什么是GraphQL,有什么特点
什么是GraphQL?
GraphQL 是一种用于 API(应用程序编程接口)的查询语言,由 Facebook 在 2012 年开发,并于 2015 年开源。它提供了一种更高效、强大的方式来获取和操作数据,与传统的 RESTful API 相比,GraphQL 具有更高的灵活性和更低的网络负载。通过 GraphQL,客户端可以精确地请求所需的数据,而服务器则只返回这些数据,从而避免了过度加载或不足加载的问题。
GraphQL 的核心概念
-
类型系统:GraphQL 使用强类型系统定义数据模型。每个字段都有明确的数据类型,如
String、Int、Boolean等,还可以定义复杂类型如对象类型、枚举类型、输入对象类型等。 -
查询:客户端可以通过发送一个查询语句来请求特定的数据。查询语句是一个树状结构,描述了需要获取的数据字段及其子字段。
-
变更(Mutations):用于执行写操作,如创建、更新或删除数据。变更操作也遵循严格的类型定义。
-
订阅(Subscriptions):允许客户端实时接收数据更新。订阅通常用于实现实时通信功能,如聊天应用中的消息推送。
-
字段解析器(Resolvers):服务器端的逻辑单元,负责处理查询中的每个字段。解析器可以根据请求参数从数据库或其他数据源中获取数据,并将其返回给客户端。
-
模式(Schema):定义了 API 的结构,包括可用的查询、变更和订阅,以及它们的参数和返回类型。模式是 GraphQL API 的核心部分,确保了客户端和服务器之间的契约。
GraphQL 的特点
-
精确的数据请求:客户端可以精确地指定需要的数据字段,避免了不必要的数据传输,提高了性能和响应速度。
-
单个端点:GraphQL API 通常只有一个端点,所有查询和变更都通过这个端点进行。这简化了客户端的实现,减少了 API 管理的复杂性。
-
强类型系统:通过定义明确的类型和字段,确保了数据的一致性和可靠性。客户端可以在编译时检查查询的有效性,减少运行时错误。
-
灵活的数据聚合:客户端可以请求多个资源的数据,并在一次请求中获得结果。这减少了网络往返次数,提高了用户体验。
-
版本控制:由于客户端可以精确地请求所需的数据,因此可以在不破坏现有客户端的情况下逐步演进 API。这使得版本控制变得更加灵活。
-
工具支持:GraphQL 生态系统提供了丰富的工具,如 GraphiQL、Apollo Studio 等,帮助开发者调试和优化 API。
GraphQL 的作用
-
提高开发效率:通过精确的数据请求和强类型系统,开发者可以更快地构建和测试 API,减少调试时间。
-
优化性能:客户端只需请求必要的数据,减少了网络负载和服务器压力,提高了整体性能。
-
增强用户体验:通过减少网络往返次数和提高数据加载速度,用户可以更快地获取所需信息,提升应用的响应性和流畅度。
-
简化后端架构:单个端点的设计减少了后端服务的数量和复杂性,使得维护和扩展更加容易。
-
支持实时数据:通过订阅机制,可以实现实时数据更新,适用于需要实时通信的应用场景。
示例说明
为了更好地理解 GraphQL 的工作原理和优势,我们通过一个具体的示例来说明。假设我们正在开发一个社交媒体应用,需要展示用户的个人信息和最近发布的帖子。
定义模式
首先,我们需要定义 GraphQL 模式,描述可用的查询、变更和订阅。以下是一个简单的模式定义:
type User {id: ID!name: String!email: String!posts: [Post!]!
}type Post {id: ID!title: String!content: String!createdAt: String!author: User!
}type Query {user(id: ID!): Userposts(userId: ID!): [Post!]!
}type Mutation {createUser(name: String!, email: String!): UsercreatePost(title: String!, content: String!, userId: ID!): Post
}type Subscription {newPost: Post
}查询示例
假设我们想获取某个用户的详细信息及其最近发布的帖子,可以发送以下查询:
query GetUserWithPosts($userId: ID!) {user(id: $userId) {idnameemailposts {idtitlecontentcreatedAt}}
}在这个查询中,我们使用了变量 $userId 来指定要查询的用户 ID。服务器将返回该用户的详细信息及其最近发布的帖子。
变更示例
假设我们要创建一个新的用户,可以发送以下变更请求:
mutation CreateUser($name: String!, $email: String!) {createUser(name: $name, email: $email) {idnameemail}
}在这个变更请求中,我们传递了用户的姓名和电子邮件地址。服务器将创建新的用户并返回其详细信息。
订阅示例
假设我们要实现实时的新帖子通知,可以使用订阅机制:
subscription NewPost {newPost {idtitlecontentcreatedAtauthor {idname}}
}当有新的帖子发布时,服务器会实时推送新帖子的信息到订阅的客户端。
实现细节
服务器端实现
在服务器端,我们需要实现字段解析器来处理查询和变更请求。以下是一个使用 Node.js 和 Express 实现的简单示例:
const express = require('express');
const { ApolloServer, gql } = require('apollo-server-express');// 模拟数据存储
const users = [{ id: '1', name: 'Alice', email: 'alice@example.com' },{ id: '2', name: 'Bob', email: 'bob@example.com' }
