高并发内存池扩展 -- 处理大内存,优化释放时需要传入空间大小,加入定长内存池,存放映射关系的容器的锁机制,优化性能(基数树,优势,优化前后对比)
目录
高并发内存池 扩展
测试
大内存
介绍
代码
优化释放时需要传入空间大小
介绍
赋值
代码
加入定长内存池
引入
介绍
代码
存放映射关系的容器 锁机制
写入
读取
优化性能
引入
基数树
单级基数树
两级基数树
三级基数树
优势
引入代码
优化前后对比
项目介绍+定长内存池实现 -- 高并发内存池 -- 内存池介绍+问题,定长内存池原理+代码-CSDN博客
整体框架+基本实现 -- 高并发内存池 -- 内存池介绍+问题,定长内存池原理+代码-CSDN博客
高并发内存池 扩展
测试
void TestConcurrentAlloc1() {Thread_Cache tc;void *p1 = tc.alloc(6);void *p2 = tc.alloc(8); // 剩1void *p3 = tc.alloc(1); // 拿1void *p4 = tc.alloc(7); // 剩2void *p5 = tc.alloc(8); // 拿1void *p6 = tc.alloc(8); // 拿1void *p7 = tc.alloc(8); // 剩3std::cout << p1 << std::endl;std::cout << p2 << std::endl;std::cout << p3 << std::endl;std::cout << p4 << std::endl;std::cout << p5 << std::endl;std::cout << p6 << std::endl;std::cout << p7 << std::endl;tc.dealloc(p1, 6);tc.dealloc(p2, 8);tc.dealloc(p3, 1);tc.dealloc(p4, 7);tc.dealloc(p5, 8);tc.dealloc(p6, 8);tc.dealloc(p7, 8); }可以看到,这里我们申请出来的内存块,地址都是连续的:
- 符合我们之前维持了连续地址的特性 -- 在central cache中将切分出来的内存块尾插进链表 + thread cache 分配内存块是头删

