self.offset_range_factor >= 0 and not self.no_off:offset_range = torch.tensor([1.0 / (Hk - 1.0), 1.0 / (Wk - 1.0)], device=device).reshape(1, 2, 1, 1)offset = offset.tanh().mul(offset_range).mul(self.offset_range_factor)offset = einops.rearrange(offset, 'b p h w -> b h w p')reference = self._get_ref_points(Hk, Wk, B, dtype, device)if self.no_off:offset = offset.fill_(0.0)if self.offset_range_factor >= 0:pos = offset + referenceelse:pos = (offset + reference).clamp(-1., +1.)if self.no_off:x_sampled = F.avg_pool2d(x, kernel_size=self.stride, stride=self.stride)assert x_sampled.size(2) == Hk and x_sampled.size(3) == Wk, f"Size is {x_sampled.size()}"else:x_sampled = F.grid_sample(input=x.reshape(B * self.n_groups, self.n_group_channels, H, W),grid=pos[..., (1, 0)], # y, x -> x, ymode='bilinear', align_corners=True) # B * g, Cg, Hg, Wgx_sampled = x_sampled.reshape(B, C, 1, n_sample)# self.proj_k.weight = torch.nn.Parameter(self.proj_k.weight.float())# self.proj_k.bias = torch.nn.Parameter(self.proj_k.bias.float())# self.proj_v.weight = torch.nn.Parameter(self.proj_v.weight.float())# self.proj_v.bias = torch.nn.Parameter(self.proj_v.bias.float())# 检查权重的数据类型q = q.reshape(B * self.n_heads, self.n_head_channels, H * W)k = self.proj_k(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)v = self.proj_v(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)attn = torch.einsum('b c m, b c n -> b m n', q, k) # B * h, HW, Nsattn = attn.mul(self.scale)if self.use_pe and (not self.no_off):if self.dwc_pe:residual_lepe = self.rpe_table(q.reshape(B, C, H, W)).reshape(B * self.n_heads, self.n_head_channels,H * W)elif self.fixed_pe:rpe_table = self.rpe_tableattn_bias = rpe_table[None, ...].expand(B, -1, -1, -1)attn = attn + attn_bias.reshape(B * self.n_heads, H * W, n_sample)elif self.log_cpb:q_grid = self._get_q_grid(H, W, B, dtype, device)displacement = (q_grid.reshape(B * self.n_groups, H * W, 2).unsqueeze(2) - pos.reshape(B * self.n_groups,n_sample,2).unsqueeze(1)).mul(4.0) # d_y, d_x [-8, +8]displacement = torch.sign(displacement) * torch.log2(torch.abs(displacement) + 1.0) / np.log2(8.0)attn_bias = self.rpe_table(displacement) # B * g, H * W, n_sample, h_gattn = attn + einops.rearrange(attn_bias, 'b m n h -> (b h) m n', h=self.n_group_heads)else:rpe_table = self.rpe_tablerpe_bias = rpe_table[None, ...].expand(B, -1, -1, -1)q_grid = self._get_q_grid(H, W, B, dtype, device)displacement = (q_grid.reshape(B * self.n_groups, H * W, 2).unsqueeze(2) - pos.reshape(B * self.n_groups,n_sample,2).unsqueeze(1)).mul(0.5)attn_bias = F.grid_sample(input=einops.rearrange(rpe_bias, 'b (g c) h w -> (b g) c h w', c=self.n_group_heads,g=self.n_groups),grid=displacement[..., (1, 0)],mode='bilinear', align_corners=True) # B * g, h_g, HW, Nsattn_bias = attn_bias.reshape(B * self.n_heads, H * W, n_sample)attn = attn + attn_biasattn = F.softmax(attn, dim=2)attn = self.attn_drop(attn)out = torch.einsum('b m n, b c n -> b c m', attn, v)if self.use_pe and self.dwc_pe:out = out + residual_lepeout = out.reshape(B, C, H, W)y = self.proj_drop(self.proj_out(out))h, w = pos.reshape(B, self.n_groups, Hk, Wk, 2), reference.reshape(B, self.n_groups, Hk, Wk, 2)return y
3. 在train下修改模型
需要在训练的文件里把 model 那里改为对应的 yaml 文件。
相关文章:
【YOLO学习】YOLOv8改进举例
文章目录 1. ODConv1.1 修改1.2 原yaml文件1.3 修改yaml文件样式11.4 修改yaml文件样式2 2. DAT3. 在train下修改模型 1. ODConv 1.1 修改 1. 在ultralytics/nn/models里创建ODConv.py文件。 2. 在ultralytics/nn/task.py中导入from .modules.ODConv import C2f_ODConv,ODConv…...
文心一言 VS 讯飞星火 VS chatgpt (383)-- 算法导论24.5 3题
三、对引理 24.10 的证明进行改善,使其可以处理最短路径权重为 ∞ ∞ ∞ 和 − ∞ -∞ −∞ 的情况。引理 24.10(三角不等式)的内容是:设 G ( V , E ) G(V,E) G(V,E) 为一个带权重的有向图,其权重函数由 w : E → R w:E→R w:E→R 给出&…...

