MongoDB索引操作和执行计划Explain()详解
一、索引操作
说明,下面的内容举例时,以"dailyTrip"collection为例。 字段内容如下:
{"_id" : ObjectId("63ec5a971ddbe429cbeeffe3"), // object id"car_type" : "Gett", // string"date" : ISODate("2016-04-01T00:00:00.000+0000"), //ISODate"trips" : 0.0, // number"monthly" : "NA", // string"parent_type" : "Ride-hailing apps", // string"monthly_is_estimated" : true, // boolean"geo" : { // object "$concat" : [ // array "$parent_type","$grouping"]}
}
执行看看有5.17万条数据
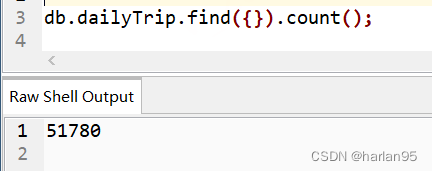
1. 索引类型
- 单列索引: 在一个字段上创建的索引。
- 复合索引:由多个字段组合一起创建的索引。使用的时候要注意最左前缀原则,避免索引无法命中(失效)。
- 文本索引(全文索引)和空间索引(GEO索引),不常用,这里不讲,具体自行网上查询。
2. 查看
语法:
db.Collection.getIndexs();
返回内容说明:
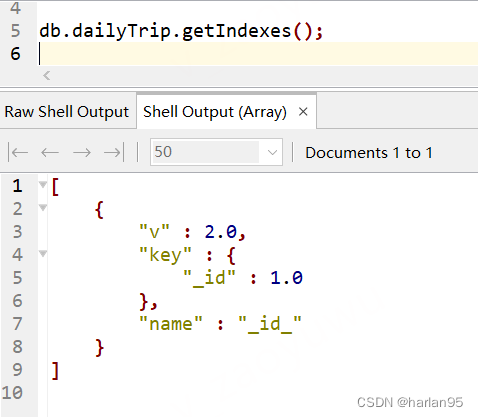
[ // 返回一个数组,内容是所有索引{"v" : 2.0, // 索引版本,可忽略"key" : { // 索引加在哪个字段,以及排序"_id" : 1.0 // _id 是字段, 1.0是正序(升序), -1.0是倒序(倒序)},"name" : "_id_" // 索引名,如果添加的时候没有指定,Mongo会自动生成。 }
]
举例:
可以看到返回一个name为 id的索引。 作用于 _id上, 升序排列。
3. 创建
语法:
db.collection.createIndex(keys, options)// 组合索引
db.collection.createIndex( { <field1>: <type>, <field2>: <type2>, ... } ) // 其中 <fieldN>是字段名 <typeN>是排序注意:3.0.0 版本之前创建索引方法为 db.collection.ensureIndex()。 5.0之后ensureIndex() 已被移除。
举例:
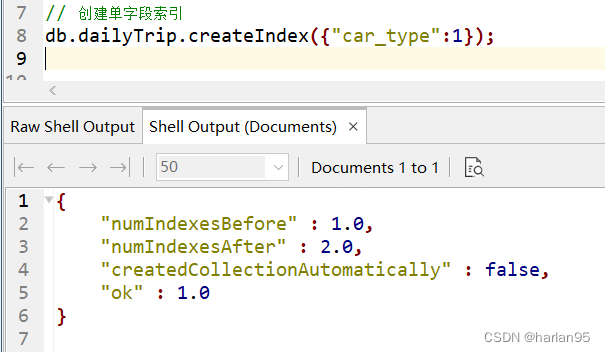
// 创建单字段索引
db.dailyTrip.createIndex({"car_type":1});// 返回结果
{"numIndexesBefore" : 1.0, // 新建索引前的索引数"numIndexesAfter" : 2.0, // 新建索引后的索引数 "createdCollectionAutomatically" : false, // 一般情况下,如果该集合存在,这里就是返回false。如果指定的集合不存在,MongoDB 默认情况下会自动创建该集合,并在该集合上创建索引,此时返回true。"ok" : 1.0 // 创建结果 1.0则是成功。返回0则说明报错了。
}// 如果创建的字段的索引已经存在,则返回如下
{"numIndexesBefore" : 2.0,"numIndexesAfter" : 2.0,"note" : "all indexes already exist", // 提示已经存在"ok" : 1.0
}// 创建复合索引
db.dailyTrip.createIndex({"parent_type":1, "car_type":1})
// 也可以指定自定义索引名
db.dailyTrip.createIndex({"parent_type":1, "car_type":1}, { name: "inx_parantType_carType" }) // 这里自己试验// 来自官方文档 https://www.mongodb.com/docs/manual/reference/command/createIndexes/

