Elastic Cloud Serverless:深入探讨大规模自动扩展和性能压力测试
作者:来自 Elastic David Brimley, Jason Bryan, Gareth Ellis 及 Stewart Miles

深入了解 Elasticsearch Cloud Serverless 如何动态扩展以处理海量数据和复杂查询。我们探索其在实际条件下的性能,深入了解其可靠性、效率和可扩展性。
简介
Elastic Cloud Serverless 的出现重塑了企业如何利用 Elasticsearch 的强大功能,而无需管理集群、节点或资源扩展。Elastic Cloud Serverless 的一项关键创新是其自动扩展功能,该功能可实时适应工作负载和流量的变化。本文探讨了自动扩展背后的技术细节、Elastic Cloud Serverless 在负载下的性能以及大量压力测试的结果。
什么是 Elastic Cloud Serverless?
Elastic Cloud Serverless 提供自动化、托管版本的 Elasticsearch,可根据需求进行扩展。与传统的 Elasticsearch 部署(用户必须配置和管理硬件或云实例)不同,Elastic Cloud Serverless 可管理基础设施扩展和资源分配。这对于工作负载多变的组织尤其有益,因为手动扩展和缩减基础设施可能很麻烦且容易出错。该系统的内置自动扩展功能可适应繁重的提取任务、搜索查询和其他操作,无需人工干预。
Elastic Cloud Serverless 有两个不同的层级,即搜索层(search tier)和索引层(indexing tier),每个层级都针对特定工作负载进行了优化。搜索层专用于处理查询执行,确保快速高效地响应搜索请求。同时,索引层负责提取和处理数据、管理写入操作以及确保数据正确存储和可搜索。通过解耦这些问题,Elastic Cloud Serverless 允许每个层根据工作负载需求独立扩展。这种分离提高了资源效率,因为索引的计算和存储需求(例如,处理高吞吐量提取)不会干扰搜索操作期间的查询性能。同样,搜索层资源可以扩展以处理复杂查询或流量高峰,而不会影响提取过程。这种架构可确保最佳性能、成本效益和弹性,使 Elastic Cloud Serverless 能够动态适应波动的工作负载,同时保持一致的用户体验。