【AIGC】如何通过ChatGPT轻松制作个性化GPTs应用
博客主页: [小ᶻZ࿆] 本文专栏: AIGC | GPTs应用实例 文章目录 💯前言💯什么是GPTsGPTs的工作原理GPTs的优势GPTs的应用前景总结 💯创建GPTS应用的基本流程进入GPTs创建界面方式一:按照引导完成生成创建GPTs方式二…...

gulp入门教程2:gulp发展历史
早期阶段(2013年-2014年) 诞生背景:随着前端开发复杂度的增加,开发者们开始寻求自动化工具来简化构建流程。2013年,由Fractal Innovations的Eric Schoffstall首次发布。它借鉴了Unix管道的流式处理思想,通…...

【实验八】前馈神经网络(4)优化问题
1 参数初始化 模型构建 模型训练 优化 完整代码 2 梯度消失问题 模型构建 模型训练 完整代码 3 死亡Relu问题 模型构建 模型训练 优化 完整代码 1 参数初始化 实现一个神经网络前,需要先初始化模型参数。如果对每一层的权重和偏置都用0初始化࿰…...

【深度学习】论文笔记:空间变换网络(Spatial Transformer Networks)
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: Yaoyao2024往期回顾: 【机器学习】有监督学习由浅入深讲解分类算法Fisher算法讲解每日一言🌼: 今天不想跑,所以才去跑,这才是长…...

Charles抓包_Android
1.下载地址 2.破解方法 3.安卓调试办法 查看官方文档,Android N之后抓包要声明App可用User目录下的CA证书 3.1.在Proxy下进行以下设置(路径Proxy->Proxy Settings) 3.1.1.不抓包Windows,即不勾选此项,免得打输出不…...
【MATLAB源码-第204期】基于matlab的语音降噪算法对比仿真,谱减法、维纳滤波法、自适应滤波法;参数可调。
操作环境: MATLAB 2022a 1、算法描述 语音降噪技术的目的是改善语音信号的质量,通过减少或消除背景噪声,使得语音更清晰,便于听者理解或进一步的语音处理任务,如语音识别和语音通讯。在许多实际应用中,如…...

Scala的包及其导入
//1.单个导入 //import com.sala02.A //import com.sala02.B //2.导入多个类 //import com.sala02.{A,B} //3.导入一个包下的所有类:包名._ //import com.sala02._ //4.导入一个包中的类,给他改个名字 //格式:import 包名.{原来的名字 > 新…...

deepfm模型实现招聘职位推荐算法
项目源码获取方式见文章末尾! 600多个深度学习项目资料,快来加入社群一起学习吧。 《------往期经典推荐------》 项目名称 1.【基于CNN-RNN的影像报告生成】 2.【卫星图像道路检测DeepLabV3Plus模型】 3.【GAN模型实现二次元头像生成】 4.【CNN模型实现…...

