SQL语言基础
SQL(Struct Query Language)是结构化查询语言的简称,是一种在关系型数据库中定义和操纵数据的标准语言。
不要使用面向对象的思想学习SQL,因为它不是面向对象的语言
目标
- SQL语言简介(了解)
- 从数据库数据检索数据(重点)
- 子查询(重点)
- Oracle常用函数(掌握)
1 SQL语言简介
1.1 SQL的特点
SQL语句通常用于完成一些数据库的操作任务,例如增加、修改、删除、查询数据以及对数据库对象(表、视图、索引、过程、函数、触发器等等)的一些列操作。巧妙运用SQL语句能够简化编程起到事半功倍效果。
程序员或者数据库管理员使用SQL语句能够完成下面的操作:
创建用户、创建表空间、创建表
- create user
- create tablespace
- create table
删除用户、删除表空间、删除表
- drop user
- drop tablespace
- drop table
改变数据库系统环境设置
- set pagesize
- set linesize
- set newpage
用户授权
- grant
为数据库的表建立索引
- create index
修改数据库表结构
- 通过alter table 关键字新建、删除、修改表个字段
对数据库中的数据进行添加、修改、删除、查询
- 通过insert into、update、delete from、select....from语句对数据库表中的数据进行增删改查
SQL语言主要的特点如下:
1. 集合性
SQL语句执行返回一个结果集。例如:使用select查询一个结果集、使用delete from语句删除表中的多条数
据、使用update语句批量修改多条数据
2. 统一性
SQL语句为许多任务提供了统一的命令
查询数据使用select from关键字
在表中插入、修改、删除数据使用insert into、update、delete from关键字
创建、删除、修改数据对象
- 创建数据对象使用create关键字
- 修改数据对象使用alter关键字
- 删除数据对象使用drop关键字
控制对数据和数据对象的读写
- commit关键字提交数据
- rollback关键字回滚数据
保证数据的完整性和一致性,每一种约束都有自己统一的关键字
- 主键约束使用primary key关键字
- 外键约束使用foreign key关键字
- 唯一约束使用unique关键字
- 检查约束使用check关键字
- 非空约束使用not null关键字
- 默认约束使用default关键字
3. 非过程化
SQL语句是一个非过程化语言,因为它没有分支、循环结构
4. 简单
SQL只有几个命令动词就可以实现对数据库以及数据的查询和管理。下面的表讲解了SQL语言的分类,以及对应的关键字(命令动词)
| SQL的分类 | 关键字(命令动词) | 职责 |
| 数据定义语 言(DDL) | create、drop、alter | 创建、删除、修改数据对象 |
| 数据查询语 言(DQL) | select、into、from、where、group by、having、order by | 从数据库表中检索(查询)数据。特征:读 |
| 数据操纵语 言(DML) | delete、update、insert | 改变数据库表中的数据。特征:写 |
| 数据控制语 言(DCL) | grant、revoke | 用于执行权限授予和权限回收操作 |
| 事务控制语 言(TCL): | commit、rollback | 用于执行权限授予和权限回收操作 |
1.2 SQL的编写规则
- SQL关键字不区分大小写、既可以使用大写格式、又可以使用小写格式、或者大小写混用。
- 对象名(表名称)、列名称不区分大小写
- 字符值区分大小写
如果SQL语句很长,可以将其分行显示,提高阅读性
select empno 员工编号, ename 员工姓名, job 职位
from emp
where empno = 7369
小结:本单元主要对SQL语言做了一个宏观上的总体介绍,后面还会针对每个关键字进行详细讲解
2 用户模式
在Oracle数据库中,为了方便管理创建的数据库对象(表、视图、索引等等),引入了模式的概念,某个用户创建的数据库对象都属于该用户模式。例如在 scott 模式下创建了 student 表,那该表就属于scott模式。
Student表此时就是一个数据对象,它在scott用户下面创建的,只能属于scott用户
模式也叫作用户 模式 等价于 用户
Oracle数据库里面的数据库对象(表、视图、索引等等)都是跟着用户(模式)走的。创建用户(模式)的目的:为了更好的管理数据对象(表、视图、索引等等)
2.1 模式与数据库对象关系
模式是数据库对象的集合,一个模式对应多个数据库对象。例如:sys模式、scott模式等等。在一个模式(sys)内部不可以直接访问其他模式(scott)的数据库对象,即使在具有访问权限的情况下,也需要指定模式名称才可以访问其
它模式的数据库对象。
例如:使用sys模式登录,在sys模式(用户)下访问scott模式(用户)的emp表
select * from scott.emp;
scott.emp表示scott模式(用户)下的emp表
小结:
- 模式(用户)用来管理数据库对象的,一个模式(用户)下面可以有多个数据对象
- 某个数据对象(emp表)只能属于一个模式(用户)
- 必须指定模式名称才可以访问其它模式的数据库对象 scott.emp
2.2 scott模式(用户)
scott模式(用户)是Oracle数据库经典的模式(用户),该模式演示了一个很简单的人力资源管理的数据结构。我们通常使用它进行学习。在Oracle19c中并没有scott用户需要我们手动创建并激活

