初学人工智不理解的名词3
TTS领域的名词 from gpt-4o
在 TTS(文本到语音合成) 领域,以下是 CFM、One-Step 蒸馏 和 ReFlow 的含义和作用的详细解释:
1. CFM(Consistent Flow Matching)
Consistent Flow Matching(一致流匹配) 是一种用于训练生成模型的方法,特别适用于概率密度建模和连续变量生成任务。它是生成式流模型中的一种技术,用于通过流(Flow)模型直接对目标分布进行建模。
在 TTS 中,CFM 的作用是:
- 通过流模型学习语音的连续分布。
- 避免传统方法中复杂的多阶段处理流程(如从文本特征到声学特征,再到波形生成的多步转换),实现更直接的文本到语音生成。
- 改善模型的稳定性和一致性,确保合成语音的质量更加自然流畅。
优势:
- 模型能够更好地捕获复杂的语音特征分布。
- 提高生成的语音质量,同时减少训练和推理的复杂性。
2. One-Step 蒸馏
One-Step 蒸馏 是一种知识蒸馏(Knowledge Distillation)的优化方法,目标是通过一次训练让学生模型学习教师模型的知识,而无需多步迭代。
在 TTS 中,One-Step 蒸馏通常用于:
- 模型压缩:从复杂的教师模型(如高性能但较大的 TTS 模型)中提取知识,让轻量级的学生模型生成类似的高质量语音。
- 加速推理:通过蒸馏技术,减少推理步骤的计算量,使生成过程更快(如直接生成波形而无需中间的 Mel 频谱阶段)。
- 简化训练流程:相比于多步蒸馏,One-Step 蒸馏仅需一次训练,显著减少了计算资源和时间成本。
优点:
- 减少模型大小,适合部署在资源有限的设备上(如嵌入式设备或移动端)。
- 在不显著牺牲语音质量的前提下,提高生成速度。
3. ReFlow
ReFlow(Reversible Flow Matching) 是一种流模型优化方法,用于提升生成模型的灵活性和表现。ReFlow 在概率密度估计和采样方面进行了改进,允许训练时以匹配目标分布的方式优化模型。
在 TTS 中,ReFlow 的应用:
- 高效波形生成:ReFlow 可用于直接生成波形,而无需传统的阶段化流程(如从 Mel 频谱生成波形)。
- 稳定训练:通过引入可逆流(Reversible Flow)的机制,ReFlow 可以在训练过程中对特征空间进行稳定的映射,从而减少不一致性带来的问题。
- 提升音质:ReFlow 能更精准地捕捉语音信号的复杂分布,生成更加自然的语音。
技术特点:
- 可逆性:通过可逆的流模型,ReFlow 允许模型在前向生成和反向学习之间切换,增强了模型的灵活性。
- 高效性:与传统方法相比,ReFlow 更高效,因为它减少了训练时对模型参数的大规模调整需求。
总结
| 方法 | 定义与用途 | 优势 |
|---|---|---|
| CFM | 一致流匹配,通过流模型建模目标分布,适合直接生成语音。 | 提高语音质量,减少处理步骤,生成更加一致和自然的语音。 |
| One-Step 蒸馏 | 一次性知识蒸馏,将教师模型的知识高效转移到学生模型中,压缩模型并加速生成过程。 | 减少训练时间,提升生成效率,适合移动端或嵌入式设备部署。 |
| ReFlow | 可逆流匹配,通过流模型优化生成过程,捕获语音分布并改进波形生成。 | 增强生成模型的灵活性和音质,减少训练不稳定性,支持高效的波形生成。 |
这些技术各自的目标是提高 TTS 模型的效率、质量和推理速度,并在不同应用场景下为开发者提供灵活的解决方案。
4. Resemblyzer
Resemblyzer 是一个开源的 Python 库,用于处理语音嵌入(voice embeddings),可以将音频中的语音特征编码为紧凑的、高维的向量表示。通过这些嵌入向量,系统能够对语音进行各种分析,如说话人验证、说话人识别、说话人聚类等任务。它广泛应用于语音处理任务中,特别是在需要识别或区分说话人的应用场景中。
核心功能
-
说话人嵌入生成:
- Resemblyzer 提供一种高效的方式,将语音文件转化为固定长度的嵌入向量。这些向量包含了说话人的特征信息,具有较高的语义一致性。
- 即使输入音频的长度不同,生成的嵌入向量依然可以直接比较。
-
