LangChain实际应用
1、LangChain与RAG检索增强生成技术
LangChain是个开源框架,可以将大语言模型与本地数据源相结合,该框架目前以Python或JavaScript包的形式提供;
- 大语言模型:可以是GPT-4或HuggingFace的模型;
- 本地数据源:可以是一本书、一个PDF文件、一个包含专有信息的数据库;
LangChain的工作流程:
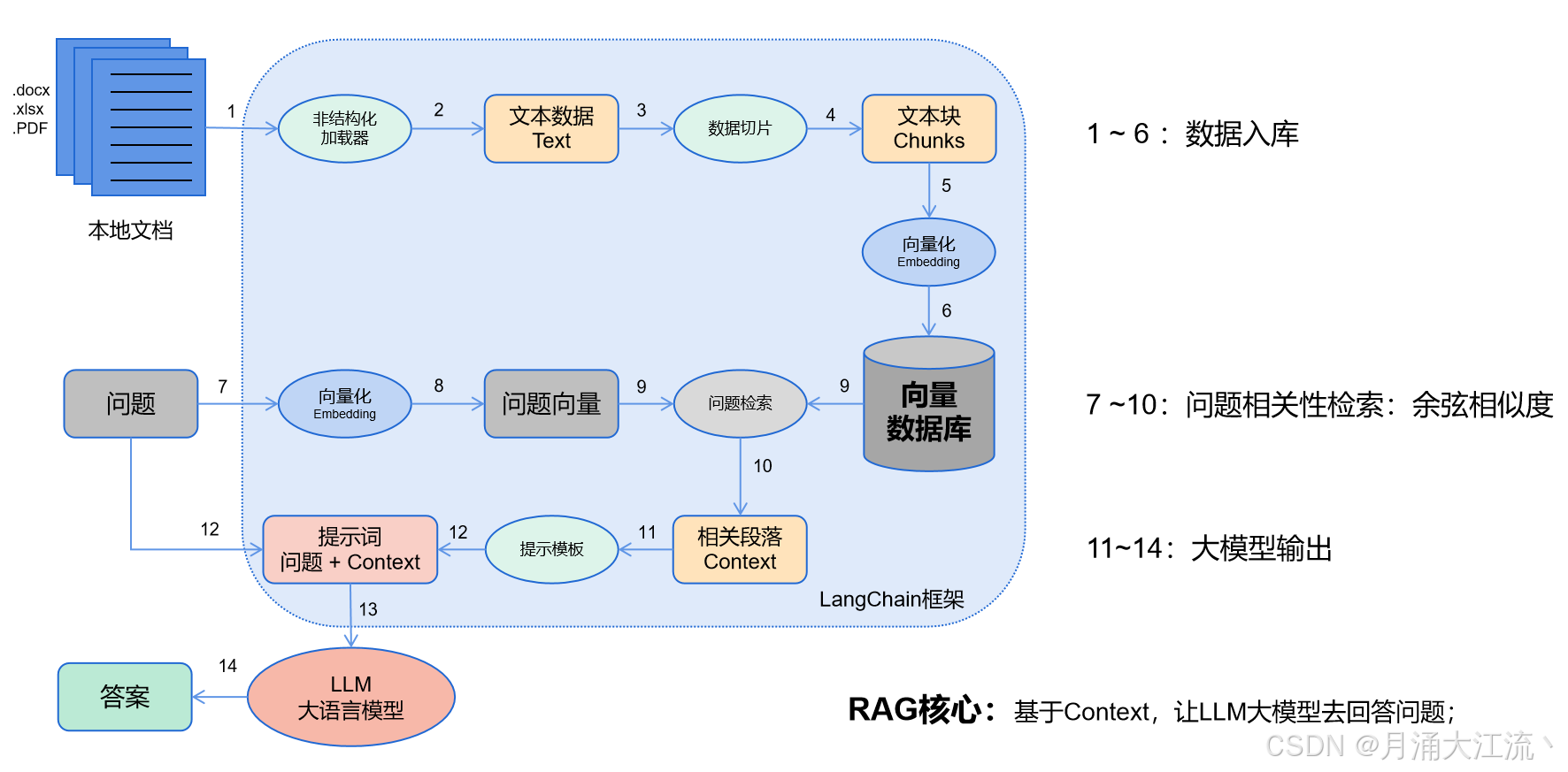
- 数据入库:读取本地数据并切成小块,并把这些小块经过编码embedding后,存储在一个向量数据库中(下图1——6步);
- 相关性检索:用户提出问题,问题经过编码,再在向量数据库中做相似性检索,获取与问题相关的信息块context,并通过重排序算法,输出最相关的N个context(下图7——10步);
- 问题输出:相关段落context + 问题组合形成prompt输入大模型中,大模型输出一个答案或采取一个行动(下图11——15步)
安装 LangChain
pip install langchain
2、构建简单的 Chain 流程
LangChain 中的 Chain 能将多个 LLM 调用和逻辑步骤串联起来,比如将生成的问题传递给一个搜索工具,或将多个步骤的结果集成在一起。
示例:问答链(QA Chain)
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
import os# 初始化 OpenAI 的 LLM
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
llm = OpenAI(model_name="gpt-4")# 创建一个简单的问答模板
prompt_template = PromptTemplate(input_variables=["question"],template="Answer the question as detailed as possible: {question}",
)# 使用 LLM 和提示模板创建一个问答 Chain
qa_chain = LLMChain(llm=llm, prompt=prompt_template)# 提问
answer = qa_chain.run(question="What is LangChain?")
print(answer)
3、应用复杂的 Prompt 模板
在复杂的应用场景中,设计更灵活的 Prompt 模板,LangChain 支持动态生成复杂的输入模板。
from langchain.prompts import PromptTemplate# 创建带有多个变量的 Prompt 模板
prompt = PromptTemplate(input_variables=["product", "audience"],template="Describe the {product} in a way that appeals to {audience}.",
)# 生成 Prompt 内容
result_prompt = prompt.format(product="LangChain", audience="data scientists")
print(result_prompt)
4、构建多步 Chain
LLMChain能够组合多步任务,比如文本分析、摘要、总结等任务。
from langchain.chains import LLMChain, SimpleSequentialChain
from langchain.prompts import PromptTemplate# 定义第一个步骤:描述产品
prompt_1 = PromptTemplate(input_variables=["product"],template="Please describe what {product} does in a brief way.",
)
chain_1 = LLMChain(llm=llm, prompt=prompt_1)# 定义第二个步骤:针对第一步的描述生成市场营销方案
prompt_2 = PromptTemplate(input_variables=["description"],template="Create a marketing strategy for a product with this description: {description}",
)
chain_2 = LLMChain(llm=llm, prompt=prompt_2)# 将两个步骤组合成一个 Chain
