985研一学习日记 - 2024.11.8
一个人内耗,说明他活在过去;一个人焦虑,说明他活在未来。只有当一个人平静时,他才活在现在。
日常
1、起床
2、健身
3、LeetCode刷了2题
- 买卖股票的最佳时机
- 将最大利润拆分为每天的利润之和,仅仅收集每天的正利润
- 跳跃游戏
- 取最大跳跃范围,不用拘泥于每次究竟跳几步,而是看覆盖范围,覆盖范围内一定是可以跳过来的,不用管是怎么跳的。
- 使用一个变量表示当前可以到达的最大范围,遍历数组,每次对当前可以达到的最大范围进行更新,直到到达最后
- 跳跃游戏2
- 求可以到达的最小次数,使用数组进行记录,遍历每个元素,对于其能到达的所有元素修改最小次数,用数组记录,遍历所有元素,对其后面位置的最小次数数组进行更新,判断当前最小+1是否小于后面可以达到位置的最小次数,如果小于就对其进行更新
- K次取反后最大化的数组和
- 先让绝对值大的负数变为正数,如果k小于负数个数,则此时操作k次后所有元素之和就是最大的数组和,如果k大于负数个数,则此时找最小的正数对其操作剩下的次数,最后的数组之和就是结果
- 可以先对数组排序,然后从前向后遍历的同时,如果是负的则取反操作并使得k-1,直到k为0则直接退出求数组和,或者遇到第一个正数,则此时先判断是不是第一个,如果不是则判断与前一个正数的大小,要找到最小的正数对其执行剩下的取反操作,然后退出求数组和即可;也可能全为负数,且k大于元素个数,则此时全取反后数组末尾就是最小元素,则将剩余的次数全部作用于最后一个元素即可
- 贪心的思路,局部最优:让绝对值大的负数变为正数,当前数值达到最大,整体最优:整个数组和达到最大。
4、复盘
不复盘等于白学!!!
学习和感想
1、Docker学习
1. Docker复杂安装
对于存储类应用容器,必须使用容器数据卷进行持久化
- 安装MySQL主从复制
- 新建主MySQL容器服务器master-mysql,并修改配置文件配置主从复制并设置utf-8字符集,修改后重启容器以重启内部运行的服务 ![[Pasted image 20241107151904.png]]![[Pasted image 20241107152133.png]]
- 在master-mysql主机上创建数据同步用户以完成授权,由从机登录该用户以实现主从复制,从而实现授权![[Pasted image 20241107152358.png]]
- 启动从mysql容器:slave-mysql,同样修改配置文件实现从机配置,并重启容器以重启内部的mysql服务![[Pasted image 20241107152527.png]]![[Pasted image 20241107152628.png]]
- 先在主机master-mysql中查看主从复制的状态,然后进入从slave-mysql中配置主从复制 ![[Pasted image 20241107152933.png]]
- 配置完成后在从机中查看主从同步状态,然后在从机中开启主从复制,配置后要自己开启主从复制start slave; ![[Pasted image 20241107153203.png]]
- 总体步骤![[Pasted image 20241107151714.png]]
- 安装Redis集群
- 面试题:分布式存储算法
- 大量数据需要缓存,肯定不能使用单机存储,必须使用分布式存储
- 分布式存储算法
- 概念
- 分布式存储算法,是将数据分布式的存储在不同的服务器上,此时就出现了数据的分配问题,即数据应该存储到哪台服务器上
- 哈希取余分区,是根据部署的服务器个数来对数据进行分配,直接根据数据的KEY求出哈希值,然后对服务器的个数取余,得到结果就是存放的位置,此时不便于扩缩容,每次扩缩容都要全部重新分配
- 一致性哈希算法,采用哈希环,即让key的哈希值对固定的值进行取余,使其落在长度为固定值的一个环上的某个位置,固定值与服务器的个数无关,不会收到扩缩容影响,然后对每台服务器也进行取余,平均落到哈希环的某个位置,当key的哈希值取余后,顺时针遇到的第一个服务器就是存放的位置,此时扩缩容只会影响与服务器邻近的部分数据,而不会对整个哈希环上的数据造成影响,但可能会造成数据倾斜问题到时数据分布不均匀
- 哈希槽算法(在一致性哈希算法中加一层slot槽)是将数据分配在16384个slot槽中,先根据哈希函数计算出key的哈希值,然后对16384取余得到要存放的槽位,然后每台服务器均均匀管理着部分槽位,当扩缩容时直接进行槽位的转移即可,而无需对数据进行重新分配,为什么用16384,因为建议集群最多用1000个节点,故每个节点平均管理16个槽位就可以,且16384个槽位只需要2k数据进行存放,而心跳包要携带完整信息,故要修改2k的槽数据,如果使用2 ^ 16位来存放,则需要8K,此时会造成大量开销
- 哈希取余分区
- 直接对Redis节点数进行取余以得到要保存到哪个节点中,取余算法很快,且实现了负载均衡和分而治之 ![[Pasted image 20241107160002.png]]
- 但每次扩缩容都要对所有的数据进行重新分配,因为当扩缩容后取余值发生了改变,故之前分配的结果不一定是现在的结果,故必须全部重新分配![[Pasted image 20241107160211.png]]
- 扩缩容时必须全部重新分配,因为前面存储的数据的key取余后结果发生了改变
- 一致性哈希
- 为了解决哈希取余算法数据变动和映射问题而提出的,其直接固定值取余,从而实现一个固定的哈希环,此时节点扩缩容不会影响数据取余后的结果,然后对节点也进行取余均匀存放到哈希环的位置上,此时数据取余后顺时针遇到的第一个节点就是存放的节点![[Pasted image 20241107164256.png]]
- 此时扩缩容不会影响所有数据的映射,只会对相应节点附近的数据(所有落到当前节点的数据,即当前节点逆时针到上一个节点之间的数据)造成变动,只影响顺时针的下一个节点
- 有较高的容错性和扩展性,某一个节点出错只会影响落到该节点上的数据,不会造成数据的全部重新分配,且节点增加时,只影响落到该节点的数据,即新增节点与逆时针上一个节点之间的数据会被映射到该节点上,只影响顺时针的下一个节点
- 但节点很少时可能存在数据倾斜问题,导致每个节点数据分配不均匀,节点映射是根据IP随机映射的,不一定会均匀,故节点很少时可能会出现数据倾斜问题 ![[Pasted image 20241107164215.png]]
- 三大步骤:1、算法构建哈希环;2、服务器节点IP映射(将服务器节点映射到哈希环的某个位置,可以使用IP);3、key落到服务器的落键规则(key映射到哈希环上后顺时针遇到的第一个节点就是存放的位置)![[Pasted image 20241107163254.png]]![[Pasted image 20241107163419.png]]
- 哈希槽slot
- 一致性哈希算法会出现数据倾斜问题
- 为了解决均匀分配问题,在数据和节点直接加了一层哈希槽slot,数据先均匀存放在哈希槽slot中,然后再由节点管理哈希槽
- 在数据和节点之间加入一层哈希槽slot,一共有16384个哈希槽slot,数据计算哈希值后对16384取余得到槽位,放入指定的槽中,然后节点均匀分配槽的个数来管理数据,建议最多1000个节点,之所以16384个槽,因为在发送心跳包时,要携带节点的所有信息,其中就有槽的信息,而设置16384=2 ^ 14 个槽时,此时只需要2KB就可以携带所有的槽信息,而如果用 2 ^ 16 个槽,则此时要携带 8KB 的数据存放槽信息,就会造成极大的延迟并浪费带宽且压缩效率低,且建议Redis节点最多1000个,故不需要使用太多的槽个数,只要16384个就行
- 只有16384个哈希槽,每个数据key先计算哈希值,然后再对16384取余来确定所在的哈希槽
- 概念
- ![[Pasted image 20241107154041.png]]
- 三主三从Redis集群配置