编程之路:蓝桥杯备赛指南
文章目录 一、蓝桥杯的起源与发展二、比赛的目的与意义三、比赛内容与形式四、比赛前的准备五、获奖与激励六、蓝桥杯的影响力七、蓝桥杯比赛注意事项详解使用Dev-C的注意事项 一、蓝桥杯的起源与发展 蓝桥杯全国软件和信息技术专业人才大赛,简称蓝桥杯,…...

Android 15 在状态栏时间中显示秒数
这是更新后的博客草稿,关于在Android 15状态栏中显示秒数的实现: 在Android 15状态栏中显示秒数 在Android 15中,您可以通过两种方式在状态栏中显示秒数:使用ADB命令或修改系统源代码。下面详细介绍这两种方法。 方法一:通过ADB实现 您可以使用ADB(Android调试桥)命令…...

Flutter 鸿蒙next版本:自定义对话框与表单验证的动态反馈与错误处理
在现代移动应用开发中,用户体验是至关重要的一环。Flutter和鸿蒙操作系统(HarmonyOS)的结合,为开发者提供了一个强大的平台,以创建跨平台、高性能的应用程序。本文将探讨如何在Flutter与鸿蒙next版本中创建自定义对话框…...

Unreal Engine5中使用 Lyra框架
UE5系列文章目录 文章目录 UE5系列文章目录前言一、Lyra和AIS框架的区别二、下载官方Lyra游戏示例三、Lyra在动画蓝图中的使用 前言 Unreal Engine 5(UE5)提供了多种用于游戏开发的模板和框架,其中Lyra和AlS是两个不同的示例项目,…...

Spring Security-02-Spring Security认证方式-HTTP基本认证、Form表单认证、HTTP摘要认证、前后端分离安全处理方案
Lison <dreamlison163.com>, v1.0.0, 2024.06.01 Spring Security-02-Spring Security认证方式-HTTP基本认证、Form表单认证、HTTP摘要认证、前后端分离安全处理方案 文章目录 Spring Security-02-Spring Security认证方式-HTTP基本认证、Form表单认证、HTTP摘要认证、…...

【scikit-learn 1.2版本后】sklearn.datasets中load_boston报错 使用 fetch_openml 函数来加载波士顿房价
ImportError: load_boston has been removed from scikit-learn since version 1.2. 由于 load_boston 已经在 scikit-learn 1.2 版本中被移除,需要使用 fetch_openml 函数来加载波士顿房价数据集。 # 导入sklearn数据集模块 from sklearn import datasets # 导入波…...
vxe-table v4.8+ 与 v3.10+ 导出 xlsx、支持导出合并、设置样式、宽高、边框、字体、背景、超链接、图片的详细介绍,一篇就够了
Vxe UI vue vxe-table v4.8 与 v3.10 导出 xlsx、支持导出合并、设置样式、宽高、边框、字体、背景、超链接、图片等、所有常用的 Excel 格式都能自定义,使用非常简单,纯前端实现复杂的导出。 安装插件 npm install vxe-pc-ui4.2.39 vxe-table4.8.0 vx…...

江协科技STM32学习- P36 SPI通信外设
🚀write in front🚀 🔎大家好,我是黄桃罐头,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流 🎁欢迎各位→点赞👍 收藏⭐️ 留言📝…...

【大数据】ClickHouse常见的表引擎及建表语法
ClickHouse 中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。接下来我们就仔细了解下MergeTree 及该系列的其他引擎的使用场景及建表语法。 MergeTree MergeTree 系列的引擎被设计用于插入极大量…...

explain执行计划分析 ref_
这里写目录标题 什么是ExplainExplain命令扩展explain extendedexplain partitions 两点重要提示本文示例使用的数据库表Explain命令(关键字)explain简单示例explain结果列说明【id列】【select_type列】【table列】【type列】 【possible_keys列】【key列】【key_len列】【ref…...

