J.U.C - 深入解读阻塞队列实现原理源码
文章目录
- Pre
- 生产者-消费者模式
- 阻塞队列 vs 普通队列
- JUC提供的7种适合与不同应用场景的阻塞队列
- 插入操作:添加元素到队列中
- 移除操作:从队列中移除元素。
- ArrayBlockingQueue源码解析
- 类结构
- 指定初始容量及公平/非公平策略的构造函数
- 根据已有集合初始化队列的构造函数
- ArrayBlockingQueue主要属性
- 出队和入队的环形队列
- 插入元素
- 1. offer(E e)方法:非阻塞插入元素
- 2. add(E e)方法:非阻塞插入元素
- 3. put(E e)方法:阻塞式插入元素
- 4. offer(e,time,unit):阻塞式插入元素
- 移除元素
- 1. poll()方法:非阻塞移除元素
- 2. remove()方法:非阻塞移除元素
- 3. take()方法:阻塞式移除元素
- 4.poll(long timeout, TimeUnit unit)):阻塞式移除元素
- 小结
- LinkedBlockingQueue源码解析
- LinkedBlockingQueue类结构
- LinkedBlockingQueue的主要属性
- LinkedBlockingQueue的三个构造函数
- 插入元素
- 移除元素
- 小结
- ArrayBlockingQueue vs LinkedBlockingQueue 小结

