机器学习(基础2)
特征工程
特征工程:就是对特征进行相关的处理
一般使用pandas来进行数据清洗和数据处理、使用sklearn来进行特征工程
特征工程是将任意数据(如文本或图像)转换为可用于机器学习的数字特征,比如:字典特征提取(特征离散化)、文本特征提取、图像特征提取。
特征工程API
实例化转换器对象,转换器类有很多,都是Transformer的子类, 常用的子类有:
DictVectorizer 字典特征提取
CountVectorizer 文本特征提取
TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
MinMaxScaler 归一化
StandardScaler 标准化
VarianceThreshold 底方差过滤降维
PCA 主成分分析降维转换器对象调用fit_transform()进行转换, 其中fit用于计算数据,transform进行最终转换
fit_transform()可以使用fit()和transform()代替
data_new = transfer.fit_transform(data)
可写成
transfer.fit(data)
data_new = transfer.transform(data)DictVectorizer 字典列表特征提取
api
-
创建转换器对象:
sklearn.feature_extraction.DictVectorizer(sparse=True)
参数:
sparse=True返回类型为csr_matrix的稀疏矩阵
sparse=False表示返回的是数组,数组可以调用.toarray()方法将稀疏矩阵转换为数组
-
转换器对象:
转换器对象调用fit_transform(data)函数,参数data为一维字典数组或一维字典列表,返回转化后的矩阵或数组
转换器对象get_feature_names_out()方法获取特征名
示例1 提取为稀疏矩阵对应的数组
from sklearn.feature_extraction import DictVectorizer
import pandas as pd
data =[{'city':'成都','age':30,'temperature':200},{'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
transfer = DictVectorizer(sparse=False)
arr = transfer.fit_transform(data)
feature = transfer.get_feature_names_out()
ddata = pd.DataFrame(arr,columns=feature)
print(ddata)
示例2 提取为稀疏矩阵
from sklearn.feature_extraction import DictVectorizer
import pandas as pd
data =[{'city':'成都','age':30,'temperature':200},{'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
transfer = DictVectorizer(sparse=True)
arr = transfer.fit_transform(data)
print(arr)
稀疏矩阵转为数组
稀疏矩阵对象调用toarray()函数, 得到类型为ndarray的二维稀疏矩阵
from sklearn.feature_extraction import DictVectorizer
import pandas as pd
data =[{'city':'成都','age':30,'temperature':200},{'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
transfer = DictVectorizer(sparse=True)
arr = transfer.fit_transform(data)
print(arr)
arr1 = arr.toarray()
print(arr1)
CountVectorizer 文本特征提取
API
sklearn.feature_extraction.text.CountVectorizer
构造函数关键字参数stop_words,值为list,表示词的黑名单(不提取的词)
fit_transform函数的返回值为稀疏矩阵
英文文本提取
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
data = ['i love you','you like her','i like book']
# 创建转换器对象
transfer = CountVectorizer(stop_words=[])
# 提取,得到稀疏矩阵
data1 = transfer.fit_transform(data)
print(data1)
# data1转为对应的完整数组
data2 = data1.toarray()
# 获取特征名称
feature = transfer.get_feature_names_out()
# 创建DataFrame对象
arr = pd.DataFrame(data2,columns=feature)
print(arr)
中文文本提取
a.中文文本不像英文文本,中文文本文字之间没有空格,所以要先分词,一般使用jieba分词.
b.下载jieba组件, (不要使用conda)
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import jieba
def cut(text):return ' '.join(list(jieba.cut(text)))data = ['正义也许会迟到,但永远不会缺席','迟到的正义还是正义吗','正义和邪恶究竟哪一方会缺席']
data1 = [cut(i) for i in data]
print(data1)
transfer = CountVectorizer(stop_words=['还是'])
re = transfer.fit_transform(data1)
print(re)
feature = transfer.get_feature_names_out()
arr = re.toarray()
ddata = pd.DataFrame(arr,columns=feature)
ddata


