【大数据学习 | Spark】RDD的概念与Spark任务的执行流程
1. RDD的设计背景
在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。显然,如果能将结果保存在内存当中,就可以大量减少IO。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的落地存储,大大降低了数据复制、磁盘IO和序列化开销。
2. RDD的概念
RDD(Resilient Distributed Datasets,弹性分布式数据集)代表可并行操作元素的不可变分区集合。
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段(HDFS上的块),并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。
RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
RDD典型的执行过程
Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作。RDD典型的执行过程如下:
1)RDD读入外部数据源(或者内存中的集合)进行创建;
2)RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
3)最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala/JAVA集合或变量)。
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作(行动算子底层代码调用了runJob函数),对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。


val conf = new SparkConf
val sparkContext = new SparkContext(conf)
val lines :RDD = sparkContext.textFile(logFile)
//lines.filter((a:String) => a.contains("hello world"))
val count = lines.filter(_.contains("hello world")).count()
println(count)可以看出,一个Spark应用程序,基本是基于RDD的一系列计算操作。
第1行代码用于创建JavaSparkContext对象;
第2行代码从HDFS文件中读取数据创建一个RDD;
第3行代码对fileRDD进行转换操作得到一个新的RDD,即filterRDD;
count()是一个行动操作,用于计算一个RDD集合中包含的元素个数。
这个程序的执行过程如下:
1)创建这个Spark程序的执行上下文,即创建SparkContext对象;
2)从外部数据源(即HDFS文件)中读取数据创建fileRDD对象;
3)构建起fileRDD和filterRDD之间的依赖关系,形成DAG图,这时候并没有发生真正的计算,只是记录转换的轨迹;
4)执行action代码时,count()是一个行动类型的操作,触发真正的计算,开始执行从fileRDD到filterRDD的转换操作,并把结果持久化到内存中,最后计算出filterRDD中包含的元素个数。
3. spark任务的执行过程
每一个应用都是由driver端组成的,并且driver端可以解析用户的代码,并且在集群中并行执行,spark给大家提供了一个编程对象,它是一个抽象的,叫做弹性分布式数据集,这个数据集和一堆数据的集合并且是被分区的,因为分区的数据可以被并行的进行操作,rdd的创建方式有两种 1.读取hdfs的文件 2.在driver的一个集合可以转换为rdd,rdd可以被持久化到内存中,并且rdd可以实现更好的失败恢复容错。

为什么rdd是抽象的呢?因为rdd并不存在数据,它是虚拟的,我们在定义逻辑的时候要标识一个节点,表示数据在流动到此处的时候要进行什么样的处理,我们可以理解rdd是一个代理对象。