];const posts = [{ id: '1', title: 'First Post', content: 'This is the first post.', createdAt: '2023-10-01T00:00:00Z', authorId: '1' },{ id: '2', title: 'Second Post', content: 'This is the second post.', createdAt: '2023-10-02T00:00:00Z', authorId: '2' }
];// 定义模式
const typeDefs = gql`type User {id: ID!name: String!email: String!posts: [Post!]!}type Post {id: ID!title: String!content: String!createdAt: String!author: User!}type Query {user(id: ID!): Userposts(userId: ID!): [Post!]!}type Mutation {createUser(name: String!, email: String!): UsercreatePost(title: String!, content: String!, userId: ID!): Post}type Subscription {newPost: Post}
`;// 定义解析器
const resolvers = {Query: {user: (parent, { id }) => users.find(user => user.id === id),posts: (parent, { userId }) => posts.filter(post => post.authorId === userId)},Mutation: {createUser: (parent, { name, email }) => {const newUser = { id: users.length + 1, name, email };users.push(newUser);return newUser;},createPost: (parent, { title, content, userId }) => {const newPost = { id: posts.length + 1, title, content, createdAt: new Date().toISOString(), authorId: userId };posts.push(newPost);return newPost;}},Subscription: {newPost: {subscribe: () => pubsub.asyncIterator('NEW_POST')}},User: {posts: (parent) => posts.filter(post => post.authorId === parent.id)},Post: {author: (parent) => users.find(user => user.id === parent.authorId)}
};// 创建 Apollo Server
const server = new ApolloServer({ typeDefs, resolvers });// 应用中间件
const app = express();
server.applyMiddleware({ app, path: '/graphql' });// 启动服务器
app.listen({ port: 4000 }, () => {console.log(`🚀 Server ready at http://localhost:4000${server.graphqlPath}`);
});客户端实现
在客户端,我们可以使用 Apollo Client 来发送查询和变更请求。以下是一个使用 React 和 Apollo Client 的示例:
import React from 'react';
import { ApolloProvider, useQuery, gql } from '@apollo/client';// 配置 Apollo Client
const client = new ApolloClient({uri: 'http://localhost:4000/graphql'
});const GET_USER_WITH_POSTS = gql`query GetUserWithPosts($userId: ID!) {user(id: $userId) {idnameemailposts {idtitlecontentcreatedAt}}}
`;function App() {const { loading, error, data } = useQuery(GET_USER_WITH_POSTS, {variables: { userId: '1' }});if (loading) return <p>Loading...</p>;if (error) return <p>Error: {error.message}</p>;return (<div><h1>User: {data.user.name}</h1><p>Email: {data.user.email}</p><h2>Posts</h2><ul>{data.user.posts.map(post => (<li key={post.id}><h3>{post.title}</h3><p>{post.content}</p><p>Created At: {post.createdAt}</p></li>))}</ul></div>);
}function Root() {return (<ApolloProvider client={client}><App /></ApolloProvider>);
}export default Root;总结
GraphQL 提供了一种强大且灵活的方式来构建和使用 API。通过精确的数据请求、强类型系统和单个端点设计,GraphQL 能够显著提高开发效率、优化性能并增强用户体验。同时,丰富的工具支持和生态系统使得 GraphQL 成为现代 Web 开发的重要选择之一。希望本文的介绍和示例能够帮助你更好地理解和应用 GraphQL。
相关文章:

什么是GraphQL,有什么特点
什么是GraphQL? GraphQL 是一种用于 API(应用程序编程接口)的查询语言,由 Facebook 在 2012 年开发,并于 2015 年开源。它提供了一种更高效、强大的方式来获取和操作数据,与传统的 RESTful API 相比&#…...
Java项目-基于SpringBoot+vue的租房网站设计与实现
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...
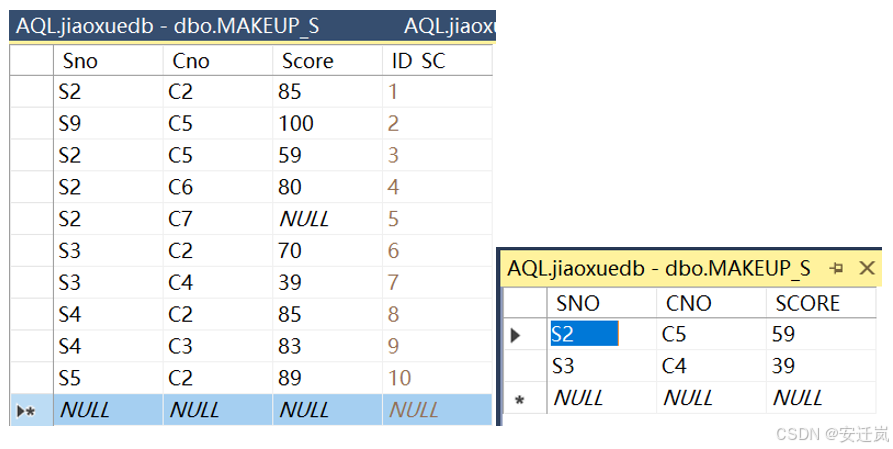
【SQL Server】华中农业大学空间数据库实验报告 实验三 数据操作
1.实验目的 熟悉了解掌握SQL Server软件的基本操作与使用方法,以及通过理论课学习与实验参考书的帮助,熟练掌握使用T-SQL语句和交互式方法对数据表进行插入数据、修改数据、删除数据等等的操作;作为后续实验的基础,根据实验要求重…...
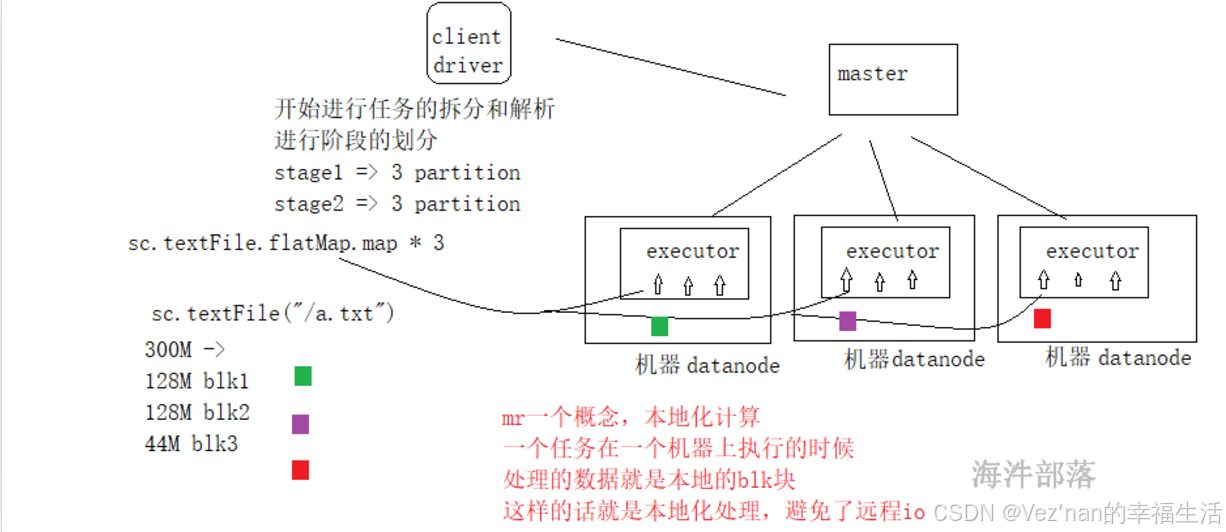
【大数据学习 | Spark】RDD的概念与Spark任务的执行流程
1. RDD的设计背景 在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中&…...