- 先关闭防火墙并且启动Docker服务 systemctl start docker
- 以集群的方式启动6台Redis容器(运行Redis服务的简易版Linux环境) –net host模式不需要端口映射,直接使用宿主机的端口 ![[Pasted image 20241107204749.png]]![[Pasted image 20241107205104.png]]
- 进入其中一台Redis容器的Linux环境中来配置主从关系 使用redis-cli –cluster create xxx1 xxx2 xxx3 –cluster-replicas 1 来为每个master创建一个slave节点,会自动分配master和slave节点,通过–cluster-replicas 来设置为每个master自动分配指定的slave节点个数,创建集群成功后,会自动为每个master节点均匀分配哈希槽 ![[Pasted image 20241107205248.png]]
- 进入任一个集群节点查看集群状态 cluster info 、 cluster nodes,在登录redis-cli 要使用 -p 指定redis的端口号 ![[Pasted image 20241107210203.png]]
- 每一次主从节点的分配都是随机的,随机为每个master分配指定个数的slave,且主从分配结束后会自动均匀分配哈希槽slot
- ![[Pasted image 20241107204559.png]]
- 主从容错切换迁移
- 当集群中某个master节点宕机时,会自动将其slave节点切换为master节点以保证容错,且原来的master会变为slave,当重新启动时不会还原为master,而是会变为新的master的slave
- 当集群中某个master宕机后,会将其slave变为新的master,而原来的master就会变为新master的slave,且集群就是主从复制+哨兵,内部自带哨兵功能
- 数据读写存储,开启集群后,数据通过哈希槽分配到不同的master节点中,此时一定要通过 -c 开启路由转发,否则无法操作别的master节点的数据key![[Pasted image 20241107212142.png]]
- 一定要使用 -c 启动redis-cli,开启路由转发,否则无法访问别的master所管理的哈希槽中的数据
- 在集群环境下登录redis时一定要使用 -p 指定端口号,如果不指定则默认是6379端口,且集群下对数据处理时,一定要加上 -c 启动路由转发,此时会直接跳转到对应的master,然后处理该master所管理哈希槽下的数据
- 集群环境下必须使用 -c 启动redis客户端,此时会自动进行路由跳转,跳转到指定哈希槽所在的master节点中再对数据进行操作
- -c 会开启集群的路由转发,会自动跳转到对应的master
- redis -cli --cluster check ip:port 检查指定节点所在的集群的信息
- 只有master可写,从机slave只可读
- 1
- 主从扩容
- 将新节点作为master加入集群:redis-cli –cluster add-node 新节点IP+PORT 集群节点IP+PORT ,向集群加入新master节点时,必须设置指路节点以指明加入哪个集群,且新加入的节点会作为master节点,而且不会自动分配槽位,要自己手动分配 ![[Pasted image 20241108075433.png]]
- 为新加入集群的master节点手动分配槽位:redis-cli --cluster reshard 新加入节点IP+PORT,为新加入的master节点手动分配哈希槽位slot,在原有分配的基础上,释放原来master节点的槽位分配给新节点,并指定分配多少个槽位,此时会从别的master的槽位中分别匀一点组成新master节点的槽位,不是从0开始分配,而是分别匀出一点
- 为集群的master节点添加新的slave节点,先向集群中添加新的节点–cluster add-node 新节点 集群节点 然后指定是哪个节点的slave: --cluster-slave --cluster-masdter-id master节点ID ![[Pasted image 20241108081041.png]]
- 就是添加新的master节点,此时要自己手动为节点分配哈希槽位,先将节点加入到集群中,需要一个指路的master节点来指明加入哪个集群,加入成功后要自己手动分配哈希槽,且重新分配哈希槽不会影响槽中的数据
- 当集群创建时,会自动为每个master节点分配均匀的哈希槽位,但是当扩容或者缩容时,必须手动的分配和释放槽位
- 先将新的节点作为master加入集群,此时不会为其分配槽位,要自己手动为其分配槽位![[Pasted image 20241108075225.png]]
- 主从缩容
- 集群主从缩容时,必须先删除从机节点,然后释放主机master上分配的槽位,再删除主机master节点
- 主从缩容时先删除从机节点:redis-cli –cluster del-node 从机IP+PORT 从机ID ![[Pasted image 20241108082228.png]]
- 将主机master的槽位释放,仍是使用 --cluster reshard 集群节点 来对指定节点所在集群的槽位进行释放![[Pasted image 20241108082546.png]]
- 删除主从节点时,必须先删除从机节点,然后再删除主机节点,因为主机作为写入,如果先删除会造成容错迁移导致额外的开销,故先删除从机节点
- 集群操作
- 当主从扩缩容时,只是将槽位的分配进行了变动,但其内的数据仍然属于该槽位,不需要对数据重新分配
- 使用 –cluster reshard 集群节点 :可以实现对指定节点所在集群的槽位进行操作,且cluster操作要输入集群的某个节点以指定所在的集群,然后再对集群中的节点进行操作,要先指定节点的集群
- 集群主从扩容时,先通过 --cluster add-node 将节点添加到指定的集群中,此时作为master节点,然后使用reshard让新增节点作为接收节点,从all集群master节点中抽取槽位对其进行分配,然后新增从节点,并配置作为新master节点的slave --cluster-slave --cluster-master-id xxx
- 集群主从缩容时,先通过 --cluster del-node 删除从节点,然后使用reshard对master节点的槽位进行释放,指定一个节点接收,从要删除的master节点抽取槽位分配给要接收的节点,或者多次释放给多个节点,然后删除master节点
- 面试题:分布式存储算法
2. DockerFile解析
- 是什么:构建镜像的文件
- 创建镜像的两种方式
- 通过对本地的容器使用 docker commit 操作 提交为一个镜像,其在原来镜像的基础上添加一个容器层文件,然后保存到本地
- 通过DockerFile来创建镜像文件
- **DockerFile是创建Docker镜像的文本文件,是由一条条构建镜像所需的指令和参数构成的脚本
- DockerFile是构建Docker镜像的文本文件,由一条条指令和参数构成
- 先编写dockerFile文件,然后docker build 命令根据dockerFile构建镜像,然后docker run该镜像生成容器实例
- 使用commit构建镜像时,每次都要在已有镜像基础上进行容器层修改然后commit为新的镜像
- 故引入了DockerFile直接根据指令和参数生成镜像
- 根据DockerFile构建Docker镜像,然后根据Docker镜像创建Docker实例,Docker镜像是包含服务环境和配置的模板,Docker容器是运行镜像内服务的一个简易版的Linux系统![[Pasted image 20241108092112.png]]![[Pasted image 20241108094442.png]]