dept部门表
| 属性英文名 | 属性中文名 |
| deptno | 部门编号 |
| dname | 部门名称 |
| loc | 部门所在位置 |
emp雇员表
| 属性英文名 | 属性中文名 |
| empno | 雇员编号 |
| ename | 雇员姓名 |
| jop | 雇员职位 |
| mgr | 雇员对应领导编号 |
| hiredate | 雇员的雇佣日期 |
| sal | 雇员的基本工资 |
| comm | 奖金或补助 |
| deptno | 所在部门 |
salgrade工资等级
| 属性英文名 | 属性中文名 |
| ename | 雇员名字 |
| jop | 雇员职位 |
| sal | 雇员工资 |
| comm | 雇员奖金 |
小结:
1. 模式(用户)拥有数据库对象(表、视图、索引等等),数据对象被模式(用户)拥有。
一个模式(用户)下面有多个数据对象
一个数据库对象只属于一个模式(用户)
2. 在工作中我们通常说数据库对象(表、视图、索引等等)是跟着用户走的。
3 数据检索(查询)
用户对表或视图用的最多的操作就是检索(查询)数据。检索数据可以通过select语句来实现,该语句由多个子句组成,通过这些子句对数据库表进行各种操作,最终得到用户想要的查询结果。select基本语法格式如下:

在数据检索(查询)语句中SELECT和FROM子句必须有,其它关键字可选
[] 表示可选
|表示或者
3.1 简单的查询
只包含select和from子句的查询就是简单查询
- 连接scott用户,查询员工表所有的列

小结:
1. 上面的查询语句表示:从emp表中检索数据,然后选择表中所有的列
2. 先执行from关键字确定要查询哪张表,然后执行select选择表中的列
- 查询指定的列
指定查询表中某些列名称,这些列名称跟在select关键字后面,每个列名称之间使用逗号分隔。法如下
![]()
例如:查询员工表的:员工编号、员工姓名、基本工资、职位

- 为列指定别名
列别名就是指列的小名,使用列别名可以提高查询语句的可读性

- select语句中的算术运算符 + - * /
算数运算符大多数情况下用在select后面的列中,对列值进行算数运算
通常只对数值类型的列进行算数运算

- select语句中的比较运算符
- 比较运算符通常对where或者having关键字后面的条件进行判断,如果条件成立就提取数据,否则就过滤
数据。Oracle的比较运算符:= , >, >=,< ,<= , != , <>
注意:Oracle比较运算符有两个不等于 != <>

