NumPy 数据类型
1.常用 NumPy 基本类型
(1)bool_:布尔型数据类型(True 或者 False)
(2)int_:默认的整数类型(类似C 语言long,int32 或 int64)
(3)intc:与 C 语言的 int 类型相似,一般是 int32 或 int 64
(4)intp:用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64)
(5)int8:字节(-128 to 127)
(6)int16:整数(-32768 to 32767)
(7)int32:整数(-2147483648 to 2147483647)
(8)int64:整数(-9223372036854775808 to 9223372036854775807)
(9)uint8:无符号整数(0 to 255)
(10)uint16:无符号整数(0 to 65535)
(11)uint32:无符号整数(0 to 4294967295)
(12)uint64:无符号整数(0 to 18446744073709551615)
(13)float_:float64 类型的简写
(14)float16:半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位
(15)float32 :单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位
(16)float64:双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位
(17)complex_:complex128 类型,即 128 位复数
(18)complex64:复数,双 32 位浮点数(实数部分和虚数部分)
(19)complex128:复数,双 64 位浮点数(实数部分和虚数部分)
(20)numpy 的数值类型实际上是 dtype 对象的实例,并对应唯一的字符,包括 np.bool_,np.int32,np.float32,等等。
2数据类型对象 (dtype) 描述与数组对应的内存区域使用
字节顺序通过对数据类型预先设定 < 或 > 决定。 < 小端法(最小值存储在最小的地址,低位组放在最前面)。> 大端法(最重要的字节存储在最小的地址,高位组放在最前面)。
(1)数据的类型(整数,浮点数或者 Python 对象)
(2)数据的大小(例如, 整数使用多少个字节存储)
(3)数据的字节顺序(小端法或大端法)
(4)在结构化类型的情况下,字段的名称、每个字段的数据类型和每个字段所取的内存块的部分
(5)如果数据类型是子数组,那么它的形状和数据类型是什么。
numpy.dtype(object, align, copy)
(1)object:要转换为的数据类型对象
(2)align:如果为 true,填充字段使其类似 C 的结构体。
(3)copy:复制 dtype 对象 ,如果为 false,则是对内置数据类型对象的引用
3.定义并查看 int32 类型的描述信息
import numpy as np
# 使用标量类型
dt = np.dtype(np.int32)
print(dt)
(1)导入 numpy 库:import numpy as np 将 numpy 库导入并简写为 np,方便后续使用。
(2)定义数据类型:np.dtype(np.int32) 创建了数据类型对象 dt,表示 32 位整型。np.int32 是 numpy 定义的 32 位整数类型,可以存储从 -2,147,483,648 到 2,147,483,647 之间的整数。
(3)输出数据类型:print(dt) 会输出 int32,显示定义的数据类型。
4.用缩写符号 'i4' 表示 int32 数据类型,并输出描述信息
import numpy as np
# int8, int16, int32, int64 四种数据类型可以使用字符串 'i1', 'i2','i4','i8' 代替
dt = np.dtype('i4')
print(dt)
(1)导入 numpy 库:import numpy as np 导入 numpy 库并简写为 np,便于后续代码调用。
(2)使用缩写表示数据类型:np.dtype('i4') 创建了数据类型对象 dt,表示 32 位整数类型(int32), 'i4' 是 int32 的缩写形式。'i1' 表示 int8 类型,8 位整数。'i2' 表示 int16 类型,16 位整数。'i4' 表示 int32 类型,32 位整数。'i8' 表示 int64 类型,64 位整数。
(3)输出数据类型:print(dt) 会输出 int32,显示定义的数据类型。
5.定义小端字节序的 int32 数据类型并输出描述信息
import numpy as np
# 字节顺序标注
dt = np.dtype('<i4')
print(dt)
(1)导入 numpy 库:import numpy as np 导入 numpy 并重命名为 np,便于后续调用。
(2)使用字节顺序和数据类型缩写:np.dtype('<i4') 创建数据类型对象 dt,表示小端字节序的 32 位整数(int32)。'<i4' 中的符号解释:< 表示小端字节序(little-endian),即低字节位存储在低地址处。i4 表示 int32 类型,即 4 字节的整数。在字节顺序标注中,'<' 表示小端字节序,'>' 表示大端字节序(big-endian)。
(3)输出数据类型:print(dt) 会输出 int32,显示该数据类型。
6.创建包含单个字段的结构化数据类型
# 首先创建结构化数据类型
import numpy as np
dt = np.dtype([('age',np.int8)])
print(dt)
(1)导入 numpy 库:import numpy as np 导入 numpy 并重命名为 np。
(2)定义结构化数据类型:np.dtype([('age', np.int8)]) 定义了一个结构化数据类型 dt,其中包含一个字段。[('age', np.int8)] 是一个包含字段定义的列表,每个字段由名称和数据类型组成。'age' 是字段的名称。np.int8 是字段的数据类型,表示 8 位的整数(范围是 -128 到 127)。这使得 dt 成为一种结构,可以用于存储包含 age 字段的数据。
(3)输出数据类型:print(dt) 输出 dt 的描述信息,显示结构化数据类型的定义。
7.通过 dtype 参数将结构化数据类型 dt 应用于 ndarray 对象
# 将数据类型应用于 ndarray 对象
import numpy as np
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print(a)
