python代码制作数据集的测试和数据质量检测思路
前言
本文指的数据集为通用数据集,并不单是给机器学习领域使用。包含科研和工业领域需要自己制作数据集的。
首先,在制作大型数据集时,代码错误和数据问题可能会非常复杂。
前期逻辑总是简单的,库库一顿写,等排查的时候两眼无泪。
后期慢慢摸排和检查的时候不断完善代码,前期代码主要是完成功能,后期是增加维护性和检测性。
这部分工作其实前期可以考虑进去。
以下提供一些血泪经验
方法
1. 模块化设计
将代码分成多个小模块或函数,每个模块负责一个特定的任务。这样更容易定位和修复问题。
模块化在最开始拿到需求和实现思路的时候估计还做不到,但代码写到一定程度该考虑拆成模块的就得拆成模块。不然后期调试会特别复杂。
2.单元测试
TDD我是支持的,但同时写测试和代码我是做不到的。所以对我来说都是代码写到一定程度再考虑添加单元测试。分为功能测试,计算测试,还有数据样例测试。
3.日志记录
需要记录过程数据,推荐建立单独文件夹,存储计算中的过程数据。
注意!!! 这个除了开发阶段非常有用! 后期在程序上线生产环境后对于帮助排查bug也是非常有帮助的,上线后注意的是控制过程数据文件数量。
如图,一般建立check_data文件夹或者logs文件夹。

还可以用logging模块,代码如图:
import logginglogging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)def process_data(data):logger.debug("Starting data processing")logger.debug("Data processing completed")但我个人倾向自定义log文件。logging模块的排版虽然整齐,无用字符也太多了。自己单独费点时间写个表保存。
晒一下,嘿嘿:

4. debug
打断点逐步调试啦!!没有捷径可走,加油吧少年!!
5.数据验证
在每个计算步骤核对计算结果确保计算正确。
6.版本控制
保存每个能跑的版本。不管是不是shit。
可以用管理工具git也可以手动保存。
7.数据抽样
对数据集进行抽样组成小样本数据集代入程序进行验证和核对结果,可以大大减少工作量!
8.自动化测试
编写自动化测试脚本,定期运行这些脚本以检测新引入的错误。可以使用CI/CD工具(如Jenkins、GitHub Actions)来实现这一点。
9.并行处理
将数据集切分多个进程进行计算,加快速度同时也会帮助更快发现问题!
提供一个按进程数均分数据集进行计算的代码:
from multiprocessing import Process
import timedef func_demo(age,name_list)for name in name_list:print(name,":",age)def func(param1,process_number):# 总输入xxx_list = [str(i) for i in range(100)]# 统计任务数量number = len(xxx_list) # 计算平均每个进程需承担多少任务delta = int(number / process_number)p_list = []# 启动多进程for i in range(0, process_number):# 按delta遍历取需要计算的任务。if i == process_number - 1:s = delta * ie = numberelse:s = delta * ie = delta * (i + 1)p = Process(target=calculate_name, args=(param1, xxx_list[s:e]))p.start()p_list.append(p)for p in p_list:p.join()# 测试划分的对不对
def test_p_delta():number = len(xxx_list)delta = int(number / 4)for i in range(0, 4):if i == 3:s = delta * ie = numberelse:s = delta * ie = delta * (i + 1)print("s:", s, " e:", e)if __name__ == '__main__':age=10process_number = 4func(age,process_number)
10.文档和注释
确保代码有充分的文档和注释,后期翻看的时候,也能快速理解代码逻辑和数据处理过程。
希望对看官有所帮助!!!
相关文章:
python代码制作数据集的测试和数据质量检测思路
前言 本文指的数据集为通用数据集,并不单是给机器学习领域使用。包含科研和工业领域需要自己制作数据集的。 首先,在制作大型数据集时,代码错误和数据问题可能会非常复杂。 前期逻辑总是简单的,库库一顿写,等排查的时…...

笔记记录 k8s-install
master节点安装: yum upgrade -y 更新系统 yum update -y 升级内核 ifconfig ens33 关闭swap swapoff -a (临时) vim /etc/fstab (永久) #/dev/mapper/cl-swap swap swap defaults 0 0 vim /etc/sysctl.conf vm.swappin…...

丹摩征文活动|基于丹摩算力的可图(Kolors)的部署与使用
Kolors是一个以生成图像为目标的人工智能系统,可能采用了类似于OpenAI的DALLE、MidJourney等文本生成图像的技术。通过自然语言处理(NLP)和计算机视觉(CV)相结合,Kolors能够根据用户提供的文本描述生成符合…...