说话人验证(Speaker Verification):
- 通过计算两个嵌入向量之间的余弦相似度,判断它们是否属于同一个说话人。
-
语音聚类(Speaker Clustering):
- 将多段音频进行分组,归类为不同的说话人群体。
-
说话人分离(Speaker Diarization):
- 结合 Resemblyzer 的嵌入和其他工具,可以对一个音频文件中的多位说话人进行分离,并标注说话时间段。
技术特点
-
预训练模型:
Resemblyzer 使用了预训练的语音编码器(基于开源的 VoxCeleb 数据集),可以直接用于生成高质量的说话人嵌入。 -
无监督学习:
嵌入生成和比较任务不需要额外的监督标签。只需输入音频文件,系统就能生成适合的向量表示。 -
灵活性:
可与其他工具(如 PyTorch、Kaldi)结合,用于更复杂的语音分析任务。
使用示例
下面是一个简单的代码示例,展示如何用 Resemblyzer 生成语音嵌入并计算相似度:
from resemblyzer import VoiceEncoder, preprocess_wav
from pathlib import Path# 初始化语音编码器
encoder = VoiceEncoder()# 预处理音频文件
wav1 = preprocess_wav(Path("audio1.wav"))
wav2 = preprocess_wav(Path("audio2.wav"))# 生成语音嵌入
embed1 = encoder.embed_utterance(wav1)
embed2 = encoder.embed_utterance(wav2)# 计算相似度
similarity = encoder.similarity(embed1, embed2)
print(f"两个音频的相似度为: {similarity:.2f}")
应用场景
-
语音验证和身份确认:
- 用于电话客服、门禁系统等场景,验证用户是否为系统中的注册用户。
-
多说话人场景分析:
- 在会议记录或访谈中分离不同说话人的语音段落(即说话人分离)。
-
语音聚类和分类:
- 例如,整理语音数据集时自动将语音分组到不同说话人中。
-
个性化 TTS 系统:
- 提取目标用户的语音特征,生成个性化语音合成模型。
总结
Resemblyzer 是一个功能强大、易于使用的语音嵌入工具,适合语音处理领域的多种任务。它简化了说话人嵌入生成过程,为语音识别和分析提供了强大的支持,同时具有开源、灵活、高效的特点,受到开发者的广泛青睐。
5. MBTFNet
MBTFNet(Multi-Branch Temporal-Frequency Network) 是一种专门设计用于语音增强(Speech Enhancement)和去噪(Denoising)任务的深度学习网络。该网络通过结合时域和频域特征来提升语音处理的效果,特别是在噪声环境中提取清晰的语音信号。
MBTFNet 的核心思想
MBTFNet 的主要设计目的是将时域信息和频域信息有效融合,以增强语音信号的清晰度和自然性。它采用了**多分支(Multi-Branch)**结构,以便在不同尺度上捕捉语音的时频特征,从而实现更加精细的语音增强效果。
- 多分支结构:MBTFNet 将语音信号分解成多个时域和频域分支,每个分支专注于不同频段或时间段的特征,能够独立处理高频、中频和低频等不同频率的噪声成分。
- 时频融合:通过时域和频域的特征融合,MBTFNet 可以更全面地分析语音信号特征,有助于在复杂噪声环境中恢复语音细节。
- 跨尺度特征提取:各分支网络在不同尺度上处理特征,以便捕捉从局部到全局的信息,改善语音增强效果。
MBTFNet 的技术细节
-
输入特征:
- 输入通常是经过短时傅里叶变换(STFT)处理的语音信号频谱。
- 通过频谱处理,能够更容易地分析不同频率成分,以适应不同类型的噪声。
-
多分支网络:
- 时域分支:主要捕捉语音信号的时间结构信息,包括音素和音节等细节。
- 频域分支:主要捕捉频谱特征,包括语音的频率成分和能量分布。
- 各分支提取的特征会在后续层进行融合,以增强整体语音特征。
-
特征融合:
- 将时域和频域分支输出的特征进行融合,使得网络能够更全面地捕捉语音和噪声的分布特性。
