GMAN解读(论文+代码)
一、注意力机制

注意力机制与传统的卷积神经网络不同的是,前者擅长捕获全局依赖和长程关系,权重会动态调整。而后者对于所有特征都使用同一个卷积核。关于更多注意力机制内容,详见:
注意力机制、自注意力机制、多头注意力机制、通道注意力机制、空间注意力机制超详细讲解-CSDN博客
而本论文基于空间注意力机制,提出了空间和时间注意力机制,以建模动态的时空相关性。
二、GMAN 模型


1. 时空嵌入(Sptio-Tempoal Embedding,STE)
STE 的作用是将图结构和时间信息融入多注意力机制中。
空间嵌入采用Node2Vec方法将N个顶点编码为保留图结构信息的向量,然后将其输入两层全连接神经网络中以进行联合训练。从而可以得到一个 RD 的向量。
时间嵌入而是将每个时间步编码为向量。首先将将一天划分为 T 个时间步,并对每个时间步的“周几”和“时间段”进行独热编码。然后通过两层全连接网络将时间特征也转换为一个 RD 的向量。
最后,对于顶点 vi 和时间步 tj ,STE定义为
![]()
2. 时空注意力模块(ST-Attention Block)
2.1 空间注意力(Spatial Attention)
在传统图卷积GCN中,隐藏状态通过以下方式计算:

其中,A代表图的邻接矩阵,W代表权重。但在实际场景中,不同邻居对目标节点的重要性可能不同。因此,在注意力机制中,通过一个注意力分数 α 表示顶点 v 对顶点 vi 的重要性。那么加入注意力机制后的隐藏状态计算方式如下:

注意力分数 α 的计算方式如下所示:

![]()
式中,|| 表示拼接,< ,> 表示左右两个元素点乘。e 也就是上一步的时空嵌入(STE)。 其代码如下所示:
X = tf.concat((X, STE), axis = -1)query = FC(X, units = D, activations = tf.nn.relu, bn = bn, bn_decay = bn_decay, is_training = is_training)
key = FC(X, units = D, activations = tf.nn.relu, bn = bn, bn_decay = bn_decay, is_training = is_training)# 多头分解(K代表有几个头)
query = tf.concat(tf.split(query, K, axis = -1), axis = 0)
key = tf.concat(tf.split(key, K, axis = -1), axis = 0)# 计算注意力分数
attention = tf.matmul(query, key, transpose_b = True)
attention /= (d ** 0.5)
attention = tf.nn.softmax(attention, axis = -1)2.2 时间注意力(Temporal Attention)
时间注意力和空间注意力的实现方法类似。只有一点不同,空间注意力在空间维度(N)中捕捉节点间的依赖。而时间注意力在时间维度(num_step)中捕捉时间步间的依赖。
作者在这一块的代码部分加入了可选的掩码(mask)。它与因果卷积的作用相同,都是为了解决时间序列建模中的因果性问题,防止未来信息泄露。不同点如下所示:

2.3 门控融合(Gated Fusion)
在某些情况下,交通状况可能主要受空间因素影响(如附近道路拥堵)。在另一些情况下,时间因素可能更为关键(如高峰期的规律性变化)。为了平衡空间和时间注意力的贡献,使得模型可以在不同时空条件下动态调整两者的重要性,作者在这里使用了门控机制。Hs 代表空间注意力机制,Ht 代表时间注意力机制。
![]()
z 是一个门控权重,z 越接近 1,模型越依赖空间注意力输出。反之越接近 0 ,模型越依赖时间注意力输出。其中 z 通过以下公式计算:
![]()
其算法代码如下,
XS = FC(HS, units = D, activations = None,bn = bn, bn_decay = bn_decay,is_training = is_training, use_bias = False)
XT = FC(HT, units = D, activations = None,bn = bn, bn_decay = bn_decay,is_training = is_training, use_bias = True)
z = tf.nn.sigmoid(tf.add(XS, XT))
H = tf.add(tf.multiply(z, HS), tf.multiply(1 - z, HT))
3. 编码器-解码器结构
编码器会接收历史交通数据(比如过去 1 小时的交通流量),将这些时间序列的信息“浓缩”为一个隐藏表示,这个表示概括了所有历史时间步的信息。解码器接收编码器生成的隐藏表示,结合目标预测的要求(比如未来 1 小时的交通流量),逐步生成未来时间步的预测值。
4. 转换注意力(Transform Attention)
在长时间交通预测中,我们不仅需要知道历史的交通状况,还要明白历史的哪些时刻对未来的影响更重要。而转换注意力的作用就是把历史信息直接“映射”到未来,建立一种历史时间步和未来时间步之间的直接联系。比如,要想预测明天早上的交通状况,就要先知道今天早上的交通状况和昨天晚上的交通状况。如果昨天晚上有交通事故,那么一定会影响今天早上的交通状况。最后就可以建立映射关系:
昨天晚上——>今天早上,那么今天晚上——>明天早上。
转换注意力会计算每个历史时间步和每个未来时间步之间的“相关性分数”。这个分数告诉我们某个历史时刻对未来有多重要。然后根据计算出的相关性分数,为未来时间步选择最重要的历史时间步,提取它们的特征信息。最后把这些选出来的历史特征送到解码器,直接生成未来的预测值。
在代码上,transformAttention 和 temporalAttention、spatialAttention 的写法类似,只不过传入的参数有所不同。具体来说,也就是 Query、Key、Value 不同。transformAttention 使用历史时间步(STE_P)和预测时间步(STE_Q) 构建 Query-Key 机制,实现时间序列的转换。
相关文章:

GMAN解读(论文+代码)
一、注意力机制 注意力机制与传统的卷积神经网络不同的是,前者擅长捕获全局依赖和长程关系,权重会动态调整。而后者对于所有特征都使用同一个卷积核。关于更多注意力机制内容,详见: 注意力机制、自注意力机制、多头注意力机制、通…...

速盾:ddos防御手段哪种比较好?高防cdn怎么样?
DDoS(分布式拒绝服务)攻击是一种威胁网络安全的常见攻击手段。为了保护网站和服务器免受DDoS攻击的影响,许多安全专家和公司开发了各种防御手段。在这篇文章中,我们将重点讨论一种常见的DDoS防御手段——高防CDN(内容分…...

Spring:AOP切入点表达式
对于AOP中切入点表达式,我们总共会学习三个内容,分别是语法格式、通配符和书写技巧。 语法格式 首先我们先要明确两个概念: 切入点:要进行增强的方法切入点表达式:要进行增强的方法的描述方式 对于切入点的描述,我们其实是有两中方式的&a…...

《文件操作》
一 . 文本文件和二进制文件 根据数据的组织形式,数据文件被分为了二进制文件和文本文件 数据在内存中是以二进制的形式存储,如果不加转换的输出到外存的文件中,就是二进制文件。 如果要求在外存上以ASCII 码的形式存储,则需要再存…...

python特殊字符序列
字符 描述 \A 只匹配字符串的开始 \b 匹配一个单词边界 \B 匹配一个单词的非边界 \d 匹配任意十进制数字字符,等价于r[0-9] \D 匹配任意非十进制数字字符,等价于r[^0-9]’ \s 匹配任意空格字符(空格符、tab制表符、换…...

卷积神经网络(CNN)中的批量归一化层(Batch Normalization Layer)
批量归一化层(BatchNorm层),或简称为批量归一化(Batch Normalization),是深度学习中常用的一种技术,旨在加速神经网络的训练并提高收敛速度。 一、基本思想 为了让数据在训练过程中保持同一分布…...

LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models 论文解读
目录 一、概述 二、相关工作 1、LLMs到多模态 2、3D对象生成 3、自回归的Mesh生成 三、LLaMA-Mesh 1、3D表示 2、预训练模型 3、有监督的微调数据集 4、数据集演示 四、实验 1、生成的多样性 2、不同模型text-to-Mesh的比较 3、通用语境的评估 一、概述 该论文首…...

