Python日志分析与故障定位
Python日志分析与故障定位
目录
- 📊 分布式系统日志分析:ELK Stack与Fluentd
- ⚡ 实时日志流处理与异常检测
- 🐍 使用Python分析并处理海量日志数据
- 🚨 自动化故障检测与报警系统
- 🔍 故障根因分析(Root Cause Analysis, RCA)
1. 📊 分布式系统日志分析:ELK Stack与Fluentd
在分布式系统中,日志数据是诊断故障、监控应用性能和分析系统行为的重要来源。随着微服务架构的普及,传统的单一日志文件管理方式已不再适应复杂的分布式环境。ELK Stack(Elasticsearch, Logstash, Kibana)和Fluentd是两种广泛使用的日志分析平台,能够帮助运维人员高效地收集、存储、分析和可视化海量日志数据。
ELK Stack架构与使用
- Elasticsearch:一个开源的分布式搜索引擎,通常用于存储和查询日志数据。它能够处理大规模的实时数据,并为后续的分析提供支持。
- Logstash:一个强大的日志收集、过滤和转发工具,负责从各种日志源收集数据并进行预处理,如过滤、转换和格式化。
- Kibana:一个数据可视化工具,专门用来展示从 Elasticsearch 中提取的数据。通过 Kibana,用户可以创建仪表盘、图表和实时视图,帮助直观地分析日志数据。
一个典型的 ELK Stack 工作流如下所示:
- Logstash 收集来自不同服务的日志数据,并通过预定义的过滤规则处理数据。
- 经过处理后的日志数据被存储到 Elasticsearch 中,供后续查询。
- Kibana 用于展示和可视化 Elasticsearch 中存储的数据,帮助用户分析系统行为。
使用ELK Stack的优势在于,它可以通过强大的数据索引和查询功能,迅速定位日志中的异常行为或错误,从而加速故障排查过程。
Fluentd:日志收集和转发
Fluentd 是一种开源的数据收集器,旨在统一不同数据源的日志格式,并将其转发到指定的目标,如 Elasticsearch、Kafka 或其他分析平台。Fluentd 的主要优势在于其高度的可扩展性和丰富的插件支持,使得它能够灵活地适应多种日志收集需求。
# Fluentd 配置示例
<source>@type tailpath /var/log/app/*.logpos_file /var/log/td-agent/app.postag app.logsformat json
</source><match app.logs>@type elasticsearchhost localhostport 9200logstash_format trueflush_interval 5s
</match>
这个配置会将 /var/log/app/*.log 目录下的日志文件收集并转发到 Elasticsearch,进行进一步的分析和存储。Fluentd 提供了强大的数据处理能力,能够将各种格式的日志数据统一标准化后进行处理。
通过ELK Stack和Fluentd,分布式系统中的日志管理变得高效而灵活,可以处理大量的日志数据并实现实时监控与分析。
2. ⚡ 实时日志流处理与异常检测
在分布式环境中,处理海量的日志数据是一个具有挑战性的任务。尤其是对于实时数据流的处理和异常检测,如何快速捕获异常事件并发出警报,直接关系到系统的稳定性和运维效率。
实时日志流处理
日志数据的实时处理要求能够在数据产生的瞬间对其进行捕获、处理和分析。使用工具如 Apache Kafka、Fluentd 等进行日志流的处理和转发,能够实现实时日志数据的收集和流转。通过这种方式,可以保证日志数据在产生后几乎没有延迟地进行处理。
Kafka 是一种分布式流处理平台,常被用于实时数据流的传输和处理。Kafka 的高吞吐量和容错能力使得它非常适合用于实时日志数据的收集。
# Kafka 配置示例
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic app_logs --from-beginning
通过 Kafka,日志数据流可以传递到多个消费端,进行实时分析和监控。
异常检测
异常检测是日志分析中的核心任务之一。通过对日志数据的实时流处理,可以利用 Python 和机器学习算法对异常模式进行检测,自动识别系统中的故障或异常行为。
使用 Scikit-learn 或 TensorFlow 等机器学习框架,结合日志数据的特征(如错误码、响应时间等),可以训练异常检测模型。这些模型可以通过 Python 脚本进行实时推断,检测出系统中的潜在问题。
from sklearn.ensemble import IsolationForest
import pandas as pd# 示例:加载日志数据
log_data = pd.read_csv('logs.csv')# 特征:错误代码、响应时间
X = log_data[['error_code', 'response_time']]# 使用Isolation Forest进行异常检测
