操作系统个人八股文总结
1.进程和线程的区别
进程和线程的定义
- 进程:
- 进程是一个运行中的程序实例,是资源分配的基本单位。每个进程都有自己的地址空间、数据、堆栈以及其他辅助数据。
- 线程:
- 线程是进程中的一个执行单元,是CPU调度的基本单位。一个进程可以包含多个线程,多个线程共享进程的资源(如内存)。
进程和线程的主要区别
-
资源拥有:
- 进程:每个进程都有自己独立的地址空间和资源,进程之间相互独立。
- 线程:同一进程中的多个线程共享进程的资源,如内存和文件句柄。
-
执行:
- 进程:进程间的切换需要保存和加载进程的上下文,开销较大。
- 线程:线程之间切换时只需要保存和加载线程的上下文,开销较小。
-
上下文切换:
- 进程:进程之间的上下文切换速度较慢,因为涉及到更多的状态信息。
- 线程:线程之间的上下文切换速度较快,因为它们共享同一进程的资源。
-
创建和销毁开销:
- 进程:创建和销毁进程的开销较大,因为需要分配新的资源和地址空间。
- 线程:创建和销毁线程的开销较小,因为它们共享进程的资源。
进程间通信和线程间通信
-
进程间通信(IPC):
- 方式:常用的IPC方式包括管道、消息队列、共享内存和套接字等。
- 特点:由于进程之间的独立性,IPC通常比线程间通信复杂,且开销较大。
-
线程间通信:
- 方式:可以通过共享内存、条件变量、信号量以及Java中的
wait()和notify()等机制进行通信。 - 特点:由于线程共享内存,通信相对简单且高效。
- 方式:可以通过共享内存、条件变量、信号量以及Java中的
实际编程经验
在实际的多线程或多进程编程中,选择使用进程还是线程取决于具体的应用场景:
-
使用线程的场景:
- 当需要高并发处理和快速切换时,适合使用线程。例如,在Web服务器中处理多个请求时,可以使用线程池来管理多个线程,提升响应速度和资源利用率。
-
使用进程的场景:
- 当需要更高的隔离性和安全性时,适合使用进程。例如,在一个需要处理多个用户请求的应用中,可以为每个用户请求创建独立的进程,确保一个请求的崩溃不会影响其他请求。
最佳实践
- 使用线程池:在执行大量短小任务时,使用线程池可以有效管理线程的生命周期,减少开销,提升性能。
- 避免共享状态:尽量减少线程间共享数据,以避免竞争条件和死锁。可以使用
java.util.concurrent包中的工具类来管理线程安全。 - 合理使用进程:在需要高隔离性和独立性的场景下,使用进程而不是线程,如在处理用户输入时。
进程的状态
一个进程在其生命周期中可以处于多种不同的状态。主要的进程状态包括:
-
新建(New):
- 进程刚被创建,系统分配必要的资源,但还未开始执行。
- 处于此状态的进程通常正在等待被操作系统调度。
-
就绪(Ready):
- 进程已经获得了所需的资源(如内存),并准备好执行,但由于CPU正在执行其他进程,因此处于等待状态。
- 就绪状态的进程可以随时被调度到运行状态。
-
运行(Running):
- 进程正在CPU上执行指令。
- 只有一个进程处于运行状态,其他就绪进程等待调度。
-
阻塞(Blocked):
- 进程因为等待某些事件的发生而停止执行,例如等待I/O操作完成或等待某个资源的释放。
- 阻塞状态的进程无法继续执行,直到所等待的事件发生。
-
结束(Terminated):
- 进程执行完毕或被强制终止,系统释放该进程占用的资源。
- 结束状态的进程不再执行,也不再占用系统资源。
状态转换
进程在这些状态之间会进行转换,常见的转换包括:
- 新建 → 就绪:当进程创建完成并准备好执行。
- 就绪 → 运行:当调度器选择这个进程进行执行。
- 运行 → 就绪:当当前运行的进程被抢占(例如,时间片用完)。
- 运行 → 阻塞:当进程请求等待I/O或某个资源。
- 阻塞 → 就绪:当所等待的事件发生,进程重新准备好执行。
- 运行 → 结束:当进程完成执行或被终止。
2.并行和并发有什么区别
定义
-
并发(Concurrency):
- 并发是指多个任务在同一时间段内被处理,虽然它们可能不是同时执行的。并发强调的是任务的结构,允许多个任务在逻辑上交替进行,比如在多核或单核CPU上通过时间片轮转来共享CPU时间。
-
并行(Parallelism):
- 并行是指多个任务在同一时间点上同时执行。并行通常需要多个处理单元(如多核CPU)来支持任务的同时运行。并行强调的是任务的执行效率。
区别
-
实现:
- 并发:可以在单处理器系统上实现,任务通过时间分片进行切换,给人一种同时进行的错觉。
- 并行:需要多处理器或多核系统,任务在物理上同时执行。
-
性能:
- 并发:由于任务在时间上交替执行,可能会引入额外的上下文切换开销,性能提升不如并行明显。
- 并行:多个任务真正同时执行,能够充分利用系统资源,性能提升更显著。
-
应用场景:
- 并发:适用于I/O密集型任务,例如网络请求、文件读取等场景,在这些场景中,任务经常处于等待状态,适合用并发来提高资源利用率。
- 并行:适用于CPU密集型任务,例如图像处理、大规模数据计算等场景,这些任务能有效分解为多个子任务并同时处理。
-
复杂性:
- 并发:编程模型相对复杂,需要考虑任务之间的协调、共享数据的状态管理、竞争条件等问题。
- 并行:虽然也存在复杂性,但由于任务的独立性较强,往往更容易实现,尤其是在使用高层抽象(如Java的Fork/Join框架)时。
联系
- 并发与并行并不是相互排斥的,一个系统可以同时支持并发和并行。例如,一个Web服务器可以同时处理多个用户请求(并发),而在处理每个请求时,可以利用多核CPU来加速数据处理(并行)。
3.解释一下用户态和核心态
定义
-
用户态(User Mode):
- 用户态是指程序在运行时的基本状态,通常是指用户应用程序的执行环境。在用户态下,程序运行时的权限受到限制,无法直接访问硬件或系统资源。
-
核心态(Kernel Mode):
- 核心态是操作系统内核运行的状态,具有完全的访问权限,可以直接操作硬件和管理系统资源。内核态下的代码可以执行任何CPU指令。
区别
-
特权级别:
- 用户态:特权级别较低,操作系统限制应用程序的权限,以保护系统资源和其他程序。
- 核心态:特权级别较高,内核可以执行任何操作,包括直接访问硬件和管理内存。
-
系统调用:
- 从用户态切换到核心态通常通过系统调用。当应用程序需要执行特权操作(如文件操作、网络通信等)时,它会使用系统调用请求内核服务。
- 例如,在Java中,打开文件或网络连接时,会通过系统调用进入核心态。
-
安全性:
- 用户态:由于权限限制,用户态程序不能直接进行可能影响系统稳定性和安全性的操作,增加了系统的安全性。
- 核心态:内核态下的代码执行时,若出现错误或恶意代码,可能会导致整个系统崩溃,因此核心态的代码必须经过严格的控制和审查。
-
性能:
- 切换用户态和核心态的过程称为上下文切换,这个过程涉及保存和恢复CPU寄存器、堆栈和其他状态信息,通常会带来性能开销。
- 用户态代码的执行速度相对较快,因为不涉及上下文切换,而核心态代码由于特权操作的复杂性,执行时可能会较慢。
角色
-
用户态:
- 主要用于运行用户应用程序,如浏览器、文本编辑器等,提供用户友好的界面和操作。
- 程序在用户态下运行,确保了应用程序的隔离性和安全性。
-
核心态:
- 负责管理系统资源,如内存管理、进程调度和设备驱动等。
- 核心态的代码在系统启动时加载,并确保系统的稳定性和安全性。
在什么场景下,会发生内核态和用户态的切换
- 系统调用:当用户程序需要请求操作系统提供的服务时,会通过系统调用进入内核态。
- 异常:当程序执行过程中出现错误或异常情况时,CPU会自动切换到内核态,以便操作系统能够处理这些异常。
- 中断:外部设备(如键盘、鼠标、磁盘等)产生的中断信号会使CPU从用户态切换到内核态。操作系统会处理这些中断,执行相应的中断处理程序,然后再将CPU切换回用户态。
4.进程调度算法你了解多少
常见的进程调度算法
-
先来先服务(FCFS,First-Come, First-Served):
- 描述:按照进程到达就绪队列的顺序进行调度,最早到达的进程最先执行。
- 特点:
- 简单易实现。
- 可能导致“饥饿”现象(长进程可能一直等待短进程执行完)。
- 平均等待时间较长,尤其在短进程较多时。
-
短作业优先(SJF,Shortest Job First):
- 描述:选择估计运行时间最短的进程优先执行。
- 特点:
- 能够减少平均等待时间。
- 可能导致长作业的饥饿,因为短作业优先执行。
- 实现上可能需要对每个进程的运行时间进行估计。
-
轮转调度(RR,Round Robin):
- 描述:为每个进程分配一个固定时间片,时间片用完后,进程被挂起,调度器选择下一个进程。
- 特点:
- 公平性好,所有进程都有机会获得CPU。
- 适合交互式系统。
- 时间片过小可能导致频繁上下文切换,过大则可能造成响应时间变长。
-
优先级调度(Priority Scheduling):
- 描述:根据进程的优先级进行调度,优先级高的进程优先执行。
- 特点:
- 可实现不同类型的任务处理(如实时任务优先处理)。
- 可能导致低优先级进程的饥饿问题。
- 可以是非抢占式(低优先级进程不能打断高优先级进程)或抢占式(高优先级进程可以打断低优先级进程)。
-
多级队列调度(Multilevel Queue Scheduling):
- 描述:将进程分为不同的队列,每个队列有不同的调度算法(如短作业、长作业等)。
- 特点:
- 适合不同类型的进程(交互式、批处理等)。
- 可以灵活调整不同队列的优先级和调度策略。
选择适合的调度算法