数字代表这个词在句子中出现的频次,在代码中“还是”被作为了黑名单词,并不会进行划分
TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
API
sklearn.feature_extraction.text.TfidfVectorizer()
构造函数关键字参数stop_words,表示词特征黑名单
fit_transform函数的返回值为稀疏矩阵
示例
代码与CountVectorizer的示例基本相同,仅仅把CountVectorizer改为TfidfVectorizer即可
示例中data是一个字符串list, list中的第一个元素就代表一篇文章.
from sklearn.feature_extraction.text import TfidfVectorizer,CountVectorizer
import pandas as pd
import jieba
data = ['正义也许会迟到,但永远不会缺席','迟到的正义还是正义吗','正义和邪恶究竟哪一方会缺席']
def cut(text):return ' '.join(jieba.cut(text))
data1 = [cut(i) for i in data]
transfer1 = TfidfVectorizer(stop_words=[])
transfer2 = CountVectorizer(stop_words=[])
data01 = transfer1.fit_transform(data1)
data02 = transfer2.fit_transform(data1)
# 转换成完整矩阵
arr1 = data01.toarray()
arr2 = data02.toarray()
# 获取特征名称
feature1 = transfer1.get_feature_names_out()
feature2 = transfer2.get_feature_names_out()
# 创建DataFrame对象
Data1 = pd.DataFrame(arr1,columns=feature1)
Data2 = pd.DataFrame(arr2,columns=feature2)
Data1
Data2

无量纲化-预处理
无量纲,即没有单位的数据
无量纲化包括"归一化"和"标准化", 为什么要进行无量纲化呢?
(1) MinMaxScaler 归一化
通过对原始数据进行变换把数据映射到指定区间(默认为0-1)
<1>归一化公式:

这里的 𝑥min 和 𝑥max 分别是每种特征中的最小值和最大值,而 𝑥是当前特征值,𝑥scaled 是归一化后的特征值。
若要缩放到其他区间,可以使用公式:x=x*(max-min)+min;
<2>归一化API
sklearn.preprocessing.MinMaxScaler(feature_range)
参数:feature_range=(0,1) 归一化后的值域,可以自己设定
fit_transform函数归一化的原始数据类型可以是list、DataFrame和ndarray, 不可以是稀疏矩阵
fit_transform函数的返回值为ndarray
<3>归一化示例
from sklearn.preprocessing import MinMaxScaler
data = [[19,12,15],[23,15,25],[25,18,20]]
# 定义转换后的值域
transfer = MinMaxScaler(feature_range=(0,1))
# 转换
data1 = transfer.fit_transform(data)
print(data1)
<4>缺点
最大值和最小值容易受到异常点影响,所以鲁棒性较差。所以常使用标准化的无量钢化
(2)StandardScaler 标准化
<1>标准化公式
最常见的标准化方法是Z-score标准化,也称为零均值标准化。它通过对每个特征的值减去其均值,再除以其标准差,将数据转换为均值为0,标准差为1的分布。这可以通过以下公式计算:

其中,z是转换后的数值,x是原始数据的值,μ是该特征的均值,σ是该特征的标准差
<2> 标准化 API
sklearn.preprocessing.StandardScale
与MinMaxScaler一样,原始数据类型可以是list、DataFrame和ndarray
fit_transform函数的返回值为ndarray, 归一化后得到的数据类型都是ndarray
from sklearn.preprocessing import StandardScaler
data = [[19,12,15],[23,15,25],[25,18,20]]
transfer = StandardScaler()
data1 = transfer.fit_transform(data)
print(data1)
<3>标准化示例
from sklearn.preprocessing import StandardScaler
import numpy as np
import pandas as pd
# 获取数据
data = pd.read_csv('./src/dating.txt')
print(type(data)) # <class 'pandas.core.frame.DataFrame'>
print(data.shape) # (1000, 4)
# 实例化一个转换器
transfer = StandardScaler()
# 调用fit_transform
data1 = transfer.fit_transform(data) # 把DataFrame数据进行标准化
print(data1[0:5])
data2 = data.values # 把DateFrame转为ndarray
data3 = transfer.fit_transform(data2) # 把ndarray数据进行标准化
print(data3[0:5])
data4 = data.values.tolist() # 把DateFrame转为list
data5 = transfer.fit_transform(data4) #把list数据进行标准化
print(data5[0:5])特征降维
实际数据中,有时候特征很多,会增加计算量,降维就是去掉一些特征,或者转化多个特征为少量个特征
特征降维其目的:是减少数据集的维度,同时尽可能保留数据的重要信息。
特征选择
(a) VarianceThreshold 低方差过滤特征选择
-
Filter(过滤式): 主要探究特征本身特点, 特征与特征、特征与目标 值之间关联
方差选择法: 低方差特征过滤-
如果一个特征的方差很小,说明这个特征的值在样本中几乎相同或变化不大,包含的信息量很少,模型很难通过该特征区分不同的对象,比如区分甜瓜子和咸瓜子还是蒜香瓜子,如果有一个特征是长度,这个特征相差不大可以去掉。
-
过滤特征:移除所有方差低于设定阈值的特征
-
设定阈值:选择一个方差阈值,任何低于这个阈值的特征都将被视为低方差特征。
-
计算方差:对于每个特征,计算其在训练集中的方差(每个样本值与均值之差的平方,在求平均)。
-
from sklearn.feature_selection import VarianceThreshold
import pandas as pd
def variance_demo():# 1、获取数据,data是一个DataFrame,可以是读取的csv文件data=pd.DataFrame([[10,1,2],[11,3,3],[11,1,5],[11,5,7],[11,9,12],[11,3,14],[11,2,12],[11,6,9]])print(data)# 实例化一个转换器transfer = VarianceThreshold(threshold=1)# 调用fit_transformdata1 = transfer.fit_transform(data)print('data1:\n',data1)return None
variance_demo()