大内存
介绍
thread cache最大支持256kb以下的内存申请
如果大于256kb呢?
- 256kb等于64页(页大小为4kb的情况下),在要申请这么多页的情况下,从thread cache开始走流程显然不可能
- 可以考虑从page cache开始
- 从这里申请,也从这里归还 -- 归还后的空间可以被合并/切分后分配给其他线程
如果再大一点,大于128页呢?
- 只能向堆申请了,page cache管不了128页以上的大内存
但依然需要借助page cache的alloc接口
- 也就是要创建一个span来管理分配的内存,因为释放的时候需要传入空间大小
- 如果只是一个指针,无法得知指向的空间是多大的
代码
#include "helper.hpp" #include "thread_cache.hpp" #include <cassert>void *concurrent_alloc(size_t size) {if (size <= helper::THREAD_CACHE_MAX_SIZE){// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象if (TLS_ThreadCache == nullptr){TLS_ThreadCache = new Thread_Cache;}return TLS_ThreadCache->alloc(size);}else // 直接走page cache流程{int page_size = 1 << helper::PAGE_SHIFT;// int page = (size % page_size > 0) ? (size / page_size + 1) * page_size : size >> helper::PAGE_SHIFT;int page = (size + page_size - 1) >> helper::PAGE_SHIFT;std::unique_lock<std::mutex> lock(Page_Cache::get_instance()->mtx_);Span *span = Page_Cache::get_instance()->alloc(page);return helper::pageid_to_ptr(span->start_pageid_);} }void concurrent_free(void *ptr,size_t size) {if (size <= helper::THREAD_CACHE_MAX_SIZE){assert(TLS_ThreadCache);TLS_ThreadCache->dealloc(ptr, size);}else{std::unique_lock<std::mutex> lock(Page_Cache::get_instance()->mtx_);Page_Cache::get_instance()->recycle(span);} }Span *alloc(int page){if (page > 128) // 直接向堆申请{void *ptr = helper::allocate_memory(page);// 创建并初始化spanSpan *span = new Span;span->n_ = page;span->start_pageid_ = helper::ptr_to_pageid(ptr);page_to_span_[span->start_pageid_] = span; // 用于在释放的时候拿到span结构,来确定分配的空间大小return span;}...
优化释放时需要传入空间大小
介绍
因为我们要和free靠拢,free就只需要指针就可以正确释放空间
- 解决这个问题其实也很简单
本身,我们能通过指针来找到空间对应的页号
- 页号+页号->span的映射关系,我们可以找到空间对应的span结构
而每个span被切分成小块后,小块内存的大小都是一样的
- 所以,我们可以直接在span结构内定义一个字段,记录申请时的内存块大小
- 这样就不需要在释放接口处额外传入空间大小
- 可以通过指针->页号->span->空间大小
赋值
- 如果要走三层缓存,在切分对象时赋值
- 如果走page cache/堆,在申请到span后赋值
这也就是为什么向堆申请空间后,依然要转成span结构,并且要建立页号和span的映射关系
- 就是为了这里的优化
- 因为这个大小本身就是被用来判断究竟走thread cache还是page cache的释放逻辑,无论存储的是实际使用大小,还是对齐后的大小,都不影响
代码
void concurrent_free(void *ptr) {Span *span = Page_Cache::get_instance()->obj_to_span(ptr);size_t size = span->size_;if (size <= helper::THREAD_CACHE_MAX_SIZE){assert(TLS_ThreadCache);TLS_ThreadCache->dealloc(ptr, size);}else{std::unique_lock<std::mutex> lock(Page_Cache::get_instance()->mtx_);Page_Cache::get_instance()->recycle(span);} }central cache.hpp
Span *get_nonnull_span(std::unique_lock<std::mutex> &lock, int id, size_t size){Span *span = span_map_[id].get_nonnull_span();if (span != nullptr){return span;}else // 没有span就去page cache里要{span = alloc_page_cache(lock, id, size);span->size_ = size;// 切分成若干个对象...return span;}}page_cache.hpp
Span *alloc(int page){if (page > 128) // 直接向堆申请{void *ptr = helper::allocate_memory(page);// 创建并初始化spanSpan *span = new Span;span->n_ = page;span->start_pageid_ = helper::ptr_to_pageid(ptr);span->size_ = page << helper::PAGE_SHIFT;page_to_span_[span->start_pageid_] = span; // 用于在释放的时候拿到span结构,来确定分配的空间大小return span;}Span *span = nullptr;// 当前有对应页的spanif (!span_map_[page].empty()){span = span_map_[page].pop_front();// 建立好每页的映射for (int i = 0; i < span->n_; ++i){page_to_span_[span->start_pageid_ + i] = span;}return span;}// 继续往下找else{for (int i = page + 1; i <= helper::MAX_PAGE_NUM; ++i){if (!span_map_[i].empty()){span = span_map_[i].pop_front(); // 移除即将被切分的大spanbreak;}}// 找到了就切分成两个spanif (span != nullptr){page_to_span_.erase(span->start_pageid_);page_to_span_.erase(span->start_pageid_ + span->n_ - 1);// 大span的前page个页属于分配出去的span,剩下的部分链入到对应位置Span *newspan = new Span;newspan->n_ = span->n_ - page;newspan->start_pageid_ = span->start_pageid_ + page;span_map_[newspan->n_].insert(newspan);span->n_ = page;span->size_ = page << helper::PAGE_SHIFT;// 建立页号->span的地址// span是要分配给central cache,最终给thread cache,会涉及到内存回收问题,所以需要每页都映射for (int i = 0; i < span->n_; ++i){page_to_span_[span->start_pageid_ + i] = span;}// newspan留在page cache,只需要被合并,所以首尾页映射即可page_to_span_[newspan->start_pageid_] = newspan;page_to_span_[newspan->start_pageid_ + newspan->n_ - 1] = newspan;}// 如果实在找不到span,向系统申请128页else{void *ptr = helper::allocate_memory(helper::MAX_PAGE_NUM);// 创建并初始化spanspan = new Span;span->n_ = helper::MAX_PAGE_NUM;span->start_pageid_ = helper::ptr_to_pageid(ptr);span_map_[span->n_].insert(span);page_to_span_[span->start_pageid_] = span;page_to_span_[span->start_pageid_ + span->n_ - 1] = span;return alloc(page);}return span;}return nullptr;}
加入定长内存池
引入
我们这个项目本身是为了替代malloc而设计的
- 但我们内部却又在使用malloc,这就不太行
所以,我们需要用其他方案来代替项目内部使用的malloc
介绍
其实这个项目也就是在两个场景下使用了:
定义span对象时
- 基本我们的span对象都是在page cache下申请出来的,然后按需分配给central cache使用
- 因为span的大小是固定的,只是span下管理的页数在发生变化
- 所以我们可以直接用定长内存池来作为替代方案 -- 在定长内存池中,内存是直接向堆申请的,并没有借助malloc
定义thread cache对象时
- 对于每个线程,我们都需要定义一个thread cache对象
- 所以也需要定义一个专门用来申请thread cache的定长内存池
而central cache和page cache两个结构是直接定义的静态对象
- 单例模式下虽然返回的是对象地址,但不涉及new
- 所以不需要替换
代码
page cache.hpp
