【数据仓库】Hive 拉链表实践
背景
拉链表是一种数据模型,主要是针对数据仓库设计中表存储数据的方式而定义的;顾名思义,所谓拉链表,就是记录历史。记录一个事务从开始一直到当前状态的所有变化的信息。
拉链表可以避免按每一天存储所有记录造成的海量存储问题,同时也是处理缓慢变化数据(SCD2)的一种常见方式。
应用场景
现假设有如下场景:一个企业拥有5000万会员信息,每天有20万会员资料变更,需要在数仓中记录会员表的历史变化以备分析使用,即每天都要保留一个快照供查询,反映历史数据的情况。
在此场景中,需要反映5000万会员的历史变化,如果保留快照,存储两年就需要2X365X5000W条数据存储空间,数据量为365亿,如果存储更长时间,则无法估计需要的存储空间。而利用拉链算法存储,每日只向历史表中添加新增和变化的数据,每日不过20万条,存储4年也只需要3亿存储空间。
实现步骤
在拉链表中,每一条数据都有一个生效日期(effective_date)和失效日期(expire_date)。假设在一个用户表中,在2019年11月8日新增了两个用户,如下表所示,则这两条记录的生效时间为当天,由于到2019年11月8日为止,这两条就还没有被修改过,所以失效时间为一个给定的比较大的值,比如:3000-12-31
| member_id | phoneno | create_time | update_time |
| 10001 | 13300000001 | 2019-11-08 | 3000-12-31 |
| 10002 | 13500000002 | 2019-11-08 | 3000-12-31 |
第二天(2019-11-09),用户10001被删除了,用户10002的电话号码被修改成13600000002.为了保留历史状态,用户10001的失效时间被修改为2019-11-09,用户10002则变成了两条记录,如下表所示:
| member_id | phoneno | create_time | update_time |
| 10001 | 13300000001 | 2019-11-08 | 2019-11-09 |
| 10002 | 13500000002 | 2019-11-08 | 2019-11-09 |
| 10002 | 13600000002 | 2019-11-09 | 3000-12-31 |
第三天(2019-11-10),又新增了用户10003,则用户表数据如小表所示:
| member_id | phoneno | create_time | update_time |
| 10001 | 13300000001 | 2019-11-08 | 2019-11-09 |
| 10002 | 13500000002 | 2019-11-08 | 2019-11-09 |
| 10002 | 13600000002 | 2019-11-09 | 3000-12-31 |
| 10003 | 13300000006 | 2019-11-10 | 3000-12-31 |
如果要查询最新的数据,那么只要查询失效时间为3000-12-31的数据即可,如果要查11月8号的历史数据,则筛选生效时间<= 2019-11-08并且失效时间>2019-11-08的数据即可。如果查询11月9号的数据,那么筛选条件则是生效时间<=2019-11-09并且失效时间>2019-11-09
表结构
-
MySQL源member表
CREATE TABLE member(member_id VARCHAR ( 64 ),phoneno VARCHAR ( 20 ),create_time datetime,update_time datetime );-
ODS层增量表member_delta,每天一个分区
CREATE TABLE member_delta(member_id string,phoneno string,create_time string,update_time string)
PARTITIONED BY (DAY string);
-
临时表
CREATE TABLE member_his_tmp(member_id string,phoneno string,effective_date date,expire_date date);-