(b) 根据相关系数的特征选择
<1>理论
正相关性(Positive Correlation)是指两个变量之间的一种统计关系,其中一个变量的增加通常伴随着另一个变量的增加,反之亦然。在正相关的关系中,两个变量的变化趋势是同向的。当我们说两个变量正相关时,意味着:
-
如果第一个变量增加,第二个变量也有很大的概率会增加。
-
同样,如果第一个变量减少,第二个变量也很可能会减少。
<2>api:
scipy.stats.personr(x, y) 计算两特征之间的相关性
返回对象有两个属性:
statistic皮尔逊相关系数[-1,1]
pvalue零假设(了解),统计上评估两个变量之间的相关性,越小越相关
<3>示例:
from scipy.stats import pearsonr
import pandas as pd
def pear():# 获取数据data = pd.DataFrame([[1,2,3],[2,4,5],[3,5,4],[4,6,2],[5,8,5],[6,8,4]],columns=['1','2','3'])print(data)# 计算某两个变量之间的相关系数r1 = pearsonr(data['1'],data['2'])print(r1.statistic,r1.pvalue)
pear()
![]()
2.主成份分析(PCA)
PCA的核心目标是从原始特征空间中找到一个新的坐标系统,使得数据在新坐标轴上的投影能够最大程度地保留数据的方差,同时减少数据的维度。
原理:将不同特征看作向量投射到一条新向量上。达到降维的目的

投影到L上的值就是降维后保留的信息,投影到与L垂直的轴上的值就是丢失的信息。保留信息/丢失信息=信息保留的比例
api
-
from sklearn.decomposition import PCA
-
PCA(n_components=None)
-
主成分分析
- n_components:
-
实参为整数时:表示减少到多少特征
-
实参为小数时:表示降维后保留百分之多少的信息
-
n_components为小数,例(0.8),表示保留80%的特征信息来进行降维
n_components为整数,例(3),表示最后结果只保留下3个特征,来进行降维
示例:
from sklearn.decomposition import PCA
data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]]
# 实例化转换器
transfer = PCA(n_components=0.8)
# 调用fit_transform
arr = transfer.fit_transform(data)
print('arr:\n',arr)
将4维特征降为了2维特征。
相关文章:
机器学习(基础2)
特征工程 特征工程:就是对特征进行相关的处理 一般使用pandas来进行数据清洗和数据处理、使用sklearn来进行特征工程 特征工程是将任意数据(如文本或图像)转换为可用于机器学习的数字特征,比如:字典特征提取(特征离散化)、文本特征提取、图像特征提取。 特征工程API 实例化…...

Cpolar 内网穿透使用
Cpolar登录地址:cpolar - secure introspectable tunnels to localhost 使用固定公网TCP连接ssh ssh -p端口号 用户名公网地址...

ThreadLocal 提供线程局部变量
ThreadLocal作用 相当于建立一个独立的空间,可以把使用频率高的任何类型的数据放到里面,方便调用用来存取数据:set()/get()使用ThreadLocal存储的数据,线程安全 ThreadLocal工具类 /*** ThreadLocal 工具类*/ SuppressWarnings(…...

MongoDB聚合管道数组操作
数组表达式运算符判断数组中是否包含元素( i n ) 并获取元素索引 ( in)并获取元素索引( in)并获取元素索引(indexOfArray) 一、初始化成员数据 db.persons.insertMany([{ "_id" : "1001", "name" : "张三", "fruits" : [ …...

大数据如何助力干部选拔的公正性
随着社会的发展和进步,干部选拔成为组织管理中至关重要的一环。传统的选拔方式可能存在主观性、不公平性以及效率低下等问题。大数据技术的应用,为干部选拔提供了更加全面、精准、客观的信息支持,显著提升选拔工作的科学性和公正性。以下是大…...

