Hbase整合Mapreduce案例2 hbase数据下载至hdfs中——wordcount
目录
- 整合结构
- 准备
- 数据下载
- pom.xml
- Main.java
- Reduce.java
- Map.java
- 操作
- 总结
整合结构
和案例1的结构差不多,Hbase移动到开头,后面跟随MR程序。
因此对于输入的K1 V1会进行一定的修改
准备
- 在HBASE中创建表,并写入数据
create "wunaiieq:sentence","colf"
- 系统文件上传
datain3.java
package org.wunaiieq.hbase2hdfs;import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.wunaiieq.HBaseConnection;
import org.wunaiieq.HbaseDML;import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;public class datain3 {public static Connection connection = HBaseConnection.connection;public static void main(String[] args) throws IOException {BufferedReader bufferedReader =new BufferedReader(new FileReader("/opt/module/jar/data.txt"));String line =null;Table table = connection.getTable(TableName.valueOf("wunaiieq", "sentence"));int rowkey = 1;while ((line=bufferedReader.readLine())!=null){Put put = new Put(Bytes.toBytes(rowkey));put.addColumn(Bytes.toBytes("colf"),Bytes.toBytes("line"),Bytes.toBytes(line));table.put(put);rowkey++;}bufferedReader.close();}
}

数据下载
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.hbase</groupId><artifactId>hbase2hdfs</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><hadoop.version>3.1.3</hadoop.version><hbase.version>2.2.3</hbase.version></properties><dependencies><!-- Hadoop Dependencies --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-hdfs</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-core</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-yarn-api</artifactId><version>${hadoop.version}</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-streaming</artifactId><version>${hadoop.version}</version></dependency><!-- HBase Dependencies --><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-common</artifactId><version>${hbase.version}</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-mapreduce</artifactId><version>${hbase.version}</version></dependency><!-- Other Dependencies --><dependency><groupId>com.google.protobuf</groupId><artifactId>protobuf-java</artifactId><version>3.19.1</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>RELEASE</version><scope>compile</scope></dependency></dependencies><build><plugins><plugin><!--声明--><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.3.0</version><!--具体配置--><configuration><archive><manifest><!--jar包的执行入口--><mainClass>org.wunaiieq.hbase2hdfs.Main</mainClass></manifest></archive><descriptorRefs><!--描述符,此处为预定义的,表示创建一个包含项目所有依赖的可执行 JAR 文件;允许自定义生成jar文件内容--><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><!--执行配置--><executions><execution><!--执行配置ID,可修改--><id>make-assembly</id><!--执行的生命周期--><phase>package</phase><goals><!--执行的目标,single表示创建一个分发包--><goal>single</goal></goals></execution></executions></plugin></plugins></build></project>Main.java
package org.wunaiieq.hbase2hdfs;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class Main {public static void main(String[] args) throws Exception {//配置文件,写在resources目录下Job job =Job.getInstance(new Configuration());//入口类job.setJarByClass(Main.class);Scan scan = new Scan();TableMapReduceUtil.initTableMapperJob("wunaiieq:sentence",//表名scan,//表输入时,可以在此处进行部分设置,如选择查询的列簇,列,过滤行等等org.wunaiieq.hbase2hdfs.Map.class,//指定mapper类Text.class,//k2IntWritable.class,//v2job,false);job.setOutputKeyClass(Text.class);//K3job.setOutputValueClass(IntWritable.class);//V3job.setReducerClass(org.wunaiieq.hbase2hdfs.Reduce.class);//手动输入输出路径FileOutputFormat.setOutputPath(job,new Path(args[0]));job.waitForCompletion(true);}
}Reduce.java
package org.wunaiieq.hbase2hdfs;import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;// K3 V3 K4 V4
public class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{private IntWritable v4 =new IntWritable();private Text k4 =new Text();@Overrideprotected void reduce(Text k3, Iterable<IntWritable> v3,Context context) throws IOException, InterruptedException {int sum =0;for (IntWritable v30:v3){sum+=v30.get();}v4.set(sum);k4=k3;context.write(k4,v4);}
}Map.java
package org.wunaiieq.hbase2hdfs;import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;
// K1 V1
public class Map extends TableMapper<Text,IntWritable> {private Text k2=new Text();private IntWritable v2 =new IntWritable(1);@Overrideprotected void map(ImmutableBytesWritable k1, Result v1,Context context) throws IOException, InterruptedException {System.out.println("k1:"+k1.toString());//读取当前行中的colf:line数据byte[] data =v1.getValue(Bytes.toBytes("colf"),Bytes.toBytes("line"));String line =Bytes.toString(data);String [] words =line.split(" ");for (String word :words){k2.set(word);context.write(k2,v2);}}
}操作
打包上传至linux系统中
hadoop jar hbase2hdfs-1.0-SNAPSHOT-jar-with-dependencies.jar /output/test
检查文件
hdfs dfs -cat /output/test/part-r-00000
总结
没什么特殊点,记录下这两个案例即可,只需要在MR程序中替换掉对应的Mapper和Reducer即可
相关文章:
Hbase整合Mapreduce案例2 hbase数据下载至hdfs中——wordcount
目录 整合结构准备数据下载pom.xmlMain.javaReduce.javaMap.java操作 总结 整合结构 和案例1的结构差不多,Hbase移动到开头,后面跟随MR程序。 因此对于输入的K1 V1会进行一定的修改 准备 在HBASE中创建表,并写入数据 create "wunaii…...