sequential_chain = SimpleSequentialChain(chains=[chain_1, chain_2])# 执行 Chain
result = sequential_chain.run("LangChain")
print(result)
5、Memory 记录上下文
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain# 初始化记忆模块
memory = ConversationBufferMemory()# 创建会话 Chain,包含记忆模块
conversation = ConversationChain(llm=llm, memory=memory)# 模拟对话
conversation_result_1 = conversation("What is LangChain?")
conversation_result_2 = conversation("And what can it be used for?")
print(conversation_result_1)
print(conversation_result_2)"""
不同类型的 Memory 记录上下文
"""
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory, ConversationSummaryMemory# Conversation Buffer Memory - 记录完整对话
buffer_memory = ConversationBufferMemory()
conversation_chain_1 = ConversationChain(llm=llm, memory=buffer_memory)# 模拟对话
conversation_chain_1("What is LangChain?")
conversation_chain_1("What applications can it be used for?")
print(conversation_chain_1.memory.buffer)# Conversation Summary Memory - 提供对话概述
summary_memory = ConversationSummaryMemory(llm=llm)
conversation_chain_2 = ConversationChain(llm=llm, memory=summary_memory)# 模拟对话
conversation_chain_2("Tell me about quantum computing.")
conversation_chain_2("How is it different from classical computing?")
print(conversation_chain_2.memory.buffer)6、自定义 Agent:添加多个工具和自定义动作
Agent 可以配置多个工具,如搜索、计算和数据库访问。以下是一个包含自定义工具的示例。
示例:基于自定义工具的 Agent
from langchain.agents import initialize_agent, Tool
from langchain.tools import DuckDuckGoSearchResults, WikipediaAPI# 配置多个工具
search_tool = Tool.from_function(DuckDuckGoSearchResults(), name="search")
wiki_tool = Tool.from_function(WikipediaAPI(), name="wikipedia")# 创建 Agent 并加载工具
agent = initialize_agent(tools=[search_tool, wiki_tool],llm=llm,agent="zero-shot-react-description",
)# 使用 Agent 查询
response = agent("Find the latest information on AI and summarize it for me.")
print(response)
7、使用 Self-Ask 模式的 Agent
Self-Ask 是一种链式推理 Agent,适合回答需要分解的复杂问题。
from langchain.agents import initialize_agent# 初始化 Self-Ask 模式的 Agent
agent_self_ask = initialize_agent(tools=[search_tool, wiki_tool],llm=llm,agent="self-ask",
)# 测试 Self-Ask 模式