DW层历史拉链表
CREATE TABLE member_his(member_id string,phoneno string,effective_date date,expire_date date);Demo数据准备
2019-11-08的数据为:
| member_id | phoneno | create_time | update_time |
| 10001 | 13500000001 | 2019-11-08 14:47:55 | 2019-11-08 14:47:55 |
| 10002 | 13500000002 | 2019-11-08 14:48:33 | 2019-11-08 14:48:33 |
| 10003 | 13500000003 | 2019-11-08 14:48:53 | 2019-11-08 14:48:53 |
| 10004 | 13500000004 | 2019-11-08 14:49:02 | 2019-11-08 14:49:02 |
2019-11-09的数据为:其中蓝色代表新增数据,红色代表修改的数据
| member_id | phoneno | create_time | update_time |
| 10001 | 13500000001 | 2019-11-08 14:47:55 | 2019-11-08 14:47:55 |
| 10002 | 13600000002 | 2019-11-08 14:48:33 | 2019-11-09 14:48:33 |
| 10003 | 13500000003 | 2019-11-08 14:48:53 | 2019-11-08 14:48:53 |
| 10004 | 13500000004 | 2019-11-08 14:49:02 | 2019-11-08 14:49:02 |
| 10005 | 13500000005 | 2019-11-09 08:54:03 | 2019-11-09 08:54:03 |
| 10006 | 13500000006 | 2019-11-09 09:54:25 | 2019-11-09 09:54:25 |
2019-11-10的数据:其中蓝色代表新增数据,红色代表修改的数据
| member_id | phoneno | create_time | update_time |
| 10001 | 13500000001 | 2019-11-08 14:47:55 | 2019-11-08 14:47:55 |
| 10002 | 13600000002 | 2019-11-08 14:48:33 | 2019-11-09 14:48:33 |
| 10003 | 13500000003 | 2019-11-08 14:48:53 | 2019-11-08 14:48:53 |
| 10004 | 13600000004 | 2019-11-08 14:49:02 | 2019-11-10 14:49:02 |
| 10005 | 13500000005 | 2019-11-09 08:54:03 | 2019-11-09 08:54:03 |
| 10006 | 13500000006 | 2019-11-09 09:54:25 | 2019-11-09 09:54:25 |
| 10007 | 13500000007 | 2019-11-10 17:41:49 | 2019-11-10 17:41:49 |
全量初始装载
在启用拉链表时,先对其进行初始装载,比如以2019-11-08为开始时间,那么将MySQL源表全量抽取到ODS层member_delta表的2018-11-08的分区中,然后初始装载DW层的拉链表member_his
INSERT overwrite TABLE member_his
SELECTmember_id,phoneno,to_date ( create_time ) AS effective_date,'3000-12-31'
FROM
member_delta
WHERE
DAY = '2019-11-08'
查询初始的历史拉链表数据