上述任务执行过程可以划分为两个stage,从创建rdd开始到groupBy的shuffle,划分为一个stage,然后该shuffle到任务执行结束,又是一个stage。后面读源码我们会发现,当出现shuffle时,就要划分出一个阶段。因为业务逻辑发生了变化。
任务的执行和层架关系:
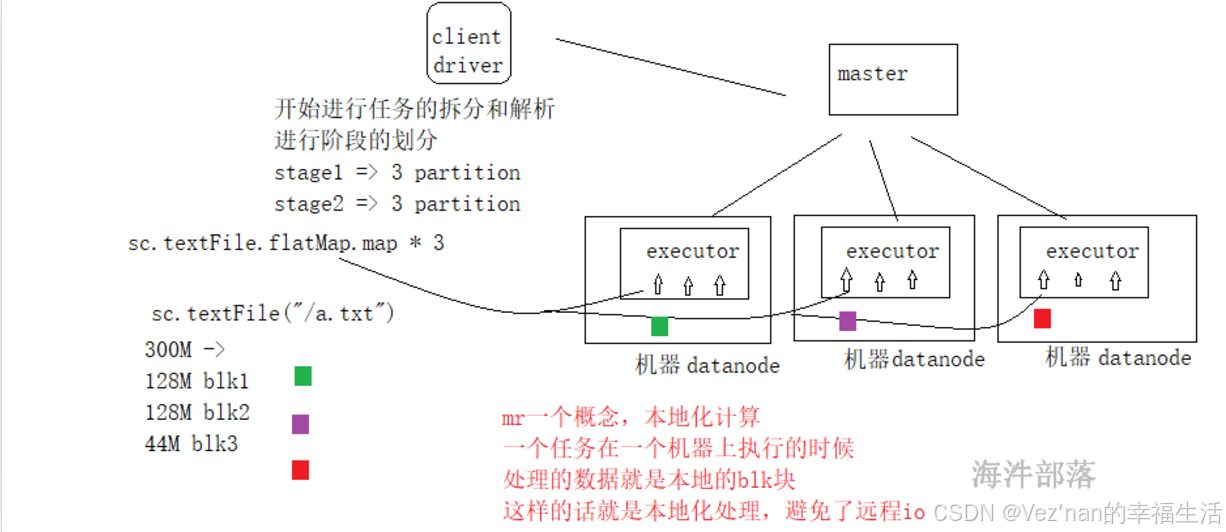
读取hdfs数据的时候映射应该是一个blk块对应一个分区
- 在一个任务中,一个action算子会生成一个job。(行动算子的源码都会包含runJob函数)
- 在一个job中存在shuffle算子,比如group sort切分阶段,shuffle+1个阶段。
- shuffle是任务的划分的重点,前面的任务会将数据放入到自己的本地存储,后续的任务进行数据的拉取。
- 在一个stage中任务都是管道形式执行的,避免了io,序列化和反序列化,这个就是dag切分的原理。
- 在一个阶段中分区数量就是task任务的数量,task任务就是一堆非shuffle类算子的整体任务链。
- 有几个分区就会并行的执行几个task任务。
- 有几个分区是根据读取的文件来进行适配的,比如有三个blk那么就会生成三个分区,因为我们可以在每个分区中进行处理数据,实现本地化的处理,避免远程io。
我们知道,分区的个数与读取的文件的Split切片数量有关。假如textFile读取文件的大小为400M,则会被物理切分为3个block,因为每个block-size的大小最大为128M,block1为128M,block2为128M,block3为144M。默认逻辑切片split-size的大小与block-size相适配,为128M,所以有三个分区。三个分区就会并行的执行3个task任务。
spark中一个executor可以执行多个task任务。这是通过将executor配置为拥有多个cores来实现的。每个核心可以并行执行一个task。即executor是一个JVM进程,负责在节点上运行任务。可以为executor配置多个核心来并行处理多个任务。
如果分区数多于executor的核心数,某些task必须等待其他task任务完成才能开始执行。
相关文章:
【大数据学习 | Spark】RDD的概念与Spark任务的执行流程
1. RDD的设计背景 在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中&…...

ruoyi框架完成分库分表,按月自动建表功能
前提 这个分库分表功能,按月自动建表,做的比较久了,还没上线,是在ruoyi框架内做的,踩了不少坑,但是已经实现了,就分享一下代码吧 参考 先分享一些参考文章 【若依系列】集成ShardingSphere S…...

Antd中的布局组件
文章目录 一、Layout二、Menu三、Grid栅格 布局组件涉及项目框架的搭建,往往被忽略和低关注,毕竟不是经常用到,但是在调整项目结构的时候往往又需要重新设计布局,所以有必要提前归纳分析; 一、Layout Layout导出Sider,…...
一文详解kafka知识点
目录 1、kafka定义 2、消息队列 2.1、产品选择 2.2、应用场景 2.3、消息队列的两种模式 3、kafka架构 4、kafka生产者 4.1、kafka生产者原理 4.2、kafka生产者异步发送 4.3、同步发送 4.4、分区 4.4.1、kafka分区好处 4.4.2、分区策略 4.4.3、自定义分区 4.5、生成吞…...

C语言基础学习:抽象数据类型(ADT)
基础概念 抽象数据类型(ADT)是一种数据类型,它定义了一组数据以及可以在这组数据上执行的操作,但隐藏了数据的具体存储方式和实现细节。在C语言中,抽象数据类型(ADT)是一种非常重要的概念&…...