response = agent_self_ask("What is the main difference between AI and ML?")
print(response)
8、结合外部数据源:用 Pandas DataFrame 处理表格数据
LangChain 支持直接处理 Pandas 数据,可以轻松构建一个从表格数据中提取信息的功能。
import pandas as pd
from langchain.chains import AnalyzeDocumentChain# 创建数据表
data = pd.DataFrame({"name": ["AI Model A", "AI Model B", "AI Model C"],"accuracy": [0.95, 0.90, 0.85]
})# 配置 Chain 以处理表格数据
analyze_chain = AnalyzeDocumentChain.from_df(llm=llm,dataframe=data,question="Which AI model has the highest accuracy?"
)# 生成答案
result = analyze_chain.run()
print(result)
9、自定义 PromptPipelineChain:多模型的组合使用
可以结合多个模型,按步骤组合成更复杂的 Pipeline。
例如先调用小模型进行摘要,再用大模型进行详细生成。
from langchain.chains import PromptPipelineChain# 配置 PromptPipelineChain
pipeline_chain = PromptPipelineChain(steps=[{"llm": OpenAI(model_name="gpt-3.5-turbo", api_key="your_key"), "prompt": "Summarize the text: {text}"},{"llm": OpenAI(model_name="gpt-4"), "prompt": "Explain in detail: {summary}"},]
)# 运行 Pipeline
text = "LangChain is a framework for developing applications powered by language models."
result = pipeline_chain.run(text=text)
print(result)
10、使用 Retrieval 进行大规模文档查询
LangChain 支持集成向量存储库,例如 FAISS、Pinecone,进行语义搜索,适用于处理大量文档数据的场景。
示例:基于 FAISS 的语义搜索
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.retrievers import RetrievalQAChain# 假设有文档数据
docs = ["LangChain is a library for LLM applications.", "AI is revolutionizing many fields."]# 使用 FAISS 创建向量数据库
embedding = OpenAIEmbeddings()
faiss_store = FAISS.from_texts(docs, embedding)# 使用检索器进行语义搜索
retrieval_chain = RetrievalQAChain(llm=llm, retriever=faiss_store.as_retriever())
result = retrieval_chain.run("Tell me about LangChain.")
print(result)
11、结合 LangChain 的 RAG 模式
from langchain.chains import RetrievalQAChain# 创建 Retrieval Chain
rag_chain = RetrievalQAChain(llm=llm, retriever=faiss_store.as_retriever())# 查询
result = rag_chain("What is the LangChain library used for?")
print(result)
相关文章:
LangChain实际应用
1、LangChain与RAG检索增强生成技术 LangChain是个开源框架,可以将大语言模型与本地数据源相结合,该框架目前以Python或JavaScript包的形式提供; 大语言模型:可以是GPT-4或HuggingFace的模型;本地数据源:…...