ruoyi框架完成分库分表,按月自动建表功能
前提 这个分库分表功能,按月自动建表,做的比较久了,还没上线,是在ruoyi框架内做的,踩了不少坑,但是已经实现了,就分享一下代码吧 参考 先分享一些参考文章 【若依系列】集成ShardingSphere S…...

Antd中的布局组件
文章目录 一、Layout二、Menu三、Grid栅格 布局组件涉及项目框架的搭建,往往被忽略和低关注,毕竟不是经常用到,但是在调整项目结构的时候往往又需要重新设计布局,所以有必要提前归纳分析; 一、Layout Layout导出Sider,…...
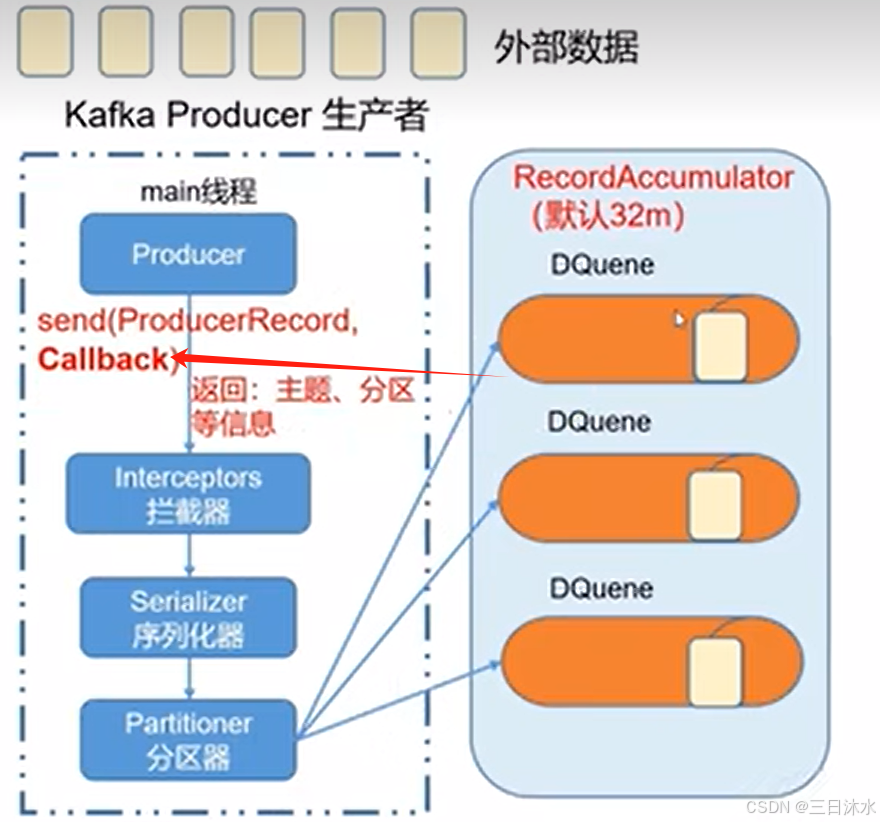
一文详解kafka知识点
目录 1、kafka定义 2、消息队列 2.1、产品选择 2.2、应用场景 2.3、消息队列的两种模式 3、kafka架构 4、kafka生产者 4.1、kafka生产者原理 4.2、kafka生产者异步发送 4.3、同步发送 4.4、分区 4.4.1、kafka分区好处 4.4.2、分区策略 4.4.3、自定义分区 4.5、生成吞…...