- 融合后的特征经过卷积、激活等处理后,最终生成去噪后的语音频谱。
-
输出:
- 网络的最终输出是增强后的语音频谱,再经过逆短时傅里叶变换(iSTFT)还原成时域的清晰语音信号。
MBTFNet 的优势
- 高效的去噪效果:多分支结构可以独立处理不同频段的噪声,提高去噪效果。
- 适应复杂环境:MBTFNet 擅长处理各种复杂噪声环境,例如交通噪声、背景人声、工业噪声等。
- 实时性:其架构设计可以适应较低的延迟,使其适合应用于实时语音处理系统。
应用场景
MBTFNet 可以广泛应用于需要语音增强的场景中,包括:
- 电话语音增强:在通话过程中实时去除背景噪声,提高通话质量。
- 语音助手:提高语音助手在嘈杂环境下的识别准确性。
- 视频会议:减少远程会议中的环境噪声,使交流更清晰。
- 听力设备:用于助听器或其他听力设备中,帮助用户更清晰地听到周围的声音。
总结
MBTFNet 是一种多分支时频融合的网络架构,通过结合时域和频域的特征来实现高质量的语音增强。它在处理复杂噪声、提升语音清晰度和自然度方面具有显著优势,适合用于需要语音增强的实时和非实时应用中。
6. DNSMOS
DNSMOS(Deep Noise Suppression Mean Opinion Score) 是一种由微软开发的用于评估语音增强(speech enhancement)系统性能的指标。它是基于深度学习的无参考语音质量评估模型,能够在无需干净参考语音的情况下,对语音质量和语音清晰度进行自动评估。
背景与用途
传统的语音质量评估方法通常分为两类:
-
主观评价:
- 人类评估者对语音质量进行评分,例如 MOS(Mean Opinion Score),这是语音质量评估的黄金标准。
- 缺点:耗时、昂贵,且不适合实时或大规模评估。
-
客观评价:
- 使用信噪比(SNR)、PESQ(Perceptual Evaluation of Speech Quality)等算法。
- 缺点:通常需要干净的参考语音,与实际应用场景(如语音增强后的语音)不匹配。
DNSMOS 的开发目的是提供一种高效的、无参考的语音质量评估方法,特别是针对语音增强任务(如噪声抑制)的场景。
核心原理
DNSMOS 基于一个深度神经网络(DNN),通过学习与人类主观评分之间的映射关系,实现对语音质量的自动预测。
- 训练数据:包括大量带有主观评分的语音片段,涵盖各种噪声环境和语音增强算法处理后的语音。
- 预测输出:模型会生成一个类似于 MOS 的评分,表示语音质量或语音清晰度。
DNSMOS 使用了无参考的评估方式,因此不需要干净语音作为对比参考,可以直接对增强后的语音进行质量分析。
DNSMOS 的三个评分维度
DNSMOS 输出通常包含以下三个维度的评分,以便对语音质量进行全面评估:
-
SIG(Signal Quality):
- 反映语音信号的整体质量,包括失真情况。
-
BAK(Background Noise):
- 衡量背景噪声的感知程度,评分越高,背景噪声越低。
-
OVL(Overall Quality):
- 综合考虑语音信号质量和背景噪声的主观感知得分,代表整体语音质量。
评分范围通常为 1-5,数值越高,代表质量越好。
应用场景
-
语音增强系统的性能评估:
- 用于比较不同语音增强模型(如噪声抑制、回声消除)的效果。
-
语音数据集质量检测:
- 快速评估大规模语音数据集的整体质量。
-
实时语音应用:
- 在 VoIP 通信、视频会议、语音助手中,动态评估增强后的语音质量。
-
模型优化:
- 帮助优化语音增强算法,指导模型训练和参数调整。
与传统方法的对比
| 特性 | DNSMOS | PESQ | 主观 MOS |
|---|---|---|---|
| 是否需要参考信号 | 否 | 是 | 否 |
| 计算复杂度 | 低 | 较高 | 高(需要人力) |
| 适用场景 | 噪声抑制、语音增强等 | 通信网络音质评估 | 任何语音质量评估 |
| 输出维度 | SIG、BAK、OVL | 单一分数 | 单一分数 |
| 实时性 | 高 | 中 | 低 |
优势
- 无参考:无需干净参考语音,可直接用于实际应用场景。
- 高效性:适合实时或大规模语音质量分析。
- 全面性:通过多个维度评估语音质量,结果更具参考价值。
局限性