Pre
J.U.C Review - 阻塞队列原理/源码分析
生产者-消费者模式
阻塞队列的使用场景一般是在“生产者-消费者”模式中,在该模式中“生产者”和“消费者”相互独立,两者之间的通信依靠阻塞队列完成。
生产者将待处理的数据放入“队列”中,随后消费者从该“队列”中取出数据进行后续处理。“生产者-消费者”模式简化了开发流程,消除了“生产者”和“消费者”对代码实现的依赖,生产者只需将生成的数据放入队列中,而不需要知道由谁消费以及何时和如何消费,同样消费者也不需要知道数据是谁生产的,这样就实现了将“生产者”和“消费者”两者操作解耦。
在JUC中,线程池本质上就是一个“生产者-消费者”模式的实现,提交任务的线程是生产者,线程池中线程是消费者,在线程池中当提交的任务不能被立即执行的时候,线程池就会将提交的任务放到一个阻塞的任务队列中。我们可以根据业务场景的需求,选用相应类型的阻塞队列来构造不同功能的线程池。
阻塞队列 vs 普通队列
阻塞队列与普通队列的区别在于,阻塞队列提供了可阻塞的put和take方法。
- 如果队列是空的,消费者使用take方法从队列中获取数据就会被阻塞,直到队列有数据可用;
- 当队列是满的,生产者使用put方法向队列里添加数据就会被阻塞,直到队列中数据被消费有空闲位置可用
JUC提供的7种适合与不同应用场景的阻塞队列
JUC提供了7种适合与不同应用场景的阻塞队列。
- 1)ArrayBlockingQueue:基于数组实现的有界阻塞队列。
- 2)LinkedBlockingQueue:基于链表实现的有界阻塞队列。
- 3)PriorityBlockingQueue:支持按优先级排序的无界阻塞队列。
- 4)DelayQueue:优先级队列实现的无界阻塞队列。
- 5)SynchronousQueue:不存储元素的阻塞队列。
- 6)LinkedTransferQueue:基于链表实现的无界阻塞队
- 7)LinkedBlockingDeque:基于链表实现的双向无界阻塞队列。
7个阻塞队列全部实现了BlockingQueue接口,插入和移除元素分别各提供了4种处理方式。
插入操作:添加元素到队列中
- 1)
add(e):当队列满的时候,继续插入元素会抛出IllegalStateException("Queue full")异常。 - 2)
offer(e):当队列满的时候,继续插入元素不会阻塞,直接返回false。如果插入成功则返回true。 - 3)
put(e):当队列满的时候,继续插入元素线程会被一直阻塞直到队列有空闲位置可用时为止。 - 4)
offer(e,time,unit):当队列满的时候,调用该方法的线程会被阻塞一段时间,如果超过指定时间还未添加成功,线程直接退出。
移除操作:从队列中移除元素。
- 1)
remove():当队列为空时,调用该方法元素会抛出NoSuchElementException异常。 - 2)
poll():当队列为空时,调用该方法不会阻塞,直接返回null。当队列不为空时,则从队列中取出一个元素。 - 3)
take():当队列为空时,调用该方法会被一直阻塞直到队列有数据可用时为止 - 4)
poll(time,unit):当队列为空时,调用该方法的线程会被阻塞一段时间,如果超过指定时间队列仍没有数据可用,直接返回null。
当然,如果是向无界阻塞队列中插入元素,因为无界队列永远不可能会出现满的情况,所以使用put或offerr(e,time,unit)方法永远不会被阻塞
ArrayBlockingQueue源码解析
Java Review - 并发编程_ArrayBlockingQueue原理&源码剖析
ArrayBlockingQueue是一个基于数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。
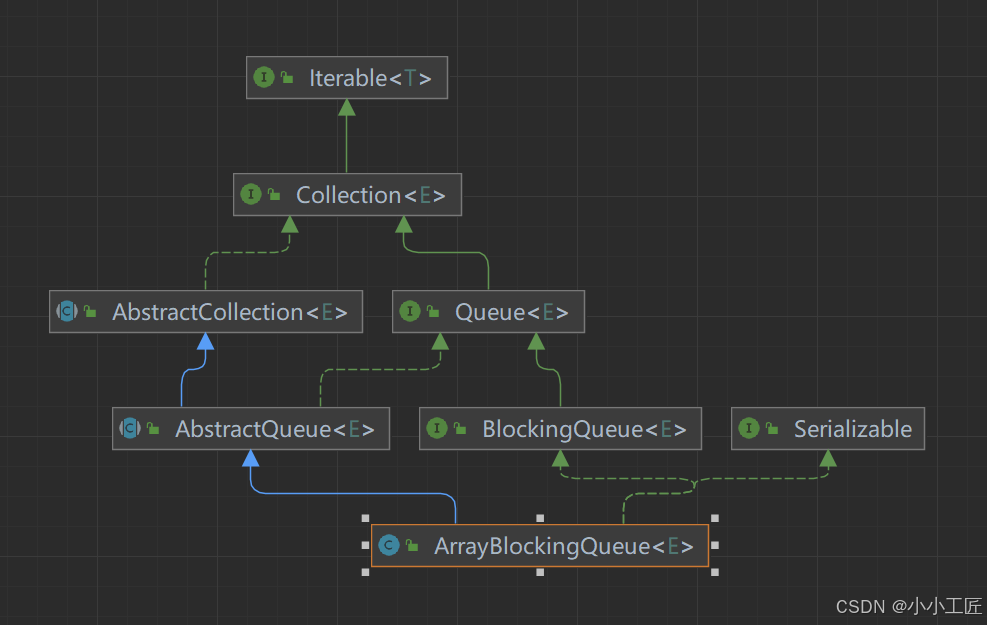
类结构
指定初始容量及公平/非公平策略的构造函数
/*** 创建一个具有给定(固定)容量和默认访问策略的 {@code ArrayBlockingQueue}。** @param capacity 该队列的容量* @throws IllegalArgumentException 如果 {@code capacity < 1}*/public ArrayBlockingQueue(int capacity) {this(capacity, false); // 使用默认的非公平访问策略}/*** 创建一个具有给定(固定)容量和指定访问策略的 {@code ArrayBlockingQueue}。** @param capacity 该队列的容量* @param fair 如果 {@code true},则被阻塞在插入或移除操作上的线程按 FIFO 顺序处理;* 如果 {@code false},则访问顺序是未指定的。* @throws IllegalArgumentException 如果 {@code capacity < 1}*/public ArrayBlockingQueue(int capacity, boolean fair) {if (capacity <= 0)throw new IllegalArgumentException(); // 容量必须大于 0this.items = new Object[capacity]; // 初始化存储数组lock = new ReentrantLock(fair); // 创建 ReentrantLock,根据 fair 参数决定是否使用公平锁notEmpty = lock.newCondition(); // 创建一个表示队列非空的条件notFull = lock.newCondition(); // 创建一个表示队列非满的条件}构造函数实现代码如上所示,它属于核心构造函数,按照指定的容量初始化items数组,队列的容量在构造时指定,一旦指定就不能修改.
该函数支持公平/非公平策略,在构造器中以指定的策略实例化lock全局锁,使用ReentrantLock独占锁保证同时只能有一个线程进行入队和出队的操作。
- fair=true为公平策略,表示所有线程严格按照请求的顺序添加或删除元素;
- fair=true为非公平策略,表示允许新申请线程“插队”,即新申请线程和被唤醒的线程,谁先抢占到锁,谁就能往队列中添加/删除元素。
- 此外还创建了两个Condition条件队列对象。当队列满时,申请插入元素的线程需要在notFull上等待;当队列空时,申请获取元素的线程会在notEmpty上等待
根据已有集合初始化队列的构造函数
/*** 创建一个具有给定(固定)容量、指定访问策略,并且初始包含给定集合中元素的 {@code ArrayBlockingQueue},* 元素按照集合迭代器的遍历顺序添加。** @param capacity 该队列的容量* @param fair 如果 {@code true},则被阻塞在插入或移除操作上的线程按 FIFO 顺序处理;* 如果 {@code false},则访问顺序是未指定的。* @param c 初始包含的元素集合* @throws IllegalArgumentException 如果 {@code capacity} 小于 {@code c.size()} 或小于 1。* @throws NullPointerException 如果指定的集合或其任何元素为 null。*/public ArrayBlockingQueue(int capacity, boolean fair,Collection<? extends E> c) {this(capacity, fair); // 调用构造函数初始化队列final ReentrantLock lock = this.lock;lock.lock(); // 仅为了可见性锁定,而不是互斥try {final Object[] items = this.items;int i = 0;try {for (E e : c)items[i++] = Objects.requireNonNull(e); // 将集合中的元素添加到队列中} catch (ArrayIndexOutOfBoundsException ex) {throw new IllegalArgumentException(); // 如果索引超出范围,抛出 IllegalArgumentException}count = i; // 更新队列中的元素数量putIndex = (i == capacity) ? 0 : i; // 更新下一个插入位置的索引} finally {lock.unlock(); // 解锁}}集合c的长度不能大于capacity,否则会抛出IllegalArgumentException异常。以集合c初始化队列时,使用了lock锁,这是为了保证数据的可见性,保证在构造器结束后,items、count和putIndex的修改对所有线程可见.
ArrayBlockingQueue在构造时指定容量,后面不能被改变。ArrayBlockingQueue是基于数组构建的,它的内部有一个数组items,用于存储队列元素
ArrayBlockingQueue主要属性
/** 队列中的元素 */final Object[] items;/** 下一次 take、poll、peek 或 remove 操作的 items 索引 */int takeIndex;/** 下一次 put、offer 或 add 操作的 items 索引 */int putIndex;/** 队列中的元素数量 */int count;/** 主锁,保护所有访问 */final ReentrantLock lock;/** 等待 take 操作的条件 */private final Condition notEmpty;/** 等待 put 操作的条件 */private final Condition notFull;-
1)putIndex字段,初始值0,表示下一个入队元素的数组索引,takeIndex为队头位置。
-
2)takeIndex字段,初始值0,表示下一个出队元素的数组索引,putIndex为队尾位置。
-
3)count字段,同于存储队列中当前元素个数。
-
4)lock字段,全局ReentrantLock锁。使用ReentrantLock锁保证元素入队和出队操作的线程安全,保证同时只能有一个线程进行出队入队的操作。我们知道,ReentrantLock锁有公平和非公平两种实现,可以在ArrayBlockingQueue构造时指定lock锁的类型。
-
5)notEmpty字段,是lock的一个Condition实例。当队列为空时,获取元素的线程会被阻塞并在该队列等待被唤醒。当队列有数据可用时,其他线程会调用notEmpty.signal()唤醒等待中线程。
-
6)notFull字段,是lock的一个Condition实例。当队列已满时,插入元素的线程会在该队列等待被唤醒。当队列有空闲位置时,其他线程会调用notFull. signal()唤醒等待中线程。
出队和入队的环形队列
我们再看插入元素和移除元素方法源码前,需要先对ArrayBlockingQueue的出队和入队流程有个总体的认识,这样后面理解源码时就会更容易。
ArrayBlockingQueue在进行不断的元素入队和出队操作时,内部数组items、putIndex、takeIndex三者其实构成了一个环形结构
-
当ArrayBlockingQueue被初始化时,takeIndex和putIndex都指向item索引0的位置,假设队列的容量为n。
-
当生产者线程向队列中插入元素时,如果队列有空闲位置,元素会被插入items[putIndex]中,putIndex会向后移动。
-
当putIndex移动到数组items最后一个索引位置(n-1)时,如果这时继续向队列中插入元素,元素会被插入到items[n-1],putIndex会重新指向item第一个索引位置0。putIndex的移动过程其实就是一个环形循环的过程
-
当消费者线程从队列中获取元素时,如果队列是非空状态,队列将item [takeIndex]位置的元素返回后,takeIndex会向后移动。takeIndex的移动过程和putIndex一样,都是环形循环的过程。
假设阻塞队列的容量为6。item数组容量为6
1)初始状态 : 元素个数count=0,put索引:putIndex=0,take索引:takeIndex=0 . 如果此时使用take方法移除元素,take线程会被阻塞。
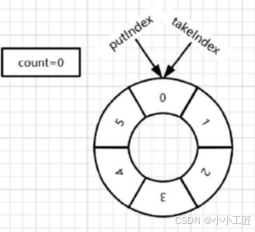