#pragma once#include <unordered_map> #include <map> #include "helper.hpp" #include "list.hpp" #include "fixed_length_memorypool.hpp"class Page_Cache {static Page_Cache instance_;std::map<helper::page_t, Span *> page_to_span_;SpanList span_map_[helper::MAX_PAGE_NUM + 1];public:static std::mutex mtx_;public:static Page_Cache *get_instance(){return &instance_;}Span *obj_to_span(void *ptr){helper::page_t page_id = ((helper::page_t)ptr) >> helper::PAGE_SHIFT;std::unique_lock<std::mutex> lock(mtx_);auto ret = page_to_span_.find(page_id);if (ret == page_to_span_.end()){return nullptr;}return ret->second;}Span *alloc(int page){if (page > 128) // 直接向堆申请{void *ptr = helper::allocate_memory(page);// 创建并初始化span// Span *span = new Span;Span *span = span_pool.New();span->n_ = page;span->start_pageid_ = helper::ptr_to_pageid(ptr);span->size_ = page << helper::PAGE_SHIFT;page_to_span_[span->start_pageid_] = span; // 用于在释放的时候拿到span结构,来确定分配的空间大小return span;}Span *span = nullptr;// 当前有对应页的spanif (!span_map_[page].empty()){span = span_map_[page].pop_front();// 建立好每页的映射for (int i = 0; i < span->n_; ++i){page_to_span_[span->start_pageid_ + i] = span;}return span;}// 继续往下找else{for (int i = page + 1; i <= helper::MAX_PAGE_NUM; ++i){if (!span_map_[i].empty()){span = span_map_[i].pop_front(); // 移除即将被切分的大spanbreak;}}// 找到了就切分成两个spanif (span != nullptr){page_to_span_.erase(span->start_pageid_);page_to_span_.erase(span->start_pageid_ + span->n_ - 1);// 大span的前page个页属于分配出去的span,剩下的部分链入到对应位置// Span *newspan = new Span;Span *newspan = span_pool.New();newspan->n_ = span->n_ - page;newspan->start_pageid_ = span->start_pageid_ + page;span_map_[newspan->n_].insert(newspan);span->n_ = page;span->size_ = page << helper::PAGE_SHIFT;// 建立页号->span的地址// span是要分配给central cache,最终给thread cache,会涉及到内存回收问题,所以需要每页都映射for (int i = 0; i < span->n_; ++i){page_to_span_[span->start_pageid_ + i] = span;}// newspan留在page cache,只需要被合并,所以首尾页映射即可page_to_span_[newspan->start_pageid_] = newspan;page_to_span_[newspan->start_pageid_ + newspan->n_ - 1] = newspan;}// 如果实在找不到span,向系统申请128页else{void *ptr = helper::allocate_memory(helper::MAX_PAGE_NUM);// 创建并初始化spanspan = new Span;Span *span = span_pool.New();span->n_ = helper::MAX_PAGE_NUM;span->start_pageid_ = helper::ptr_to_pageid(ptr);span_map_[span->n_].insert(span);page_to_span_[span->start_pageid_] = span;page_to_span_[span->start_pageid_ + span->n_ - 1] = span;return alloc(page);}return span;}return nullptr;}void recycle(Span *span){if (span->n_ > 128){void *ptr = helper::pageid_to_ptr(span->start_pageid_);page_to_span_.erase(span->start_pageid_);helper::release_memory(ptr, span->n_);// delete span;span_pool.Delete(span);return;}// 合并helper::page_t page_id = span->start_pageid_ - 1;while (true) // 往前找{// 这里需要页号->span的映射关系// 找到了就合并if (page_to_span_.find(page_id) != page_to_span_.end()){Span *merged_span = page_to_span_[page_id];// 存在但不一定处于空闲状态,该span现在不一定链接在page cache中// 如果合并后>128页,就不要再合并了if (merged_span->is_use_ == false && span->n_ + merged_span->n_ <= 128){span->n_ += merged_span->n_;span->start_pageid_ -= merged_span->n_;page_id = span->start_pageid_ - 1;// 解除[被合并的页]和其他结构的关系,并释放spanpage_to_span_.erase(merged_span->start_pageid_);page_to_span_.erase(merged_span->start_pageid_ + merged_span->n_ - 1);span_map_[merged_span->n_].remove(merged_span);// delete merged_span;span_pool.Delete(merged_span);}else{break;}}else{break;}}page_id = span->start_pageid_ + span->n_;while (true) // 往后找{if (page_to_span_.find(page_id) != page_to_span_.end()){Span *merged_span = page_to_span_[page_id];if (merged_span->is_use_ == false && span->n_ + merged_span->n_ <= 128){span->n_ += merged_span->n_;page_id += merged_span->n_;// 解除[被合并的页]和其他结构的关系,并释放spanpage_to_span_.erase(merged_span->start_pageid_);page_to_span_.erase(merged_span->start_pageid_ + merged_span->n_ - 1);span_map_[merged_span->n_].remove(merged_span);// delete merged_span;span_pool.Delete(merged_span);}else{break;}}else{break;}}span_map_[span->n_].insert(span);page_to_span_[span->start_pageid_] = span;page_to_span_[span->start_pageid_ + span->n_ - 1] = span;}private:Page_Cache() {}~Page_Cache() {}Page_Cache(const Page_Cache &) = delete;Page_Cache &operator=(const Page_Cache &) = delete; };std::mutex Page_Cache::mtx_; Page_Cache Page_Cache::instance_;concurrent.hpp
static FixedLength_MemoryPool<Thread_Cache> thread_cache_pool;void *concurrent_alloc(size_t size) {if (size <= helper::THREAD_CACHE_MAX_SIZE){// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象if (TLS_ThreadCache == nullptr){// TLS_ThreadCache = new Thread_Cache;TLS_ThreadCache = thread_cache_pool.New();}return TLS_ThreadCache->alloc(size);}else // 直接走page cache流程{int page_size = 1 << helper::PAGE_SHIFT;// int page = (size % page_size > 0) ? (size / page_size + 1) * page_size : size >> helper::PAGE_SHIFT;int page = (size + page_size - 1) >> helper::PAGE_SHIFT;std::unique_lock<std::mutex> lock(Page_Cache::get_instance()->mtx_);Span *span = Page_Cache::get_instance()->alloc(page);return helper::pageid_to_ptr(span->start_pageid_);} }
存放映射关系的容器 锁机制
写入
我们用unordered_map容器存放页号->span指针的映射关系
- 而这个项目属于高并发场景,且stl是不保证容器的线程安全的
- 所以,在修改该结构里的数据时,我们需要加锁
纵观整个代码,修改该容器中的数据时:
- 要么在page cache的alloc中,要么在page cache的recycle中
- 而调用这两个接口时,都处于page cache加的大锁中,所以不必另外加锁