【Vue】 npm install amap-js-api-loader指南
前言 项目中的地图模块突然打不开了 正文 版本太低了,而且Vue项目就应该正经走项目流程啊喂! npm i amap/amap-jsapi-loader --save 官方说这样执行完,就这结束啦!它结束了,我还没有,不然不可能记录这篇文…...

MacOS下的Opencv3.4.16的编译
前言 MacOS下编译opencv还是有点麻烦的。 1、Opencv3.4.16的下载 注意,我们使用的是Mac,所以ios pack并不能使用。 如何嫌官网上下载比较慢的话,可以考虑在csdn网站上下载,应该也是可以找到的。 2、cmake的下载 官网的链接&…...

Android中的依赖注入(DI)框架Hilt
Hilt 是 Android 提供的一种依赖注入(DI)框架,它基于 Dagger,目的是简化依赖注入的使用,提供更易用的接口和与 Android 生命周期组件的紧密集成。下面是 Hilt 的详细介绍。 为什么选择 Hilt? 依赖注入的优势…...

5.STM32之通信接口《精讲》之USART通信---实验串口接收程序
根据上节,我们一已经完成了串口发送程序的代码,并且深入的解析探索了串口的原理,接下来,Whappy小编将带领大家进入串口接收程序的探索与实验,并将结合上一节串口发送一起来完成串口的发送和接收实验。 上来两张图 上图…...

【Redis_Day6】Hash类型
【Redis_Day6】Hash类型 Hash类型操作hash的命令hset:设置hash中指定的字段(field)的值(value)hsetnx:想hash中添加字段并设置值hget:获取hash中指定字段的值hexists:判断hash中是否…...
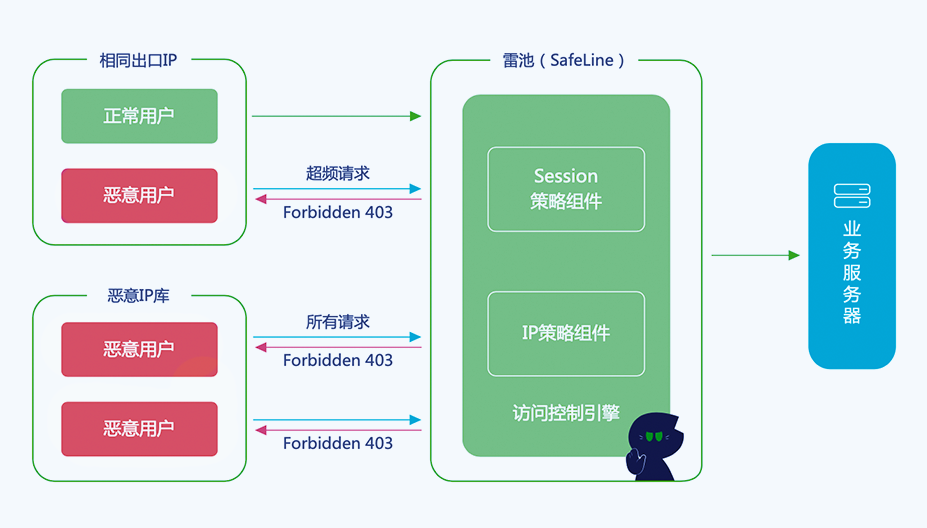
[开源] SafeLine 好用的Web 应用防火墙(WAF)
SafeLine,中文名 “雷池”,是一款简单好用, 效果突出的 Web 应用防火墙(WAF),可以保护 Web 服务不受黑客攻击 一、简介 雷池通过过滤和监控 Web 应用与互联网之间的 HTTP 流量来保护 Web 服务。可以保护 Web 服务免受 SQL 注入、XSS、 代码注…...

40分钟学 Go 语言高并发:Select多路复用
Select多路复用 学习目标 知识点掌握程度应用场景select实现原理深入理解底层机制channel通信和多路选择超时处理掌握超时控制方法避免阻塞和资源浪费优先级控制理解优先级实现处理多个channel的顺序性能考虑了解性能优化点高并发场景优化 1. Select实现原理 让我们通过一个…...

candence: 如何快速设置SUBCLASS 的颜色
如何快速设置SUBCLASS 的颜色 一、一般操作 正常情况下修改SUBCLASS,需要如下步骤进行设置: 二、快速操作 右键,选择一个颜色即可...

FinalShell进行前端项目部署及nginx配置
首先需要准备服务器(阿里云、腾讯云都可)与域名; 示例为阿里云服务器; 1.进行FinalShell下载 下载官网 https://www.hostbuf.com/ 2.下载完毕后 配置FinalShell ssh 名称自定义即可! 2-1 提示连接成功 3.首先检查nginx是否下载 …...