提升性能测试效率与准确性:深入解析JMeter中的各类定时器
在软件性能测试领域,Apache JMeter是一款广泛使用的开源工具,它允许开发者模拟大量用户对应用程序进行并发访问,从而评估系统的性能和稳定性。在进行性能测试时,合理地设置请求之间的延迟时间对于模拟真实用户行为、避免服务器过载…...

施密特正交化与单位化的情形
在考研数学的线性代数部分,施密特正交化和单位化是两种不同的处理向量的方法,它们在特定的情况下被使用。以下是详细说明: 施密特正交化的应用场景 施密特正交化(Gram-Schmidt Orthogonalization)是一种从线性无关向…...
ROS机器视觉入门:从基础到人脸识别与目标检测
前言 从本文开始,我们将开始学习ROS机器视觉处理,刚开始先学习一部分外围的知识,为后续的人脸识别、目标跟踪和YOLOV5目标检测做准备工作。我采用的笔记本是联想拯救者游戏本,系统采用Ubuntu20.04,ROS采用noetic。 颜…...

2024 APMCM亚太数学建模C题 - 宠物行业及相关产业的发展分析和策略(详细解题思路)
在当下, 日益发展的时代,宠物的数量应该均为稳步上升,在美国出现了下降的趋势, 中国 2019-2020 年也下降,这部分变化可能与疫情相关。需要对该部分进行必要的解释说明。 问题 1: 基于附件 1 中的数据及您的团队收集的…...

C#里怎么样访问文件时间
C#里怎么样访问文件时间 文件时间也是一个关键信息, 因为很多数据处理需要时间来判断数据的有效性,比如股票中的股价, 它是的权重,是随着时间递减的。 一般来说,超过5年以上的数据,都是可以删除掉了。 或者说超过三年的数据,就需要压缩保存了,这样可以省掉很多磁盘空…...

Cesium教程01_认识View
Cesium 地图视图组件 目录 一、引言二、功能说明三、代码实现 1. 模板结构2. 脚本逻辑3. 样式设计 四、总结 一、引言 在三维地球可视化中,Cesium 是一个强大的开源 JavaScript 库,它能够展示精美的地球和地图应用。本示例展示了如何使用 Vue 组件化…...

【SQL Server】华中农业大学空间数据库实验报告 实验八 存储过程
1.实验目的 通过实验课程与理论课的学习深入理解掌握的存储过程的原理、创建、修改、删除、基本的使用方法、主要用途,并且可以在练习的基础上,熟练使用存储过程来进行数据库的应用程序的设计;深入学习深刻理解与存储过程相关的T-SQL语句的编…...

ArcMap 处理栅格数据的分辨率功能操作
ArcMap 处理栅格数据的分辨率功能操作 一、统一多分辨率栅格数据 1、查看两个栅格数据的分辨率 1)raster1 点击属性 2) raster2 2、统一像元大小 1)点击环境 展示和填写 处理范围 栅格分析 点击确定 3、重采样 让raster1和..2保持一致,即…...
 ae事件处理器(一))
redis7.x源码分析:(4) ae事件处理器(一)
ae模块是redis实现的Reactor模型的封装。它的主要代码实现集中在 ae.c 中,另外还提供了平台相关的io多路复用的封装,它们都实现了一套相同的poll接口,就类似于C中提供了一个接口基类,由针对不同平台的派生类去实现。 // 创建平台…...

【React】React Router:深入理解前端路由的工作原理
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 React Router:深入理解前端路由的工作原理路由的演进历程传统多页面…...

51单片机-独立按键与数码管联动
独立键盘和矩阵键盘检测原理及实现 键盘的分类:编码键盘和非编码键盘 键盘上闭合键的识别由专用的硬件编码器实现,并产生键编码号或键值的称为编码键盘,如:计算机键盘。靠软件编程识别的称为非编码键盘;在单片机组成…...

visual studio 2005的MFC各种线程函数之间的调用关系
在 Visual Studio 2005 的 MFC 程序中的函数和消息机制涉及线程间通信、消息处理以及与窗口消息的交互。接下来我将详细分析以下每个函数的作用、如何使用它们以及它们之间的调用关系。 1. PostThreadMessage(m_iThOpID, MSG_OP_OVER, 0, (LPARAM)iLparm); 函数用途࿱…...

