SQL 实战问题解析
在数据分析和数据库操作中,SQL 查询是至关重要的一环。本文将通过分析四道典型的 SQL 题目,深入探讨如何从复杂的业务需求中构建准确高效的 SQL 查询。
一、删除学生表冗余信息
需求解读
给定一个学生表,其中包含自动编号、学号、姓名、课程编号、课程名称和分数等字段。要求删除除了自动编号不同,其他信息(学号、姓名、课程编号、课程名称、分数)都相同的冗余记录。
学生表
自动编号 学号 姓名 课程编号 课程名称 分数
1 2005001 张三 0001 数学 69
2 2005002 李四 0001 数学 89
3 2005001 张三 0001 数学 69
代码片段
建表
CREATE TABLE students (id INT, -- 自动编号student_id STRING, -- 学号student_name STRING, -- 姓名course_id STRING, -- 课程编号course_name STRING, -- 课程名称score INT -- 分数
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
导入数据
INSERT INTO students
VALUES ('1', '2005001', '张三', '0001', '数学', '69'),('2', '2005002', '李四', '0001', '数学', '89'),('3', '2005001', '张三', '0001', '数学', '69');SQL如下
select *
from students
where id not in (select min(id)from studentsgroup by student_id, student_name, course_id, course_name, score);如果查询结果符合预期,再将SELECT *替换为DELETE来执行实际的删除操作。
二、寻找 GDP 增速超过罗湖区的区
1)表名:macro_index_data
2)字段名:数据期(年月)(occur_period)、地区代码(area_code)、指标代码
(index_code)、指标类型(增速、总量)(index_type)、指标值(index_value)、数据更新时间
(update_time)。说明:罗湖区的区划代码为440305000000、GDP指标代码为gmjj_jjzl_01、指标类型的枚举值分别是增速(TB)、总量(JDZ)
3)请写出,2020年4个季度中GDP的增速都超过罗湖区同期的区有哪些
需求解读
本题要求找出 2020 年四个季度中 GDP 增速都超过罗湖区同期的区。涉及到从macro_index_data表中筛选出符合条件的数据。
代码剖析
查询语句通过两个子查询分别计算罗湖区和其他区的 GDP 增速数据。在每个子查询中,使用sum函数与case when语句根据月份范围计算每个季度的 GDP 增速指标值。然后通过join条件,将其他区与罗湖区的数据进行比较,筛选出四个季度增速都大于罗湖区的区。例如:
代码片段
建表
CREATE TABLE macro_index_data (occur_period string, -- 数据期(年月)area_code string, -- 地区代码index_code string, -- 指标代码index_type string, -- 指标类型index_value double, -- 指标值,这里使用 double,可根据实际调整update_time timestamp -- 数据更新时间
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t' -- 假设字段分隔符为制表符,可根据实际修改
STORED AS TEXTFILE;
导入数据
数据暂无可由AI生成放入 HDFS 中,例如在/user/hive/data/macro_index_data.txt路径下,使用以下命令:
LOAD DATA INPATH '/user/hive/data/macro_index_data.txt' INTO TABLE macro_index_data;SQL如下
select t2.area_code
from (--先求出罗湖区2020年四季度的GDP指标select area_code,sum(case when month('occur_period') between 1 and 3 thenindex_value else 0 end) `one`, sum(case when month('occur_period') between 4 and 6 thenindex_value else 0 end) `two`, sum(case when month('occur_period') between 7 and 9 thenindex_value else 0 end) `three`, sum(case when month('occur_period') between 10 and 12 thenindex_value else 0 end) `four` from macro_index_datawhere area_code = '440305000000' and index_code = 'gmjj_jjzl_01' and index_type = 'TB' and year('occur_period') = 2020 group by area_code
) t1
join (--再求出其它区2020年四季度的GDP指标select area_code,sum(case when month('occur_period') between 1 and 3 thenindex_value else 0 end) `one`, sum(case when month('occur_period') between 4 and 6 thenindex_value else 0 end) `two`, sum(case when month('occur_period') between 7 and 9 thenindex_value else 0 end) `three`, sum(case when month('occur_period') between 10 and 12 thenindex_value else 0 end) `four` from macro_index_datawhere area_code <> '440305000000' and index_code = 'gmjj_jjzl_01' and index_type = 'TB' and year('occur_period') = 2020 group by area_code