- 创建镜像的两种方式
- DockerFile构建过程
- DockerFiel执行流程
- 把之前多次commit的操作打包为一个Dockerfile文件,由Docker自动执行
- 当docker build根据Dockerfile构建镜像时,先创建一个基础镜像,然后顺序执行每条指令,对每一条指令创建一个容器层执行指令的操作,然后commit提交为镜像层,然后基于提交的镜像再创建一个容器层,继续处理下一条指令,直到全部指令执行完成
- ![[Pasted image 20241108091722.png]]
- DockerFile常用保留字
DockerFile文件中保留字后面至少一个参数,且保留字建议大写,不一定要大写,但创建的Dockerfile文件的D必须大写- FROM 基础镜像,指定当前镜像基于哪个镜像,必须是一个已经存在的镜像作为模板,且在第一条,构建时执行
- MAINTAINER 镜像维护者姓名和邮箱
- RUN 容器构建(docker build)时执行的命令![[Pasted image 20241108094946.png]]
- EXPOSE 当前容器对外暴露的端口,容器运行时执行
- WORKDIR 指定在创建容器后,终端默认登录进来的工作目录
- USER 指定镜像以什么用户身份去执行,默认是root
- ENV 在构建镜像中设置环境变量,可以在RUN指令和其他指令中使用 ![[Pasted image 20241108095408.png]]
- ADD 将宿主机目录下的文件拷贝进镜像且会自动处理URL和解压tar包,相当于拷贝+解压,宿主机的相对路径
- COPY 将宿主机命令下的文件拷贝进镜像,仅仅拷贝 ![[Pasted image 20241108095855.png]]
- VOLUME 指定容器数据卷,用于数据持久化工作,运行容器时执行
- CMD 指定容器启动后要干的事情,会被run之后的参数覆盖![[Pasted image 20241108100030.png]]
- ENTRYPOINT 也是指定容器启动后要干的事情,但不会被参数覆盖,且CMD相当于在ENTRYPOINT后添加参数![[Pasted image 20241108100417.png]]
- RUN是在docker build时运行的指令,CMD是在docker run时运行的指令![[Pasted image 20241108094524.png]]![[Pasted image 20241108100824.png]]
- DockerFile常用保留字案例
- 自定义镜像
- 使用DockerFile自定义镜像,先创建一个Dockerfile文件(D必须大写),在Dockerfile文件中使用保留字编写镜像,然后使用docker build -t IMAGE:TAG . 来根据当前文件夹下的Dockerfile文件构建指定的镜像文件,此时会顺序执行Dockerfile文件下的每一行命令并生成镜像层,最后生成镜像保存到本地仓库中,然后使用docker run 就可以启动镜像,创建一个运行该镜像的Linux环境,还可以在后面添加一些命令
- 编写DockerFile
- 文件名必须叫 Dockerfile![[Pasted image 20241108101606.png]]
- ADD保留字是拷贝+解压,使用宿主机的相对路径
- RUN保留字是在构建Docker镜像时执行的命令,相当于在终端的命令行中执行的命令,有两种格式,推荐使用 shell 命令行格式,此时一个RUN代表运行一个命令行命令
- CMD保留字中的参数是在Docker容器运行后执行的命令,且只会执行一个CMD,当多个时会被覆盖,只执行最后的CMD,且run之后的命令参数也会覆盖CMD
- 构建Docker镜像
- docker build -t 新镜像名字:TAG .(Dockerfile文件目录)
- 要指定Dockerfile文件所在的目录,. 表示当前目录,其会自动在目录下找到Dockerfile文件并进行构建,要指定构建出镜像的名字和TAG,否则将会生成虚悬镜像,此时无意义,要通过 docker image prune删除所有的虚悬镜像
- 根据Dockerfile文件构建Docker镜像时,会顺序执行每一条指令,每一条指令的运行都是一个镜像层,不断叠加为最终镜像
- 运行Docker容器
- 构建后的Docker镜像会保存在本地仓库中,直接docker run 运行镜像生成容器即可
- 运行后会执行CMD保留字中的命令,且会被run后面的命令覆盖
- 虚悬镜像 dangling image
- 镜像名和TAG版本标签全为none的镜像为虚悬镜像,已经失去了意义,必须删除,通过 docker image prune 来删除本地仓库中 的所有虚悬镜像
- 镜像仓库REPOSITORY和TAG版本标签全为 none 的IMAGE
- 在根据Dockerfile文件构建镜像时,不指定镜像的名和TAG标签,此时生成的镜像就是虚悬镜像,即镜像名和TAG标签均为none的镜像为虚悬镜像
- 根据Dockerfile文件构建镜像时,docker build -t 镜像名字:TAG . ,必须指定构建镜像的名字和版本标签TAG,否则将会生成虚悬镜像(镜像名字和TAG全为none),此时是无意义的且会占用空间,故必须删除,通过 docker image prune 来删除所有的虚悬镜像
- 自定义镜像
3. Docker微服务实战
- 是什么
- 在Docker容器中运行SpringBoot创建的微服务,前提要先将微服务构建为一个镜像,通过Dockerfile文件进行构建
- 怎么做
- 先使用SpringBoot编写一个微服务,然后打成 jar 包,并上传到docker所在的宿主机中,然后编写Dockerfile文件,在Dockerfile文件中实现运行jar包的操作,然后构建Dockerfile文件生成镜像文件
- jar包和Dockerfile文件在同一个目录下,因为在Dockerfile文件中要使用 ADD 将相对路径下的文件拷贝到指定的容器目录下并解压,将相对路径下的jar包拷贝到容器中并解压
- 在Dockerfile文件中通过 RUN 来在构建时如果命令行运行传入的jar包
- Dockerfile文件的内容,在Dockerfile 文件中实现运行jar包的操作![[Pasted image 20241108125843.png]]
- 1、创建一个微服务并打包为jar包;2、将微服务jar包上传到Docker所在的宿主机上;3、构建Dockerfile文件,将jar包上传到容器上并运行;4、根据Dockerfile文件构建镜像;5、根据镜像生成容器来运行镜像文件![[Pasted image 20241108130125.png]]
4. Docker-network网络
- 是什么
- 每台机器都会有两个IP地址,其中一个是自身网卡的IP地址,应该是local本地IP地址,如果有选择相关虚拟化的服务安装系统后,启动网卡会发现一个以网桥连接的私网地址virbr0网卡,有固定的IP地址,是做虚拟网桥使用的,为连接其上的虚拟网卡提供NAT访问外网功能![[Pasted image 20241108131659.png]]
- 也就是说,主机自带一个自身的网卡IP和一个本地IP,然后当启动虚拟化技术时,也会为其虚拟一个网桥并配置IP,此时就可以通过这个IP访问虚拟机
- Docker网络命令
- docker network ls:查看docker的网络模式,默认创建3大网络模式下(bridge、host、null)的三个network:bridge、host、none
- docker network COMMAND;均是docker network开头![[Pasted image 20241108132340.png]]
- 能干嘛
- 容器间的互联和通信以及端口映射