读取
除了修改,很多地方也都在读这个结构
- 除了page cache结构内部的读取,在central cache的回收逻辑+线程使用的接口中也会读取
- 其中,page cache提供的obj_to_span接口就是在读取数据
基于unordered_map结构底层是哈希表
- 可能我在读的时候,其他线程正在修改
- 如果触发了再哈希,可能会更改底层结构和内存布局,导致我读取操作失效/错误
所以,读也需要加锁
- 可以借助具备RAII的锁 -- std::unique_lock
- 定义时可以自动加锁,出作用域后自动解锁,也支持手动加/解锁


优化性能
引入
通过性能测试工具来查看本项目中函数的调用次数占比
linux下的Callgrind工具:
我们会发现是锁竞争+多次page_to_span的访问导致性能差
我们来分析下哪里会用到锁:
- central cache/page cache下对span链表的修改
- central cache中对page_to_span结构的修改 -- 也就是存放页号->span映射关系的容器
- 对容器的访问越慢,锁竞争越激烈
思来想去,只能对[如何存放页号->span地址的映射关系]做优化了
- 解决 -- 基数树

基数树
- 核心思想 -- 将地址或键值空间分为多个“层级”或“桶”,并基于这些层级进行查找、插入和管理
这里为了考虑可移植性,在32位/64位下均能运行
- 需要设计三颗基数树 (其中32位使用一级/两级基数树都可以,64位必须使用三级基数树)
- 这里的基数树均用数组结构来实现

单级基数树
因为只有一层,所以采用直接映射法
- 在这一层,页号是几就去对应的位置拿指针就行
这里使用模板参数,外部传入表示页号需要的位数
- BITS = 32/64 - PAGE_SHIFT -- 存储页号需要的位数
- PAGE_SHIFT是页位移(4kb的页大小是12,8kb是13)
如果在32位,页大小为8kb的情况下,一共有2^32/2^13个页,也就是2^19个页 位数就是19
64位下同理
空间占用2^19*4=2^21字节=2MB
两级基数树
分层哈希,共有两层:
- 第一层有32个位置
- 每个位置对应一个指针数组(第二层),每个数组有2^(19-5)个元素
和一级基数树占用的空间相同
- 二级基数树占用空间 : 32*2^14*4=2^21字节=2MB
如何映射?
在32位下,虽然页号只需要19位,但一般存放页号的变量可以存放32位
- 所以是低19位存储页号,高13位为0
- 其中,低19位的前5位决定去第一层的哪一个位置
- 后14位决定去第二层的哪个位置找