) t2 on t2.one > t1.oneand t2.two > t1.twoand t2.three > t1.threeand t2.four > t1.four;
三、核酸检测人数相关统计
1)表1:t_syrkxxb (实有人口信息表),字段名:姓名(xm)、证件号码(zjhm)、证件类型(zjlx)、出
生日期(csrq)、居住地址(jzdz)、所在街道(jdmc)、所在社区(sqmc)、联系电话(lxdh)、更新时间(gxsj)
2)表2:t_hsjcqkb (核酸检测情况表),字段名:姓名(xm)、证件号码(zjhm)、证件类型(zjlx)、
检测机构(jcjgou)、检测时间(jcsj)、报告时间(bgsj)、检测结果(jcjguo)
3)说明:实有人口信息表中,因网格统计的时候一人有多处房产或者在多地有居住过的,会有多
条数据,仅取最新一条记录;核酸检测情况表中,同一人在同一天内不同检测机构检测多次的算多次检
测,同一人在同一天内同一检测机构检测多次的只算最后一次
4)请写出各街道已参与核酸检测总人数、今日新增人数、已检测人数占总人口数的比例;
需求解读
需要计算各街道已参与核酸检测总人数、今日新增人数以及已检测人数占总人口数的比例。涉及到t_syrkxxb(实有人口信息表)和t_hsjcqkb(核酸检测情况表)两张表。
代码剖析
通过三个子查询和连接操作来实现。首先从实有人口信息表计算各街道总人口数。对于今日新增人数,从核酸检测表中筛选出今日(2021 - 07 - 29)检测的用户,通过左连接排除之前检测过的用户后按街道分组计数。已参与核酸检测总人数的计算,先从实有人口表中获取每个用户的最新记录,再与检测过的用户连接并按街道分组计数。最后将三个结果集连接并选择相应字段。
代码片段
建表
创建实有人口信息表t_syrkxxb
CREATE TABLE t_syrkxxb (xm STRING,zjhm STRING,zjlx STRING,csrq STRING,jzdz STRING,jdmc STRING,sqmc STRING,lxdh STRING,gxsj TIMESTAMP
);
创建核酸检测情况表t_hsjcqkb
CREATE TABLE t_hsjcqkb (xm STRING,zjhm STRING,zjlx STRING,jcjgou STRING,jcsj TIMESTAMP,bgsj TIMESTAMP,jcjguo STRING
);导入数据
数据暂无可由AI生成放入 HDFS 中,例如在/user/hive/data/t_hsjcqkb.txt路径下,使用以下命令:
LOAD DATA INPATH '/user/hive/data/t_hsjcqkb.txt' INTO TABLE t_hsjcqkb;LOAD DATA INPATH '/user/hive/data/t_syrkxxb.txt' INTO TABLE t_syrkxxb;SQL如下
select t6.jdmc `所在街道`,t8.jiance_person_num `已参与核酸检测总人数`,t7.add_num `今日新增人数`,t6.person_num `已检测人数占总人口数的比例`
from (--各街道总人口数select jdmc,count(*) `person_num`from t_syrkxxbgroup by jdmc
) t6
join (--各街道今日新增人数:以前没有检测过的用户select t4.jdmc,count(*) `add_num`from (select zjhm,zjlx,jdmcfrom t_hsjcqkbwhere date_format('jcsj','yyyy-MM-dd') = '2021-07-29') t4left join (--求出检测过的用户select zjhm,zjlxfrom t_hsjcqkbgroup by zjhm,zjlx) t5 on t4.zjhm = t5.zjhmand t4.zjlx = t5.zjlxwhere t5.zjhm is nullgroup by jdmc
) t7 on t6.jdmc = t7.jdmc
join (--求出各街道已参与核酸检测总人数select t1.jdmc,count(*) `jiance_person_num`from (--先将实有人口表按更新时间排序后过滤出最新的记录select t1.*from (select *,row_number() over(partition by zjhm order by gxsj desc)`rank_gxsj`from t_syrkxxbgroup by zjhm ) t1where rank_gxsj = '1') t2join (--求出检测过的用户select zjhm,zjlxfrom t_hsjcqkbgroup by zjhm,zjlx) t3 on t2.zjhm = t3.zjhm and t2.zjlx = t3.zjlxgroup by t1.jdmc
) t8 t6.jdmc = t8.jdmc;
四、查询用户连续三天登录数据
需求解读
给定用户登录记录表,要查询出用户连续三天登录的所有数据记录。
代码剖析
查询过程分为四步。首先使用lead()函数求出每行日期后面第三行的日期later3dt,同时用date_add()函数求出真正第三天的日期true3dt。第二步通过if函数判断两者是否相等来标记是否连续登录。第三步筛选出标记为 1 的记录,即连续登录三天的起始日期。第四步通过与一个包含 0、1、2 的数组进行笛卡尔积操作和date_add()函数计算出连续三天的日期。核心代码如下:
代码片段
建表
create table user_log(id int,dt string
)
row format delimited
fields terminated by '\t';导入数据
INSERT INTO user_log
VALUES
(1, '2024-04-25'),
(1, '2024-04-26'),
(1, '2024-04-27'),
(1, '2024-04-28'),
(1, '2024-04-30'),
(1, '2024-05-01'),
(1, '2024-05-02'),
(1, '2024-05-04'),
(1, '2024-05-05'),
(2, '2024-04-25'),
(2, '2024-04-28'),
(2, '2024-05-02'),
(2, '2024-05-03'),
(2, '2024-05-04');SQL如下
第一步
求解每行日期后面第三行的日期 lead()和 真正第三天的日期
select*,lead(dt,2) over(partition by id order by dt) later3dt,date_add(dt,2) true3dt
from user_log;

