java xml 文本解析
示例文本
<Message><MessageName>time_request</MessageName><Timestamp>20220217165432906359</Timestamp><Body><EQPID>CMMAB01-DTP01</EQPID></Body>
</Message>
示例代码
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import java.io.ByteArrayInputStream;
String textContent = null;try {// 创建文档构建器并解析 XML 字符串DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document doc = builder.parse(new ByteArrayInputStream(object.getBytes("UTF-8")));doc.getDocumentElement().normalize();// 获取 MessageName 元素NodeList messageNameList = doc.getElementsByTagName("MessageName");if (messageNameList.getLength() > 0) {textContent = messageNameList.item(0).getTextContent();} else {throw new ApiException(ApiException.showStr("Missing MessageName element."));}// 获取 Body 元素NodeList bodyList = doc.getElementsByTagName("Body");// 根据 MessageName 处理请求return equSMTService.saveICT(textContent, bodyList);} catch (Exception e) {// 记录异常并抛出 ApiExceptionthrow new ApiException(ApiException.showStr("Error processing the request: " + e.getMessage()));}
String eqpId = body.getElementsByTagName("EQPID").item(0).getTextContent();String machineId = body.getElementsByTagName("MACHINEID").item(0).getTextContent();String panelid = body.getElementsByTagName("PANELID").item(0).getTextContent();NodeList recipeid = body.getElementsByTagName("ITEM");for (int i = 0; i < recipeid.getLength(); i++) {Node badeNode = recipeid.item(i);if (badeNode.getNodeType() == Node.ELEMENT_NODE) {Element badeElement = (Element) badeNode;String itemid = badeElement.getElementsByTagName("ITEMID").item(0).getTextContent();String itemvalue =badeElement.getElementsByTagName("ITEMVALUE").item(0).getTextContent();}}
XML 解析流程概述 在这段代码中,主要实现了从一个 XML 格式的对象(假设object存储了 XML 数据)中解析出特定元素的值,并根据解析结果进行后续处理的功能。整体流程包括以下几个关键步骤:
- 准备解析环境
- 首先,创建DocumentBuilderFactory实例,通过调用DocumentBuilderFactory.newInstance()方法来获取一个工厂对象,用于创建DocumentBuilder实例。
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
- 创建 DocumentBuilder 使用前面获取的工厂对象创建DocumentBuilder实例,这是实际用于解析 XML 的构建器。
DocumentBuilder builder = factory.newDocumentBuilder();
- 解析 XML 数据 将存储 XML 数据的object转换为字节流,并使用创建好的DocumentBuilder进行解析,得到代表整个
XML 文档结构的Document对象。同时,对文档元素进行规范化处理(例如处理文本节点的空白等)。
Document doc = builder.parse(new ByteArrayInputStream(object.getBytes("UTF-8")));
doc.getDocumentElement().normalize();
- 提取特定元素的值
提取 MessageName 元素的值:
通过getElementsByTagName方法在解析后的Document对象中查找所有名为MessageName的元素,返回一个NodeList集合。
然后判断该集合的长度,如果大于 0,则获取第一个MessageName元素的文本内容,并存储到textContent变量中;否则,抛出一个自定义的ApiException异常,表示缺少MessageName元素。
NodeList messageNameList = doc.getElementsByTagName("MessageName");
if (messageNameList.getLength() > 0) {textContent = messageNameList.item(0).getTextContent();
} else {throw new ApiException(ApiException.showStr("Missing MessageName element."));
}
- 提取 Body 元素的值(虽然代码中未完整展示对 Body 元素内容的详细处理,但获取了该元素的节点列表):
