第T7周:Tensorflow实现咖啡豆识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标
具体实现
(一)环境
语言环境:Python 3.10
编 译 器: PyCharm
框 架:
(二)具体步骤
1. 使用GPU
--------------------------utils.py-------------------
import tensorflow as tf
import PIL
import matplotlib.pyplot as plt def GPU_ON(): # 查询tensorflow版本 print("Tensorflow Version:", tf.__version__) # 设置使用GPU gpus = tf.config.list_physical_devices("GPU") print(gpus) if gpus: gpu0 = gpus[0] # 如果有多个GPU,仅使用第0个GPU tf.config.experimental.set_memory_growth(gpu0, True) # 设置GPU显存按需使用 tf.config.set_visible_devices([gpu0], "GPU")
使用GPU并查看数据
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
import os, PIL, pathlib
from utils import GPU_ONGPU_ON() data_dir = "./datasets/coffee/"
data_dir = pathlib.Path(data_dir) image_count = len(list(data_dir.glob("*/*.png")))
print("图片总数量为:", image_count)
------------------
图片总数量为: 1200
2. 加载数据
# 加载数据
batch_size = 32
img_height, img_width = 224, 224 train_ds = tf.keras.preprocessing.image_dataset_from_directory( data_dir, validation_split=0.2, subset="training", seed=123, image_size=(img_height, img_width), batch_size=batch_size,
) val_ds = tf.keras.preprocessing.image_dataset_from_directory( data_dir, validation_split=0.2, subset="validation", seed=123, image_size=(img_height, img_width), batch_size=batch_size,
)
--------------------
Found 1200 files belonging to 4 classes.
Using 960 files for training.
Found 1200 files belonging to 4 classes.
Using 240 files for validation.
获取标签:
# 获取标签
class_names = train_ds.class_names
print(class_names)
------------------
['Dark', 'Green', 'Light', 'Medium']
可视化数据:
# 可视化数据
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(2): for i in range(30): ax = plt.subplot(5, 6, i+1) plt.imshow(images[i].numpy().astype("uint8")) plt.title(class_names[labels[i]]) plt.axis("off")
plt.show()

检查一下数据:
# 检查一下数据
for image_batch, labels_batch in train_ds: print(image_batch.shape) print(labels_batch.shape) break
----------------------------
(32, 224, 224, 3)
(32,)
**3.**配置数据集
# 配置数据集
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE) normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
train_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
val_ds = val_ds.map(lambda x, y: (normalization_layer(x), y)) image_batch, labels_batch = next(iter(train_ds))
first_image = image_batch[0] # 查看归一化后的数据
print(np.min(first_image), np.max(first_image))
--------------------
0.0 1.0
4.搭建VGG-16网络
本次准备直接调用官方模型
# 搭建VGG-16网络模型
model = tf.keras.applications.VGG16(weights="imagenet")
print(model.summary())
-------------------------------
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels.h5
553467096/553467096 [==============================] - 14s 0us/step
Model: "vgg16"
_________________________________________________________________Layer (type) Output Shape Param #
=================================================================input_1 (InputLayer) [(None, 224, 224, 3)] 0 block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 flatten (Flatten) (None, 25088) 0 fc1 (Dense) (None, 4096) 102764544 fc2 (Dense) (None, 4096) 16781312 predictions (Dense) (None, 1000) 4097000 =================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
简简单单1亿的参数的模型。哈哈。
编译一下:
# 编译模型
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay( initial_learning_rate=initial_learning_rate, decay_steps=30, decay_rate=0.92, staircase=True
) # 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=initial_learning_rate) model.compile( optimizer=opt, loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics=['accuracy']
)
训练模型:
# 训练模型
epochs = 20
history = model.fit( train_ds, validation_data=val_ds, epochs=epochs,
)

