软件设计师-计算机体系结构分类
计算机体系结构分类
Flynn分类法
- 根据不同的指令流数据流组织方式分类
- 单指令流但数据流SISD,单处理器系统
- 单指令多数据流SIMD,单指令流多数据流是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据矢量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。并行处理器,阵列处理机,超级向量处理机
- 多指令流单数据流MISD,被证明不可能,至少是不实际,理论模型,未形成产品。
- 多指令流多数据流MIMD,多处理机系统多计算机,能够实现作业、任务、指令等各级全面并行
- 科学计算机对运算速度要求高,数据库计算机对内存容量、存取速度要求高,网络计算机对IO速度要求高
指令系统
- CISC,复杂指令集计算机,指令数量多,使用频率差别大,可变长格式,支持多种寻址方式,使用微程序控制技术实现
- RISC,精简指令集计算机,指令数量少,使用频率接近,定长格式,大部分为单周期指令,操作寄存器,只有Load/Store操作内存,支持的寻址方式少,增加了通用寄存器,硬布线逻辑控制为主,采用流水线,优化编译,有效支持高级语言;关键技术,重叠寄存器窗口技术,超流水和超标量技术等
- 指令包括两个部分,操作码和操作数,操作码的位数可以计算出指令的数量
- 指令流水线的的操作周期是流水线中最慢的操作的时间
- 指令顺序执行和流水执行,流水执行时总时间等于操作周期*(n-1) + t一条指令时间
- 吞吐率 = 指令数/(执行的总时间)
总线
计算机设备和设备之间传输信息的公共数据通道,总线上的所有设备共享
总线的分类
- 数据总线用来传送数据,双向,DB的宽度决定了设备之间每次交换数据的位数
- 地址总线,用于传送CPU发出的地址信息,是单向的,传送地址的目的是指明与CPU交换信息的内存单元或IO设备。地址总线的宽度决定了CPU的最大寻址能力,34位的地址总线允许16GB的内存
- 控制总线,用来传送控制信号、时序信号和状态信息等,每一根线是单向的,但是总体是双向的
常见总线
- PCI总线,用于将显卡、声卡、网卡和硬盘控制器等告诉外围设备直接挂在CPU总线上,其负责CPU和外围设备的通信,即插即用,通过在PCI上插上网卡可以组件局域网,可以组建多处理机系统
- STD规模较小,面向工业控制的8位系统总线
- 交叉开关将各个CPU连接成动态互联网络,组成多处理机系统
- Centronic总线属于外部总线,用于计算机连接打印机
- ISA总线,工业标准总线,支持16位I/O设备
- PCI Express总线,点对点串行连接,速度很快
- 前段总线(FSB),将CPU连接到北桥芯片的总线,北桥芯片负责联系内存显卡等数据吞吐量大的部件,并于南桥芯片连接,FSB对计算机整体性能作用很大。
- RS-232C,一条串行外总线,传输线比较少,全双工通信
- SCSI总线,小型计算机系统接口是一条并行外总线,广泛用于连接软硬磁盘、光盘、扫描仪等
- SATA,串行ATA,用作主板和大量存储设备之间的数据传输,具有纠错能力
- USB,通形串行总线,自带电源,即插即用,支持热插拔
- IEEE-1394,高速串行外总线,可提供电源,
- IEEE-488总线
计算机系统硬件基本组成
中央处理单元CPU
- 计算机系统的核心部件,负责获取程序指令,对指令进行译码并加以执行
- 程序控制,CPU通过执行指令来控制程序的执行顺序
- 操纵控制,一条指令功能的实现需要若干操作信号配合来完成,CPU产生每条指令的操作信号并将操作信号送往对应的部件,控制相应的部件按指令的功能要求进行操作
- 时间控制,CPU对各种操作进行时间上的控制,即指令执行过程中操作信号的出现时间,持续时间以及出现的时间顺序都需要进行严格控制
