使用 PyTorch-BigGraph 构建和部署大规模图嵌入的完整教程
当涉及到图数据时,复杂性是不可避免的。无论是社交网络中的庞大互联关系、像 Freebase 这样的知识图谱,还是推荐引擎中海量的数据量,处理如此规模的图数据都充满挑战。
尤其是当目标是生成能够准确捕捉这些关系本质的嵌入表示时,更需要一种不会在庞大数据量下崩溃的解决方案。
PyTorch-BigGraph (PBG) 正是为应对这一挑战而设计的。它从一开始就被设计为能够在多个 GPU 或节点上无缝扩展。该工具利用高效的分区技术,将庞大的图分解为可管理的部分,使得处理和嵌入数十亿的实体和边成为可能。
通过使用 PBG 生成的嵌入,可以在一个紧凑的向量空间中表示高维、复杂的关系,这使得节点分类、链接预测和聚类等下游任务变得高效且可行。
以下是一些PyTorch-BigGraph实际应用:
-
社交网络:处理拥有数十亿用户和数万亿连接的 Facebook 社交图。使用 PBG,可以创建捕捉用户行为和亲和力的嵌入,这对于推荐、广告定位等应用至关重要。
-
推荐系统:PBG 能够处理庞大的推荐数据集,生成捕捉细微关系的嵌入,非常适合用于个性化内容或产品推荐。
-
知识图谱:在搜索引擎等应用中,知识图谱表示实体及其关系。使用 PBG 对这些数据进行嵌入,可以进行链接预测,增强相关信息的发现。