第二步
判断是否连续登录三天
with t as (select*,lead(dt,2) over(partition by id order by dt) later3dt,date_add(dt,2) true3dtfrom user_log
) select *,if(later3dt==true3dt,1,0) num from t;
第三步
筛选出连续登录三天的每个起始日期
with t as (select*,lead(dt,2) over(partition by id order by dt) later3dt,date_add(dt,2) true3dtfrom user_log
) ,t1 as (select *,if(later3dt==true3dt,1,0) num from t
)select * from t1 where num=1;
第四步
表合并求最终结果(和一个三行的表进行合并)(笛卡尔积)
with t as (select*,lead(dt,2) over(partition by id order by dt) later3dt,date_add(dt,2) true3dtfrom user_log
) ,t1 as (select *,if(later3dt==true3dt,1,0) num from t
),t2 as (select * from t1 where num=1
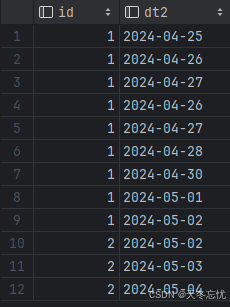
) select id, date_add(dt,d.list) dt2 from t2,(select explode(array(0,1,2)) list) d;

按照需求修改代码
with t as (select*,lead(dt,2) over(partition by id order by dt) later3dt,date_add(dt,2) true3dtfrom user_log
) ,t1 as (select *,if(later3dt==true3dt,1,0) num from t
),t2 as (select * from t1 where num=1
) select id, date_add(dt,d.list) dt2 from t2,(select explode(array(0,1,2)) list) d;
结果
四、总结
通过对这四道 SQL 题目的分析,我们可以看到在处理实际业务需求中的数据查询时,需要深入理解业务逻辑,构建合适的查询语句。对代码进行优化是提高查询效率和代码质量的关键,这包括合理使用数据库函数、优化连接条件和处理日期数据等方面。希望这些分析和建议能帮助大家在 SQL 查询中更加得心应手,写出高效准确的代码。
相关文章:
SQL 实战问题解析
在数据分析和数据库操作中,SQL 查询是至关重要的一环。本文将通过分析四道典型的 SQL 题目,深入探讨如何从复杂的业务需求中构建准确高效的 SQL 查询。 一、删除学生表冗余信息 需求解读 给定一个学生表,其中包含自动编号、学号、姓名、课程编…...
Android MVVM demo(使用DataBinding,LiveData,Fresco,RecyclerView,Room,ViewModel 完成)
使用DataBinding,LiveData,Fresco,RecyclerView,Room,ViewModel 完成 玩Android 开放API-玩Android - wanandroid.com 接口使用的是下面的两个: https://www.wanandroid.com/banner/jsonhttps://www.wan…...
python的安装环境Miniconda(Conda 命令管理依赖配置)
这一段时间,对AI大模型 有了兴趣就想研究一下。 在研究之前肯定要先把需要的编程技能掌握了。经过我查阅资料,今天就先学一下 python的 环境安装。 Node.js 包管理工具:npm 依赖配置文件:package.json 环境管理:nvm&am…...

