微服务day08
Elasticsearch



需要安装elasticsearch和Kibana,应为Kibana中有一套控制台可以方便的进行操作。
安装elasticsearch
使用docker命令安装:
docker run -d \ --name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ //设置他的运行内存空间,不要低于512否则出问题-e "discovery.type=single-node" \ //设置安装模式,当前为单点模式,而非集群模式。-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network hm-net \-p 9200:9200 \-p 9300:9300 \ //集群通信的端口。elasticsearch:7.12.1安装Kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1
通过kibana向es发送Http请求。
倒排索引



小结:

IK分词器
安装

在线安装:
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip重启:
docker restart es线下安装:
首先,查看之前安装的Elasticsearch容器的plugins数据卷目录:
docker volume inspect es-plugins结果如下:
[{"CreatedAt": "2024-11-06T10:06:34+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data","Name": "es-plugins","Options": null,"Scope": "local"}
]可以看到elasticsearch的插件挂载到了/var/lib/docker/volumes/es-plugins/_data这个目录。我们需要把IK分词器上传至这个目录。
找到课前资料提供的ik分词器插件,课前资料提供了7.12.1版本的ik分词器压缩文件,你需要对其解压:

然后上传至虚拟机的/var/lib/docker/volumes/es-plugins/_data这个目录
重启es容器:
docker restart esIK分词器包含两种模式:
-
ik_smart:智能语义切分 -
ik_max_word:最细粒度切分
POST /_analyze
{"analyzer": "ik_smart","text": "黑马程序员学习java太棒了"
}结果:
{"tokens" : [{"token" : "黑马","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 0},{"token" : "程序员","start_offset" : 2,"end_offset" : 5,"type" : "CN_WORD","position" : 1},{"token" : "学习","start_offset" : 5,"end_offset" : 7,"type" : "CN_WORD","position" : 2},{"token" : "java","start_offset" : 7,"end_offset" : 11,"type" : "ENGLISH","position" : 3},{"token" : "太棒了","start_offset" : 11,"end_offset" : 14,"type" : "CN_WORD","position" : 4}]
}
由于互联网词汇不断增多,需要拓展词汇库。
所以要想正确分词,IK分词器的词库也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:

注意,如果采用在线安装的通过,默认是没有config目录的,需要把课前资料提供的ik下的config上传至对应目录。
在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 *** 添加扩展词典--><entry key="ext_dict">ext.dic</entry>
</properties>在IK分词器的config目录新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改:
传智播客
泰裤辣重启elasticsearch
docker restart es再次测试,可以发现传智播客和泰裤辣都正确分词了:
{"tokens" : [{"token" : "传智播客","start_offset" : 0,"end_offset" : 4,"type" : "CN_WORD","position" : 0},{"token" : "开设","start_offset" : 4,"end_offset" : 6,"type" : "CN_WORD","position" : 1},{"token" : "大学","start_offset" : 6,"end_offset" : 8,"type" : "CN_WORD","position" : 2},{"token" : "真的","start_offset" : 9,"end_offset" : 11,"type" : "CN_WORD","position" : 3},{"token" : "泰裤辣","start_offset" : 11,"end_offset" : 14,"type" : "CN_WORD","position" : 4}]
}总结
分词器的作用是什么?
-
创建倒排索引时,对文档分词
-
用户搜索时,对输入的内容分词
IK分词器有几种模式?
-
ik_smart:智能切分,粗粒度 -
ik_max_word:最细切分,细粒度
IK分词器如何拓展词条?如何停用词条?
-
利用config目录的
IkAnalyzer.cfg.xml文件添加拓展词典和停用词典 -
在词典中添加拓展词条或者停用词条
基础概念