(1)导入 numpy 库:import numpy as np 导入 numpy 并重命名为 np。
(2)定义结构化数据类型:dt = np.dtype([('age', np.int8)]) 创建结构化数据类型 dt,包含一个字段 'age',类型为 int8。
(3)创建结构化数组:np.array([(10,), (20,), (30,)], dtype=dt) 使用定义的数据类型 dt 创建一个 ndarray 数组 a。数组 a 的每个元素都是一个包含单一字段的元组,其中 'age' 字段的值分别是 10, 20 和 30。dtype=dt 指定数组的每个元素应当符合 dt 定义的结构,即每个元素包含一个 int8 类型的 age 字段。
(4)输出数组:print(a) 打印数组内容,输出结果将显示 [(10,) (20,) (30,)],其中每个元素的值对应 age 字段。
8.通过字段名称来访问结构化数组中的具体列
# 类型字段名可以用于存取实际的 age 列
import numpy as np
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print(a['age'])
(1)导入 numpy 库:import numpy as np 导入 numpy 并简写为 np。
(2)定义结构化数据类型:dt = np.dtype([('age', np.int8)]) 定义了结构化数据类型 dt,包含一个字段 'age',数据类型为 int8。
(3)创建结构化数组:a = np.array([(10,), (20,), (30,)], dtype=dt) 用定义的结构化数据类型 dt 创建一个 ndarray 数组 a,每个元素包含一个 age 字段。每个元组对应一个元素,10、20 和 30 分别为 age 字段的值。
(4)通过字段名访问数据:a['age'] 使用字段名 'age' 来获取数组 a 中所有元素的 age 数据。这个操作返回一个数组,包含了 age 字段的所有值 [10, 20, 30]。
(5)输出结果:print(a['age']) 输出 [10 20 30],age 字段的所有值。
9.创建适用于学生数据的结构化数据类型 student
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
print(student)
(1)导入 numpy 库:import numpy as np 导入 numpy 并重命名为 np。
(2)定义结构化数据类型:student = np.dtype([('name', 'S20'), ('age', 'i1'), ('marks', 'f4')]) 定义了一个结构化数据类型 student,包含三个字段:'name':数据类型为 'S20',表示一个长度为 20 的字符串。S 表示字节字符串类型,20 是最大字符长度。'age':数据类型为 'i1',表示一个 8 位的整数(即 int8),范围是 -128 到 127。'marks':数据类型为 'f4',表示一个 32 位的浮点数(即 float32)。这个结构化数据类型适合表示学生的 name(名字),age(年龄),和 marks(分数)。
(3)输出结构化数据类型描述:print(student) 打印 student 类型的描述信息。输出显示:[('name', 'S20'), ('age', 'i1'), ('marks', 'f4')],每个字段及其对应的数据类型。
10.创建包含多个学生信息的结构化数组 a
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
print(a)
(1)导入 numpy 库:import numpy as np 导入 numpy 并简写为 np。
(2)定义结构化数据类型:student = np.dtype([('name', 'S20'), ('age', 'i1'), ('marks', 'f4')]) 定义了名为 student 的结构化数据类型。'name' 字段为 S20,长度为 20 的字节字符串,用于存储学生名字。'age' 字段为 i1,8 位整数(即 int8),用于存储学生年龄。'marks' 字段为 f4,表示 32 位浮点数(即 float32),用于存储学生分数。
(3)创建结构化数组:a = np.array([('abc', 21, 50), ('xyz', 18, 75)], dtype=student) 创建了一个数组 a,包含两个学生的记录:第一条记录:('abc', 21, 50),其中 'abc' 是学生的名字,21 是年龄,50 是分数。第二条记录:('xyz', 18, 75),其中 'xyz' 是学生的名字,18 是年龄,75 是分数。dtype=student 指定了数组 a 的数据类型为之前定义的结构化数据类型 student。
(4)输出数组:print(a) 打印数组 a 的内容,结果为[(b'abc', 21, 50.) (b'xyz', 18, 75.)]输出显示了每个学生的详细信息,其中 b'abc' 和 b'xyz' 表示字节字符串格式的名字,21 和 18 是年龄,50. 和 75. 是分数(浮点数格式)。
11.常用数据类型代码(字符)及对应实际数据类型
(1)b:布尔型,表示布尔值 (True/False)
(2)i :(有符号) 整型,表示有符号整数,允许负数,例如 -128 到 127(具体范围根据字节数不同而不同)
(3)u:无符号整型,表示无符号整数,只允许正数,例如 0 到 255(具体范围根据字节数不同而不同)
(4)f :浮点型:表示浮点数,即带小数的数值,例如 3.14
(5)c :复数浮点型,表示复数,由两个浮点数表示实部和虚部,如 3 + 2j
(6)m:timedelta,表示时间间隔,用于日期和时间的差值
(7)M:datetime,表示日期时间类型,用于存储具体的日期和时间
(8)O:对象,表示 Python 对象,一般用于存储任意 Python 对象
(9)S, a:(byte-)字符串,表示字节字符串,例如 b'hello'。S 和 a 的后面可以指定长度,例如 S10 表示长度为 10 的字节字符串
(10)U:Unicode,表示 Unicode 字符串,可用于存储多语言字符
(11)V:原始数据类型 (void) ,表示原始数据,用于定义结构化数据类型或指定占位空间
相关文章:
NumPy 数据类型
1.常用 NumPy 基本类型 (1)bool_:布尔型数据类型(True 或者 False) (2)int_:默认的整数类型(类似C 语言long,int32 或 int64) (3&a…...

