es 3期 第13节-多条件组合查询实战运用
#### 1.Elasticsearch是数据库,不是普通的Java应用程序,传统数据库需要的硬件资源同样需要,提升性能最有效的就是升级硬件。
#### 2.Elasticsearch是文档型数据库,不是关系型数据库,不具备严格的ACID事务特性,任何企图直接替代严格事务性场景的应用项目都会失败!!!
##### 索引字段与属性都属于静态设置,若后期变更历史数据需要重建索引才可生效
##### 对历史数据无效!!!!
##### 一定要重建索引!!!!
### 组合查询分类
## bool:布尔组合
## boost:加权
## constant:固定分值
## dis_max:单字符多字段组合
## function:函数脚本组合
## bool 逻辑条件
## bool逻辑条件是组合查询,最常用的,也是必须掌握的,DSL查询与SQL不一,传统查询里面的多条件组合通过观关键字组合,这里采用的是以下关键字
# 关键字 说明
# must 必须包含,类同Mysq1关键字 and ,计算分值
# should 可选包含,类同 Mysql关键字 or
# filter 必须包含,类同Mysql关键字 and,不计算分值
# must not 不包含,类同 Mysql 不等于关键字
# mixed 水平组合 混合以上,类同Mysgl多个条件平级组合
# mixed 嵌套组合 混合以上,类同Mysgl 多个括号组合条件
DELETE kibana_sample_data_flights_reindex
# 复制一份航班数据用于查询
# reindex后新索引字段是推断出来的,原来的keyword类型会被推断为text
POST _reindex
{"source": {"index": "kibana_sample_data_flights"},"dest": {"index": "kibana_sample_data_flights_reindex"}
}
GET kibana_sample_data_flights
GET kibana_sample_data_flights_reindex## 最多支持1024个条件,有时候需要反思,如果业务上有这么多入参条件是否合理
# must 在数组里面2个字段是and的关系
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits":true,# query 是DSL的入口"query":{"bool": {"must": [{"match": {"Dest":"Warsaw"}},{"match": {"DestWeather": "Rain"}}]}}
}# should 满足任意一个即可,等同于or,注意观察第二个查询total是增加的
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits":true,"query":{"bool": {"should": [{"match": {"Dest":"Warsaw"}}]}}
}
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits":true,"query":{"bool": {"should": [{"match": {"Dest":"Warsaw"}},{"match": {"DestWeather": "Rain"}}]}}
}# filter,类同于must,不过不计算分值,效率比must高,背后采用RaoringBitmap算法高效查询检索
# 这个使用是最多的,一般用来解决mysql的查询瓶颈
# 主要掌握这个就可以了!!!
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits":true,"query":{"bool": {"filter": [{"match": {"Dest":"Warsaw"}},{"match": {"DestWeather": "Rain"}}]}}
}# must_not 与must相反,反向选择不符合条件的结果
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits":true,"query":{"bool": {"must_not": [{"match": {"Dest":"Warsaw"}},{"match": {"DestWeather": "Rain"}}]}}
}# mixed 混合,水平组合,es可以说为每种字段类型都定义了查询语法
# 不同于mysql的索引,查询条件的先后不会影响查询结果和效率
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits":true,"query":{"bool": {"must": [{"match": {"Dest": "Genoa"}}], "must_not": [{"match": {"Dest":"Warsaw"}},{"match": {"DestWeather": "Rain"}}]}}
}# mixed 混合,嵌套组合,类同Mysgl 多个括号组合条件
# 可以一直嵌套,但是不推荐,不利于解析和阅读
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits":true,"query":{"bool": {"must": [{"match": {"Dest": "Genoa"}},{"bool": {"must_not": [{"match": {"DestWeather": "Sunny"}}]}}]}}
}## boost 加权组合查询,需要深度学习,这里为入门,适用于text字段
## 给部分字段增加分值权重,以此来影响分词查询排序
## ES 查询默认排序,采取的是依据关键字的关联度计算分值,默认算法是 BM25,多个字段查询时,可以跟不同的字段设定不同的权重,来调整排序。
# 权重组合应用
# 正向加权,就是增加此字段的权重,一般为正值
# 反向加权,就是降低此字段的权重,一般为小于1或者负值
# boosting,关键字
# positive,关键字,正向
# negative,关键字,反向
# negative_boost,关键字,用于降低反向加权的权重比值,取值范围 0~1之间
# boost,关键字,查询时使用,默认1,设置字段分值比重
# 查询1,标准分值
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits":true,"query":{"bool": {"must_not": [{"match": {"Dest":"Warsaw"}},{"match": {"DestWeather": "Rain"}}]}}
}
# 查询2,negative_boost=0
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits": true,"query": {"boosting": {"positive": {"match": {"Dest": "Warsaw"}},"negative": {"match": {"DestWeather": "Rain"}},"negative_boost": 0}}
}
# 查询3,negative_boost=2
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits": true,"query": {"boosting": {"positive": {"match": {"Dest": "Warsaw"}},"negative": {"match": {"DestWeather": "Rain"}},"negative_boost": 2}}
}
# 查询4,negative_boost=0.5
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits":true,"query":{"bool": {"must": [{"match": {"Dest": "Genoa"}},{"bool": {"must_not": [{"match": {"DestWeather": {"query": "Sunny","boost": 0.2 // 使用 negative_boost 降低不包含 "Sunny" 标签的文档的得分}}}]}}]}}
}
# 7.0版本以上不支持,静态加权方式,创建mapping时设置
DELETE device-001
PUT device-001
{"settings": {"refresh_interval": "15s","number_of_shards": 1},"mappings": {"properties": {"devId": {"type": "keyword"},"devName": {"type": "text","boost": 2},"devNameExt": {"type": "text","boost": 0.2}}}