索引库操作
Mapping映射属性

索引库操作
Restful规范

索引库操作

创建索引库:
基本语法:
-
请求方式:
PUT -
请求路径:
/索引库名,可以自定义 -
请求参数:
mapping映射
格式:
PUT /索引库名称
{"mappings": {"properties": {"字段名":{"type": "text","analyzer": "ik_smart"},"字段名2":{"type": "keyword","index": "false"},"字段名3":{"properties": {"子字段": {"type": "keyword"}}},// ...略}}
}实例代码
PUT /hmall
{"mappings": {"properties": {"info":{"type": "text","analyzer": "ik_smart"},"email":{"type": "keyword","index": false},"name":{"properties": {"firstName":{"type":"keyword"},"lastName":{"type":"keyword"}}}}}
}返回结果:
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "hmall"
}查询索引库
基本语法:
-
请求方式:GET
-
请求路径:/索引库名
-
请求参数:无
格式
GET /索引库名实例代码
GET /hmall查询结果:
{"hmall" : {"aliases" : { },"mappings" : {"properties" : {"email" : {"type" : "keyword","index" : false},"info" : {"type" : "text","analyzer" : "ik_smart"},"name" : {"properties" : {"firstName" : {"type" : "keyword"},"lastName" : {"type" : "keyword"}}}}},"settings" : {"index" : {"routing" : {"allocation" : {"include" : {"_tier_preference" : "data_content"}}},"number_of_shards" : "1","provided_name" : "hmall","creation_date" : "1731489076840","number_of_replicas" : "1","uuid" : "KJqNTGY9RhiqFHkliRdGcw","version" : {"created" : "7120199"}}}}
}修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。因此修改索引库能做的就是向索引库中添加新字段,或者更新索引库的基础属性。
语法说明:
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}添加字段:
PUT /hmall/_mapping
{"properties": {"age":{"type": "integer"}}
}返回结果:
{"acknowledged" : true
}删除索引库
语法:
-
请求方式:DELETE
-
请求路径:/索引库名
-
请求参数:无
语法格式
DELETE /索引库名删除库
DELETE /hmall执行结果
{"acknowledged" : true
}
索引库操作总结:
索引库操作有哪些?
-
创建索引库:PUT /索引库名
-
查询索引库:GET /索引库名
-
删除索引库:DELETE /索引库名
-
修改索引库,添加字段:PUT /索引库名/_mapping
可以看到,对索引库的操作基本遵循的Restful的风格,因此API接口非常统一,方便记忆。
文档操作



新增文档
语法规范
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"},
}实例代码
POST /hmall/_doc/1
{"info": "黑马程序员Java讲师","email": "zy@itcast.cn","name": {"firstName": "云","lastName": "赵"}
}运行结果
{"_index" : "hmall","_type" : "_doc","_id" : "1","_version" : 8,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 8,"_primary_term" : 1
}查询文档
语法规范
GET /{索引库名称}/_doc/{id}实例代码
GET /hmall/_doc/1运行结果
{"_index" : "hmall","_type" : "_doc","_id" : "1","_version" : 8,"_seq_no" : 8,"_primary_term" : 1,"found" : true,"_source" : {"info" : "黑马程序员Java讲师","email" : "zy@itcast.cn","name" : {"firstName" : "云","lastName" : "赵"}}
}
删除文档
语法规范
DELETE /{索引库名}/_doc/id值实例代码
DELETE /hmall/_doc/1运行结果
{"_index" : "hmall","_type" : "_doc","_id" : "1","_version" : 9,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 9,"_primary_term" : 1
}
修改文档
全量修改
语法规范
PUT /{索引库名}/_doc/文档id
{"字段1": "值1","字段2": "值2",// ... 略
}实例代码
#全量修改
PUT /hmall/_doc/1
{"info": "黑马程序员Python讲师","email": "ls@itcast.cn","name": {"firstName": "四","lastName": "李"}
}运行结果
第一次运行,由于前面已经删除了该文档所以 执行类型为 created.
{"_index" : "hmall","_type" : "_doc","_id" : "1","_version" : 10,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 10,"_primary_term" : 1
}第二次运行,为修改返回的类型为 updated。
{"_index" : "hmall","_type" : "_doc","_id" : "1","_version" : 11,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 11,"_primary_term" : 1
}部分修改
语法规范
POST /{索引库名}/_update/文档id
{"doc": {"字段名": "新的值",}
}实例代码
#局部修改
POST /hmall/_update/1
{"doc": {"email":"ZhaoYuen@itcast.com"}
}运行结果
{"_index" : "hmall","_type" : "_doc","_id" : "1","_version" : 12,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 12,"_primary_term" : 1
}当前文档的数据:
{"_index" : "hmall","_type" : "_doc","_id" : "1","_version" : 12,"_seq_no" : 12,"_primary_term" : 1,"found" : true,"_source" : {"info" : "黑马程序员Python讲师","email" : "ZhaoYuen@itcast.com","name" : {"firstName" : "四","lastName" : "李"}}
}文档基础操作小结