三级基数树
适合64位
- 因为64位下的页号需要51位来存放
- 如果采用两级基数树,第二层里的每个数组就是2^51/2^5=2^46字节,一次开辟的空间太大了
原理和二级的相同
- 只是将页号分为三部分,然后一部分映射一层
- 但是,对于相同大小的页号,两级/三级基数树需要的空间 和 一级基数树 是相同的
为什么要分层设计呢?
- 不同点在于,一层结构需要一次就把所有空间开出来,这样需要的连续空间就太大了
- 而二层,三层的可以用的时候再开辟一部分
优势
优势 -- 不用加锁+本身就快
本身就快:
- 随着数据量增大+页号长度较长,基数树通过合并公共前缀,可以提高查询效率
- 并且节省了内存
为什么不用加锁?
- 在读取unordered_map容器时,其他线程可能同时在插入/删除,就可能会改变结构 -- 无论是红黑树还是哈希桶,都会有影响
- 所以,必须加锁
- 而使用基数树后,无论怎么修改数值,都不会影响结构 -- 除非是两个线程同时操作同一个位置
并且在代码里,我们对这个结构是读写分离的:
写: 获取到一个新span后(大span切小 / 回收span到page cache中)
- 其实这里不加锁也是可以的,同一个span不可能同时被获取和回收
- 但是经过我实操,发现只能是在[线程归还大内存时]不用加page_cache的锁
- central_cache从page cache那获取span还是要加锁的,因为有可能多个线程获取到同一个span
读: 小块内存还给span,找到对应span / 线程归还内存时,找到内存对应的大小
- 而span在被读时候,该span不可能被其他线程写,因为已经被线程持有了
所以对基数树的访问不需要加锁
引入代码
将unordered_map替换成基数树
- 根据当前操作系统的位数(32/64位),选择合适的基数树
- 32位使用一级/两级基数树 ; 64位使用三级基数树
它里面也借助了malloc开辟空间
- 所以需要引入定长内存池
一级的需要直接开空间,需要传入可以开辟空间的函数指针
- 而我们又想脱离malloc,所以直接向堆申请
- 但堆申请出来的空间都是以页为单位的,所以需要先计算出这块空间以页对齐后的大小
两级的是用的时候再开辟
- 我们可以简单一点,直接像一级基数树那样全部开好
- 因为一次只要2M,还可以接收
#pragma once#include <cassert> #include "helper.hpp" #include "fixed_length_memorypool.hpp"// Single-level array template <int BITS> class TCMalloc_PageMap1 {static const int LENGTH = 1 << BITS; // 表示页号需要的位数void **array_; // 指针数组public:typedef helper::page_t Number;explicit TCMalloc_PageMap1() // 防止隐式转换{size_t size = sizeof(void *) << BITS; // 计算页号大小size_t alignSize = helper::Round_up(size, 1 << helper::PAGE_SHIFT); // 对齐到页array_ = (void **)helper::allocate_memory(alignSize >> helper::PAGE_SHIFT); // 一次将空间开好memset(array_, 0, sizeof(void *) << BITS);}void *get(Number k) const{if ((k >> BITS) > 0){return NULL;}return array_[k];}void set(Number k, void *v){array_[k] = v;} };// Two-level radix tree template <int BITS> class TCMalloc_PageMap2 {// 第一层 32个位置static const int ROOT_BITS = 5;static const int ROOT_LENGTH = 1 << ROOT_BITS;// 第二层 每个数组都有2^14个位置static const int LEAF_BITS = BITS - ROOT_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;// 第二层 每一个元素都是指针数组struct Leaf{void *values[LEAF_LENGTH];};Leaf *root_[ROOT_LENGTH]; // Pointers to 32 child nodespublic:typedef helper::page_t Number;explicit TCMalloc_PageMap2(){memset(root_, 0, sizeof(root_));PreallocateMoreMemory(); // 这里选择一次就把空间开好,因为只有2MB,所以不影响}void *get(Number k) const{const Number i1 = k >> LEAF_BITS; // 取出前5位const Number i2 = k & (LEAF_LENGTH - 1); // 取出后14位if ((k >> BITS) > 0 || root_[i1] == NULL) // 页号超出19位 / 不存在i1这个桶{return NULL;}return root_[i1]->values[i2]; // 取出span指针}void set(Number k, void *v){const Number i1 = k >> LEAF_BITS;const Number i2 = k & (LEAF_LENGTH - 1);assert(i1 < ROOT_LENGTH);root_[i1]->values[i2] = v;}bool Ensure(Number start, size_t n){for (Number key = start; key <= start + n - 1;){const Number i1 = key >> LEAF_BITS;if (i1 >= ROOT_LENGTH)return false;// Make 2nd level node if necessaryif (root_[i1] == NULL) // 如果不存在这个桶{static FixedLength_MemoryPool<Leaf> leafPool1;Leaf *leaf = (Leaf *)leafPool1.New(); // 创建桶memset(leaf, 0, sizeof(*leaf));root_[i1] = leaf;}// Advance key past whatever is covered by this leaf nodekey = ((key >> LEAF_BITS) + 1) << LEAF_BITS; // 指向下一个叶子结点}return true;}void PreallocateMoreMemory(){// Allocate enough to keep track of all possible pagesEnsure(0, 1 << BITS); // 表示所有页号} };// Three-level radix tree template <int BITS> // 20 class TCMalloc_PageMap3 { private:// How many bits should we consume at each interior levelstatic const int INTERIOR_BITS = (BITS + 2) / 3; // Round-upstatic const int INTERIOR_LENGTH = 1 << INTERIOR_BITS;// How many bits should we consume at leaf levelstatic const int LEAF_BITS = BITS - 2 * INTERIOR_BITS;static const int LEAF_LENGTH = 1 << LEAF_BITS;// Interior nodestruct Node{Node *ptrs[INTERIOR_LENGTH];};// Leaf nodestruct Leaf{void *values[LEAF_LENGTH];};Node *root_; // Root of radix treeNode *NewNode(){// Node *result = reinterpret_cast<Node *>((*allocator_)(sizeof(Node)));static FixedLength_MemoryPool<Node> NodePool;Node *result = NodePool.New();if (result != NULL){memset(result, 0, sizeof(*result));}return result;}public:typedef helper::page_t Number;explicit TCMalloc_PageMap3(){root_ = NewNode();}void *get(Number k) const{const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);const Number i3 = k & (LEAF_LENGTH - 1);if ((k >> BITS) > 0 ||root_->ptrs[i1] == NULL || root_->ptrs[i1]->ptrs[i2] == NULL){return NULL;}return reinterpret_cast<Leaf *>(root_->ptrs[i1]->ptrs[i2])->values[i3];}void set(Number k, void *v){assert(k >> BITS == 0);const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);const Number i3 = k & (LEAF_LENGTH - 1);reinterpret_cast<Leaf *>(root_->ptrs[i1]->ptrs[i2])->values[i3] = v;}bool Ensure(Number start, size_t n){for (Number key = start; key <= start + n - 1;){const Number i1 = key >> (LEAF_BITS + INTERIOR_BITS);const Number i2 = (key >> LEAF_BITS) & (INTERIOR_LENGTH - 1);// Check for overflowif (i1 >= INTERIOR_LENGTH || i2 >= INTERIOR_LENGTH)return false;// Make 2nd level node if necessaryif (root_->ptrs[i1] == NULL){Node *n = NewNode();if (n == NULL)return false;root_->ptrs[i1] = n;}// Make leaf node if necessaryif (root_->ptrs[i1]->ptrs[i2] == NULL){// Leaf *leaf = reinterpret_cast<Leaf *>((*allocator_)(sizeof(Leaf)));static FixedLength_MemoryPool<Leaf> leafPool2;Leaf *leaf = leafPool2.New();if (leaf == NULL)return false;memset(leaf, 0, sizeof(*leaf));root_->ptrs[i1]->ptrs[i2] = reinterpret_cast<Node *>(leaf);}// Advance key past whatever is covered by this leaf nodekey = ((key >> LEAF_BITS) + 1) << LEAF_BITS;}return true;}void PreallocateMoreMemory(){} };
优化前后对比
linux下的性能检查:
- 优化前:
- 优化后:
- 其中,锁相关操作占比减少,哈希表相关操作没有了,并且没有调用malloc接口
- 说明引入基数树后确实实现了我们的目标,并且彻底脱离了malloc