你可以在以下博客文章中阅读有关 Elastic Cloud Serverless 架构的更多信息。
压力测试 Elastic Cloud Serverless
全面的压力测试评估了 Elastic Cloud Serverless 处理大量波动工作负载的能力。这些测试旨在衡量系统提取数据、处理搜索查询以及在极端条件下保持性能的能力。需要注意的是,系统的性能可能超出我们在此处介绍的范围,具体取决于客户端数量和批量索引大小等因素。在这里,我们将介绍这些测试的方法和结果。
测试范围和方法
我们压力测试的主要目标是回答关键问题:
- Elastic Cloud Serverless 如何处理大量并发客户端的大规模提取和搜索查询?
- 它能否动态扩展以适应工作负载的突然激增?
- 系统是否在较长时间内保持稳定性?
对搜索用例进行压力测试。
在 Elastic Cloud Serverless 中,你可以从三种项目类型中进行选择:Elasticsearch、可观察性和安全性。我们使用 Github Archive 数据集并模拟可能的摄取和搜索行为,开始了对 Elasticsearch 搜索用例的压力测试之旅。在测试之前,我们通过摄取 186GB/4300 万个文档的基础语料库来准备系统。然后,我们在十分钟内逐渐添加客户端,以便 Elasticsearch 有时间适当扩展。数据是通过 Bulk API 使用 Datastreams 摄取的。
对索引层进行压力测试。
首先,让我们谈谈索引数据(摄取)。Elastic Cloud Serverless 中的摄取自动扩展会动态调整资源以满足数据摄取需求,从而确保最佳性能和成本效益。系统持续监控摄取吞吐量、资源利用率(CPU、内存和网络)和响应延迟等指标。当这些指标超过预定义的阈值时,自动扩缩器会按比例提供额外的容量来处理当前和预期的需求,同时为意外峰值保留缓冲。数据管道的复杂性和系统施加的资源限制也会影响扩展决策。通过动态添加或删除容量,摄取自动扩缩可确保无缝扩展而无需人工干预。
在 Elastic Cloud Serverless 等资源效率得到优化的自动扩缩系统中,可能会出现工作负载突然大幅增加超出系统立即扩展的能力的情况。在这种情况下,客户端可能会收到 HTTP 429 状态代码,表示系统不堪重负。为了处理这些情况,客户端应实施指数退避策略,以逐渐延长的间隔重试请求。在压力测试期间,我们会主动跟踪 429 响应,以评估系统在高需求下的反应,从而提供有关自动扩缩有效性的宝贵见解。你可以在此处阅读有关我们如何自动扩缩索引的更深入的博客文章。现在,让我们看看我们在索引层的压力测试中遇到的一些结果。
在扩大规模的同时建立索引:
| Corpus | Bulk Size | Actual Volume | Indexing Period (minutes) | Volume / hr | Median Throughput (docs/s) | 90th PCT Indexing latency (seconds) | Avg. % Error Rate (429s, other) |
|---|---|---|---|---|---|---|---|
| 1TB | 2500 | 1117.43 GB | 63 | 1064.22 GB | 70,256.96 | 7.095 | 0.05% |
| 2TB | 2500 | 2162.02 GB | 122 | 1063.29 GB | 68,365.23 | 8.148 | 0.05% |
| 5TB | 2500 | 5254.84 GB | 272 | 1159.16 GB | 74,770.27 | 7.46 | 0 |
对于 1TB 和 2TB 语料库的初始测试,我们分别实现了 1064 GB/小时和 1063 GB/小时的吞吐量。对于 5TB,我们实现了更高的 1160 GB/小时的摄取速度,因为我们观察到摄取层继续扩大,从而提供了更好的吞吐量。
在完全扩展的情况下进行索引:
| Clients | Bulk Size | Actual Volume | Duration | Volume / hr | Median Throughput (docs/s) | 99th PCT Indexing latency (seconds) | Avg. % Error Rate (429s, other) |
|---|---|---|---|---|---|---|---|
| 3,000 | 2,000 | 1 TB | 8 minutes | 7.5 TB | 499,000 | 33.5 | 0.0% |
使用最大规模的索引层时,ECS 在 8 分钟内提取了 1TB 的数据,每秒索引的速率约为 499K 文档/秒。这相当于每天 180TB 的推断容量。
从最小规模到最大规模的索引:
| Clients | Bulk Size | Actual Volume | Duration | Volume / hr | Median Throughput (docs/s) | 99th PCT Indexing latency (seconds) | Avg. % Error Rate (429s, other) |
|---|---|---|---|---|---|---|---|
| 2,048 | 1,000 | 13 TB | 6 hours | 2.1 TB | 146,478 | 55.5 | 1.55% |
在对 2TB 数据进行测试时,我们逐渐扩展到 2048 个客户端,并设法以每秒 146K 文档的速度提取数据,在 1 小时内完成 2TB 的数据。推算下来,每天的数据量为 48TB。
72 小时稳定性测试:
| Clients | Bulk Size | Actual Volume | Indexing Period (hours) | Volume / hr | Median Throughput (docs/s) | 99th PCT Indexing latency (seconds) | Avg. % Error Rate (429s, other) |