文档批量处理

-
index代表新增操作-
_index:指定索引库名 -
_id指定要操作的文档id -
{ "field1" : "value1" }:则是要新增的文档内容
-
-
delete代表删除操作-
_index:指定索引库名 -
_id指定要操作的文档id
-
-
update代表更新操作-
_index:指定索引库名 -
_id指定要操作的文档id -
{ "doc" : {"field2" : "value2"} }:要更新的文档字段
-
#批量新增
POST /_bulk
{"index": {"_index":"hmall", "_id": "3"}}
{"info": "黑马程序员C++讲师", "email": "ww@itcast.cn", "name":{"firstName": "五", "lastName":"王"}}
{"index": {"_index":"hmall", "_id": "4"}}
{"info": "黑马程序员前端讲师", "email": "zhangsan@itcast.cn", "name":{"firstName": "三", "lastName":"张"}}POST /_bulk
{"delete":{"_index":"hmall", "_id": "3"}}
{"delete":{"_index":"hmall", "_id": "4"}}JavaRestClient
作用:向restful接口发送请求。
客户端初始化

1)在item-service模块中引入es的RestHighLevelClient依赖:
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>2)因为SpringBoot默认的ES版本是7.17.10,所以我们需要覆盖默认的ES版本:
<properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target><elasticsearch.version>7.12.1</elasticsearch.version></properties>3)初始化RestHighLevelClient:
初始化的代码如下:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.150.101:9200")
));4)创建一个测试用例来实现
package com.hmall.item.es;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;import java.io.IOException;public class Test {private RestHighLevelClient client;//创建开始初始化函数,对客户端进行初始化@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.21.101:9200")));}//测试代码@org.junit.jupiter.api.Testpublic void test(){System.out.println(client);}//测试用例结束后释放资源@AfterEachvoid tearDown() throws IOException {client.close();}
}商品Mapping映射
分析那些字段需要添加到文档中。

根据分析编写的需求:
PUT /hmall
{"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "ik_smart"},"price":{"type": "integer"},"image":{"type": "keyword","index": false},"category":{"type": "keyword"},"brand":{"type": "keyword"},"sold":{"type": "integer"},"commentCount":{"type": "integer","index": false},"isAD":{"type": "boolean"},"updateTime":{"type": "date"}}}
}索引库操作
创建索引库:

//创建索引库@org.junit.jupiter.api.Testpublic void testCreateIndex() throws IOException {//创建Requst对象CreateIndexRequest request = new CreateIndexRequest("items");//准备参数 ,将编写的JSON字符串赋值给MAPPINF_JSON,XContentType.JSON用于指定是JSON格式request.source(MAPPINF_JSON, XContentType.JSON);//发送请求,RequestOptions.DEFAULT为是否有自定义配置,选择默认client.indices().create(request, RequestOptions.DEFAULT);}private final String MAPPINF_JSON = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_smart\"\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"image\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"category\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"sold\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"commentCount\":{\n" +" \"type\": \"integer\",\n" +" \"index\": false\n" +" },\n" +" \"isAD\":{\n" +" \"type\": \"boolean\"\n" +" },\n" +" \"updateTime\":{\n" +" \"type\": \"date\"\n" +" }\n" +" }\n" +" }\n" +"}";删除索引库

//删除索引库@org.junit.jupiter.api.Testpublic void testDeleteIndex() throws IOException {//创建Requst对象DeleteIndexRequest request = new DeleteIndexRequest("items");//发送请求client.indices().delete(request,RequestOptions.DEFAULT);}查看索引库