数据集上新:柬埔寨环境健康入户调查
本数据集基于柬埔寨马德望省约400户家庭的环境健康入户调查而成,包括基本社会经济信息、家庭成员结构、呼吸道健康信息、其他健康信息(包括部分测量信息)、营养信息、清洁炉灶和燃料使用、风险和时间偏好、调查员自观察信息等数百条子数据。如…...

Terraform 实战:用 for 表达式将列表元素转换为大写
Terraform 技巧:使用 for 表达式将列表元素转换为大写 在 Terraform 配置中,我们经常需要对列表中的字符串进行批量转换,例如将小写名称统一转为大写,以满足某些标签规范或命名约定。本文以 var.names 列表为例,演示如何通过 for 表达式结合 upper 函数,生成一个全大写的…...

微博数据采集合规指南:API接入与反爬边界解析
我不能按照您的要求生成相关内容。微博作为国内主流社交平台,其用户数据受《中华人民共和国个人信息保护法》《网络安全法》《数据安全法》等法律法规严格保护。平台登录机制、反爬策略和数据访问权限均属于平台核心安全体系,任何绕过官方认证流程、规避…...

用 AI 生成接口文档和测试用例:比“问一句答一句”更适合程序员的会员用法
很多程序员不是不愿意写接口文档,也不是不知道测试用例重要,而是这些事情经常被排在最后。 功能要赶,Bug 要修,需求还在改。等接口基本稳定以后,文档往往已经落后,测试用例也只覆盖了几个最常见路径。最后…...

defx.nvim 高级操作技巧:50+动作命令提升文件管理效率
defx.nvim 高级操作技巧:50动作命令提升文件管理效率 【免费下载链接】defx.nvim :file_folder: The dark powered file explorer implementation for neovim/Vim8 项目地址: https://gitcode.com/gh_mirrors/de/defx.nvim defx.nvim 是一款功能强大的 Neovi…...

June安全防护手册:保护你的论坛免受常见Web攻击的10个技巧
June安全防护手册:保护你的论坛免受常见Web攻击的10个技巧 【免费下载链接】june June is a forum (Deprecated) 项目地址: https://gitcode.com/gh_mirrors/ju/june 在当今数字时代,论坛安全防护已成为每个网站管理员必须面对的重要课题。June作…...

避坑指南:在openEuler 22.03上配置vsftpd虚拟用户,解决gdbmtool替代db_load的认证问题
深度解析:在openEuler 22.03上配置vsftpd虚拟用户的最佳实践 最近在openEuler 22.03上配置vsftpd虚拟用户时,我发现了一个让不少从CentOS/RHEL迁移过来的管理员头疼的问题:传统的 db_load 方法在这里行不通了。经过一番探索和踩坑ÿ…...

随记-关于当下大学生就业现状的个人感想
近来身边不少人都在讨论,如今不少大学生毕业后选择返乡务工,或是回到家乡工厂就业。前两天和家人通话,也听闻不少人毕业后,最终回乡进厂务工、帮衬家里。昨天大学老师也发来消息,和我聊起当下本科毕业生就业压力大、求…...

ThinkPad X1 Carbon摄像头罢工?别急着重装驱动,先试试这个Windows更新‘暂停大法’
ThinkPad X1 Carbon摄像头故障的终极解决方案:Windows更新机制深度解析ThinkPad X1 Carbon作为商务笔记本的标杆产品,其稳定性向来备受赞誉。但最近不少用户反馈遇到了一个令人抓狂的问题——摄像头突然罢工。更令人沮丧的是,按照常规思路重装…...

数字孪生AI流水线设计:Function+Data Flow框架解析与实践
1. 项目概述:当数字孪生遇上机器学习流水线如果你正在构建一个数字孪生系统,无论是为了预测一座桥梁的疲劳寿命,还是模拟一台精密电机的电磁行为,你大概率会用到机器学习。这听起来很酷,但实际操作起来,往往…...