同样使用getElementsByTagName方法获取所有名为Body的元素,得到一个NodeList。
NodeList bodyList = doc.getElementsByTagName("Body");
- 提取 Body 元素下特定子元素的值(以示例中的循环处理为例):
先通过body.getElementsByTagName(“EQPID”)等类似方式获取特定子元素(如EQPID、MACHINEID、PANELID等)的第一个节点,并获取其文本内容,分别存储到对应的变量(eqpId、machineId、panelid等)中。
对于ITEM元素下的子元素ITEMID和ITEMVALUE,通过循环遍历body.getElementsByTagName(“ITEM”)得到的NodeList,判断节点类型为元素节点后,进行强制类型转换,再分别获取其文本内容存储到相应变量(itemid和itemvalue)中。
String eqpId = body.getElementsByTagName("EQPID").item(0).getTextContent();
String machineId = body.getElementsByTagName("MACHINEID").item(0).getTextContent();
String panelid = body.getElementsByTagName("PANELID").item(0).getTextContent();
NodeList recipeid = body.getElementsByTagName("ITEM");
for (int i = 0; i < recipeid.getLength(); i++) {Node badeNode = recipeid.item(i);if (badeNode.getNodeType() == Node.ELEMENT_NODE) {Element badeElement = (Element) badeNode;String itemid = badeElement.getElementsByTagName("ITEMID").item(0).getTextContent();String itemvalue = badeElement.getElementsByTagName("ITEMVALUE").item(0).getTextContent();}
}
通过以上步骤,实现了对给定 XML 数据的解析、特定元素值的提取以及基于解析结果的后续业务处理,并对可能出现的异常进行了相应的处理。
返回XML 文本信息
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;import org.w3c.dom.Document;
import org.w3c.dom.Element;public class XmlMessageCreator {public static String createXmlMessage() {try {// 创建DocumentBuilderFactory实例DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();// 创建DocumentBuilderDocumentBuilder builder = factory.newDocumentBuilder();// 创建一个空的Document对象Document doc = builder.newDocument();// 创建根元素<Message>Element messageElement = doc.createElement("Message");doc.appendChild(messageElement);// 创建<MessageName>元素并设置文本内容Element messageNameElement = doc.createElement("MessageName");messageNameElement.setTextContent("time_request");messageElement.appendChild(messageNameElement);// 创建<Timestamp>元素并设置文本内容Element timestampElement = doc.createElement("Timestamp");timestampElement.setTextContent("20220217165432906359");messageElement.appendChild(timestampElement);// 创建<Body>元素Element bodyElement = doc.createElement("Body");messageElement.appendChild(bodyElement);// 创建<EQPID>元素并设置文本内容Element eqpidElement = doc.createElement("EQPID");eqpidElement.setTextContent("CMMAB01-DTP01");bodyElement.appendChild(eqpidElement);// 将Document对象转换为XML字符串TransformerFactory transformerFactory = TransformerFactory.newInstance();Transformer transformer = transformerFactory.newTransformer();DOMSource source = new DOMSource(doc);StreamResult result = new StreamResult(new java.io.StringWriter());transformer.transform(source, result);return result.getWriter().toString();} catch (Exception e) {e.printStackTrace();return null;}}public static void main(String[] args) {String xmlMessage = createXmlMessage();if (xmlMessage!= null) {System.out.println(xmlMessage);}}
}
相关文章:

java xml 文本解析
示例文本 <Message><MessageName>time_request</MessageName><Timestamp>20220217165432906359</Timestamp><Body><EQPID>CMMAB01-DTP01</EQPID></Body> </Message>示例代码 import org.w3c.dom.Document; impo…...

Docker占用空间太大磁盘空间不足清理妙招
docker占用空间太大了,磁盘空间不足,清理3妙招 清除所有已停止的容器(container)、未被任何容器所使用的卷(volume)、未被任何容器所关联的网络(network)、所有悬空镜像(…...

编程之路,从0开始:字符函数和字符串函数
Hello大家好!很高兴我们又见面了! 给生活添点passion,开始今天的编程之路! 目录 1、字符分类函数 2、字符转换函数 3、字符串函数 1、 strcpy 2、 strcat 3、 strcmp 4、strlen(s) 5、strstr(s1, s2) 6、 strtok(s1, s2…...
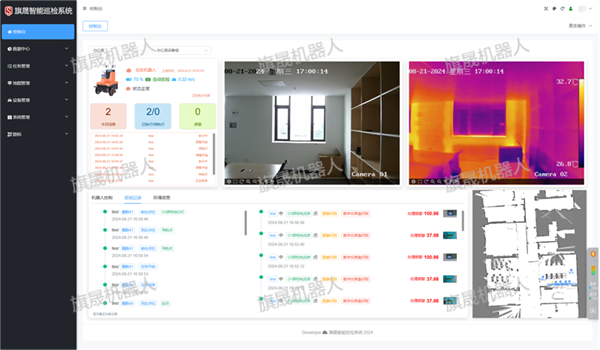
化工防爆巡检机器人:在挑战中成长,为化工安全保驾护航
随着全球能源需求的不断攀升,化工行业的安全性与高效性愈发受到关注。化工设施规模巨大,而且其中多数存在高风险因素,像是易燃易爆化学物质、高温环境、有毒有害物质以及高压设备等。仅2023年,国内危化品事故就多达652起ÿ…...

音频采样数据格式
音频信号在模拟到数字转换时,会涉及到多个关键参数,如采样率、位深度、通道数等。下面是常见的音频采样数据格式及其相关概念: 1. 采样率 (Sample Rate) 采样率指的是每秒钟对音频信号进行采样的次数,单位为赫兹 (Hz)。常见的值…...
)
【pytorch】常用强化学习算法实现(持续更新)
持续更新常用的强化学习算法,采用单python文件实现,简单易读 2024.11.09 更新:PPO(GAE); SAC2024.11.12 更新:OptionCritic(PPOC) "PPO" import copy import time import torch import numpy as np import torch.nn as …...
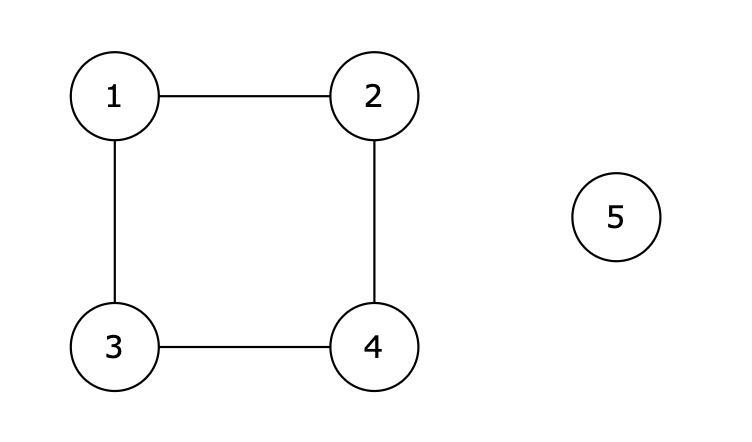
DAY59||并查集理论基础 |寻找存在的路径
并查集理论基础 并查集主要有两个功能: 将两个元素添加到一个集合中。判断两个元素在不在同一个集合 代码模板 int n 1005; // n根据题目中节点数量而定,一般比节点数量大一点就好 vector<int> father vector<int> (n, 0); // C里的一…...

Mybatis执行自定义SQL并使用PageHelper进行分页
Mybatis执行自定义SQL并使用PageHelper进行分页 基于Mybatis,让程序可以执行动态传入的SQL,而不需要在xml或者Select语句中定义。 代码示例 pom.xml 依赖 <dependency><groupId>org.mybatis.spring.boot</groupId><artifactId&g…...

