【大数据学习 | kafka高级部分】文件清除原理
2. 两种文件清除策略
kafka数据并不是为了做大量存储使用的,主要的功能是在流式计算中进行数据的流转,所以kafka中的数据并不做长期存储,默认存储时间为7天
那么问题来了,kafka中的数据是如何进行删除的呢?
在Kafka中,存在数据过期的机制,称为data expire。如何处理过期数据是根据指定的policy(策略)决定的,而处理过期数据的行为,即为log cleanup。
在Kafka中有以下几种处理过期数据的策略:
-
log.cleanup.policy=delete(Kafka中所有用户创建的topics,默认均为此策略)
-
根据数据已保存的时间,进行删除(默认为1周)
-
根据log的max size,进行删除(默认为-1,也就是无限制)
-
log.cleanup.policy=compact(topic __consumer_offsets 默认为此策略)
-
根据messages中的key,进行删除操作
-
在active segment 被commit 后,会删除掉old duplicate keys
- 无限制的时间与空间的日志保留
自动清理Kafka中的数据可以控制磁盘上数据的大小、删除不需要的数据,同时也减少了对Kafka集群的维护成本。
那Log cleanup 在什么时候发生呢?
-
首先值得注意的是:log cleanup 在partition segment 上发生
-
更小/更多的segment,也就意味着log cleanup 发生的频率会上升
-
Log cleanup 不应该频繁发生=> 因为它会消耗CPU与内存资源
- Cleaner的检查会在每15秒进行一次,由log.cleaner.backoff.ms 控制
2. log.cleanup.policy=delete(日志删除)
log.cleanup.policy=delete 的策略,根据数据保留的时间、以及log的max size,对数据进行cleanup。控制数据保留时间以及log max size的参数分别为:
-
log.retention.hours:指定数据保留的时常(默认为一周,168)
-
将参数调整到更高的值,也就意味着会占据更多的磁盘空间
-
更小值意味着保存的数据量会更少(假如consumer 宕机超过一周,则数据便会再未处理前即丢失)
-
log.retention.bytes:每个partition中保存的最大数据量大小(默认为-1,也就是无限大)
- 再控制log的大小不超过一个阈值时,会比较有用
在到达log cleanup 的条件后,cleaner会自动根据时间或是空间的规则进行删除,新数据仍写入active segment:

针对于这个参数,一般有以下两种使用场景,分别为:
-
log保留周期为一周,根据log保留期进行log cleanup:
-
log.retention.hours=168 以及 log.retention.bytes=-1
-
log保留期为无限制,根据log大小进行进行log cleanup:
- log.retention.hours=17520以及 log.retention.bytes=524288000
其中第一个场景会更常见。
2. Log Compaction(日志合并)
Log compaction用于确保:在一个partition中,对任意一个key,它所对应的value都是最新的。
这里举个例子:我们有个topic名为employee-salary,我们希望维护每个employee当前最新的工资情况。
左边的是compaction前,segments中的数据,右边为compaction 后,segments中的数据,其中有部分key对应的value有更新:

可以看到在log compaction后,相对于更新后的key-value message,旧的message被删除。
Log Compaction 有如下特点:
-
messages的顺序仍然是保留的,log compaction 仅移除一些messages,但不会重新对它们进行排序
-
一条message的offset是无法改变的(immutable),如果一条message缺失,则offset会直接被跳过
- 被删除的records在一段时间内仍然可以被consumers访问到,这段时间由参数delete.retention.ms(默认为24小时)控制
需要注意的是:Kafka 本身是不会组织用户发送duplicate data的。这些重复数据也仅会在一个segment在被commit 的时候做重复数据删除,所以consumer仍会读取到这部分重复数据(如果客户端有发的话)。
Log Compaction也会有时失败,compaction thread 可能会crash,所以需要确保给Kafka server 足够的内存用于做这些操作。如果log compaction异常,则需要重启Kafka(此为一个已知的bug)。
Log Compaction也无法通过API手动触发(至少到现在为止是这样),只能server端自动触发。
下面是一个 Log Compaction过程的示意图:

正在写入的records仍会被写入Active Segment,已经committed segments会自动做compaction。此过程会遍历所有segments中的records,并移除掉所有需要被移除的messages。
Log compaction由上文提到的log.cleanup.policy=compact进行配置,其中:
-
Segment.ms(默认为7天):在关闭一个active segment前,所需等待的最长时间
-
Segment.bytes(默认为1G):一个segment的最大大小
-
Min.compaction .lag.ms(默认为0):在一个message可以被compact前,所需等待的时间
-
Delete.retention.ms(默认为24小时):在一条message被加上删除标记后,在实际删除前等待的时间
- Min.Cleanable.dirty.ratio(默认为0.5):若是设置的更高,则会有更高效的清理,但是更少的清理操作触发。若是设置的更低,则清理的效率稍低,但是会有更多的清理操作被触发
相关文章:
【大数据学习 | kafka高级部分】文件清除原理
2. 两种文件清除策略 kafka数据并不是为了做大量存储使用的,主要的功能是在流式计算中进行数据的流转,所以kafka中的数据并不做长期存储,默认存储时间为7天 那么问题来了,kafka中的数据是如何进行删除的呢? 在Kafka…...