}## constant:固定分值
## 多字段组合查询,数据排序依赖很多字段共同的分值,有些不必要的字段,可以设定一个固定值,仅仅用来作为过滤条件,防止过度干预排序分值计算,从而影响排序
## 依赖filter查询模式
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits": true,"query": {"constant_score": {"filter": {"match": {"Dest": "Warsaw"}},"boost": 1.2}}
}## disiunction 最大分值多条件查询中,提取其中分值最高的,作为影响数据排序的因子
## 应用领域
## 多字段查询检索领域,有很多字段可以同时作为检索条件,但排序时,只要运用其中分值最高的那个用来排序即可,比如电商"商品标题"与"商品简要描述"
## dis_max 查询
## dis_max,关键字,最大值查询入口
## tie_breaker,关键字,最大分值增加分值,在原有的基础之上增加 多少,百分比,取值范围 0~1,默认 0.0
## boost,关键字,最大分值乘以权重,直接在原有分值上乘以权重值,默认 1=100%
## queries,关键字,组合多个查询条件,注意是should 关系
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits": true,"query": {"dis_max": {"tie_breaker": 0,"boost": 1,"queries": [{"term": {"DestCountry.keyword": {"value": "GB"}}},{"match": {"Dest": "London"}}]}}
}## Function函数组合
# 函数组合查询是 ES中最灵活的,也是最复杂的,同样功能型上也是提高了很多机制
# 查询原理:函数组合,是基于查询后的结果,在结果集上做二次打分,与之前组合查询不一样
# 先初步了解这种方法
# 查询模式
# Function:定义多个查询打分块
# Script_score:脚本定义分值计算规则
# weight:权重占比打分规则
# random:随机自动生成规则
# Field_value_factor:字段值因子
# gauss:高级函数等
# function score
# function_score,关键字,函数查询入口
# query,限制查询数据结果
# 查询航班案例数据,比对 function score 与之前的查询分值数值
# 普通查询
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits": true,"query": {"term": {"DestCountry.keyword": {"value": "GB"}}}
}
# 入门查询1,限制查询范围
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits": true,"query": {"function_score": {"query": {"term": {"DestCountry.keyword": {"value": "GB"}}}}}
}# functions 多函数组合
# 组合多个 function 自定义查询,基于多个function 组合分值,自定义计算分值逻辑
# function_score,关键字,函数查询入口
# functions,关键字,多个函数组合
# weight,每个函数占比权重
# boost_mode,多函数组合分值计算规则,默认是multiply,相乘
# score_mode,多函数组合分值计算规则,默认是multiply,相乘
# score_mode 取值,多函数组合分值计算规则,默认是 multiply
# 取值 说明
# multiply 所有独立 function 计算后的分值相乘
# Sum 所有独立 function 计算后的分值汇总
# avg 所有独立 function 计算后的分值均值
# first 所有独立 function 计算后的分值选择第一个
# max 所有独立 function 计算后的分值最大值
# min 所有独立 function 计算后的分值最小值
# boost_mode 取值
# 取值 说明
# multiply 所有独立 function 计算后的分值相乘
# Sum 所有独立 function 计算后的分值汇总
# avg 所有独立 function 计算后的分值均值
# first 所有独立 function 计算后的分值选择第一个
# max 所有独立 function 计算后的分值最大值
# min 所有独立 function 计算后的分值最小值
# 查询航班案例数据,对比前后 functions 条件查询分值数据
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits": true,"query": {"function_score": {"query": {"term": {"DestCountry.keyword":"GB"}},"boost": 1,"functions": [{"filter": {"match":{"Dest":"Manchester"}},"weight": 1},{"filter": {"match":{"Origin":"London"}},"weight": 2}],"max_boost": 10,"score_mode": "min","boost_mode": "multiply","min_score": 5}}
}# script_score 脚本组合
# 自定义分值计算逻辑,替代默认的 BM25 算法等
# script score,关键字,脚本函数
# script,脚本语法,默认 painless
# boost_mode,分值计算方式,默认multiply=相乘,此处设置sum,加权值
# score_mode,分值计算方式,默认multiply=相乘
# 查询航班案例数据,对比前后查询分值数据,对比数据排序
# 查询1,基于数据字段值打分
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits": true,"query": {"function_score": {"query": {"term": {"DestCountry.keyword": "GB"}},"script_score": {"script": "doc['FlightDelayMin'].value"},"score_mode": "multiply","boost_mode": "sum"}}
}
# 查询2,集成数学函数,Math.log
GET kibana_sample_data_flights_reindex/_search
{"track_total_hits": true,"query": {"function_score": {"query": {"term": {"DestCountry.keyword": "GB"}},"script_score": {"script": "Math.log(1+doc['FlightDelayMin'].value)"},"score_mode": "multiply","boost_mode": "sum"}}
}## Range 应用
# Range 范围类型,是ES数据类型很大的创新,相比传统数据库,性能优势非常明显,高达几个数量级,内部采用BDK树算法检索。有很多应用场景,比如衣服尺寸,设计时都是按照一个范围值设计的,适合 175~185 身高范围等。
# 范围类型
# 类型名称 类型说明
# integer_range 整数范围数值类型
# float_range 单精度范围数值类型
# long_range 日期范围类型
# double_range 应用于IP地址范围检索
# date_range 注意日期格式 format
# ip_range 注意ip查询时,语法规则必须符合规范
# 逻辑关系
# 关键字 说明
# gte 填充数据时,数据的起始值包括值本身,类同Mysql 中的大于等于
# gt 数据起始值,不包括值本身
# lte 填充数据时,数据的结尾值,包括值本身,类同Mysql 中的小于等于
# lt 数据结尾值,不包括值本身
# relation 查询时,范围计算的关系模式,必须是range字段才有效,关系值:WITHIN=包含, CONTAINS=反包含,INTERSECTS=交叉(默认)
# 创建索引,设置range字段,对比前后查询结果
DELETE device-001
PUT device-001