增量抽取数据
每天,从源系统member表中,将前一天的增量数据抽取到ODS层的增量数据表member_delta对应的分区中。这里的增量需要通过member表中的创建时间和修改时间来确定,或者使用sqoop job监控update时间来进行增联抽取。比如,本案例中2019-11-09和2019-11-10为两个分区,分别存储了2019-11-09和2019-11-10日的增量数据。2019-11-09分区的数据为:

2019-11-10分区的数据为:

增量刷新历史拉链数据
-
2019-11-09增量刷新历史拉链表将数据放进临时表
INSERT overwrite TABLE member_his_tmp
SELECT *
FROM(
-- 2019-11-09增量数据,代表最新的状态,该数据的生效时间是2019-11-09,过期时间为3000-12-31
-- 这些增量的数据需要被全部加载到历史拉链表中
SELECT member_id,phoneno,'2019-11-09' effective_date,'3000-12-31' expire_dateFROM member_deltaWHERE DAY='2019-11-09'UNION ALL
-- 用当前为生效状态的拉链数据,去left join 增量数据,
-- 如果匹配得上,则表示该数据已发生了更新,
-- 此时,需要将发生更新的数据的过期时间更改为当前时间.
-- 如果匹配不上,则表明该数据没有发生更新,此时过期时间不变
SELECT a.member_id,a.phoneno,a.effective_date,if(b.member_id IS NULL, to_date(a.expire_date), to_date(b.day)) expire_dateFROM(SELECT *FROM member_hisWHERE expire_date='3000-12-31') aLEFT JOIN(SELECT *FROM member_deltaWHERE DAY='2019-11-09') b ON a.member_id=b.member_id)his
将数据覆盖到历史拉链表
INSERT overwrite TABLE member_his
SELECT *
FROM member_his_tmp
查看历史拉链表
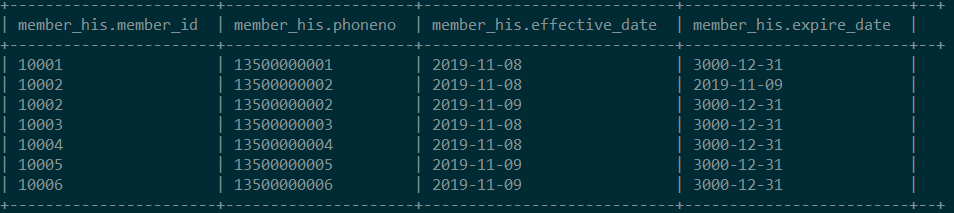
-
2019-11-10增量刷新历史拉链表
将数据放进临时表
INSERT overwrite TABLE member_his_tmp
SELECT *
FROM
(
-- 2019-11-10增量数据,代表最新的状态,该数据的生效时间是2019-11-10,过期时间为3000-12-31
-- 这些增量的数据需要被全部加载到历史拉链表中
SELECT member_id,phoneno,'2019-11-10' effective_date,'3000-12-31' expire_dateFROM member_deltaWHERE DAY='2019-11-10'UNION ALL
-- 用当前为生效状态的拉链数据,去left join 增量数据,
-- 如果匹配得上,则表示该数据已发生了更新,
-- 此时,需要将发生更新的数据的过期时间更改为当前时间.
-- 如果匹配不上,则表明该数据没有发生更新,此时过期时间不变
SELECT a.member_id,a.phoneno,a.effective_date,if(b.member_id IS NULL, to_date(a.expire_date), to_date(b.day)) expire_dateFROM(SELECT *FROM member_hisWHERE expire_date='3000-12-31') aLEFT JOIN(SELECT *FROM member_deltaWHERE DAY='2019-11-10') b ON a.member_id=b.member_id)his查看历史拉链表
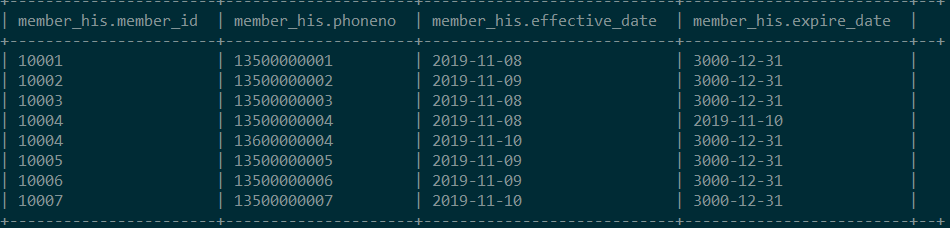
将以上脚本封装成shell调度的脚本
#!/bin/bash
#如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
INSERT overwrite TABLE member_his_tmp
SELECT *
FROM
(
-- 2019-11-10增量数据,代表最新的状态,该数据的生效时间是2019-11-10,过期时间为3000-12-31
-- 这些增量的数据需要被全部加载到历史拉链表中
SELECT member_id,
phoneno,
'$do_date' effective_date,
'3000-12-31' expire_date
FROM member_delta
WHERE DAY='$do_date'
UNION ALL
-- 用当前为生效状态的拉链数据,去left join 增量数据,
-- 如果匹配得上,则表示该数据已发生了更新,
-- 此时,需要将发生更新的数据的过期时间更改为当前时间.
-- 如果匹配不上,则表明该数据没有发生更新,此时过期时间不变
SELECT a.member_id,
a.phoneno,
a.effective_date,
if(b.member_id IS NULL, to_date(a.expire_date), to_date(b.day)) expire_date
FROM
(SELECT *
FROM member_his
WHERE expire_date='3000-12-31') a
LEFT JOIN
(SELECT *
FROM member_delta
WHERE DAY='$do_date') b ON a.member_id=b.member_id)his;
"
$hive -e "$sql"
如需获取更多资料,您可以下载知识星球app,并搜索加入‘数据要素X’。