JavaScript——(4)
【DOM】 一、DOM基本概念 DOM(Document Object Model,文档对象模型)是 JavaScript 操作 HTML 文档的接口,使文档操作变得非常优雅、简便。 DOM 最大的特点就是将 HTML 文档表示为 “节点树”。 DOM 元素/节点:就是…...
)
每日一练 | DHCP Relay(DHCP 中继)
01 真题题目 DHCP Relay 又称为 DHCP 中继,下列关于 DHCP Relay 的说法正确的是(多选): A. DHCP 协议多采用广播报文,如果出现多个子网则无法穿越,所以需要 DHCP Relay 设备。 B. DHCP Relay 一定是一台交…...

`psdparse`:解锁Photoshop PSD文件的Python密钥
文章目录 psdparse:解锁Photoshop PSD文件的Python密钥背景:为何选择psdparse?psdparse是什么?如何安装psdparse?简单函数使用方法应用场景常见Bug及解决方案总结 psdparse:解锁Photoshop PSD文件的Python密…...
)
考研要求掌握的C语言程度(插入排序)
插入排序是啥类型的排序 插入类型的 插入排序经常用在啥类型场景下 用在有序序列下的基础上插入新数据 时间复杂度分析 如果是有序的基础下,最好的时间复杂度是O(n); 普通情况下是O(n^2) 插入排序的原理是啥&am…...