【ESP32CAM+Android+C#上位机】ESP32-CAM在STA或AP模式下基于UDP与手机APP或C#上位机进行视频流/图像传输
前言: 本项目实现ESP32-CAM在STA或AP模式下基于UDP与手机APP或C#上位机进行视频流/图像传输。本项目包含有ESP32源码(arduino)、Android手机APP源码以及C#上位机源码,本文对其工程项目的配置使用进行讲解。实战开发,亲测无误。 AP模式,就是ESP32发出一个WIFI/热点提供给电…...

ESP-KeyBoard:基于 ESP32-S3 的三模客制化机械键盘
概述 在这个充满挑战与机遇的数字化时代,键盘已经成为我们日常学习、工作、娱乐生活必不可少的设备。而在众多键盘中,机械键盘,以其独特的触感、清脆的敲击音和经久耐用的特性,已经成为众多游戏玩家和电子工程师的首选。本文将为…...

28.UE5游戏框架,事件分发器,蓝图接口
3-3 虚幻游戏框架拆解,游戏规则基础_哔哩哔哩_bilibili 目录 1.游戏架构 2.事件分发器 2.1UI控件中的事件分发器 2.2Actor蓝图中的事件分发器 2.2.1动态决定Actor的分发事件 2.2.2父类中定义事件分发器,子类实现事件分发器 2.3组件蓝图中实现事件…...

Puppeteer 和 Cheerio 在 Node.js 中的应用
Puppeteer 和 Cheerio 在 Node.js 中的应用 引言 在现代 Web 开发中,自动化测试、数据抓取和页面分析是常见的需求。Node.js 提供了丰富的工具和库来满足这些需求。本文将介绍两个在 Node.js 中常用的库:Puppeteer 和 Cheerio,它们分别用于…...

Unity2D 关于N方向俯视角 中 角色移动朝向的问题
通常对俯视角2d游戏的角色移动我们使用简单2d混合树的方式,但是其不移动时的朝向该如何定义? 十分简单:移动和不移动之间形成逻辑自锁 详细说明思路就是再创建一个简单2d混合树 定义其N方向的idle 并用lastDirc二维向量保存玩家输入,当玩家输…...
` 只能用于只有一个元素的张量. 防止显存爆炸)
pytorch 和tensorflow loss.item()` 只能用于只有一个元素的张量. 防止显存爆炸
loss.item() 是 PyTorch 中的一个方法,它用于从一个只包含单个元素的张量(tensor)中提取出该元素的值,并将其转换为一个 Python 标量(即 int 或 float 类型)。这个方法在训练神经网络时经常用到,…...

链表刷题|判断回文结构
题目来自于牛客网,本文章仅记录学习过程的做题理解,便于梳理思路和复习 我做题喜欢先把时间复杂度和空间复杂度放一边,先得有大概的解决方案,最后如果时间或者空间超了再去优化即可。 思路一:要判断是否为回文结构则…...

海盗王集成网关和商城服务端功能golang版
之前用golang把海盗王的商城服务端和网关服务端都重写了一次。 后来在同时开启网关和商城服务时,发现窗口数量有点多,有时要找到商城窗口比较麻烦。 既然2个都是用golang govcl写的,是不是可以集成到一起,方便使用呢?…...