【LeetCode】【算法】128. 最长连续序列
LeetCode 128. 最长连续序列 题目描述 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。 示例: 输入:nums [10…...

【dvwa靶场:XSS系列】XSS (Reflected)低-中-高级别,通关啦
一、低级low 简单拿捏 <script>alert(123)</script>二、中级middle 源码过滤了script但是没有过滤大小写,改成大写S <Script>alert(123)</script>三、高级high 比中级高,过滤了script并且以及大小写,使用其他标…...
)
imu_tk配置教程(锁死ubuntu18.04,不要22.04)
在ubuntu18.04上安装。 imu_tk 的 cmake 必须要qt4.x,但 ubuntu22.04 和qt4.x不适配。 1、安装 ceres-solver 下载路径:http://ceres-solver.org/installation.html (需要梯子,核心内容记录如下。需下载 ceres-solver 安装包&am…...

Vue 的 keep-alive
什么是 keep-alive? <keep-alive> 是一个内置组件,用于缓存组件实例,从而提高应用的性能。当包裹动态组件时,<keep-alive> 会缓存不活跃的组件实例,而不是销毁它们。这使得当组件重新激活时,可…...

linux进程的状态之环境变量
我们在前面了解了进程的状态及相关概念 接下来我们接着上一篇进程的状态接着了解环境变量 进程的状态 文章目录 目录 文章目录 前言 二、环境变量 1、常见环境变量 2、查看环境变量 3、修改PATH 4、HOME 5、PATH 编辑 6、和环境变量相关的命令 三、环境变量的组织…...
)
【系统架构设计师】预测试卷一:论文(包括4篇论文主题对应的写作要点分析)
更多内容请见: 备考系统架构设计师-专栏介绍和目录 文章目录 试题一:论面向服务的架构设计与应用试题一写作要点试题二:论软件架构的脆弱性试题二 写作要点试题三:论分布式存储系统架构设计试题三 写作要点试题四:论网络安全体系架构设计及应用试题四 写作要点试题一:论面…...

东胜物流软件 AttributeAdapter.aspx SQL 注入漏洞复现
0x01 产品简介 东胜物流软件是青岛东胜伟业软件有限公司一款集订单管理、仓库管理、运输管理等多种功能于一体的物流管理软件。该公司初创于2004年11月(前身为青岛景宏物流信息技术有限公司),专注于航运物流相关环节的产品和服务。东胜物流信息管理系统货代版采用MS-SQLser…...
2024年网鼎杯青龙组|MISC全解
转载或摘抄时请标明出处 MISC01 wdbflag{22226aba1d98c4302a6f508cad7da5d8} MISC02 一把梭工具没有任何结果,估计缺少符号表,直接strings flag > out.txt导出后慢慢找线索 在桌面上发现了png和txt文件,用文件名做一次筛选 第一行发现bas…...