//查找索引库@org.junit.jupiter.api.Testpublic void testGetIndex() throws IOException {//创建Requst对象GetIndexRequest request = new GetIndexRequest("items");//发送2请求
// client.indices().get(request, RequestOptions.DEFAULT);//由于GEt请求返回的数据较多,如果只需要判断是否存在,则使用exists方法boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);System.out.println("exists = " + exists);}文档操作
新增文档
由于索引库结构与数据库结构还存在一些差异,因此我们要定义一个索引库结构对应的实体。
package com.hmall.item.domain.po;import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;import java.time.LocalDateTime;@Data
@ApiModel(description = "索引库实体")
public class ItemDoc{@ApiModelProperty("商品id")private String id;@ApiModelProperty("商品名称")private String name;@ApiModelProperty("价格(分)")private Integer price;@ApiModelProperty("商品图片")private String image;@ApiModelProperty("类目名称")private String category;@ApiModelProperty("品牌名称")private String brand;@ApiModelProperty("销量")private Integer sold;@ApiModelProperty("评论数")private Integer commentCount;@ApiModelProperty("是否是推广广告,true/false")private Boolean isAD;@ApiModelProperty("更新时间")private LocalDateTime updateTime;
}API语法
POST /{索引库名}/_doc/1
{"name": "Jack","age": 21
}
可以看到与索引库操作的API非常类似,同样是三步走:
-
1)创建Request对象,这里是
IndexRequest,因为添加文档就是创建倒排索引的过程 -
2)准备请求参数,本例中就是Json文档
-
3)发送请求
变化的地方在于,这里直接使用client.xxx()的API,不再需要client.indices()了。
//新增文档@org.junit.jupiter.api.Testpublic void test() throws IOException {//读取数据库获取商品信息Item item = service.getById(317578);//将商品信息对象转换为DtoItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);//将对象转换为JSONString jsonStr = JSONUtil.toJsonStr(itemDoc);//创建Requst对象IndexRequest request = new IndexRequest("items").id(itemDoc.getId());request.source(jsonStr, XContentType.JSON);//发送信息client.index(request, RequestOptions.DEFAULT);}



package com.hmall.item.es;import cn.hutool.core.bean.BeanUtil;
import cn.hutool.json.JSONUtil;
import com.hmall.item.domain.dto.ItemDoc;
import com.hmall.item.domain.po.Item;
import com.hmall.item.service.impl.ItemServiceImpl;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;
@SpringBootTest(properties = {"spring.profiles.active=local"})
public class docTest {private RestHighLevelClient client;@Autowiredprivate ItemServiceImpl service;//创建开始初始化函数,对客户端进行初始化@BeforeEachvoid setUp() {this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.21.101:9200")));}//新增文档,全局修改文档@org.junit.jupiter.api.Testpublic void test() throws IOException {//读取数据库获取商品信息Item item = service.getById(317578);//将商品信息对象转换为DtoItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);//将对象转换为JSONString jsonStr = JSONUtil.toJsonStr(itemDoc);//创建Requst对象IndexRequest request = new IndexRequest("items").id(itemDoc.getId());request.source(jsonStr, XContentType.JSON);//发送信息client.index(request, RequestOptions.DEFAULT);}//查看文档@org.junit.jupiter.api.Testpublic void testGet() throws IOException {//创建Requst对象GetRequest request = new GetRequest("items","317578");//发送信息GetResponse response = client.get(request, RequestOptions.DEFAULT);String json = response.getSourceAsString();ItemDoc bean = JSONUtil.toBean(json, ItemDoc.class);System.out.println("bean = " + bean);}//删除文档@org.junit.jupiter.api.Testpublic void testdelect() throws IOException {//创建Requst对象DeleteRequest request = new DeleteRequest("items","317578");//发送信息client.delete(request, RequestOptions.DEFAULT);}//修改文档@org.junit.jupiter.api.Testpublic void testupdata2() throws IOException {//创建Requst对象UpdateRequest request = new UpdateRequest("items","317578");//数据都是独立的不是成对出现的request.doc("price", 10000);//发送信息client.update(request, RequestOptions.DEFAULT);}//测试用例结束后释放资源@AfterEachvoid tearDown() throws IOException {client.close();}}批量操作文档