Python_爬虫2_爬虫引发的问题
目录 爬虫引发的问题 网络爬虫的尺寸 网络爬虫引发的问题 网络爬虫的限制 Robots协议 Robots协议的遵守方式 Robots的使用 对Robots协议的理解 爬虫引发的问题 网络爬虫的尺寸 爬取网页,玩转网页: 小规模,数据量小,爬取…...

shell编程之编程基础
目录 为什么学习和使用Shell编程Shell是什么shell起源查看当前系统支持的shell查看当前系统默认shellShell 概念 Shell 程序设计语言Shell 也是一种脚本语言用途 如何学好shell熟练掌握shell编程基础知识建议 Shell脚本的基本元素基本元素构成:Shell脚本中的注释和风…...
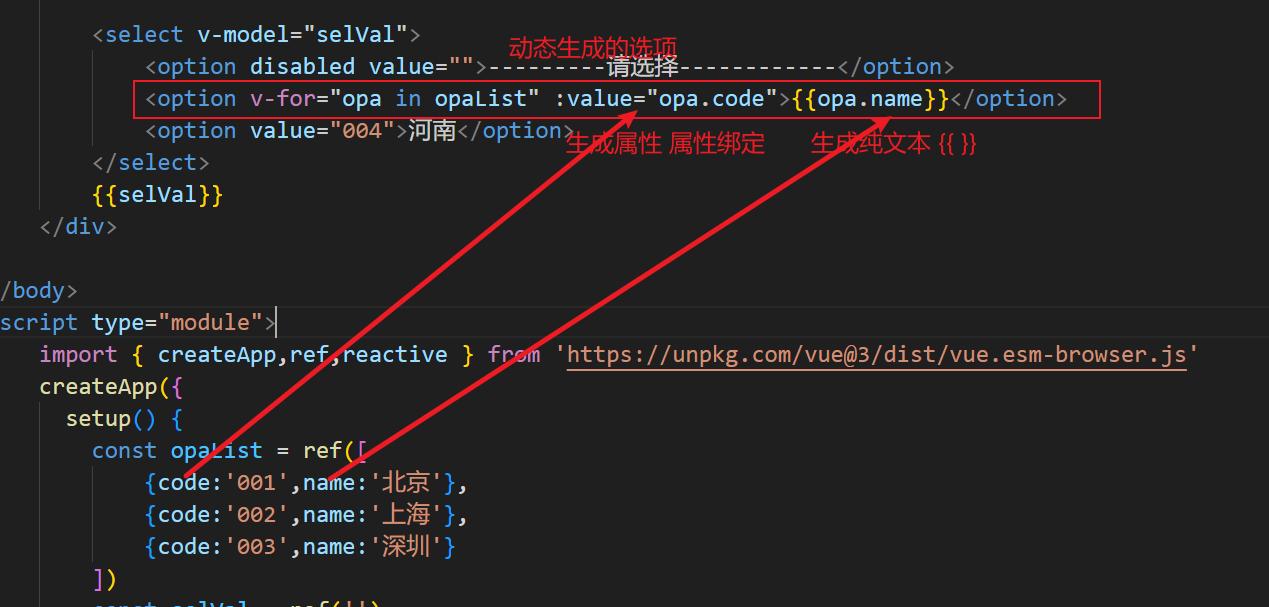
24.11.15 Vue3
let newJson new Proxy(myJson,{get(target,prop){console.log(在读取${prop}属性);return target[prop];},set(target,prop,val){console.log(在设置${prop}属性值为${val});if(prop"name"){document.getElementById("myTitle").innerHTML val;}if(prop…...
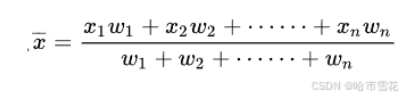
图形几何之美系列:法向量计算之轮廓有向面积辅助法
“ 垂直于平面的直线所表示的向量为该平面的法向量,可以通过法向量识别平面正反面。法向量是轮廓或面的重要特征,求轮廓法向是一种基础的几何工具算法,在图形几何、图像处理等领域具有广泛的应用。” 图形几何之美系列:三维实体结…...

CPU的性能指标总结(学习笔记)
CPU 性能指标 我们先来回顾下,描述 CPU 的性能指标都有哪些。 首先,最容易想到的应该是 CPU 使用率,这也是实际环境中最常见的一个性能指标。 用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用…...