OpenCV DNN
OpenCV DNN 和 PyTorch 都是常用的深度学习框架,但它们的定位、使用场景和功能有所不同。让我们来对比一下这两个工具: 1. 框架和功能 OpenCV DNN:OpenCV DNN 模块主要用于加载和运行已经训练好的深度学习模型,支持多种深度学习…...
和compartTo方法)
什么时候需要复写hashcode()和compartTo方法
在Java编程中,复写(重写)hashCode()和compareTo()方法的需求通常与对象的比较逻辑和哈希集合的使用紧密相关。但请注意,您提到的compartTo可能是一个拼写错误,正确的方法名是compareTo()。以下是关于何时需要复写这两个…...

PostgreSQL 日志文件备份
随着信息安全的建设,在三级等保要求中,要求日志至少保留半年 180 天以上。那么 PostgreSQL 如何实现这一要求呢。 我们需要配置一个定时任务,定时的将数据库日志 log 下的文件按照生成的规则将超过一定时间的日志拷贝到其它的路径下…...

2023年MathorCup数学建模B题城市轨道交通列车时刻表优化问题解题全过程文档加程序
2023年第十三届MathorCup高校数学建模挑战赛 B题 城市轨道交通列车时刻表优化问题 原题再现: 列车时刻表优化问题是轨道交通领域行车组织方式的经典问题之一。列车时刻表规定了列车在每个车站的到达和出发(或通过)时刻,其在实际…...
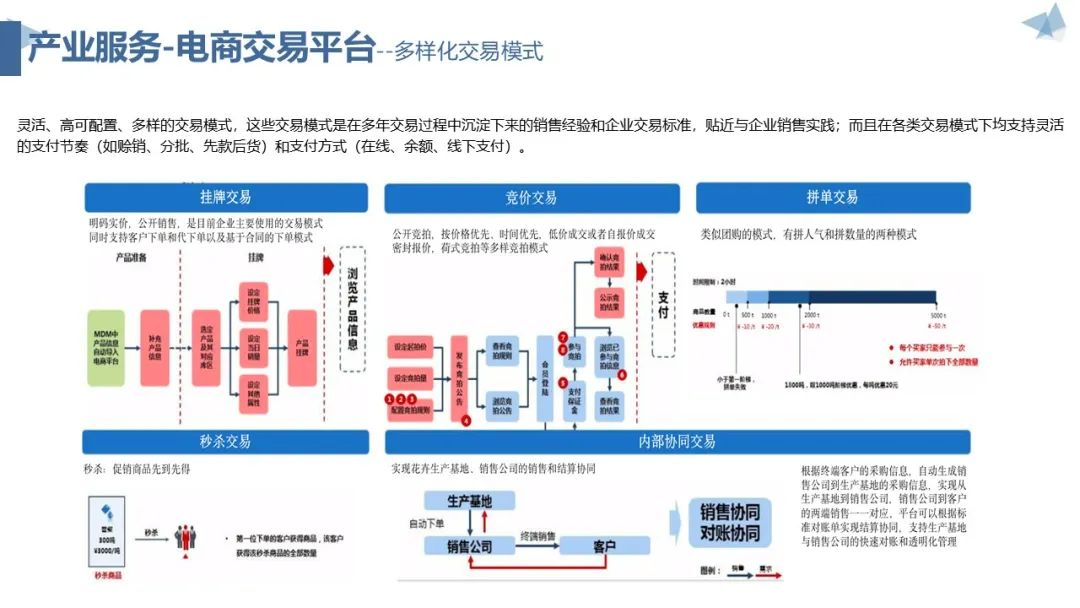
数字农业产业链整体建设方案
1. 引言 数字农业产业链整体建设方案旨在通过数字化手段提升农业产业效率与质量,推动农业现代化进程。方案聚焦于资源数字化、产业数字化、全局可视化与决策智能化的实现,构建农业产业互联网平台,促进农业全流程、全产业链线上一体化发展。 …...

awk那些事儿:在awk中使用shell变量的两种方式
awk是Linux中一款非常好用的程序,可以逐行处理文件,并提供了强大的语法和函数,和grep、sed一起被称为“Linux三剑客”。 在使用awk处理文件时,有时会用到shell中定义的变量,由于在shell中变量的调用方式是通过$符号进…...