- 数据处理,CPU通过对数据进行算数运算以及逻辑运算等方式进行加工处理,数据加工处理的结果被人们利用,所以数据的加工处理也是CPU最根本的任务
- CPU还需要对系统内部和外部的终端(异常)做出响应,进行相应的处理。
- CPU主要由运算器,控制器,寄存器和内部总线等部件组成
- 运算器由算术逻辑单元(ALU),累加寄存器,数据缓冲寄存器和状态条件寄存器等组成,所进行的全部操作都是由控制器发出的控制信号来指挥的,主要功能有执行算数和执行逻辑运算
- 算术逻辑单元,负责处理数据,实现对数据的算数运算和逻辑运算
- 累加寄存器(AC)简称累加器,通用寄存器,其功能是为ALU提供一个工作区,比如执行减法操作时,先将被减数取出暂存AC中,然后从内存中取出减数,同AC中的内容相减,结果送回AC,至少有一个
- 数据缓冲寄存器(DR),用DR暂存由内存储器读写的一条指令或一个数据字,主要作用作为CPU和内存外设之间数据传送的中转站;作为CPU和内存外设之间操作速度上的缓冲
- 状态条件寄存器(PSW),保存算数指令和逻辑指令的各种条件码内容,比如进位,溢出,结果为0等
- 控制器用于控制整个CPU的工作,包括指令控制,时序控制,总线控制和中断控制。
- 指令寄存器(IR),执行一条指令时,从内存储器中取出缓冲寄存器然后送入IR中,指令译码器根据IR的内容产生各种微操作指令。
- 程序计数器(PC),PC具有寄存器和计数两种功能,用于存储下一条指令的地址
- 地址寄存器(AR),保存当前CPU访问的内存单元地址
- 指令译码器(ID),对指令中的操作码进行分析解释,
- 32位处理器能同时处理32为数据,寄存器也是32位的,数据总线的宽度32位
存储系统
- 主存储器,主板上的存储器,与CPU直接与沟通,存放正在使用的数据和程序,内存只用于暂时存放程序和数据,一旦断电,分为RAM和ROM,RAM可读可写,ROM只读不写。
- 主存与CPU之间的硬连接有三组连线,地址总线,数据总线,控制总线。
- 高速缓冲存储器(Cache),使用SRAM计数,比RAM更快,它保存主存的一个子集,它与主存之间的数据交换是以块为单位,地址映射即是应用某种方法把主存地址定位到Cache中,位于CPU和主存储器之间的一级存储器,如果高速缓存命中率t,内存读取时间m,缓存读取时间n,则平均读写时间nt + (1-t)* m,计算高速缓存和主存映射关系是,需要把地址分为块号和块内地址,
- 寄存器是中央处理器内的组成部分,读写速度也是最高的,用来暂存指令,数据和地址。
- 存储器的访问方式分为按照地址访问和按照内容访问
- 按寻址方式分为随机存储器(RAM),顺序存储器(SAM),磁带,直接存储器(DAM),磁盘,对磁道随机,对磁道内顺序。
- 相联存储器,按内容访问的存储器
- ROM只读存储器,断电后数据不会丢失
- RAM随机存储器,断电后数据消失
- 主存由ROM和RAM共同组成
- CPU不能直接访问硬盘,要经过主存
- RAID,廉价冗余磁盘阵列,RAID0-RAID6,
- RAID0 是一种简单的、无数据校验的数据条带化技术。实际上不是一种真正的 RAID ,因为它并不提供任何形式的冗余策略。 RAID0 将所在磁盘条带化后组成大容量的存储空间(如图 2 所示),将数据分散存储在所有磁盘中,以独立访问方式实现多块磁盘的并读访问。由于可以并发执行 I/O 操作,总线带宽得到充分利用。再加上不需要进行数据校验,RAID0 的性能在所有 RAID 等级中是最高的。理论上讲,一个由 n 块磁盘组成的 RAID0 ,它的读写性能是单个磁盘性能的 n 倍,但由于总线带宽等多种因素的限制,实际的性能提升低于理论值。RAID0 具有低成本、高读写性能、 100% 的高存储空间利用率等优点,但是它不提供数据冗余保护,一旦数据损坏,将无法恢复。 因此, RAID0 一般适用于对性能要求严格但对数据安全性和可靠性不高的应用,如视频、音频存储、临时数据缓存空间等。