小结:
- from关键字确定要查询那张表
- where关键字用来做条件判断(行过滤),如果条件成立就提取数据,否则就过滤数据。
- select用来选择表中指定的列进行查询
- 关键字执行顺序from-->where-->selec
注意:WHERE执行之前通过from就已经产生了一个查询结果集,where条件判断是在结果集里面进行的
select语句中的逻辑运算符
逻辑运算符的两侧都是条件表达式,Oracle支持的逻辑运算符如下:
| 逻辑运算符 | 意义 |
| and 并且 | 运算符两侧的条件都成立就提取数据,否则就过滤数据 |
| or 或者 | 运算符两侧的条件至少有一个成立就提取数据,否则就过滤数据 |
| not | 取反 |
逻辑运算符通常定义在WHERE关键字后面,用来根据条件进行行过滤
示例:查询工资大于等于1500,并且职位等于销售人员的所有员工信息

示例:查询工资大于等于1500或者职位等于销售人员的所有员工信息

示例:查询工资不大于等于1500,或者职位不等于销售人员的所有员工信息

oracle中所有运算符的优先级如下:
算术运算符:+ ,-, * , /
链接运算符:||
比较运算符:> , >= ,< , <= ,<>
is[not] null,[not] like,[not] in [not] between-and
not and or
通常使用()可以改变运算符的优先级
显示不重复记录
在select语句中,可以使用 DISTINCT 关键字来显示不重复记录据。语法如下:
![]()
示例:显示emp表中的job(职位)列,要求显示的“职位”列记录不能重复:

小结:distinct关键字用来去重(显示不重复记录),该关键字在select和列名称之间定义,如果某个列名称前面有distinct关键字,那么该列的数据不会重复
3.2 特殊关键字筛选
in、between and、like、not null这些特殊的关键字必须定义在WHERE条件后面,用来筛选数据的集合查询
in 关键字 在...里面 。用来判断某个字段的值是否在in集合里面,如果存在就提取数据,否则就过滤数据。
语法: where 字段名称 in(目标值1,目标值2,目标值3....)
判断“字段名称”里面的每个值是否在in里面,如果在就提取数据,否则就过滤掉数据
示例:查询员工编号为7566、7499、7369的员工信息

模糊查询
like 关键字 像......一样
特征:只需要部分字符匹配即可
模糊查询有三种:
- 前面精确后面模糊
- 语法:where 字段名称 like '字符串%'
- %表示模糊匹配多个字符
- 要查找的字符串必须写在一对半角单引号里面
示例:前面精确后面模糊的方式查询所有员工姓名以J开头的员工信息

前面模糊后面精确
语法:where 字段名称 like '%要查找的字符串'
示例:前面模糊后面精确的方式查询员工名称以R结束的所有员工信息

先后模糊中间精确
语法:where 字段名称 like '%要查找的字符串%'
特征:前面和后面都可以是任意字符串,只要中间满足条件即可
示例:先后模糊中间精确的方式查询员工名称包含A的所有员工信息

小结:like关键字通常用在where后面,模糊查询的数据类型通常是字符串类型
区间查询 BETWEEN...AND
BETWEEN...AND关键字用在WHERE后面,用于判断某个条件是否在指定的区间。如果条件成立就提取数据,否则就过滤数据。
BETWEEN后面跟着低区间值
AND后面跟着高区间值
示例:查询工资在1000到2000范围的所有员工信息

IS NULL 关键字
IS NULL 关键字用来判断某个字段是否为空,通常在WHERE关键字后面使用。当字段值为空就提取数据否则就过滤数据
示例:查询emp表中没有奖金的员工信息

3.3 聚合函数
聚合就是对查询结果集做汇总,Oracle提供了5个聚合函数:count(计数)、sum(求总和)、avg(求平均值)、max(计算最大值)、min(计算最小值)。
特征:在结果集之上进行汇总
- count
count聚合函数用来统计结果集总行数。示例:统计emp表总行数