在不同的应用场景下,选择适合的进程调度算法至关重要:
-
交互式系统:如桌面应用、数据库等,通常选择轮转调度(RR),因为它能够提供良好的响应时间和公平性。
-
批处理系统:如大型计算任务,选择短作业优先(SJF)或优先级调度,可以减少平均等待时间,提升整体吞吐量。
-
实时系统:如航空航天、医疗设备,通常需要使用优先级调度,确保高优先级任务能够及时响应。
-
混合系统:在需要处理多种类型任务的系统中,可以使用多级队列调度,根据任务特性选择合适的调度策略。
5.进程间有哪些通信方式
常见的进程间通信方式
-
管道(Pipe):
- 描述:管道是一种半双工通信方式,允许一个进程的输出成为另一个进程的输入。
- 特点:
- 简单易用,适合父子进程间的通信。
- 只能在具有亲缘关系的进程间使用(如父子进程)。
- 数据传输是顺序的,适合流式数据。
-
消息队列(Message Queue):
- 描述:消息队列允许进程以消息的形式进行通信,消息在队列中排队,接收进程可以按顺序读取。
- 特点:
- 支持异步通信,发送方和接收方不需要同时存在。
- 可以设置优先级,支持多种消息类型。
- 适合需要解耦的进程间通信。
-
共享内存(Shared Memory):
- 描述:多个进程可以访问同一块内存区域,通过直接读写共享内存进行数据交换。
- 特点:
- 速度快,因为数据不需要通过内核复制。
- 需要进程间的同步机制(如信号量)来避免数据竞争。
- 适合大量数据的高效传输。
-
信号(Signal):
- 描述:信号是一种异步通知机制,用于通知进程某个事件的发生。
- 特点:
- 适合发送简单的通知或控制信号(如中断)。
- 信号处理相对简单,但不适合传输复杂数据。
- 可能导致信号丢失,因此不适合关键数据传输。
-
套接字(Socket):
- 描述:套接字是一种网络通信机制,允许不同主机上的进程进行通信。
- 特点:
- 支持网络通信,适用于分布式系统。
- 可以是面向连接的(TCP)或无连接的(UDP)。
- 适合远程进程间的通信。
进程间通信的应用及使用场景
- 多任务操作系统:IPC是多任务操作系统中进程间协作的关键,能够实现数据共享、任务调度和事件通知。
- 使用场景:
- 管道:适合简单的父子进程间数据传输。
- 消息队列:适合解耦的进程间通信,如生产者-消费者模式。
- 共享内存:适合需要高效传输大量数据的场景,如图像处理。
- 信号:适合简单的事件通知,如处理用户中断。
- 套接字:适合需要跨网络的分布式应用。
进程间通信的安全问题
-
竞态条件(Race Condition):
- 描述:多个进程同时访问共享资源,导致不一致的结果。
- 避免方法:使用互斥锁、信号量等同步机制,确保在同一时间只有一个进程访问共享资源。
-
死锁(Deadlock):
- 描述:两个或多个进程相互等待对方释放资源,导致所有进程都无法继续执行。
- 避免方法:
- 避免循环等待:对资源分配进行排序,确保资源请求有序。
- 使用超时机制:设定资源请求的最大等待时间,如果超时则释放资源并重试。
-
安全性:
- 进程间通信可能被未授权的进程访问,导致数据泄露。
- 避免方法:使用权限控制、加密等手段,确保只有授权进程可以访问IPC机制。
6.解释一下进程同步和互斥,以及如何实现进程同步和互斥
定义和目的
-
进程同步(Process Synchronization):
- 定义:进程同步是指多个进程在执行过程中协调其操作,以确保共享数据的一致性。
- 目的:避免由于进程之间的执行顺序不同而导致的数据不一致或错误。
-
互斥(Mutual Exclusion):
- 定义:互斥是在同一时间内只允许一个进程访问共享资源的机制。
- 目的:防止多个进程同时访问和修改共享资源,确保数据的正确性和一致性。
区别
- 进程同步更关注于多个进程之间的协调,确保它们在某些时刻按照预定的顺序执行。
- 互斥则是一个具体的实现手段,确保在任何时刻只允许一个进程访问共享资源。
实现进程同步和互斥的方法
-
互斥锁(Mutex):
- 工作原理:
- 在访问共享资源之前,进程必须先获取互斥锁,访问完成后再释放锁。
- 如果一个进程持有锁,其他进程必须等待,直到该锁被释放。
- 适用场景:
- 用于保护对共享数据的访问,适合需要严格控制资源访问的场景。
- Java实现:可以使用
ReentrantLock类或synchronized关键字。
- 工作原理:
-
信号量(Semaphore):
- 工作原理:
- 信号量维护一个计数值,表示可用资源的数量。通过P(等待)操作减少计数值,V(信号)操作增加计数值。
- 当计数值为0时,进程会被阻塞,直到有资源可用。
- 适用场景:
- 适合控制对有限资源的访问,如限制同时访问数据库连接的进程数量。
- Java实现:可以使用
Semaphore类。
- 工作原理:
-
条件变量(Condition Variable):
- 工作原理:
- 条件变量用于在某个条件不满足时使进程等待,进程可以在某个条件满足时被唤醒。
- 适用场景:
- 用于实现生产者-消费者模型,生产者在没有空间时等待,消费者在没有产品时等待。
- Java实现:可以使用
Condition接口配合ReentrantLock。
- 工作原理:
使用示例
-
互斥锁示例:
ReentrantLock lock = new ReentrantLock();void accessSharedResource() {lock.lock(); // 获取锁try {// 访问共享资源} finally {lock.unlock(); // 释放锁} } -
信号量示例:
Semaphore semaphore = new Semaphore(3); // 允许3个进程同时访问void accessResource() {semaphore.acquire(); // 等待可用信号量try {// 访问共享资源} finally {semaphore.release(); // 释放信号量} } -
条件变量示例:
ReentrantLock lock = new ReentrantLock(); Condition condition = lock.newCondition();void producer() {lock.lock();try {// 生产数据condition.signal(); // 通知消费者} finally {lock.unlock();} }void consumer() {lock.lock();try {// 等待条件满足condition.await();// 消费数据} finally {lock.unlock();} }
7.什么是死锁,如何预防死锁?
什么是死锁?
死锁是指两个或多个线程在执行过程中,由于争夺资源而造成的一种互相等待的状态。此时,所有参与的线程都无法继续执行,导致程序陷入无穷等待。
死锁的危害
- 系统停滞:死锁会导致系统资源的浪费,影响程序的正常运行。
- 性能下降:系统中有死锁的线程会阻塞其他线程,可能导致整个系统性能下降。
- 复杂性增加:死锁的调试和恢复相对复杂,增加了系统维护的难度。
死锁的四个必要条件
为了发生死锁,必须同时满足以下四个条件:
- 互斥条件:至少有一个资源必须被一个线程持有,且该资源不能被其他线程使用。
- 保持并等待条件:一个线程持有至少一个资源,同时又请求其他资源。
- 不抢占条件:已分配给线程的资源在未使用完之前,不能被其他线程强制抢占。
- 循环等待条件:存在一个线程的集合 {T1, T2, ..., Tn},其中 T1 等待 T2 持有的资源,T2 等待 T3 持有的资源,...,Tn 又等待 T1 持有的资源,形成一个循环等待。
死锁的预防策略
-
资源分配策略:
- 避免循环等待:定义一个资源的请求顺序,确保线程请求资源时遵循这个顺序,这样可以避免形成循环等待。
- 请求资源时一次性分配:线程在请求资源时,一次性请求所需的所有资源,避免在持有资源的情况下再请求其他资源。
-
资源抢占:
- 在某些情况下,可以允许线程抢占其他线程持有的资源,以打破死锁条件。
-
时间限制:
- 为资源请求设置时间限制,如果请求超时,则释放已持有的资源,并重新尝试。
死锁检测和恢复机制
-
死锁检测:
- 定期检查系统状态,检测是否存在死锁。可以使用资源分配图的方式,构建一个图,分析是否存在循环等待的情况。
- 采用算法(如银行家算法)来检测资源的分配情况。
-
恢复机制:
- 杀死线程:选择一个或多个线程进行强制终止,以释放资源。
- 撤回资源:通过撤回某个线程已持有的资源,允许其他线程继续执行,从而打破死锁。
案例与并发编程讨论
考虑以下简单的例子,展示如何在并发编程中防止死锁:
class Resource {private final String name;public Resource(String name) {this.name = name;}public String getName() {return name;}
}class Task implements Runnable {private Resource resource1;private Resource resource2;public Task(Resource resource1, Resource resource2) {this.resource1 = resource1;this.resource2 = resource2;}@Overridepublic void run() {synchronized (resource1) {System.out.println(Thread.currentThread().getName() + " acquired " + resource1.getName());// Simulate some worktry { Thread.sleep(100); } catch (InterruptedException e) {}synchronized (resource2) {System.out.println(Thread.currentThread().getName() + " acquired " + resource2.getName());}}}
