深入理解索引(一)
1.引言
在数据库和数据结构中,索引(Index)是一种用于提高数据检索速度的重要机制。本文将详细深入介绍索引。
2. 索引的分类
2.1 B - 树索引(B - Tree Index)
2.1.1 结构细节
- 树状结构:B - 树索引是一种平衡的多叉树结构。它由根节点、分支节点和叶子节点组成。根节点位于树的顶部,包含指向子节点的指针和索引键值范围。分支节点用于引导搜索路径,也包含指向子节点的指针和索引键值范围。叶子节点存储实际的索引键值和对应的行标识符(ROWID),ROWID 用于定位表中的数据行。
- 有序存储:索引键值在树的节点中是按照一定顺序(通常是升序)排列的。这种有序排列使得范围查询和排序查询更加高效。例如,在一个存储员工工资信息的表中,如果对工资列建立了 B - 树索引,工资数据会按照从小到大的顺序存储在索引的叶子节点中。
2.1.2 查询场景优势
- 等值查询高效:当进行等值查询(如查询工资等于 5000 元的员工)时,数据库可以从根节点开始,沿着索引树的分支节点快速定位到存储该工资值的叶子节点,然后通过 ROWID 找到对应的员工记录。这个过程避免了全表扫描,大大提高了查询速度。
- 范围查询支持良好:对于范围查询(如查询工资在 4000 - 6000 元之间的员工),由于索引键值的有序性,数据库可以顺序读取叶子节点中的数据,找到符合范围的索引键值及其对应的 ROWID,从而获取相应的员工记录。这种顺序读取减少了磁盘 I/O 的随机访问,提高了查询效率。
2.1.3 更新操作影响
- 插入和删除影响:当插入新数据时,B - 树索引可能需要调整树的结构来保持平衡。例如,如果插入一个新的工资值,可能会导致索引节点的分裂或合并操作。删除数据时也可能导致节点的调整。这些操作会消耗一定的系统资源,但 Oracle 数据库有相应的机制来尽量减少这种影响。
- 更新索引列影响:如果更新的是索引列的值,那么索引也需要相应地更新。如果更新后的索引列值仍然在原索引键值的范围内,可能只需要在叶子节点内进行调整;如果超出了原范围,可能会导致节点的重新排列。
2.2 位图索引(Bitmap Index)
2.2.1 结构细节
- 位图表示:位图索引针对表中的每一个可能的索引值都有一个对应的位图。位图是由一系列的位(0 或 1)组成,位图中的每一位代表表中的一行。如果位的值为 1,表示该行包含对应的索引值;如果为 0,则表示该行不包含。例如,在一个有性别(男 / 女)列的客户表中,对于 “男” 这个索引值,位图中对应男性客户行的位为 1,女性客户行的位为 0。
- 存储空间节省:对于具有低基数(即不同值的数量相对较少)的列,位图索引可以有效地节省存储空间。因为它不需要像 B - 树索引那样存储每个索引键值和 ROWID,而是通过位图来表示数据分布。
2.2.2 查询场景优势
- 低基数列查询高效:在查询低基数列时,位图索引表现出色。例如,在查询所有男性客户的信息时,数据库只需对 “男” 对应的位图进行扫描,找到位为 1 的行,就可以快速定位到男性客户的记录。对于多条件查询(如查询男性且年龄大于 30 岁的客户),位图索引可以通过位运算(如 AND、OR 操作)来快速合并查询条件,提高查询效率。
2.2.3 更新操作影响
- 更新复杂性:位图索引在更新操作时比较复杂。当插入或删除数据时,需要更新多个位图。例如,在客户表中插入一个新的男性客户,需要更新性别列的位图,将新客户对应的位置为 1。而且,由于位运算的特性,在高并发环境下,位图索引的更新可能会导致锁竞争等问题,影响系统性能。
2.3 函数索引(Function - Based Index)
2.3.1 结构细节
- 基于函数结果存储:函数索引不是直接对列的值进行索引,而是对列经过特定函数或表达式计算后的结果进行索引。例如,在一个存储产品销售日期的表中,对日期列建立一个提取年份的函数索引,索引中存储的是经过提取年份函数计算后的结果(如 2024)和对应的 ROWID。
2.3.2 查询场景优势
- 函数查询加速:当查询条件经常涉及对列的函数操作时,函数索引可以大大提高查询效率。比如,在上述产品销售日期表中,如果经常查询某一年的销售情况,通过提取年份的函数索引,数据库可以直接定位到该年份对应的销售记录,而不需要对每个销售日期进行函数计算后再查询。
2.3.3 更新操作影响
- 更新时重新计算:当更新索引列时,由于函数索引是基于函数结果的,需要重新计算函数值来更新索引。如果函数计算比较复杂,可能会增加更新操作的成本。而且,函数索引的创建和维护需要考虑函数的确定性(即相同的输入总是得到相同的输出),否则可能会导致索引不一致等问题。