//新增文档,全局修改文档@org.junit.jupiter.api.Testpublic void testBulk() throws IOException {//设置分页信息int size = 1000,pageNo = 1;//循环写入数据while (true){//读取数据库获取商品信息分页查询//设置当前查询条件,即状态为起售//创建分页对象Page<Item> page = service.lambdaQuery().eq(Item::getStatus, 1).page(new Page<Item>(pageNo, size));List<Item> records = page.getRecords();//判空if (records.isEmpty()||records == null){return;}//创建Requst对象
// BulkRequest request = new BulkRequest();
// for (Item item : records) {
// request.add(new IndexRequest("items")
// .id(item.getId().toString())
// .source(JSONUtil.toJsonStr(BeanUtil.copyProperties(item, ItemDoc.class))),XContentType.JSON
// );
// }BulkRequest request = new BulkRequest("items");for (Item item : records) {// 2.1.转换为文档类型ItemDTOItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);// 2.2.创建新增文档的Request对象request.add(new IndexRequest().id(itemDoc.getId()).source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON));}//发送信息client.bulk(request, RequestOptions.DEFAULT);pageNo++;}}相关文章:
微服务day08
Elasticsearch 需要安装elasticsearch和Kibana,应为Kibana中有一套控制台可以方便的进行操作。 安装elasticsearch 使用docker命令安装: docker run -d \ --name es \-e "ES_JAVA_OPTS-Xms512m -Xmx512m" \ //设置他的运行内存空间&#x…...

JAVA接入WebScoket行情接口
Java脚好用的库很多,开发效率一点不输Python。如果是日内策略,需要更实时的行情数据,不然策略滑点太大,容易跑偏结果。 之前爬行情网站提供的level1行情接口,实测平均更新延迟达到了6秒,超过10只股票并发请…...

使用Axios函数库进行网络请求的使用指南
目录 前言1. 什么是Axios2. Axios的引入方式2.1 通过CDN直接引入2.2 在模块化项目中引入 3. 使用Axios发送请求3.1 GET请求3.2 POST请求 4. Axios请求方式别名5. 使用Axios创建实例5.1 创建Axios实例5.2 使用实例发送请求 6. 使用async/await简化异步请求6.1 获取所有文章数据6…...

Vue2+ElementUI:用计算属性实现搜索框功能
前言: 本文代码使用vue2element UI。 输入框搜索的功能,可以在前端通过计算属性过滤实现,也可以调用后端写好的接口。本文介绍的是通过计算属性对表格数据实时过滤,后附完整代码,代码中提供的是死数据,可…...

抖音热门素材去哪找?优质抖音视频素材网站推荐!
是不是和我一样,刷抖音刷到停不下来?越来越多的朋友希望在抖音上创作出爆款视频,但苦于没有好素材。今天就来推荐几个超级实用的抖音视频素材网站,让你的视频内容立刻变得高大上!这篇满是干货,直接上重点&a…...

spring-cache concurrentHashMap 自定义过期时间
1.自定义实现缓存构建工厂 import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.ConcurrentMap;import lombok.Getter; import lombok.Setter; import org.springframework.beans.factory.BeanNameAware; import org.springframework.beans.factory.…...

解析传统及深度学习目标检测方法的原理与具体应用之道
深度学习目标检测算法 常用的深度学习的目标检测算法及其原理和具体应用方法: R-CNN(Region-based Convolutional Neural Networks)系列1: 原理: 候选区域生成:R-CNN 首先使用传统的方法(如 Se…...

shell数组
文章目录 🍊自我介绍🍊shell数组概述🍊Shell数组使用方法数组的定义直接定义单元素定义 元素的获取获取单个元素获取全部元素 获取数组长度获取整个数组长度获取单个元素的长度 操作数组增加删除 关联数组 🍊 你的点赞评论就是对博…...

高斯混合模型回归(Gaussian Mixture Model Regression,GMM回归)
高斯混合模型(GMM)是一种概率模型,它假设数据是由多个高斯分布的混合组成的。在高斯混合回归中,聚类与回归被结合成一个联合模型: 聚类部分 — 使用高斯混合模型进行聚类,识别数据的不同簇。回归部分 — 对…...