本文将介绍设置、训练和扩展 PyTorch-BigGraph 模型的实用知识。你可以了解到如何在生产环境中部署 PBG,并针对您的特定数据需求进行优化。让我们开始吧!
安装和设置
现在,让我们谈谈如何启动和运行PyTorch-BigGraph。
设置PyTorch-BigGraph并不复杂,但如果正在使用GPU或多GPU环境,有一些技术方面需要优化。建议设置一个专用的Python环境(使用virtualenv或conda)以避免依赖冲突,特别是如果你正在使用特定的CUDA版本。
设置环境:
conda create -n pytorch-biggraph python=3.8
conda activate pytorch-biggraph
配置GPU/CUDA支持:检查系统的CUDA版本,并安装相应的PyTorch版本。
# 如果您有兼容的GPU,请安装支持CUDA的PyTorch
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
库安装
接下来安装PyTorch-BigGraph:
# 安装PBG库
!pip install torch-biggraph
数据集准备
PyTorch-BigGraph要求数据采用特定格式——通常是TSV(制表符分隔值)或二进制文件。为了使这一过程顺利进行,需要预先准备数据,特别是正在处理大型稀疏图时。
虽然可以使用公开数据集,如Open Graph Benchmark(OGB),但为了介绍完整的流程,我们假设有一个自定义数据集。然后将数据转换为PBG所需的格式。PBG期望有一个边列表,其中每条边连接两个节点(实体),并且可以选择具有关系类型。对于大型数据集,需要对数据进行分区,以便在GPU之间有效分配。
数据格式化
数据准备的第一步是格式化。PBG期望您的数据为TSV格式,具有特定的列用于源节点、目标节点和关系。这种格式让PBG知道图中的节点是如何连接的。
数据格式化示例代码
import pandas as pd def format_data(df): """ 将DataFrame格式化为与PyTorch-BigGraph兼容的TSV格式。 参数: df (pd.DataFrame): 至少包含节点和边的两列的DataFrame。 返回: 无(写入TSV文件) """ # 假设DataFrame具有'source'、'target'、'relation'列 df[['source', 'target', 'relation']].to_csv("graph_data.tsv", sep='\t', index=False, header=False) print("数据已格式化并保存为'graph_data.tsv'。") # 示例用法
data = {'source': [1, 2, 3], 'target': [4, 5, 6], 'relation': ['follows', 'likes', 'shares']}
df = pd.DataFrame(data)
format_data(df)
图分区
对于大规模图,分区对于分布式处理至关重要。PBG可以图分割成多个部分(分区),从而在多个GPU或机器上高效处理。
以下是有效分区图的方法:
from torchbiggraph.config import parse_config
from torchbiggraph.partitionserver import start_partition_server config = parse_config("config.json") # 启动分区服务器(通常在单独的实例上运行)
start_partition_server(config)
提示:根据环境中的GPU或机器数量调整分区数量。分区过少会导致瓶颈,而分区过多可能会使系统因小而低效的任务而过载。
节点和边的准备
数据格式化后,需要确保节点和边已准备好进行处理。PBG期望每个节点和边类型都有唯一的标识符。以下是预处理节点和边的代码片段:
def prepare_nodes_and_edges(df): """ 通过为每个实体创建唯一ID来准备节点和边。 参数: df (pd.DataFrame): 包含'source'和'target'列的DataFrame。 返回: dict: 实体到唯一ID的映射。 """ nodes = set(df['source']).union(set(df['target'])) node_mapping = {node: idx for idx, node in enumerate(nodes)} print("节点和边的准备已完成。") return node_mapping # 示例用法
node_mapping = prepare_nodes_and_edges(df)
有了这些,就可以将数据输入PyTorch-BigGraph并开始构建嵌入。
PyTorch-BigGraph的配置
在配置PyTorch-BigGraph(PBG)时,主要就是定义指导嵌入过程的基本参数。
深入了解配置文件
PBG要求定义实体和关系的路径、批处理大小、训练周期和检查点等参数。每个参数都在PBG如何处理图数据中起着重要作用。
以下是关键参数及其控制内容的概述:
**entity_path**:这是PBG查找节点(实体)数据的路径。可以将其视为图连接中的“谁”的来源。**relation_path**:类似于entity_path,这是关系(边)数据的路径,指定实体如何连接。**checkpoint_path**:训练期间保存模型检查点的文件夹。检查点允许您在中断时恢复训练,并作为备份以避免从头开始重新训练。**dimension**:设置嵌入空间的维度。更高的维度可以捕捉更复杂的关系,需要在内存和计算上有权衡。**num_epochs**训练周期的数量。虽然这取决于数据大小,但建议从10开始,并根据性能进行调整。**batch_size**:控制在单个批处理中处理的边的数量。较大的批处理大小可以提高训练速度,但在较小的GPU上可能会导致内存问题。**eval_fraction**:保留用于评估的数据比例,有助于在训练过程中监控模型性能。
让我们通过一个示例配置文件将这些参数放在上下文中:
config = dict( entity_path="data/entities", relation_path="data/relations", checkpoint_path="models/checkpoints", dimension=200, # 更高的维度用于更复杂的关系 num_epochs=10, # 根据数据集的实验设置 batch_size=10000, # 根据硬件能力进行调整 eval_fraction=0.1, # 使用10%的数据进行评估 num_partitions=4, # 根据图的大小和可用的GPU数量 num_gpus=2, # 如果使用多GPU设置,指定GPU数量 bucket_order="random" # 控制数据桶的处理顺序
)
参数优化
为什么要优化这些特定参数呢?原因如下:
1. `num_partitions`:将图分成分区可以实现分布式训练。对于非常大的数据集,可能需要4-8个分区。更多的分区意味着更复杂的协调,因此根据硬件进行调整。
2. `num_gpus:如果使用多个GPU,请指定此参数。数量越多,处理的分布越广,但每个GPU应有足够的内存来处理批处理大小。
3. `bucket_order`:确定处理数据“桶”的顺序。`random`顺序通常适用于复杂图,因为它确保每个批次的数据暴露多样化。
4. `dimension`:找到合适的维度是一种平衡。对于大多数应用,建议从100-200开始,如果处理非常复杂的图结构,可以增加。
训练嵌入模型
配置设置好后,就可以开始训练过程了。这是PBG真正将图数据转化为嵌入的地方。
模型初始化
要使用配置初始化模型,首先需要将配置文件保存为JSON,然后加载到PBG中。
import json
from torchbiggraph.config import ConfigSchema
from torchbiggraph.train import train # 将配置保存为JSON文件
with open("config.json", "w") as f: json.dump(config, f) # 使用配置初始化并训练模型
train(config_path="config.json")
训练循环
在大型图上进行训练可能会消耗大量硬件资源,因此优化循环至关重要。以下是一个使用多GPU支持的train示例循环:
def train_model(config_path, num_gpus): if num_gpus > 1: # 对于多GPU设置 torch.distributed.init_process_group(backend="nccl") train(config_path=config_path) # 运行训练
train_model("config.json", num_gpus=2)
提示:使用集群,每个节点可以处理一部分分区,从而实现跨节点的并行训练。
实时监控
在大型图上进行训练可能需要时间,因此需要密切监控资源使用情况。使用PyTorch实用程序,如torch.cuda.memory_allocated()或第三方工具,如nvidia-smi进行实时监控。
import torch # 监控GPU内存使用情况的示例代码
print("GPU内存使用情况:", torch.cuda.memory_allocated())
第三方工具如TensorBoard也有助于跟踪损失、准确性和其他训练统计数据随时间的变化。
检查点策略
在长时间的训练过程中,PBG的内置检查点定期保存模型进度。如果训练中断,可以在不丢失所有进度的情况下恢复。
from torchbiggraph.checkpoint import save_checkpoint # 示例:在每个周期保存一个检查点
for epoch in range(config['num_epochs']): # 执行训练步骤 save_checkpoint(config['checkpoint_path'], model_state) print(f"检查点已保存,周期 {epoch}")
高级优化技术
有了基本的训练,下面我们就需要看看如何进行优化。对于非常大的图,需要一些技术来保持内存和计算使用情况在可控范围内。
内存优化
在巨大的图上训练嵌入时,内存通常成为主要瓶颈。为了解决这个问题,可以利用稀疏数据表示和分区训练,其中每个GPU一次只处理一部分数据。
1. **分区训练**:将图分解为较小的块,每个块单独处理。这减少了每个GPU上的内存占用。
2. **稀疏张量**:如果图非常稀疏,可以使用稀疏张量来节省内存。但是PBG目前不直接支持稀疏张量,因此对于非常稀疏的数据集,可能需要自定义处理。
扩展技术
在使用多个节点或GPU时,分布式训练是必不可少的。以下是启动多节点训练运行的代码片段。需要配置PyTorch的distributed包以进行多节点设置。
import torch.distributed as dist def distributed_training(): dist.init_process_group(backend='nccl') # 现在使用分布式后端进行正常训练 train(config_path="config.json") # 启动分布式训练
distributed_training()
超参数调优
优化超参数可以显著提高模型性能。像Optuna这样的库可以自动化超参数调优,以最少的手动努力找到最佳设置,但是记住,超参数调优需要个更多的训练时间
import optuna def objective(trial): # 采样要调优的超参数 batch_size = trial.suggest_int("batch_size", 1000, 10000) dimension = trial.suggest_int("dimension", 50, 300) learning_rate = trial.suggest_loguniform("learning_rate", 1e-5, 1e-1) config['batch_size'] = batch_size config['dimension'] = dimension config['lr'] = learning_rate # 使用新超参数训练模型 train_model("config.json", config['num_gpus']) # 返回用于优化的评估指标 return evaluate_model(config['checkpoint_path']) # 运行超参数优化
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=50)
通过使用Optuna,可以快速探索超参数空间,并为特定数据集识别最佳配置。
评估和微调
训练完成后,可以使用一些标准来量化嵌入的整体质量以及特定的链接预测或实体相似性。
嵌入质量评估