|---|---|---|---|---|---|---|---|
| 128 | 500 | 61 TB | 72 | ~868.6 GB | 51,700 | 7.7 | <0.05% |
在 72 小时的稳定性测试中,我们使用 128 个客户端提取了 60TB 的数据。Elasticsearch 在扩展索引和搜索层的同时,保持了令人印象深刻的 870GB/小时的吞吐量,错误率极低。这证明了 Elasticsearch 能够在较长时间内保持高吞吐量,同时保持较低的故障率。
对搜索层进行压力测试。
Elastic Cloud Serverless 中的搜索层自动扩展功能会根据数据集大小和搜索负载动态调整资源,以保持最佳性能。系统将数据分为两类:增强型和非增强型。增强型数据包括用户定义的增强窗口内的基于时间的文档(带有 @timestamp 字段的文档)和所有非基于时间的文档,而非增强型数据则不在此窗口内。用户可以设置增强窗口来定义增强数据的时间范围,并选择搜索能力级别(按需、高性能或高吞吐量)来控制资源分配。你可以在此处阅读有关配置搜索能力和搜索增强窗口的更多信息。
自动扩展器监控查询延迟、资源利用率(CPU 和内存)和查询队列长度等指标。当这些指标表明需求增加时,系统会相应地扩展资源。此扩展是按项目执行的,对最终用户是透明的。
负载下的搜索稳定性:
| Corpus | Actual Volume (from corpus tab) | Duration | Average Search Rate (req/s) | Max Search Rate (req/s) | Response Time (P50) | Response Time (P99) |
|---|---|---|---|---|---|---|
| 5TB | 5254.84 GB | 120 minutes | 891 | 3,158 | 36 ms | 316 ms |
使用 5TB 的数据,我们测试了一组运行超过 2 小时的 8 次搜索,包括复杂查询、聚合和 ES|QL。每次搜索的客户端数量从 4 个增加到 64 个。总共有 32 到 512 个客户端执行搜索。随着客户端数量从 32 个增加到 512 个,性能保持稳定。当使用 512 个客户端运行时,我们观察到搜索请求率为每秒 3,158 个查询,P50 响应时间为 36 毫秒。在整个测试过程中,我们观察到搜索层扩展符合预期,可以满足需求。
24 小时搜索稳定性测试:
| Corpus | Actual Volume | Duration | Average Search Rate (req/s) | Max Search Rate (req/s) | Response Time (P50) | Response Time (P99) |
|---|---|---|---|---|---|---|
| 40TB | 60 TB | 24 hours | 183 | 250 | 192 ms | 520 ms |
一组 7 次搜索、聚合和一个 ES|QL 查询用于查询 40TB(主要是)增强数据。客户端数量从每次搜索 1 个增加到 12 个,总共 7 个到 84 个搜索客户端。在将搜索能力设置为平衡的情况下,我们观察到 192 毫秒(P50)的响应时间。你可以在此处阅读有关配置搜索能力和搜索增强窗口的更多信息。
并发索引和搜索
在同时运行索引和搜索的测试中,我们的目标是以 6 个“chunks/块”的形式提取 5TB。我们将提取数据的客户端从 24 个增加到 480 个,批量大小为 2500 个文档。对于搜索,客户端从每次搜索 2 个增加到 40 个。总共有 16 到 320 个客户端执行搜索。
我们观察到两个层级都自动扩展,并且搜索延迟始终保持在 24 毫秒(p50)和 1359 毫秒(p99)左右。系统在保持性能的同时进行索引和搜索的能力对于许多用例至关重要。
结论
上面讨论的压力测试侧重于 Elasticsearch 项目中的搜索用例,该项目设计为具有特定字段类型、字段数量、客户端和批量大小的配置。这些参数经过量身定制,以在与用例相关的明确条件下评估 Elastic Cloud Serverless,从而提供有关其性能的宝贵见解。但是,需要注意的是,结果可能无法直接反映你的工作负载,因为性能取决于各种因素,例如查询复杂性、数据结构和索引策略。
这些基准作为基准,但实际结果将根据你的独特用例和要求而有所不同。还应注意,这些结果并不代表性能上限。
我们压力测试的关键结论是 Elastic Cloud Serverless 表现出非凡的稳健性。它每天可以提取数百 TB 的数据,同时保持强大的搜索性能。这使其成为大规模搜索工作负载的强大解决方案,可确保高数据量下的可靠性和效率。在即将发布的文章中,我们将进一步探索对 Elastic Cloud Serverless 进行压力测试,以实现可观察性和安全性用例,重点介绍其在不同应用领域的多功能性,并深入了解其功能。
了解有关 Elastic Cloud Serverless 的更多信息,并开始 14 天免费试用,亲自测试一下。
原文:Elastic Cloud Serverless: A Deep Dive into Autoscaling and Performance Stress Testing at Scale - Search Labs
相关文章:
Elastic Cloud Serverless:深入探讨大规模自动扩展和性能压力测试
作者:来自 Elastic David Brimley, Jason Bryan, Gareth Ellis 及 Stewart Miles 深入了解 Elasticsearch Cloud Serverless 如何动态扩展以处理海量数据和复杂查询。我们探索其在实际条件下的性能,深入了解其可靠性、效率和可扩展性。 简介 Elastic Cl…...