训练效果不错,可视化看看:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']loss = history.history['loss']
val_loss = history.history['val_loss']epochs_range = range(epochs)plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
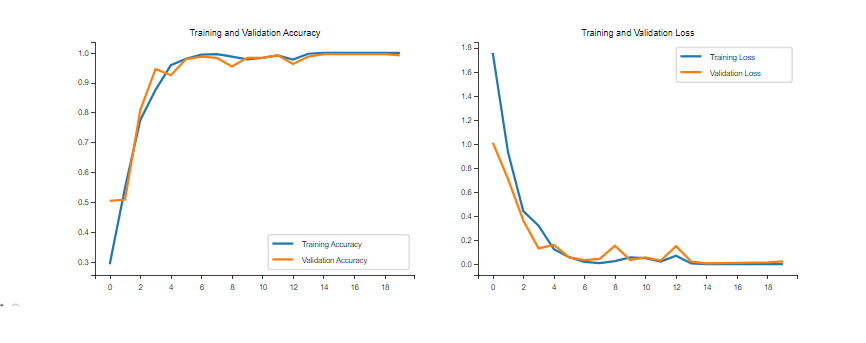
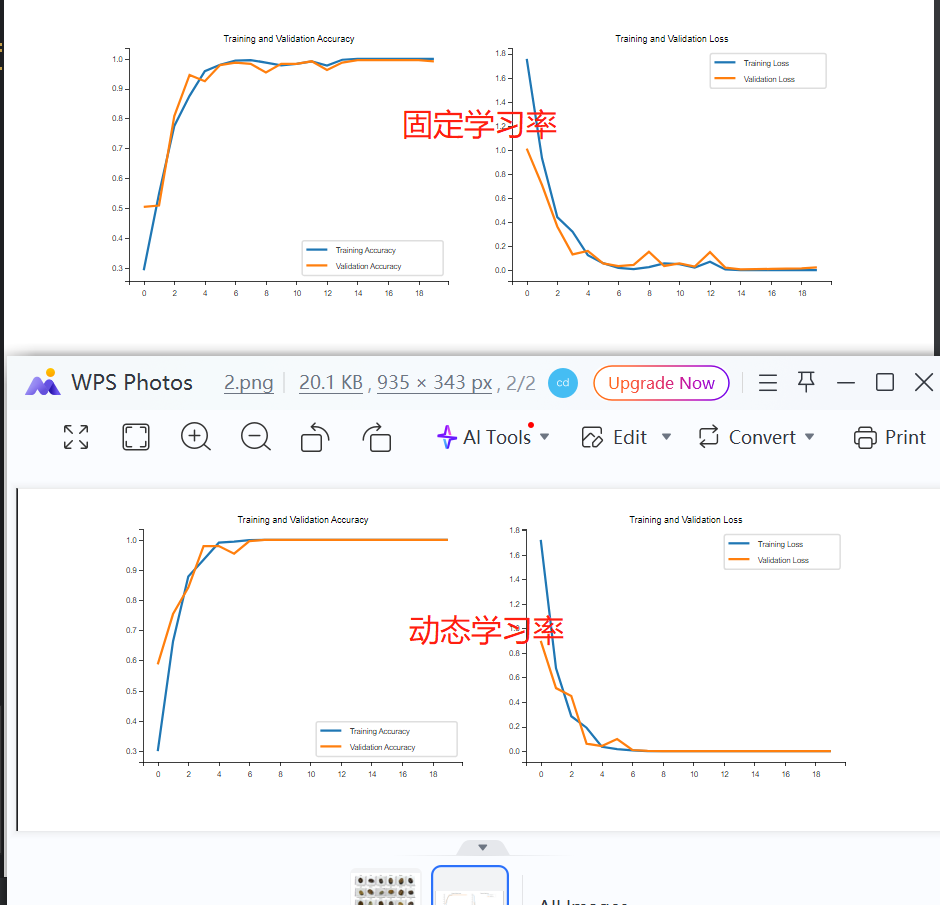
果然超赞。
改成动态学习率的结果:
opt = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
5. 手动搭建VGG-16模型
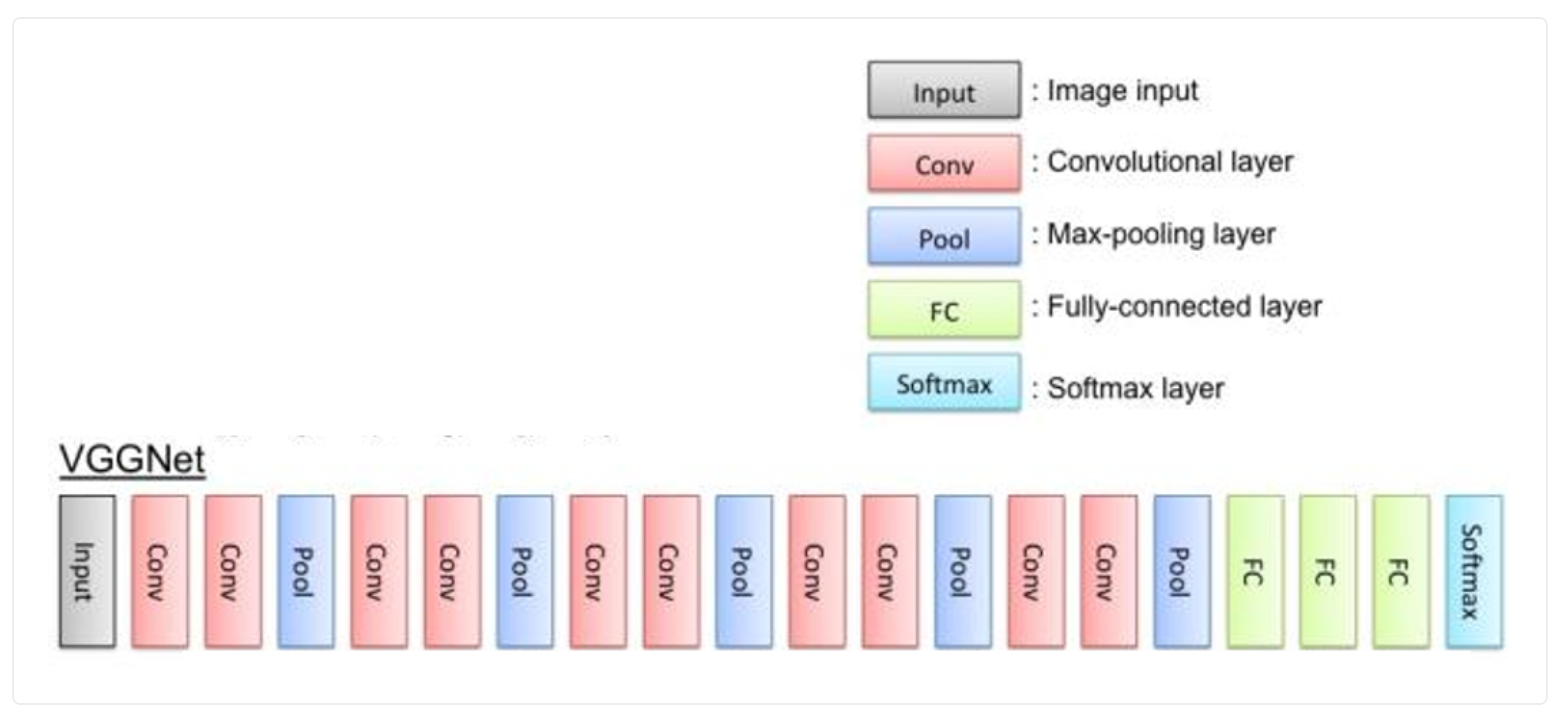