网页中调用系统的EXE文件,如打开QQ
遇到一个实际的问题,需要在网页中打开本地的某个工业软件。 通过点击exe文件就可以调用到程序。 比如双击qq的exe就可以启动qq的程序。 那么问题就变成了如何加载exe程序呢? 可以通过Java的 Process process Runtime.getRuntime().exec(command);通过…...

【单点知识】基于PyTorch讲解自动编码器(Autoencoder)
文章目录 0. 前言1. 自动编码器的基本概念1.1 定义1.2 目标1.3 结构 2. PyTorch实现自动编码器2.1 导入必要的库2.2 定义自动编码器模型2.3 加载数据2.4 训练自动编码器 3. 自动编码器的意义4. 自动编码器的应用4.1 图像处理4.2自然语言处理:4.3推荐系统:…...
Halo 正式开源: 使用可穿戴设备进行开源健康追踪
在飞速发展的可穿戴技术领域,我们正处于一个十字路口——市场上充斥着各式时尚、功能丰富的设备,声称能够彻底改变我们对健康和健身的方式。 然而,在这些光鲜的外观和营销宣传背后,隐藏着一个令人担忧的现实:大多数这些…...

抖音批量下载神器:5分钟掌握高效内容采集的终极指南
抖音批量下载神器:5分钟掌握高效内容采集的终极指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...

XBOX360 KINECT体感游戏合集109个
实体机模拟器都可以用,模拟器游戏说明: 1,解压后把游戏文件夹放进模拟器Roms文件夹 2、模拟器运行文件为xenia_canary.exe。点击File—Open,找到游戏目录下的Roms文件夹,一直打开下级文件夹,直到看到以20位…...

新手网站建设教程:域名、主机、建站方式一次讲清楚
在数字化时代,拥有一个属于自己的网站,无论是用于展示个人作品、创建企业官网,还是开启电商副业,都是一项极具价值的长线投资。但对于零基础的新手来说,搭建网站似乎总是隔着“代码”这座大山。其实,随着技…...

Taotoken助力初创团队低成本管理多个AI项目API用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken助力初创团队低成本管理多个AI项目API用量 对于小型创业团队的技术负责人而言,同时推进多个AI项目是常态。每个…...

创业团队如何利用Taotoken统一技术栈并降低AI接入门槛
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何利用Taotoken统一技术栈并降低AI接入门槛 对于资源有限的创业团队而言,在产品中集成人工智能能力是提升竞…...

如何三步实现AI虚拟试衣:OOTDiffusion从安装到实战的完整指南
如何三步实现AI虚拟试衣:OOTDiffusion从安装到实战的完整指南 【免费下载链接】OOTDiffusion [AAAI 2025] Official implementation of "OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on" 项目地址: https://…...

OpenRPA完全指南:免费开源的企业级RPA自动化终极方案
OpenRPA完全指南:免费开源的企业级RPA自动化终极方案 【免费下载链接】openrpa Free Open Source Enterprise Grade RPA 项目地址: https://gitcode.com/gh_mirrors/op/openrpa OpenRPA是一款免费开源的企业级RPA(机器人流程自动化)软…...

Servlet 容器与过滤器 超详细讲解
目录 一、Servlet 容器(Servlet Container) 1. 是什么? 2. 核心作用(必须掌握) 3. Servlet 生命周期(容器全权控制) 4. 工作流程(HTTP 请求完整链路) 5. 总结一句话 二、过滤器(Filter) 1. 是什么? 2. 核心特点 3. 过滤器能做什么?(高频场景) 4. 过滤…...

利用Taotoken模型广场为AIGC应用选择性价比最优的文本生成模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为AIGC应用选择性价比最优的文本生成模型 对于AIGC应用开发者而言,文本生成模型的选择直接影响着…...

如何快速自定义游戏光标:提升操作精度的完整指南
如何快速自定义游戏光标:提升操作精度的完整指南 【免费下载链接】YoloMouse Game Cursor Changer 项目地址: https://gitcode.com/gh_mirrors/yo/YoloMouse 在激烈的游戏战斗中,你是否经常因为找不到鼠标光标而错失良机?当屏幕特效绚…...