model = IsolationForest(contamination=0.05)
log_data['anomaly'] = model.fit_predict(X)# 输出异常记录
anomalies = log_data[log_data['anomaly'] == -1]
print(anomalies)
通过这种方式,可以实时监测系统日志,发现异常行为并采取相应的行动。
3. 🐍 使用Python分析并处理海量日志数据
Python 是进行日志分析的强大工具,尤其是对于海量日志数据的处理。利用 Python 中的各种库,如 Pandas、NumPy、Matplotlib 和 Loguru 等,可以高效地处理和分析大规模日志数据。
使用Pandas进行日志数据清洗与分析
在日志数据分析过程中,通常需要对日志进行清洗、转换和格式化。Pandas 是处理结构化数据的首选库,可以将日志数据转换为 DataFrame 格式,方便进一步分析。
import pandas as pd# 读取日志文件
log_data = pd.read_csv('application_logs.csv')# 清洗数据:去除空值
log_data = log_data.dropna()# 统计每个错误码的出现频次
error_count = log_data['error_code'].value_counts()
print(error_count)
使用Matplotlib进行数据可视化
通过 Python 的 Matplotlib 和 Seaborn 等库,可以将日志数据转化为直观的图表,帮助运维人员快速识别系统中的异常趋势。
import matplotlib.pyplot as plt# 绘制错误码的频次图
log_data['error_code'].value_counts().plot(kind='bar')
plt.title('Error Code Frequency')
plt.xlabel('Error Code')
plt.ylabel('Frequency')
plt.show()
通过这种方式,可以非常方便地分析和呈现日志数据,帮助快速定位问题。
4. 🚨 自动化故障检测与报警系统
自动化故障检测与报警系统在现代运维中至关重要,它能实时监控系统状态,一旦出现异常便立即通知运维人员。结合日志分析技术,Python 可以用来构建智能的报警系统,提升运维效率,减少故障响应时间。
构建自动化报警系统
通过结合日志分析结果与监控工具,可以基于 Python 构建自动化报警系统。例如,可以通过检查日志中的错误信息,一旦出现特定的错误模式或达到阈值,就触发报警。
import smtplib
from email.mime.text import MIMEText# 配置SMTP服务器信息
smtp_server = 'smtp.example.com'
smtp_port = 587
sender = 'alert@example.com'
receiver = 'admin@example.com'# 检查日志中的异常事件
def send_alert(message):msg = MIMEText(message)msg['Subject'] = 'System Alert'msg['From'] = sendermsg['To'] = receiverwith smtplib.SMTP(smtp_server, smtp_port) as server:server.starttls()server.login(sender, 'password')server.sendmail(sender, receiver, msg.as_string())# 如果日志中发现错误,触发报警
if 'error' in log_data['error_code'].values:send_alert('Critical error detected in the system logs!')
通过这种方式,可以在系统出现问题时及时通知运维人员,避免延误响应时间。
5. 🔍 故障根因分析(Root Cause Analysis, RCA)
故障根因分析(RCA)是一种系统性的方法,用于识别和解决故障发生的根本原因。通过对日志数据的深入分析,可以帮助运维人员确定故障发生的真正原因,从而避免类似问题的再次发生。
根因分析流程
- 收集数据:通过 ELK Stack、Fluent
d 等工具收集故障发生时的日志数据。
2. 数据分析:利用 Python 脚本进行日志数据的深度分析,识别异常模式和问题区域。
3. 确定根因:根据日志数据中的异常信息,结合系统状态和运行环境,确定故障的根本原因。
# 查找日志中最常见的错误模式
error_patterns = log_data[log_data['error_code'] == '500']
print(error_patterns)
通过这种系统化的分析,运维人员可以快速找到问题的核心,减少故障发生的频率,并提升整体系统的稳定性。
相关文章:

Python日志分析与故障定位
Python日志分析与故障定位 目录 📊 分布式系统日志分析:ELK Stack与Fluentd⚡ 实时日志流处理与异常检测🐍 使用Python分析并处理海量日志数据🚨 自动化故障检测与报警系统🔍 故障根因分析(Root Cause An…...

w029基于springboot的网上购物商城系统研发
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹赠送计算机毕业设计600个选题excel文件࿰…...

Uniapp全局文件执行顺序详解
Uniapp全局文件执行顺序详解 在Uni-App项目中,全局文件的执行顺序对于深入理解应用的启动和初始化流程至关重要。本文将详细阐述这些文件的执行顺序,并提供相应的示例代码,以便开发者更好地理解和应用。 1. index.html 文件描述࿱…...
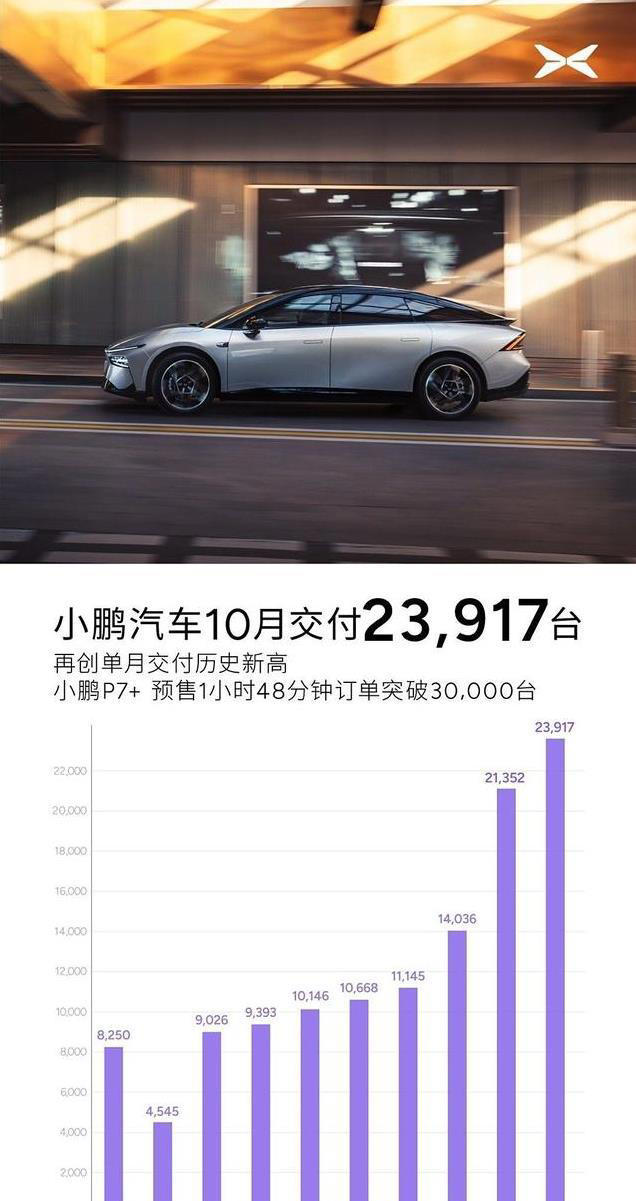
车企死亡加速,买车看好这三条线
文 | AUTO芯球 作者 | 雷慢 真不是我危言耸听, 新能源车是真不能随便买啊, 就在这几天,哪吒被传出要裁员70%, 多少车主,多少员工和家庭要失眠了, 哪吒也回应了,说没有裁员,只是精…...

SpringClud一站式学习之Eureka服务治理(二)
SpringClud一站式学习之Eureka服务治理 引言1. 搭建Eureka Server1.1. 添加Eureka Server依赖1.2. 添加 Eureka Server注解1.3. 配置Eureka Server1.4. 运行Eureka Server 2. 搭建Eureka Client 服务提供者2.1. 添加依赖2.2. 添加注解2.3. 配置Eureka Client2.4. 启动服务 3. 搭…...

空间解析几何【上】
文章目录 两向量共线&三向量共面线段定比分点内积&外积&混合积内积(点积)外积(叉积)几何性质混合积轮换对称性对换改变一次符号线性性质几何性质球面方程特点空间平面参数方程行列式方程(点位式)向量式方程三点式方程行列式方程点法式一般式截距式法式方程离…...
Python 获取PDF的各种页面信息(页数、页面尺寸、旋转角度、页面方向等)
目录 安装所需库 Python获取PDF页数 Python获取PDF页面尺寸 Python获取PDF页面旋转角度 Python获取PDF页面方向 Python获取PDF页面标签 Python获取PDF页面边框信息 了解PDF页面信息对于有效处理、编辑和管理PDF文件至关重要。PDF文件通常包含多个页面,每个页…...