C语言基础学习:抽象数据类型(ADT)
基础概念 抽象数据类型(ADT)是一种数据类型,它定义了一组数据以及可以在这组数据上执行的操作,但隐藏了数据的具体存储方式和实现细节。在C语言中,抽象数据类型(ADT)是一种非常重要的概念&…...

提升性能测试效率与准确性:深入解析JMeter中的各类定时器
在软件性能测试领域,Apache JMeter是一款广泛使用的开源工具,它允许开发者模拟大量用户对应用程序进行并发访问,从而评估系统的性能和稳定性。在进行性能测试时,合理地设置请求之间的延迟时间对于模拟真实用户行为、避免服务器过载…...

施密特正交化与单位化的情形
在考研数学的线性代数部分,施密特正交化和单位化是两种不同的处理向量的方法,它们在特定的情况下被使用。以下是详细说明: 施密特正交化的应用场景 施密特正交化(Gram-Schmidt Orthogonalization)是一种从线性无关向…...
ROS机器视觉入门:从基础到人脸识别与目标检测
前言 从本文开始,我们将开始学习ROS机器视觉处理,刚开始先学习一部分外围的知识,为后续的人脸识别、目标跟踪和YOLOV5目标检测做准备工作。我采用的笔记本是联想拯救者游戏本,系统采用Ubuntu20.04,ROS采用noetic。 颜…...

2024 APMCM亚太数学建模C题 - 宠物行业及相关产业的发展分析和策略(详细解题思路)
在当下, 日益发展的时代,宠物的数量应该均为稳步上升,在美国出现了下降的趋势, 中国 2019-2020 年也下降,这部分变化可能与疫情相关。需要对该部分进行必要的解释说明。 问题 1: 基于附件 1 中的数据及您的团队收集的…...

C#里怎么样访问文件时间
C#里怎么样访问文件时间 文件时间也是一个关键信息, 因为很多数据处理需要时间来判断数据的有效性,比如股票中的股价, 它是的权重,是随着时间递减的。 一般来说,超过5年以上的数据,都是可以删除掉了。 或者说超过三年的数据,就需要压缩保存了,这样可以省掉很多磁盘空…...

Cesium教程01_认识View
Cesium 地图视图组件 目录 一、引言二、功能说明三、代码实现 1. 模板结构2. 脚本逻辑3. 样式设计 四、总结 一、引言 在三维地球可视化中,Cesium 是一个强大的开源 JavaScript 库,它能够展示精美的地球和地图应用。本示例展示了如何使用 Vue 组件化…...

【SQL Server】华中农业大学空间数据库实验报告 实验八 存储过程
1.实验目的 通过实验课程与理论课的学习深入理解掌握的存储过程的原理、创建、修改、删除、基本的使用方法、主要用途,并且可以在练习的基础上,熟练使用存储过程来进行数据库的应用程序的设计;深入学习深刻理解与存储过程相关的T-SQL语句的编…...

ArcMap 处理栅格数据的分辨率功能操作
ArcMap 处理栅格数据的分辨率功能操作 一、统一多分辨率栅格数据 1、查看两个栅格数据的分辨率 1)raster1 点击属性 2) raster2 2、统一像元大小 1)点击环境 展示和填写 处理范围 栅格分析 点击确定 3、重采样 让raster1和..2保持一致,即…...
 ae事件处理器(一))
redis7.x源码分析:(4) ae事件处理器(一)
ae模块是redis实现的Reactor模型的封装。它的主要代码实现集中在 ae.c 中,另外还提供了平台相关的io多路复用的封装,它们都实现了一套相同的poll接口,就类似于C中提供了一个接口基类,由针对不同平台的派生类去实现。 // 创建平台…...

【React】React Router:深入理解前端路由的工作原理
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 React Router:深入理解前端路由的工作原理路由的演进历程传统多页面…...