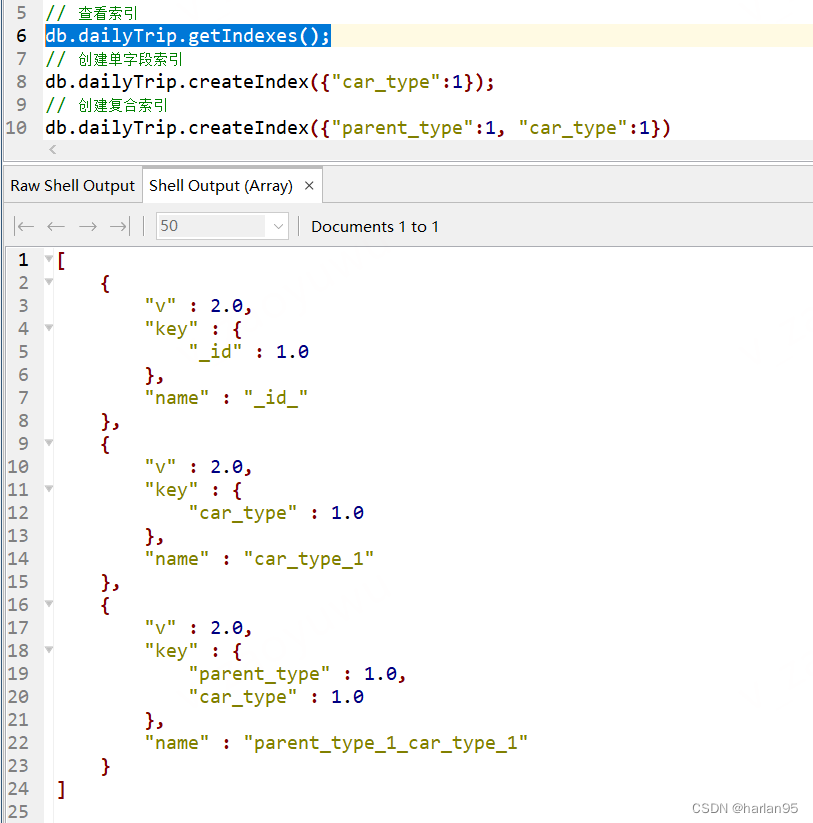
创建完毕后,再次查看当前索引情况
4. 删除
语法:
删除指定集合中所有索引:
db.collection.dropIndexes();
删除指定集合中的具体索引:
db.collection.dropIndex("索引名称");
举例:
// 删除指定索引
db.dailyTrip.dropIndex("car_type_1");// 返回结果
{"nIndexesWas" : 3.0, // 指示在删除索引之前集合中存在的索引数量。"ok" : 1.0
}// 删除所有,自行尝试。 注意, 主键_id的索引是不会也不能被删除的。
db.collection.dropIndexes();