Cadence安装
记录一下安装过程,方便以后安装使用Cadence。 去吴川斌的博客下载安装包,吴川斌博客: https://www.mr-wu.cn/cadence-orcad-allegro-resource-downloads/ 下载阿狸狗破戒大师 我这边下载的是版本V3.2.6,同样在吴川斌的博客下载安装…...

【网络】子网掩码
> 作者:დ旧言~ > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:了解什么是子网掩码,并且能熟练掌握子网掩码的相关计算。 > 毒鸡汤:有些事情,总是不明白,所以我不会…...

Android Osmdroid + 天地图 (二)
Osmdroid 天地图 (二) 前言正文一、定位监听二、改变地图中心三、添加Marker四、地图点击五、其他配置① 缩放控件② Marker更换图标③ 添加比例尺④ 添加指南针⑤ 添加经纬度网格线⑥ 启用旋转手势⑦ 添加小地图 六、源码 前言 上一篇中我们显示了地图…...

使用大语言模型创建 Graph 数据
Neo4j 是开源的 Graph 数据库,Graph 数据通过三元组进行表示,两个顶点一条边,从语意上可以理解为:主语、谓语和宾语。GraphDB 能够通过图来表达复杂的结构,非常适合存储知识型数据,本文将通过大语言实现图数…...
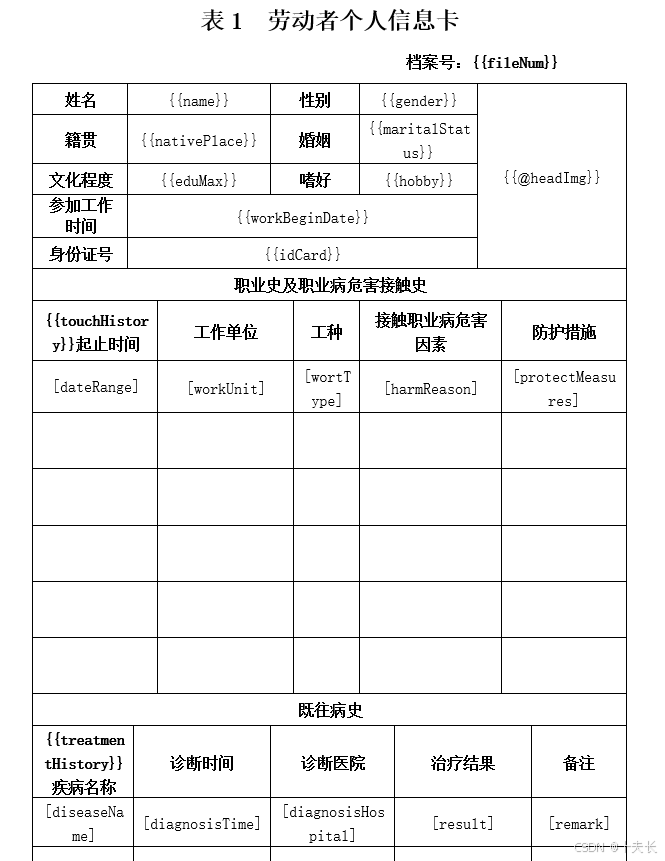
Java poi 模板导出Word 带图片
Java poi 模板导出Word 带图片 重点!!! 官方文档:https://deepoove.com/poi-tl/#_maven 最终效果 模板 其实内容都在官方文档里写的非常明白了 我这里只是抛砖引玉。 Maven依赖 <poi.version>4.1.2</poi.version>…...

SpringCloud-使用FFmpeg对视频压缩处理
在现代的视频处理系统中,压缩视频以减小存储空间、加快传输速度是一项非常重要的任务。FFmpeg作为一个强大的开源工具,广泛应用于音视频的处理,包括视频的压缩和格式转换等。本文将通过Java代码示例,向您展示如何使用FFmpeg进行视…...
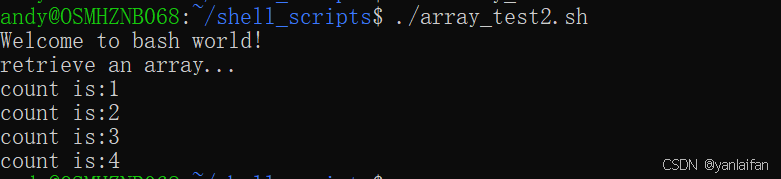
shell bash---类似数组类型
0 Preface/Foreword C/C,Python,Java等编程语言,都含有数组类型,那么shell脚本是不是也有类似的语法呢? 1 类似数组类型 1.1 ()类似数组类型 #! /bin/bashecho "Welcome to bash world!" anim…...
)
IIoT(Industrial Internet of Things,工业物联网)
IIoT(Industrial Internet of Things,工业物联网) 是指物联网技术在工业领域的应用。它将工业设备、传感器、控制系统、数据采集设备等通过互联网或局域网连接起来,实现设备的互联互通和智能化管理。IIoT的目标是提高工业生产效率…...
)
【C++】引用(reference)
引用是对一个变量或者对象取的别名 定义:真名的数据类型& 别名 真名; 既然是对一个变量或者对象取别名,那就得先有变量或对象,不能凭空取一个别名。也就是定义引用必须初始化。 对引用的操作和对引用对应的变量的操作是完全等价的引用…...