51单片机-独立按键与数码管联动
独立键盘和矩阵键盘检测原理及实现 键盘的分类:编码键盘和非编码键盘 键盘上闭合键的识别由专用的硬件编码器实现,并产生键编码号或键值的称为编码键盘,如:计算机键盘。靠软件编程识别的称为非编码键盘;在单片机组成…...

visual studio 2005的MFC各种线程函数之间的调用关系
在 Visual Studio 2005 的 MFC 程序中的函数和消息机制涉及线程间通信、消息处理以及与窗口消息的交互。接下来我将详细分析以下每个函数的作用、如何使用它们以及它们之间的调用关系。 1. PostThreadMessage(m_iThOpID, MSG_OP_OVER, 0, (LPARAM)iLparm); 函数用途࿱…...

AI+HR 全生命周期智能管理实战指南:从概念到落地,解锁组织效能新增长!
在企业数字化转型的浪潮中,人力资源管理正经历着前所未有的变革。据行业数据,61% 的 HR 领导者已进入 GenAI 实施进阶阶段,82% 的企业计划在 12 个月内部署 AI 智能体,而 AI 驱动的企业人均效能已实现3.2 倍提升。当传统 HR 深陷事…...

NVIDIA突破:单显卡实现图片驱动720p长视频世界模型生成能力提升
这项由NVIDIA研究团队主导的研究成果于2026年5月以预印本形式发布,论文编号为arXiv:2605.15178,感兴趣的读者可通过该编号查阅完整原文。给你一张照片,再给你一条摄像机的移动路线,然后电脑自动生成一段完整的一分钟高清视频&…...

性价比高的卫浴软件供应商
在卫浴行业数字化转型浪潮中,蓝猿BLUEAPE大力投入AI建设,其成果融入产品,为企业带来高效解决方案。降低成本,提升效率蓝猿云册多端同步,省略传统纸质画册印刷等环节,降低样品制作与分发成本,某卫…...

记一次 Ollama 部署 GGUF 模型后的异常输出修复
最近在 Ollama 中部署了一个来自 Hugging Face 的 GGUF 模型: hf.co/WithinUsAI/Opus4.7-GODs.Ghost.Codex-4B.GGuF:Q4_K_M部署完成后,原本只是想简单测试一下模型是否能正常对话,于是在终端里输入: hello结果模型并没有像普通聊天…...

AMD Ryzen终极调试工具:硬件级性能调优完全指南
AMD Ryzen终极调试工具:硬件级性能调优完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.…...

格式规范否?8款AI论文网站排名,毕业答辩稳了!
论文选题总在反复纠结,文献检索耗时又费力?写作过程中思路混乱,逻辑难以梳理?查重修改一遍又一遍,时间精力都被消耗殆尽? 别担心!AI论文工具正在成为高校学子的得力助手。本文将基于内容生成质量…...

Honey Select 2中文汉化补丁终极指南:一键安装完整中文体验
Honey Select 2中文汉化补丁终极指南:一键安装完整中文体验 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的日语界面而烦恼吗…...

基于 RPA 自动化技术的私域机器人助手构建指南
利用自动化工作流实现私域运营中的消息智能响应与多任务协同 能力介绍 在私域流量运营中,如何高效响应用户需求、精细化管理社群是提升转化率的关键。传统的人工客服模式往往面临响应不及时、重复性劳动繁重等问题。 本方案基于 RPA(机器人流程自动化…...

BilibiliDown音频提取终极指南:3种方法从B站视频提取高质量音乐
BilibiliDown音频提取终极指南:3种方法从B站视频提取高质量音乐 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_…...

蓝牙5.0广播包PDU字段逐行解读:从ADV_IND到AUX_CHAIN_IND,新手也能看懂的报文拆解
蓝牙5.0广播包PDU字段逐行解读:从ADV_IND到AUX_CHAIN_IND 在物联网设备开发中,蓝牙低功耗(BLE)技术因其低功耗和简单连接特性而广受欢迎。但对于刚接触BLE协议的开发者来说,最头疼的莫过于理解那些晦涩的协议文档和复…...