我们如何知道嵌入是否好?一些标准指标可以提供嵌入质量的见解,特别是在排名和最近邻评估方面。
1. **平均倒数排名(MRR)**:此指标广泛用于链接预测任务。它通过在可能的边中将真实连接(边)排名较高时分配更高的分数来评估排名质量。
2. **Hits@K**:这是另一个用于排名任务的流行指标。Hits@K计算正确链接出现在前K个位置的频率,K通常设置为1、3或10。
3. **最近邻评估**:这涉及找到给定节点的最相似嵌入,并查看它们是否属于正确的关系类别。
4. **边预测**:边预测测试嵌入在图中预测未见边或链接的准确性。这在推荐和知识图谱应用中特别有用。
以下是评估嵌入的MRR和Hits@K的示例代码片段:
import numpy as np def evaluate_embeddings(embeddings, test_data): """ 使用平均倒数排名(MRR)和Hits@K评估嵌入。 参数: embeddings (dict): 节点嵌入的字典。 test_data (list): 测试边的列表,形式为(source, target)。 返回: dict: MRR和Hits@K分数。 """ mrr = 0 hits_at_k = {1: 0, 3: 0, 10: 0} for source, target in test_data: source_emb = embeddings[source] target_emb = embeddings[target] # 计算与所有其他节点的相似性 similarities = {node: np.dot(source_emb, embeddings[node]) for node in embeddings} ranked_nodes = sorted(similarities, key=similarities.get, reverse=True) rank = ranked_nodes.index(target) + 1 mrr += 1 / rank for k in hits_at_k.keys(): if rank <= k: hits_at_k[k] += 1 num_edges = len(test_data) mrr /= num_edges hits_at_k = {k: hits / num_edges for k, hits in hits_at_k.items()} return {"MRR": mrr, "Hits@K": hits_at_k}
参数调整
提高嵌入质量通常涉及调整嵌入维度、周期和学习率:
- 嵌入维度:更高的维度可以捕捉更复杂的模式,但在某个点之后收益递减。建议从200左右开始,并根据数据集进行增量实验。
- 周期:周期过少可能导致模型欠拟合;周期过多则可能导致过拟合。监控每个周期的评估指标以找到理想的停止点。
- 学习率:调整学习率可以显著影响收敛。如果模型振荡,请降低学习率;如果速度太慢,请考虑增加学习率。
与其他嵌入的比较
要衡量PyTorch-BigGraph嵌入相对于其他嵌入的效果,可以使用t-SNE或UMAP等可视化技术。以下是使用t-SNE可视化嵌入的快速代码片段。
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt def visualize_embeddings(embeddings): """ 使用t-SNE可视化嵌入。 参数: embeddings (dict): 节点嵌入的字典。 返回: 无 """ nodes = list(embeddings.keys()) emb_matrix = np.array([embeddings[node] for node in nodes]) tsne = TSNE(n_components=2, perplexity=30) emb_2d = tsne.fit_transform(emb_matrix) plt.figure(figsize=(10, 10)) plt.scatter(emb_2d[:, 0], emb_2d[:, 1], alpha=0.7) plt.title("嵌入的t-SNE可视化") plt.show() # 示例用法
visualize_embeddings(embeddings)
在这个二维空间中比较不同模型的嵌入的分布和聚类可以提供有价值的定性见解。
部署和推理
在评估嵌入后,下一步是将它们部署到实际使用中。无论是用于实时推荐还是批量预测,都需要一种高效的方式来提供和查询嵌入。
提供嵌入
为了快速检索,Redis是一个很好的选择。Redis可以将嵌入存储为键值对,其中节点是键,嵌入是值。
import redis def deploy_embeddings(embeddings, redis_host="localhost", redis_port=6379): """ 将嵌入存储在Redis中以便快速检索。 参数: embeddings (dict): 节点嵌入的字典。 redis_host (str): Redis服务器主机名。 redis_port (int): Redis服务器端口。 返回: 无 """ r = redis.Redis(host=redis_host, port=redis_port) for node, emb in embeddings.items(): r.set(node, np.array2string(emb, separator=',')) print("嵌入已部署到Redis。") # 将嵌入部署到Redis
deploy_embeddings(embeddings)
实时推理
如果是一个推荐系统,则需要进行实时的处理。对于实时推理需要从Redis中提取相关嵌入,实时计算相似性,并提供推荐。以下是一个简化的示例:
def recommend_items(user_embedding, redis_conn, top_k=5): """ 根据用户嵌入相似性推荐项目。 参数: user_embedding (np.array): 用户或源节点的嵌入。 redis_conn (Redis): Redis连接对象。 top_k (int): 推荐数量。 返回: list: 推荐项目。 """ items = redis_conn.keys() similarities = {} for item in items: item_emb = np.fromstring(redis_conn.get(item)[1:-1], sep=',') similarity = np.dot(user_embedding, item_emb) similarities[item] = similarity # 按相似性排序项目并返回top_k recommended_items = sorted(similarities, key=similarities.get, reverse=True)[:top_k] return recommended_items # 示例用法