学习日记_20241115_聚类方法(层次聚类)
前言 提醒: 文章内容为方便作者自己后日复习与查阅而进行的书写与发布,其中引用内容都会使用链接表明出处(如有侵权问题,请及时联系)。 其中内容多为一次书写,缺少检查与订正,如有问题或其他拓展…...

为什么你的NotebookLM要点召回率低于61.8%?——基于172份真实用户数据集的BERT-Chunk对齐缺陷报告
更多请点击: https://intelliparadigm.com 第一章:NotebookLM要点提取方法概览 核心原理与数据输入方式 NotebookLM 通过语义理解而非关键词匹配来提取要点,其底层依赖于 Google 的 Gemini 模型对上传文档(PDF、TXT、Google Doc…...
)
超越点灯:深入探索高云FPGA云源软件的高级调试与优化功能(逻辑分析仪+时序约束实战)
超越点灯:深入探索高云FPGA云源软件的高级调试与优化功能(逻辑分析仪时序约束实战) 当LED流水灯项目已经无法满足你的FPGA开发需求时,意味着你正站在从入门到进阶的关键转折点。高云FPGA平台提供的云源软件不仅支持基础开发&#…...

NotebookLM摘要质量断崖式下滑?揭秘92%用户忽略的3个语义锚点校准技巧
更多请点击: https://intelliparadigm.com 第一章:NotebookLM摘要质量断崖式下滑的真相溯源 近期大量用户反馈 NotebookLM 生成的摘要出现关键信息遗漏、逻辑断裂与事实扭曲等现象,部分案例中摘要准确率较 2023 年底下降超 40%。这一退化并非…...

别再只用MD5了!聊聊Java中MessageDigest的SHA-256、SHA-3等算法选择与实战避坑
别再只用MD5了!Java哈希算法安全升级实战指南 哈希算法在现代应用开发中扮演着数据指纹的角色,但很多Java开发者仍然停留在MD5/SHA-1的舒适区。当数据库泄露事件频发、算力攻击成本不断降低时,选择正确的哈希算法已经不再是简单的技术选型问题…...

NotebookLM电影文献处理失效真相:92%研究者忽略的3类语义断层及修复方案
更多请点击: https://kaifayun.com 第一章:NotebookLM电影研究辅助 NotebookLM 是 Google 推出的基于 AI 的研究协作者,专为深度阅读与知识整合设计。在电影研究场景中,它能高效解析剧本、影评、导演访谈、学术论文等多源文本&am…...
)
高校学生综合测评管理系统(10054)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

小学期学习报告-1
通过B站视频学习之后,我掌握冰设计出了555方波发生电路和低通滤波器,通过示波器可以看到,已经除了稳定的方波和正弦波 在这个过程中,根据公式T0.7*( R12R2)*C1,多次调整并得出稳定波形ÿ…...
)
从热设计小白到专家:我是如何用RC6-4-01这颗TEC搞定激光器温控的(真实项目复盘)
从热设计小白到专家:我是如何用RC6-4-01这颗TEC搞定激光器温控的(真实项目复盘) 激光器温控从来不是简单的"制冷片贴上去就行"。去年接手某光纤激光器项目时,面对客户要求的0.1℃控温精度,我盯着规格书里密密…...

如何用VR-Reversal在普通屏幕上观看VR视频:3分钟免费转换指南
如何用VR-Reversal在普通屏幕上观看VR视频:3分钟免费转换指南 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址: https://gitcode.co…...

Warcraft Helper完整指南:3步解决魔兽争霸3在Win10/Win11的兼容性问题
Warcraft Helper完整指南:3步解决魔兽争霸3在Win10/Win11的兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在W…...