- 容器IP变动时可以通过服务名直接网络通信而不受IP变动影响,使用自定义网络,自定义网络自动维护了IP和服务名的映射,此时就可以通过服务名实现容器之间的通信
- Docker是虚拟化容器技术,创建Docker后会为其虚拟一个网桥实现访问
- 网络模式(bridge|host|none|container)
- 在创建容器时通过 --net 来指定容器的网络模式,不指定默认为bridge模式:为每个新建的容器分配并设置独立的IP,并创建 eth0和veth接口与docker0网桥相连
- 默认虚拟网桥bridge模式,为每个容器分配并设置IP,并将容器通过eth0和veth连接到docker0上
- host模式:容器不会虚拟出自己的网卡,也不会配置IP,而是使用宿主机的IP和端口,使用主机的IP和端口,且内部的容器会使用自动指定的PORT,如果占用则自动递增
- none模式:容器有独立的网络空间,但并没有任何网络设置,如分配IP等,要自己配置,基本不用,只有一个 local,需要自己配置
- container模式:新创建的容器不会直接创建IP,而是和指定的容器共享IP和端口,与指定的容器共享IP和PORT,当容器关闭时也会取消共享
- 总体介绍![[Pasted image 20241108133935.png]]![[Pasted image 20241108134018.png]]
- Docker网络底层IP与容器映射是动态的
- 当启动一个容器时,不指定–network就是默认网桥bridge模式,会为每一个容器均分配一个IP地址,而且是动态分配的,如果某个IP的容器关闭,则此时该IP会分配给下一个容器,故容器访问容器写死IP,则会导致IP映射错误
- 即Docker容器底层分配的IP不是固定的,而是可能会变化的,每次启动容器均会随机动态分配一个未被占用的IP,当删除容器时就会回收该IP继续分配,故不可以使用固定的IP进行访问
- 不同的network就是不同的网段,通过 docker network create 来创建自定义网络模式,自动维护了容器分配的IP和容器名的映射,此时通过容器名就可以访问容器,而不需要使用动态的IP地址
- Docker网络模式
- bridge模式
- 启动docker后会创建一个docker0网桥,此时不指定–net默认使用bridge模式创建容器,每次都会给容器分配一个IP,以及一个eth0,且在bridge中有一个veth与其对应相连,从而实现容器与容器以及宿主机之间的通信,且IP的分配是动态的,分配一个未被占用的IP,当重新启动时就不一定是之前的IP了
- docker0网桥就是将主机和所有Docker容器的网络桥接为同一个网段,使得主机和容器之间可以相互通信![[Pasted image 20241108135704.png]]
- 因为创建容器时也会为其分配网桥为docker0,故所有的docker容器和宿主机之间均在同一个网络,通过docker0网桥相连![[Pasted image 20241108140128.png]]
- 在创建容器时默认bridge模式下会对每个容器分配一个网卡IP地址,并通过docker0网桥与宿主机和其他容器相连
- 每创建一个容器就会在网桥中创建一个veth接口,并在容器中创建一个eth0接口与veth接口相连,从而实现各个容器通过网桥和宿主机的通信
- 打开docker服务时会创建一个docker0网桥与宿主机相连,然后每创建一个容器就会在网桥中创建一个veth接口,并在容器中创建一个eth0接口与其相连,从而使得docker内各个容器与宿主机之间通信
- 每个容器内的eth0均会与宿主机中的某个veth相连
- bridge模式下如果不使用端口映射则必须访问网桥中veth接口对应的IP地址才可以访问容器,而如果使用了端口映射,则直接访问宿主机的对应端口就可以映射到容器的对应端口
- 当容器启动时,其内的服务会自动根据端口号运行
- host模式
- host模式下不会为容器配置IP,而是使用宿主机的IP,此时使用端口映射是失效的,而且容器内的网络配置和宿主机的完全相同,且端口映射以默认的为主,如果被占用则递增,host模式下使用宿主机的网络配置,此时的端口映射是失效的,容器中的服务使用默认的端口号进行运行
- 直接使用宿主机的IP地址作为容器的IP地址,不需要额外地址转换,即不为容器分配单独的IP地址,使用宿主机的地址
- host模式下容器不会虚拟出自己的网卡IP,而是使用宿主机的IP和端口
- 当使用host模式时,使用 -p 端口映射会出现warning警告,且不会生效,因为容器与宿主机共用IP,故不需要端口映射,只需要指定容器的PORT即可![[Pasted image 20241108151916.png]]
- none模式
- 禁用网络功能,只有 local 标识
- 不为Docker容器做任何网络配置,只有一个local,需要自己配置网卡和IP![[Pasted image 20241108153110.png]]
- container模式
- 和另一个容器共享网络配置,使用同一个eth0的接口配置与docker0网桥的,使用同一个IP地址进行访问
- 在创建容器时使用 --network container 使用container模式,此时不会为该容器配置IP,而是和指定容器共享网络配置![[Pasted image 20241108154241.png]]
- container模式下,两个容器共享同一个网络配置,要注意端口映射的冲突,不可以映射到同一个端口中,因为共享同一个网络配置
- 而且如果此时被共享的容器如果关闭,则共享的容器的网络配置也会消失,就变为了none模式,当被共享的容器关闭时,此时网络配置也会消失
- 自定义网络模式(自动维护容器名和IP的映射)
- 通过 docker network create xxx 来创建一个自定义网络
- 默认bridge网络模式的缺点
- 当两个容器在同一个网段时,此时就可以通过IP地址进行访问,其会通过网桥bridge访问到指定的容器,但在bridge默认模式下,每次给容器分配的IP地址是动态的,会将当前未被占用的IP地址分配给容器,如果容器重新启动则会导致IP地址发生改变,故不可以固定IP地址去访问容器,应该通过容器名去访问同一个网桥网段下的容器,但在bridge模式下如果使用容器名去访问容器,则无法连通
- 在默认的bridge模式下创建容器时,此时IP地址是随机动态分配的,而且会发生变化,可以通过IP地址实现容器通信,但当容器重启后IP地址就会发生变化,故无法固定IP,故引入了自定义网络,实现通过容器名进行容器之间的通信,自动维护容器名和IP的映射
- 自定义网络实现通过容器名通信
- 自定义网络本身就维护了容器名和IP的对应关系(ip和域名都能通)
- 使用 docker network create 创建的网络默认是bridge桥接驱动模式
- 此时将容器加入到自定义网络中就可以实现通过容器名来进行通信
- 小总结
- 当启动docker服务时就会创建一个 docker0 的网桥,且一端与宿主机相连,当创建容器时不使用–network指定模式时会默认使用bridge网桥模式,此时会为容器单独配置网络IP,在容器内创建一个eth0接口,并在docker0网桥中创建一个veth接口与其相连,从而实现当前容器与网桥和宿主机在同一个网段,此时每加入一个容器都会生成一对接口实现相连,如果想访问容器,可以通过为容器分配的IP进行访问,或者使用-p实现与宿主机的端口映射,此时访问宿主机的端口就会映射到容器的端口,此时容器底层IP是动态分配的,每次启动都会随机分配一个未被占用的IP
- 当使用host模式时,此时不为容器配置网络,而是与宿主机使用相同的网络配置
- 当使用none模式时,此时不会为容器配置网络,需要自己配置,容器内只有一个local
- 当使用container模式时,此时也不会为容器配置网络,而是与指定的容器共享同一个eth0网络配置,且指定容器如果关闭,则当前容器的网络配置也会消失
- bridge模式
相关文章:

985研一学习日记 - 2024.11.8
一个人内耗,说明他活在过去;一个人焦虑,说明他活在未来。只有当一个人平静时,他才活在现在。 日常 1、起床 2、健身 3、LeetCode刷了2题 买卖股票的最佳时机 将最大利润拆分为每天的利润之和,仅仅收集每天的正利润…...
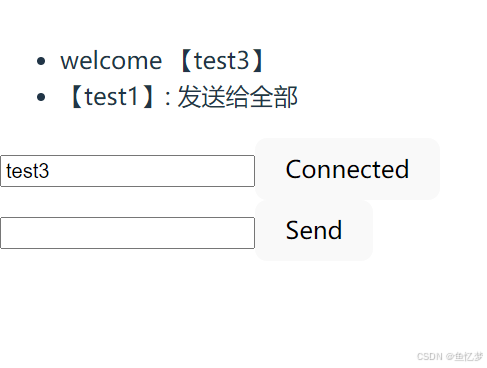
编写一个基于React的聊天室
前言 此前已经编写了一版后端的im,此次就用其作为服务端,可查看参考资料1 代码 使用WebStorm创建React项目 安装依赖包 PS C:\learn-demo\front\chatroom> npm installadded 183 packages, and audited 184 packages in 16s43 packages are looki…...