- sum
sum聚合函数用来计算某一列的总和。示例:统计emp表所有员工工资总和

- max
max聚合函数用来计算某一列的最大值。示例:统计emp表最高工资

- min
min聚合函数用来计算某一列的最小值。示例:统计emp表最低工资

- avg
avg聚合函数用来计算某一列的平均值。示例:统计emp表平均工资

- 多个聚合函数一起使用
示例:查询员工表的总行数、工资总和、最高工资、最低工资、平均工

小结:
1. 每个聚合函数返回的结果集为单行单列
2. 除了count以外,其它的聚合函数都使用数值类型作为参数
3.4 分组查询
数据分组的目的是用来汇总数据,在查询结果集中使用 GROUP BY 子句对记录(行)进行分组,它通常和聚合函数一起使用。语法格式如下:

3.4.1 使用GROUP BY进行单列分组
进行单列分组时,会基于分组列的每个不同值生成一个统计结果

示例:统计每个职位的总工资,还要排除员工编号为7369的员工
步骤:
- 列出查询语句需要的关键字 select from where group by
- 在from后面定义要查询的表名称 emp
- 在where后面定义条件 ,此时的条件是:排除员工编号为7369的员工 where empno <> 7369
- 在group by后面定义 需要分组的列,此时为 职位
- 在select后面定义要查询的列名称

小结:
1. 上面的SQL语句执行的时候先执行group by对每个职位进行分组,然后执行聚合函数 sum(sal)对每个分组的职位进行汇总
2. 关键字执行的顺序 from-->group-->select
3.4.2 使用GROUP BY进行多列分组
多列分组是基于两个或者两个以上的列生成分组统计结果。当进行多列分组时,会基于多个列的不同值生成统计结果。
示例:显示每个部门每种职位平均工资、职位最高工资
分析:我们需要对deptno(部门编号)字段和job(职位)字段进行分组,然后对sal(工资字段)进行汇总
步骤:
- 列出查询语句需要的关键字 select from group by
- 在from后面定义要查询的表名称 emp
- 在group by后面定义 需要分组的列,此时为 部门编号 和 职位
- 在select后面定义要查询的列名称
3.5 having
having跟where关键字一样都用于行过滤,如果要对分组之后的结果集进行行过滤请使用having关键字。
having职责:对分组之后的结果集进行过滤
示例:我要统计每个职位的总工资,但是排除员工编号为7369的员工,还要排除职位总工资小于5000的数据
步骤:
- 列出查询关键字 select、from、where、group by、having
- 使用from 关键字查询emp表
- 使用where关键字过滤掉7369的员工信息
- 使用group by 关键字对职位进行分组
- 使用having关键字对分组之后的结果集进行行过滤,过滤掉职位工资总和小于5000的数据
- 在select关键字后面,使用聚合函数计算每个职位的工资总和
目的:理解having关键字

3.6 order by 子句
order by关键字用于对查询的结果集进行排序
排序关键字: order by
语法 : order by 列名称 或者 列别名 asc 或者 desc
asc 升序排序
desc 降序排序
默认asc 升序排序
注意:order by 关键字通常定义在having的后面
示例:在上一个示例基础上对职位工资总和进行升序排序
步骤:
- 列出查询关键字 select、from、where、group by、having、order by
- 使用from 关键字查询emp表
- 使用where关键字过滤掉7369的员工信息
- 使用group by 关键字对职位进行分组
- 使用having对分组之后的结果集进行行过滤,过滤掉职位工资总和小于5000的数据
- 定义select关键字,使用聚合函数计算每个职位的工资总和
- 使用order by 关键字对职位工资总和进行升序排序

3.7 多表联合查询

关系型数据库管理系统为了减少数据冗余将数据化整为零存放在多张表中,彼此之间通过某种关系进行关联。在需要的时候用户可以将多张表的数据关联起来,组合成一个结果集这个就是多表联合查询。常用的多表联合查询分为
4种:内连接查询、左外连接查询、自连接查询、合并查询查询
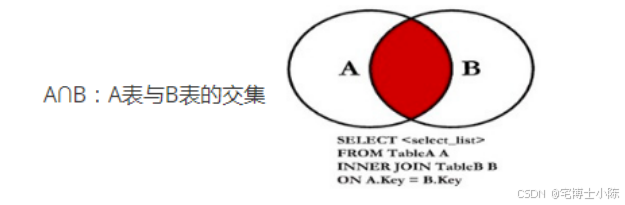
内连接查询两张表共有的数据(取交集),会用到inner join on关键字。其中使用inner join用来指定连接的两张表,使用on指定连接表的连接条件。内连接语法格式如下:

示例:使用内连接查询员工编号、员工姓名、部门名称
分析:员工编号、员工姓名在员工表(emp),部门名称在部门表(dept)
步骤:
- 列出查询关键字。select、from、inner join on
- 确定要查询的表名称。例如:from dept inner join emp
- 使用on关键字进行条件过滤。例如: on dept.deptno = emp.deptno
- 指定要查询的列。例如: emp.empno 员工编号,emp.ename 员工名称, dept.dname 部门名称

小结:
1. 多表联合查询在指定列时使用表名称.列名称,这样做的目的是告诉MySQL服务器你的列属于那张表。
2. select emp.empno 表示选择员工表的员工编号字段进行查询。点(英文dot)可以理解为“的”。
使用inner join on关键字的内连接叫做显示内连接,除此之外还有一种内连接叫做隐式内连接。它忽略了
inner join on关键字, 将内连接的条件表达式定义在where后面。隐式内连接语法如下:

示例:使用隐式内连接查询员工编号、员工姓名、部门名称。
步骤:
- 列出查询关键字。select、from、where
- 确定要查询的表名称。例如:from dept,emp
- 使用where关键字进行条件过滤。例如:where dept.deptno =emp .deptno
- 指定要查询的列。例如: emp.empno 员工编号,emp.ename 员工名称, dept.dname 部门名称

还可以使用表别名(表别名就是表的小名).列名称,这样做的好处让查询语句更加简洁
示例:使用表别名的方式查询员工编号、员工姓名、部门名称

相关文章:
SQL语言基础
SQL(Struct Query Language)是结构化查询语言的简称,是一种在关系型数据库中定义和操纵数据的标准语言。 不要使用面向对象的思想学习SQL,因为它不是面向对象的语言目标 SQL语言简介(了解)从数据库数据检索数据(重点)子查询(重点)Oracle常用函数(掌握) …...

在USB电源测试中如何降低测试成本?-纳米软件
USB 电源模块在现代电子设备中广泛应用,其性能的稳定性和可靠性至关重要。然而,测试 USB 电源模块的成本可能会很高,这对于企业和研发机构来说是一个重要的问题。因此,寻找降低 USB 电源模块测试成本的方法具有重要的现实意义。 降…...

springboot - 定时任务
定时任务是企业级应用中的常见操作 定时任务是企业级开发中必不可少的组成部分,诸如长周期业务数据的计算,例如年度报表,诸如系统脏数据的处理,再比如系统性能监控报告,还有抢购类活动的商品上架,这些都离不…...

一篇文章理解CSS垂直布局方法
方法1:align-content: center 在 2024 年的 CSS 原生属性中允许使用 1 个 CSS 属性 align-content: center进行垂直居中。 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewpo…...

SpringBoot day 1105
ok了家人们,今天继续学习spring boot,let‘s go 六.SpringBoot实现SSM整合 6.1 创建工程,导入静态资源 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>Title</…...

MySQL 完整教程:从入门到精通
MySQL 完整教程:从入门到精通 MySQL 是一个广泛使用的关系型数据库管理系统,它使用结构化查询语言 (SQL) 来管理和操作数据。本文将详细介绍 MySQL 的基本概念、安装与配置、常用 SQL 语法、数据表的创建与管理、索引、视图、存储过程、触发器等高级特性…...

【贝叶斯公式】贝叶斯公式、贝叶斯定理、贝叶斯因子,似然比
一、是什么? 贝叶斯公式的本质在于它提供了一种在已有知识的基础上更新和调整我们对事件的信念的方式。具体来说,贝叶斯公式描述了后验概率(即在观察到某些证据后更新的概率)与先验概率(即在没有观察证据之前的概率&a…...