{"mappings": {"properties": {"devId": {"type": "keyword"},"in_voltage": {"type": "integer_range"},"out_voltage": {"type": "integer"}}}
}
PUT device-001/_doc/1
{"devId":"001","in_voltage":{"gte":100,"lte":200},"out_voltage": 100
}
PUT device-001/_doc/2
{"devId":"002","in_voltage":{"gte":200,"lte":300},"out_voltage": 200
}
PUT device-001/_doc/3
{"devId":"003","in_voltage":{"gte":300,"lte":400},"out_voltage": 200
}
GET device-001/_search
{}
# 查询1,默认关系,INTERSECTS 交叉
GET device-001/_search
{"query":{"range": {"in_voltage": {"gte": 150,"lte": 250,"relation":"INTERSECTS"}}}
}
# 查询2,包含
GET device-001/_search
{"query":{"range": {"in_voltage": {"gte": 150,"lte": 350,"relation":"WITHIN"}}}
}
# 查询3,反包含
GET device-001/_search
{"query":{"range": {"in_voltage": {"gte": 150,"lte": 350,"relation":"CONTAINS"}}}
}# 单数值类型
# 单数值类型,在设置时,仅需要一个值,后续查询可以采用范围查询
# range,关键字来,查询语法,包括范围 gte,lte
# relation,关键字,查询时关系类型,默认交叉,与range类型一样
GET device-001/_search
{"query":{"range": {"out_voltage": {"gte": 50,"lte": 150}}}
}## Join父子关系查询
# join,字段“类型关键字
# relations,关系关键字
# routing ,路由保证父子数据在同一分片中
# 场景:假设公司的基本信息,一个公司会有多个子公司,子公司下属又有子公司
DELETE company-001
# 创建join类型字段索引
PUT company-001
{"mappings": {"properties": {"companyId": {"type": "keyword"},"companyName": {"type": "keyword"},"join_father_child": {"type": "join","relations": {"father": "child"}}}}
}
PUT company-001/_doc/1
{"companyId":"001","companyName":"集团总公司","join_father_child":"father"
}
PUT company-001/_doc/2?routing=1
{"companyId":"002","companyName":"浙江分公司","join_father_child":{"name":"child","parent":"1"}
}
PUT company-001/_doc/3?routing=1
{"companyId":"003","companyName":"武汉分公司","join_father_child":{"name":"child","parent":"1"}
}
# 查询分为子查询和父查询,关键字:parent_id,has_parent,has_child
# 依据父id查询所有子节点
GET company-001/_search
{"query":{"parent_id":{"type":"child","id":1}}
}
# 查询有子节点的父节点数据
GET company-001/_search
{"query":{"has_child":{"type":"child","query":{"match_all": {}}}}
}
# 查询有父节点的子节点数据
GET company-001/_search
{"query":{"has_parent":{"parent_type":"father","query":{"match_all": {}}}}
}## Nested 嵌套关系
# ES 支持数组类型,但数组类型在查询时,如果是键值对需求,则会出现查询误差,这是由内部实现决定的,为此ES 推出了 nested 嵌套键值对类型
# nested,字段类型关键字
# 场景:假设一个公司有很多区域信息,每一组都是一个键值对,包括省份与城市,运用 nested 类型,在 area字段下增加 type=nested,查询语法中增加 nested 标记
DELETE company-001
# 创建nested类型字段索引
PUT company-001
{"mappings":{"properties":{"companyId":{"type":"keyword"},"companyName":{"type":"keyword"},"area":{"type":"nested","properties":{"province":{"type":"keyword"},"city":{"type":"keyword"}}}}}
}
# 设置数据
PUT company-001/_doc/1
{"companyId": "001","companyName": "零食铺","area": [{"province": "zj","city": "hz"},{"province": "hb","city": "wh"}]
}
# 查询数据,无结果
GET company-001/_search
{"query":{"nested": {"path": "area","query": {"bool": {"must": [{"term": {"area.province": {"value": "zj"}}},{"term": {"area.city": {"value": "wh"}}}]}}}}
}
# 查询数据,有结果
GET company-001/_search
{"query":{"nested": {"path": "area","query": {"bool": {"must": [{"term": {"area.province": {"value": "zj"}}},{"term": {"area.city": {"value": "hz"}}}]}}}}
}### 组合查询限制条件与设置
## indices.query.bool.max clause_count
## 索引查询条件,单次最多组合条件查询限制默认1024个,超过会报错
## 此设置属于静态设置,需要在节点启动前设置,且集群中所有节点必须设置为一样
## 在节点 elasticsearch.yml 文件中设置
## indices.query.bool.max clause_count: 1024
### 组合查询建议
## Bool组合优先filter,满足绝大多数场景
## 组合查询优先bool组合条件,其他的都是特定领域,需要再深入研究
## 性能上慎重使用function组合,脚本有性能问题
## 文档地址
# compound 组合查询
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/compound-queries.html
# function score 函数查询
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/query-dsl-function-score-query.html
# range 范围查询
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/range.html
# join 关联查询
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/joining-queries.html
# search-setting 查询条件数量限制
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/search-settings.html
# boost 字段属性
# https://www.elastic.co/guide/en/elasticsearch/reference/8.6/mapping-boost.html
相关文章:

es 3期 第13节-多条件组合查询实战运用
#### 1.Elasticsearch是数据库,不是普通的Java应用程序,传统数据库需要的硬件资源同样需要,提升性能最有效的就是升级硬件。 #### 2.Elasticsearch是文档型数据库,不是关系型数据库,不具备严格的ACID事务特性ÿ…...

全局token验证
全局token验证 简介 通俗地说,JWT的本质就是一个字符串,它是将用户信息保存到一个Json字符串中,然后进行编码后得到一个JWT token,并且这个JWT token带有签名信息,接收后可以校验是否被篡改,所以可以用…...

实时美颜技术详解:美颜SDK与直播APP开发实践
通过集成美颜SDK(软件开发工具包),开发者能够轻松为直播APP提供实时美颜效果,改善用户的直播体验。本篇文章,小编将深入探讨实时美颜技术,重点分析美颜SDK的核心技术及其在直播APP中的应用实践。 一、实时…...
电子应用设计方案-41:智能微波炉系统方案设计
智能微波炉系统方案设计 一、引言 随着科技的不断进步,人们对于厨房电器的智能化需求日益增长。智能微波炉作为现代厨房中的重要设备,应具备更便捷、高效、个性化的功能,以满足用户多样化的烹饪需求。 二、系统概述 1. 系统目标 - 提供精确…...