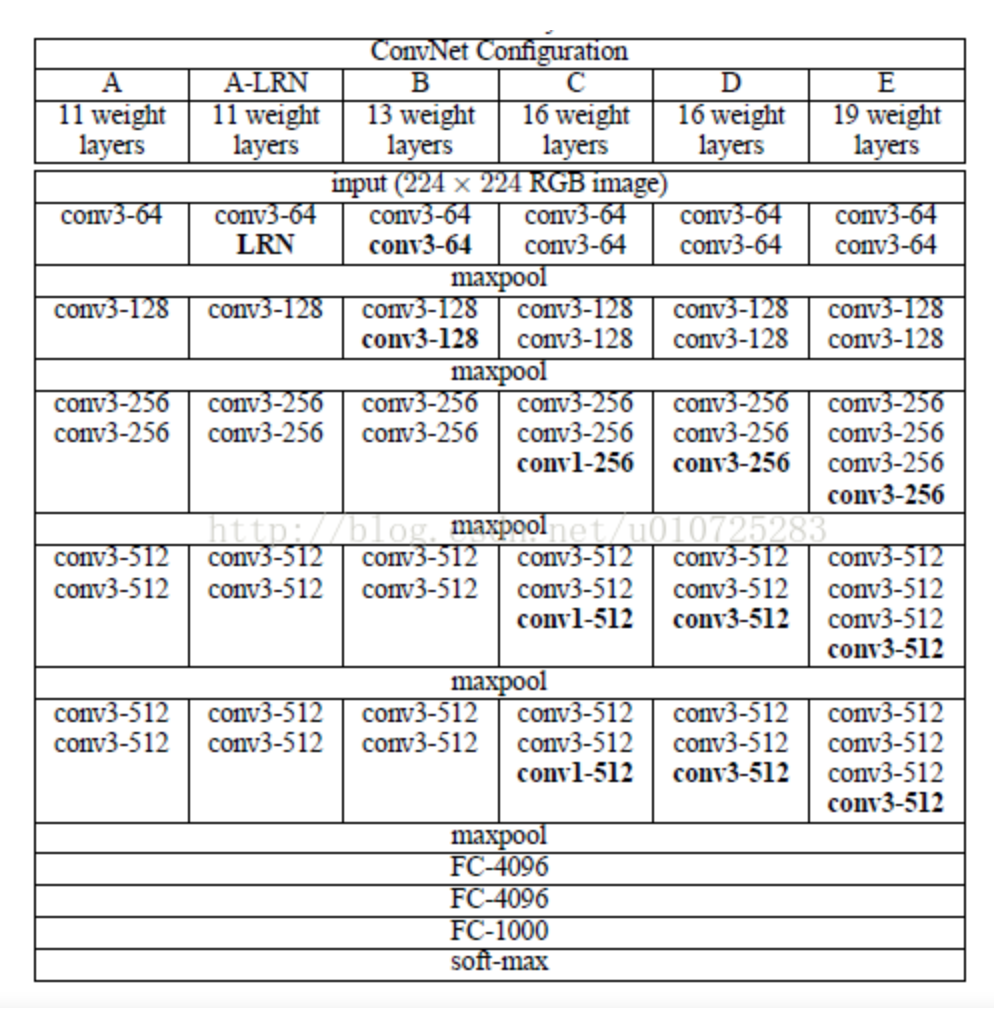
VGG-16的网络 有13个卷积层(被5个max-pooling层分割)和3个全连接层(FC),所有卷积层过滤器的大小都是3X3,步长为1,进行padding。5个max-pooling层分别在第2、4、7、10,13卷积层后面。每次进行池化(max-pooling)后,特征图的长宽都缩小一半,但是channel都翻倍了,一直到512。最后三个全连接层大小分别是4096,4096, 1000,我们使用的是咖啡豆识别,根据数据集的类别数量修改最后的分类数量(即从1000改成len(class_names))
-----------------------------
Model: "model"
_________________________________________________________________Layer (type) Output Shape Param #
=================================================================input_1 (InputLayer) [(None, 224, 224, 3)] 0 block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 flatten (Flatten) (None, 25088) 0 fc1 (Dense) (None, 4096) 102764544 fc2 (Dense) (None, 4096) 16781312 predictions (Dense) (None, 4) 16388 =================================================================
Total params: 134,276,932
Trainable params: 134,276,932
Non-trainable params: 0
_________________________________________________________________(三)总结
相关文章:
第T7周:Tensorflow实现咖啡豆识别
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目标 具体实现 (一)环境 语言环境:Python 3.10 编 译 器: PyCharm 框 架: (二)具体步骤 1. 使…...