【3D Slicer】的小白入门使用指南八
3D Slicer DMRI(Diffusion MRI)-扩散磁共振认识和使用 0、简介 大脑解剖 ● 白质约占大脑的 45% ● 有髓神经纤维(大约10微米轴突直径) 白质探索 朱尔斯约瑟夫德杰林(Jules Joseph Dejerine,《神经中心解剖学》(巴黎,1890-1901):基于髓磷脂染色标本的神经解剖图谱)…...

【流量分析】常见webshell流量分析
免责声明:本文仅作分享! 对于常见的webshell工具,就要知攻善防;后门脚本的执行导致webshell的连接,对于默认的脚本要了解,才能更清晰,更方便应对。 (这里仅针对部分后门代码进行流量…...

基于树莓派的边缘端 AI 目标检测、目标跟踪、姿态估计 视频分析推理 加速方案:Hailo with ultralytics YOLOv8 YOLOv11
文件大纲 加速原理硬件安装软件安装基本设置系统升级docker 方案Demo 测试目标检测姿态估计视频分析参考文献前序树莓派文章hailo加速原理 Hailo 发布的 Raspberry Pi AI kit 加速原理,有几篇文章介绍的不错 https://ubuntu.com/blog/hackers-guide-to-the-raspberry-pi-ai-ki…...

Java在算法竞赛中的常用方法
在算法竞赛中,Java以其强大的标准库和高效的性能成为了众多参赛者的首选语言。本文将详细介绍Java在算法竞赛中的常用集合、字符串处理、进制转换、大数处理以及StringBuilder的使用技巧,帮助你在竞赛中更加得心应手。 常用集合 Java的集合框架提供了多…...
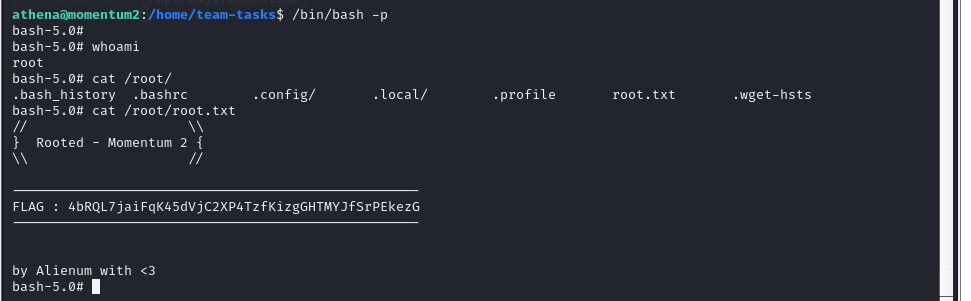
Vulnhub靶场案例渗透[10]- Momentum2
文章目录 一、靶场搭建1. 靶场描述2. 下载靶机环境3. 靶场搭建 二、渗透靶场1. 确定靶机IP2. 探测靶场开放端口及对应服务3. 扫描网络目录结构4. 代码审计5. 反弹shell6. 提权 一、靶场搭建 1. 靶场描述 - Difficulty : medium - Keywords : curl, bash, code reviewThis wor…...

Spark RDD中常用聚合算子源码层面的对比分析
在 Spark RDD 中,groupByKey、reduceByKey、foldByKey 和 aggregateByKey 是常用的聚合算子,适用于按键进行数据分组和聚合。它们的实现方式各不相同,涉及底层调用的函数也有区别。以下是对这些算子在源码层面的分析,以及每个算子…...

计算机网络 (6)物理层的基本概念
前言 计算机网络物理层是OSI模型(开放式系统互联模型)中的第一层,也是七层中的最底层,它涉及到计算机网络中数据的物理传输。 一、物理层的主要任务和功能 物理层的主要任务是处理物理传输介质上的原始比特流,确保数据…...
)
快速上手:Docker 安装详细教程(适用于 Windows、macOS、Linux)
### 快速上手:Docker 安装详细教程(适用于 Windows、macOS、Linux) --- Docker 是一款开源容器化平台,广泛应用于开发、测试和部署。本文将为您提供分步骤的 Docker 安装教程,涵盖 Windows、macOS 和 Linux 系统。 …...

kafka消费者出现频繁Rebalance
kafka消费者在正常使用过程中,突然出现了不消费消息的情况,项目里是使用了多个消费者消费不同数据,按理不会相互影响,看日志,发现消费者出现了频繁的Rebalance。 Rebalance的触发条件 组成员发生变更(新consumer加入组…...
rk3399开发环境使用Android 10初体验蓝牙功能
版本 日期 作者 变更表述 1.0 2024/11/10 于忠军 文档创建 零. 前言 由于Bluedroid的介绍文档有限,以及对Android的一些基本的知识需要了(Android 四大组件/AIDL/Framework/Binder机制/JNI/HIDL等),加上需要掌握的语言包括Java/C/C等࿰…...