- RAID1 称为镜像,它将数据完全一致地分别写到工作磁盘和镜像 磁盘,它的磁盘空间利用率为 50% 。 RAID1 在数据写入时,响应时间会有所影响,但是读数据的时候没有影响。 RAID1 提供了最佳的数据保护,一旦工作磁盘发生故障,系统自动从镜像磁盘读取数据,不会影响用户工作。工作原理如图 3 所示。RAID1与RAID0刚好相反,是为了增强数据安全性使两块磁盘数据呈现完全镜像,从而到安全性好、技术简单、管理方便。RAID1拥有完全容错的能力,但实现成本高。RAID1应用于对顺序读写性能要求高以及对数据保护极为重视的应用,如对邮件系统的数据保护。
- RAID2 称为纠错海明码磁盘阵列,其设计思想是利用海明码实现数据校验冗余。海明码是一种在原始数据中加入若干校验码来进行错误检测和纠正的编码技术,其中第 2n 位( 1, 2, 4, 8, … )是校验码,其他位置是数据码。因此在 RAID2 中,数据按位存储,每块磁盘存储一位数据编码,磁盘数量取决于所设定的数据存储宽度,可由用户设定。图 4 所示的为数据宽度为 4 的 RAID2 ,它需要 4 块数据磁盘和 3 块校验磁盘。如果是 64 位数据宽度,则需要 64 块数据磁盘和7块校验磁盘。可见,RAID2的数据宽度越大,存储空间利用率越高,但同时需要的磁盘数量也越多。海明码自身具备纠错能力,因此 RAID2 可以在数据发生错误的情况下对纠正错误,保证数据的安全性。它的数据传输性能相当高,设计复杂性要低于后面介绍的 RAID3 、 RAID4和RAID5。但是,海明码的数据冗余开销太大,而且RAID2的数据输出性能受阵列中最慢磁盘驱动器的限制。再者,海明码是按位运算,RAID2数据重建非常耗时。由于这些显著的缺再加上大部分磁盘驱动器本身都具备了纠错功能,因此RAID在实际中很少应用,没有形成商业产品,目前主流存储磁盘阵列均不提供 RAID2 支持。
- RAID3 (图 5 )是使用专用校验盘的并行访问阵列,它采用一个专用的磁盘作为校验盘,其余磁盘作为数据盘,数据按位可字节的方式交叉存储到各个数据盘中。RAID3至少需要三块磁盘,不同磁盘上同一带的数据作 XOR 校验,校验值写入校验盘中。RAID3完好时读性能与RAID0完全一致,并行从多个磁盘条带读取数据,性能非常高,同时还提供了数据容错能力。向RAID3写入数据时,必须计算与所有同条带的校验值,并将新校验值写入校验盘中。一次写操作包含了写据块、读取同条带的数据块、计算校验值、写入校验值等多个操作,系统开销非常大,性能较低。如果RAID3中某一磁盘出现故障,不会影响数据读取,可以借助校验数据和其他完好数据来重建数据。假如所要读取的数据块正好位于失效磁盘,则系统需要读取所有同一条带的数据块,并根据校验值重建丢失的数据,系统性能将受到影响。当故障磁盘被更换后,系统按相同的方式重建故障盘中的数据至新磁盘
- RAID4 与 RAID3 的原理大致相同,区别在于条带化的方式不同。RAID4(图6)按照块的方式来组织数据,写操作只涉及当前数据盘和校验盘两个盘,多个 I/O 请求可以同时得到处理,提高了系统性能。 RAID4 按块存储可以保证单块的完整性,可以避免受到其他磁盘上同条带产生的不利影响。RAID4在不同磁盘上的同级数据块同样使用 XOR 校验,结果存储在校验盘中。写入数据时,RAID4按这种方式把各磁盘上的同级数据的校验值写入校验 盘,读取时进行即时校验。因此,当某块磁盘的数据块损坏,RAID4可以通过校验值以及其他磁盘上的同级数据块进行数据重建。