5. 修改
无法直接修改,如果需要调整索引字段、名称、组合索引的顺序,需要先删除原来索引,再新建索引。
6. 索引使用原则
- 选择经常被查询的字段来创建索引。那些在查询条件、排序和聚合操作中频繁出现的字段是最佳选择。
- 选择合适的、常用作查询条件的字段,综合判断是否可以使用复合索引,如果可以优先复合索引。 比如多数情况是按照字段A、B、C或者A、B条件去查询,那么可以优先考虑基于字段A、B、C创建复合索引。 使用复合索引来覆盖多个查询条件,以减少索引的数量。
- 尽量使用索引覆盖,和MySQL中的索引覆盖是类似的。 覆盖索引是指索引包含了查询所需的字段,从而避免了查询需要访问实际文档。这可以提高查询性能,减少IO操作。 其实这里和上面的复合索引是相关的。
- 其他的还有包括使用Explain去查看执行计划、定期监控性能、删除冗余无用的索引之类的,不一而足。 上面是基于实际开发经验得出的常用手段原则。
7. 索引失效的情况
- 查询条件不满足索引前缀: 例如,复合索引是 { a: 1, b: 1 },而查询条件只包含 { b: 1 },则该复合索引将无法被使用。
- 数据类型不匹配: 如果查询条件中的数据类型与索引字段的数据类型不匹配,索引可能无法被使用。例如,如果索引字段是数字类型,而查询条件中使用了字符串类型的值,索引将无法被使用。// 类似Mysql中的隐式转换会使索引失效。
- 索引选择性低: 索引的选择性是指索引中不同值的唯一性程度。如果索引的选择性很低,即索引中的值几乎都相同,那么使用该索引可能不会带来明显的性能提升。// 这里其实是说索引列的值的区分度,如果重复度过高,那么使用索引的性能可能不如不用,索引底层优化器可能不选择使用索引。假如字段gender只有2个值,male和female,其中一半数据是male,另一半是female,此时用gender索引,还不如不用。
- 使用不支持的操作符: 某些查询操作符可能无法使用索引。例如,正则表达式查询、模糊查询(如 $text 操作符)等可能无法充分利用索引。
- 数据量较小: 当集合中的数据量较小时,MongoDB 可能会选择全表扫描而不使用索引,因为全表扫描可能更快。// 类似mysql中,一般建议小于1000条就不加索引,因为索引有额外开销。
- 索引过期或损坏: 如果索引过期或损坏,MongoDB 将无法使用该索引。
- 索引被禁用: 如果在查询时禁用了索引,或者索引的存储引擎不支持该查询,索引将无法被使用。
- 索引尺寸过大: 如果索引的尺寸超过了 MongoDB 的限制,该索引可能无法被使用。
使用 explain() 方法可以查看查询计划和索引使用情况,帮助识别索引失效的原因,并进行相应的优化。
接下来对Explain方法做说明解释。
二、执行计划 Explain()
1. 什么是Explain()执行计划?
- explain() 是一个用于查询解释和性能分析的方法(函数)。
- 可以在find()、aggregate() 和 count() 等查询操作的结果上调用 explain() 方法。
- 其作用:
- 有助于了解查询的执行计划、索引使用情况以及查询性能的相关指标。
- 调用该方法后。MongoDB 会返回一条包含查询执行计划的文档(结果)(具体说明如下),其中包含了查询优化器的决策、索引使用情况、扫描文档数量等信息。通过分析 explain() 返回的执行计划,可以确定是否使用了适当的索引,是否存在潜在的性能问题,并根据需要进行索引优化、查询重写等操作,以提高查询性能。
- 执行计划的返回结果:
- queryPlanner:查询优化器的决策和统计信息。
- winningPlan:优化器选择的最佳执行计划。
- executionStats:执行计划的统计信息,如扫描的文档数量、查询时间等。
- serverInfo:MongoDB 服务器的信息。
注意:explain()` 的输出非常详细,包含了大量的信息。因此,它在调试和优化查询时非常有用,但在生产环境中不应该频繁地使用,以避免对性能产生负面影响。
官方文档:
- explain的详细说明 explain — MongoDB Manual
- explain的返回结果的详细说明 Explain Results — MongoDB Manual
2. Explain的语法和使用
语法
// 普通的语句,直接在语句后面加上explain,也可以挪到find的前面。
db.collection.find({}).explain(<optional verbosity mode>);// 对聚合pipeline的执行计划分析,explain放前面
db.collection.explain(<optional verbosity mode>).aggregate([]);<optional verbosity mode> 是可选的输出模式。
如果什么都不写,比如 db.collection.find({"name"”":"onepiece"}).explain(); 那么mongo会走默认模式 "queryPlanner"。
如果要指定模式,则直接加上,比如 db.collection.find({"name"”":"onepiece"}).explain("executionStats")
explain有三种模式:
- queryPlanner (默认) : 只列出所有可能执行的方案,不会执行实际的语句,显示已经胜出的方案winningPlan(最佳查询计划)。
- executionStats : 只执行winningPlan方案,并输出结果。