2)插入元素1 . 线程调用put方法插入元素1,putIndex向后移动,putIndex++。put操作结束后:count=1,putIndex=1,takeIndex=0
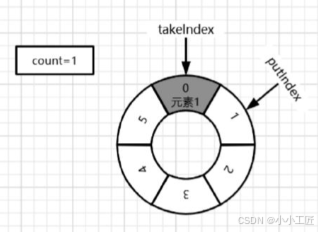
3)继续插入元素2至元素5. put操作结束后:count=5,putIndex=5,takeIndex=0
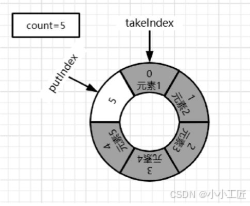
4)继续插入元素6. putIndex向后移,putIndex++=6超过数组最大索引,重置为0。put操作结束后:count=6,putIndex=0,takeIndex=0。此时队列是满的,如果继续插入元素,put线程会被阻塞
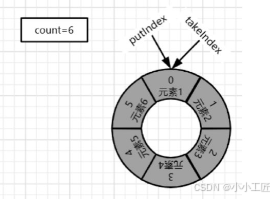
5)移除元素. 线程调用take方法移除元素,从队列中取出元素1。takeIndex向后移,takeIndex++=1。take结束后:count=5,putIndex=0,takeIndex=1
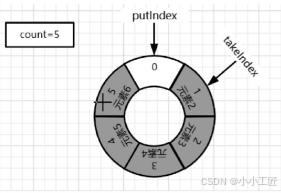
6)继续移除元素2至元素5. take操作结束后:count=1,putIndex=0,takeIndex=5
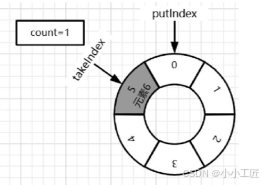
7)继续移除元素. takeIndex向后移,takeIndex++=6超过数组最大索引,重置为0。take操作结束后:count=0,putIndex=0,takeIndex=0 . 这时队列是空的,如果继续移除元素,take线程会被塞。
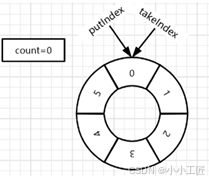
插入元素
插入元素的逻辑很简单,用同一个ReentrantLock独占锁lock实例保证同时只有一个线程执行插入操作,如果队列中有空闲位置,元素插入队尾。否则队列是满的,ArrayBlock-ingQueue提供了4种不同的处理方式:offer(E e),add(E e),put(E e)、offer(e,time,u-nit)。其中前两个插入元素时不会阻塞线程,后两个方法在队列满时会阻塞线程。
1. offer(E e)方法:非阻塞插入元素
线程使用该方法向插入元素时,如果队列中有空闲位置,插入成功并返回true。如果队列是满的,线程也不会被阻塞,而是直接返回false。
/*** 将指定的元素插入到此队列的尾部,如果可以立即完成而不会超过队列的容量,则返回 {@code true},* 否则如果队列已满则返回 {@code false}。此方法通常优于 {@link #add} 方法,* 因为后者在无法插入元素时只会抛出异常。** @param e 要插入的元素* @return 如果元素成功插入则返回 {@code true},否则返回 {@code false}* @throws NullPointerException 如果指定的元素为 null*/
public boolean offer(E e) {// 确保插入的元素不为 nullObjects.requireNonNull(e);// 获取锁以确保插入过程中的线程安全final ReentrantLock lock = this.lock;lock.lock();try {// 检查队列是否已满if (count == items.length)return false;else {// 将元素插入队列的尾部enqueue(e);return true;}} finally {// 释放锁以避免死锁lock.unlock();}
}- 1)首先使用lock. lock()加锁,保证只能有一个线程执行入队操作。
- 2)如果队列是满的,插入元素失败,直接返回false。
- 3)如果队列未满,调用私有方法enqueue(e)插入元素到队尾,插入成功后返回true。
- 4)最后,操作完毕后释放锁。
enqueue插入元素的核心方法,插入元素到队尾。
/*** 在当前的 put 位置插入元素,前进位置,并发出信号。* 只有在持有锁的情况下才能调用此方法。*/
private void enqueue(E e) {// 断言当前线程持有锁// assert lock.isHeldByCurrentThread();// 断言锁的持有计数为 1// assert lock.getHoldCount() == 1;// 断言当前 put 位置为空// assert items[putIndex] == null;final Object[] items = this.items;items[putIndex] = e; // 将元素存储到当前的 put 位置if (++putIndex == items.length) putIndex = 0; // putIndex 增加 1,如果达到数组长度则重置为 0count++; // 队列中的元素数量增加 1notEmpty.signal(); // 唤醒在 notEmpty 条件上等待的线程
}主要步骤如下:
- 1)首先存储插入元素到items[putIndex]。
- 2)对尾位置putIndex向后移1位,如果putIndex达到最大索引,重新定位到索引0。
- 3)队列中元素个数加1。
- 4)唤醒notEmpt上一个等待线程,该线程执行后续移除元素操作。
2. add(E e)方法:非阻塞插入元素
线程使用该方法向插入元素时,如果队列中有空闲位置,插入成功并返回true。如果队列是满的,线程也不会被阻塞,而是直接抛出异常。
add方法比较简单,直接调用了父类AbstractQueue的add方法。一般这种调用方式采用模板模式的写法,可以使用模板方法来解决通用流程的实现
/*** 将指定的元素插入到此队列的尾部,如果可以立即完成而不会超过队列的容量,则返回 {@code true},* 否则如果队列已满则抛出 {@code IllegalStateException} 异常。** @param e 要添加的元素* @return {@code true}(符合 {@link Collection#add} 的规定)* @throws IllegalStateException 如果队列已满* @throws NullPointerException 如果指定的元素为 null*/
public boolean add(E e) {return super.add(e); // 调用父类的 add 方法进行元素添加
}AbstractQueue. add方法很简单,首先调用ArrayBlockingQueue的offer(e)插入元素,如果插入成功直接返回ture,否则抛出IllegalStateException(“Queue full”)异常
/*** 将指定的元素插入到此队列的尾部,如果可以立即完成而不会超过队列的容量,则返回 {@code true},* 否则如果队列已满则抛出 {@code IllegalStateException} 异常。** @param e 要添加的元素* @return {@code true}(符合 {@link Collection#add} 的规定)* @throws IllegalStateException 如果队列已满* @throws NullPointerException 如果指定的元素为 null*/
public boolean add(E e) {if (offer(e)) { // 尝试使用 offer 方法插入元素return true; // 插入成功,返回 true} else {throw new IllegalStateException("Queue full"); // 队列已满,抛出异常}
}3. put(E e)方法:阻塞式插入元素
线程使用该方法向插入元素时,如果队列是满的,线程会被一直阻塞并进入notFull条件队列等待。否则,就调用enqueue方法插入元素
/*** 将指定的元素插入到此队列的尾部,如果队列已满,则等待空间变得可用。** @param e 要插入的元素* @throws InterruptedException 如果当前线程被中断* @throws NullPointerException 如果指定的元素为 null*/
public void put(E e) throws InterruptedException {Objects.requireNonNull(e); // 确保插入的元素不为 nullfinal ReentrantLock lock = this.lock;lock.lockInterruptibly(); // 使用可中断的锁获取机制try {while (count == items.length) { // 如果队列已满notFull.await(); // 等待 notFull 条件信号,直到队列中有空闲空间}enqueue(e); // 插入元素到队列尾部} finally {lock.unlock(); // 释放锁}
}-
1)判断插入元素不能为Null,否则抛出NullPointerException异常。
-
2)使用lock. lockInterruptibly()加锁,保证只能有一个线程执行入队操作。
-
3)如果队列是满的,当前线程会被阻塞,让出lock锁并在notFull条件队列中等待被其他线程唤醒。
线程被唤醒后,需重新尝试获取锁,获取锁成功后再次判断队列是否有空闲位置可用,如果队列是满的线程再次被阻塞。
final ReentrantLock lock = this.lock;入队和出队时使用了同一把独占锁,也就是说同时只有一个线程进行出队和入队操作,线程被唤醒后,为什么还需要再次判断 ? 其实,这里使用while循环有两个原因:
- 其一,防止虚假唤醒,防止线程被意外唤醒,不经再次判断就直接调用enqueue方法。
- 其二,如果ArrayBlockingQueue使用的非公平锁策略,则在本线程被其他线程唤醒后,有可能新线程抢先完成了入队操作
-
4)如果队列有空闲位置可用,调用私有方法enqueue(e)插入元素
-
5)最后,操作完毕后释放锁。
4. offer(e,time,unit):阻塞式插入元素
线程使用该方法向插入元素时,如果队列是满的,线程会被阻塞一段时间,如果超过指定时间还未添加成功,线程直接退出,返回false。如果插入元素成功,返回true
/*** 将指定的元素插入到此队列的尾部,如果队列已满,则最多等待指定的时间以等待空间变得可用。** @param e 要插入的元素* @param timeout 最大等待时间* @param unit 时间单位* @return 如果在指定时间内成功插入元素则返回 {@code true},否则返回 {@code false}* @throws InterruptedException 如果当前线程被中断* @throws NullPointerException 如果指定的元素为 null*/
public boolean offer(E e, long timeout, TimeUnit unit)throws InterruptedException {Objects.requireNonNull(e); // 确保插入的元素不为 nulllong nanos = unit.toNanos(timeout); // 将指定的时间转换为纳秒final ReentrantLock lock = this.lock;lock.lockInterruptibly(); // 使用可中断的锁获取机制try {while (count == items.length) { // 如果队列已满if (nanos <= 0L) { // 如果剩余等待时间小于等于 0return false; // 返回 false 表示插入失败}nanos = notFull.awaitNanos(nanos); // 等待 notFull 条件信号,直到队列中有空闲空间或超时}enqueue(e); // 插入元素到队列尾部return true; // 返回 true 表示插入成功} finally {lock.unlock(); // 释放锁}
}-
1)判断插入元素不能为Null,否则抛出NullPointerException异常。
-
2)使用lock. lockInterruptibly()加锁,保证只能有一个线程执行入队操作。
-
3)如果队列是满的,当前线程会被阻塞,让出lock锁并在notFull条件队列中等待被其他线程唤醒。线程被唤醒后,需重新尝试获取锁。
线程在两种情况下会被唤醒。
- 情况1:等待超时被唤醒并获取到锁。线程会重新判断是否有空闲位置,如果队列仍然是满的,直接返回false。