[libos源码学习 1] Liboc协程生产者消费者举例
文章目录 1. CoRoutineEnv_t结构体用于管理协程环境 3 Liboc协程生产者消费者例子4 Liboc协程生产者消费者, 为什么队列不需要上锁?5. 两个协程访问资源不需要加队列吗5. 参考 1. CoRoutineEnv_t结构体用于管理协程环境 struct stCoRoutineEnv_t { stCo…...

Python OpenCV 图像改变
更改图像数据 通过 改像素点 或者 切片的区域 import cv2 import numpy as np img cv2.imread("image.jpg") print(img[3,5]) # 显示某位置(行3列5)的像素值( 如 [53 34 29] 它是有三通道 B G R 组成) img[3,5] (0,0,255) # 更改该位置的像素…...

k8s按需创建 PV和创建与使用 PVC
在 Kubernetes 中,PersistentVolume(PV)和 PersistentVolumeClaim(PVC)用于管理存储资源。PV 是集群中的存储资源,而 PVC 是 Pod 请求 PV 的方式。按需创建 PV 通常使用 StorageClass 实现动态存储分配&…...
揭秘云计算 | 2、业务需求推动IT发展
揭秘云计算 | 1、云从哪里来?-CSDN博客https://blog.csdn.net/Ultipa/article/details/143430941?spm1001.2014.3001.5502 书接上文: 过去几十年间IT行业从大型主机过渡到客户端/服务器,再过渡到现如今的万物互联,IT可把控的资…...

【系统面试篇】进程与线程类(2)(笔记)——进程调度、中断、异常、用户态、核心态
目录 一、相关面试题 1. 进程的调度算法有哪些? 调度原则 (1)先来先服务调度算法 (2)最短作业优先调度算法 (3)高响应比优先调度算法 (4)时间片轮转调度算法 &am…...

基于MySQL的企业专利数据高效查询与统计实现
背景 在进行产业链/产业评估工作时,我们需要对企业的专利进行评估,其中一个重要指标是统计企业每一年的专利数量。本文基于MySQL数据库,通过公司名称查询该公司每年的专利数,实现了高效的专利数据统计。 流程 项目流程概述如下&…...

热成像手机VS传统热成像仪:AORO A23为何更胜一筹?
热成像技术作为一种非接触式测温方法,广泛应用于石油化工巡检、电力巡检、应急救援、医疗、安防等“危、急、特”场景。提及热成像设备,人们往往会首先想到价格高昂、操作复杂且便携性有限的热成像仪。但是,随着技术的不断进步,市…...

Spring IoC——依赖注入
1. 依赖注入的介绍 DI,也就是依赖注入,在容器中建立的 bean (对象)与 bean 之间是有依赖关系的,如果直接把对象存在 IoC 容器中,那么就都是一个独立的对象,通过建立他们的依赖关系,…...

Linux 中,flock 对文件加锁
在Linux中,flock是一个用于对文件加锁的实用程序,它可以帮助协调多个进程对同一个文件的访问,避免出现数据不一致或冲突等问题。以下是对flock的详细介绍: 基本原理 flock通过在文件上设置锁来控制多个进程对该文件的并发访问。…...
CentOS下载ISO镜像的方法
步骤 1:访问CentOS官方网站 首先,打开浏览器,输入CentOS的官方网站地址:Download 在网站上找到ISO镜像的下载链接,通常位于“Downloads”或类似的页面上。 选择所需的CentOS版本和架构(如x86_64…...

Node.js 入门指南:从零开始构建全栈应用
🌈个人主页:前端青山 🔥系列专栏:node.js篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来node.js篇专栏内容:node.js-入门指南:从零开始构建全栈应用 前言 大家好,我是青山。作…...