SCI 中科院分区中位于4区,JCR分区位于Q2 是什么水平?
环境: ACM Transactions on Interactive Intelligent Systems 《Acm Transactions On Interactive Intelligent Systems》(《交互式智能系统上的 Acm 事务》)是一本由ASSOC COMPUTING MACHINERY (ACM)出版的Computer Interaction-Computer Science-Human学术刊物&…...
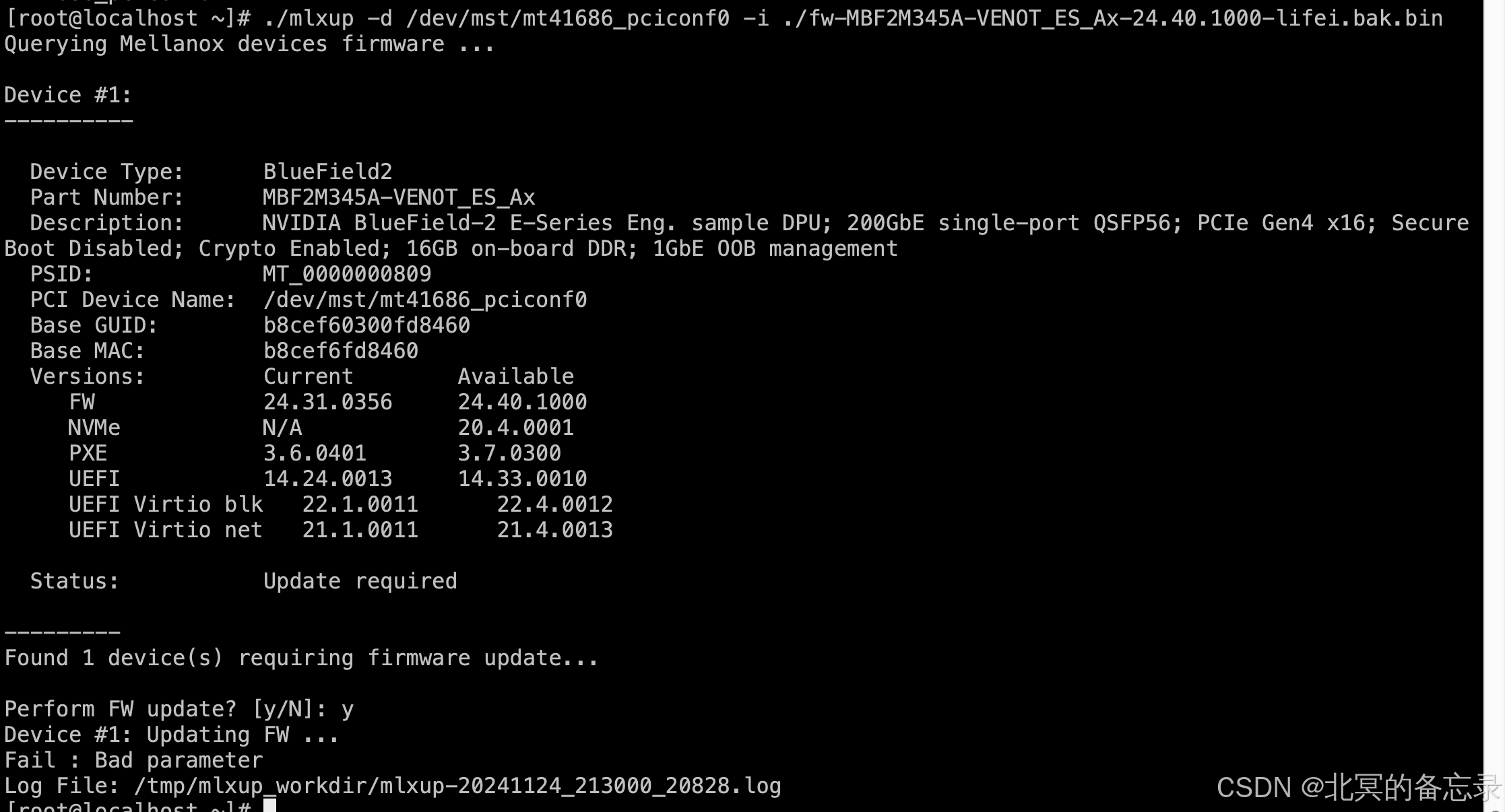
微知-Mellanox网卡的另外一种升级方式mlxup?(mlxup -d xxx -i xxx.bin)
背景 一般升级Mellanox网卡使用flint,还有另外一种叫做mlxup。 NVIDIA 提供了两种固件工具来更新和查询适配器固件: MLXUP - 固件更新和查询实用程序。该实用程序允许扫描服务器计算机以查找可用的 NVIDIA 适配器,并指示每个适配器是否需要…...

《Shader入门精要》透明效果
代码以及实例图可以看github :zaizai77/Shader-Learn: 实现一些书里讲到的shader 在实时渲染中要实现透明效果,通常会在渲染模型时控制它的透明通道(Alpha Channel)。当开启透明混合后,当一个物体被渲染到屏幕上时&…...