- RAID5 应该是目前最常见的RAID等级,它的原理与RAID4相似,区别在于校验数据分布在阵列中的所有磁盘上,而没有采用专门的校验磁盘。对于数据和校验数据,它们的写操作可以同时发生在完全不同的磁盘上。因此, RAID5 不存在 RAID4中的并发写操作时的校验盘性能瓶颈问题。另外,RAID5还具备很好的扩展性。当阵列磁盘 数量增加时,并行操作量的能力也随之增长,可比RAID4支持更多的磁盘,从而拥有更高的容量以及更高的性能。RAID5 (图7)的磁盘上同时存储数据和校验数据,数据块和对应的校验信息存保存在不同的磁盘上,当一个数据盘损坏时,系统可以根据同一条带的其他数据块和对应的校验数据来重建损坏的数据。与其他 RAID 等级一样,重建数据时, RAID5 的性能会受到较大的影响。
- 存储器中数据常用的存储有顺序存取,直接存取,随机存取,相联存取,随机和相连的存取时间和数据的位置无关
数据表示
- 计算机中的加减法使用补码,可以实现符号位也一起参与计算,结果的符号位和进位标志异或如果为1说明溢出,简化了计算机运算部件的设计,减法可以用加负数实现
- 浮点数的表示,阶符,阶码,数符,尾数,如果浮点数的阶码使用R位的移码表示,尾数用M位的补码表示则范围是-1 * 2(2(R-1)-1)到(1-2(-(M-1)))*2(2^(R-1)-1)
- 海明码 m+k+1 < 2^k,如果码距离为d,d-1位的错误可以检查出来,d/2位的错误可以纠正
- 对于某种长度的错误串,要纠正错误就要用比仅仅检查它多一倍的冗余位
程序
- 程序局部性原理指程序在一段时间内访问相对较小的一段地址空间,时间局部性和空间局部性
寻址方式
- 立即寻址,指令的地址字段指出的不是操作数的地址,而是操作数本身
- 直接寻址,指令格式的地址字段中直接指出操作数在内存中的地址,只需根据地址字段中的值,即可访问内存读取到操作数
- 间接寻址,指令格式的地址字段指向内存中的位置存放的是操作数的地址,需要两次访问内存才能得到操作数
- 寄存器寻址,指令格式的地址字段是寄存器的编号,从寄存器中取操作数
- 寄存器相对寻址,指令格式的地址字段是寄存器的编号,寄存器中的内容是操作数内存的地址,需要两次寻址
- 相对寻址方式,把程序计数器PC中的内容加上指令格式中的形式地址形成操作数的有效地址
- 基址寻址方式,将CPU中基址寄存器的内容加上指令格式中形式地址而形成的操作数的有效地址
- 变址寻址方式,把CPU中某个变址寄存器中内容加上指令格式的中偏移量
输入输出
- 外设数据的输入输出过程在CPU执行程序的控制下完成,分为无条件传送和程序查询传送
- 无条件传送,外设总是准备好的,无条件接收CPU发来的输出数据,也能无条件的随机向CPU提供需要输入的数据
- 程序查询方式,CPU执行程序查询外设的状态,判断外设是否准备好接收或者提供数据,一个计算机有很多外设,CPU逐一查询,缺点有降低了CPU的效率,对外部的突发事件无法做出实时响应
- 由程序控制IO,主要缺点是CPU必须等待IO完成,在此期间需要定期的查询IO的状态,系统性能下降,利用中断方式完成数据的输入输出,当IO系统与外设交换数据时,CPU无需等待,无需查询状态,可以做其他的任务。当IO系统准备好后,发出中断请求信号,CPU收到中断后,保存正在执行的程序现场,转入IO中断服务,完成与IO系统的数据交换,然后再返回被打断的程序继续执行。
- 直接存储器存取方式(DMA)
- 在内存和IO设备之间直接块传送,不需要CPU干涉,由DMA硬件直接执行完成,DMA需要占用系统总线,期间CPU不能使用总线
- 输入输出处理机(IOP),通道比DMA进一步提高了CPU的效率,通道是一个具有特殊功能的处理器,它分担了CPU的一部分功能,实现对外围设备的统一管理
- 中断方式下数据需要经过CPU,而DMA数据直接从外设到内存
系统可靠性
- 串联 R*R
- 并联 (1-(1-R)^2)
题目
- 由n块芯片组成的存储器,可以根据片地址,内存地址得出最后的地址
相关文章:

软件设计师-计算机体系结构分类
计算机体系结构分类 Flynn分类法 根据不同的指令流数据流组织方式分类单指令流但数据流SISD,单处理器系统单指令多数据流SIMD,单指令流多数据流是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据矢量”)中的每一…...

《基于深度学习的车辆行驶三维环境双目感知方法研究》
复原论文思路: 《基于深度学习的车辆行驶三维环境双目感知方法研究》 1、双目测距的原理 按照上述公式算的话,求d的话,只和xl-xr有关系,这样一来,是不是只要两张图像上一个测试点的像素位置确定,对应的深…...

jwt用户登录,网关给微服务传递用户信息,以及微服务间feign调用传递用户信息
1、引入jwt依赖 <dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt</artifactId><version>0.9.1</version></dependency> 2、Jwt工具类,生成token以及解析token package com.niuniu.gateway.uti…...

ubontu安装anaconda
1.下载 Anaconda 安装脚本 2. 复制到服务器上/home/username文件夹中,进入文件夹,执行: bash Anaconda3-2024.10-1-Linux-x86_64.sh一直按回车,然后输入yes同意协议。 3. 初始化 Anaconda 环境,会自动配置环境变量&a…...

【Docker容器化技术】docker安装与配置、常用命令、容器数据卷、应用部署实战、Dockerfile、服务编排docker-compose、私有仓库
文章目录 一、Docker的安装与配置1、docker概述2、安装docker3、docker架构4、配置镜像加速器 二、Docker命令1、服务相关命令2、镜像相关命令3、容器相关命令 三、Docker容器数据卷1、数据卷概念及作用2、配置数据卷3、配置数据卷容器 四、Docker应用部署实战1、部署MySQL2、部…...

Python模拟A卷实操题
1.某机械公司生产两种产品。A的单件利润分别是100元,B的单件利润是150元。 每种产品由三种材料构成,现给出每种材料的库存(库存小于100000),求利润最大的生产方案。输入说明:第一行给出生产每件A产品所需要…...
Leetcode 检测相邻递增子数组
3349. 检测相邻递增子数组 I 给你一个由 n 个整数组成的数组 nums ,请你找出 k 的 最大值,使得存在 两个 相邻 且长度为 k 的 严格递增 子数组 。具体来说,需要检查是否存在从下标 a 和 b (a < b) 开始的 两个 子数组,并满…...

rockylinux 8安装 gcc11.2
方法 1:从源代码编译安装最新版本的 GCC 下载 GCC 源代码: 访问 GCC 官方网站下载最新版本的源代码,例如: wget https://ftp.gnu.org/gnu/gcc/gcc-11.2.0/gcc-11.2.0.tar.gz tar -xf gcc-11.2.0.tar.gz cd gcc-11.2.0安装依赖项&a…...
-奇数序列排序)
【蓝桥等考C++真题】蓝桥杯等级考试C++组第13级L13真题原题(含答案)-奇数序列排序
C L13 奇数序列排序 给定一个长度为N的正整数序列, 请将其中的所有奇数取出,并按增序(从小到大)输出。 输入: 共2行 第1行是一个正整数 N(不大于500); 第2行有 N 个正整数&#x…...

【AI】好用的AI记录
好用的AI 一、国内 KIMI通义 二、国外 GPT4Cursorv0...

linux安装boost.python
前言 boost.python库被用于C与Python代码间的交互,提供了两者间大部分数据类型的转换 相关环境 操作系统:Ubuntu 20.04 python版本:Python 3.8 boost版本:boost 1.78.0 安装 1.boost.python检查与卸载 在安装boost之前需要检…...