- 情况2:被其他线程唤醒并获取到锁。线程被唤醒后重新判断是否有空闲位置,如果线程仍然是满的并且等待超时,直接返回false。
-
4)如果队列有空闲位置可用,调用私有方法enqueue(e)插入元素。
-
5)最后操作完毕后释放锁。
移除元素
移除元素的逻辑也很简单,使用同一个ReentrantLock独占锁lock保证同时只有一个线程执行移除操作,如果队列中不为空,从队头取出一个元素。如果队列是空的,Array-BlockingQueue也提供了4种不同的处理方式:remove()、poll()、take()、poll(time,unit)。
其中前两个移除元素时不会阻塞线程,后两个方法在队列为空时会阻塞线程
1. poll()方法:非阻塞移除元素
线程使用该方法移除元素时,如果队列不为空,从队头移除一个元素并返回。如果队列是空的,线程不会被阻塞,而是直接返回null。
/*** 从队列的头部移除并返回元素,如果队列为空则返回 {@code null}。** @return 如果队列不为空则返回队列头部的元素,否则返回 {@code null}*/
public E poll() {final ReentrantLock lock = this.lock;lock.lock(); // 获取锁以确保线程安全try {if (count == 0) { // 如果队列为空return null; // 返回 null} else {return dequeue(); // 移除并返回队列头部的元素}} finally {lock.unlock(); // 释放锁}
}-
首先使用lock. lock()加锁,保证只能有一个线程执行入队操作。
-
如果队列是空的,直接返回null。
-
如果队列元素个数大于0,直接调用私有的dequeue()从对头取出一个元素。
/*** 从当前的取位置提取元素,前进位置,并发出信号。* 只有在持有锁的情况下才能调用此方法。*/ private E dequeue() {// 断言当前线程持有锁// assert lock.isHeldByCurrentThread();// 断言锁的持有计数为 1// assert lock.getHoldCount() == 1;// 断言当前取位置的元素不为 null// assert items[takeIndex] != null;final Object[] items = this.items;@SuppressWarnings("unchecked")E e = (E) items[takeIndex]; // 从当前取位置提取元素items[takeIndex] = null; // 将当前取位置的元素设置为 nullif (++takeIndex == items.length) takeIndex = 0; // takeIndex 增加 1,如果达到数组长度则重置为 0count--; // 队列中的元素数量减少 1if (itrs != null) {itrs.elementDequeued(); // 通知迭代器元素已被移除}notFull.signal(); // 唤醒在 notFull 条件上等待的线程return e; // 返回提取的元素 } -
最后,操作完毕后释放锁。
2. remove()方法:非阻塞移除元素
/*** 从队列中移除指定元素的一个实例(如果存在)。具体来说,移除一个满足 {@code o.equals(e)} 的元素,* 如果队列中包含一个或多个这样的元素。* 如果队列包含指定的元素(或者等价地说,如果此调用导致队列发生变化),则返回 {@code true}。** <p>基于循环数组的队列中移除内部元素是一个本质上较慢且具有破坏性的操作,因此应仅在特殊情况下进行,* 理想情况下,仅当已知队列未被其他线程访问时才进行。** @param o 要从队列中移除的元素(如果存在)* @return 如果此调用导致队列发生变化,则返回 {@code true}*/
public boolean remove(Object o) {if (o == null) return false; // 如果指定的元素为 null,直接返回 falsefinal ReentrantLock lock = this.lock;lock.lock(); // 获取锁以确保线程安全try {if (count > 0) { // 如果队列不为空final Object[] items = this.items;for (int i = takeIndex, end = putIndex, to = (i < end) ? end : items.length; ; i = 0, to = end) {for (; i < to; i++) {if (o.equals(items[i])) { // 如果找到匹配的元素removeAt(i); // 移除该元素return true; // 返回 true 表示队列已更改}}if (to == end) break; // 如果已经遍历完所有元素,退出循环}}return false; // 没有找到匹配的元素,返回 false} finally {lock.unlock(); // 释放锁}
}3. take()方法:阻塞式移除元素
/*** 从队列的头部移除并返回元素,如果队列为空,则等待直到有元素可用。** @return 从队列头部移除并返回的元素* @throws InterruptedException 如果当前线程被中断*/
public E take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly(); // 使用可中断的锁获取机制try {while (count == 0) { // 如果队列为空notEmpty.await(); // 等待 notEmpty 条件信号,直到队列中有元素}return dequeue(); // 移除并返回队列头部的元素} finally {lock.unlock(); // 释放锁}
}4.poll(long timeout, TimeUnit unit)):阻塞式移除元素
/*** 从队列的头部移除并返回元素,如果队列为空,则最多等待指定的时间以等待元素变得可用。** @param timeout 最大等待时间* @param unit 时间单位* @return 如果在指定时间内有元素可用,则返回队列头部的元素;否则返回 {@code null}* @throws InterruptedException 如果当前线程被中断*/
public E poll(long timeout, TimeUnit unit) throws InterruptedException {long nanos = unit.toNanos(timeout); // 将指定的时间转换为纳秒final ReentrantLock lock = this.lock;lock.lockInterruptibly(); // 使用可中断的锁获取机制try {while (count == 0) { // 如果队列为空if (nanos <= 0L) { // 如果剩余等待时间小于等于 0return null; // 返回 null 表示没有元素可用}nanos = notEmpty.awaitNanos(nanos); // 等待 notEmpty 条件信号,直到队列中有元素或超时}return dequeue(); // 移除并返回队列头部的元素} finally {lock.unlock(); // 释放锁}
}-
使用lock. lockInterruptibly()加锁,保证只能有一个线程执行出队操作。
-
如果队列是空的,当前线程会被阻塞,让出lock锁并在notEmpty条件队列中等待被其他线程唤醒。线程被唤醒后,需重新尝试获取锁。
线程在两种情况下会被唤醒。
- 情况1:超时被唤醒并获取到锁,线程会重新判断是否有数据可用,如果队列仍然是空的,直接返回null。
- 情况2:被其他线程唤醒并获取到锁,线程会重新判断是否有数据可用,如果队列仍然是空的并且等待超时,直接返回null。
-
如果队列有数据可用,调用私有方法dequeue()从队头移除元素。
-
最后,操作完毕后释放锁。
小结
ArrayBlockingQueue是一个有界阻塞队列,在初始化时需要指定容量大小,在生产者“生产”数据的速度和消费者“消费”数据速度比较稳定且基本匹配的情况下,使用Array-BlockingQueue是不错的选择。否则如果生产者产出数据的速度大于消费者消费的速度,且当队列中被填满的情况下,会有大量生产线程被阻塞。
ArrayBlockingQueue使用独占锁ReentrantLock来实现线程安全,出队和入队操作使用同一个锁对象,作用类似于synchronized同步锁,同时只能有一个线程进行入队和出队操作。这也就意味着生产者和消费者无法并行操作,在并发量一般的场景基本够用,在高并发场景下,可能会成为性能瓶颈。
LinkedBlockingQueue源码解析
Java Review - 并发编程_LinkedBlockingQueue原理&源码剖析
LinkedBlockingQueue是一个基于链表实现的无界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。
LinkedBlockingQueue类结构
LinkedBlockingQueue和ArrayBlockingQueue的类图结构是一样的。LinkedBlockingQueue实现了BlockingQueue接口,继承自AbstractQueue
LinkedBlockingQueue的主要属性
/*** 队列的容量上限,如果没有上限则为 Integer.MAX_VALUE*/
private final int capacity;/*** 当前元素的数量*/
private final AtomicInteger count = new AtomicInteger();/*** 链表的头节点。* 不变性条件:head.item == null*/
transient Node<E> head;/*** 链表的尾节点。* 不变性条件:last.next == null*/
private transient Node<E> last;/*** 由 take、poll 等方法持有的锁*/
private final ReentrantLock takeLock = new ReentrantLock();/*** 等待 take 操作的等待队列*/
@SuppressWarnings("serial") // 实现 Condition 接口的类可能是可序列化的
private final Condition notEmpty = takeLock.newCondition();/*** 由 put、offer 等方法持有的锁*/
private final ReentrantLock putLock = new ReentrantLock();/*** 等待 put 操作的等待队列*/
@SuppressWarnings("serial") // 实现 Condition 接口的类可能是可序列化的
private final Condition notFull = putLock.newCondition();- 1)capacity字段:队列容量,默认容量是Integer.MAX_VALUE。表示队列中最多存储元素个数。
- 2)count字段:AtomicInteger类型原子变量,用于存储队列中元素个数,默认值0。
- 3)head和last字段:LinkedBlockingQueue基于单向链表实现,head为链表的头节点,last为链表的尾节点。
- 4)takeLock和putLock:两个非公平独占锁ReentrantLock实例,分别保证出队和入队操作线程安全。takeLock用来控制同时只能有一个线程从队头移除元素,putLock用来控制同时只能有一个线程从队头插入元素。
- 5)notEmpty字段:是takeLock的一个Condition实例。当队列为空时,获取元素的线程会被阻塞并在该队列等待被唤醒。当队列有数据可用时,其他线程会调用notEmpty. signal()会唤醒等待中线程。
- 6)notFull字段:是takeLock的一个Condition实例。当队列满时,插入元素的线程会在该队列等待被唤醒。当队列有空闲位置时,其他线程会调用notFull. signal()会唤醒等待中线程。
LinkedBlockingQueue的三个构造函数