mybatis源码解析-sql执行流程
1 执行器的创建 1. SimpleExecutor 描述:最基本的执行器,每次查询都会创建新的语句对象,并且不会缓存任何结果。 特点: 每次查询都会创建新的 PreparedStatement 对象。 不支持一级缓存。 适用于简单的查询操作,不…...
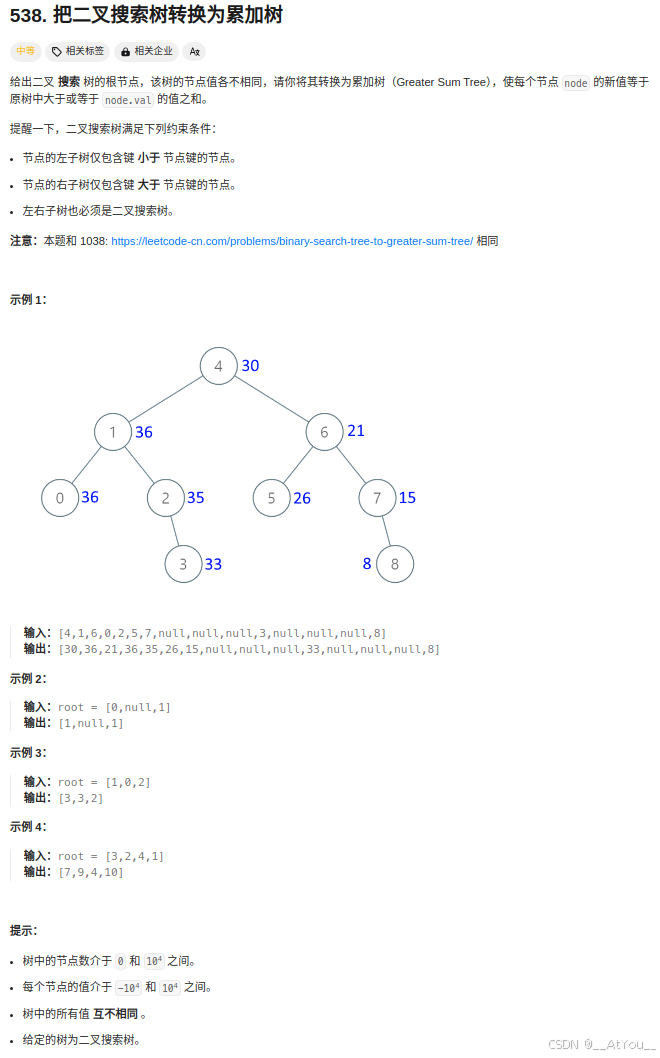
Golang | Leetcode Golang题解之第538题把二叉搜索树转换为累加树
题目: 题解: func getSuccessor(node *TreeNode) *TreeNode {succ : node.Rightfor succ.Left ! nil && succ.Left ! node {succ succ.Left}return succ }func convertBST(root *TreeNode) *TreeNode {sum : 0node : rootfor node ! nil {if n…...

【linux】HTTPS 协议原理
1. 了解 HTTPS 协议原理 (一)认识 HTTPS HTTPS 也是一种应用层协议,是在 HTTP 协议的基础上引入了一个加密层 因为 HTTP协议的内容都是按照文本的方式进行传输的,这个过程中,可能会出现一些篡改的情况 (…...
安利一款开源企业级的报表系统SpringReport
SpringReport是一款企业级的报表系统,支持在线设计报表,并绑定动态数据源,无需写代码即可快速生成想要的报表,可以支持excel报表和word报表两种格式,同时还可以支持excel多人协同编辑,后续考虑实现大屏设计…...

数据安全-接口数据混合加密笔记
接口数据传输安全设计方案 采用非对称加密对称加密混合方式,接口混合加、解密过程梳理: 后端准备sm2公钥和私钥后端将SM2公钥传输到前端前端生成SM4密钥前端使用SM2公钥加密SM4秘钥,获得密文使用SM4秘钥加密数据将密文和加密数据传输至后端…...
JeecgBoot入门
最近在了解低代码平台,其中关注到gitee上开源项目JeecgBoot,JeecgBoot官方也有比较完整的入门教学文档,这里我们将耕者官方教程学习,并将其记录下来。 一、项目简介 JeecgBoot 是一款基于代码生成器的低代码开发平台拥有零代码能力…...