}// 主程序
public class DeadlockExample {public static void main(String[] args) {Resource resourceA = new Resource("ResourceA");Resource resourceB = new Resource("ResourceB");Thread thread1 = new Thread(new Task(resourceA, resourceB), "Thread1");Thread thread2 = new Thread(new Task(resourceB, resourceA), "Thread2");thread1.start();thread2.start();}
}
在这个例子中,Thread1 和 Thread2 可能会导致死锁,因为一个线程持有 ResourceA,另一个线程持有 ResourceB,并且各自等待对方释放资源。
预防措施
- 避免循环等待:确保所有线程按照相同的顺序请求资源。例如,始终先请求
ResourceA,再请求ResourceB。
8.介绍一下几种典型的锁
1. 典型的锁及其基本概念
a. 互斥锁(Mutex)
- 概念:互斥锁是最基本的锁机制,确保在同一时间只有一个线程可以访问共享资源。
- 用途:用于保护临界区,以防止多个线程同时访问和修改共享数据。
b. 可重入锁(Reentrant Lock)
- 概念:可重入锁是继承自互斥锁的一种特殊锁,允许同一线程多次获得同一把锁,而不会导致死锁。
- 用途:适合需要递归调用或复杂锁定逻辑的场景。
c. 读写锁(ReadWrite Lock)
- 概念:读写锁允许多个线程同时读取共享资源,但在写入时会独占锁,只有一个线程可以进行写操作。
- 用途:适合读操作多于写操作的场景,可以提高系统的并发性能。
d. 乐观锁(Optimistic Lock)
- 概念:乐观锁假设在操作过程中不会发生冲突,因此不在操作前加锁,而是通过版本号或时间戳进行检查。
- 用途:适合读多写少的场景,减少锁竞争。
e. 悲观锁(Pessimistic Lock)
- 概念:悲观锁在访问共享资源时假设会发生冲突,因此在操作前立即加锁。
- 用途:适合写操作频繁的场景,确保数据一致性。
2. 不同锁机制的适用场景和优缺点
a. 互斥锁
- 适用场景:简单的共享数据保护。
- 优点:实现简单,易于理解。
- 缺点:可能导致线程饥饿和性能瓶颈。
b. 可重入锁
- 适用场景:需要递归调用或者复杂的锁逻辑。
- 优点:避免死锁,提高安全性。
- 缺点:相对开销较大,性能下降。
c. 读写锁
- 适用场景:读操作远多于写操作的系统。
- 优点:提高并发性,允许多个读者同时访问。
- 缺点:写操作时会阻塞所有读者,写入性能下降。
d. 乐观锁
- 适用场景:读多写少的场景。
- 优点:减少锁的竞争,提高性能。
- 缺点:在高冲突时性能下降,可能需要重试。
e. 悲观锁
- 适用场景:写操作频繁的场景。
- 优点:确保数据一致性。
- 缺点:降低并发性,可能导致性能瓶颈。
3. 如何选择合适的锁机制
- 访问模式:如果是读多写少,优先考虑读写锁;如果是写多,可以使用悲观锁。
- 性能需求:对于高并发场景,乐观锁或读写锁更适合,减少锁的竞争。
- 复杂性:如果业务逻辑复杂,可能需要使用可重入锁来避免死锁。
4. 锁机制对性能的影响与优化
- 锁竞争:多个线程争用同一把锁会导致性能下降,可以通过减少锁的持有时间和锁的粒度来优化。
- 锁的划分:将大锁拆分为多个小锁,减少竞争。
- 使用无锁数据结构:在某些情况下,使用无锁数据结构(如
ConcurrentHashMap)可以避免锁的开销。
自旋锁的基本概念
- 概念:自旋锁是一种非阻塞锁,当一个线程试图获取锁时,如果锁已经被其他线程持有,它不会立即进入休眠状态,而是会在一个循环中反复检查锁的状态(即“自旋”),直到获取到锁为止。
- 用途:自旋锁适用于锁持有时间非常短的场景,因为它避免了线程上下文切换的开销。
自旋锁的优缺点
优点
- 低开销:在锁持有时间短时,自旋锁比传统的阻塞锁更高效,因为它避免了线程的上下文切换。
- 简单实现:自旋锁的实现相对简单,通常只需要一个标志位和一个循环。
缺点
- 忙等待:自旋锁会导致CPU资源的浪费,因为在等待锁的同时,线程仍在占用CPU资源。
- 不适合长时间锁:如果锁持有时间较长,自旋锁会导致性能下降,适合轻量级的锁定场景。
9.讲一讲你理解的虚拟内存
1. 虚拟内存的定义
虚拟内存是一种内存管理方式,允许程序使用比物理内存更大的地址空间。它通过将物理内存和磁盘空间结合起来提供一个连续的、逻辑上的内存地址空间,给用户和程序一种“每个程序都有自己的内存”的幻觉。
工作原理
- 地址映射:虚拟内存将程序使用的虚拟地址映射到物理内存地址。操作系统维护一个页面表,将虚拟地址转换为物理地址。
- 分页:虚拟内存将内存划分为固定大小的块,称为“页面”(通常是4KB)。物理内存也被划分成同样大小的“页框”。程序在运行时,只需加载所需的页面到物理内存中。
- 按需加载:当程序访问某个页面时,如果该页面不在物理内存中,操作系统会触发“缺页异常”,然后从磁盘读取该页面并加载到物理内存中。
2. 页置换算法
当物理内存已满且需要加载新的页面时,操作系统会使用页置换算法来决定哪一个页面被替换出去。常见的页置换算法包括:
a. 最近最少使用(LRU)
- 描述:替换掉最近最少使用的页面。
- 优点:通常能够提供较好的性能,因为它基于实际使用情况。
b. 先进先出(FIFO)
- 描述:按照页面进入内存的顺序进行替换。
- 优点:实现简单。
- 缺点:可能会替换掉仍然被频繁使用的页面(即“Belady's Anomaly”)。
c. 最不久使用(OPT)
- 描述:理论上最优的算法,总是替换在未来最久不被使用的页面。
- 优点:提供最好的性能,但不可实现,因为需要预测未来的访问模式。
d. 随机置换
- 描述:随机选择一个页面进行替换。
- 优点:实现简单,避免了复杂的策略。
- 缺点:性能不稳定。
3. 虚拟内存的优点
- 扩展性:程序可以使用大于物理内存的地址空间,支持更大的应用程序运行。
- 内存保护:每个进程都有自己的虚拟地址空间,避免了进程间的相互干扰,提高了安全性。
- 简化内存管理:程序员不需要直接管理物理内存,简化了开发过程。
4. 可能带来的性能问题
- 缺页异常:频繁的缺页异常会导致性能下降,因为每次缺页都需要进行磁盘I/O操作,速度远低于内存访问。
- 页面抖动:当程序不断地加载和释放页面时,可能导致大量的页面在物理内存和磁盘之间频繁切换,造成系统资源的浪费和性能下降。
- 内存碎片:虽然虚拟内存可以减少外部碎片,但在内存的使用过程中,依然可能存在内部碎片。
10.你知道的线程同步的方式有哪些?
定义和目的
-
进程同步(Process Synchronization):
- 定义:进程同步是指多个线程在执行过程中协调其操作,以确保共享数据的一致性。
- 目的:避免由于进程之间的执行顺序不同而导致的数据不一致或错误。
-
互斥(Mutual Exclusion):
- 定义:互斥是在同一时间内只允许一个进程访问共享资源的机制。
- 目的:防止多个进程同时访问和修改共享资源,确保数据的正确性和一致性。
区别
- 进程同步更关注于多个进程之间的协调,确保它们在某些时刻按照预定的顺序执行。
- 互斥则是一个具体的实现手段,确保在任何时刻只允许一个进程访问共享资源。
1. 互斥锁(Mutex)
基本概念
互斥锁是一种最基本的线程同步机制,确保在同一时刻只有一个线程可以访问共享资源。通常通过 synchronized 关键字或 ReentrantLock 类实现。
用途
用于保护临界区,防止多个线程同时修改共享数据。
适用场景
适合简单的共享数据访问,如对一个共享变量的增减操作。
优缺点
- 优点:实现简单,易于使用。
- 缺点:可能导致线程饥饿和性能瓶颈,特别是在高竞争情况下。
2. 自旋锁(Spin Lock)
基本概念
自旋锁是一种轻量级锁,当一个线程尝试获取锁时,如果锁已经被其他线程持有,它会在一个循环中反复检查锁的状态,而不是进入休眠。
用途
适用于锁持有时间短的场景,避免线程上下文切换的开销。
适用场景
多核处理器环境中,短时间的锁定需求。
优缺点
- 优点:在短时间内比传统的阻塞锁更高效。
- 缺点:如果锁持有时间较长,会导致CPU资源的浪费。
3. 读写锁(ReadWrite Lock)
基本概念
读写锁允许多个线程同时读取共享资源,但在写入时会独占锁。可以使用 ReentrantReadWriteLock 来实现。
用途
适用于读操作远多于写操作的场景,可以提高并发性能。
适用场景
数据库系统或缓存系统,读多写少的情况。
优缺点
- 优点:提高并发性,允许多个读者同时访问。
- 缺点:写操作时会阻塞所有读者,写性能可能下降。
4. 条件变量(Condition Variable)
基本概念
条件变量是一种用于线程间通信的机制,允许线程在某种条件下等待或被通知。Java 中可以通过 Object 类的 wait()、notify() 和 notifyAll() 方法实现。