P5736 【深基7.例2】质数筛
题目描述 输入 𝑛个不大于 105 的正整数。要求全部储存在数组中,去除掉不是质数的数字,依次输出剩余的质数。 输入格式 第一行输入一个正整数 𝑛,表示整数个数。 第二行输入 𝑛 个正整数 𝑎…...

数据结构初阶1 时间复杂度和空间复杂度
本章重点 算法效率时间复杂度空间复杂度常见时间复杂度以及复杂度OJ练习 1.算法效率 1.1 如何衡量一个算法的好坏 如何衡量一个算法的好坏呢?比如对于以下斐波那契数列: long long Fib(int N) { if(N < 3) return 1;return Fib(N-1) Fib(N-2); }斐…...

E130 PHP+MYSQL+动漫门户网站的设计与实现 视频网站系统 在线点播视频 源码 配置 文档 全套资料
动漫门户网站 1.摘要2. 开发背景和意义3.项目功能4.界面展示5.源码获取 1.摘要 21世纪是信息的时代,随着信息技术与网络技术的发展,其已经渗透到人们日常生活的方方面面,与人们是日常生活已经建立密不可分的联系。本网站利用Internet网络, M…...

OSCP - Proving Grounds - Fanatastic
主要知识点 CVE-2021-43798漏洞利用 具体步骤 执行nmap 扫描,22/3000/9090端口开放,应该是ssh,grafana 和Prometheus Nmap scan report for 192.168.52.181 Host is up (0.00081s latency). Not shown: 65532 closed tcp ports (reset) PORT STA…...
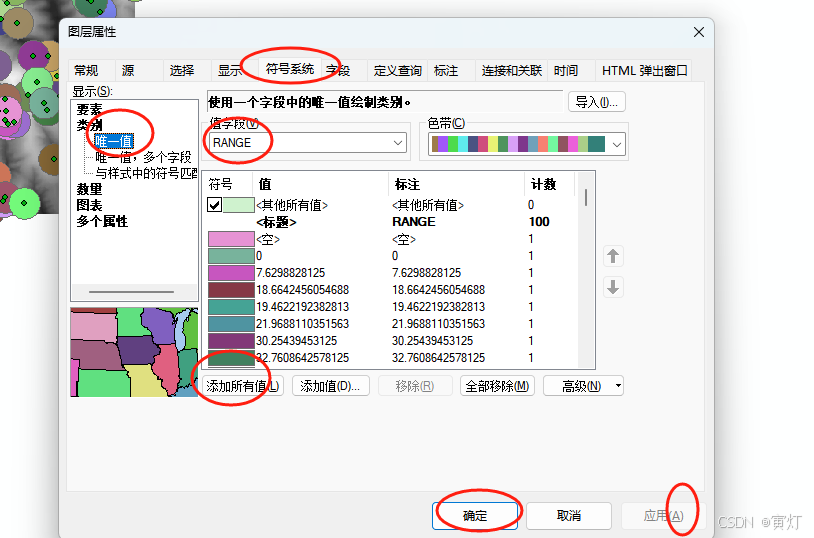
ArcMap 分享统计点要素、路网、降雨量等功能操作
ArcMap 分享统计点要素、路网等功能等功能操作今天进行 一、按格网统计点要素 1、创建公里网格统计单元 点击确定后展示 打开连接 点击后 展示 2、处理属性 1)查看属性表 每个小格都统计出了点的数量 2)查看属性 符号系统 点击应用后展示结果&#x…...