imagehash图片去重:保留图片文件名
简介 在日常工作中,我们可能需要管理大量图片,这些图片中可能存在图像相同文件名不同的情况。手动删除这些重复的图片既费时又费力。为了解决这个问题,我们可以编写一个Python脚本来自动化这个过程。 准备工作 在开始之前,请确保…...
在Docker环境下为Nginx配置HTTPS
前言 配置HTTPS已经成为网站部署的必要步骤。本教程将详细介绍如何在Docker环境下为Nginx配置HTTPS,使用自签名证书来实现加密通信。虽然在生产环境中建议使用权威CA机构颁发的证书,但在开发测试或内网环境中,自签名证书是一个很好的选择。 …...

vue面试题9|[2024-11-15]
问题1:scoped原理 1.作用:让样式在本组件中生效,不影响其他组件 2.原理:给节点新增自定义属性,然后css根据属性选择器添加样式。 问题2:让css只在当前组件生效 <style scoped> 问题3:scss…...

大数据技术在金融风控中的应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 大数据技术在金融风控中的应用 大数据技术在金融风控中的应用 大数据技术在金融风控中的应用 引言 大数据技术概述 定义与原理 发…...

安装一键式重置密码插件(Linux)-CloudResetPwdAgent
为了保证使用镜像创建的裸金属服务器可以实现一键式密码重置功能,建议您在制作镜像时安装重置密码插件“CloudResetPwdAgent”。 前提条件 需保证虚拟机根目录可写入,且剩余空间大于600MB。 1.下载插件包 华为云已提供下载包连接 在PC机里下载好软件…...
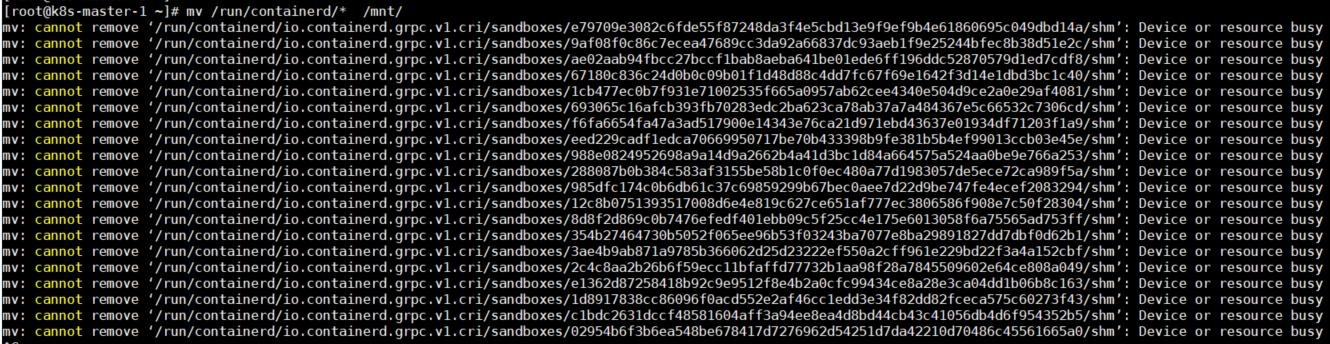
如何平滑切换Containerd数据目录
如何平滑切换Containerd数据目录 大家好,我是秋意零。 这是工作中遇到的一个问题。搭建的服务平台,在使用的过程中频繁出现镜像本地拉取不到问题(在项目群聊中老是被人出来😅)原因是由于/目录空间不足导致࿰…...

月影和米家大路灯哪个好?书客、月影、米家谁会更胜一筹!
月影和米家大路灯哪个好?近两年以来,护眼大路灯以良好的品质走进大众的视线,成为许多用眼人群的刚需品,不少用户说可以改善光线质量,视觉疲劳感夜可以减少,但又有人说护眼大路灯是“幌子、智商税”…...

instanceof 的模式匹配(二)
在经过了JEP305(jdk14)和JEP375(jdk15)的两轮预览之后,模式匹配终于迎来了他的交付日期,在2022年发布的JDK16中,伴随着JEP 394的发布,预览结束了,我们来看一下这个特性的结束点到底说了什么。 在这次预览之中ÿ…...

【Spring】Bean的作用域和Spring的执行流程
目录 1.Bean的作用域 1.1 Singleton(单例) 1.2 Prototype(原型) 1.3 适用于SpringMVC的作用域 2.Spring的执行流程 2.1 Spring容器的初始化 2.2 Bean的创建和装配 2.3 Bean的生命周期管理 2.4 其他重要概念 3. Spring的执行流程简洁版 1.Bean的作用域 Spring Bean的…...

自动驾驶系列—从数据采集到存储:解密自动驾驶传感器数据采集盒子的关键技术
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...

QtWebServer
QtWebServer 是创建基于 Qt 的高性能 Web 应用程序服务器的尝试,即。运行本机 C/Qt 代码以交付网站的 Web 服务器。 一个完美的用例是为较小的服务提供 REST API。 在 Qt 应用程序中,您可以设置资源并将其绑定到物理提供程序,例如文件或数据…...

网络基础概念与应用:深入理解计算机网络
引言 计算机网络作为现代信息技术的重要支柱,是连接世界各地的重要纽带。它使得计算机能够相互通信、协同工作,从而极大地提高了我们的工作效率和生活质量。本篇文章将深入探讨计算机网络的基础概念,覆盖网络的分层模型、协议、数据传输原理…...