用 Vue.js 打造炫酷的动态数字画廊:展示学生作品的创意之旅
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
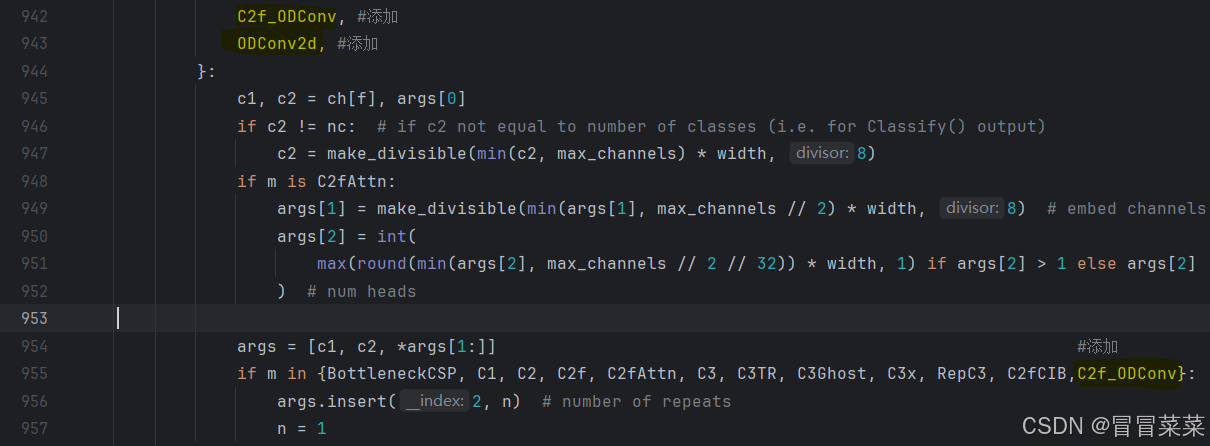
【YOLO学习】YOLOv8改进举例
文章目录 1. ODConv1.1 修改1.2 原yaml文件1.3 修改yaml文件样式11.4 修改yaml文件样式2 2. DAT3. 在train下修改模型 1. ODConv 1.1 修改 1. 在ultralytics/nn/models里创建ODConv.py文件。 2. 在ultralytics/nn/task.py中导入from .modules.ODConv import C2f_ODConv,ODConv…...
文心一言 VS 讯飞星火 VS chatgpt (383)-- 算法导论24.5 3题
三、对引理 24.10 的证明进行改善,使其可以处理最短路径权重为 ∞ ∞ ∞ 和 − ∞ -∞ −∞ 的情况。引理 24.10(三角不等式)的内容是:设 G ( V , E ) G(V,E) G(V,E) 为一个带权重的有向图,其权重函数由 w : E → R w:E→R w:E→R 给出&…...

【AIGC】如何通过ChatGPT轻松制作个性化GPTs应用
博客主页: [小ᶻZ࿆] 本文专栏: AIGC | GPTs应用实例 文章目录 💯前言💯什么是GPTsGPTs的工作原理GPTs的优势GPTs的应用前景总结 💯创建GPTS应用的基本流程进入GPTs创建界面方式一:按照引导完成生成创建GPTs方式二…...

gulp入门教程2:gulp发展历史
早期阶段(2013年-2014年) 诞生背景:随着前端开发复杂度的增加,开发者们开始寻求自动化工具来简化构建流程。2013年,由Fractal Innovations的Eric Schoffstall首次发布。它借鉴了Unix管道的流式处理思想,通…...

【实验八】前馈神经网络(4)优化问题
1 参数初始化 模型构建 模型训练 优化 完整代码 2 梯度消失问题 模型构建 模型训练 完整代码 3 死亡Relu问题 模型构建 模型训练 优化 完整代码 1 参数初始化 实现一个神经网络前,需要先初始化模型参数。如果对每一层的权重和偏置都用0初始化࿰…...

【深度学习】论文笔记:空间变换网络(Spatial Transformer Networks)
博主简介:努力学习的22级计算机科学与技术本科生一枚🌸博主主页: Yaoyao2024往期回顾: 【机器学习】有监督学习由浅入深讲解分类算法Fisher算法讲解每日一言🌼: 今天不想跑,所以才去跑,这才是长…...