/*** 创建一个容量为 {@link Integer#MAX_VALUE} 的 {@code LinkedBlockingQueue}。*/
public LinkedBlockingQueue() {this(Integer.MAX_VALUE); // 调用带有最大容量的构造函数
}/*** 创建一个具有给定固定容量的 {@code LinkedBlockingQueue}。** @param capacity 此队列的容量* @throws IllegalArgumentException 如果 {@code capacity} 不大于零*/
public LinkedBlockingQueue(int capacity) {if (capacity <= 0) throw new IllegalArgumentException(); // 检查容量是否有效this.capacity = capacity; // 设置队列的容量last = head = new Node<E>(null); // 初始化链表的头节点和尾节点
}/*** 创建一个容量为 {@link Integer#MAX_VALUE} 的 {@code LinkedBlockingQueue},初始包含给定集合中的元素,* 元素按集合迭代器的遍历顺序添加。** @param c 初始包含的元素集合* @throws NullPointerException 如果指定的集合或其任何元素为 null*/
public LinkedBlockingQueue(Collection<? extends E> c) {this(Integer.MAX_VALUE); // 调用带有最大容量的构造函数final ReentrantLock putLock = this.putLock;putLock.lock(); // 获取 put 锁,确保可见性try {int n = 0;for (E e : c) {if (e == null)throw new NullPointerException(); // 检查元素是否为 nullif (n == capacity)throw new IllegalStateException("Queue full"); // 检查队列是否已满enqueue(new Node<E>(e)); // 将元素添加到队列中++n;}count.set(n); // 设置当前元素的数量} finally {putLock.unlock(); // 释放 put 锁}
}- 使用默认构造函数创建LinkedBlockingQueue实例时,会创建一个容量为Integer. MAX_VALUE的阻塞队列,近似无界
- 指定初始容量的构造函数
- 根据已有集合初始化队列的构造函数
队列的容量为Integer. MAXVALUE,遍历集合将集合中所有元素依次入队。如果集合中元素不能为null,否则抛出NullPointerException异常;集合中容量大于Integer.MAXVALUE会抛出IllegalStateException("Queu full")异常。
在用集合初始化队列时,使用了putLock锁,这是为了保证数据的可见性,保证在构造器结束后,数据修改结果对所有线程可见。
构造完成后,LinkedBlockingQueue的初始结构如下
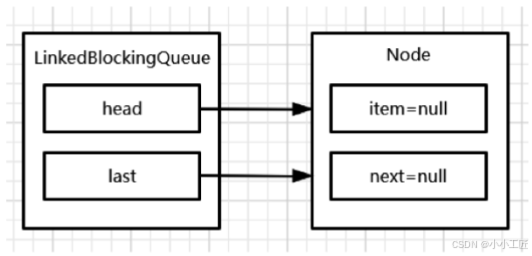
插入元素
插入元素的逻辑很简单,用同一个putLock独占锁保证同时只有一个线程执行插入操作,如果队列中有空闲位置,元素插入队尾。LinkedBlockingQueue同样也提供了4种不同的处理方式:offer(E e)、add(E e)、put(E e)、offer(e,time,unit)。
4种方法主体流程差别不大 , 以put方法为例,来分析Linked-BlockingQueue插入元素的流程
线程使用该方法向插入元素时,如果队列是满的,线程会被一直阻塞并进入notFull条件队列等待。否则,如果队列不是满的,元素就会被插入到队列尾部。
/*** 将指定的元素插入到队列的尾部,如果必要的话,等待空间可用。** @throws InterruptedException 如果当前线程被中断* @throws NullPointerException 如果指定的元素为 null*/
public void put(E e) throws InterruptedException {if (e == null) throw new NullPointerException(); // 检查元素是否为 nullfinal int c;final Node<E> node = new Node<E>(e); // 创建新节点final ReentrantLock putLock = this.putLock;final AtomicInteger count = this.count;putLock.lockInterruptibly(); // 使用可中断的锁获取机制try {/** 注意,即使 count 未受锁保护,它仍然用于等待条件。* 这是因为在此点上 count 只能减少(所有其他 put 操作都被锁排除),* 并且如果 count 从容量变为其他值,我们(或其他等待的 put 操作)将收到信号。* 类似地,其他等待条件中对 count 的使用也是如此。*/while (count.get() == capacity) { // 如果队列已满notFull.await(); // 等待 notFull 条件信号,直到队列中有空闲空间}enqueue(node); // 将新节点添加到队列中c = count.getAndIncrement(); // 增加元素计数if (c + 1 < capacity) // 如果增加后队列仍未满notFull.signal(); // 通知其他等待的 put 操作} finally {putLock.unlock(); // 释放锁}if (c == 0) // 如果之前队列为空signalNotEmpty(); // 通知等待的 take 操作
}- 1)判断插入元素不能为Null,否则抛出NullPointerException异常。
- 2)执行putLock. lockInterruptibly()加锁,保证同时只能有一个线程执行入队操作。
- 3)如果队列是满的,当前线程会被阻塞,让出putLock锁并在notFull条件队列中等待被其他线程唤醒。如果队列未满,调用enqueue(e)插入元素。
- 5)调用count. getAndIncrement递增元素个数,并将递增前队列中元素个数存储在局部变量c中。如果入队后,队列仍然未满,就调用notFull. signal唤醒一个notFull条件队列上等待线程,该线程被唤醒后执行插入元素操作。
- 6)入队结束,执行putLock. unlock()解锁。解锁后,其他线程可以抢占putLock进行入队操作。
- 7)如果入队前队列是空的,就可能有线程因为执行移除元素操作而被阻塞在notEmpty上。所以,当前线程入队完毕后,需要唤醒notEmpty中一个等待的线程,通知它队列上现有有元素可以获取
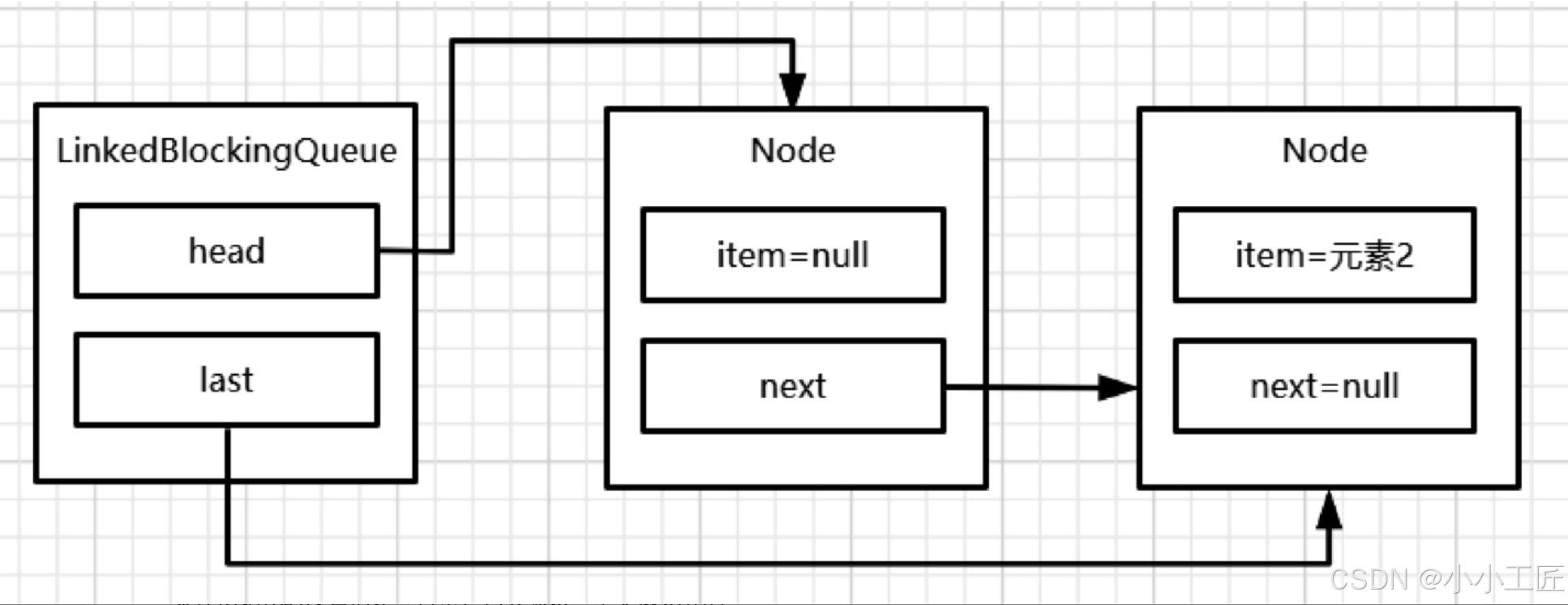
插入1个元素后,结构如图
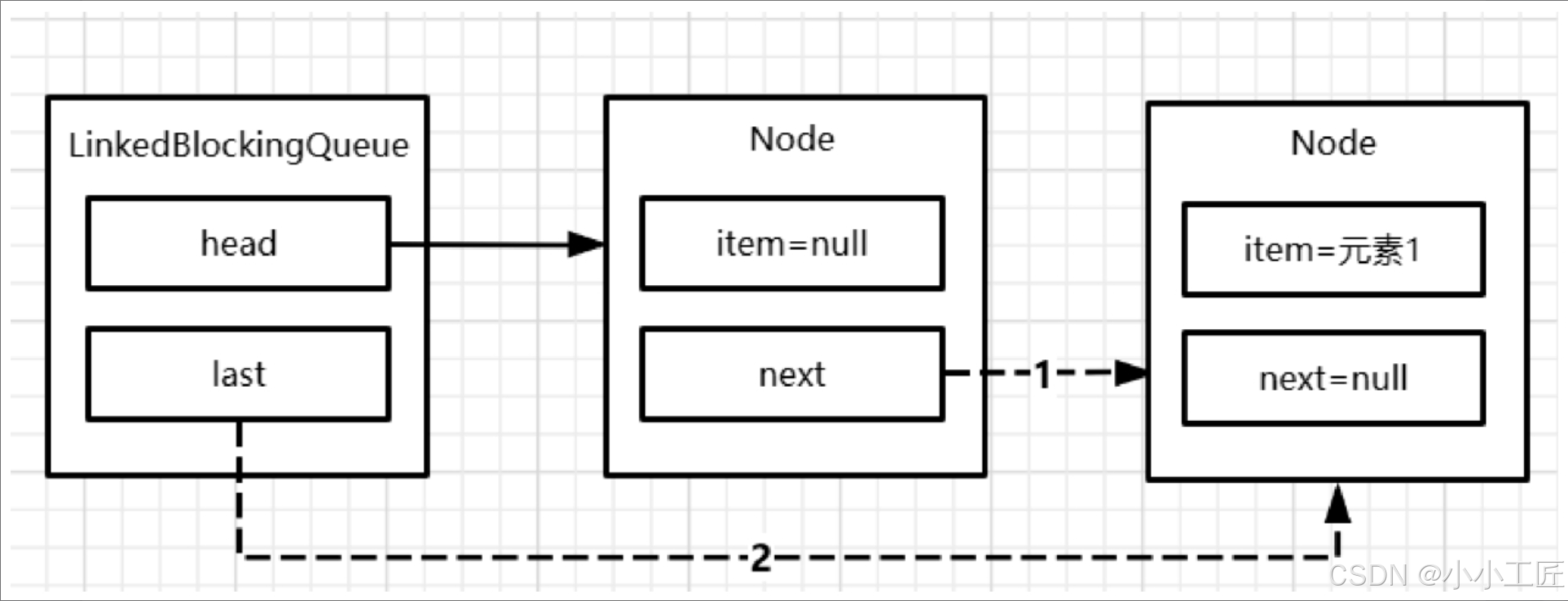
插入2个元素后,结构如图
移除元素
移除元素的逻辑很简单,用同一个takeLock独占锁保证同时只有一个线程执行移除操作,如果队列中不为空,则从队头取出一个元素。LinkedBlockingQueue同样也提供了4种不同的处理方式:remove()、poll()、take()、poll(time,unit)。
4种方法主体流程差别不大,这里仅以take方法为例,来分析Linked-BlockingQueue移除元素的流程。
线程使用该方法移除元素时,如果队列不为空,从队头移除一个元素并返回。如果队列是空的,当队列为空时,线程会被阻塞并进入notEmpty条件队列等待
/*** 从队列的头部移除并返回元素,如果队列为空,则等待直到有元素可用。** @return 从队列头部移除并返回的元素* @throws InterruptedException 如果当前线程被中断*/
public E take() throws InterruptedException {final E x;final int c;final AtomicInteger count = this.count;final ReentrantLock takeLock = this.takeLock;takeLock.lockInterruptibly(); // 使用可中断的锁获取机制try {while (count.get() == 0) { // 如果队列为空notEmpty.await(); // 等待 notEmpty 条件信号,直到队列中有元素}x = dequeue(); // 从队列中移除并返回头部元素c = count.getAndDecrement(); // 减少元素计数if (c > 1) // 如果减少后队列中仍有多个元素notEmpty.signal(); // 通知其他等待的 take 操作} finally {takeLock.unlock(); // 释放锁}if (c == capacity) // 如果之前队列已满signalNotFull(); // 通知等待的 put 操作return x; // 返回移除的元素
}-
使用takeLock. lockInterruptibly()加锁,保证只能有一个线程执行出队操作。
-
如果队列是空的,当前线程会被阻塞,让出takeLock锁并在notEmpty条件队列中等待被其他线程唤醒。线程被唤醒后,需重新尝试获取锁。
线程在两种情况下会被唤醒。- 如果队列有数据可用,调用私有方法dequeue()从队头移除元素。调用count. getAndDecrement递减元素个数,并将递减前队列中元素个数存储在局部变量c中。
- 如果入队后,队列仍然不为空,就调用notEmpty. signal唤醒一个notEmpty条件队列上等待线程,该线程被唤醒后执行移除元素操作。
-
元素出队结束,执行takeLock. unlock()解锁。解锁后,其他线程可以抢占takeLock进行出队操作。
-
如果出队前队列是满的,就可能有线程因为执行插入元素操作而被阻塞在notFull上。所以,当前元素出队完毕后,需要唤醒notFull中一个等待的线程,通知它可以继续插入元素了。
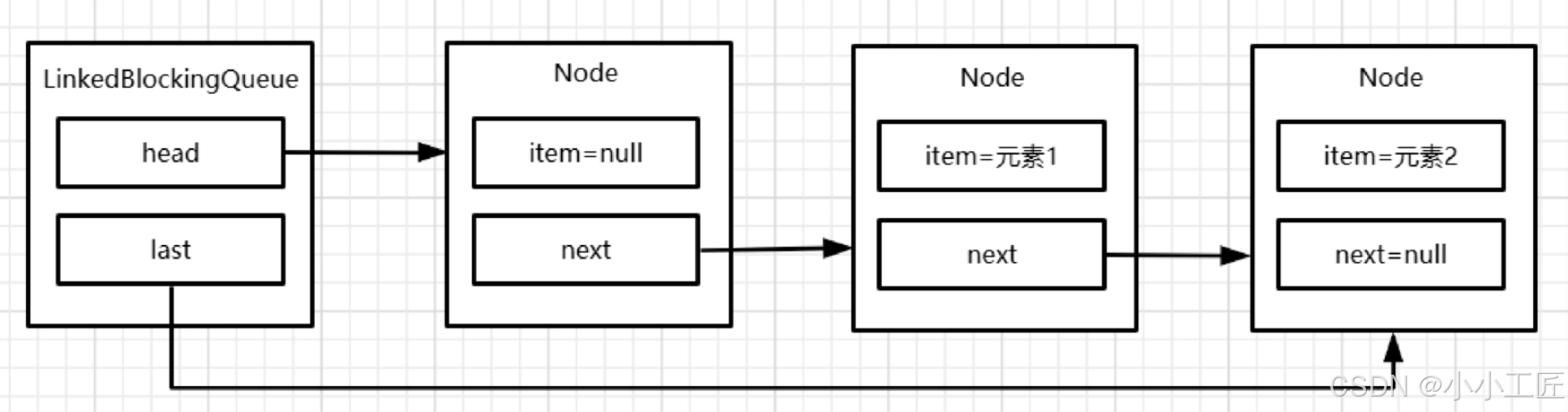
移除1个元素后,结构如图
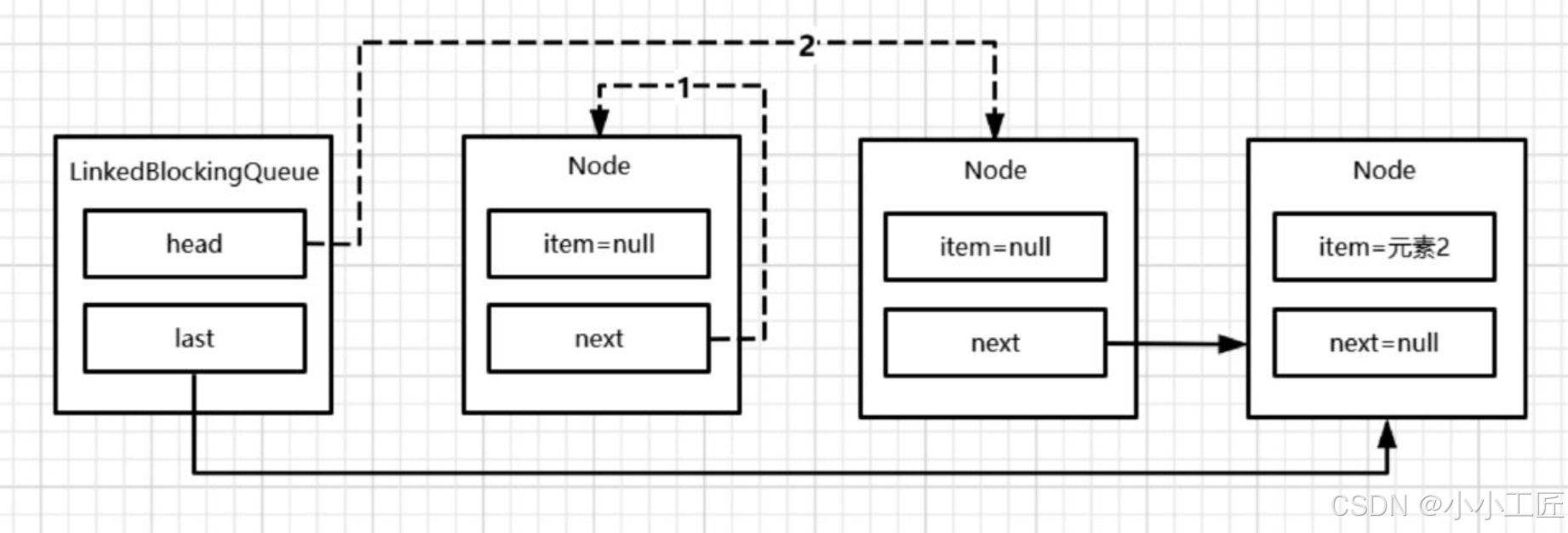
最终状态如图
小结
LinkedBlockingQueue是一个基于链表的阻塞队列,如果在初始化时没有指定其容量,它会默认一个类似无界的容量。如果当生产者产出数据的速度远大于消费者消费的速度时,LinkedBlockingQueue会缓存大量的数据,这时系统内存可能被消耗殆尽。
LinkedBlockingQueue和ArrayBlockingQueue不同的是,它使用两把独立的锁takeLock和putLock来保证出队和入队操作线程安全。这样入队和出队之间可以真正的做到并发执行,同时可以有一个线程进行入队操作,另一个线程进行出队操作,这样比ArrayBlockingQueue提升了2倍的并发效率
ArrayBlockingQueue vs LinkedBlockingQueue 小结
LinkedBlockingQueue和ArrayBlockingQueue两个队列的主要区别如下
-
1)底层数据结构不同。ArrayBlockingQueue基于数组实现,使用数组存储元素。LinkedBlockingQueue基于单链表实现,使用链表存储元素。
-
2)队列容量不同。ArrayBlockingQueue构造时必须指定容量,且后续不能改变。LinkedBlockingQueue既可以指定大小,也可以不指定,默认使用一个类似无界的容量(Integer. MAX_VALUE)。
-
3)ArrayBlockingQueue可以使用公平/非公平锁策略,而LinkedBlockingQueue只能使用非公平策略。
ArrayBlockingQueue入队和出队公用一把全局ReentrantLock锁;LinkedBlockingQueue出队和入队分别使用独立的锁,所以LinkedBlockingQueue的并发性能要比ArrayBlockingQueue好