2.4 全文索引(Full - Text Index)
2.4.1 结构细节
- 文本内容分析:全文索引用于对文本数据进行索引,它会对文本中的单词、词组等进行分析和存储。Oracle 会将文本内容分解为一个个的词汇单元(token),并记录这些词汇单元在文本中的位置等信息。例如,在一个包含文章内容的表中,全文索引会对文章中的每个单词进行索引,包括单词出现的频率、位置等。
2.4.2 查询场景优势
- 文本搜索高效:当进行文本搜索(如查询包含某个特定关键词的文章)时,全文索引可以快速定位到相关的文本内容。它支持多种文本搜索方式,如模糊搜索、词干搜索(如搜索 “run” 可以匹配 “running”)等,为文本相关的应用提供了强大的搜索功能。
2.4.3 更新操作影响
- 更新成本高:由于全文索引需要对文本内容进行复杂的分析和处理,在更新文本数据时,全文索引的更新成本相对较高。特别是对于大量文本数据的更新,可能会导致系统性能下降。
2.5 反向键索引(Reverse Key Index)
2.5.1 结构细节
- 键值反转存储:反向键索引是一种特殊的 B - 树索引,它将索引键值的字节顺序反转后存储。例如,对于索引键值为 1234 的列,在反向键索引中存储为 4321。这种反转存储主要是为了避免在插入数据时,由于索引键值的顺序性导致索引树的不平衡。
2.5.2 查询场景优势
- 插入热点问题缓解:在一些应用场景中,如使用序列生成的主键列,数据可能会按照顺序插入,导致索引树的右侧分支过度增长(插入热点问题)。反向键索引通过反转键值,使得插入的数据在索引树中的分布更加均匀,从而在一定程度上缓解了插入热点问题,提高了插入操作的性能。
2.5.3 查询性能权衡
反向键索引在查询性能上可能会有一定的损失。因为在查询时,需要先将查询条件中的键值反转,然后再在索引树中进行搜索。对于范围查询,反向键索引的性能通常不如普通 B - 树索引,因为反转后的键值顺序打乱了原有的范围顺序。
3. 索引的创建
3.1 B - 树索引创建
3.1.1 语法
基本的创建 B - 树索引的语法是:
CREATE INDEX index_name ON table_name (column_name [ASC|DESC],...);
其中,index_name是要创建的索引名称,table_name是索引所属的表名,column_name是要建立索引的列名。可以指定多个列来创建组合索引,列名之间用逗号分隔。ASC或DESC用于指定索引列的排序方式,默认为ASC(升序)。
3.1.2 示例
假设存在一个员工表employees,包含employee_id(员工编号)、employee_name(员工姓名)和department_id(部门编号)列。如果经常根据员工姓名进行查询,可以创建一个 B - 树索引:
CREATE INDEX idx_employee_name ON employees (employee_name);
3.1.3 考虑因素:
- 选择合适的列:应该选择那些经常在查询条件中出现的列建立索引。同时,要避免对数据变化频繁的列过度建立索引,因为这会增加数据更新的成本。例如,在一个日志记录表中,日志内容列通常不需要建立索引,因为很少会根据日志内容进行查询,而且日志内容可能会频繁变化。
- 组合索引的列顺序:当创建组合索引时,列的顺序很重要。应该将最常用于过滤数据的列放在前面。例如,在一个订单表中,如果经常根据客户编号和订单日期进行查询,且客户编号的选择性更高(不同客户编号的数量相对订单日期的组合更多),那么组合索引的顺序应该是(customer_id, order_date)。
3.2 位图索引创建
3.2.1 语法
创建位图索引的语法为:
CREATE BITMAP INDEX bitmap_index_name ON table_name (column_name);
其中,bitmap_index_name是位图索引的名称,table_name是所属表名,column_name是要建立位图索引的列名。
3.2.2 示例
对于一个包含产品类别列product_category的产品表products,如果产品类别列的取值较少(低基数),可以创建位图索引:
CREATE BITMAP INDEX bitmap_product_category ON products (product_category);
3.2.3 考虑因素:
- 适用场景:主要适用于低基数列,即列的取值范围较小且重复值较多的情况。如性别、状态等列。对于高基数列,使用位图索引可能会导致存储空间过大和性能下降。
- 更新操作影响:要考虑到位图索引在更新操作时比较复杂。当插入或删除数据时,需要更新多个位图,在高并发环境下可能会导致锁竞争等问题,影响系统性能。
3.3 函数索引创建
3.3.1 语法
创建函数索引的语法是:
CREATE INDEX function_index_name ON table_name (function(column_name));
其中,function_index_name是函数索引的名称,table_name是所属表名,function(column_name)是基于列column_name的函数表达式。
3.3.2 示例
在一个销售记录表sales中,包含销售日期列sale_date,如果经常需要查询某一月份的销售记录,可以创建一个提取月份的函数索引:
CREATE INDEX idx_sale_month ON sales (EXTRACT(MONTH FROM sale_date));
3.3.3 考虑因素:
- 函数确定性:函数索引的创建和维护需要考虑函数的确定性,即相同的输入总是得到相同的输出。否则可能会导致索引不一致等问题。
- 更新成本:当更新索引列时,由于函数索引是基于函数结果的,需要重新计算函数值来更新索引。如果函数计算比较复杂,可能会增加更新操作的成本。
3.4 全文索引创建
3.4.1 语法(以 Oracle Text为例)
首先需要安装和配置 Oracle Text 组件。创建全文索引的基本语法如下:
CREATE INDEX fulltext_index_name ON table_name (column_name) INDEXTYPE IS CTXSYS.CONTEXT;
3.4.2 示例
在一个文档内容表documents中,包含content(文档内容)列,可以创建全文索引:
CREATE INDEX idx_document_content ON documents (content) INDEXTYPE IS CTXSYS.CONTEXT;
3.4.3 考虑因素:
- 文本分析要求:在创建全文索引时,需要考虑对文本内容的分析要求,如是否需要进行词干提取、停用词过滤等操作。这些操作可以通过 Oracle Text 的参数进行配置。
- 更新成本:由于全文索引需要对文本内容进行复杂的分析和处理,在更新文本数据时,全文索引的更新成本相对较高。特别是对于大量文本数据的更新,可能会导致系统性能下降。
4. 管理索引
4.1 查看索引信息
- 数据字典视图:可以使用数据字典视图来查看索引的相关信息。USER_INDEXES视图显示当前用户拥有的索引信息,包括索引名称、所属表、索引类型等。ALL_INDEXES视图可以查看当前用户有权访问的所有索引信息,DBA_INDEXES视图(需要管理员权限)则可以查看数据库中的所有索引信息。
- 示例:通过以下查询可以查看用户自己创建的索引:
SELECT index_name, table_name, index_type FROM USER_INDEXES;
4.2 重建和维护索引
- 索引碎片问题:随着数据的插入、更新和删除操作,索引可能会变得碎片化,影响其性能。例如,在频繁更新数据的表中,B - 树索引的节点可能会频繁分裂和合并,导致索引结构不紧凑,降低查询效率。
- 重建索引方法:可以通过重建索引来优化其性能。对于 B - 树索引,使用ALTER INDEX index_name REBUILD;语句进行重建。重建索引可以重新组织索引结构,减少碎片,提高索引的效率。
4.3 删除索引
- 语法:当索引不再需要时,可以使用DROP INDEX index_name;语句删除索引。
- 考虑因素:在删除索引之前,需要谨慎考虑。应该评估该索引是否真的不再使用,因为删除索引后可能会导致相关查询性能下降。如果是为了测试或者临时调整,可以先备份索引定义,以便在需要时重新创建。
未完待续
码字不易,宝贵经验分享不易,请各位支持原创,转载注明出处,多多关注作者,后续不定期分享DB基本知识和排障案例及经验、性能调优等。
相关文章:
)
深入理解索引(一)
1.引言 在数据库和数据结构中,索引(Index)是一种用于提高数据检索速度的重要机制。本文将详细深入介绍索引。 2. 索引的分类 2.1 B - 树索引(B - Tree Index) 2.1.1 结构细节 树状结构:B - 树索引是一…...