用途
用于在某个条件满足之前,让线程挂起;当条件满足时,通知等待的线程继续执行。
适用场景
生产者-消费者模型、任务调度等场景。
优缺点
- 优点:灵活,可以实现复杂的线程间协调。
- 缺点:实现复杂,容易出现死锁或遗漏通知的问题。
5. 信号量(Semaphore)
基本概念
信号量是一种计数器,用于控制对共享资源的访问。Java 中可以使用 Semaphore 类来实现。
用途
用于限制对特定资源的访问数量,适合管理有限的资源。
适用场景
连接池、线程池等场景,控制并发访问的数量。
优缺点
- 优点:灵活,能够控制多个线程的访问。
- 缺点:实现复杂,可能导致资源浪费或线程饥饿。
选择合适的线程同步机制
在选择合适的线程同步机制时,可以考虑以下因素:
- 访问模式:如果是读多写少,可以使用读写锁;如果是写多,可以使用互斥锁。
- 锁持有时间:锁持有时间短的情况适合使用自旋锁。
- 复杂性:如果需要复杂的线程间通信,可以考虑使用条件变量。
- 资源管理:如果需要控制对资源的并发访问数量,可以使用信号量。
11.有哪些页面置换算法
1. 最近最少使用(Least Recently Used, LRU)
工作原理
LRU算法通过追踪每个页面被使用的时间,选择最近最久未被使用的页面进行替换。可以使用链表或队列等数据结构来实现。
适用场景
适合访问模式具有局部性原则的场景,即程序经常重复访问相同的数据或代码。
特点
- 优点:通常能提供较好的性能,因为它基于实际使用情况。
- 缺点:实现复杂,需要额外的存储来跟踪页面的使用情况,且在高负载时可能导致性能下降。
2. 先进先出(First-In, First-Out, FIFO)
工作原理
FIFO算法简单地维护一个页面队列,按照页面进入内存的顺序进行替换。最先进入的页面最先被替换。
适用场景
适合实现简单、对性能要求不高的系统。
特点
- 优点:实现简单,易于理解。
- 缺点:可能会替换掉仍然被频繁使用的页面,导致性能下降(即“Belady's Anomaly”)。
3. 最不久使用(Optimal Page Replacement, OPT)
工作原理
OPT算法在进行页面替换时,选择未来最长时间不被使用的页面进行替换。虽然它提供了最好的性能,但不可实现,因为需要预测未来的页面访问情况。
适用场景
用于理论分析和比较其他页面置换算法的性能。
特点
- 优点:在理论上提供最好的性能。
- 缺点:不可实现,实际应用中无法预测未来的访问模式。
4. 随机置换(Random Replacement)
工作原理
随机置换算法在需要替换页面时,随机选择一个页面进行替换,不考虑页面的使用情况。
适用场景
适用于对性能要求不高的系统,或者当实现简单性比性能更重要时。
特点
- 优点:实现简单,易于编程。
- 缺点:性能不稳定,可能不适合所有访问模式。
5. 计数器置换(Least Frequently Used, LFU)
工作原理
LFU算法维护一个计数器,记录每个页面被访问的次数。在需要替换页面时,选择访问次数最少的页面进行替换。
适用场景
适合访问模式中某些页面被频繁使用,而其他页面几乎不被访问的情况。
特点
- 优点:能很好的适应长期不再使用的页面。
- 缺点:实现复杂,需要额外的存储来维护计数器,可能导致频繁更新。
11.熟悉哪些Linux命令
1. 文件操作
-
ls:列出目录中的文件和子目录。- 用法:
ls -l(详细信息),ls -a(包括隐藏文件)。
- 用法:
-
cp:复制文件或目录。- 用法:
cp source.txt destination.txt(复制文件),cp -r src_dir/ dest_dir/(递归复制目录)。
- 用法:
-
mv:移动或重命名文件或目录。- 用法:
mv old_name.txt new_name.txt(重命名文件),mv file.txt /path/to/destination/(移动文件)。
- 用法:
-
rm:删除文件或目录。- 用法:
rm file.txt(删除文件),rm -r dir_name/(递归删除目录)。
- 用法:
2. 文件内容查看
-
cat:查看文件内容。- 用法:
cat file.txt(显示文件内容)。
- 用法:
-
more和less:分页显示文件内容。- 用法:
more file.txt,less file.txt(less支持向前和向后翻页)。
- 用法:
-
head:查看文件的前几行。- 用法:
head -n 10 file.txt(显示前10行)。
- 用法:
-
tail:查看文件的后几行。- 用法:
tail -n 10 file.txt(显示后10行),tail -f file.txt(实时跟踪文件增长)。
- 用法:
3. 权限管理
-
chmod:修改文件或目录的权限。- 用法:
chmod 755 file.txt(设置权限为rwxr-xr-x)。
- 用法:
-
chown:更改文件或目录的所有者。- 用法:
chown user:group file.txt(更改所有者和组)。
- 用法:
-
chgrp:更改文件或目录的组。- 用法:
chgrp group_name file.txt(更改文件的组)。
- 用法:
4. 网络管理
-
ping:测试网络连接。- 用法:
ping www.example.com(测试到指定主机的连通性)。
- 用法:
-
ifconfig或ip:查看和配置网络接口。- 用法:
ifconfig(查看网络接口信息),ip addr show(显示IP地址)。
- 用法:
-
netstat:查看网络连接和监听端口。- 用法:
netstat -tuln(查看所有监听的TCP和UDP端口)。
- 用法:
-
curl:与URL进行数据传输。- 用法:
curl http://www.example.com(获取网页内容)。
- 用法:
5. 进程管理
-
ps:查看当前运行的进程。- 用法:
ps aux(显示所有用户的进程)。
- 用法:
-
top:实时显示系统进程和资源使用情况。- 用法:直接输入
top,按q退出。
- 用法:直接输入
-
kill:终止进程。- 用法:
kill PID(使用进程ID终止进程),kill -9 PID(强制终止)。
- 用法:
-
htop:更友好的进程查看工具(需额外安装)。- 用法:直接输入
htop,按q退出。
- 用法:直接输入
6. 磁盘管理
-
df:查看文件系统的磁盘空间使用情况。- 用法:
df -h(以人类可读的格式显示)。
- 用法:
-
du:查看目录和文件的磁盘使用情况。- 用法:
du -sh /path/to/dir(显示目录的总大小)。
- 用法:
-
mount:挂载文件系统。- 用法:
mount /dev/sdX /mnt(将设备挂载到指定目录)。
- 用法:
-
umount:卸载文件系统。- 用法:
umount /mnt(卸载指定目录)。
- 用法:
7. 软件包管理
-
apt(Debian/Ubuntu系列):- 更新软件包列表:
sudo apt update - 安装软件:
sudo apt install package_name - 卸载软件:
sudo apt remove package_name
- 更新软件包列表:
-
yum(CentOS/RHEL系列):- 更新软件包列表:
sudo yum check-update - 安装软件:
sudo yum install package_name - 卸载软件:
sudo yum remove package_name
- 更新软件包列表:
12.Linux中如何查看一个进程,如何杀死一个进程,如何查看某个端口有没有被占用
1. 查看一个进程
要查看当前系统中运行的进程,我们通常使用 ps 命令或 top 命令。
使用 ps 命令
-
基本命令:
ps auxa:显示所有用户的进程。u:以用户格式显示进程信息。x:显示没有控制终端的进程。
-
查找特定进程:
如果你想查找名为java的进程,可以使用:ps aux | grep java
使用 top 命令
- 命令:
top- 这个命令会实时显示系统中的进程,按 CPU 和内存使用情况排序。
- 按
q可以退出。
2. 杀死一个进程
一旦找到了特定进程的 PID(进程ID),可以使用 kill 命令终止它。
-
基本用法:
kill <PID>- 例如,终止进程ID为 1234 的进程:
kill 1234 -
强制终止进程:
如果进程不响应,可以使用-9选项强制终止:kill -9 <PID>- 例如:
kill -9 1234
3. 查看某个端口是否被占用
要检查某个端口是否被占用,可以使用 netstat、lsof 或 ss 命令。
使用 netstat 命令
-
检查端口:
netstat -tuln | grep :<端口号>- 例如,检查端口8080
netstat -tuln | grep :8080 -
输出结果解释:
- 如果有输出,表示该端口正在被某个进程占用,状态通常是
LISTEN。 - 如果没有输出,说明该端口未被占用。
- 如果有输出,表示该端口正在被某个进程占用,状态通常是
使用 lsof 命令
-
命令:
lsof -i :<端口号>- 例如,检查8080端口:
lsof -i :8080 -
输出结果解释:
- 输出将显示使用该端口的进程及其 PID。如果有输出,表示该端口被占用。
使用 ss 命令
-
命令:
ss -tuln | grep :<端口号>- 例如,检查8080端口:
ss -tuln | grep :8080 -
输出结果解释:
- 与
netstat类似,输出显示监听状态的端口。如果有输出,表示该端口被占用。
- 与
网络问题排查案例
假设你在开发一个Java应用时,遇到“端口被占用”的错误,使用8080端口进行测试。可以按照以下步骤进行排查:
-
检查端口占用:
使用netstat -tuln | grep :8080检查8090端口是否被占用。 -
分析输出:
- 如果输出显示该端口在监听,使用
lsof -i :8080找到占用该端口的进程ID。
- 如果输出显示该端口在监听,使用
-
终止占用进程:
找到对应的 PID 后,使用kill <PID>或kill -9 <PID>终止它。 -
重新启动应用:
终止占用的进程后,重新启动你的Java应用,检查是否能够正常启动。
13.介绍一下io多路复用
什么是I/O多路复用?
I/O多路复用 是一种在单个线程中同时管理多个I/O操作的技术。它允许程序在等待某些I/O操作(如网络请求、文件读取等)时,不必阻塞线程,而是可以同时监控多个I/O通道的状态,从而提高应用程序的效率。
工作原理
I/O多路复用的核心思想是通过一个或多个系统调用,监视多个I/O流的状态。当其中一个或多个I/O流准备好进行读写操作时,操作系统会通知应用程序,从而避免了线程的频繁创建和销毁。
常用的I/O多路复用机制
在Linux系统中,常见的I/O多路复用机制包括:
-
select:
- 一个较早的多路复用机制,使用一个固定大小的文件描述符集合来监视I/O状态。
- 最大文件描述符数量通常受限(如1024),在高并发场景中性能较低。
-
poll:
- 类似于select,但没有最大文件描述符数量的限制,使用动态数组。
- 仍然需要遍历整个数组来检查状态,性能在高并发场景下不如epoll。
-
epoll:
- Linux特有的高效多路复用机制,设计用于解决select和poll在高并发情况下的性能问题。
- 使用事件驱动模型,内核和用户空间可以高效地进行交互,适合大量连接的场景。
优缺点
优点
- 提高效率:通过在单个线程中管理多个I/O操作,减少了线程上下文切换的开销。
- 节省资源:减少了系统对线程和进程的需求,降低了内存和CPU的使用。
- 响应性:能及时响应I/O事件,适用于高并发场景。
缺点
- 复杂性:编程模型较为复杂,需要处理状态管理、事件驱动模型等。
- 平台依赖性:不同操作系统的多路复用实现可能有所不同,移植性差。
在Java中的实现
在Java中,I/O多路复用通常通过 NIO(Non-blocking I/O)包实现。Java NIO提供了以下核心组件:
-
Selector:
- 用于监视多个Channel(通道)的事件,支持非阻塞I/O操作。
-
Channel:
- 表示一个可以进行I/O操作的对象,支持读写数据。
-
Buffer:
- 用于在Channel和应用程序之间传输数据,数据在Buffer中存储。
示例代码
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;public class NioExample {public static void main(String[] args) throws IOException {Selector selector = Selector.open();ServerSocketChannel serverChannel = ServerSocketChannel.open();serverChannel.bind(new InetSocketAddress(8080));serverChannel.configureBlocking(false);serverChannel.register(selector, serverChannel.validOps());while (true) {selector.select(); // 阻塞直到有事件发生// 处理就绪的事件for (var key : selector.selectedKeys()) {if (key.isAcceptable()) {SocketChannel clientChannel = serverChannel.accept();clientChannel.configureBlocking(false);clientChannel.register(selector, clientChannel.validOps());} else if (key.isReadable()) {// 读取数据SocketChannel clientChannel = (SocketChannel) key.channel();ByteBuffer buffer = ByteBuffer.allocate(256);clientChannel.read(buffer);// 处理数据...}}selector.selectedKeys().clear(); // 清除已处理的事件}}
}14.说一下 select、poll、epoll
1. 定义和工作原理
1.1 select
-
定义:
select是一种 I/O 多路复用机制,用于监视多个文件描述符(如套接字)的状态,以便在某些文件描述符变为可读、可写或发生异常时进行处理。 -
工作原理:
- 使用一个固定大小的文件描述符集合。
- 调用
select()时,将需要监视的文件描述符添加到集合中。 - 阻塞调用,直到其中至少一个文件描述符准备好进行操作(可读、可写)。
- 返回后,程序需要遍历文件描述符集合,检查哪些描述符发生了事件。
1.2 poll
-
定义:
poll是另一种 I/O 多路复用机制,类似于select,但它支持更多的文件描述符,并且没有select的固定大小限制。 -
工作原理:
poll()使用一个数组来描述需要监视的文件描述符。- 不同于
select的集合,poll的数组大小是动态的,程序可以任意添加文件描述符。 - 阻塞调用,直到至少一个文件描述符准备好进行操作。
- 返回后,程序需要遍历返回的数组,检查哪些描述符发生了事件。
1.3 epoll
-
定义:
epoll是 Linux 特有的高效 I/O 多路复用机制,旨在解决select和poll在高并发场景下的性能问题。 -
工作原理:
epoll通过内核与用户空间的交互来监视文件描述符。- 使用
epoll_create()创建一个 epoll 实例,然后将需要监视的文件描述符添加到 epoll 实例中。 - 使用
epoll_wait()阻塞调用,等待事件的发生。 - 当有事件发生时,内核会将就绪的文件描述符的状态通知用户空间,避免了遍历所有文件描述符的开销。
2. 应用与区别
| 特性 | select | poll | epoll |
|---|---|---|---|
| 最大文件描述符数量 | 通常为 1024(受限于 FD_SETSIZE) | 受限于系统内存 | 理论上无限(受限于系统内存) |
| 数据结构 | 集合(固定大小) | 数组(动态大小) | 红黑树和事件数组 |
| 效率 | 随着文件描述符数量增加,效率降低 | 随着文件描述符数量增加,效率降低 | 高效,适合大量连接 |
| 适用场景 | 适合少量连接的场景 | 适合中等连接数的场景 | 适合高并发、大量连接的场景 |
3. 各自的限制和适用场景
-
select:
- 限制:最大文件描述符数量受限(通常为1024),且随着连接数的增加,遍历集合的开销增加。
- 适用场景:适合小规模的应用,如简单的网络服务。
-
poll:
- 限制:虽然没有最大文件描述符数量的限制,但仍需遍历整个数组,性能在高并发情境下会下降。
- 适用场景:适合中等规模的应用,如中小型的服务器。
-
epoll:
- 限制:仅在 Linux 下可用,且需要较新的内核版本。
- 适用场景:适合高并发、大量连接的应用,如高性能的网络服务器(如 Nginx、Apache)。
-
Linux 的 IO 多路复用用三种实现:select、poll、epoll。select 的问题是:
-
a)调用 select 时会陷入内核,这时需要将参数中的 fd_set 从用户空间拷贝到内核空间,高并发场景下这样的拷贝会消耗极大资源;(epoll 优化为不拷贝)
b)进程被唤醒后,不知道哪些连接已就绪即收到了数据,需要遍历传递进来的所有 fd_set 的每一位,不管它们是否就绪;(epoll 优化为异步事件通知)
c)select 只返回就绪文件的个数,具体哪个文件可读还需要遍历;(epoll 优化为只返回就绪的文件描述符,无需做无效的遍历)
d)同时能够监听的文件描述符数量太少,是 1024 或 2048;(poll 基于链表结构解决了长度限制)
-
poll 只是基于链表的结构解决了最大文件描述符限制的问题,其他 select 性能差的问题依然没有解决;终极的解决方案是 epoll,解决了 select 的前三个缺点;
-
epoll 的实现原理看起来很复杂,其实很简单,注意两个回调函数的使用:数据到达 socket 的等待队列时,通过回调函数 ep_poll_callback 找到 eventpoll 对象中红黑树的 epitem 节点,并将其加入就绪列队 rdllist,然后通过回调函数 default_wake_function 唤醒用户进程 ,并将 rdllist 传递给用户进程,让用户进程准确读取就绪的 socket 的数据。这种回调机制能够定向准确的通知程序要处理的事件,而不需要每次都循环遍历检查数据是否到达以及数据该由哪个进程处理,日常开发中可以学习借鉴下这种思想。
相关文章:

操作系统个人八股文总结
1.进程和线程的区别 进程和线程的定义 进程: 进程是一个运行中的程序实例,是资源分配的基本单位。每个进程都有自己的地址空间、数据、堆栈以及其他辅助数据。线程: 线程是进程中的一个执行单元,是CPU调度的基本单位。一个进程可…...
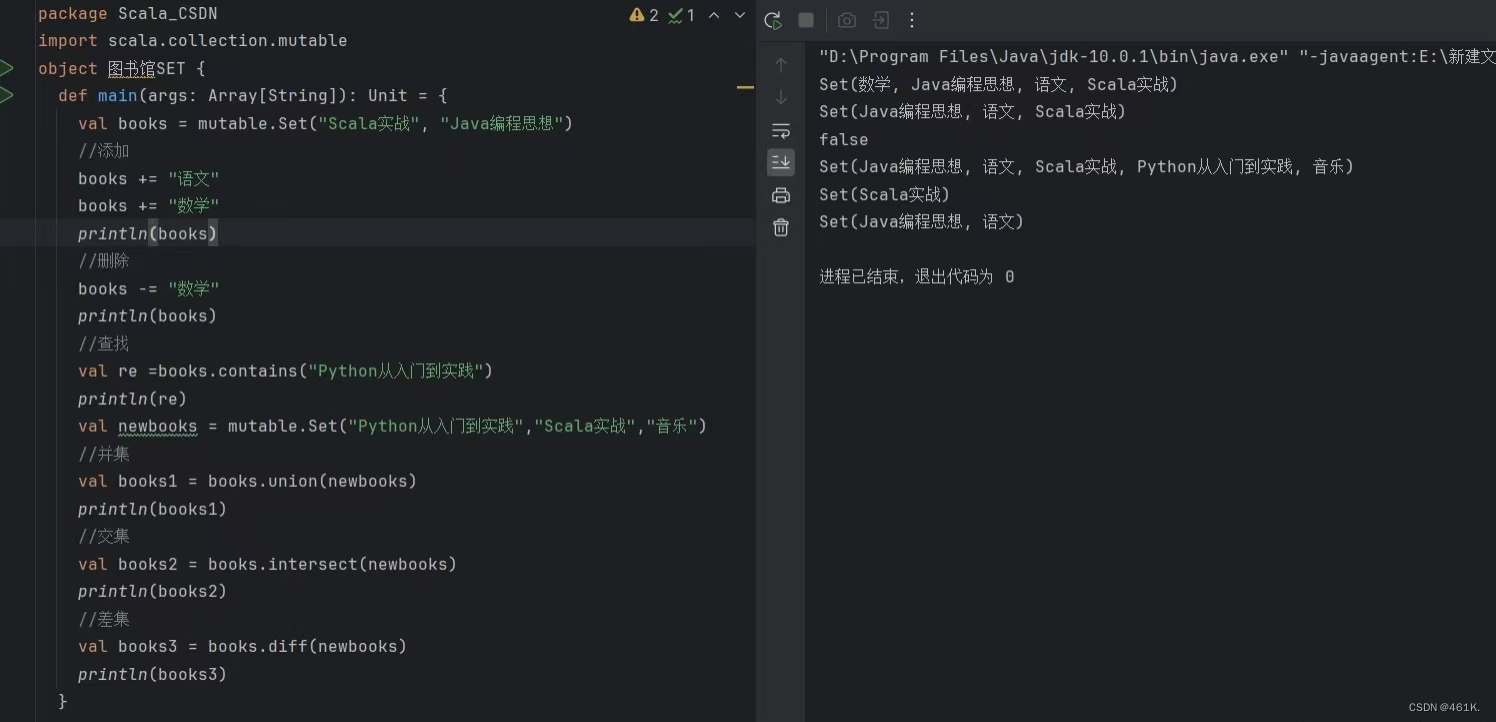
scala set训练
Set实训内容: 1.创建一个可变Set,用于存储图书馆中的书籍信息(假设书籍信息用字符串表示),初始化为包含几本你喜欢的书籍 2.添加两本新的书籍到图书馆集合中,使用操作符 3.删除一本图书馆集合中的书籍&…...