相关文章:
J.U.C - 深入解读阻塞队列实现原理源码
文章目录 Pre生产者-消费者模式阻塞队列 vs 普通队列JUC提供的7种适合与不同应用场景的阻塞队列插入操作:添加元素到队列中移除操作:从队列中移除元素。 ArrayBlockingQueue源码解析类结构指定初始容量及公平/非公平策略的构造函数根据已有集合初始化队列…...

【大语言模型学习】LORA微调方法
LORA: Low-Rank Adaptation of Large Language Models 摘要 LoRA (Low-Rank Adaptation) 提出了一种高效的语言模型适应方法,针对预训练模型的适配问题: 目标:减少下游任务所需的可训练参数,降低硬件要求。方法:冻结预训练模型权重,注入低秩分解矩阵,从而在不影响推理…...

Spring Boot【一】
Spring Boot全局配置文件 application.properties 是 Spring Boot 的标准配置文件,用于集中管理应用程序的配置属性。它的主要作用是将配置信息与代码分离,使得应用程序更具可维护性和可配置性。 Application.yaml配置文件 YAML文件格式是JSON超集文件…...

H.265流媒体播放器EasyPlayer.js H.264/H.265播放器chrome无法访问更私有的地址是什么原因
EasyPlayer.js H5播放器,是一款能够同时支持HTTP、HTTP-FLV、HLS(m3u8)、WS、WEBRTC、FMP4视频直播与视频点播等多种协议,支持H.264、H.265、AAC、G711A、MP3等多种音视频编码格式,支持MSE、WASM、WebCodec等多种解码方…...