【数据结构】哈希/散列表
目录 一、哈希表的概念二、哈希冲突2.1 冲突概念2.2 冲突避免2.2.1 方式一哈希函数设计2.2.2 方式二负载因子调节 2.3 冲突解决2.3.1 闭散列2.3.2 开散列(哈希桶) 2.4 性能分析 三、实现简单hash桶3.1 内部类与成员变量3.2 插入3.3 获取value值3.4 总代码…...
flutter 项目初建碰到的控制台报错无法启动问题
在第一次运行flutter时,会碰见一直卡在Runing Gradle task assembleDebug的问题。其实出现这个问题的原因有两个。 一:如果你flutter -doctor 检测都很ok,而且环境配置都很正确,那么大概率就是需要多等一会,少则几十分…...

Java字符串深度解析:String的实现、常量池与性能优化
引言 在Java编程中,字符串操作是最常见的任务之一。String 类在 Java 中有着独特的实现和特性,理解其背后的原理对于编写高效、安全的代码至关重要。本文将深入探讨 String 的实现机制、字符串常量池、不可变性的优点,以及 String、StringBu…...

leetcode 2043.简易银行系统
1.题目要求: 示例: 输入: ["Bank", "withdraw", "transfer", "deposit", "transfer", "withdraw"] [[[10, 100, 20, 50, 30]], [3, 10], [5, 1, 20], [5, 20], [3, 4, 15], [10, 50]] 输出ÿ…...
框架的文物管理系统)
基于SSM(Spring + Spring MVC + MyBatis)框架的文物管理系统
基于SSM(Spring Spring MVC MyBatis)框架的文物管理系统是一个综合性的Web应用程序,用于管理和保护文物资源。下面我将提供一个详细的案例程序概述,包括主要的功能模块和技术栈介绍。 项目概述 功能需求 用户管理:…...

yakit中的规则详细解释
官方文档 序列前置知识之高级配置 | Yak Program Language 本文章多以编写yaml模版的视角来解释 规则一览 匹配器 在编写yaml中会使用到这里两个东西 点击添加会在返回包的右下角出现匹配器 上面有三个过滤器模式,官方解释 丢弃:丢弃模式会在符合匹配…...
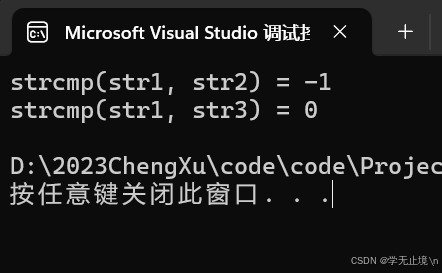
[c语言]strcmp函数的使用和模拟实现
1.strcmp函数的使用 int strcmp ( const char * str1, const char * str2 ); 如果 str1 小于 str2,返回一个负值。如果 str1 等于 str2,返回 0。如果 str1 大于 str2,返回一个正值。 实例: #include <stdio.h> #include &…...

如何把子组件的v-model修改数据,进行接收然后定义数据格式,子传父的实现
在 Vue 中,实现子组件通过 v-model 向父组件传递数据并接收后进行格式化,可以按照以下步骤来封装和实现: 步骤 1: 子组件实现 v-model 子组件需要定义一个 props 来接收 v-model 的值,并通过 emit 方法发出更新事件。 <!-- …...

linux dpkg 查看 安装 卸载 .deb
1、安装 sudo dpkg -i google-chrome-stable.deb # 如果您在安装过程中或安装和启动程序后遇到任何依赖项错误, # 您可以使用以下apt 命令使用-f标志解析和安装依赖项,该标志告诉程序修复损坏的依赖项。 # -y 表示自动回答“yes”,在安装…...

【算法】递归+深搜:105.从前序与中序遍历序列构造二叉树
目录 1、题目链接 2、题目介绍 3、解法 函数头-----找出重复子问题 函数体---解决子问题 4、代码 1、题目链接 105.从前序与中序遍历序列构造二叉树. - 力扣(LeetCode) 2、题目介绍 3、解法 前序遍历性质: 节点按照 [ 根节点 …...

ESP32 gptimer通用定时器初始化报错:assert failed: timer_ll_set_clock_prescale
背景:IDF版本V5.1.2 ,配置ESP32 通用定时器,实现100HZ,占空比50% 的PWM波形。 根据乐鑫官方的IDF指导文档设置内部计数器的分辨率,计数器每滴答一次相当于 1 / resolution_hz 秒。 (ESP-IDF编程指导文档&a…...

基于Python的旅游景点推荐系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码、微信小程序源码 精品专栏:…...

【开源社区】ELK 磁盘异常占用解决及优化实践
1、问题及场景描述 本文主要讨论在 CentOS环境下基于 rpm 包部署 ELK 系统磁盘异常占用的问题解析和解决方案。 生产问题描述:以下问题现实场景基于ELK体系下,ES服务的磁盘占用问题解析。默认情况下,基于 RPM 安装的 Elasticsearch 服务的安…...

达梦数据守护集群_动态增加实时备库
目录 1、概述 2、实验环境 2.1环境信息 2.2配置信息 2.3 查看初始化参数 3、动态增加实时备库 3.1数据准备 3.2配置新备库 3.3动态增加MAL配置 3.4 关闭守护进程及监视器 3.5修改归档(方法1:动态添加归档配置) 3.6 修改归档&…...

计算机基础:Ping、Telnet和SSH
文章目录 PingTelnetSSLSSH隧道 Ping Ping和Telnet是两种常见的网络工具,它们分别用于测试网络连接和检查服务端口的连通性。 Ping是一种网络工具,用于测试主机之间的连通性。它通过发送ICMP(Internet Control Message Protocol)…...

Java教学新动力:SpringBoot辅助平台
1系统概述 1.1 研究背景 随着计算机技术的发展以及计算机网络的逐渐普及,互联网成为人们查找信息的重要场所,二十一世纪是信息的时代,所以信息的管理显得特别重要。因此,使用计算机来管理教学辅助平台的相关信息成为必然。开发合适…...