ASP.NET 部署到IIS,访问其它服务器的共享文件 密码设定
asp.net 修改上面的 IIS需要在 配置文件 添加如下内容 》》》web.config <system.web><!--<identity impersonate"true"/>--><identity impersonate"true" userName"您的账号" password"您的密码" /><co…...

Purpur性能调优实战指南:7大核心优化方案深度解析
Purpur性能调优实战指南:7大核心优化方案深度解析 【免费下载链接】Purpur Purpur is a drop-in replacement for Paper servers designed for configurability, and new fun and exciting gameplay features. 项目地址: https://gitcode.com/gh_mirrors/pu/Purpu…...

GEO优化实操框架:GEO优化的正确姿势是“带着答案去找客户”
如果你是B2B企业的老板或市场负责人,你一定听过这句话: “我们网上曝光是不少,但来的询盘都不对——问价格的比问方案的还多,还有不少是学生做调研的。” 这不是你一个人遇到的问题。这是传统SEO和竞价广告的天然缺陷——你只能“…...

Netgear路由器急救指南:nmrpflash如何让变砖设备重获新生
Netgear路由器急救指南:nmrpflash如何让变砖设备重获新生 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你心爱的Netgear路由器因为固件升级失败、意外断电或其他原因变成一块"砖头&q…...

mnestra:基于ESBuild的极简前端构建工具,速度与体验的完美平衡
1. 项目概述:一个被低估的现代前端构建工具如果你在前端开发领域摸爬滚打超过五年,大概率经历过从 Grunt、Gulp 到 Webpack 的构建工具变迁史。每次工具的迭代,都伴随着配置文件的日益复杂和构建速度的微妙下降。当 Vite 携 ES Module 原生支…...

攻克R与Python的壁垒:Giotto空间转录组分析环境一站式搭建指南
1. 为什么你的Giotto安装总是失败? 每次看到空间转录组数据就手痒想用Giotto分析,结果安装环节就被劝退?这可能是大多数生物信息学新手都会遇到的尴尬。作为一个在生信领域摸爬滚打多年的"环境配置工程师",我太理解这种…...

罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性
罗技PUBG鼠标宏终极教程:告别压枪烦恼,轻松提升射击稳定性 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求…...

3个维度深度解析:UABEA如何重塑Unity资源处理生态
3个维度深度解析:UABEA如何重塑Unity资源处理生态 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity游戏开发和资源处理的复杂生态中,开发者常常面临一个核心挑战…...
.name()到可读类型名)
C++运行时类型识别实战:从typeid().name()到可读类型名
1. 为什么我们需要关心运行时类型识别? 在C开发中,我们经常会遇到需要知道某个变量或表达式具体类型的情况。特别是在调试复杂代码、编写泛型程序或进行元编程时,能够准确获取类型信息就显得尤为重要。想象一下,当你看到一个日志输…...

AI驱动工作流自动化:从原理到实践,构建智能效率引擎
1. 项目概述:当AI遇上工作流,一场效率革命正在发生最近在GitHub上看到一个名为“WorkflowAI/WorkflowAI”的项目,这个名字本身就充满了想象空间。作为一个长期与各种自动化工具和效率方法论打交道的人,我立刻意识到,这…...

数据分析师能力展示:从项目构建到报告呈现的完整指南
1. 项目概述:一个数据分析师的能力展示平台最近在GitHub上看到一个挺有意思的项目,叫“dataanalyst-showcase”。光看名字,你可能会觉得这又是一个数据科学项目合集,但点进去仔细研究后,我发现它的定位非常精准——它不…...