查询引擎的演变之旅 | OceanBase原理解读
在关系型数据库中,查询调度器与计划执行器,有着与查询优化器同样重要的地位,随着计算机硬件技术的飞速进步,这两大模块的重要性日益凸显,成为提升数据库性能的关键所在。接下来,本文将由来自 OceanBase 的技…...
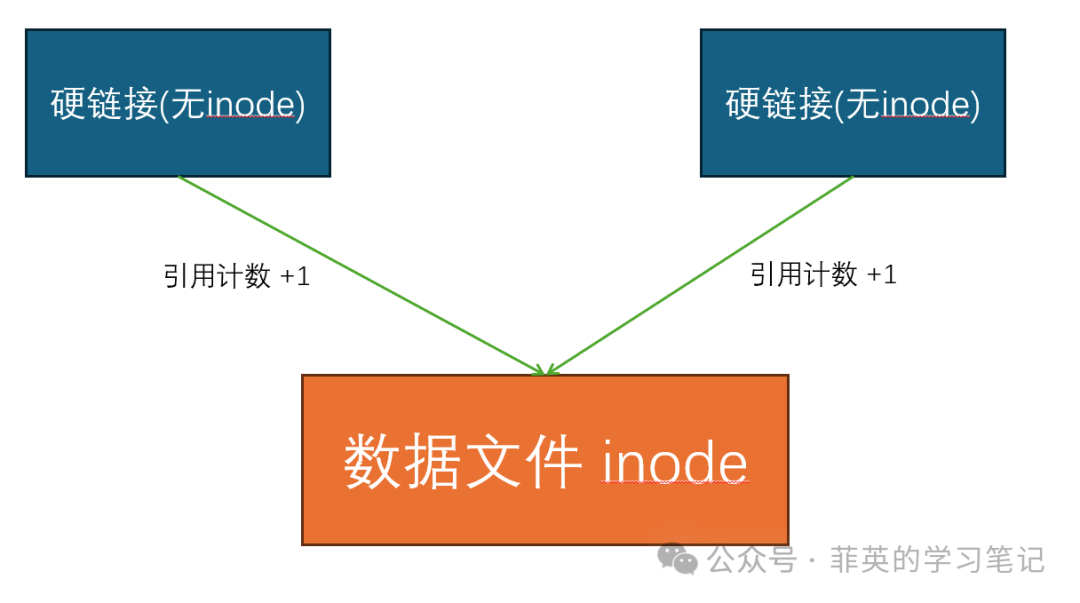
轻松理解操作系统 - Linux 软硬链接是什么?
Linux 由于其开源、比较稳定等特点统治了服务端领域。也因此,学习Linux 系统相关知识在后端开发等岗位中变得越来越重要,甚至可以说是必不可少的。 因为它的广泛应用,所以在程序员的日常工作和面试中,它都是经常出现的。它的开源特…...
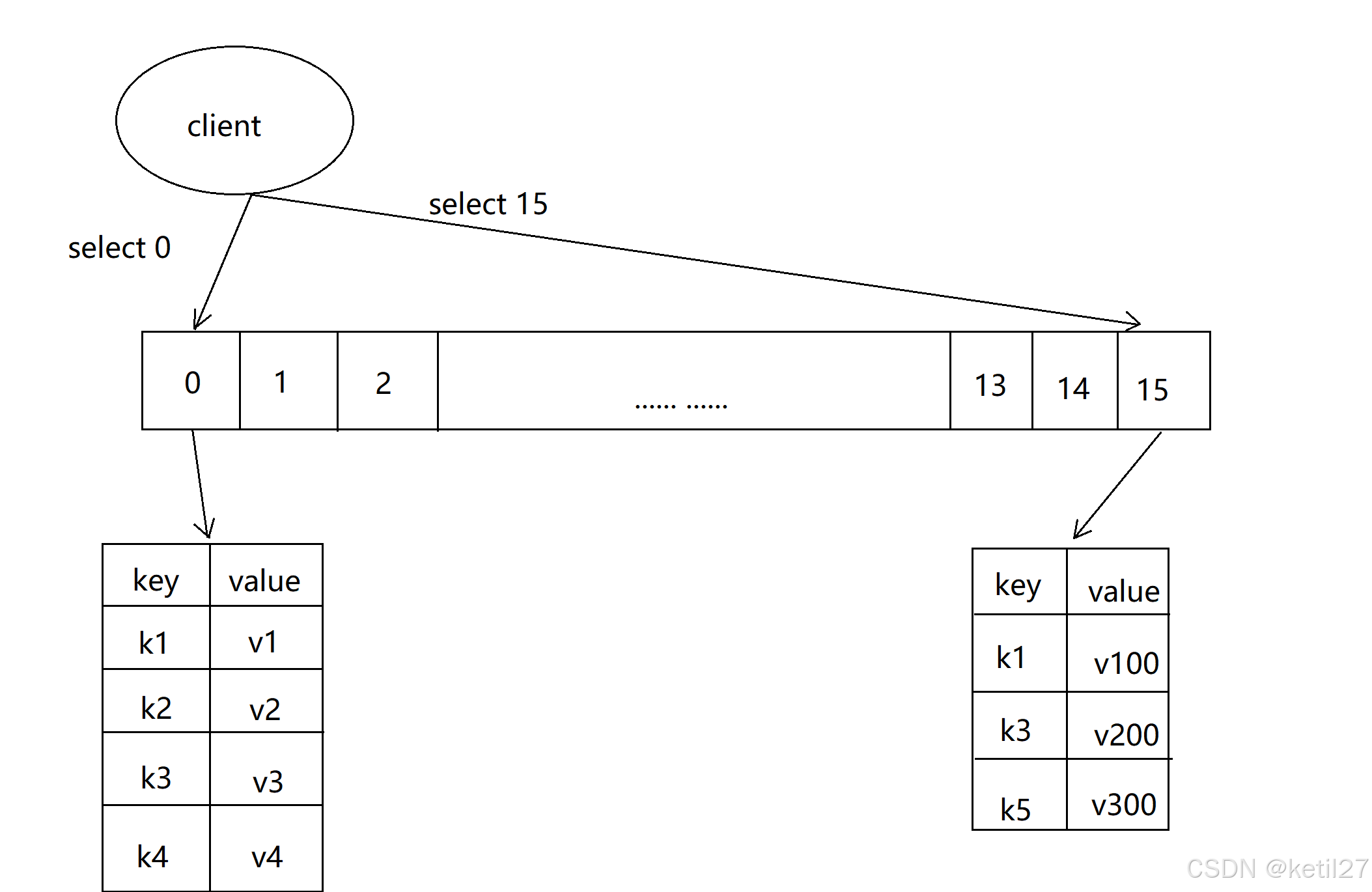
Redis - 数据库管理
Redis 提供了⼏个⾯向Redis数据库的操作,分别是dbsize、select、flushdb、flushall命令, 本机将通过具体的使⽤常⻅介绍这些命令。 一、切换数据库 select dbIndex 许多关系型数据库,例如MySQL⽀持在⼀个实例下有多个数据库存在的&#…...
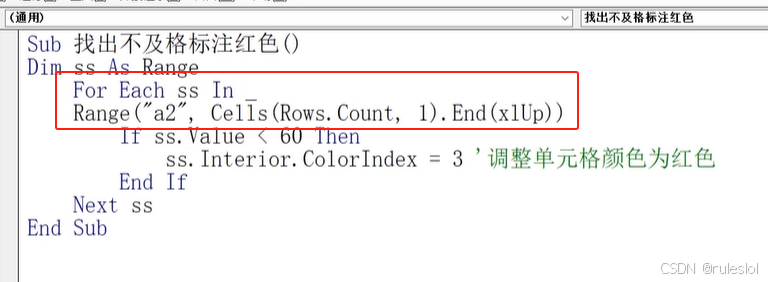
VBA02-初识宏——EXCEL录像机
一、录制宏 录制宏其实就是将一系列操作结果录制下来,并命名存储。这些操作可以是关于数据的处理、格式的设置、函数的运用等,相当于在编程语言(如VB)中定义的一个子程序。 在录制宏时,软件会记录用户执行的一系列操…...