相关文章:

高并发内存池扩展 -- 处理大内存,优化释放时需要传入空间大小,加入定长内存池,存放映射关系的容器的锁机制,优化性能(基数树,优势,优化前后对比)
目录 高并发内存池 扩展 测试 大内存 介绍 代码 优化释放时需要传入空间大小 介绍 赋值 代码 加入定长内存池 引入 介绍 代码 存放映射关系的容器 锁机制 写入 读取 优化性能 引入 基数树 单级基数树 两级基数树 三级基数树 优势 引入代码 优化前后…...

Composite(组合)
1)意图 将对象组合成树型结构以表示“部分-整体”的层次结构。Composite 使得用户对单个对象和组合对象的使用具有一致性。 2)结构 组合模式的结构如图 7-33 所示。 其中: Component 为组合中的对象声明接口;在适当情况下实现所有类共有接口的默认行为;声明一个接口用于访问…...

有Bootloader,为什么还要BROM?
有Bootloader,为什么还要BROM? 不少硬件平台都提供类似Boot ROM或者PBL(高通平台)固化的一段程序,出厂后用户一定不能修改。BROM可以引导Bootloader程序。大家知道,每个可启动的平台都会在存储设备,例如EMMC/NAND/UFS保存Bootloa…...

【MATLAB代码】CV和CA模型组成的IMM(滤波方式为UKF),可复制粘贴源代码
该MATLAB代码实现了基于无迹卡尔曼滤波器(UKF)的交互式多模型(IMM)滤波算法,旨在跟踪目标在不同运动模式(匀速直线运动CV和匀速圆周运动CT)的位置和速度。订阅专栏后,直接复制粘贴代码到MATLAB空脚本中,即可运行 文章目录 运行结果源代码程序介绍1. 初始化和参数设定2…...

【网络】传输层协议TCP(下)
目录 四次挥手状态变化 流量控制 PSH标记位 URG标记位 滑动窗口 快重传 拥塞控制 延迟应答 mtu TCP异常情况 四次挥手状态变化 之前我们讲了四次挥手的具体过程以及为什么要进行四次挥手,下面是四次挥手的状态变化 那么我们下面可以来验证一下CLOSE_WAIT这…...

服务器数据恢复—EVA存储故障导致上层应用不可用的数据恢复案例
服务器存储数据恢复环境: 一台EVA某型号控制器EVA扩展柜FC磁盘。 服务器存储故障&检测: 磁盘故障导致该EVA存储中LUN不可用,导致上层应用无法正常使用。 服务器存储数据恢复过程: 1、将所有磁盘做好标记后从扩展柜中取出。硬…...

支持向量机相关证明 解的稀疏性
主要涉及拉格朗日乘子法,对偶问题求解...

静态ip和动态ip适合什么场景
静态住宅ip由于他的ip位置保持不变的,更加适合: 1、账号管理。 使用静态住宅来注册和管理社交媒体账号,例如facebook、领英等,包括电商类的账号也是可以的,例如亚马逊等 2、网站测试 很多网站会检测使用者是否为机器…...

Istio Gateway发布服务
1. Istio Gateway发布服务 在集群中部署一个 tomcat 应用程序。然后将部署一个 Gateway 资源和一个与 Gateway 绑定的 VirtualService,以便在外部 IP 地址上公开该应用程序。 1.1 部署 Gateway 资源 vim ingressgateway.yaml --- apiVersion: networking.istio.…...

前端vue3若依框架pnpm run dev启动报错
今天前端vue3若依框架pnpm run dev启动报错信息: > ruoyi3.8.8 dev D:\AYunShe\2024-11-6【无锡出门证】\wuxi-exit-permit-web > vite error when starting dev server: Error: listen EACCES: permission denied 0.0.0.0:80 at Server.setupListenHand…...

python线条爱心
效果图 代码 import math from turtle import * def hearta(k):return 15*math.sin(k)**3 def heartb(k):return 12*math.cos(k)-5*\math.cos(2*k)-2*\math.cos(3*k)-\math.cos(4*k) speed(1000) bgcolor("black") for i in range(6000):goto(hearta(i)*20,heartb(…...