大数据面试题--kafka夺命连环问(后10问)
目录 16、kafka是如何做到高效读写? 17、Kafka集群中数据的存储是按照什么方式存储的? 18、kafka中是如何快速定位到一个offset的。 19、简述kafka中的数据清理策略。 20、消费者组和分区数之间的关系是怎样的? 21、kafka如何知道哪个消…...

智能量化交易的多样化策略与风险控制:中阳模型的应用与发展
随着金融市场的不断创新与发展,智能量化交易正逐渐成为金融投资的重要手段。中阳智能量化交易模型通过技术优势、策略优化与实时风险控制等多方面结合,为投资者提供了强有力的工具支持。本文将对中阳量化模型的技术细节、多策略组合与市场适应性进行深入…...

小皮PHP连接数据库提示could not find driver
最近遇到一个奇怪的问题,我的小皮上安装的8.0.2版本的php连接数据库正常。下载使用8.2.9时,没有php.ini,把php-development.ini改成 php.ini后,就提示could not find driver。 网上查了说把php.ini里的这几个配置打开,我也打开了&…...
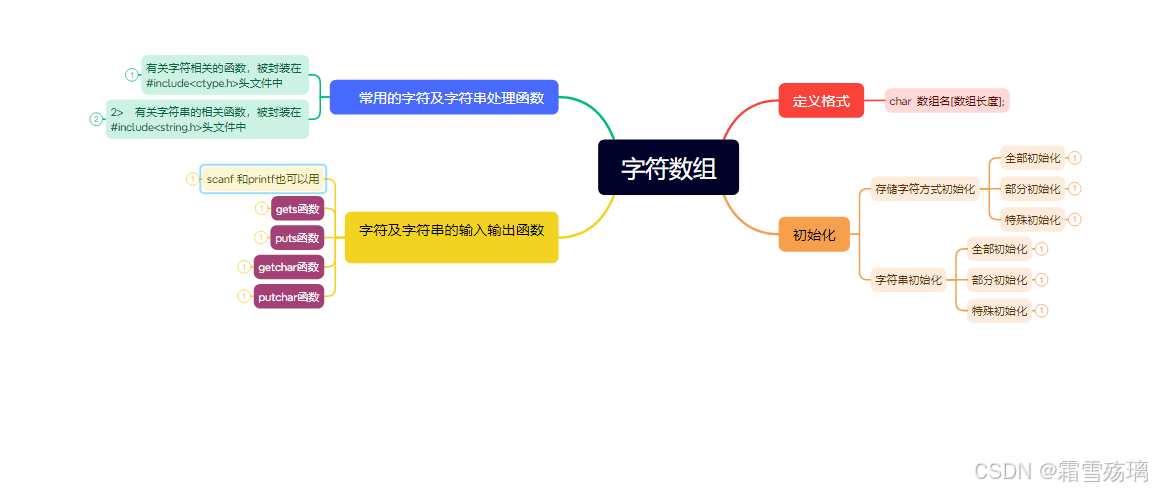
2024.11.13(一维数组相关)
思维导图 1> 提示并输入一个字符串,统计该字符串中大写字母、小写字母、数字字符、空格字符的个数并输出 2> 提示并输入一个字符串,将该字符串中的所有字母挑选到一个新数组中,将所有的数字字符挑选到另一个新数组中。并且将数字字符对…...

豆包MarsCode算法题:数组元素之和最小化
数组元素之和最小化 问题描述思路分析分析思路解决方案 参考代码(Python)代码分析1. solution 函数2. 计算 1 2 3 ... n 的和3. 乘以 k 得到最终的数组元素之和4. 主程序(if __name__ __main__:)代码的时间复杂度分析&#x…...