动态规划子数组系列一>最长湍流子数组
1.题目: 解析: 代码: public int maxTurbulenceSize(int[] arr) {int n arr.length;int[] f new int[n];int[] g new int[n];for(int i 0; i < n; i)f[i] g[i] 1;int ret 1;for(int i 1; i < n-1; i,m. l.kmddsfsdafsd){int…...

MATLAB矩阵元素的修改及删除
利用等号赋值来进行修改 A ( m , n ) c A(m,n)c A(m,n)c将将矩阵第 m m m行第 n n n列的元素改为 c c c,如果 m m m或 n n n超出原来的行或列,则会自动补充行或列,目标元素改为要求的,其余为 0 0 0 A ( m ) c A(m)c A(m)c将索引…...

对 TypeScript 中函数如何更好的理解及使用?与 JavaScript 函数有哪些区别?
TypeScript 中函数的理解 在 TypeScript 中,函数本质上与 JavaScript 中的函数类似,但是它增强了类型系统的支持,使得我们可以对函数的参数和返回值进行更严格的类型检查。这样可以有效减少类型错误,提高代码的可维护性和可读性。…...

ubuntu搭建k8s环境详细教程
在Ubuntu上搭建Kubernetes(K8s)环境可以通过多种方式实现,下面是一个详细的教程,使用kubeadm工具来搭建Kubernetes集群。这个教程将涵盖从准备工作到安装和配置Kubernetes的所有步骤。 环境准备 操作系统:确保你使用的…...

ubuntu安装Eclipse
版本 ubuntu16.04 64bitEclipse 2019-12 (太高容易崩溃)下载:wget https://archive.eclipse.org/technology/epp/downloads/release/2019-12/R/eclipse-java-2019-12-R-linux-gtk-x86_64.tar.gzjdk安装 将jdk1.8.0_211-linux-x64.tar.gz解压到…...

C#里怎么样使用线程暂停?
C#里怎么样使用线程暂停? 如果一个线程没有任务在处理,并且又不进行暂停, 这时候,这个线程就会把当前这个CPU占满,即是所谓的死循环。 因此我们设计线程时,一定要知道线程在什么时候没有工作处理时, 就需要进入等待状态,不能再进行下去,否则会导致死循环, 只是耗费…...