user_embedding = np.random.rand(200)
recommend_items(user_embedding, redis.Redis())
批量推理
对于批量处理,可以将嵌入加载到像Apache Spark这样的数据处理框架中,并行运行推理。
故障排除和优化提示
在处理大规模图和嵌入系统时,不可避免地会遇到一些问题。以下是一些常见的问题和解决方案。
常见问题
1. **内存不足错误**:鉴于大规模图的大小,GPU内存通常是一个限制因素。特别是如果批处理大小或嵌入维度设置过高,可能会遇到内存不足错误。
2. **GPU兼容性**:PyTorch-BigGraph需要特定的CUDA版本以利用GPU加速。不兼容的CUDA版本可能导致运行时错误或显著较慢的处理速度。
3. **数据格式错误**:PyTorch-BigGraph对数据格式有严格要求。如果数据未正确分区或格式化为TSV文件,训练可能会失败或产生错误结果。
4. **训练速度慢**:由于数据加载效率低、分区不佳或GPU利用率问题,训练大型图可能会变得缓慢。
调试提示
我们深入探讨识别和解决这些问题
1、内存调试
要调试内存问题,请在训练过程中密切关注GPU内存分配。使用torch.cuda.memory_allocated()可以实时监控内存使用情况,帮助您识别瓶颈。
import torch # 检查内存使用情况
print("分配的GPU内存:", torch.cuda.memory_allocated())
print("缓存的GPU内存:", torch.cuda.memory_reserved())如果内存使用过高,请尝试减少batch_size,降低dimension,或增加num_partitions以在GPU之间分配数据。
2、CUDA兼容性检查
检查CUDA版本以确保与已安装的PyTorch-BigGraph设置兼容。以下是验证CUDA版本的方法:
!nvcc --version
import torch
print("CUDA版本:", torch.version.cuda)
print("CUDA是否可用?", torch.cuda.is_available())
如果存在不匹配,请考虑重新安装具有正确CUDA版本的PyTorch。例如:
# 重新安装具有特定CUDA版本的PyTorch
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
3、数据格式验证
为了避免格式问题,通过加载一个小样本并确保其符合PyTorch-BigGraph的期望来验证TSV文件。以下是数据验证的快速脚本:
import pandas as pd def validate_data_format(file_path): data = pd.read_csv(file_path, sep='\t', header=None) # 确保存在所需的列 assert data.shape[1] >= 2, "数据应至少有2列(source, target)" print("数据格式已验证。") # 验证数据
validate_data_format("graph_data.tsv")
4、提高训练速度
训练度慢可以通过优化num_partitions和bucket_order设置来解决。通常增加分区数量有助于在GPU之间分配负载,而将bucket_order设置为random可以防止重复处理相似的数据块。
性能优化
这里我总结了一些性能优化的方向,供参考:
模型准确性与训练时间
- 更高维度:增加
dimension可以提高嵌入质量,但需要更多内存。尝试从dimension=200开始,如果看到质量改进的空间而不影响性能,可以增加。 - 批处理大小:较大的
batch_size可以加快训练速度,但需要更多内存。如果遇到内存问题,特别是在消费级GPU上,请使用较小的批处理大小。
内存消耗与模型复杂性
复杂图受益于高维嵌入,但内存限制通常需要降低维度。对于大多数应用,建议在50-200维度范围内进行实验,只有在准确性收益证明额外的内存负载是合理的情况下才增加。
硬件利用率
如果你可以访问集群,运行分布式训练是扩展的最有效方法。分布式训练将数据分割到GPU和节点之间,最大化硬件利用率。
import torch.distributed as dist def distributed_training(config_path): dist.init_process_group(backend='nccl') train(config_path=config_path)
混合精度训练:对于大型模型,混合精度(在可能的情况下使用float16)可以减少内存使用,而不会显著影响性能。虽然PBG不原生支持混合精度,但您可以通过在可能的情况下转换张量手动应用此方法。
通过结合这些优化策略,您将能够推动PyTorch-BigGraph的能力,以高效处理甚至是最大的数据集。
总结
本文深入探讨了使用 PyTorch-BigGraph (PBG) 构建和部署大规模图嵌入的完整流程,涵盖了从环境设置、数据准备、模型配置与训练,到高级优化技术、评估指标、部署策略以及实际案例研究等各个方面。我们重点讲解了如何高效处理包含数十亿节点和边的庞大图数据,并提供了优化内存管理、分布式训练等方面的实用技巧。文章还分析了常见问题及相应的调试策略,并展望了自定义关系类型、多跳关系等进阶方向,通过学习本文提供的最佳实践和优化技巧,可以有效提升大规模图嵌入模型的性能,并为实际应用场景提供更有价值的洞见。
希望本文能成为你探索大规模图嵌入世界的有力指南,并帮助你进一步探索和创新。
https://avoid.overfit.cn/post/71e37a58f683413f95d1b002d0dcb79d
作者:Amit Yadav
相关文章:
使用 PyTorch-BigGraph 构建和部署大规模图嵌入的完整教程
当涉及到图数据时,复杂性是不可避免的。无论是社交网络中的庞大互联关系、像 Freebase 这样的知识图谱,还是推荐引擎中海量的数据量,处理如此规模的图数据都充满挑战。 尤其是当目标是生成能够准确捕捉这些关系本质的嵌入表示时,…...