Linux之SELinux与防火墙
一、SELinux的说明 开发背景与目的: SELinux由美国国家安全局(NSA)开发,旨在避免资源的误用。传统的Linux基于自主访问控制(DAC),通过判断进程所有者/用户组与文件权限来控制访问,对…...

深度学习使用LSTM实现时间序列预测
大家好,LSTM是一种特殊的循环神经网络(RNN)架构,它被设计用来解决传统RNN在处理长序列数据时的梯度消失和梯度爆炸问题,特别是在时间序列预测、自然语言处理和语音识别等领域中表现出色。LSTM的核心在于其独特的门控机…...
)
ChatGPT生成内容同质化困局破局术:用故事化表达重构人机协作范式(仅限首批200位读者获取的叙事权重矩阵)
更多请点击: https://codechina.net 第一章:叙事权重矩阵的底层逻辑与人机协作范式跃迁 叙事权重矩阵并非传统意义上的数值张量,而是一种动态语义映射结构,它将人类叙事意图、上下文可信度、模型生成置信度及跨模态对齐信号统一编…...
)
DeepSeek模型越狱攻击实录与反制(2024最新0day漏洞封堵手册)
更多请点击: https://kaifayun.com 第一章:DeepSeek模型安全加固概述 DeepSeek系列大语言模型在开源生态中广泛应用,但其默认部署配置存在若干潜在安全风险,包括未授权API访问、提示注入攻击面暴露、敏感信息泄露通道及权重文件未…...

从 ROI 看:什么时候只用单 Agent 更优
从 ROI 看:什么时候只用单 Agent 更优一、 引言 (Introduction) 1.1 钩子 (The Hook) 你有没有见过这样的项目场景? 场景1:创业公司MVP阶段 小团队只有2个算法工程师、1个全栈,预算只有30万/月的云服务和人力折算(算法…...

企业如何利用 Taotoken 为内部知识问答系统集成大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业如何利用 Taotoken 为内部知识问答系统集成大模型 构建一个高效、可靠的内部知识问答系统,是企业提升信息流转效率…...
)
跟着 MDN 学CSS day_14:(尺寸调整技能测试与实战解析)
在掌握了 CSS 元素尺寸调整的理论知识之后,实际动手练习是检验理解程度的最佳方式。MDN 的"Test your skills: Sizing"这一节提供了三个精心设计的任务,分别覆盖了最小高度与固定高度的区别、百分比宽度与内边距在 border-box 模型下的计算、以…...

为Nodejs后端服务配置Taotoken多模型聚合API调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Nodejs后端服务配置Taotoken多模型聚合API调用 基础教程类,指导Nodejs开发者将Taotoken服务集成到现有后端项目中&am…...

基于个性化机器学习与智能穿戴数据的痴呆症行为预测系统
1. 项目概述:当智能手表学会“预见”痴呆症患者的情绪风暴在痴呆症照护的漫长征途中,照护者最棘手的挑战往往不是记忆的衰退,而是那些突如其来、难以捉摸的行为与心理症状。想象一下,你照顾的长辈平时温和安静,却在某个…...

基于SpringBoot的技术博客与开源知识分享平台毕设
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot技术栈的技术博客与开源知识分享平台以解决传统知识传播模式中存在的信息孤岛现象与协作效率低下问题。随着信息技术的快速发…...

如何永久保存微信聊天记录?这款开源工具帮你一键导出并生成年度报告!
如何永久保存微信聊天记录?这款开源工具帮你一键导出并生成年度报告! 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com…...

MindSpore 适配 NPU 的全链路解析——从算子注册到端到端性能调优
MindSpore 怎么在 NPU 上跑起来?不是简单的「编译运行」,而是从前端算子注册、后端算子选择、内存分配、到通信库对接的全链路适配。这篇文章把这整套流程拆开讲清楚。 上周有个 MindSpore 的用户问我:「为什么我的网络在 GPU 上能跑…...