[前端]NodeJS常见面试题目
什么是非阻塞 I/O? Node.js 如何实现非阻塞 I/O? 非阻塞 I/O 是一种编程模式,它允许 I/O 操作(如读取文件、网络请求等)在执行时不阻塞程序的其余部分。换句话说,当一个 I/O 操作发起后,程序可以立即继续执行其他任…...

【实测可用】Sublime Text4 4180 windows 已测可用
------------------测试时间2024年11月7日------------------- 打开浏览器进入网站: 点击进入修改网站打开sublime text4安装目录选择文件sublime_text.exe搜索80 79 05 00 0f 94 c2更改为c6 41 05 01 b2 00 90(第一个匹配到的)保存文件命名为sublime_text.exe并…...

JAVA日期加减运算 JsonObject 转换对象List
1.用java.util.Calender来实现 Calendar calendarCalendar.getInstance(); calendar.setTime(new Date());System.out.println(calendar.get(Calendar.DAY_OF_MONTH));//今天的日期calendar.set(Calendar.DAY_OF_MONTH,calendar.get(Calendar.DAY_OF_MONTH)1);//让日期加1 Sy…...

在 PostgreSQL 中,重建索引可以通过 `REINDEX` 命令来完成
在 PostgreSQL 中,重建索引 在 PostgreSQL 中,重建索引可以通过 REINDEX 命令来完成。 重建索引的主要目的是提高查询性能,尤其是在数据频繁更新的情况下。以下是重建索引的基本语法和示例: 基本语法 REINDEX INDEX index_name…...

SQL相关常见的面试题
SQL(Structured Query Language)是数据库管理中不可或缺的一部分,因此在技术面试中经常会被问到与 SQL 相关的问题。以下是一些常见的 SQL 面试题及其答案。 基础概念 什么是 SQL? SQL 是一种用于管理和处理关系型数据库的标准语…...