相关文章:
【数据仓库】Hive 拉链表实践
背景 拉链表是一种数据模型,主要是针对数据仓库设计中表存储数据的方式而定义的;顾名思义,所谓拉链表,就是记录历史。记录一个事务从开始一直到当前状态的所有变化的信息。 拉链表可以避免按每一天存储所有记录造成的海量存储问题…...

【python_pandas_将列表按照某几列进行分组,再求和,按照原列表的字段顺序返回】
说明: 1、按照[“行描述”,”‘公司代码’, ‘科目代码’, ‘预算项目代码’] 进行分组。 2、对“贷方”列进行求和。 3、最后按照之前的表头顺序进行排序,返回结果列表。 #-*- coding:utf-8-*import pandas as pd def consolidate_salary_provisions(l…...

Vue的双向绑定
Vue的双向绑定特性介绍 在现代前端开发中,数据的管理和UI的更新是至关重要的。Vue.js作为一个渐进式JavaScript框架,提供了强大的双向数据绑定机制,极大地简化了这些操作。在本文中,我们将深入探讨Vue的双向绑定特性。 什么是双…...

谷歌浏览器安装 Vue.js devtools 插件
文章目录 1. 安装2. 使用3. 注意 1. 安装 ① 搜索极简插件:https://chrome.zzzmh.cn/index ② 搜索框输入 Vue,选择 Vue.js devtools ③ 从历史版本里面选择并下载,选择 6.4 版本的就行 ④ 打开浏览器,右上角三个点 → 扩展程序…...

LWIP通信协议UDP发送、接收源码解析
1.UDP发送函数比较简短,带操作系统和裸机一样。以下是udp_sendto源码解析; 2.LWIP源码UDP接收数据 2.1.UDP带操作系统接收数据,以下是源码解析; 2.2.UDP裸机接收数据,以下是源码解析...

Linux—进程学习-01
目录 Linux—进程学习—11.冯诺依曼体系结构2.操作系统2.1操作系统的概念2.2操作系统的目的2.3如何理解管理2.4计算机软硬件体系的理解2.5系统调用和库函数的概念 3.进程3.1进程是什么3.2管理进程3.2.1描述进程-PCB3.2.2组织进程3.2.3总结 3.3查看进程 4.与进程有关的系统调用 …...

FR动态数据源插件支持配置模板中某个数据集进行数据连接的切换
1 需求背景 该插件的需求来源于官方帮助文档: 动态数据源/数据库- FineReport帮助文档 - 全面的报表使用教程和学习资料 官方的方案的缺点是会暴露数据库IP,端口密码等,不安全。...

epoll 技术为什么用rbtree而不用hashmap呢?
目录 1.epoll 技术为什么用rbtree而不用hashmap呢?2 .红黑树支持顺序遍历,这对于epoll的事件管理机制可能非常有用, 怎么理解 epoll 理解,可以参考这个 https://zhuanlan.zhihu.com/p/64746509 1.epoll 技术为什么用rbtree而不用…...

关于Android Studio Koala Feature Drop | 2024.1.2下载不了插件的解决办法
解决 androidStudio Settings->Plugins下载插件,点击install后没反应,同时插件描述相关显示不出来 第一步: 第二步: 点击设置,勾选Auto-detect proxy settings,输入网址 https://plugins.jetbrains.com…...

公共命名空间,2024年11月的笔记
进行类比思维。对于在电脑上显示字符的任务,需要字符集。曾经有人研究算法,希望编出一个神奇的程序,能够显示所有字符。但最终的结果是,需要字符集,人工地把所有字符收集起来,让电脑一个个记住,…...