- 依赖训练数据:DNSMOS 的评估效果依赖于训练数据的质量和多样性。
- 与主观评分的差异:尽管 DNSMOS 的预测值与人类主观评分高度相关,但在特定情况下可能会有偏差。
总结
DNSMOS 是一个专门为语音增强和噪声抑制任务设计的无参考语音质量评估工具。它通过深度学习模型,快速、准确地预测语音质量,并在多个实际场景中展示了其强大的应用价值,是当前语音质量评估领域的重要工具之一。
7. Diarization
Diarization 是指将一段音频中不同的说话人区分开来的过程,也称为 说话人分离 或 说话人分段标注。它在语音处理领域中具有广泛的应用,特别是在多说话人场景下对音频数据的分析和处理中。
Diarization 的核心任务
目标:将音频数据按照说话人划分成不同的时间段,并标注每段音频属于哪个说话人。最终输出的结果是一段时间轴上的说话人标签。
例如,在一段会议录音中,有三位参与者(A、B、C),Diarization 的任务是将音频分段并标注如下:
| 时间段 | 说话人 |
|---|---|
| 0-10秒 | A |
| 10-20秒 | B |
| 20-30秒 | A |
| 30-40秒 | C |
Diarization 的关键步骤
-
音频预处理:
- 对输入的音频进行短时傅里叶变换(STFT)或其他特征提取,生成频谱或语音特征。
-
语音活动检测(VAD, Voice Activity Detection):
- 识别音频中的语音段落,去除沉默、背景噪声和非语音信号。
-
特征提取:
- 提取音频的低维或高维特征,例如 MFCC(梅尔频率倒谱系数)、i-vectors、x-vectors 或 embeddings。
-
分段与聚类:
- 将音频划分成固定长度的短片段。
- 使用聚类算法(如 K-Means 或谱聚类)将相似的音频片段分组,每组对应一个说话人。
-
说话人标注:
- 对每个聚类结果赋予一个唯一的说话人标签。
- 如果有预先标注的说话人信息,可以进一步匹配实际身份。
-
后处理:
- 平滑过渡的分段,避免因算法噪声导致的频繁切换。
- 优化输出时间轴以提升连续性和准确性。
Diarization 的常用算法和工具
1. 基于传统方法:
- PLDA (Probabilistic Linear Discriminant Analysis):
用于计算音频片段之间的相似性并进行聚类。 - HMM (Hidden Markov Model):
模拟说话人状态的时序变化。
2. 基于深度学习的方法:
- x-vectors 和 d-vectors:
提取高维语音嵌入,捕捉说话人特征,用于聚类。 - EEND (End-to-End Neural Diarization):
使用端到端的神经网络模型直接输出说话人分段结果,跳过传统的特征提取和聚类步骤。
3. 开源工具:
- Pyannote.audio:
基于深度学习的语音分段和说话人分离工具。 - Kaldi:
一个强大的语音处理工具包,支持基于 x-vector 的 Diarization。 - Resemblyzer:
提供语音嵌入生成工具,支持聚类和说话人分离。
应用场景
-
会议记录:
- 将会议录音分成不同参与者的语音段落,用于生成自动化会议摘要。
-
多说话人 ASR(自动语音识别):
- 在自动语音识别中,对不同说话人的语音进行分离,以生成独立的转录文本。
-
语音分析:
- 用于分析电话客服录音,分辨客户和客服代表的发言。
-
法律与执法:
- 在证据音频中分离不同说话人,以便进行深入调查。
-
电影和广播:
- 将音频分段,标注角色台词或解说内容。
Diarization 的挑战
-
背景噪声:
- 噪声环境可能干扰语音特征提取。
-
重叠语音:
- 多个说话人同时讲话时,难以准确分离语音段。
-
说话人数量未知:
- 需要动态估计说话人数量,增加算法复杂性。
-
长时音频的处理:
- 长音频的内存需求较大,且可能导致分段间的一致性下降。
总结
Diarization 是语音处理中的重要任务,用于将音频数据按说话人分段并标注身份。它在会议分析、语音助手、客户服务、法律调查等领域中具有重要作用。尽管存在一些技术挑战,但随着深度学习和语音嵌入技术的发展,其准确性和实用性正在不断提升。
相关文章:

初学人工智不理解的名词3
TTS领域的名词 from gpt-4o 在 TTS(文本到语音合成) 领域,以下是 CFM、One-Step 蒸馏 和 ReFlow 的含义和作用的详细解释: 1. CFM(Consistent Flow Matching) Consistent Flow Matching(一致流…...

ADS项目笔记 1. 低噪声放大器LNA天线一体化设计
在传统射频结构的设计中,天线模块和有源电路部分相互分离,两者之间通过 50 Ω 传输线级联,这种设计需要在有源电路和天线之间建立无源网络,包括天线模块的输入匹配网络以及有源电路的匹配网络。这些无源网络不仅增加了系统的插入损…...

J.U.C - 深入解读阻塞队列实现原理源码
文章目录 Pre生产者-消费者模式阻塞队列 vs 普通队列JUC提供的7种适合与不同应用场景的阻塞队列插入操作:添加元素到队列中移除操作:从队列中移除元素。 ArrayBlockingQueue源码解析类结构指定初始容量及公平/非公平策略的构造函数根据已有集合初始化队列…...

【大语言模型学习】LORA微调方法
LORA: Low-Rank Adaptation of Large Language Models 摘要 LoRA (Low-Rank Adaptation) 提出了一种高效的语言模型适应方法,针对预训练模型的适配问题: 目标:减少下游任务所需的可训练参数,降低硬件要求。方法:冻结预训练模型权重,注入低秩分解矩阵,从而在不影响推理…...

Spring Boot【一】
Spring Boot全局配置文件 application.properties 是 Spring Boot 的标准配置文件,用于集中管理应用程序的配置属性。它的主要作用是将配置信息与代码分离,使得应用程序更具可维护性和可配置性。 Application.yaml配置文件 YAML文件格式是JSON超集文件…...

H.265流媒体播放器EasyPlayer.js H.264/H.265播放器chrome无法访问更私有的地址是什么原因
EasyPlayer.js H5播放器,是一款能够同时支持HTTP、HTTP-FLV、HLS(m3u8)、WS、WEBRTC、FMP4视频直播与视频点播等多种协议,支持H.264、H.265、AAC、G711A、MP3等多种音视频编码格式,支持MSE、WASM、WebCodec等多种解码方…...