<el-select> :remote-method用法
el-select :remote-method用法 说明代码实现单选多选 说明 在 Vue.js 中, 是 Element UI 库提供的一个下拉选择框组件。:remote-method 是 组件的一个属性,用于指定一个远程方法,该方法将在用户输入时被调用,以获取下拉列表的选项…...

CKA认证 | Day3 K8s管理应用生命周期(上)
第四章 应用程序生命周期管理(上) 1、在Kubernetes中部署应用流程 1.1 使用Deployment部署Java应用 在 Kubernetes 中,Deployment 是一种控制器,用于管理 Pod 的部署和更新。以下是使用 Deployment 部署 Java 应用的步骤&#x…...

JavaWeb——HTML、CSS
目录 1.概述 2.HTML a.HTML结构标签 b.图片标签 c.标题标签 d.水平线标签 e.布局标签 f.超链接标签 e.视频标签 f.音频标签 e.换行标签 f.段落标签 g.加粗标签 h.表格 1.声明表格 2.表行 3.普通表格 4.加粗表格 i.表单标签 1.声明表单 2. 表单 3.下拉列表…...

springboot如何获取控制层get和Post入参
一、在 Spring 配置中创建一个过滤器,将 HttpServletRequest 包装为 ContentCachingRequestWrapper import org.springframework.stereotype.Component; import org.springframework.web.filter.OncePerRequestFilter; import javax.servlet.FilterChain; import j…...
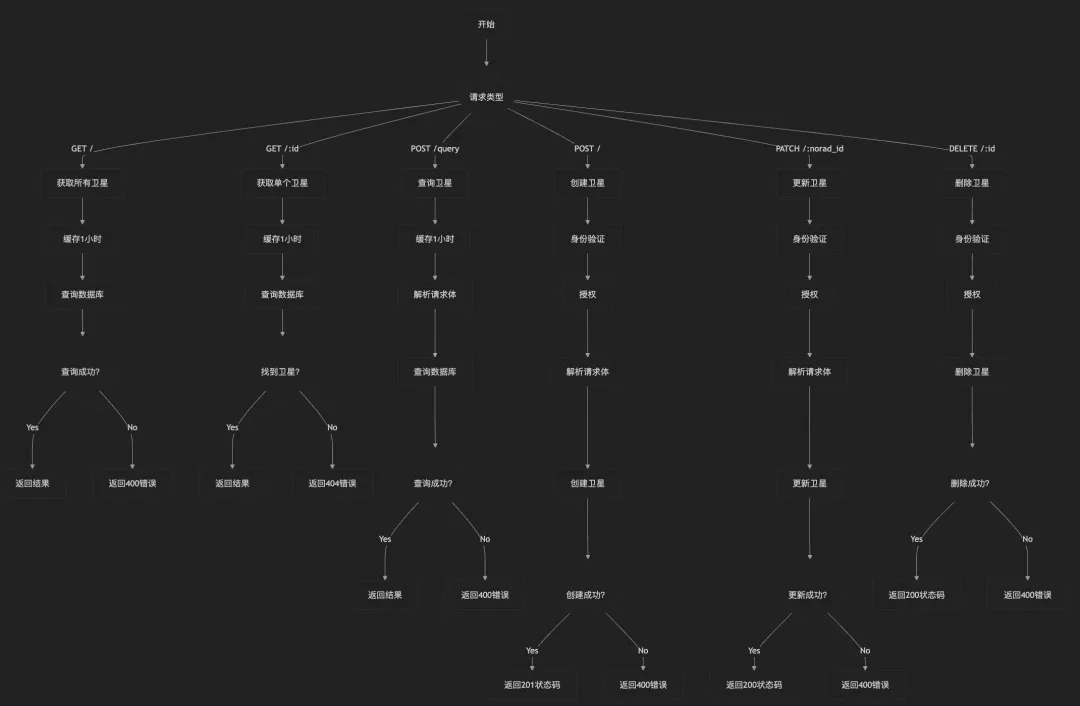
30 秒!用通义灵码画 SpaceX 星链发射流程图
不想读前人“骨灰级”代码, 不想当“牛马”程序员, 想像看图片一样快速读复杂代码和架构? 来了,灵码又加新 buff!! 通义灵码支持代码逻辑可视化, 可以把你的每段代码画成流程图。 你可以把…...

设计模式之组合模式(营销差异化人群发券,决策树引擎搭建场景)
前言: 往往很多大需求都是通过增删改查堆出来的,今天要一个需求if一下,明天加个内容else扩展一下。日积月累需求也就越来越大,扩展和维护的成本也就越来越高。往往大部分研发是不具备产品思维和整体业务需求导向的,总以…...