畅听FM 3.0.0 | 很有果味的电台软件,超多FM电台,支持播放本地音乐
畅听FM是一款简洁且富有设计感的电台软件,支持收听超多FM电台,还支持播放本地音乐,甚至可以用网址创建音乐源。3.0新版本主要改进了对Android 4.x系统的支持,使得老旧电视和车机也能安装使用,并且新增了横屏显示功能&a…...
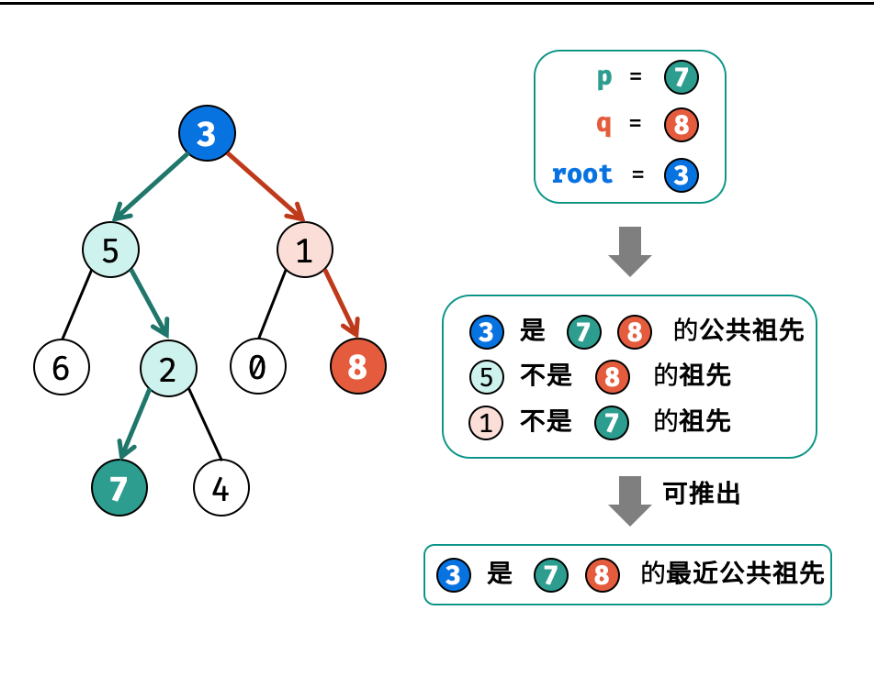
力扣面试经典 150(上)
文章目录 数组/字符串1. 合并两个有序数组2. 移除元素3. 删除有序数组中的重复项4. 删除有序数组的重复项II5. 多数元素6. 轮转数组7. 买卖股票的最佳时机8. 买卖股票的最佳时机II9. 跳跃游戏10. 跳跃游戏II11. H 指数12. O(1)时间插入、删除和获取随机元素13. 除自身以外数组的…...

鸿蒙开发-音视频
Media Kit 特点 一般场合的音视频处理,可以直接使用系统集成的Video组件,不过外观和功能自定义程度低Media kit:轻量媒体引擎,系统资源占用低支持音视频播放/录制,pipeline灵活拼装,插件化扩展source/demu…...

第一个autogen与docker项目
前提条件:在windows上安装docker 代码如下: import os import autogen from autogen import AssistantAgent, UserProxyAgentllm_config {"config_list": [{"model": "GLM-4-Plus","api_key": "your api…...

第三十四篇 MobileNetV1、V2、V3模型解析
摘要 这篇文章将 MobileNetV1、V2、V3汇在一起,解析移动端网络的结构。MobileNet系列的模型是非常经典的模型,值得深入研究一番。 MobileNetV1、V2、V3是MobileNet系列的三个重要版本,它们均针对移动和嵌入式设备进行了优化,具有轻量化、高效能的特点。以下是这三个模型的…...

Python学习——字符串操作方法
mystr “hello word goodbye” str “bye” Find函数:检测一个字符串中是否包含另一个字符串,找到了返回索引值,找不到了返回-1 print(mystr.find(str,0,len(mystr))) print(mystr.find(str,0,13)) index函数:检测一个字符串是否包含另一…...

力扣—15.三数之和
15. 三数之和 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复的三元…...