系统性能优化方法论详解:从理解系统到验证迭代
在当今的企业级和云计算环境中,系统性能优化已成为提升竞争力的关键因素。本文将对系统优化的步骤进行深入解析,帮助读者系统化地进行性能优化,从而显著提升系统的整体表现。 流程概述: 系统性能优化的流程可以分为以下几个关键步骤&#x…...

使用Tengine 对负载均衡进行状态检查(day028)
本篇文章对于在服务器已经安装了nginx,但却希望使用Tengine 的状态检查或其他功能时使用,不需要卸载服务器上的nginx,思路是使用干净服务器(未安装过nginx)通过编译安装Tengine,通过对./configure的配置,保证安装Tengi…...

网站推广实战案例:杭州翔胜科技有限公司如何为中小企业打开市场大门
以下是以杭州翔胜科技有限公司为例,解析其如何通过网站推广为中小企业打开市场大门的实战案例: 一、一站式网站推广方案 杭州翔胜科技有限公司提供一站式网站推广方案,该方案整合了多种推广手段,如搜索引擎优化(SEO&a…...

视频修复技术和实时在线处理
什么是视频修复? 视频修复技术的目标是填补视频中的缺失部分,使视频内容连贯合理。这项技术在对象移除、视频修复和视频补全等领域有着广泛的应用。传统方法通常需要处理整个视频,导致处理速度慢,难以满足实时处理的需求。 技术发…...

文心一言 VS 讯飞星火 VS chatgpt (396)-- 算法导论25.2 1题
一、在图 25-2 所示的带权重的有向图上运行 Floyd-Warshall 算法,给出外层循环的每一次迭代所生成的矩阵 D ( k ) D^{(k)} D(k) 。如果要写代码,请用go语言。 文心一言: 好的,让我们一步步分析在带权重的有向图上运行 Floyd-Wa…...

如何使用本地大模型做数据分析
工具:interpreter --local 样本数据: 1、启动分析工具 2、显示数据文件内容 输入: 显示/Users/wxl/work/example_label.csv 输出:(每次输出的结果可能会不一样) 3、相关性分析 输入: 分析客户类型与成…...

【Nginx从入门到精通】04-安装部署-使用XShell给虚拟机配置静态ip
文章目录 总结1、XShell :方便管理多台机器2、配置ip文件:区分大小写 一、查看上网模式二、Centos 7 设置静态ipStage 1 :登录root账号Stage 2 :设置静态ip : 修改配置文件 <font colororange>ifcfg-ens33Stage 2-1…...

C# 面向对象的接口
接口,多态性,密封类 C# 接口 遥控器是观众和电视之间的接口。 它是此电子设备的接口。 外交礼仪指导外交领域的所有活动。 道路规则是驾车者,骑自行车者和行人必须遵守的规则。 编程中的接口类似于前面的示例。 接口是: APIsC…...

使用IDEA+Maven实现MapReduced的WordCount
使用IDEAMaven实现MapReduce 准备工作 在桌面创建文件wordfile1.txt I love Spark I love Hadoop在桌面创建文件wordfile2.txt Hadoop is good Spark is fast上传文件到Hadoop # 启动Hadoop cd /usr/local/hadoop ./sbin/start-dfs.sh # 删除HDFS的hadoop对应的input和out…...

go语言示例代码
go语言示例代码, package mainimport "fmt" import "encoding/json"func main() {list : []int{11, 12, 13, 14, 15}for i,x : range list {fmt.Println("i ", i, ",x ", x)}fmt.Println("")for i : range l…...

华为云容器监控平台
首先搜索CCE,点击云容器引擎CCE 有不同的测试,生产,正式环境 工作负载--直接查询服务名看监控 数据库都是走的一个 Redis的查看...

阿里短信发送报错 InvalidTimeStamp.Expired
背景 给客户做的人力资源系统,今天客户用阿里云短信,结果报错: nvalidTimeStamp.Expired Specified time stamp or date value is expired. HTTP Status: 400 RequestID: A 怎么办呢?搜资料, 是客户端时间ÿ…...

Ubuntu问题 -- 设置ubuntu的IP为静态IP (图形化界面设置) 小白友好
目的 为了将ubuntu服务器IP固定, 方便ssh连接人在服务器前使用图形化界面设置 设置 找到自己的网卡名称, 我的是 eno1, 并进入设置界面 查看当前的IP, 网关, 掩码和DNS (注意对应eno1) nmcli dev show掩码可以通过以下命令查看完整的 (注意对应eno1) , 我这里是255.255.255.…...