独孤思维:曾经副业赚大钱的人,怎么不见了
01 总有一双眼睛默默关注你。 别以为自己每天做项目,日更文章,没人看。 总会有人默默观察你。 看你能坚持多久,看多段时间,你是不是还在。 今天上午,有个2年前认识的副业同行,今天突然跟我发消息。 说…...

OpenGL 异常处理-glCreateShader失败
【1】glCreateShader创建顶点着色器时候报错,如下 【2】原因分析 初始化失败,你使用一个扩extension loader library来访问现代OpenGL,当需要初始化它时,加载器需要一个当前的上下文来加载 【3】解决办法 GLenum glew_err gle…...

【el-pagination的使用及修改分页组件的整体大小修改默认样式的宽度详细教程】
今天遇到个bug,使用element-puls中的分页的时候,长度会超出盒子,今天教大家如何修改el-pagination的宽度,以及修改分页组件的整体大小 直接修改 style"width: 100%; margin-top: 10px"不生效 控制台修改el-pagination…...

Uniapp的学习
uniapp的内容和vue网页开发会有很多区别,但是都是基于vue开发的,大多数业务还是在vue打交道,但是这些uniapp的特殊的知识点也是要掌握好的。 基本配置 创建uniapp项目 npx degit dcloudio/uni-preset-vue#vite-ts 项目名 :用于…...

C#-万物之父object、装箱拆箱
万物之父:object 基于里氏替换原则,可以用object容器装载一切类型的变量。可以用来表示不确定类型,作为函数参数类型 object是所有类型的基类 装箱拆箱 用object存值类型(装箱)→ 把值类型用引用类型存储,…...

AI大模型重塑软件开发流程:从自动化编码到智能协作的未来展望
目录 1. 引言:AI大模型的崛起与软件开发的变革 1.1 AI大模型的兴起与发展背景 1.2 软件开发的现状与痛点 1.3 AI大模型如何解决这些问题 2. AI大模型的工作原理与技术背景 2.1 什么是AI大模型? 2.2 深度学习与自然语言处理技术的演变 2.3 大模型…...

HTB:GreenHorn[WriteUP]
目录 连接至HTB服务器并启动靶机 使用nmap对靶机TCP端口进行开放扫描 再次使用nmap对这三个端口进行脚本、服务扫描 尝试先通过curl访问靶机80端口 将靶机IP与该域名写入hosts使DNS本地解析 使用浏览器访问greenhorn.htb 使用Wappalyzer插件查看该页面技术栈 尝试在sea…...

SelfAttention在Ascend上的实现
1 SelfAttention是什么? Self-Attention(自注意力)机制是深度学习领域的一种重要技术,尤其在自然语言处理(NLP)任务中得到广泛应用。它是 Transformer 架构的核心组成部分之一,由 Vaswani 等人…...

C#设计模式
文章目录 项目地址一、开放封闭原则1.1 不好的版本1.2 将BankProcess的实现改为接口1.3 修改BankStuff类和IBankClient类二、依赖倒置原则2.1 高层不应该依赖于低层模块2.1.1 不好的例子2.1.2 修改:将各个国家的歌曲抽象2.2 抽象不应该依于细节2.2.1 不同的人开不同的车(接口…...

仪表板展示|DataEase看中国:历年双十一电商销售数据分析
背景介绍 2024年“双十一”购物季正在火热进行中。自2009年首次推出至今,“双十一”已经成为中国乃至全球最大的购物狂欢节,并且延伸到了全球范围内的电子商务平台。随着人们消费水平的提升以及电子商务的普及,线上销售模式也逐渐呈现多元化…...