容器安全检测和渗透测试工具
《Java代码审计》http://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247484219&idx1&sn73564e316a4c9794019f15dd6b3ba9f6&chksmc0e47a67f793f371e9f6a4fbc06e7929cb1480b7320fae34c32563307df3a28aca49d1a4addd&scene21#wechat_redirect Docker-bench-…...

sqlite3自动删除数据的两种设置方式记录
文章概要 〇、背景一、基本思路1.1 按时间分多文件,限制文件的个数1.2 按时间分数据表,限制表的个数1.3 按记录的时间删除超过规定时间数据,限制记录数据的时间1.4 按记录的数据条数删除多余的数据,限制记录数据的个数二、实现代码三、测试方式〇、背景 基于嵌入式编程,在…...

Hive分桶超详细!!!
1、分桶的意义 数据分区可能导致有些分区,数据过多,有些分区,数据极少。分桶是将数据集分解为若干部分(数据文件)的另一种技术。 分区和分桶其实都是对数据更细粒度的管理。当单个分区或者表中的数据越来越大,分区不能细粒度的划分数据时,我…...
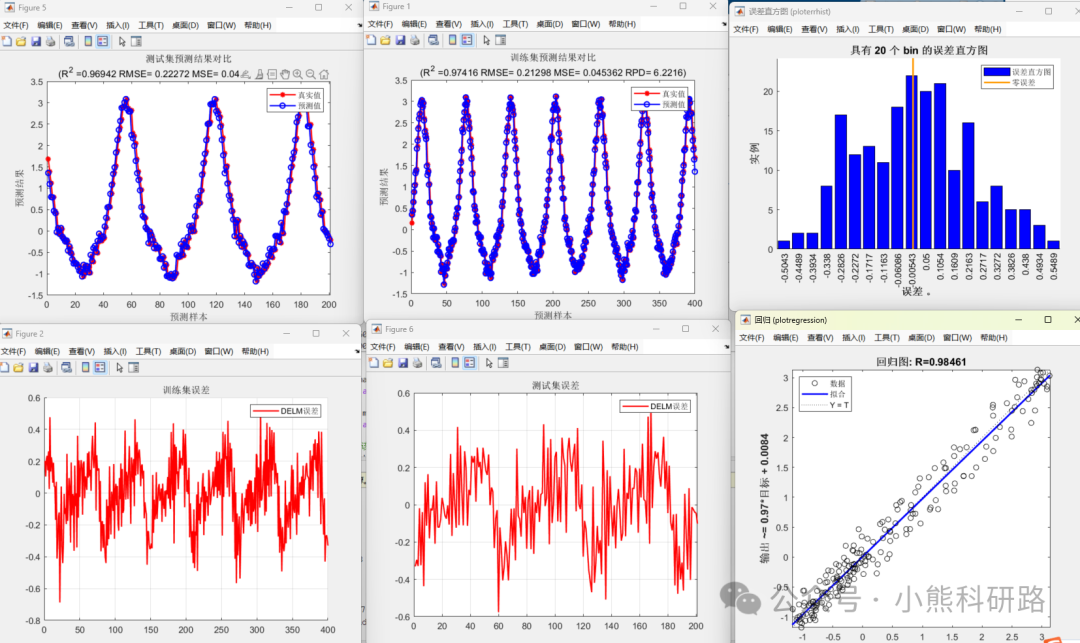
【深度学习之回归预测篇】 深度极限学习机DELM多特征回归拟合预测(Matlab源代码)
深度极限学习机 (DELM) 作为一种新型的深度学习算法,凭借其独特的结构和训练方式,在诸多领域展现出优异的性能。本文将重点探讨DELM在多输入单输出 (MISO) 场景下的应用,深入分析其算法原理、性能特点以及未来发展前景。 1、 DELM算法原理及其…...
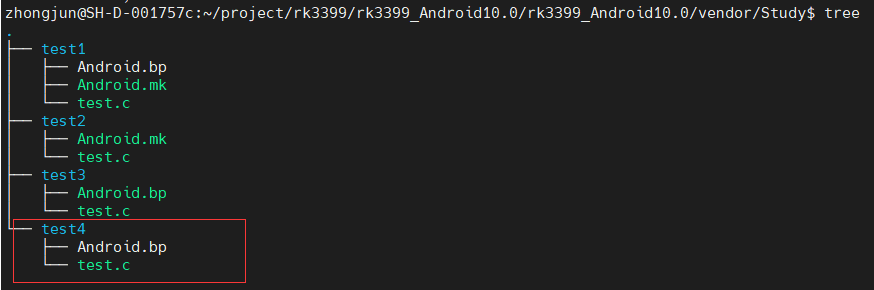
Android mk/bp构建工具介绍
零. 前言 由于Bluedroid的介绍文档有限,以及对Android的一些基本的知识需要了(Android 四大组件/AIDL/Framework/Binder机制/JNI/HIDL等),加上需要掌握的语言包括Java/C/C等,加上网络上其实没有一个完整的介绍Bluedroid系列的文档࿰…...