概率论——假设检验
解题步骤: 1、提出假设H0和H1 2、定类型,摆公式 3、计算统计量和拒绝域 4、定论、总结 Z检验 条件: 对μ进行检验,并且总体方差已知道 例题: 1、假设H0为可以认为是570N,H1为不可以认为是570N 2、Z…...

爬虫项目练手
python抓取优美图库小姐姐图片 整体功能概述 这段 Python 代码定义了一个名为 ImageDownloader 的类,其主要目的是从指定网站(https://www.umei.cc)上按照不同的图片分类,爬取图片并保存到本地相应的文件夹中。不过需要注意&…...

C程序设计:解决Fibonacci.数列问题
‘ 斐波那契数列(Fibonacci sequence),又称黄金分割数列,因数学家莱昂纳多斐波那契(Leonardo Fibonacci)以兔子繁殖为例子而引入,故又称“兔子数列”,其数值为:1、1、2、…...

35页PDF | 元数据与数据血缘落地实施(限免下载)
一、前言 这份报告详细介绍了元数据与数据血缘的概念、重要性以及在企业数据中台中的应用。报告阐述了数据中台的核心价值在于整合和管理体系内的数据,以提升数据资产化能力并支持业务决策。报告还涵盖了元数据的分类(技术元数据和业务元数据࿰…...

Lua元表和元方法的使用
元表是一个普通的 Lua 表,包含一组元方法,这些元方法与 Lua 中的事件相关联。事件发生在 Lua 执行某些操作时,例如加法、字符串连接、比较等。元方法是普通的 Lua 函数,在特定事件发生时被调用。 元表包含了以下元方法࿱…...

基于Pyhton的人脸识别(Python 3.12+face_recognition库)
使用Python进行人脸编码和比较 简介 在这个教程中,我们将学习如何使用Python和face_recognition库来加载图像、提取人脸编码,并比较两个人脸是否相似。face_recognition库是一个强大的工具,它基于dlib的深度学习模型,可以轻松实…...

Spring Boot+Netty
因工作中需要给第三方屏幕厂家下发广告,音频,图片等内容,对方提供TCP接口于是我使用Netty长链接进行数据传输 1.添加依赖 <!-- netty依赖--><dependency><groupId>io.netty</groupId><artifactId>netty-all&…...

LCR 023. 相交链表
一.题目: LCR 023. 相交链表 - 力扣(LeetCode) 二.我的原始解法-无: 三.其他人的正确及好的解法,力扣解法参考: 哈希表法及双指针法:LCR 023. 相交链表 - 力扣(LeetCode࿰…...

Linux命令行下载工具
1. curl 1.1. 介绍 curl是一个功能强大的命令行工具,用于在各种网络协议下传输数据。它支持多种协议,包括但不限于 HTTP、HTTPS、FTP、FTPS、SCP、SFTP、SMTP、POP3、IMAP 等,这使得它在网络数据交互场景中有广泛的应用。curl可以模拟浏览器…...

期末复习-Hadoop名词解释+简答题纯享版
目录 一、名称解释(8选5) 1.什么是大数据 2.大数据的5V特征 3.什么是SSH 4.HDFS(p32) 5.名称节点 6.数据节点 7.元数据 8.倒排索引 9.单点故障 10.高可用 11.数据仓库 二、简答题 1.简述Hadoop的优点及其含义 2.简述…...