【大数据学习 | HBASE高级】rowkey的设计,hbase的预分区和压缩
1. rowkey的设计 RowKey可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,字典顺序排序,rowkey的设计至关重要,会影响region分布,如果rowkey设计不合理还会出现region写热点等一系列问题。 …...

Dart:字符串
字符串:单双引号 String c hello \c\; // hello c,单引号中使用单引号,需要转义\ String d "hello c"; // hello c,双引号中使用单引号,不需要转义 String e "hello \“c\”"; // hell…...

平衡二叉搜索树之 红黑 树的模拟实现【C++】
文章目录 红黑树的简单介绍定义红黑树的特性红黑树的应用 全部的实现代码放在了文章末尾准备工作包含头文件类的成员变量和红黑树节点的定义 构造函数和拷贝构造swap和赋值运算符重载析构函数findinsert【重要】第一步:按照二叉搜索树的方式插入新节点第二步&#x…...

2:Vue.js 父子组件通信:让你的组件“说话”
上一篇我们聊了如何用 Vue.js 创建一个简单的组件,这次咱们再往前走一步,讲讲 Vue.js 的父子组件通信。组件开发里,最重要的就是让组件之间能够“说话”,数据能流通起来。废话不多说,直接开干! 父组件传数据…...

6. Keepalived配置Nginx自动重启,实现7x24提供服务
一. Keepalived配置Nginx自动重启,实现7x24提供服务 1.编写不停的检查nginx服务器状态,停止并重启,重启失败后则停止keepalived脚本 cd /etc/keepalived/ vim check_nginx_alive_or_not.sh #---内容如下:--------------- #!/bin/bash A=`ps -C nginx --no-header |wc -l...

【PS】蒙版与通道
内容1: 、选择蓝色通道并复制,对复制的蓝色通道ctrli进行反向选择,然后ctrll调整色阶。 、选择载入选区,然后点击rgb。 、点击蒙版 、点击云彩图层调整位置 、点击色相/饱和度,适当调整 、最后使用滤镜等功能添加光圈…...

C++创建型模式之生成器模式
解决的问题 生成器模式(Builder Pattern)主要解决复杂对象的构建问题。当一个对象的创建过程非常复杂,涉及多个步骤和多个部件时,使用生成器模式可以将对象的构建过程与其表示分离,使得同样的构建过程可以创建不同的表…...