dolphin 配置data 从文件导入hive 实践(一)
datax 支持多种数据源的相互读写,作为开源软件,提供了离线采集功能,方便系统开发,过程中遇到诸多配置,需要开发者自己探索,免费同样有成本 配置模板 {"setting": {},"job": {"s…...
)
Docker Compose部署Rabbitmq(脚本下载延迟插件)
整个工具的代码都在Gitee或者Github地址内 gitee:solomon-parent: 这个项目主要是总结了工作上遇到的问题以及学习一些框架用于整合例如:rabbitMq、reids、Mqtt、S3协议的文件服务器、mongodb github:GitHub - ZeroNing/solomon-parent: 这个项目主要是…...

麦当劳自助点餐机——实现
餐厅自助点餐优点 1. 降低服务成本: - 减少了对服务员数量的需求,降低了人力成本。 - 减轻了服务员的工作负担,使其能够更专注于提供优质的服务,如解决顾客的特殊需求和处理复杂问题。 2. 提升点餐效率和准确性…...

C++ STL CookBook 6:STL Containers (I)
目录 顺序容器 关联容器 容器适配器 使用统一擦除函数从容器中删除指定项 在恒定时间内对一个对排序不敏感的vector中删除项目 如果不确定自己访问容器会不会越界,那就使用.at方法而不是[] 在我们开始之前,先来回顾一下传统的经典的几个容器&#…...

行转列实现方式总结
前言 在日常开发中遇到了,需要对表中数据某个字段行数据转成列,个人觉得这中做目前想到两种, 一种是sql 操作, 另一种代码中做逻辑处理。 方式一 Java 操作 import lombok.Data;import java.util.ArrayList; import java.util.H…...

【go从零单排】初探goroutine
🌈Don’t worry , just coding! 内耗与overthinking只会削弱你的精力,虚度你的光阴,每天迈出一小步,回头时发现已经走了很远。 📗概念 Goroutines 是 Go 语言中的一种轻量级线程,用于并发编程。它们允许程…...

HarmonyOS NEXT应用元服务开发Intents Kit(意图框架服务)本地搜索接入方案
一、方案概述 当用户使用应用/元服务时,开发者可以按照标准意图Schema向系统共享数据,并支持意图调用(空调用与传参调用),以实现用户点击卡片后,可后台执行功能(例如播放指定歌曲)或…...

C语言可变参数列表编程实战指南:从基础概念到高级应用的全面解析
引言 在C语言中,可变参数列表的功能使得函数能够灵活地处理不确定数量的输入参数。本文将深入探讨可变参数列表的基础概念、技术原理及其在实际编程中的应用,帮助开发者更好地理解和使用这一特性。 一、可变参数列表的基本概念 1.1 什么是可变参数列表…...

AndroidStudio-文本显示
一、设置文本的内容 1.方式: (1)在XML文件中通过属性:android:text设置文本 例如: <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas.andr…...
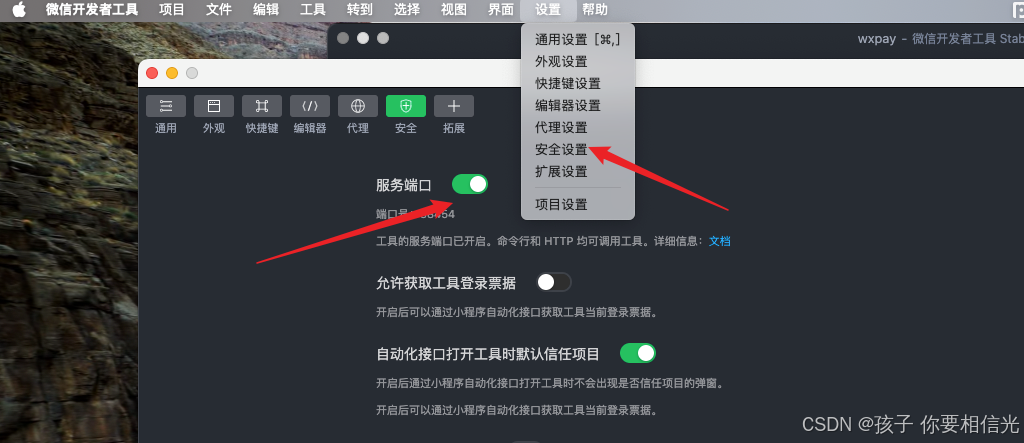
HBuilderX运行微信小程序,编译的文件在哪,怎么运行
1. 点击HBuilderX顶部的运行-运行到小程序模拟器-微信开发者工具,就会开始编译 2. 编译完成后的文件在根目录找到 unpackage -- dist -- dev -- mp-weixin, 这里面就是编译后的文件,如果未跳转到开发者工具,那可能是没设置启动路径࿰…...