GPU的内存是什么?
GPU(图形处理器)的内存是指专门用于 GPU 存储数据的内存,也被称为显存。 一、显存的作用: 1、存储图像数据 当计算机要显示图像时,显存会存储屏幕上每个像素点的颜色、亮度等信息。例如,对于一个分辨率为 1…...
)
Linux - 弯路系列1:xshell能够连接上linux,但xftp连不上(子账号可以连接,但不能上传数据)
问题如题目阐述。 注:所有操作在root账户下操作。 解决办法: 1、确认连接设置 服务器地址和端口:确保在 Xftp 中输入的服务器地址和端口号与 Xshell 使用的相同。默认情况下,SFTP 使用端口 22。 用户凭证:检查用户名…...

数组逆序重存放
题目描述 将一个数组中的值按逆序重新存放。例如,原来的顺序为8,6,5,4,1。要求改为1,4,5,6,8。 输入 输入为两行:第一行数组中元素的个数n(1<n<100),第二行是n个整数,每两个整数之间用空格分隔。 输出 输出…...

归并排序:高效算法的深度解析
一、归并排序概述 归并排序是一种基于分治思想的经典排序算法。它的核心操作分为三个主要步骤:分割、排序和合并。 首先是分割步骤,将待排序的数组不断地分成更小的子数组,直到每个子数组中只有一个元素。例如,对于一个包含多个…...
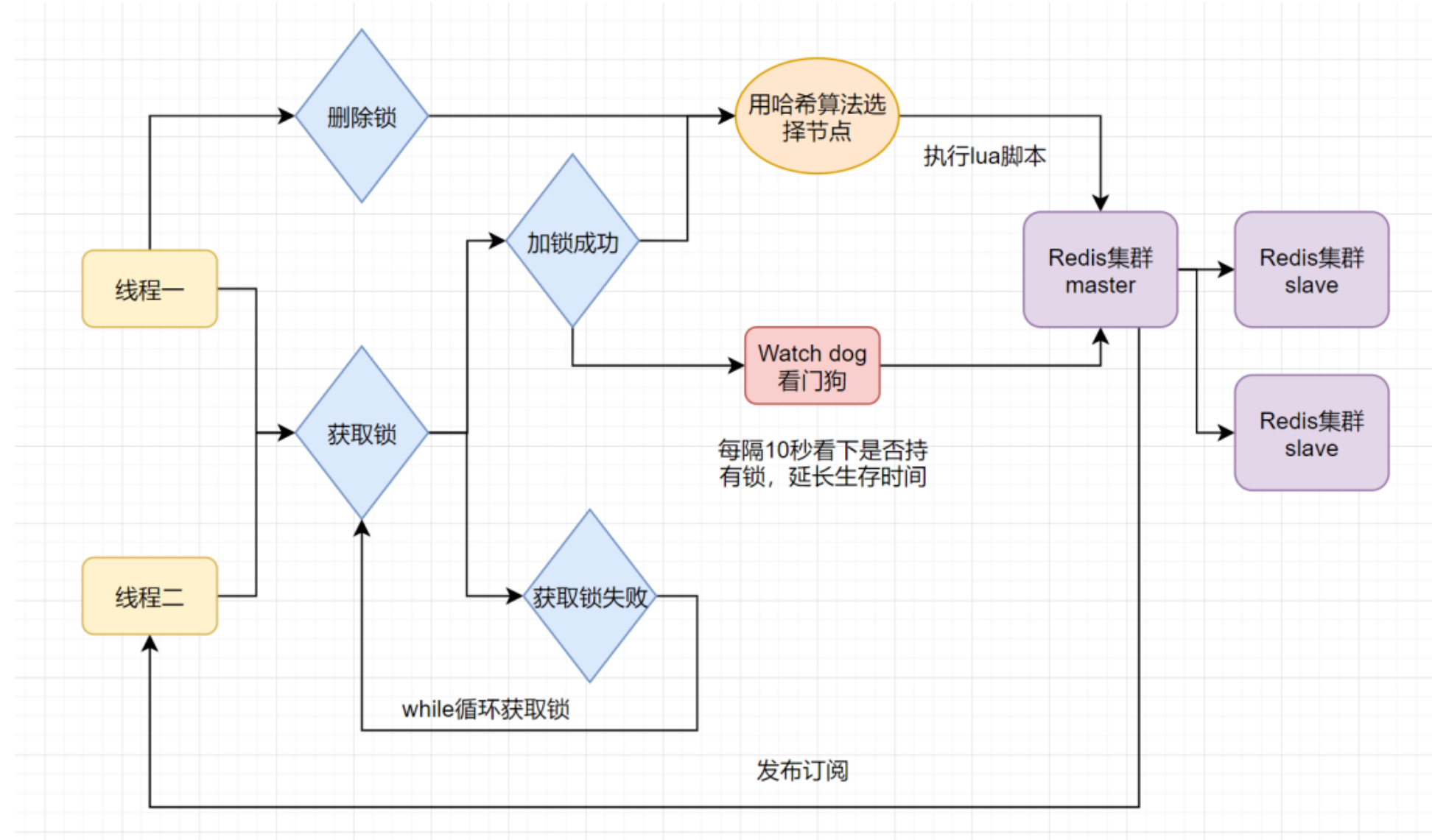
微服务中常用分布式锁原理及执行流程
1.什么是分布式锁 分布式锁是一种在分布式系统环境下实现的锁机制,它主要用于解决,多个分布式节点之间对共享资源的互斥访问问题,确保在分布式系统中,即使存在有多个不同节点上的进程或线程,同一时刻也只有一个节点可…...