嵌入式Linux无窗口系统下搭建 Qt 开发环境
嵌入式Linux无窗口系统下搭建 Qt 开发环境 本文将介绍如何在树莓派的嵌入式 Linux 环境下,搭建 Qt 开发环境,实现无窗口系统模式(framebuffer)下的图形程序开发。 1. 安装 Qt 环境 接下来,安装核心 Qt 开发库以及与 …...

Stateflow实战:构建LKA系统状态机的模块化建模与数据管理
1. 从零理解LKA系统与Stateflow建模 第一次接触车道保持辅助系统(LKA)时,我盯着那个能在高速上自动修正方向的方向盘看了半天。这玩意儿到底怎么判断什么时候该介入?后来才知道,核心就是藏在控制器里的状态机逻辑。Sta…...

当A*算法遇上真实山地DEM:一份给无人机/机器人路径规划者的Python避坑指南
当A*算法遇上真实山地DEM:无人机路径规划的Python实战与优化 山地路径规划的独特挑战 在无人机和机器人导航领域,山地地形带来了传统路径规划算法难以应对的复杂性。与平坦城市环境不同,山地DEM(数字高程模型)数据包含…...

深度解析Linux内核task_struct:从进程管理到性能调优
1. 项目概述:从一行代码到操作系统的心脏 如果你写过C语言程序,一定用过 int main() ,程序启动后,操作系统会为它创建一个“进程”。在Linux的世界里,这个进程在操作系统内核眼中,到底是什么样子的&#…...
)
【权威验证】Perplexity书评辅助效果对比实验:传统写作vs AI增强写作(N=1,247篇样本,p<0.001)
更多请点击: https://kaifayun.com 第一章:【权威验证】Perplexity书评辅助效果对比实验:传统写作vs AI增强写作(N1,247篇样本,p<0.001) 本实验基于真实学术出版场景,对1,247篇计算机科学领…...

Logstalgia高级配置技巧:自定义颜色、分组和过滤规则
Logstalgia高级配置技巧:自定义颜色、分组和过滤规则 【免费下载链接】Logstalgia replay or stream website access logs as a retro arcade game 项目地址: https://gitcode.com/gh_mirrors/lo/Logstalgia Logstalgia是一款将网站访问日志以复古街机游戏形…...

如何在Windows11中配置家长控制?限制使用时间与内容访问
如何在Windows11中配置家长控制?限制使用时间与内容访问 【免费下载链接】windows11 🌎 Windows 11 Settings, Tweaks, Scripts 项目地址: https://gitcode.com/GitHub_Trending/wi/windows11 Windows 11家长控制是保护孩子健康使用电脑的重要功能…...

Camunda并行会签实战:从BPMN设计到数据库状态变化的完整追踪
Camunda并行会签实战:从BPMN设计到数据库状态变化的完整追踪 在复杂业务流程自动化领域,并行会签是一种常见但实现难度较高的模式。当三个部门主管需要同时审批一份采购申请时,传统串行审批会导致效率低下,而并行处理又面临状态同…...
)
告别卡顿!用ZLMRTCClient.js和Vue3打造超低延迟WebRTC监控播放器(附完整代码)
超低延迟WebRTC监控播放器:基于ZLMRTCClient.js与Vue3的工程实践 在安防监控、智慧园区等对实时性要求极高的场景中,传统流媒体方案如HLS或FLV往往面临3-5秒甚至更高的延迟。这种延迟在关键场景下可能导致严重后果——当监控画面显示"一切正常"…...

iOS种子下载终极指南:iTorrent让你的iPhone变身专业下载中心
iOS种子下载终极指南:iTorrent让你的iPhone变身专业下载中心 【免费下载链接】iTorrent Torrent client for iOS 16 项目地址: https://gitcode.com/gh_mirrors/it/iTorrent 还在为iPhone无法下载种子文件而烦恼吗?iTorrent这款专业的iOS种子客户…...

探索现代媒体播放器的终极指南:免费专业播放解决方案
探索现代媒体播放器的终极指南:免费专业播放解决方案 【免费下载链接】mpv.net 🎞 mpv.net is a media player for Windows with a modern GUI. 项目地址: https://gitcode.com/gh_mirrors/mp/mpv.net 还在为Windows平台找不到一款既强大又易用的…...