Sigrity SPEED2000 TDR TDT Simulation模式如何进行时域阻抗仿真分析操作指导-差分信号
Sigrity SPEED2000 TDR TDT Simulation模式如何进行时域阻抗仿真分析操作指导-差分信号 Sigrity SPEED2000 TDR TDT Simulation模式如何进行时域阻抗仿真分析操作指导-单端信号详细介绍了单端信号如何进行TDR仿真分析,下面介绍如何对差分信号进行TDR分析,还是以下图为例进行分…...

Cesium 加载B3DM模型
一、引入Cesium,可以使用该链接下载cesium 链接: https://pan.baidu.com/s/1BRQyaFCkxO2xQQT5RzFUCw?pwdkcv9 提取码: kcv9 在index.html文件中引入cesium <script type"text/javascript" src"/Cesium/Cesium.js"></script> …...
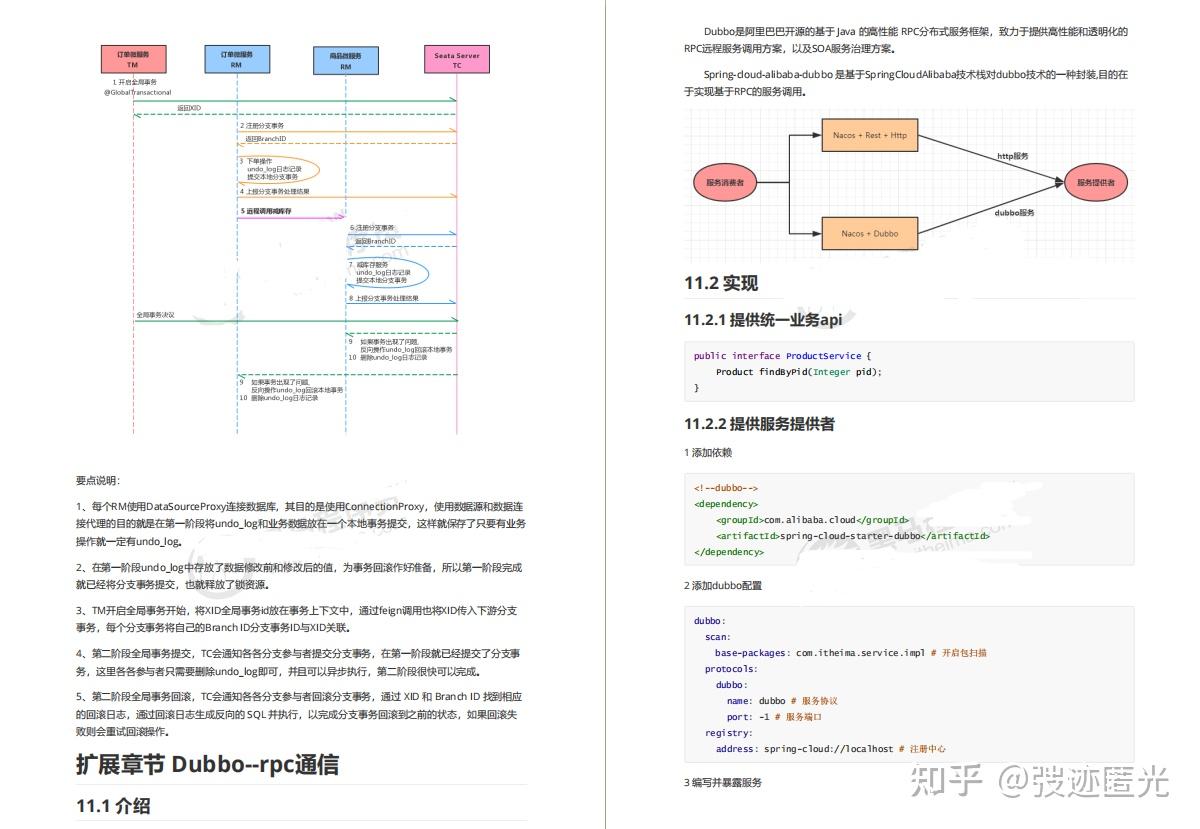
阿里巴巴官方「SpringCloudAlibaba全彩学习手册」限时开源!
最近我在知乎上看过的一个热门回答: 初级 Java 开发面临的最大瓶颈在于,脱离不出自身业务带来的局限。日常工作中大部分时间在增删改查、写写接口、改改 bug,久而久之就会发现,自己的技术水平跟刚工作时相比没什么进步。 所以我们…...