登录功能设计(php+mysql)
一 登录功能 1. 创建一个登录页面(login.php),包含一个表单,用户输入用户名和密码。 2. 在表单的提交事件中,使用PHP代码处理用户输入的用户名和密码。 3. 首先,连接MySQL数据库。然后&a…...

从0开始学习Linux——远程连接工具
往期目录: 从0开始学习Linux——简介&安装 从0开始学习Linux——搭建属于自己的Linux虚拟机 从0开始学习Linux——文本编辑器 从0开始学习Linux——Yum工具 Linux 远程连接工具是指用于从远程计算机连接到 Linux 系统并进行操作的各种工具。它们可以帮助管理员或…...

Java线程6种生命周期及转换
多线程技术是我们后端工程师在面试的时候必问的一个知识点,今天就来盘点一下多线程的相关知识, 先来说下进程,线程及线程的生命周期: 进程:进程就是正在进行中的程序,是没有生命的实体,只有在运…...

关于STM32在代码中的而GPIO里面的寄存器(ODR等)不需要宏定义的问题
1.GPIO为什么需要宏定义地址 在 STM32 这样的微控制器中,硬件寄存器的地址是固定的并且特定于每个外设(比如 GPIOA、GPIOB 等)。为了方便代码访问这些硬件寄存器,我们通常会使用宏定义来指定每个外设的基地址。这样做有几个理由&a…...

【北京迅为】《STM32MP157开发板嵌入式开发指南》-第七十七章 交叉编译QT工程
iTOP-STM32MP157开发板采用ST推出的双核cortex-A7单核cortex-M4异构处理器,既可用Linux、又可以用于STM32单片机开发。开发板采用核心板底板结构,主频650M、1G内存、8G存储,核心板采用工业级板对板连接器,高可靠,牢固耐…...

高效率的快捷回复软件 —— 客服宝聊天助手
在电商行业日益繁荣的今天,高效的客户沟通对于企业的成功至关重要。无论是电商平台、居家客服还是其他各类客服行业,都需要一款强大的工具来提升工作效率。今天,我们就来介绍一款高效率的快捷回复软件 —— 客服宝聊天助手。 一、跨平台跨店铺…...

Node.js + MongoDB + Vue 3 全栈应用项目开发
🌈个人主页:前端青山 🔥系列专栏:node.js篇 🔖人终将被年少不可得之物困其一生 依旧青山,本期给大家带来node.js篇专栏内容:Node.js MongoDB Vue 3 全栈应用项目开发 在前几篇文章中,我们已经为 Node.j…...

【云原生开发】如何通过client-go来操作K8S集群
✨✨ 欢迎大家来到景天科技苑✨✨ 🎈🎈 养成好习惯,先赞后看哦~🎈🎈 🏆 作者简介:景天科技苑 🏆《头衔》:大厂架构师,华为云开发者社区专家博主,…...

CSS基础知识六(浮动的高度塌陷问题及解决方案)
目录 1.浮动高度塌陷概念 2.下面是几种解决高度塌陷的几种方案: 解决方案一: 解决方案二: 解决方案三: 1.浮动高度塌陷概念 在CSS中,高度塌陷问题指的是父元素没有正确地根据其内部的浮动元素或绝对定位元素来计…...

开源模型应用落地-glm模型小试-glm-4-9b-chat-vLLM集成(四)
一、前言 GLM-4是智谱AI团队于2024年1月16日发布的基座大模型,旨在自动理解和规划用户的复杂指令,并能调用网页浏览器。其功能包括数据分析、图表创建、PPT生成等,支持128K的上下文窗口,使其在长文本处理和精度召回方面表现优异&a…...