关于做完 C# 项目的问题总结
1. .Any()方法使用 可以与其他LINQ方法结合使用,以构建更复杂的查询。例如,你可以首先过滤集合,然后检查过滤后的集合是否包含任何元素: List<string> fruits new List<string> { "Apple", "Banana&q…...

收藏!小白程序员必看:如何抓住AI大模型时代红利?从入门到高薪就业全解析!
脉脉《2026春招职场洞察报告》显示,AI岗位量同比暴增8.7倍,AI科学家/负责人月薪破10万元,成为高薪职业断层领先者。新经济行业高薪岗位TOP20中,AI占据多数。字节跳动、大疆等大厂吸纳就业力强。文章建议考生关注AI相关新专业&…...

手把手教你创建CST自定义材料:以吸波材料为例,导入厂家S参数曲线
手把手教你创建CST自定义材料:以吸波材料为例,导入厂家S参数曲线 在电磁仿真领域,材料参数的精确建模往往是决定仿真结果可靠性的关键因素。当我们需要模拟特殊频段的吸波材料、频率色散介质或各向异性材料时,仅依赖CST内置材料库…...

用NE555和LM324做个红外倒车雷达:从仿真到焊接,一个模电新手的踩坑实录
从零打造红外倒车雷达:NE555与LM324实战手记 第一次拿起电烙铁时,我的手抖得像风中的芦苇。作为电子工程专业的大二学生,模电课的理论公式在面包板上变成了一团乱麻。直到导师建议我尝试做个红外倒车雷达——这个结合了振荡电路、信号放大和电…...

3步打造智能设计转换桥梁:从Figma到Unity的无缝对接方案
3步打造智能设计转换桥梁:从Figma到Unity的无缝对接方案 【免费下载链接】UnityFigmaBridge Easily bring your Figma Documents, Components, Assets and Prototypes to Unity 项目地址: https://gitcode.com/gh_mirrors/un/UnityFigmaBridge 在现代游戏开发…...

别再滥用Promise.all了!聊聊Vue/React项目中用p-limit控制并发请求的实战心得
别再滥用Promise.all了!聊聊Vue/React项目中用p-limit控制并发请求的实战心得 在Vue/React项目中处理批量数据请求时,许多开发者会条件反射地使用Promise.all,认为这是最高效的方案。直到某次线上事故——用户尝试导出500条订单数据时浏览器直…...

5分钟实战:用Sunshine轻松搭建你的专属游戏串流服务器
5分钟实战:用Sunshine轻松搭建你的专属游戏串流服务器 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 还在为只能在书房玩游戏而烦恼吗?想不想在客厅大电视…...

华为鸿蒙与欧拉操作系统:全场景战略下的技术架构与生态构建
1. 从“备胎”到“主干”:华为操作系统的战略突围之路 最近科技圈里关于华为的消息,大家讨论得最多的,除了孟晚舟女士的归国,可能就是华为在软件领域接连放出的几个“大招”了。作为一名在ICT行业摸爬滚打了十几年的老兵ÿ…...

Python跨平台应用开发终极指南:用Flet框架轻松构建桌面、移动和Web应用
Python跨平台应用开发终极指南:用Flet框架轻松构建桌面、移动和Web应用 【免费下载链接】flet Build realtime web, mobile and desktop apps in Python only. No frontend experience required. 项目地址: https://gitcode.com/gh_mirrors/fl/flet 你是否曾…...

从协议到实战:深度剖析WiFi Deauth攻击的底层原理与Kali工具链应用
1. WiFi Deauth攻击的本质:从协议层理解管理帧 当你用手机连接咖啡厅的WiFi时,背后其实在进行一场精密的无线协议对话。802.11标准中定义了三种关键帧类型:数据帧负责传输网页内容,控制帧协调信道占用,而管理帧则是连…...

终极指南:如何在Mac上完美使用Xbox控制器玩游戏
终极指南:如何在Mac上完美使用Xbox控制器玩游戏 【免费下载链接】360Controller TattieBogle Xbox 360 Driver (with improvements) 项目地址: https://gitcode.com/gh_mirrors/36/360Controller 你是否曾经在Mac上尝试连接Xbox控制器,却发现按键…...