Unity网络开发基础(part5.网络协议)
目录 前言 网络协议概述 OSI模型 OSI模型的规则 第一部分 物理层 数据链路层 网络层 传输层 第二部分 编辑 应用层 表示层 会话层 每层的职能 TCP/IP协议 TCP/IP协议的规则 TCP/IP协议每层的职能 TCP/IP协议中的重要协议 TCP协议 三次握手 四次挥手 U…...

forEach可以遍历不可枚举属性吗
首先第一个问题,forEach能不能遍历对象的属性 const obj { a: 1, b: 2, c: 3 }; obj.forEach((item) > console.log(item))运行这段代码我们发现发生了一个错误 这说明forEach是不可以遍历对象的属性的 在js中,forEach 方法用于遍历数组或类数组对象(如 NodeL…...
Docsify文档编辑器:Windows系统下个人博客的快速搭建与发布公网可访问
文章目录 前言1. 本地部署Docsify2. 使用Docsify搭建个人博客3. 安装Cpolar内网穿透工具4. 配置公网地址5. 配置固定公网地址 前言 本文主要介绍如何在Windows环境本地部署 Docsify 这款以 markdown 为中心的文档编辑器,并即时生成您的文档博客网站,结合…...
索引基础篇
前言 通过本篇博客的学习,我希望大家可以了解到 “索引” 是为了提高数据的查询效率。 索引的介绍 索引是为了提高查询数据效率的数据结构 索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着…...