急着骂华为?我劝你别急
文 | AUTO芯球 作者 | 雷慢 赛力斯这下怒了! 要对那些华为黑、问界黑出手了, 就在这几天,赛力斯起诉了一批蓄意抹黑、散步虚假信息的人。 起因是什么,听我慢慢说, 今年7月,佛山一辆问界M7发生交通事故…...
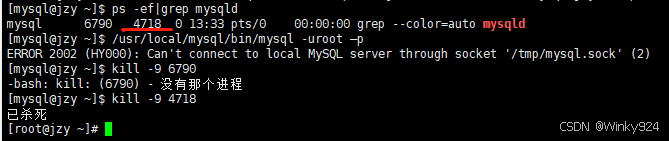
虚拟机linux7.9下安装mysql
1.MySQL官网下载安装包: MySQL :: Download MySQL Community Server https://cdn.mysql.com/archives/mysql-5.7/mysql-5.7.39-linux-glibc2.12-x86_64.tar.gz 2.解压文件: #tar xvzf mysql-5.7.39-linux-glibc2.12-x86_64.tar.gz 3.移动文件&#…...

【Linux】一篇文章轻松搞懂基本指令
本篇所有展示代码均是在超级用户的权限下进行的,如果不是超级用户并且一些命令执行的和我的不太一样,那么可以试着在对应命令前暂且加上sudo,我们在下一篇会讲权限问题,到时候再转换为普通用户。 本篇展示的内容是基于CentOs进行…...

低成本PHY芯片RTL8201F驱动移植实战:从LAN8742到RTL8201F的完整替换流程与验证
低成本PHY芯片RTL8201F驱动移植实战:从LAN8742到RTL8201F的完整替换流程与验证 在嵌入式以太网开发中,PHY芯片的选择往往需要在性能和成本之间取得平衡。当项目预算有限时,RTL8201F这类低成本PHY芯片就成为极具吸引力的选择。本文将详细介绍如…...

避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战
避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战 在医疗AI领域,癫痫脑电信号分析一直是个充满挑战的课题。许多开发者满怀信心地构建模型,却在验证阶段遭遇性能瓶颈——准确率停滞不前,误报率居…...

告别showSoftInput失效:一文读懂Android 11+的WindowInsetsController输入法控制
Android输入法控制演进:从InputMethodManager到WindowInsetsController的深度解析 在移动应用开发中,输入法交互是最基础却又最容易被忽视的细节之一。许多开发者都曾遇到过这样的场景:精心设计的登录界面,光标在输入框闪烁&#…...

δ - mem:提升大型语言模型内存效率,得分最高可达 1.31 倍!
快速通道可了解 arXiv 成为独立非营利组织的情况,也能直达康奈尔大学官网。同时,还能通过链接进行捐赠,支持 arXiv 的发展。搜索与导航提供了多种搜索途径,可在所有字段(标题、作者、摘要等)进行搜索。还有…...
)
【稀缺首发】Midjourney达达主义风格提示工程白皮书:含89组对比实验数据+12个独家种子编号(限前500名下载)
更多请点击: https://intelliparadigm.com 第一章:达达主义在AI图像生成中的哲学解构 达达主义并非技术流派,而是一场对逻辑、秩序与意义权威的激进质疑——这一精神正悄然渗透至当代AI图像生成的核心机制中。当Stable Diffusion接收“一只会…...

Obsidian智能模板终极指南:3步打造高效笔记自动化系统
Obsidian智能模板终极指南:3步打造高效笔记自动化系统 【免费下载链接】Templater A template plugin for obsidian 项目地址: https://gitcode.com/gh_mirrors/te/Templater Templater插件是Obsidian生态系统中功能最强大的智能模板解决方案,它能…...

终极指南:如何为你的Mac鼠标安装强大定制功能
终极指南:如何为你的Mac鼠标安装强大定制功能 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix Mac Mouse Fix是一款革命性的开源工具…...

AI助手API开发资源全指南:从入门到实战的宝藏清单
1. 项目概述:一个为AI助手API开发者量身打造的“藏宝图”如果你正在或打算基于OpenAI的Assistant API、Anthropic的Claude API,或是其他主流AI平台的助手接口来构建应用,那么你大概率会遇到一个经典困境:官方文档虽然详尽…...

Arm Fast Models中VGIC架构与中断虚拟化解析
1. Arm Fast Models中的VGIC架构解析虚拟通用中断控制器(Virtual Generic Interrupt Controller, VGIC)是Armv7/v8架构虚拟化扩展的核心组件之一。在Fast Models仿真环境中,Iris组件通过精确建模实现了VGIC的完整功能,包括:物理中断与虚拟中断…...

独立开发者如何利用 Taotoken 以更低成本试验多种 AI 模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 以更低成本试验多种 AI 模型能力 对于独立开发者或小型工作室而言,在产品开发的早期阶段…...