24/11/3 算法笔记 Adam优化器拆解
Adam 优化器是一种用于深度学习中的自适应学习率优化算法,它结合了两种其他流行的优化方法的优点:RMSprop 和 Momentum。简单来说,Adam 优化器使用了以下方法: 1. **指数加权移动平均(Exponentially Weighted Moving …...

浅谈语言模型推理框架 vLLM 0.6.0性能优化
在此前的大模型技术实践中,我们介绍了加速并行框架Accelerate、DeepSpeed及Megatron-LM。得益于这些框架的助力,大模型的分布式训练得以化繁为简。 然而,企业又该如何将训练完成的模型实际应用部署,持续优化服务吞吐性能…...

【大数据学习 | kafka高级部分】kafka中的选举机制
controller的选举 首先第一个选举就是借助于zookeeper的controller的选举 第一个就是controller的选举,这个选举是借助于zookeeper的独享锁实现的,先启动的broker会在zookeeper的/contoller节点上面增加一个broker信息,谁创建成功了谁就是主…...

从零搭建现代化Go开发环境:模块化、工具链与最佳实践
1. 项目概述:为什么需要一个现代化的Go开发环境? 如果你刚开始接触Go语言,或者刚从其他语言(比如Java、Python)转过来,可能会觉得“不就是装个Go编译器,配个环境变量吗?”。确实&am…...

别再折腾gcc版本了!Ubuntu 20.04下用Docker一键搞定OLLVM编译环境
用Docker容器化技术快速搭建OLLVM混淆编译环境 在逆向工程和移动安全研究领域,代码混淆是一项基础而重要的技术。传统搭建OLLVM环境需要处理复杂的依赖关系、版本冲突等问题,往往让初学者望而却步。本文将介绍如何利用Docker技术,在Ubuntu 20…...

炸了!Claude 更新后 Mac 老系统直接报废:开发者凌晨三点爬起来修环境
一、真实事故现场:上海某团队的惊魂一夜 2026年5月15日凌晨2:37,上海浦东某科技公司。 高级工程师小李盯着屏幕上的错误信息,手指在键盘上飞快地敲击着。他面前是三个显示器,每个都显示着不同的终端窗口,满屏的红色错误信息像血一样刺眼。 "这怎么可能?"他自…...
)
从芯片手册到PCB:手把手教你用TPS5430搞定24V转15V电源(附完整BOM清单)
从芯片手册到PCB:手把手教你用TPS5430搞定24V转15V电源(附完整BOM清单) 在硬件设计领域,电源模块的设计往往是最基础却也最考验工程师功底的环节。一个优秀的电源设计不仅需要满足电压转换的基本需求,还要兼顾效率、稳…...

如何打破课堂限制?JiYuTrainer让您的电脑重获自由
如何打破课堂限制?JiYuTrainer让您的电脑重获自由 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 当您在计算机课堂上被极域电子教室完全控制时,是否感到学…...

5分钟学会在Windows电脑上安装Android应用:APK Installer终极指南
5分钟学会在Windows电脑上安装Android应用:APK Installer终极指南 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行手机应用吗&#x…...

UniApp跨端开发实战:一套代码给TabBar同时穿上iOS和Material Design的“毛玻璃”外衣
UniApp跨端毛玻璃TabBar实战:融合iOS与Material Design的设计语言 在移动应用开发中,底部导航栏(TabBar)作为核心交互组件,其设计直接影响用户体验。随着iOS毛玻璃(Blur Effect)和Android Mater…...

全面战争模组制作新纪元:RPFM工具让你的创意无限延伸
全面战争模组制作新纪元:RPFM工具让你的创意无限延伸 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: https://gitc…...

数据库备份与恢复策略
数据库备份与恢复策略 1. 技术分析 1.1 备份概述 备份是数据安全的基石: 备份类型完全备份: 全部数据增量备份: 变化数据差异备份: 上次完全备份后的变化备份策略:定期完全备份增量备份补充实时备份1.2 恢复策略 恢复类型完全恢复: 恢复到最新状态时间点恢复: 恢复到…...

为汉语辩护,彰显中华文字的生命力与优越性
为汉语辩护,彰显中华文字的生命力与优越性上世纪初,一批所谓“新文化人”竟提出废除汉字的主张,他们盲目推崇拉丁文,认为汉语是落后的语言,却不知这是对中华文字深厚底蕴的无知与曲解。如今回望,汉字的独特…...