【d63】【Java】【力扣】141.训练计划III
思路 使用递归实现 出口 ,遇到null 每一层要做:把下层放进去,把本层放下去 代码 /*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode() {}* ListNode(int val) { …...

【Linux】- 权限(2)
接上一篇文章,继续介绍linux权限的相关知识。https://blog.csdn.net/hffh123/article/details/143432940?spm1001.2014.3001.5501j 目录 一、chown:修改文件的拥有者 二、chgrp:修改文件所属组 三、关于other的介绍 四、文件类型 1、分类…...

如何设置内网IP的端口映射到公网
在现代网络环境中,端口映射(Port Mapping)是一项非常实用的技术,它允许用户将内网设备的服务端口映射到公网,使外网用户可以访问内网中的服务。这项技术在远程办公、设备远程控制、游戏服务器、家庭监控等场景中得到了…...

Matplotlib | 条形图中的每个条形(patch)设置标签数据的方法
方法一 不使用子图对象如何给形图中的每个条形设置数据 plt.figure(figsize(8, 4)) sns.countplot(xWorkout_Frequency (days/week), datadf)plt.title(会员每周锻炼频率分布) plt.xlabel(锻炼频率 (每周次数)) plt.ylabel(人数)# 获取当前活动的轴对象 ax plt.gca()# 循环遍…...
机器学习3_支持向量机_线性不可分——MOOC
线性不可分的情况 如果训练样本是线性不可分的,那么上一节问题的是无解的,即不存在 和 满足上面所有N个限制条件。 对于线性不可分的情况,需要适当放松限制条件,使得问题有解。 放松限制条件的基本思路: 对每个训…...