Docker是一个容器化平台注意事项
Docker本身是一个容器化平台,它允许你将应用及其依赖打包到一个可移植的容器中,然后可以在任何安装了Docker的机器上运行这个容器。Docker容器是跨平台的,但有一些限制和注意事项: 跨架构不可行 操作系统兼容性:Docke…...

Redis中的zset用法详解
文章目录 Redis中的zset用法详解一、引言二、zset的基本概念和操作1、zset的添加和删除1.1、添加元素1.2、删除元素 2、zset的查询2.1、获取元素分数2.2、获取元素排名 3、zset的范围查询3.1、按排名查询3.2、按分数查询 三、zset的应用场景1、排行榜1.1、添加玩家得分1.2、获取…...

上位机编程命名规范
1.大小写规范 文件名全部小写是一种广泛使用的命名约定,特别是在跨平台开发和开源项目中。主要原因涉及技术约束、可读性和一致性等方面。以下是原因和优劣势的详细分析: 1. 避免跨平台问题 不同操作系统对文件名的大小写处理方式不同: Li…...

三国杀卡牌DIY终极指南:5分钟打造你的专属武将
三国杀卡牌DIY终极指南:5分钟打造你的专属武将 【免费下载链接】Lyciumaker 在线三国杀卡牌制作器 项目地址: https://gitcode.com/gh_mirrors/ly/Lyciumaker 还在羡慕别人能设计出酷炫的三国杀武将卡牌吗?Lyciumaker这个免费开源的三国杀卡牌制作…...
QT开发避坑:为什么你的QWidget死活收不到mouseMoveEvent?从setMouseTracking到子控件拦截的完整排查指南
QT开发避坑指南:QWidget鼠标移动事件失效的深度排查 最近在重构一个QT项目时,我遇到了一个看似简单却令人抓狂的问题——明明已经调用了setMouseTracking(true),但mouseMoveEvent就是死活不触发。经过两天的调试和源码追踪,终于梳…...

SMUDebugTool终极指南:深度掌握AMD Ryzen硬件调试与性能优化
SMUDebugTool终极指南:深度掌握AMD Ryzen硬件调试与性能优化 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: http…...

欢迎使用Marp for VS Code
欢迎使用Marp for VS Code 【免费下载链接】marp-vscode Marp for VS Code: Create slide deck written in Marp Markdown on VS Code 项目地址: https://gitcode.com/gh_mirrors/ma/marp-vscode 用Markdown制作专业演示文稿 简洁的语法实时预览多格式导出 ### 第四步&…...

2026论文降AIGC网站:11款工具实测谁才是真神器?
2026 年学术审核标准持续收紧,论文重复率、AIGC 检出率已经成为毕业答辩、期刊投稿的硬性门槛。随着知网、维普、Turnitin 等主流检测平台算法不断优化升级,对论文原创性和人工写作痕迹的要求愈发严格。面对日益严苛的审查机制,越来越多学生和…...

3分钟搞定!GetQzonehistory教你永久保存QQ空间青春回忆
3分钟搞定!GetQzonehistory教你永久保存QQ空间青春回忆 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 还在担心那些承载着青春记忆的QQ空间说说会消失吗?GetQzo…...
 全解析|≤68kg 单个包装件部分模拟运输测试标准)
ISTA 2A-2011 (2022) 全解析|≤68kg 单个包装件部分模拟运输测试标准
前言ISTA 2A-2011 (2022) 属于 ISTA 2 系列部分模拟性能测试,专门针对重量不大于 68kg(150lb)的单个运输包装件设计,是中小型产品包装最常用的入门级运输验证标准。该标准通过温湿度、堆码压力、振动、冲击等测试模块,…...

TCP三次握手与四次挥手——连接管理的“仪式感“
**导读:**如果说HTTP是互联网世界的"通用语言",那么TCP就是支撑这一切的"地下管道"。但这条管道不是想通就通的——它有一套严格的"礼仪规范",也就是我们常说的三次握手和四次挥手。今天,我们就来聊…...

毕业答辩效率突围!Paperxie AI 一键搞定高质量毕业论文PPT
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 每一年毕业季,绝大多数高校学生都会陷入同一个困境:论文定稿万事俱备,却卡在了毕业论文答…...

2026大模型全栈学习路线:从零基础入门到实战就业
随着AI技术全面落地,大模型已从实验室技术转变为各行各业的刚需能力。2026年,AI Agent、多模态生成、轻量化模型部署、行业定制微调成为行业主流趋势,大模型相关岗位需求持续爆发,应用工程师、微调工程师、AI架构师等岗位薪资稳居…...