鸿蒙NEXT应用示例:切换图片动画
【引言】 在鸿蒙NEXT应用开发中,实现图片切换动画是一项常见的需求。本文将介绍如何使用鸿蒙应用框架中的组件和动画功能,实现不同类型的图片切换动画效果。 【环境准备】 电脑系统:windows 10 开发工具:DevEco Studio NEXT B…...
继承特性和分区实现)
postgresql(功能最强大的开源数据库)继承特性和分区实现
PostgreSQL实现了表继承,在多重表继承下,对上亿条不同类别的数据条目进行按型号、按月份双层分区管理,既可在总表查阅所有条目的共有字段,也可在各类型字表查询附加字段,非常高效。 分区是通过继承的方式来实现的&…...
论文笔记(五十六)VIPose: Real-time Visual-Inertial 6D Object Pose Tracking
VIPose: Real-time Visual-Inertial 6D Object Pose Tracking 文章概括摘要I. INTRODACTIONII. 相关工作III. APPROACHA. 姿态跟踪工作流程B. VIPose网络 文章概括 引用: inproceedings{ge2021vipose,title{Vipose: Real-time visual-inertial 6d object pose tra…...

微服务治理详解
文章目录 什么是微服务架构为什么要使用微服务单体架构如何转向微服务架构服务治理服务治理治的是什么服务注册与发现服务熔断降级服务网关服务调用服务负载均衡服务配置中心 微服务解决方案SpringCloud体系EurekaHystrixGatewayOpenFeignRibbonConfig SpringCloud Alibaba体系…...
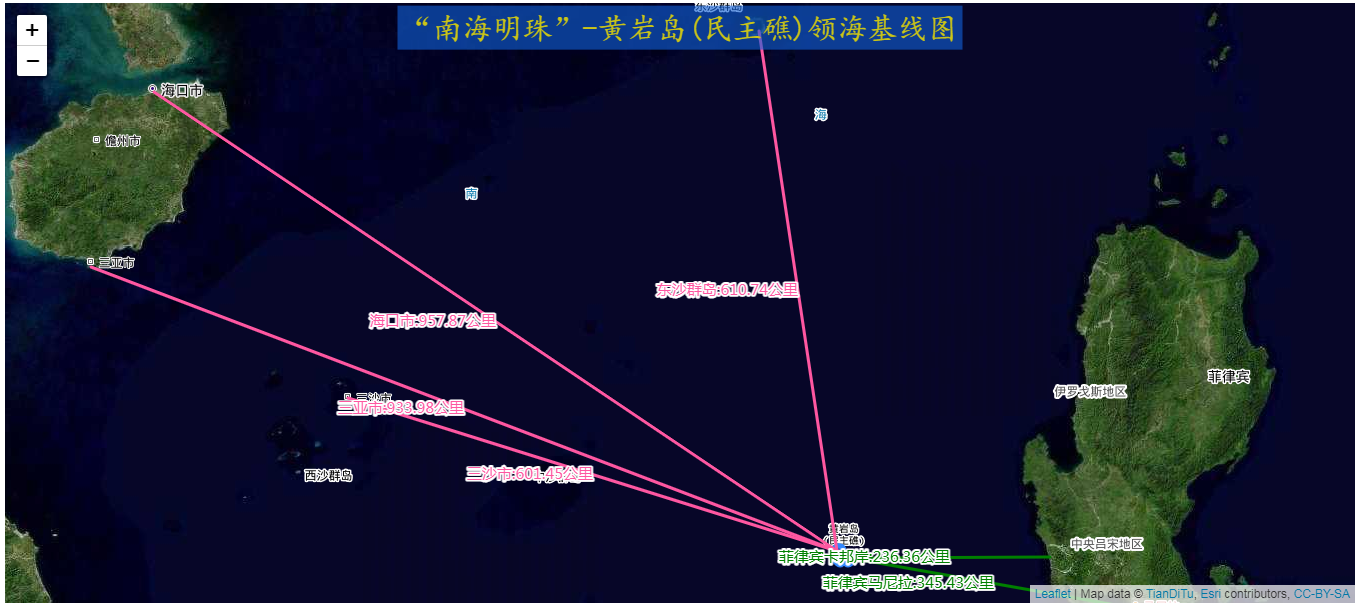
“南海明珠”-黄岩岛(民主礁)领海基线WebGIS绘制实战
目录 前言 一、关于岛屿的基点位置 1、领海基点 二、基点坐标的转换 1、最底层的左边转换 2、单个经纬度坐标点转换 3、完整的转换 三、基于天地图进行WebGIS展示 1、领海基点的可视化 2、重要城市距离计算 四、总结 前言 南海明珠黄岩岛,这座位于南海的…...

Oracle数据库 创建dblink的过程及其用法详解
前言 dblink是Oracle数据库中用于连接不同数据库实例的一种机制。通过dblink,用户可以在一个数据库实例中直接查询或操作另一个数据库实例中的表、视图或存储过程。 dblink的作用主要体现在以下几个方面: 跨数据库操作:允许用户…...

Linux从0——1之shell编程4
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...

pycharm快速更换虚拟环境
目录 1. 选择Conda 虚拟环境2. 创建环境3. 直接选择现有虚拟环境 1. 选择Conda 虚拟环境 2. 创建环境 3. 直接选择现有虚拟环境...

MVVM框架
MVVM由以下三个内容构成: Model:数据模型View:界面ViewModel:作为桥梁负责沟通View和Model 在JQuery时期,如果需要刷新UI,需要先取到对应的 DOM 再更新 UI,这样数据和业务的逻辑就和⻚⾯有强耦合。 在 MVVM 中,UI 是…...

如何用applera1n免费绕过iOS激活锁:完整指南与操作教程
如何用applera1n免费绕过iOS激活锁:完整指南与操作教程 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否购买了一部二手iPhone或iPad,却发现设备被原主人的Apple ID锁定&a…...
)
保姆级教程:用Python+NumPy复现经典Laplacian曲面编辑算法(附源码)
从理论到代码:Python实现Laplacian曲面编辑的完整指南 在三维图形处理领域,Laplacian曲面编辑技术因其出色的细节保持能力而备受推崇。这项技术允许开发者对三维模型进行直观的变形操作,同时保持模型表面的几何细节不被破坏。本文将带您从零开…...

Ruby中文分词利器Rurima:纯Ruby实现的高性能分词引擎详解
1. 项目概述:一个为Ruby打造的现代中文分词引擎在Ruby社区里,处理中文文本一直是个有点“硌脚”的活儿。如果你做过中文搜索、内容分析或者简单的词频统计,肯定遇到过这个经典难题:怎么把一串连续的中文字符,准确地切割…...

如何快速突破平台限制:跨平台Steam创意工坊模组下载终极指南
如何快速突破平台限制:跨平台Steam创意工坊模组下载终极指南 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台无法访问Steam创意工坊而烦恼…...

城通网盘高速解析终极指南:如何免费实现40倍下载提速
城通网盘高速解析终极指南:如何免费实现40倍下载提速 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否厌倦了城通网盘那令人抓狂的蜗牛下载速度?每次下载大文件都要面对漫长…...

多模态AI实战:基于OpenGVLab/Ask-Anything构建视觉问答系统
1. 项目概述:当视觉大模型学会“看图说话”最近在折腾多模态AI应用,发现了一个挺有意思的开源项目,叫OpenGVLab/Ask-Anything。简单来说,它就像一个给AI装上了“眼睛”和“嘴巴”的系统,你给它一张图片或一段视频&…...

VectorDBBench:向量数据库性能基准测试工具详解与实战
1. 项目概述:向量数据库性能测试的“瑞士军刀”如果你正在评估或使用向量数据库,那么你一定遇到过这个灵魂拷问:“这么多产品,到底哪个最适合我的场景?”是选名声在外的老牌劲旅,还是选后起之秀的专精选手&…...

终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能
终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专为NVIDIA显卡用户设计的免费优化工具&…...

UVa 366 Cutting Up
题目描述 拼布者经常需要将布料切割成 111 \times 111 的小正方形。他们有一种特殊工具(旋转切割刀),可以一次切割多层布料,切割层数的上限由布料类型决定(题目输入的第一个参数 KKK)。切割时,无…...

从零构建情感大语言模型:基于EmoLLM的实践指南
1. 项目概述:当大语言模型学会“察言观色”最近在折腾一个挺有意思的开源项目,叫SmartFlowAI/EmoLLM。光看名字你可能就猜到了,这玩意儿跟“情绪”和“大语言模型”有关。没错,它的核心目标就是让冷冰冰的LLM(Large La…...