【大数据学习 | HBASE高级】rowkey的设计,hbase的预分区和压缩
1. rowkey的设计 RowKey可以是任意字符串,最大长度64KB,实际应用中一般为10~100bytes,字典顺序排序,rowkey的设计至关重要,会影响region分布,如果rowkey设计不合理还会出现region写热点等一系列问题。 …...

Dart:字符串
字符串:单双引号 String c hello \c\; // hello c,单引号中使用单引号,需要转义\ String d "hello c"; // hello c,双引号中使用单引号,不需要转义 String e "hello \“c\”"; // hell…...

平衡二叉搜索树之 红黑 树的模拟实现【C++】
文章目录 红黑树的简单介绍定义红黑树的特性红黑树的应用 全部的实现代码放在了文章末尾准备工作包含头文件类的成员变量和红黑树节点的定义 构造函数和拷贝构造swap和赋值运算符重载析构函数findinsert【重要】第一步:按照二叉搜索树的方式插入新节点第二步&#x…...

2:Vue.js 父子组件通信:让你的组件“说话”
上一篇我们聊了如何用 Vue.js 创建一个简单的组件,这次咱们再往前走一步,讲讲 Vue.js 的父子组件通信。组件开发里,最重要的就是让组件之间能够“说话”,数据能流通起来。废话不多说,直接开干! 父组件传数据…...

6. Keepalived配置Nginx自动重启,实现7x24提供服务
一. Keepalived配置Nginx自动重启,实现7x24提供服务 1.编写不停的检查nginx服务器状态,停止并重启,重启失败后则停止keepalived脚本 cd /etc/keepalived/ vim check_nginx_alive_or_not.sh #---内容如下:--------------- #!/bin/bash A=`ps -C nginx --no-header |wc -l...

【PS】蒙版与通道
内容1: 、选择蓝色通道并复制,对复制的蓝色通道ctrli进行反向选择,然后ctrll调整色阶。 、选择载入选区,然后点击rgb。 、点击蒙版 、点击云彩图层调整位置 、点击色相/饱和度,适当调整 、最后使用滤镜等功能添加光圈…...

C++创建型模式之生成器模式
解决的问题 生成器模式(Builder Pattern)主要解决复杂对象的构建问题。当一个对象的创建过程非常复杂,涉及多个步骤和多个部件时,使用生成器模式可以将对象的构建过程与其表示分离,使得同样的构建过程可以创建不同的表…...

鸿蒙NEXT应用示例:切换图片动画
【引言】 在鸿蒙NEXT应用开发中,实现图片切换动画是一项常见的需求。本文将介绍如何使用鸿蒙应用框架中的组件和动画功能,实现不同类型的图片切换动画效果。 【环境准备】 电脑系统:windows 10 开发工具:DevEco Studio NEXT B…...
继承特性和分区实现)
postgresql(功能最强大的开源数据库)继承特性和分区实现
PostgreSQL实现了表继承,在多重表继承下,对上亿条不同类别的数据条目进行按型号、按月份双层分区管理,既可在总表查阅所有条目的共有字段,也可在各类型字表查询附加字段,非常高效。 分区是通过继承的方式来实现的&…...
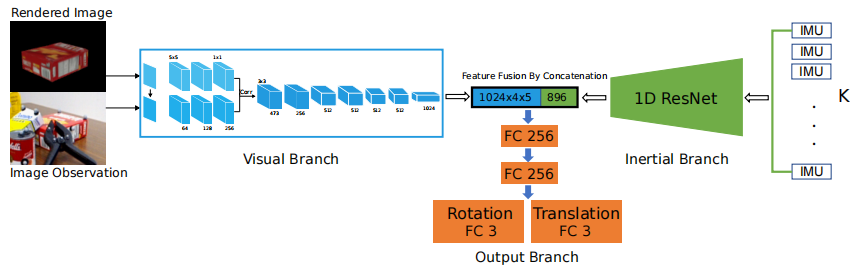
论文笔记(五十六)VIPose: Real-time Visual-Inertial 6D Object Pose Tracking
VIPose: Real-time Visual-Inertial 6D Object Pose Tracking 文章概括摘要I. INTRODACTIONII. 相关工作III. APPROACHA. 姿态跟踪工作流程B. VIPose网络 文章概括 引用: inproceedings{ge2021vipose,title{Vipose: Real-time visual-inertial 6d object pose tra…...