新一代零样本无训练目标检测
🏡作者主页:点击! 🤖编程探索专栏:点击! ⏰️创作时间:2024年12月2日21点02分 神秘男子影, 秘而不宣藏。 泣意深不见, 男子自持重, 子夜独自沉。 论文链接 点击开启你的论文编程之旅h…...

es 3期 第13节-多条件组合查询实战运用
#### 1.Elasticsearch是数据库,不是普通的Java应用程序,传统数据库需要的硬件资源同样需要,提升性能最有效的就是升级硬件。 #### 2.Elasticsearch是文档型数据库,不是关系型数据库,不具备严格的ACID事务特性ÿ…...

全局token验证
全局token验证 简介 通俗地说,JWT的本质就是一个字符串,它是将用户信息保存到一个Json字符串中,然后进行编码后得到一个JWT token,并且这个JWT token带有签名信息,接收后可以校验是否被篡改,所以可以用…...

实时美颜技术详解:美颜SDK与直播APP开发实践
通过集成美颜SDK(软件开发工具包),开发者能够轻松为直播APP提供实时美颜效果,改善用户的直播体验。本篇文章,小编将深入探讨实时美颜技术,重点分析美颜SDK的核心技术及其在直播APP中的应用实践。 一、实时…...
电子应用设计方案-41:智能微波炉系统方案设计
智能微波炉系统方案设计 一、引言 随着科技的不断进步,人们对于厨房电器的智能化需求日益增长。智能微波炉作为现代厨房中的重要设备,应具备更便捷、高效、个性化的功能,以满足用户多样化的烹饪需求。 二、系统概述 1. 系统目标 - 提供精确…...

P5736 【深基7.例2】质数筛
题目描述 输入 𝑛个不大于 105 的正整数。要求全部储存在数组中,去除掉不是质数的数字,依次输出剩余的质数。 输入格式 第一行输入一个正整数 𝑛,表示整数个数。 第二行输入 𝑛 个正整数 𝑎…...

数据结构初阶1 时间复杂度和空间复杂度
本章重点 算法效率时间复杂度空间复杂度常见时间复杂度以及复杂度OJ练习 1.算法效率 1.1 如何衡量一个算法的好坏 如何衡量一个算法的好坏呢?比如对于以下斐波那契数列: long long Fib(int N) { if(N < 3) return 1;return Fib(N-1) Fib(N-2); }斐…...

E130 PHP+MYSQL+动漫门户网站的设计与实现 视频网站系统 在线点播视频 源码 配置 文档 全套资料
动漫门户网站 1.摘要2. 开发背景和意义3.项目功能4.界面展示5.源码获取 1.摘要 21世纪是信息的时代,随着信息技术与网络技术的发展,其已经渗透到人们日常生活的方方面面,与人们是日常生活已经建立密不可分的联系。本网站利用Internet网络, M…...