- allPlansExecution :执行所有的方案,并输出结果。
关于explain的参数可以参考官网: cursor.explain() — MongoDB Manual
3. 三种模式下的说明和结果解释
3.1 queryPlanner 模式
运行查询优化器对当前的查询进行评估并选择一个最佳的查询计划,不执行实际语句。
下面三种模式均以这个查询语句为例:
db.getCollection("dailyTrip").explain().find({"parent_type":"Ride-hailing apps"}, { _id:0});
下面是一个执行的返回结果,我把详细内容先收起,可以看到返回的字段有哪些。
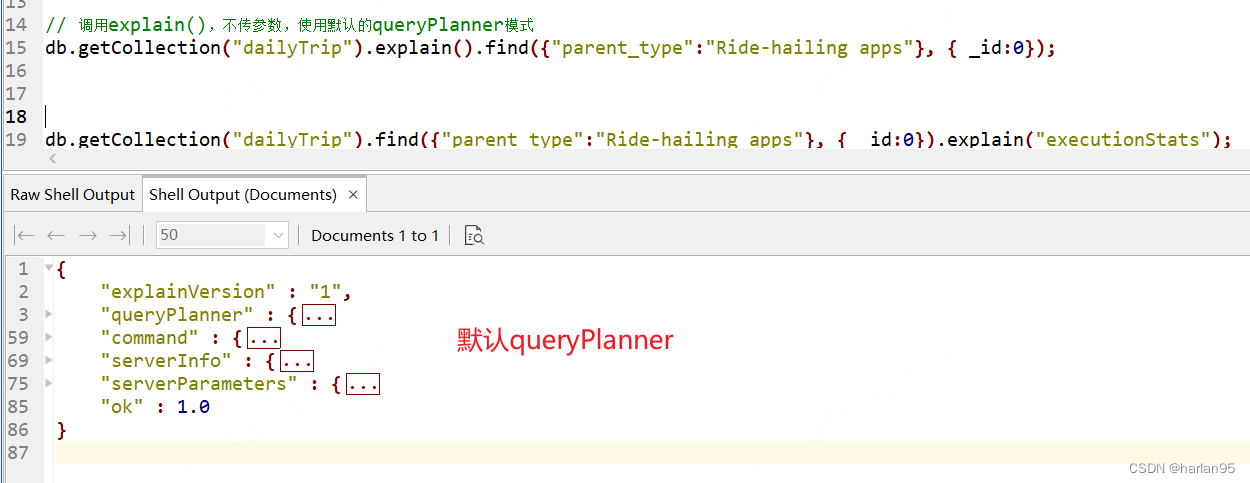
具体解释
{"explainVersion" : "1", // 执行计划的版本,可以忽略 "queryPlanner" : { // queryPlanner,就是执行计划。 这部分重点看"namespace" : "test.dailyTrip", // 就是collection和所在db"indexFilterSet" : false, // 是否设置了索引过滤器集合,Filter决定了查询优化器对于某个查询将如何使用索引"parsedQuery" : { // 经过解析后的query内容。"parent_type" : {"$eq" : "Ride-hailing apps"}},"queryHash" : "8B8C334A", // 查询的哈希值,"planCacheKey" : "F910A33F", // 查询执行计划的缓存键"maxIndexedOrSolutionsReached" : false, // 是否已达到最大索引【或】解决方案的限制。 跳过"maxIndexedAndSolutionsReached" : false, // 表示是否已达到最大索引【和】解决方案的限制。 跳过"maxScansToExplodeReached" : false, // 是否已达到最大扫描数的限制。 跳过"winningPlan" : { // 这个很关键,这里是最后底层选择的执行计划。 "stage" : "PROJECTION_DEFAULT", // stage 是指步骤 可以由stage名称看到具体做了什么。 projection是应用投影操作,选择所需的字段"transformBy" : { // 具体投影内容 跳过"_id" : 0.0},"inputStage" : { // 执行阶段的子阶段,这里是一个FETCH的子过程"stage" : "FETCH", // FETCH是 从索引中获取文档数据。"inputStage" : { // 其中一个阶段,具体操作。 这里面的东西是重点要看的。 "stage" : "IXSCAN", // 这里是说使用索引进行扫描,通常表示优化的查询。"keyPattern" : { // 表示下面的索引字段的排列方式,1.0正序,-1.0倒序。"parent_type" : 1.0,"car_type" : 1.0},"indexName" : "parent_type_1_car_type_1", // 用到的索引名称"isMultiKey" : false, // 是否为多键索引。 如果为 true,表示索引包含数组值"multiKeyPaths" : { // 如果索引是多键索引,这个属性将会包含索引中包含数组值的字段路径。本例中的索引不是多键索引,因此下面的字段为空数组。"parent_type" : [],"car_type" : []},"isUnique" : false, // 是否为唯一索引"isSparse" : false, // 是否为稀疏索引"isPartial" : false, // 是否为部分索引"indexVersion" : 2.0, // 索引版本 "direction" : "forward", // 索引的遍历方向"indexBounds" : { // 当前查询具体使用的索引"parent_type" : ["[\"Ride-hailing apps\", \"Ride-hailing apps\"]"],"car_type" : ["[MinKey, MaxKey]"]}}}},"rejectedPlans" : [ // 底层优化器拒绝的计划,没有执行的计划。 ]},"command" : { // 语句具体涉及到的命令、collection、DB"find" : "dailyTrip", // 表名 从哪个collection中查找"filter" : { // 哪个阶段,这里就是过滤"parent_type" : "Ride-hailing apps"},"projection" : { // 投影 控制要返回的字段 "_id" : 0.0},"$db" : "test" // 库},"serverInfo" : { // 服务器信息 "host" : "onepiece-pc", // mongo的示例主机名称"port" : 27017.0, // 端口"version" : "5.0.9", // mongodb的版本"gitVersion" : "6f7dae919422dcd7*****************1ad00e6" // 这里是git版本,这里无关紧要,我脱敏了。 },"serverParameters" : { // 服务器的参数,各种缓存大小、最大阈值设置,暂时和我们这里说的内容无关,跳过。"