微服务治理详解
文章目录 什么是微服务架构为什么要使用微服务单体架构如何转向微服务架构服务治理服务治理治的是什么服务注册与发现服务熔断降级服务网关服务调用服务负载均衡服务配置中心 微服务解决方案SpringCloud体系EurekaHystrixGatewayOpenFeignRibbonConfig SpringCloud Alibaba体系…...
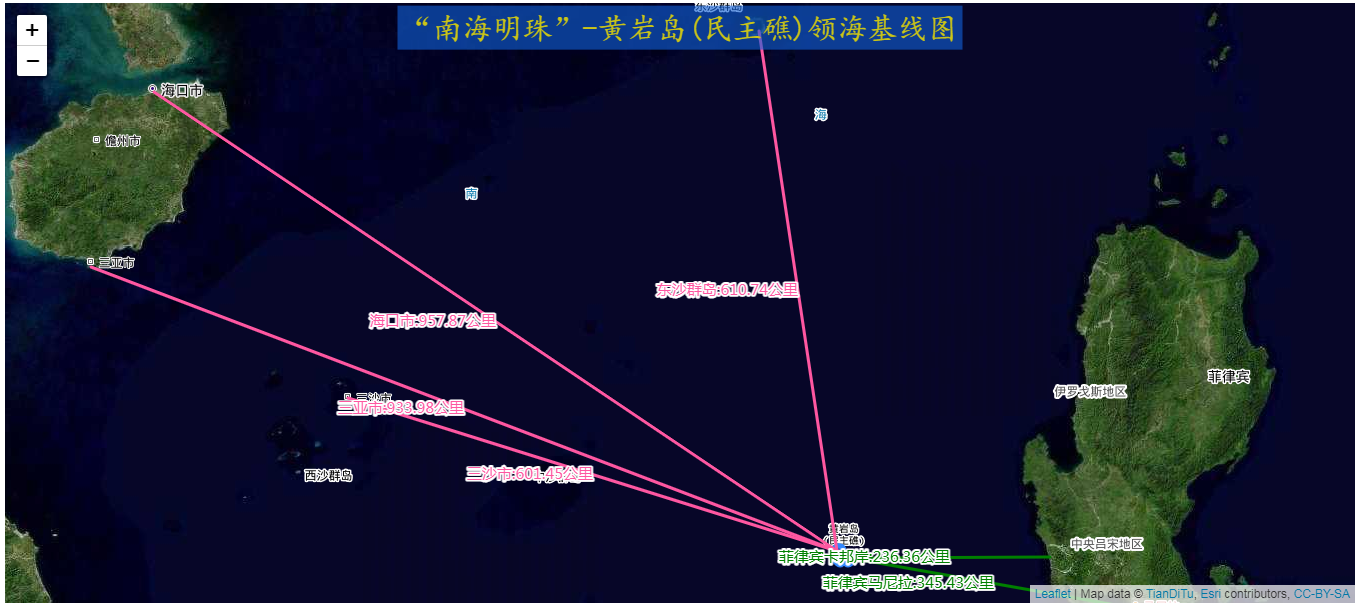
“南海明珠”-黄岩岛(民主礁)领海基线WebGIS绘制实战
目录 前言 一、关于岛屿的基点位置 1、领海基点 二、基点坐标的转换 1、最底层的左边转换 2、单个经纬度坐标点转换 3、完整的转换 三、基于天地图进行WebGIS展示 1、领海基点的可视化 2、重要城市距离计算 四、总结 前言 南海明珠黄岩岛,这座位于南海的…...