OSCP - Proving Grounds - Fanatastic
主要知识点 CVE-2021-43798漏洞利用 具体步骤 执行nmap 扫描,22/3000/9090端口开放,应该是ssh,grafana 和Prometheus Nmap scan report for 192.168.52.181 Host is up (0.00081s latency). Not shown: 65532 closed tcp ports (reset) PORT STA…...
ArcMap 分享统计点要素、路网、降雨量等功能操作
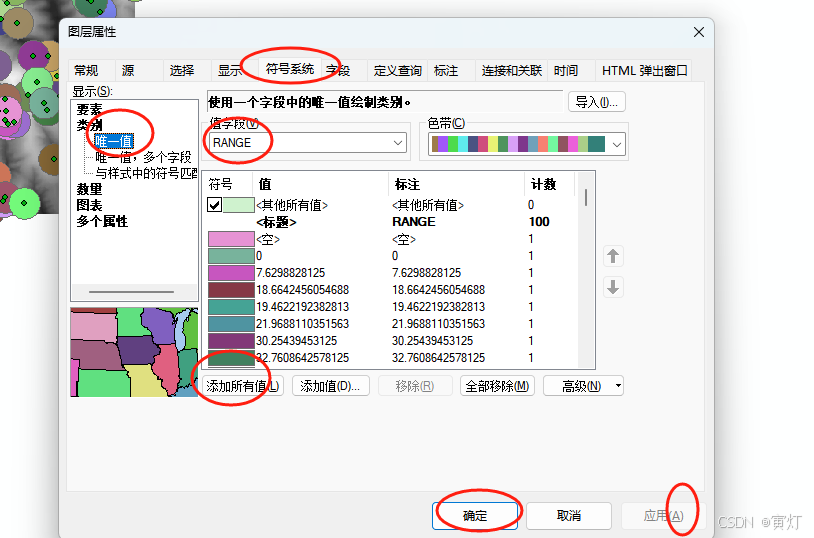
ArcMap 分享统计点要素、路网等功能等功能操作今天进行 一、按格网统计点要素 1、创建公里网格统计单元 点击确定后展示 打开连接 点击后 展示 2、处理属性 1)查看属性表 每个小格都统计出了点的数量 2)查看属性 符号系统 点击应用后展示结果&#x…...

概率论——假设检验
解题步骤: 1、提出假设H0和H1 2、定类型,摆公式 3、计算统计量和拒绝域 4、定论、总结 Z检验 条件: 对μ进行检验,并且总体方差已知道 例题: 1、假设H0为可以认为是570N,H1为不可以认为是570N 2、Z…...

爬虫项目练手
python抓取优美图库小姐姐图片 整体功能概述 这段 Python 代码定义了一个名为 ImageDownloader 的类,其主要目的是从指定网站(https://www.umei.cc)上按照不同的图片分类,爬取图片并保存到本地相应的文件夹中。不过需要注意&…...

C程序设计:解决Fibonacci.数列问题
‘ 斐波那契数列(Fibonacci sequence),又称黄金分割数列,因数学家莱昂纳多斐波那契(Leonardo Fibonacci)以兔子繁殖为例子而引入,故又称“兔子数列”,其数值为:1、1、2、…...

35页PDF | 元数据与数据血缘落地实施(限免下载)
一、前言 这份报告详细介绍了元数据与数据血缘的概念、重要性以及在企业数据中台中的应用。报告阐述了数据中台的核心价值在于整合和管理体系内的数据,以提升数据资产化能力并支持业务决策。报告还涵盖了元数据的分类(技术元数据和业务元数据࿰…...

Lua元表和元方法的使用
元表是一个普通的 Lua 表,包含一组元方法,这些元方法与 Lua 中的事件相关联。事件发生在 Lua 执行某些操作时,例如加法、字符串连接、比较等。元方法是普通的 Lua 函数,在特定事件发生时被调用。 元表包含了以下元方法࿱…...

基于Pyhton的人脸识别(Python 3.12+face_recognition库)
使用Python进行人脸编码和比较 简介 在这个教程中,我们将学习如何使用Python和face_recognition库来加载图像、提取人脸编码,并比较两个人脸是否相似。face_recognition库是一个强大的工具,它基于dlib的深度学习模型,可以轻松实…...

Spring Boot+Netty
因工作中需要给第三方屏幕厂家下发广告,音频,图片等内容,对方提供TCP接口于是我使用Netty长链接进行数据传输 1.添加依赖 <!-- netty依赖--><dependency><groupId>io.netty</groupId><artifactId>netty-all&…...

LCR 023. 相交链表
一.题目: LCR 023. 相交链表 - 力扣(LeetCode) 二.我的原始解法-无: 三.其他人的正确及好的解法,力扣解法参考: 哈希表法及双指针法:LCR 023. 相交链表 - 力扣(LeetCode࿰…...