Vue数据响应式原理
前言 Vue是一个结构的框架,也就是 数据层、视图层、数据-视图层;响应式的原理就是实现当数据更新时,视图层也要相应的更新 响应式实现 基于发布订阅模式和数据劫持实现 1.发布订阅模式:vue使用发布订阅模式来实现数据变动的通知和更新 2…...
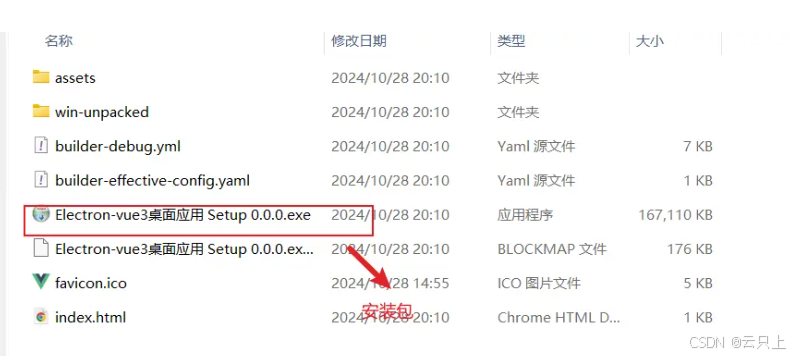
Electron + Vue3 开发桌面应用+附源码
什么是 Electron? Electron 是一个使用 JavaScript、HTML 和 CSS 构建跨平台桌面应用程序的框架。它由 GitHub 开发并维护,允许开发者使用现代 Web 技术创建原生应用程序。Electron 结合了 Chromium 渲染引擎和 Node.js 运行时环境,使得开发…...
网页服务器框架)
Webserver(5.2)网页服务器框架
目录 网页服务器服务器编程基本框架两种高效的事件处理模式reactor模式proactor模式同步IO模拟Proactor模式 网页服务器 接收、存储,处理来自客户端的HTTP请求,并对其请求做出HTTP响应。 Web服务器底层是基于tcp协议的,因为要保证数据安全。…...

股指期货交易中,如何应对震荡行情?
在股指期货交易中,趋势和震荡是市场波动的两种基本形态。然而,对于许多交易者来说,如何在趋势交易中有效应对震荡行情,却是一个令人头疼的问题。本文将结合相关链接内容,为您详细解读期货交易中如何应对震荡行情。 一…...

理想汽车Android面试题及参考答案
请解释一下 Android 中的 Handler 是如何工作的 在 Android 中,Handler 主要用于在不同线程之间进行通信,特别是在主线程(UI 线程)和工作线程之间。 Handler 是基于消息队列(MessageQueue)和 Looper 来工作…...

【数据集】【YOLO】【目标检测】口罩佩戴识别数据集 1971 张,YOLO佩戴口罩检测算法实战训练教程!
数据集介绍 【数据集】口罩佩戴检测数据集 1971 张,目标检测,包含YOLO/VOC格式标注。 数据集中包含1种分类:{0: face_mask},佩戴口罩。 数据集来自国内外图片网站和视频截图。 检测场景为城市街道、医院、商场、机场、车站、办…...

前端将后端返回的文件下载到本地
vue 将后端返回的文件地址下载到本地 在 template 拿到后端返回的文件路径 <el-button link type"success" icon"Download" click"handleDownload(file)"> 附件下载 </el-button>在 script 里面写方法 function handleDownload(v…...

GISBox VS ArcGIS:分别适用于大型和小型项目的两款GIS软件
在现代地理信息系统(GIS)领域,有许多大家耳熟能详的GIS软件。它们各自具有独特的优势,适用于不同的行业需求和使用场景。在众多企业和开发者面前,如何选择合适的 GIS 软件成为了一个值得深入思考的问题。今天ÿ…...
掌握分布式系统的38个核心概念
天天说分布式分布式,那么我们是否知道什么是分布式,分布式会遇到什么问题,有哪些理论支撑,有哪些经典的应对方案,业界是如何设计并保证分布式系统的高可用呢? 1. 架构设计 这一节将从一些经典的开源系统架…...

如何使用 VNC 服务器连接桌面
如何使用VNC软件去连接远程桌面系统呢? 一、什么是VNC? VNC(Virtual Network Computing,虚拟网络计算)是一种远程桌面共享协议,允许用户通过网络访问和控制远程计算机的桌面界面。VNC 使用的是一种基于图像的方式,将远程计算机的桌面环境发送到客户端的显示设备上,同时…...