Hbase Shell
一、启动运行HBase 首先登陆SSH,由于之前在Hadoop的安装和使用中已经设置了无密码登录,因此这里不需要密码。然后,切换至/usr/local/hadoop,启动Hadoop,让HDFS进入运行状态,从而可以为HBase存储数据&#…...

C51编译器浮点数支持与嵌入式优化实践
1. C51编译器对浮点数的支持解析作为一名在嵌入式领域摸爬滚打多年的老工程师,我深知在8位单片机上进行浮点运算的痛点。最近有同行问我关于Keil C51编译器对浮点数的支持情况,这让我想起自己早年从PL/M-51转向C51时遇到的类似困惑。本文将结合官方文档和…...

SQL 语句:从产生、发展到内容全景
引言:数据世界的通用语言 SQL(Structured Query Language,结构化查询语言)是当今数据领域最核心、最通用的语言。无论是数据分析师、后端工程师还是数据科学家,都离不开 SQL。它就像数据世界的“普通话”,连…...

Monk AI小样本分类实战:用几十张图快速构建可用AI模型
1. 项目概述:用 Monk AI 做分类,但只喂它一小块数据——这到底在解决什么问题?“Classification Using Monk AI by Using a Slice of the Dataset”这个标题乍看平平无奇,甚至有点拗口,但如果你在工业质检、医疗影像初…...

B站视频下载终极指南:5步掌握免费批量下载技巧
B站视频下载终极指南:5步掌握免费批量下载技巧 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/bi/Bilib…...

交互形态的深层迭代:从文本到具象化表达
行业在探索智能交互形态时,会发现一个共性现象:不少智能体的逻辑与生成能力已经成熟,但对外交互始终局限在文本对话框。 过去一年,行业主流做法高度趋同:大模型对接知识库、工具调用、流程编排,最终收敛为文…...

Taotoken 多模型聚合能力如何赋能智能客服场景的快速迭代
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 多模型聚合能力如何赋能智能客服场景的快速迭代 智能客服系统的核心在于其对话生成的质量与稳定性。产品经理与开发者在优…...
)
别再手动配聚合了!用LACP协议给你的交换机链路做个‘智能冗余’(附华为交换机配置命令)
告别手动配置:LACP协议如何为你的企业网络打造智能冗余链路 想象一下这样的场景:凌晨三点,核心交换机之间的某条链路突然中断,整个企业的业务系统陷入瘫痪。运维团队手忙脚乱地排查故障,却发现由于手动配置的链路聚合缺…...

港澳通行证照片怎么手机拍?2026港澳通行证照片规格要求与手机拍摄方法实测
出国、赴港澳的第一步就是办理港澳通行证,而一张符合规范的证件照是必不可少的。很多人都会问:港澳通行证照片能用手机拍吗?怎样才能拍出符合规范的照片?要不要去照相馆?今天就给大家详细讲解港澳通行证照片的拍摄全攻…...

震惊!数十万家企业用软件监控员工,数据竟流向广告平台和经纪商!
官宣惊人内幕数十万家企业使用软件监控员工,新研究发现,许多职场监控工具不仅与雇主共享数据,还与数字广告平台和数据经纪商共享。研究详情这项研究由哥伦比亚法学院法律与经济中心高级研究员、前联邦贸易委员会首席技术专家斯蒂芬妮阮&#…...

博客从 Ubuntu 16.04 迁移到 FreeBSD:成本减半,性能提升超 10 倍!
Bruno Croci 的网站迁移之旅Bruno Croci 正在为 2026 年柏林的开源硬件峰会做准备。他的博客在 Ubuntu 16.04 上运行了 10 年,于 2026 年 5 月 21 日,他将其迁移到了 FreeBSD。迁移动机:旧系统的安全隐患与成本考量这个博客在 Digital Ocean …...