多进程与多线程分不清?
多进程对应的是fork函数,而多线程对应的是thread函数。 fork 与 thread 的区别: fork开辟新进程,使用了新的资源空间,父子进程对变量的修改互不影响。由于每个进程都是独立的个体,进程间无法直接进行通信。 thread开辟…...

如何使用谷歌全新AI智能体,实现超越普通搜索的信息追踪
在谷歌 I/O 2026 开发者大会主题演讲中,这家科技巨头宣布了搜索功能中全新的智能体能力。用户现在可以创建、自定义并管理多个 AI 智能体,以便持续获取感兴趣话题的最新动态。此次发布是谷歌大力推进智能体 AI 系统战略的重要组成部分,这类系…...
)
用TensorRT加速你的YOLOv5:Windows C++推理部署实战(附完整项目配置)
用TensorRT加速YOLOv5:Windows C推理部署全流程解析 在计算机视觉领域,YOLOv5因其出色的实时检测性能广受欢迎。但当我们需要将训练好的模型部署到实际生产环境时,Python的解释执行往往难以满足性能要求。这时,TensorRT作为NVIDIA…...

Linux信号机制深度解析:从内核实现到多线程编程实践
1. 信号的角色与核心概念 信号,这个在Unix/Linux世界里存在了超过三十年的机制,至今仍然是进程间通信和内核与进程交互的基石。简单来说,信号就是内核发给进程的一个简短通知,告诉它“有事情发生了”。你可以把它想象成你手机上的…...

NY378固态MT29F32T08GSLBHL8-24QA:B
NY378固态MT29F32T08GSLBHL8-24QA:B你是否曾好奇,那些默默支撑着工业设备稳定运行、保障数据高速流转的存储核心,究竟蕴藏着怎样的技术密码?今天,我们将聚焦一颗在特定领域中扮演关键角色的芯片——来自美光(Micron&am…...

数据挖掘与多层神经网络:极简学习路径,神经网络核心机制精要
核心理念:神经网络 可学习的多层次特征提取器 模式匹配器。它通过数据自动学习从输入到输出的复杂映射规则。一、 基础奠基(必须知道的概念)数学基础:线性代数(计算骨架):数据是向量/矩阵&…...

基于CMS8S6990评估板实现高精度电压电流测量:从血氧仪到通用测量工具的移植实践
1. 项目缘起与核心思路最近终于拿到了中微半导体(CMSemicon)正版的CMS8S6990血氧仪开发板。这块板子给我的第一印象就是“精致”,尺寸不大,但该有的接口和功能一应俱全,颇有点“麻雀虽小,五脏俱全”的味道。…...
:单一职责与开闭原则)
【c++面向对象编程】第37篇:面向对象设计原则(一):单一职责与开闭原则
目录 一、为什么需要设计原则? 二、单一职责原则(Single Responsibility Principle) 违反原则的例子 重构:分离职责 三、开闭原则(Open-Closed Principle) 违反原则的例子 重构:使用多态&…...

OBS背景移除插件:从零到一的AI虚拟背景终极指南 [特殊字符]
OBS背景移除插件:从零到一的AI虚拟背景终极指南 🎬 【免费下载链接】obs-backgroundremoval An OBS plugin for removing background in portrait images (video), making it easy to replace the background when recording or streaming. 项目地址: …...

新手如何通过Taotoken控制台申请API Key并查看初始用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 新手如何通过Taotoken控制台申请API Key并查看初始用量 对于初次接触大模型API的开发者而言,第一步往往是如何获取一个…...

如何通过智能菜单栏管理让Mac界面焕然一新:Hidden Bar深度使用指南
如何通过智能菜单栏管理让Mac界面焕然一新:Hidden Bar深度使用指南 【免费下载链接】hidden An ultra-light MacOS utility that helps hide menu bar icons 项目地址: https://gitcode.com/gh_mirrors/hi/hidden 在macOS系统中,菜单栏图标堆积是…...