Linux命令行下载工具
1. curl 1.1. 介绍 curl是一个功能强大的命令行工具,用于在各种网络协议下传输数据。它支持多种协议,包括但不限于 HTTP、HTTPS、FTP、FTPS、SCP、SFTP、SMTP、POP3、IMAP 等,这使得它在网络数据交互场景中有广泛的应用。curl可以模拟浏览器…...

新手创业是注册公司好还是注册个体户好?
很多刚准备创业的朋友,最先纠结的问题就是:我到底是注册个体工商户,还是直接注册有限公司?一、先搞懂最核心的本质区别个体户属于个人经营模式,承担无限连带责任,简单说就是生意出问题,个人资产…...

零代码脚本神器:熊猫精灵脚本助手V3.6.4 --Ai找图找色多窗口驱动点击键鼠录制适合游戏自动化办公操作
🛠️ 软件核心定位熊猫精灵脚本助手V3.6.4是一款零代码可视化的自动化工具,主打后台多窗口异步操作,无需编程基础就能实现复杂的自动化流程,覆盖办公、游戏、模拟器、手机投屏等多场景需求,兼容Win7及以上系统…...

Claude Code 上下文管理机制深度拆解:超长 Agent 任务如何不崩盘
在一个真正复杂的企业级软件设计与编码任务里,Coding Agent 面对的从来不是一句简单的“帮我写个小游戏”。 它要理解用户的原始需求,要读取项目里的既有代码,要遵守架构约束、编码规范、接口协议,还要调用各种工具、加载不同的技能和规则,甚至记住用户十分钟前随口补充的…...

OAuth 接入DeepSeek总失败?这3类JWT签名验证错误正在 silently 拒绝你的请求,速查!
更多请点击: https://kaifayun.com 第一章:OAuth 接入DeepSeek总失败?这3类JWT签名验证错误正在 silently 拒绝你的请求,速查! 当你调用 DeepSeek 的 OAuth 2.0 接口(如 /v1/auth/token)时&am…...

Perplexity语言学习资源实战手册:7天掌握高效外语输入+输出闭环的3大核心技巧
更多请点击: https://intelliparadigm.com 第一章:Perplexity语言学习资源的核心定位与适用场景 Perplexity 作为一款以深度推理与实时信息整合见长的AI协作工具,其语言学习资源并非传统词典或语法教程的简单复刻,而是聚焦于**真…...

别只会用!cat了:在Kaggle Notebook里动态编辑YOLOv5配置文件的完整攻略
突破Kaggle只读限制:YOLOv5配置文件动态编辑全指南 在Kaggle Notebook中进行计算机视觉项目开发时,许多开发者都遇到过这样的困境:当需要修改YOLOv5模型配置文件时,发现Kaggle的/kaggle/input目录是只读的。本文将介绍三种专业级解…...

初创公司如何利用Taotoken管理多模型API成本与用量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创公司如何利用Taotoken管理多模型API成本与用量 对于初创公司而言,在有限的预算内高效利用大模型能力是技术决策的关…...

GIFT高级技巧:图像组合、并行处理和性能优化的终极指南
GIFT高级技巧:图像组合、并行处理和性能优化的终极指南 【免费下载链接】gift Go Image Filtering Toolkit 项目地址: https://gitcode.com/gh_mirrors/gi/gift GIFT(Go Image Filtering Toolkit)是一个强大的Go语言图像处理库&#x…...

告别熬夜做答辩 PPT!用 paperxie 一键把毕业论文转成专业演示稿
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 谁写毕业论文没被答辩 PPT 搞崩过心态?对着万字论文抠重点、调排版、找模板,半天时间耗在「做 PPT」…...
)
用C++模拟流感传播:从信息学奥赛题到理解传染病模型(附完整代码)
用C模拟流感传播:从信息学奥赛题到理解传染病模型(附完整代码) 流感传播模型一直是计算机模拟和算法竞赛中的经典问题。这道来自信息学奥赛的题目不仅考察了递推算法的应用,更让我们得以一窥传染病传播的基本原理。本文将带你从零…...