算法每日练 -- 双指针篇(持续更新中)
介绍: 常见的双指针有两种形式,一种是对撞指针(左右指针),一种是快慢指针(前后指针)。需要注意这里的双指针不是 int* 之类的类型指针,而是使用数组下标模拟地址来进行遍历的方式。 …...
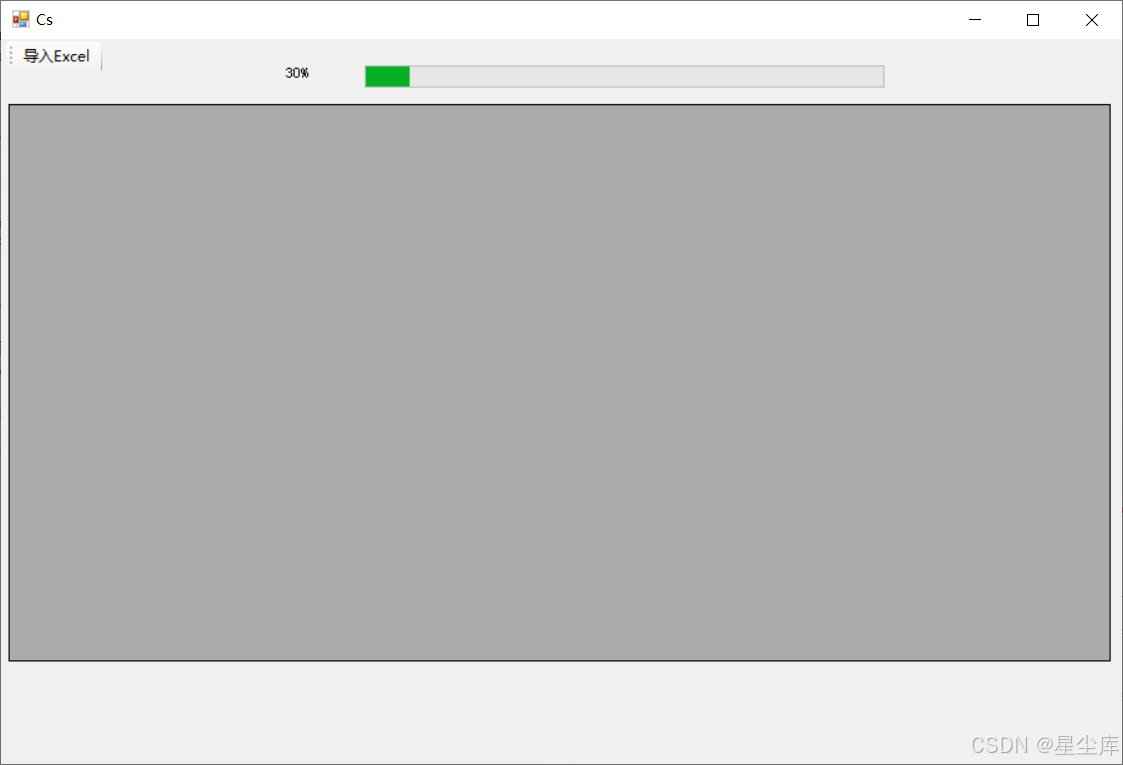
读取excel并且显示进度条
读取excel并且显示进度条 通过C#实现DataGridView加载EXCEL文件,但加载时不能阻塞UI刷新线程,且向UI显示加载进度条。 #region 左上角导入 private async void ToolStripMenuItem_ClickAsync(object sender, EventArgs e) { …...

MySQL多表查询习题
数据内容介绍 数据库中有两个表 内容如下: 习题 列出所有员工的姓名及其直接上级的姓名。列出受雇日期早于直接上级的所有员工的编号、姓名、部门名称。列出部门名称和这些部门的员工信息,同时列出那些没有员工的部门。列出在财务部工作的员…...

【C#vsPython·第一阶段】 Python 的运算符,有些地方真的“骚“
在 C# 里判断一个数在 0 到 10 之间,你得写 x > 0 && x < 10。 在 Python 里?直接写 0 < x < 10。对,就这么简单,编译器...哦不,解释器不会报错。 当我第一次看到这个写法的时候,我心…...

ViGEmBus:终极Windows游戏控制器模拟解决方案,彻底改变游戏输入体验
ViGEmBus:终极Windows游戏控制器模拟解决方案,彻底改变游戏输入体验 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 在游戏开发和输入…...

音频智能切片工具:快速解放双手的终极音频分割解决方案
音频智能切片工具:快速解放双手的终极音频分割解决方案 【免费下载链接】audio-slicer A simple GUI application that slices audio with silence detection 项目地址: https://gitcode.com/gh_mirrors/aud/audio-slicer 还在为处理冗长的音频文件而烦恼吗&…...

实战指南:如何为nvm-windows项目配置专业级持续集成流水线
实战指南:如何为nvm-windows项目配置专业级持续集成流水线 【免费下载链接】nvm-windows A node.js version management utility for Windows. Ironically written in Go. 项目地址: https://gitcode.com/gh_mirrors/nv/nvm-windows nvm-windows作为Windows平…...

5步解锁显卡隐藏性能:NVIDIA Profile Inspector全面指南
5步解锁显卡隐藏性能:NVIDIA Profile Inspector全面指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 想要让显卡发挥100%性能潜力吗?NVIDIA Profile Inspector作为一款专业的…...

桌面整理神器:NoFences让你的Windows桌面焕然一新 [特殊字符]
桌面整理神器:NoFences让你的Windows桌面焕然一新 🚀 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是不是也厌倦了Windows桌面上杂乱无章的图标&a…...

Sendwithus模板与现代邮件客户端兼容性测试:终极解决方案
Sendwithus模板与现代邮件客户端兼容性测试:终极解决方案 【免费下载链接】templates Sendwithus Open Source Email Templates 项目地址: https://gitcode.com/gh_mirrors/temp/templates Sendwithus Open Source Email Templates是一套强大的开源邮件模板集…...

5分钟掌握BilibiliDown音频提取:从B站视频轻松获取无损音乐
5分钟掌握BilibiliDown音频提取:从B站视频轻松获取无损音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirr…...

JetBrains IDE终极代码高亮指南:MultiHighlight让复杂代码一目了然
JetBrains IDE终极代码高亮指南:MultiHighlight让复杂代码一目了然 【免费下载链接】MultiHighlight Jetbrains IDE plugin: highlight identifiers with custom colors 🎨💡 项目地址: https://gitcode.com/gh_mirrors/mu/MultiHighlight …...
 方法陷阱:为什么你应该始终使用 split(regex, -1))
Java String.split() 方法陷阱:为什么你应该始终使用 split(regex, -1)
核心问题 Java 的 String.split(regex) 默认等价于 split(regex, 0),会静默丢弃尾部的所有空字符串。这个设计在结构化数据处理中是灾难性的。 "A,B,C,".split(","); // ["A", "B", "C"] 长度 3 ❌ 尾部…...