数据源及分层开发
数据源及分层开发 1. 使用Tomcat数据源 连接池工作原理: 连接池是由容器提供的,用来管理池中连接对象。 连接池自动分配连接对象并对闲置的连接进行回收。 数据源(DataSource): javax.sql.DataSource接口负责建立…...

ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流
ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流 【免费下载链接】ModernWMS The open source simple and complete warehouse management system is derived from our many years of experience in implementing erp projects. We stripped the origin…...

Style-Bert-VITS2未来发展方向:从语音克隆到实时语音转换的技术演进路线
Style-Bert-VITS2未来发展方向:从语音克隆到实时语音转换的技术演进路线 【免费下载链接】Style-Bert-VITS2 Style-Bert-VITS2: Bert-VITS2 with more controllable voice styles. 项目地址: https://gitcode.com/gh_mirrors/st/Style-Bert-VITS2 Style-Bert…...

Unity项目实战:用TriLib插件动态加载FBX模型,5分钟搞定外部资源读取
Unity项目实战:用TriLib插件高效加载外部FBX模型的完整指南在VR展示、产品配置器等需要动态加载用户上传模型的场景中,如何快速实现外部FBX文件的读取是许多Unity开发者面临的挑战。传统的手动导入方式不仅效率低下,更无法满足运行时动态加载…...

AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程
AICoverGen终极指南:快速创建AI翻唱歌曲的完整教程 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想要让你的…...

如何快速掌握ncmdumpGUI:Windows平台网易云音乐NCM文件转换完整教程
如何快速掌握ncmdumpGUI:Windows平台网易云音乐NCM文件转换完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...

告别Selenium?手把手教你用Playwright录制脚本,5分钟搞定Web自动化测试
5分钟极速上手Playwright脚本录制:零代码实现Web自动化测试当产品经理突然丢给你一个刚上线的电商活动页,要求半小时内完成所有核心链路测试时,传统的手写Selenium脚本显然来不及。作为测试工程师,我最近发现微软开源的Playwright…...

无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统
无声输入革命:如何用Chaplin在5分钟内构建本地唇语识别系统 【免费下载链接】chaplin A real-time silent speech recognition tool. 项目地址: https://gitcode.com/gh_mirrors/chapl/chaplin 在嘈杂的办公室、安静的图书馆,或是需要绝对隐私的医…...

大学生零成本副业!SRC 漏洞挖掘入门教程,玩法收益一次性讲清
大学生零成本副业!SRC 漏洞挖掘入门教程,玩法收益一次性讲清 摘要:对大学生来说,找副业最核心的需求是“时间灵活、门槛低、能兼顾学习、有长期成长”,而SRC漏洞挖掘正是完美契合这些需求的选择——无需编程基础、无需…...

TrollInstallerX终极指南:3分钟完成iOS TrollStore安装的强力工具
TrollInstallerX终极指南:3分钟完成iOS TrollStore安装的强力工具 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款专为iOS设备设计的T…...

Windows安卓子系统终极优化指南:如何通过WSABuilds实现完美Android体验
Windows安卓子系统终极优化指南:如何通过WSABuilds实现完美Android体验 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or Ke…...