internalQueryFacetBufferSizeBytes" : 104857600.0,"internalQueryFacetMaxOutputDocSizeBytes" : 104857600.0,"internalLookupStageIntermediateDocumentMaxSizeBytes" : 104857600.0,"internalDocumentSourceGroupMaxMemoryBytes" : 104857600.0,"internalQueryMaxBlockingSortMemoryUsageBytes" : 104857600.0,"internalQueryProhibitBlockingMergeOnMongoS" : 0.0,"internalQueryMaxAddToSetBytes" : 104857600.0,"internalDocumentSourceSetWindowFieldsMaxMemoryBytes" : 104857600.0},"ok" : 1.0
}
3.2 executionStats模式
db.getCollection("dailyTrip").find({"parent_type":"Ride-hailing apps"}, { _id:0}).explain("executionStats");
运行查询优化器对当前的查询进行评估并选择一个最佳的查询计划进行执行,在执行完毕后返回这个最佳执行计划执行完成时的相关统计信息。
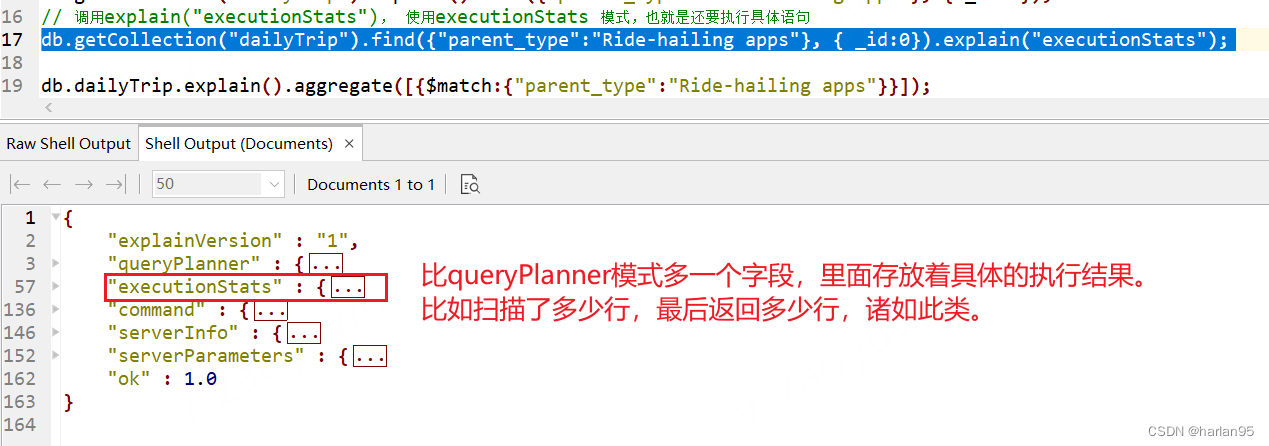
{"explainVersion" : "1","queryPlanner" : {// ... 同上,省略。"parsedQuery" : {// ... 同上,省略。},// ... 同上,省略。"winningPlan" : {// ... 同上,省略。}"rejectedPlans" : [// ... 同上,省略。]},"executionStats" : { // 重点留意这里面的内容"executionSuccess" : true, // 执行结果"nReturned" : 23010.0, // 返回的文档数"executionTimeMillis" : 70.0, // 执行耗时 ms"totalKeysExamined" : 23010.0, // 扫描了的索引总数"totalDocsExamined" : 23010.0, // 总的扫描文档数"executionStages" : { // 执行stage 里面会有具体每个stage的详细"stage" : "PROJECTION_DEFAULT", // 阶段类型"nReturned" : 23010.0, "executionTimeMillisEstimate" : 10.0, // 预估执行时间 ms"works" : 23011.0, // 阶段中扫描任务数"advanced" : 23010.0, // 阶段中向上提交数量"needTime" : 0.0, // 阶段中定位索引位置所需次数"needYield" : 0.0, // 阶段中获取锁等待时间"saveState" : 23.0, // :表示在查询执行过程中,保存中间状态所花费的时间 ms"restoreState" : 23.0, // 表示在查询执行过程中,恢复之前保存的中间状态所花费的时间 ms"isEOF" : 1.0, // 阶段中是否到达流的结束位,对于limit限制符的查询可能为0"transformBy" : { // 表示查询计划是否使用了投影操作来转换结果 "_id" : 0.0},"inputStage" : { // 执行阶段的子阶段,这里是一个fetch的子过程"stage" : "FETCH", // 内容差不多 "nReturned" : 23010.0,"executionTimeMillisEstimate" : 4.0,"works" : 23011.0,"advanced" : 23010.0,"needTime" : 0.0,"needYield" : 0.0,"saveState" : 23.0,"restoreState" : 23.0,"isEOF" : 1.0,"docsExamined" : 23010.0,"alreadyHasObj" : 0.0,"inputStage" : { // 子阶段,ixscan子过程"stage" : "IXSCAN","nReturned" : 23010.0,"executionTimeMillisEstimate" : 4.0,"works" : 23011.0,"advanced" : 23010.0,"needTime" : 0.0,"needYield" : 0.0,"saveState" : 23.0,"restoreState" : 23.0,"isEOF" : 1.0,"keyPattern" : {"parent_type" : 1.0,"car_type" : 1.0},"indexName" : "parent_type_1_car_type_1","isMultiKey" : false,"multiKeyPaths" : {"parent_type" : [],"car_type" : []},"isUnique" : false,"isSparse" : false,"isPartial" : false,"indexVersion" : 2.0,"direction" : "forward","indexBounds" : {"parent_type" : ["[\"Ride-hailing apps\", \"Ride-hailing apps\"]"],"car_type" : ["[MinKey, MaxKey]"]},"keysExamined" : 23010.0,"seeks" : 1.0,"dupsTested" : 0.0,"dupsDropped" : 0.0}}}},"command" : { // ... 