别再被GPG签名卡住了!手把手教你修复Kali老版本apt更新源报错
Kali Linux系统更新源管理进阶指南:从故障修复到高效运维当你成功解决了Kali Linux老版本因GPG签名失效导致的apt更新源报错后,这只是系统维护的第一步。真正的挑战在于如何构建一套可持续的运维策略,避免类似问题反复出现,同时提…...

C#巧用Spire.XLS for .NET隐藏或显示Excel网格线
在日常的数据处理和报表生成中,Excel是我们不可或缺的工具。然而,你是否曾遇到这样的场景:辛苦制作的报表,因为默认显示的网格线而显得不够专业,或是某些数据可视化图表,网格线反而成了干扰?手动…...

边缘计算赋能触觉互联网与数字孪生:架构、挑战与物理治疗实践
1. 从概念到现实:边缘计算如何重塑触觉互联网与人类数字孪生在远程医疗、工业操控乃至未来的元宇宙体验中,我们一直梦想着能突破屏幕的界限,实现“隔空取物”般的真实交互。医生希望远程为病人进行精准的物理治疗,工程师渴望在千里…...

ISP模型与硬件平台配置迁移实践指南
1. 理解ISP模型与硬件平台的配置迁移在图像信号处理器(ISP)开发过程中,我们经常需要在软件模型和实际硬件平台之间进行配置迁移。这种迁移的核心挑战在于确保模型仿真结果与硬件输出完全一致。根据我的经验,这涉及到两个主要操作模…...
)
全球仅17家机构掌握的PlayAI教育大模型微调技术(含3所双一流高校内部调参手册节选)
更多请点击: https://intelliparadigm.com 第一章:PlayAI教育大模型微调技术的全球稀缺性与战略价值 在全球人工智能教育应用加速落地的背景下,PlayAI教育大模型微调技术已成为少数国家与头部机构掌握的核心能力。其稀缺性不仅源于算力、数据…...
)
从‘进程打架’到‘内存搬家’:用大白话图解操作系统核心概念(附避坑指南)
从‘进程打架’到‘内存搬家’:用大白话图解操作系统核心概念(附避坑指南)当CPU变成游乐场:进程管理的奇妙比喻想象一下周末的迪士尼乐园——每个游客就像计算机中的一个进程,而CPU就是那台最热门的过山车。早晨开园时…...

Ubuntu 22.04双网卡配置踩坑记:netplan apply报错‘默认路由冲突’的三种解法
Ubuntu 22.04双网卡路由冲突实战指南:从紧急修复到高阶策略当你为Ubuntu服务器配置双网卡时,netplan apply命令突然抛出"Conflicting default route declarations for IPv4"错误,这种场景对运维工程师来说再熟悉不过。本文将带你深…...

FlexHEG:AI硬件加速器的自动化保障验证框架
1. FlexHEG技术体系概述FlexHEG(Flexible Hardware-Enabled Guarantees)是一套为AI硬件加速器设计的自动化保障验证框架。这个技术体系的核心目标是通过硬件和软件的协同设计,实现对AI计算工作负载的实时监控和策略合规性验证。在当前AI技术快…...

【教育智能化临界点预警】:再不掌握AI Agent教学编排逻辑,3个月内将被首批智能助教替代
更多请点击: https://codechina.net 第一章:教育智能化临界点的本质判据与AI Agent不可逆替代趋势 教育智能化是否真正跨越临界点,不取决于技术参数的堆叠,而在于教学闭环中“决策权迁移”的可观测性——当AI Agent在备课、学情诊…...

双系统硬盘告急?手把手教你用Ubuntu Live U盘和gparted无损调整/home分区大小
双系统用户必看:Ubuntu分区扩容实战指南你是否也遇到过这样的尴尬——当初安装双系统时随手给Ubuntu的分区分配空间,结果用着用着发现/home目录快被塞爆了,而根目录/却还有大量闲置空间?这种"旱的旱死,涝的涝死&q…...