Oracle数据库 创建dblink的过程及其用法详解
前言 dblink是Oracle数据库中用于连接不同数据库实例的一种机制。通过dblink,用户可以在一个数据库实例中直接查询或操作另一个数据库实例中的表、视图或存储过程。 dblink的作用主要体现在以下几个方面: 跨数据库操作:允许用户…...

Linux从0——1之shell编程4
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团队无关&a…...
)
别再死记硬背公式了!用Python+NumPy手把手带你仿真RLC串联谐振(附代码)
用PythonNumPy动态仿真RLC串联谐振:告别枯燥公式,直观理解电路本质 当你第一次翻开电路分析教材,看到那些密密麻麻的公式推导和抽象的频率响应曲线时,是否感到一阵眩晕?RLC串联谐振作为电路分析的核心概念,…...

JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯
JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在项目开发的关键时刻,突然看到JetBrains IDE弹出"评估期已结束…...

番茄小说下载器:打造属于你的个人数字图书馆终极指南
番茄小说下载器:打造属于你的个人数字图书馆终极指南 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾经遇到过这样的场景?深夜追更小说时网络突然断线&…...

CircuitPython嵌入式游戏开发:基于TileGrid的迷宫寻蛋与JSON数据持久化实践
1. 项目概述与核心价值如果你和我一样,对嵌入式开发充满热情,同时又对游戏开发抱有好奇心,那么将两者结合——在微控制器上编写一个完整的2D游戏——绝对是一次令人兴奋的挑战。这不仅仅是让LED闪烁或读取传感器数据,而是要在资源…...

AI驱动工作流自动化:从原理到实践,构建智能效率引擎
1. 项目概述:当AI遇上工作流,一场效率革命正在发生最近在GitHub上看到一个名为“WorkflowAI/WorkflowAI”的项目,这个名字本身就充满了想象空间。作为一个长期与各种自动化工具和效率方法论打交道的人,我立刻意识到,这…...

大语言模型可靠性监测与压缩的谱方法研究
1. 大语言模型可靠性监测与压缩的谱方法研究概述在深度学习领域,大语言模型(LLM)和视觉语言模型(VLM)的可靠性问题与计算效率挑战日益凸显。模型幻觉(生成与输入无关或错误的内容)和分布偏移(面对训练数据分布外的输入时性能下降)会严重损害用户信任,而庞…...

Faderwave合成器设计:从波形塑造到数字滤波的嵌入式音频实践
1. 项目概述:从推子到声音,Faderwave合成器的设计哲学如果你玩过硬件合成器,或者对数字音频合成感兴趣,那你肯定知道,声音设计的起点往往是一个简单的波形。但如何让这个波形“活”起来,变成你脑海中那个独…...

多智能体系统架构设计:从核心原理到AgentOrg工程实践
1. 项目概述:从“AgentOrg”看智能体组织架构的工程实践最近在开源社区里看到一个挺有意思的项目,叫“Angelopvtac/AgentOrg”。光看这个名字,可能有点抽象,但如果你正在捣鼓大语言模型应用,尤其是想构建一个能协同工作…...

VR头显立体视觉姿态估计技术解析
1. 自我中心姿态估计的技术挑战与创新思路在虚拟现实和增强现实应用中,准确估计用户在三维空间中的身体姿态是实现自然交互的基础。传统基于外部摄像头的动作捕捉系统虽然精度较高,但存在设备复杂、使用场景受限等问题。相比之下,基于头戴设备…...

从零构建天气预报Web应用:Vue.js与Node.js全栈实战指南
1. 项目概述:一个开源的天气预报应用 最近在GitHub上看到一个挺有意思的项目,叫 fsboy/weather-forecast 。光看名字就知道,这是一个天气预报应用。但如果你以为它只是个简单的天气查询工具,那就太小看它了。这个项目吸引我的地…...