同上,省略。},"serverInfo" : { // ... 同上,省略。},"serverParameters" : {// ... 同上,省略。},"ok" : 1.0
}
3.3 allPlansExecution模式
// 调用explain("allPlansExecution"), allPlansExecution 模式,执行所有的方案,并输出结果。
db.getCollection("dailyTrip").find({"parent_type":"Ride-hailing apps"}, { _id:0}).explain("allPlansExecution");
allPlansExecution相比executionStats,其他的备选执行计划也会去执行,并统计结果出来。 会存放在 executionStats中。
即按照最佳的执行计划执行以及列出统计信息, 如果有多个查询计划,还会列出这些非最佳执行计划部分的统计信息。
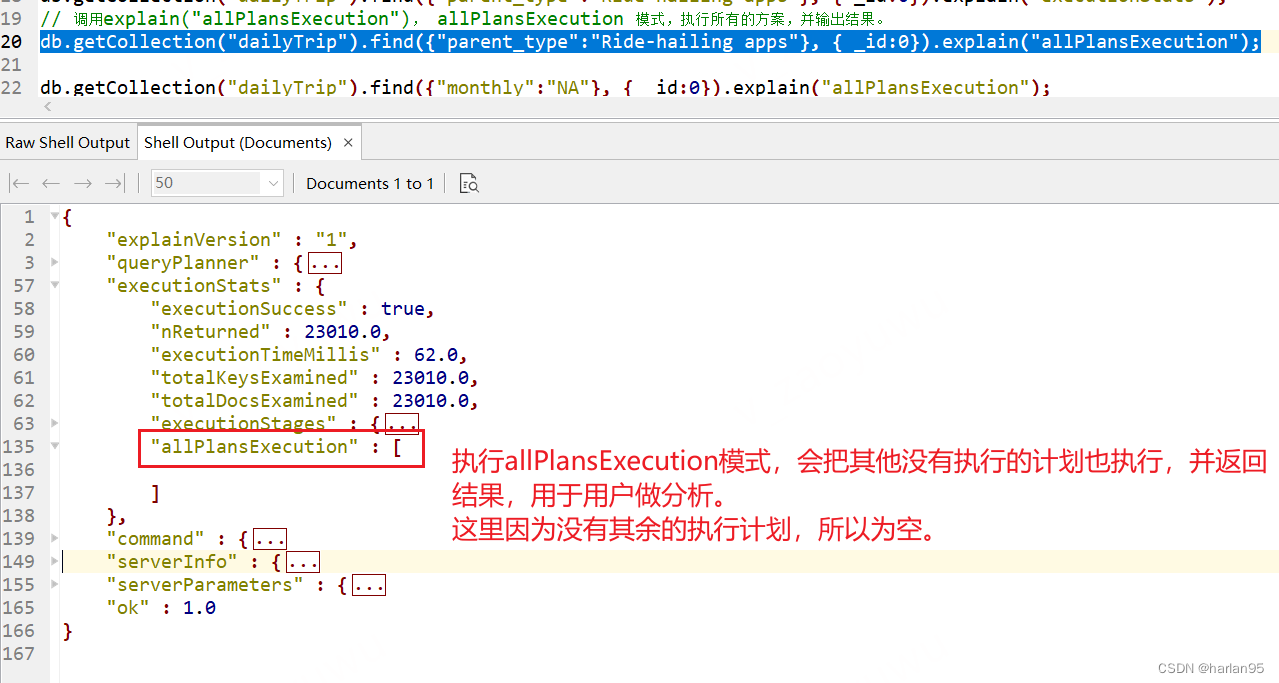
{"explainVersion" : "1","queryPlanner" : {"namespace" : "test.dailyTrip","indexFilterSet" : false,"parsedQuery" : {"parent_type" : {"$eq" : "Ride-hailing apps"}},"maxIndexedOrSolutionsReached" : false,"maxIndexedAndSolutionsReached" : false,"maxScansToExplodeReached" : false,"winningPlan" : {// ... 同上,省略。},"rejectedPlans" : [// ... 同上,省略。]},"executionStats" : {"executionSuccess" : true,"nReturned" : 23010.0,"executionTimeMillis" : 68.0,"totalKeysExamined" : 23010.0,"totalDocsExamined" : 23010.0,"executionStages" : {// 这里的executionStage和2.2的executionStats中的executionstages一样,参考那里。 },"allPlansExecution" : [ // 重点:allPlansExecution 如果有其他执行计划,那么会在这里把执行统计结果放出来。 ]},"command" : {// ... 同上,省略。},"serverInfo" : {// ... 同上,省略。},"serverParameters" : {// ... 同上,省略。},"ok" : 1.0
}
Stage参数值
- COLLSCAN:全表扫描
- IXSCAN:索引扫描
- FETCH:根据索引去检索指定document
- SHARD_MERGE:将各个分片返回数据进行merge
- SORT:表明在内存中进行了排序
- LIMIT:使用limit限制返回数
- SKIP:使用skip进行跳过
- IDHACK:针对_id进行查询
- SHARDING_FILTER:通过mongos对分片数据进行查询 —服务器是分片的才有。
- COUNT:利用db.coll.explain().count()之类进行count运算
- COUNTSCAN: count不使用Index进行count时的stage返回
- COUNT_SCAN: count使用了Index进行count时的stage返回
- SUBPLA:未使用到索引的$or查询的stage返回
- TEXT:使用全文索引进行查询时候的stage返回
- PROJECTION:限定返回字段时候stage的返回
参考文档
https://www.cnblogs.com/littleatp/p/8419678.html
4. 查询优化思路
- 尽量使用索引。 举例,比如通过上面的执行计划发现某个作为查询条件的字段,没有用上索引,且通过索引可以极大提高性能,那么可以考虑对该字段增加索引。
- 扫描文档数越小越好。举例,比如上面的执行计划中,某个阶段返回的扫描文档数量极大,那么可以考虑优化语句,比如调整语句顺序,先过滤再处理;或者对查询条件字段增加索引。
相关文章:
MongoDB索引操作和执行计划Explain()详解
一、索引操作 说明,下面的内容举例时,以"dailyTrip"collection为例。 字段内容如下: {"_id" : ObjectId("63ec5a971ddbe429cbeeffe3"), // object id"car_type" : "Gett", // string&…...