AI 扩展开发者思维方式:以 SQL 查询优化为例
在现代软件开发中,AI 技术的兴起让开发者的思维方式发生了显著变化。尤其是在 SQL 查询优化、代码重构以及算法设计等领域,AI 提供的建议不仅扩展了开发者的思考路径,还帮助他们发现以往没有意识到的潜在解决方案。 1. 传统思维模式下的 SQL…...
自定义面板,高效的游戏性能分析利器
为了更有效地聚焦并解决性能问题,UWA报告采用了分模块监控策略,确保每个模块独立成章,各司其职。然而,随着对性能分析需求的不断升级,我们已经意识到,在深入分析某些跨模块的性能瓶颈或优化点时,…...
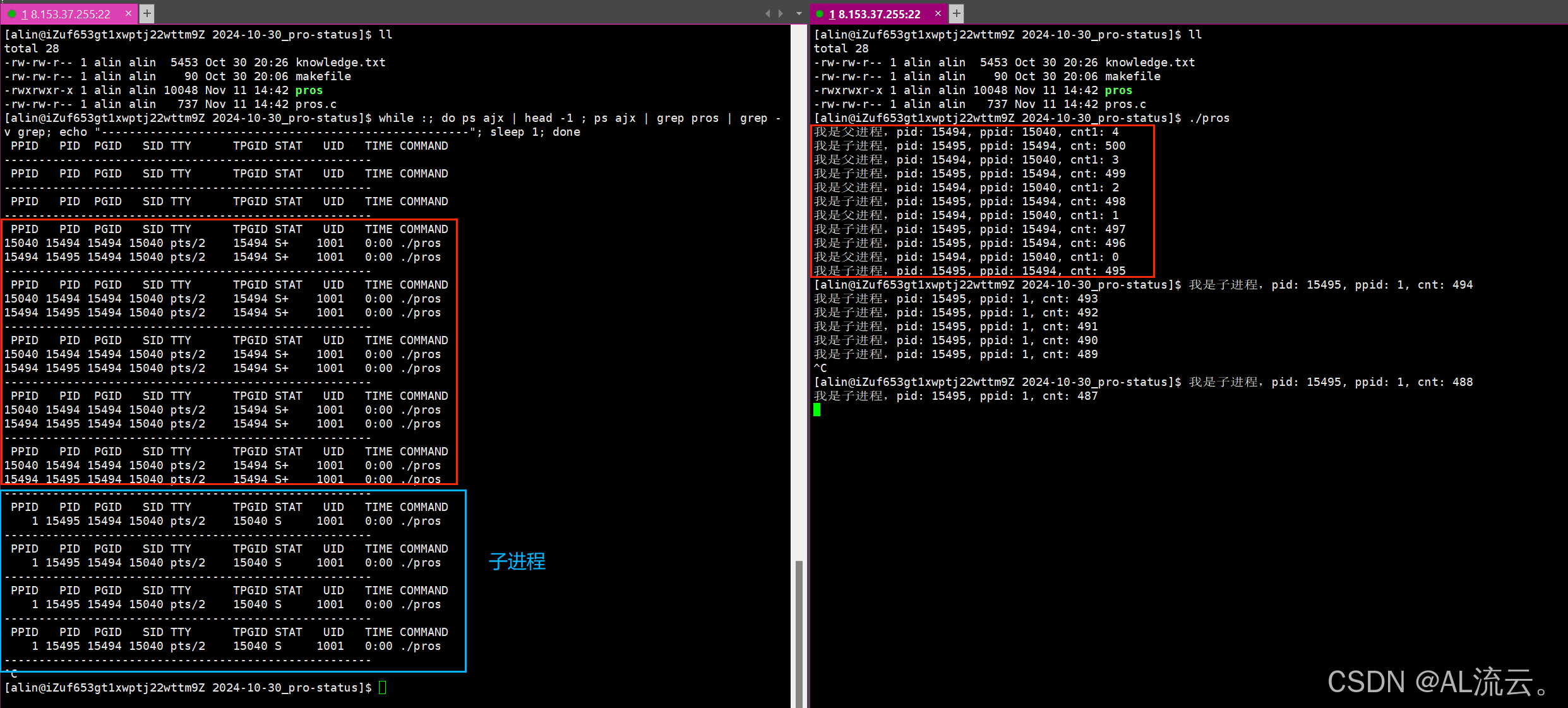
【Linux进程特别篇】深度理解辨识僵尸进程和孤儿进程
--------------------------------------------------------------------------------------------------------------------------------- 每日鸡汤:每一份坚持都是成功的积累,只要相信自己,总会遇到惊喜。 -----------------------------…...

喜报|超维机器人荣获昇腾AI创新大赛铜奖
近日,在备受瞩目的昇腾AI创新大赛中,超维机器人凭借扎实的技术实力和创新产品,荣获大赛铜奖。这一荣誉不仅展现了超维机器人在智能巡检领域的技术创新与突破,也标志着超维机器人的智能巡检解决方案在人工智能领域获得了广泛认可&a…...

从五种架构风格推导出HTTP的REST架构
在分布式系统中,架构风格(Architectural Style)决定了系统组件如何交互、通信、存储和管理数据。每种架构风格都有其独特的特性和适用场景。本文将从五种典型的架构风格出发,逐步探讨它们如何影响了REST(Representational State Transfer,表述性状态转移)架构风格的设计…...

vue-h5:在h5中实现相机拍照加上身份证人相框和国徽框
方案1:排出来照片太糊了,效果不好 1.基础功能 参考: https://blog.csdn.net/weixin_45148022/article/details/135696629 https://juejin.cn/post/7327353533618978842?searchId20241101133433B2BB37A081FD6A02DA60 https://www.freesio…...