MYSQL 真实高并发下的死锁
https://pan.baidu.com/s/1nM3VQdbkNZhnK-wWboEYxA?pwdvwu6 下面是风控更新语句 ------------------------ LATEST DETECTED DEADLOCK ------------------------ 2023-08-04 01:00:10 140188779017984 *** (1) TRANSACTION: TRANSACTION 895271870, ACTIVE 0 sec starting …...

Zookeeper 简介 | 特点 | 数据存储
1、简介 zk就是一个分布式文件系统,不过存储数据的量极小。 1. zookeeper是一个为分布式应用程序提供的一个分布式开源协调服务框架。是Google的Chubby的一个开源实现,是Hadoop和Hbase的重要组件。主要用于解决分布式集群中应用系统的一致性问题。 2. 提…...

火狐浏览器配置Burp Suite抓包完全指南
1. 为什么火狐浏览器在Burp Suite里“抓不到包”?——不是工具不行,是链路断了很多人第一次用Burp Suite配火狐时,点开Proxy → Intercept is on,浏览器照常访问网站,但Burp的HTTP History里空空如也。刷新十次、重启三…...

3步精通League Akari:英雄联盟自动化辅助的终极配置方案
3步精通League Akari:英雄联盟自动化辅助的终极配置方案 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款基于LC…...

3小时从零掌握:通达信缠论量化插件终极实战指南 [特殊字符]
3小时从零掌握:通达信缠论量化插件终极实战指南 🚀 【免费下载链接】Indicator 通达信缠论可视化分析插件 项目地址: https://gitcode.com/gh_mirrors/ind/Indicator 通达信缠论量化插件是一款革命性的技术分析工具,专为股票投资者打造…...
)
DeepSeek隐私保护能力首次第三方穿透测试报告(CNAS认证机构出具,仅限本期披露3项核心缺陷)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek数据隐私保护能力概览 DeepSeek系列大模型在设计与部署阶段即深度融入隐私优先(Privacy-by-Design)原则,其数据处理机制严格遵循最小化采集、本地化计算、端…...

【ChatGPT多语言支持权威评测】:基于27种语言、146项指标的实测数据,揭晓真实可用性天花板
更多请点击: https://kaifayun.com 第一章:【ChatGPT多语言支持权威评测】:基于27种语言、146项指标的实测数据,揭晓真实可用性天花板 评测方法论与语言覆盖范围 本次评测严格采用双盲测试协议,覆盖联合国官方语言&a…...
)
CentOS停服后,我为什么选了Rocky Linux 8.9?手把手教你从下载到配置网卡(附避坑点)
CentOS停服后,我为什么选了Rocky Linux 8.9?手把手教你从下载到配置网卡(附避坑点)当CentOS宣布转向Stream滚动更新模式时,整个运维圈都在寻找稳定可靠的替代方案。作为一位经历过CentOS 5到7全周期的系统管理员&#…...

5分钟终极指南:如何用Python-for-Android将Python代码变成Android应用
5分钟终极指南:如何用Python-for-Android将Python代码变成Android应用 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想要用你熟悉的Python语言开…...

DeepSeek模型权重完整性校验失效?揭秘SHA-3+SGX远程证明双因子加固新范式
更多请点击: https://codechina.net 第一章:DeepSeek模型安全加固 DeepSeek系列大语言模型在开源与商用场景中广泛应用,但其默认部署配置可能存在提示注入、越权推理、训练数据泄露及后门触发等安全风险。安全加固需从模型服务层、推理运行时…...

量子机器学习优化微波脉冲:从量子门到物理控制的降噪增效实践
1. 项目概述与核心价值在量子计算这个充满潜力但也布满荆棘的领域里,我们每天都在和两个“天敌”作斗争:噪声和退相干。你辛辛苦苦制备的量子态,可能还没来得及完成一次完整的计算,就已经被环境噪声“污染”得面目全非。传统的纠错…...

Taotoken API Key管理与审计日志功能的安全价值感知
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API Key管理与审计日志功能的安全价值感知 1. 引言 在团队协作开发中,将大模型能力集成到产品里已成为常见实…...