声学气膜馆助力企业年会与研学活动完美呈现—轻空间
在现代企业和教育活动中,场地的选择往往决定了活动的成败。尤其是在企业年会、研学基地等重要场合,选择一个既能满足多功能需求又能快速搭建的场地至关重要。而声学气膜馆正是为这种需求量身打造的理想场所。凭借其独特的声学性能和灵活的结构设计&#…...

Halcon3D image_points_to_world_plane详解
分三个部分来聊聊这个算子 一,算子的参数介绍 二,算法的计算过程 三,举例实现 第一部分,算子的介绍 image_points_to_world_plane( : : CameraParam, WorldPose, Rows, Cols, Scale : X, Y) 参数介绍: CameraParam,:相机内参 WorldPose 世界坐标系,也叫物体坐标系(成…...

A Consistent Dual-MRC Framework for Emotion-cause Pair Extraction——论文阅读笔记
前言 这是我第一次向同学院同年级的学生和老师们汇报的第一篇论文,于2022年发表在TOIS上,属于CCF A类,主要内容是将MRC应用到情感原因对抽取中。 论文链接:用于情绪-原因对提取的一致双 MRC 框架 |信息系统上的 ACM Transactions 这里我就不放上我自己翻译的中文版还有我…...

如何debug(Eclipse)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 2分钟教会你如何Java中DeBug【IDEA中Java】 在eclipse中如何使用Debug进行调试 双击左侧打断点(取消断点同样双击) 右上角进入debug界面(常用) 选择所需断点位置(勾选右侧需要测试的断点位置) 启动…...

深度解析DDoS攻击:运作机制与防御体系构建
深度解析 DDoS 攻击:运作机制与防御体系构建适用读者:安全工程师、运维架构师、等保/合规建设人员目标:理解 DDoS 各类攻击原理,并建立分层的纵深防御体系(云端清洗 本地抗损 应用层缓释)一、DDoS 基本概…...
)
从零开始学AI Agent:软件工程视角下的企业数字化转型实践指南(收藏版)
本文从软件工程视角出发,探讨了AI Agent在企业数字化转型中的应用与构建。首先强调需求分析的重要性,指出应从业务问题出发判断Agent是否适用。接着,介绍了Agent的系统设计,包括任务编排、上下文管理、记忆存储和工具扩展四个核心…...
)
离散几何拓扑数论(终稿·全定义完整版一)
离散几何拓扑数论(终稿全定义完整版) 作者:乖乖数学 日期:2026 年 5 月 21 日 体系:离散几何拓扑数论( Discrete Geometric Topological Number Theory)...

GBase 8a数据库实际支持的索引类型详解
本文继续说明为什么列存不依赖传统 B-Tree 索引,南大通用GBase 8a数据库(gbase database) 实际使用了哪些替代机制,以及怎样在列存环境下做到真正有效的查询加速。虽然传统 B-Tree 索引在列存引擎上效果有限,GBase 8a数据库仍然支…...

智能驾驶系统场景下的自动化仿真测试评价技术【附仿真】
✨ 长期致力于智能驾驶系统、有效性评价、测试用例生成、测试场景优化、自动化仿真测试平台研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于复杂度…...

Belkin向范围3排放碳中和目标迈进
该公司发布的《2025年环境影响报告》重点介绍了其在减排、循环设计和负责任包装方面取得的持续进展 发布了《2025年环境影响报告》(2025 Impact Report),重点介绍了关键成就,并重申了其对企业社会责任的承诺。在2025年实现范围1和…...

开源 AI Agent Harness Engineering 模型与闭源模型的对比
开源 AI Agent Harness Engineering 模型与闭源模型的对比 摘要 如果把AI Agent比作自动驾驶汽车,那么AI Agent Harness就是这辆车的操作系统:它负责管控任务规划、工具调用、记忆管理、容错重试等所有核心逻辑,是Agent落地工程化的核心支撑…...

python高校学生党员信息管理系统_829h59n3
目录同行可拿货,招校园代理 ,本人源头供货商项目背景核心功能技术实现项目特点应用价值项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目背景 高校学生党员信…...

ncmdumpGUI:3分钟解锁网易云音乐NCM加密文件,让音乐自由流动
ncmdumpGUI:3分钟解锁网易云音乐NCM加密文件,让音乐自由流动 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 当智能音箱对你说"不…...

为Claude Code配置Taotoken解决密钥被封与Token不足的烦恼
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken解决密钥被封与Token不足的烦恼 应用场景类,聚焦于使用Claude Code的编程助手用户ÿ…...