H3C NX30Pro刷机教程-2024-11-16
H3C NX30Pro刷机教程-2024-11-16 ref: http://www.ttcoder.cn/index.php/2024/11/03/h3c-nx30pro亲测无需分区备份 路由器-新机初始化设置路由器登录密码telnet进入路由器后台 刷机上传uboot到路由器后台在Windows环境下解压后的软件包中打开 tftpd64.exe在NX30Pro环境下通过以…...

无插件H5播放器EasyPlayer.js网页web无插件播放器vue和react详细介绍
EasyPlayer.js H5播放器,是一款能够同时支持HTTP、HTTP-FLV、HLS(m3u8)、WS、WEBRTC、FMP4视频直播与视频点播等多种协议,支持H.264、H.265、AAC、G711A、Mp3等多种音视频编码格式,支持MSE、WASM、WebCodec等多种解码方…...

HarmonyOS ArkUI(基于ArkTS) 开发布局 (中)
HarmonyOS ArkUI(基于ArkTS) 开发布局 (上) 四 层叠布局 (Stack) 层叠布局(StackLayout)用于在屏幕上预留一块区域来显示组件中的元素,提供元素可以重叠的布局。层叠布局通过Stack容器组件实现位置的固定定位与层叠&…...

org.springframework.context.support.ApplicationListenerDetector 详细介绍
一,功能介绍 early post-processor for detecting inner beans as ApplicationListeners 早期的PostProcessor用来检测并处理内部(inner)bean作为 ApplicationListeners BeanPostProcessor that detects beans which implement the Applica…...

MSTP实验
单点故障---冗余---环路---STP----RSTP-----MSTP MSTP 产生的背景 因为RSTP在局域网内所有VLAN 共享一棵生成树,如果链路被堵塞,将无法承载任何流量,所以为了实现流量负载均衡,MSTP诞生了。 生成树不是基于VLAN运行的ÿ…...

Linux---shell脚本
文章目录 目录 文章目录 前言 一.Shell脚本定义 shell脚本书写规范 shell脚本执行方式 二.Shell变量 变量定义 定义规范 定义方式 变量的运算 数值运算 数值比较 未完待续...... 前言 希望通过本文的学习,你能够掌握Shell脚本的基本知识和实用技巧,…...

Android12的ANR解析
0. 参考: ANR分析 深入理解 Android ANR 触发原理以及信息收集过程 1.ANR的触发分类: ANR分为4类: InputDispatchTimeout:输入事件分发超时5s,包括按键和触摸事件。BroadcastTimeout:比如前台广播在10s内未执行完成࿰…...

初学人工智不理解的名词3
TTS领域的名词 from gpt-4o 在 TTS(文本到语音合成) 领域,以下是 CFM、One-Step 蒸馏 和 ReFlow 的含义和作用的详细解释: 1. CFM(Consistent Flow Matching) Consistent Flow Matching(一致流…...

ADS项目笔记 1. 低噪声放大器LNA天线一体化设计
在传统射频结构的设计中,天线模块和有源电路部分相互分离,两者之间通过 50 Ω 传输线级联,这种设计需要在有源电路和天线之间建立无源网络,包括天线模块的输入匹配网络以及有源电路的匹配网络。这些无源网络不仅增加了系统的插入损…...

J.U.C - 深入解读阻塞队列实现原理源码
文章目录 Pre生产者-消费者模式阻塞队列 vs 普通队列JUC提供的7种适合与不同应用场景的阻塞队列插入操作:添加元素到队列中移除操作:从队列中移除元素。 ArrayBlockingQueue源码解析类结构指定初始容量及公平/非公平策略的构造函数根据已有集合初始化队列…...

【大语言模型学习】LORA微调方法
LORA: Low-Rank Adaptation of Large Language Models 摘要 LoRA (Low-Rank Adaptation) 提出了一种高效的语言模型适应方法,针对预训练模型的适配问题: 目标:减少下游任务所需的可训练参数,降低硬件要求。方法:冻结预训练模型权重,注入低秩分解矩阵,从而在不影响推理…...

Spring Boot【一】
Spring Boot全局配置文件 application.properties 是 Spring Boot 的标准配置文件,用于集中管理应用程序的配置属性。它的主要作用是将配置信息与代码分离,使得应用程序更具可维护性和可配置性。 Application.yaml配置文件 YAML文件格式是JSON超集文件…...