神经网络(系统性学习一):入门篇——简介、发展历程、应用领域、基本概念、超参数调优、网络类型分类
相关文章: 神经网络中常用的激活函数 神经网络简介 神经网络(Neural Networks)是受生物神经系统启发而设计的数学模型,用于模拟人类大脑处理信息的方式。它由大量的节点(或称为“神经元”)组成࿰…...

用nextjs开发时遇到的问题
这几天已经基本把node后端的接口全部写完了,在前端开发时考虑时博客视频类型,考虑了ssr,于是选用了nextJs,用的是nextUi,tailwincss,目前碰到两个比较难受的事情。 1.nextUI个别组件无法在服务器段渲染 目前简单的解决方法&…...
)
微前端基础知识入门篇(二)
概述 在上一篇介绍了一些微前端的基础知识,详见微前端基础知识入门篇(一)。本文主要介绍qiankun微前端框架的实战入门内容。 qiankun微前端实践 通过Vite脚手架分别创建三个程序,主应用A为:vite+vue3+ts,两个微应用分别为B:vite+vue3+ts;C:vite+React+ts。因为qiankun的…...

自然语言处理:第六十五章 MinerU 开源PDF文档解析方案
本人项目地址大全:Victor94-king/NLP__ManVictor: CSDN of ManVictor 原文地址:MinerU:精准解析PDF文档的开源解决方案 论文链接:MinerU: An Open-Source Solution for Precise Document Content Extraction git地址࿱…...

Arcpy 多线程批量重采样脚本
Arcpy 多线程批量重采样脚本 import arcpy import os import multiprocessingdef resample_tifs(input_folder, output_folder, cell_size0.05, resampling_type"BILINEAR"):"""将指定文件夹下的所有 TIFF 文件重采样到指定分辨率,并输出…...

python 画图例子
目录 多组折线图点坐标的折线图 多组折线图 数据: 第1行为x轴标签第2/3/…行等为数据,其中第一列为标签,后面为y值 图片: 代码: import matplotlib.pyplot as plt# 原始数据字符串 # 第1行为x轴标签 # 第2/3/...行等为数据,其中第一列为标签,后面…...

Win11 22H2/23H2系统11月可选更新KB5046732发布!
系统之家11月22日报道,微软针对Win11 22H2/23H2版本推送了2024年11月最新可选更新补丁KB5046732,更新后,系统版本号升至22621.4541和22631.4541。本次更新后系统托盘能够显示缩短的日期和时间,文件资源管理器窗口很小时搜索框被切…...

【STM32】MPU6050初始化常用寄存器说明及示例代码
一、MPU6050常用配置寄存器 1、电源管理寄存器1( PWR_MGMT_1 ) 此寄存器允许用户配置电源模式和时钟源。 DEVICE_RESET :用于控制复位的比特位。设置为1时复位 MPU6050,内部寄存器恢复为默认值,复位结束…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

64_《智能体微服务架构企业级实战教程》授权与认证之授权认证集成测试
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

Arduino PWM转4-20mA工业电流信号:二阶滤波与V/I转换电路设计
1. 项目概述:从PWM到工业标准电流信号在工业自动化、过程控制和传感器领域,4-20 mA电流环是一个几乎无处不在的标准。它用4 mA代表测量值的下限(如0C),20 mA代表上限(如100C),这种设…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件
告别FTP龟速:用NTFS-3G在CentOS7上直连移动硬盘拷贝200G大文件当面对数百GB的设计素材、日志文件或数据库备份需要迁移时,传统的FTP传输往往会成为效率瓶颈。我曾在一个视频处理项目中,需要将230GB的4K原始素材从移动硬盘导入服务器ÿ…...

孤舟笔记 互联网常用框架篇二 Dubbo服务请求失败怎么处理?集群容错策略你用过几种
文章目录先说结论Failover:换家店试试Failfast:不行就算了Failsafe:忘了这事Failback:回头再说Forking:同时点几家Broadcast:通知所有人怎么选择回答技巧与点评加分回答面试官点评个人网站分布式系统中&…...

Office RibbonX Editor:简单三步打造你的专属Office界面
Office RibbonX Editor:简单三步打造你的专属Office界面 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...

因果推断与机器学习融合:量化分析社会运动中镇压与抗议的动态关系
1. 项目概述:当数据科学遇见社会运动如果你研究过社会运动,尤其是那些看似突然爆发、席卷全国的抗议浪潮,你可能会被一个核心问题困扰:国家机器的镇压,究竟是浇灭火焰的冷水,还是火上浇油的催化剂ÿ…...

三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南
三步让小爱音箱秒变AI语音助手:MiGPT深度配置指南 【免费下载链接】mi-gpt 🏠 将小爱音箱接入 ChatGPT 和豆包,改造成你的专属语音助手。 项目地址: https://gitcode.com/GitHub_Trending/mi/mi-gpt 还在为小爱音箱的"人工智障&q…...