百亿AI数字人社会初现:Project Sid展示智能代理文明进化路径
项目背景 Project Sid 是一项开创性的AI代理人文明实验,旨在通过新开发的认知架构 PIANO 探讨AI代理人是否能够在大规模数字社会中实现文明的演进。这项实验不仅展示了社会进步、角色分化、治理体系及文化传播等特征,还揭示了一个包含百亿“数字人类”的社会可能性。 PIANO…...

代码随想录训练营Day21 | 491.递增子序列 - 46.全排列 - 47.全排列 II - 332.重新安排行程 - 51.N皇后 - 37.解数独
491.递增子序列 题目链接:491.递增子序列思路:和子集那道题思路很像,每次在数组中选择一个数,选过的数不能选择,这里要求集合数量必须大于2个才能符合,仍然需要去重,但这里选额的是子序列&…...

多用户商城系统的功能及设计和开发
多用户商城系统的功能及设计与开发(基于 PHP MySQL) 在现代电子商务平台的开发中,PHP MySQL 是一对非常流行且高效的技术栈。PHP作为服务器端脚本语言,结合MySQL数据库,可以高效地处理多用户商城系统的各种需求。本…...

2024年11月8日day8
半加器和全加器的区别 半加器:只能处理两个二进制位的相加,无法处理进位。全加器:不仅能处理两个二进制位的相加,还能处理来自低位的进位。 ⑴ 完成满足754标准存储格式的浮点数((43940000)16的十进制数值)…...

Debezium系列之:Debezium3版本增量快照和只读增量快照应用的变化
Debezium系列之:Debezium3版本增量快照和只读增量快照应用的变化 一、需求背景二、基于数据库信号表使用增量快照案例三、基于Kafka信号Topic使用增量快照案例四、只读增量快照案例五、增量快照技术总结增量快照相关知识请阅读博主下面系列文章: Debezium系列之:实现增量快照…...

Python正则表达式1 re.match惰性匹配详解案例
点个关注 re.match() re.match() 函数尝试从字符串的开头开始匹配一个模式,如果匹配成功,返回一个匹配成功的对象,否则返回None。大小写区分,内容匹配不到后面的,只能匹配一个,不能有空格(开头匹配&#…...
学习日志10:Prism框架下按键绑定)
WPF(C#)学习日志10:Prism框架下按键绑定
在Prism框架下,提供了DelegateCommand类用于处理了UI的按键请求,XAML中可以直接采用 Command"{Binding **}" 来绑定这些方法。这个类是一个泛型的类生命时仅需要DelegateCommand<T>即可,同时在XAML中绑定CommandParameter&qu…...

WPF中的ResizeMode
在 WPF (Windows Presentation Foundation) 中,ResizeMode 属性用于指定窗口是否可以被用户调整大小,以及如何调整大小。ResizeMode 属性可以设置为以下几个值之一: NoResize:窗口不能被用户调整大小,但可以被程序代码…...

Unity3D UI 双击和长按
Unity3D 实现 UI 元素双击和长按功能。 UI 双击和长按 上一篇文章实现了拖拽接口,这篇文章来实现 UI 的双击和长按。 双击 创建脚本 UIDoubleClick.cs,创建一个 Image,并把脚本挂载到它身上。 在脚本中,继承 IPointerClickHa…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...
)
C#学习第29天:表达式树(Expression Trees)
目录 什么是表达式树? 核心概念 1.表达式树的构建 2. 表达式树与Lambda表达式 3.解析和访问表达式树 4.动态条件查询 表达式树的优势 1.动态构建查询 2.LINQ 提供程序支持: 3.性能优化 4.元数据处理 5.代码转换和重写 适用场景 代码复杂性…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...

适应性Java用于现代 API:REST、GraphQL 和事件驱动
在快速发展的软件开发领域,REST、GraphQL 和事件驱动架构等新的 API 标准对于构建可扩展、高效的系统至关重要。Java 在现代 API 方面以其在企业应用中的稳定性而闻名,不断适应这些现代范式的需求。随着不断发展的生态系统,Java 在现代 API 方…...