bash: git: command not found
在windows上重新安装Git之后,遇到cmd可以使用git命令,但是git bash中使用的git命令的时候,会提示: $ git bash: git: command not found 解决办法 找到用户目录下的.bash_profile和.bashrc文件,编辑打开,找…...

大模型LLama3!!!Ollama下载、部署和应用(保姆级详细教程)
首先呢,大家在网站先下载ollama软件 这就和anaconda和python是一样的 废话不多说 直接上链接:Download Ollama on Windows 三个系统都支持 注意: 这里的Models,就是在上面,大家点开之后,里面有很多模型…...

ReactPress系列—NestJS 服务端开发流程简介
ReactPress Github项目地址:https://github.com/fecommunity/reactpress 欢迎提出宝贵的建议,感谢Star。 NestJS 服务端开发流程简介 NestJS 是一个用于构建高效、可靠和可扩展的服务器端应用程序的框架。它使用 TypeScript(但也支持纯 Java…...

Maven 下载配置 详解 我的学习笔记
Maven 下载配置 详解 我的学习笔记 一、Maven 简介二、maven安装配置三、maven基本使用四、idea配置mavenidea配置maven环境maven坐标idea创建maven项目配置Maven-Helper插件 五、依赖管理 一、Maven 简介 Apache Maven 是一个项目管理和构建工具,它基于项目对象模型…...

【学术精选】SCI期刊《Electronics》特刊“New Challenges in Remote Sensing Image Processing“
英文名称:New Challenges in Remote Sensing Image Processing 中文名称:"遥感图像处理的新挑战"特刊 期刊介绍 “New Challenges in Remote Sensing Image Processing”特刊隶属于《Electronics》期刊,聚焦遥感图像处理领域快速…...

卷积神经网络——pytorch与paddle实现卷积神经网络
卷积神经网络——pytorch与paddle实现卷积神经网络 本文将深入探讨卷积神经网络的理论基础,并通过PyTorch和PaddlePaddle两个深度学习框架来展示如何实现卷积神经网络模型。我们将首先介绍卷积神经网络、图像处理的基本概念,这些理论基础是理解和实现卷…...

云平台虚拟机运维笔记整理,使用libvirt创建和管理虚拟机,以及开启虚拟机嵌套,虚拟磁盘扩容,物理磁盘扩容等等
云平台虚拟机运维笔记整理,使用libvirt创建和管理虚拟机,以及开启虚拟机嵌套,虚拟磁盘扩容,物理磁盘扩容等等。 掌握和使用qemu和libvirt,分别使用它们创建一个cirros虚拟机,并配置好网络。 宿主机node0的系统为ubuntu16,IP为192.168.56.200。 qemu和libvirt简介 QEMU…...

最佳实践:如何实现函数参数之间的TS类型相依赖和自动推断
引入 最近在开发一款极致优雅的前端状态管理库AutoStore时碰到这样一个问题。 拟实现Field组件,该组件相关类型简化代码如下: type Field (props:{validate,render:(props:{value,isValid}) })该组件,具有validate和render两个属性: 其中…...

Linux基础指令1
好久没写博客了,这次我将重新做人,每星期都更,做不到的话直接倒立洗头。最近在学Linux,感觉很厉害的样子,先浅学一下再弄数据结构去。 Linux的基本操作是通过指令来执行的,所以我们先来学习下指令。 1.简…...

软件设计师:排序算法总结
一、直接插入 排序方式:从第一个数开始,拿两个数比较,把后面一位跟前面的数比较,把较小的数放在前面一位 二、希尔 排序方式:按“增量序列(步长)”分组比较,组内元素比较交换 假设…...
「Mac畅玩鸿蒙与硬件25」UI互动应用篇2 - 计时器应用实现
本篇将带领你实现一个实用的计时器应用,用户可以启动、暂停或重置计时器。该项目将涉及时间控制、状态管理以及按钮交互,是掌握鸿蒙应用开发的重要步骤。 关键词 UI互动应用时间控制状态管理用户交互 一、功能说明 在这个计时器应用中,用户…...

计算机专业开题报告写法,该怎么写好?
不会写开题报告,或者想要一些论文模版的,欢迎评论,会第一时间给大家。 题报告是计算机专业大学毕业生在开展毕业设计或论文研究前,对研究课题进行详细介绍和计划的重要环节。作为开题者对科研课题的一种文字说明,开题…...

Vue(JavaScript)读取csv表格并求某一列之和(大浮点数处理: decimal.js)
文章目录 想要读这个表格,并且求第二列所有价格的和方法一:通过添加文件输入元素上传csv完整(正确)代码之前的错误部分因为价格是小数,所以下面的代码出错。如果把parseFloat改成parseInt,那么求和没有意义…...

区块链前端技术栈介绍
这是一份完整区块链前端的学习路径,基于当前市场需求和技术趋势。 🗺️ 技术路线总览 阶段 1:基础入门 (1-2个月) 阶段 2:核心 Web3 技能 (2-3个月) 阶段 3:高级应用开发 (3-4个月) 阶段 4:架构与优化 (2-…...
)
自动化测试常用函数(操作测试对象)
上一篇我们学会了怎么用Selenium定位页面元素,接下来就是要对元素进⾏操作了。常⻅的操作有点击、提交、输⼊、清除、获取⽂本。点击:元素.click()输入:元素.send_keys("内容")清空:元素.clear()拿标签间文字:元素.text…...
)
JS 异步 从零讲(大白话 + 真实场景 + 可运行案例)
按顺序:回调函数 → Promise → async/await,工作最常用,直接上手。1. 回调函数(最原始,缺点:回调地狱)2. Promise(解决回调地狱,链式调用)new Promise((reso…...

终极指南:使用EdiZon轻松编辑Switch游戏存档与内存
终极指南:使用EdiZon轻松编辑Switch游戏存档与内存 【免费下载链接】EdiZon 💡 A homebrew save management, editing tool and memory trainer for Horizon (Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/ed/EdiZon EdiZon是一款…...

【Go Context】终极指南
一、Context 到底是干嘛的? 一句话: 用来在 Goroutine 之间传递:取消信号、超时信号、请求级数据。 核心目的:控制协程生命周期,防止泄漏、卡死、资源浪费。二、Context 四大核心能力 1. 取消信号(WithCanc…...

【APP分发系统二开版】app打包一键免IOS免签封包分发平台源码 带绿标
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 60gx版APP分发系统在线IOS免签封包分发平台源码免签封装带绿标已对接码支付 这个源码某站卖300,主要是因为他有几个功能比较好。 支持一键IOS在线免签封装。买源码可免费协助…...

如何快速实现无人机合规飞行:基于ESP32的完整远程识别解决方案
如何快速实现无人机合规飞行:基于ESP32的完整远程识别解决方案 【免费下载链接】ArduRemoteID RemoteID support using OpenDroneID 项目地址: https://gitcode.com/gh_mirrors/ar/ArduRemoteID 在FAA和欧盟无人机法规日益严格的背景下,远程识别已…...

Wand-Enhancer终极指南:一键解锁WeMod完整功能
Wand-Enhancer终极指南:一键解锁WeMod完整功能 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod免费版的诸多限制而烦恼吗&#x…...

深入RKMedia:拆解Rockchip RV1126多媒体框架,看它如何封装RGA/MPP/RKNN
深入解析RKMedia:Rockchip RV1126多媒体框架的设计哲学与实现细节 在嵌入式多媒体处理领域,Rockchip的RV1126平台凭借其出色的能效比和丰富的硬件加速单元,成为智能视觉终端设备的首选方案之一。而RKMedia作为连接应用层与底层硬件的关键中间…...
)
Wireshark实战:从流量包里‘捞出’图片和压缩包的两种方法(附CTF解题步骤)
Wireshark实战:从流量包里‘捞出’图片和压缩包的两种方法(附CTF解题步骤) 在网络安全和数字取证领域,网络流量分析是一项基础但至关重要的技能。想象一下这样的场景:你正在调查一起数据泄露事件,或者参加…...