H.265流媒体播放器EasyPlayer.js H.264/H.265播放器chrome无法访问更私有的地址是什么原因
EasyPlayer.js H5播放器,是一款能够同时支持HTTP、HTTP-FLV、HLS(m3u8)、WS、WEBRTC、FMP4视频直播与视频点播等多种协议,支持H.264、H.265、AAC、G711A、MP3等多种音视频编码格式,支持MSE、WASM、WebCodec等多种解码方…...

【大数据学习 | HBASE高级】rowkey的设计,hbase的预分区和压缩
1. rowkey的设计 RowKey可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,字典顺序排序,rowkey的设计至关重要,会影响region分布,如果rowkey设计不合理还会出现region写热点等一系列问题。 …...

Dart:字符串
字符串:单双引号 String c hello \c\; // hello c,单引号中使用单引号,需要转义\ String d "hello c"; // hello c,双引号中使用单引号,不需要转义 String e "hello \“c\”"; // hell…...

平衡二叉搜索树之 红黑 树的模拟实现【C++】
文章目录 红黑树的简单介绍定义红黑树的特性红黑树的应用 全部的实现代码放在了文章末尾准备工作包含头文件类的成员变量和红黑树节点的定义 构造函数和拷贝构造swap和赋值运算符重载析构函数findinsert【重要】第一步:按照二叉搜索树的方式插入新节点第二步&#x…...

2:Vue.js 父子组件通信:让你的组件“说话”
上一篇我们聊了如何用 Vue.js 创建一个简单的组件,这次咱们再往前走一步,讲讲 Vue.js 的父子组件通信。组件开发里,最重要的就是让组件之间能够“说话”,数据能流通起来。废话不多说,直接开干! 父组件传数据…...

6. Keepalived配置Nginx自动重启,实现7x24提供服务
一. Keepalived配置Nginx自动重启,实现7x24提供服务 1.编写不停的检查nginx服务器状态,停止并重启,重启失败后则停止keepalived脚本 cd /etc/keepalived/ vim check_nginx_alive_or_not.sh #---内容如下:--------------- #!/bin/bash A=`ps -C nginx --no-header |wc -l...

【PS】蒙版与通道
内容1: 、选择蓝色通道并复制,对复制的蓝色通道ctrli进行反向选择,然后ctrll调整色阶。 、选择载入选区,然后点击rgb。 、点击蒙版 、点击云彩图层调整位置 、点击色相/饱和度,适当调整 、最后使用滤镜等功能添加光圈…...

技术视角:分布式投票系统的异步解耦架构与多语言协同实践
技术视角:分布式投票系统的异步解耦架构与多语言协同实践 【免费下载链接】example-voting-app Example Docker Compose app 项目地址: https://gitcode.com/gh_mirrors/exa/example-voting-app 在当今企业级应用架构设计中,如何平衡高并发处理、…...

终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案
终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

如何免费下载百度文库文档:三步搞定PDF保存的终极指南
如何免费下载百度文库文档:三步搞定PDF保存的终极指南 【免费下载链接】baidu-wenku fetch the document for free 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wenku 你是否经常在百度文库找到完美的学习资料或工作报告,却因为需要下载券…...

终极CoreCycler完全指南:5步掌握CPU单核稳定性测试与精准调校
终极CoreCycler完全指南:5步掌握CPU单核稳定性测试与精准调校 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitco…...

从零到一:在个人PC上部署并集成ChatGLM-6B到Unity应用
1. 环境准备与模型下载 在个人PC上部署ChatGLM-6B需要先搞定三件事:硬件检查、软件环境搭建和模型文件获取。我的老款游戏本(i7-9750H RTX2060 6GB显存)实测可以流畅运行,关键在于正确的量化配置。 硬件检查要点: 显存…...

AI智能体任务编排框架:从概念到实战的Mission Control指南
1. 项目概述:为AI智能体打造一个“任务控制中心”最近在折腾AI智能体(Agent)的开发,发现一个挺普遍的问题:当你想让多个智能体协同工作,或者想让单个智能体执行一系列复杂、有依赖关系的任务时,…...

All in Token,三个运营商建Token工厂,中国移动跟进Token经营 三大运营商争夺AI阵地
随着Token(词元)经营战略的密集落地,三大运营商在AI领域的竞争愈发激烈。在日前举行的2026移动云大会上,中国移动正式发布了Token运营生态体系与移动模型服务平台MoMA,宣布接入超300款模型,并通过Token集约…...

罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性
罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求…...

【2026最新】鸿蒙NEXT ArkUI实战:培训班管理系统UI界面开发全攻略
鸿蒙UI开发总是踩坑?ArkUI组件用法记不住?本文用15分钟带你彻底搞懂ArkUI核心组件、布局系统、自定义组件和交互动画,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App界面从此丝滑流畅!一、培训班管理界面设计1…...

AI编程助手安全规则实战:从SQL注入防御到团队安全基线构建
1. 项目概述:当AI编程助手遇上安全红线最近在GitHub上看到一个挺有意思的项目,叫“cursor-security-rules”。光看名字,你大概能猜到它和Cursor这个AI编程工具有关,而且重点是“安全规则”。没错,这个项目本质上是一个…...