Charles抓包_Android
1.下载地址 2.破解方法 3.安卓调试办法 查看官方文档,Android N之后抓包要声明App可用User目录下的CA证书 3.1.在Proxy下进行以下设置(路径Proxy->Proxy Settings) 3.1.1.不抓包Windows,即不勾选此项,免得打输出不…...
【MATLAB源码-第204期】基于matlab的语音降噪算法对比仿真,谱减法、维纳滤波法、自适应滤波法;参数可调。
操作环境: MATLAB 2022a 1、算法描述 语音降噪技术的目的是改善语音信号的质量,通过减少或消除背景噪声,使得语音更清晰,便于听者理解或进一步的语音处理任务,如语音识别和语音通讯。在许多实际应用中,如…...

NS-USBLoader完整教程:Switch文件传输与RCM注入一站式解决方案
NS-USBLoader完整教程:Switch文件传输与RCM注入一站式解决方案 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: https://gitcode.com/…...

从备份到部署:用Clonezilla为网吧/机房批量克隆系统镜像的实战流程
从备份到部署:用Clonezilla为网吧/机房批量克隆系统镜像的实战流程在网吧、学校机房或企业IT部门中,面对数十台甚至上百台配置相同的计算机,如何高效完成系统部署和环境统一?传统逐台安装的方式不仅耗时费力,还难以保证…...

图机器学习在农药生态毒性预测中的应用与挑战
1. 项目概述:当图机器学习遇见农药设计农药,这个听起来有些“硬核”的词汇,其实是我们现代农业的基石。从除草剂到杀虫剂,它们守护着全球的粮食安全。但硬币的另一面是,农药的生态毒性问题日益凸显,尤其是对…...

Unity新手第一课:从创建立方体理解场景驱动开发
1. 这不是“Hello World”,而是你和Unity第一次真正握手很多人点开Unity,新建一个空项目,盯着灰蒙蒙的Scene视图发呆——光标悬停在空白画布上,不知道该点哪里,更不知道点下去会发生什么。我带过几十个零基础学员&…...

WABT实战指南:用wasm-decompile精准逆向WebAssembly
1. 为什么你打开一个.wasm文件看到的全是乱码,而别人却能读出函数名和逻辑? WABT(WebAssembly Binary Toolkit)不是个“点开即用”的图形化工具,它是一套命令行驱动的底层解析引擎——这恰恰是它在逆向分析场景中不可…...

Unity序列化三要素:Serializable、SerializeField与SerializeReference详解
1. 为什么Unity序列化总让人困惑——从一个真实报错说起 刚接手一个老项目时,我遇到个特别典型的场景:美术同事在Inspector里调好了角色的装备配置,保存后切到另一台机器打开,所有装备栏全空了。Debug发现, List<E…...

UE5 Vulkan PC平台适配核心:DataDrivenPlatformInfo.ini详解
1. 这不是配置文件,是UE5 Vulkan平台适配的“宪法性文档”你打开UE5项目目录下的Engine/Config/Platform/路径,一眼扫过去,DataDrivenPlatformInfo.ini这个文件名平平无奇——它不像DefaultEngine.ini那样天天被修改,也不像BaseEn…...

别再死记硬背F=G+H了!用Unity手搓一个A*寻路,从DFS、BFS到Dijkstra一步步讲透
从零构建A*寻路:用Unity可视化算法演进之路当我在开发第一个2D策略游戏时,遇到了一个经典问题:如何让单位智能地绕过障碍物找到最短路径?像许多初学者一样,我直接跳到了A*算法的实现,却被那个神秘的FGH公式…...

2026免费在线去水印保姆级教程!不用下载,3秒去除,一看就会
你是不是也遇到过这种抓狂时刻?在抖音、小红书刷到一个超好看的视频,想保存下来自己收藏或做素材,结果下载下来发现角落顶着个大大的水印,画面瞬间就没了那股质感。更气的是,找了一堆号称“免费去水印”的软件…...

Web渗透信息收集实战:从被动侦察到精准测绘
1. 这不是“黑客速成班”,而是Web渗透工程师的日常切片很多人点开“精通 Kali Linux Web 渗透测试”这个标题,第一反应是:又要教怎么黑进某个网站了?其实恰恰相反——我带过的二十多个渗透测试新人里,前两周最常犯的错…...