免费HTML模板和CSS样式网站汇总
HTML模板:(注意版权,部分不可商用) 1、Tooplate,免费HTML模板下载 Download 60 Free HTML Templates for your websitesDownload 60 free HTML website templates or responsive Bootstrap templates instantly from T…...
备份特殊文件)
Mac打开time machine(时间机器)备份特殊文件
Mac 打开time machine(时间机器)备份特殊文件 设置“时间机器”的作用具体操作办法 前言:今天在使用Nas同步文件时发现有部分重要文件没有同步,为了省事手动拖拽复制文件,导致其中一份非常重要的文件丢失,尝…...

Qt 学习第十六天:文件和事件
一、创建widget对象(文件) 二、设计ui界面 放一个label标签上去,设置成box就可以显示边框了 三、新建Mylabel类 四、提升ui界面的label标签为Mylabel 五、修改mylabel.h,mylabel.cpp #ifndef MYLABEL_H #define MYLABEL_H#incl…...

案例之RNN案例_AI歌词生成器
案例之RNN案例_AI歌词生成器...

DNS欺骗攻击原理与Wireshark实战防御指南
1. 这不是黑客电影桥段,而是每天都在发生的网络基础层失守DNS欺骗攻击——这个词听起来像极了影视作品里黑衣人敲几行代码就让银行网站跳转到钓鱼页面的炫技桥段。但现实远比剧情更朴素、更隐蔽、更危险:它不依赖0day漏洞,不挑战防火墙规则&a…...

【Appium 系列】第19节-Allure 报告与 Bug 管理 — 测试结果的可视化
对应代码:utils/allure_helper.py、utils/bug_reporter.py、utils/bug_allure_helper.py说明:本节代码来自一个真实的移动端自动化测试项目,已做模糊化处理,可直接复用。1. 为什么需要报告体系?测试跑完之后࿰…...
)
别再死记公式了!用Multisim仿真带你直观理解星三角变换(Y-Δ)
用Multisim仿真破解星三角变换:从公式恐惧到电路直觉 记得第一次在实验室里面对三相电路板时,那些密密麻麻的接线和闪烁的指示灯让我完全摸不着头脑。教授在黑板上写满Y-Δ变换公式时,我的笔记本上只留下了一堆问号——直到我发现仿真软件这…...

为开源 AI 工具 OpenClaw 配置 Taotoken 作为其模型供应商的步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源 AI 工具 OpenClaw 配置 Taotoken 作为其模型供应商的步骤 对于使用 OpenClaw 这类开源 AI 工具链的开发者而言,…...

MoE稀疏激活原理与实战:解密大模型高效计算的核心机制
1. 这不是“参数越多越强”的简单故事:拆解大模型里那个被悄悄藏起来的“开关”你肯定见过这类标题:“GPT-4 参数量突破1.8万亿!”、“DeepSeek-R1 达到6710亿参数!”——光看数字,像在比谁家粮仓堆得更高。但真正懂行…...

PDF补丁丁终极指南:5分钟学会PDF元数据精准修改技巧
PDF补丁丁终极指南:5分钟学会PDF元数据精准修改技巧 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址: https://gitc…...

3个理由让你爱上VR-Reversal:在普通电脑上自由探索VR世界
3个理由让你爱上VR-Reversal:在普通电脑上自由探索VR世界 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.com/gh…...

MAXREFDES16 Fresno:工业物联网传感器节点的全栈开发实战
1. 项目概述:从一颗芯片到一个完整的工业物联网节点 如果你在工业自动化、楼宇控制或者环境监测领域工作,一定对“传感器节点”这个概念不陌生。它就像一个前线的侦察兵,负责采集温度、压力、流量、振动等物理世界的信号,然后通过…...

5分钟完成Switch注入:TegraRcmGUI终极图形化工具完整指南
5分钟完成Switch注入:TegraRcmGUI终极图形化工具完整指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI Switch注入对于许多Nintendo Switch用户…...