diff算法
vue的diff算法详解 vue: diff 算法是一种通过同层的树节点进行比较的高效算法 其有两个特点: 比较只会在同层级进行, 不会跨层级比较 在diff比较的过程中,循环从两边向中间比较 diff 算法在很多场景下都有应用,在 vue 中&…...
最新AI问答创作运营系统(SparkAi系统),GPT-4.0/GPT-4o多模态模型+联网搜索提问+问答分析+AI绘画+管理后台系统
目录 一、人工智能 系统介绍文档 二、功能模块介绍 系统快速体验 三、系统功能模块 3.1 AI全模型支持/插件系统 AI大模型 多模态模型文档分析 多模态识图理解能力 联网搜索回复总结 3.2 AI智能体应用 3.2.1 AI智能体/GPTs商店 3.2.2 AI智能体/GPTs工作台 3.2.3 自…...

docker应用
docker version docker info docker images# 查看主机所以镜像 docker search# 搜索镜像 docker pull# 下载镜像 docker rmi# 删除镜像 docker tag 镜像名:版本 新镜像名:版本 # 复制镜像并改名 docker commit # 提交镜像 docker load -i /XXX/XXX.tar # 导入镜像 docker sav…...

COCO数据集理解
COCO(Common Objects in Context)数据集是一个用于计算机视觉研究的广泛使用的数据集,特别是在物体检测、分割和图像标注等任务中。COCO数据集由微软研究院开发,其主要特点包括: 丰富的标签:COCO数据集包含…...

C# 向上取整多种实现方法
1.使用 Math.Ceiling 方法: 在 C# 中,可以利用 System.Math 类下的 Math.Ceiling 方法来实现向上取整。它接受一个 double 或 decimal 类型的参数,并返回大于或等于该参数的最小整数(以 double 或 decimal 类型表示)。…...

Elastic Cloud Serverless:深入探讨大规模自动扩展和性能压力测试
作者:来自 Elastic David Brimley, Jason Bryan, Gareth Ellis 及 Stewart Miles 深入了解 Elasticsearch Cloud Serverless 如何动态扩展以处理海量数据和复杂查询。我们探索其在实际条件下的性能,深入了解其可靠性、效率和可扩展性。 简介 Elastic Cl…...

新一代零样本无训练目标检测
🏡作者主页:点击! 🤖编程探索专栏:点击! ⏰️创作时间:2024年12月2日21点02分 神秘男子影, 秘而不宣藏。 泣意深不见, 男子自持重, 子夜独自沉。 论文链接 点击开启你的论文编程之旅h…...

es 3期 第13节-多条件组合查询实战运用
#### 1.Elasticsearch是数据库,不是普通的Java应用程序,传统数据库需要的硬件资源同样需要,提升性能最有效的就是升级硬件。 #### 2.Elasticsearch是文档型数据库,不是关系型数据库,不具备严格的ACID事务特性ÿ…...

全局token验证
全局token验证 简介 通俗地说,JWT的本质就是一个字符串,它是将用户信息保存到一个Json字符串中,然后进行编码后得到一个JWT token,并且这个JWT token带有签名信息,接收后可以校验是否被篡改,所以可以用…...

实时美颜技术详解:美颜SDK与直播APP开发实践
通过集成美颜SDK(软件开发工具包),开发者能够轻松为直播APP提供实时美颜效果,改善用户的直播体验。本篇文章,小编将深入探讨实时美颜技术,重点分析美颜SDK的核心技术及其在直播APP中的应用实践。 一、实时…...
电子应用设计方案-41:智能微波炉系统方案设计
智能微波炉系统方案设计 一、引言 随着科技的不断进步,人们对于厨房电器的智能化需求日益增长。智能微波炉作为现代厨房中的重要设备,应具备更便捷、高效、个性化的功能,以满足用户多样化的烹饪需求。 二、系统概述 1. 系统目标 - 提供精确…...

P5736 【深基7.例2】质数筛
题目描述 输入 𝑛个不大于 105 的正整数。要求全部储存在数组中,去除掉不是质数的数字,依次输出剩余的质数。 输入格式 第一行输入一个正整数 𝑛,表示整数个数。 第二行输入 𝑛 个正整数 𝑎…...

数据结构初阶1 时间复杂度和空间复杂度
本章重点 算法效率时间复杂度空间复杂度常见时间复杂度以及复杂度OJ练习 1.算法效率 1.1 如何衡量一个算法的好坏 如何衡量一个算法的好坏呢?比如对于以下斐波那契数列: long long Fib(int N) { if(N < 3) return 1;return Fib(N-1) Fib(N-2); }斐…...

E130 PHP+MYSQL+动漫门户网站的设计与实现 视频网站系统 在线点播视频 源码 配置 文档 全套资料
动漫门户网站 1.摘要2. 开发背景和意义3.项目功能4.界面展示5.源码获取 1.摘要 21世纪是信息的时代,随着信息技术与网络技术的发展,其已经渗透到人们日常生活的方方面面,与人们是日常生活已经建立密不可分的联系。本网站利用Internet网络, M…...

OSCP - Proving Grounds - Fanatastic
主要知识点 CVE-2021-43798漏洞利用 具体步骤 执行nmap 扫描,22/3000/9090端口开放,应该是ssh,grafana 和Prometheus Nmap scan report for 192.168.52.181 Host is up (0.00081s latency). Not shown: 65532 closed tcp ports (reset) PORT STA…...
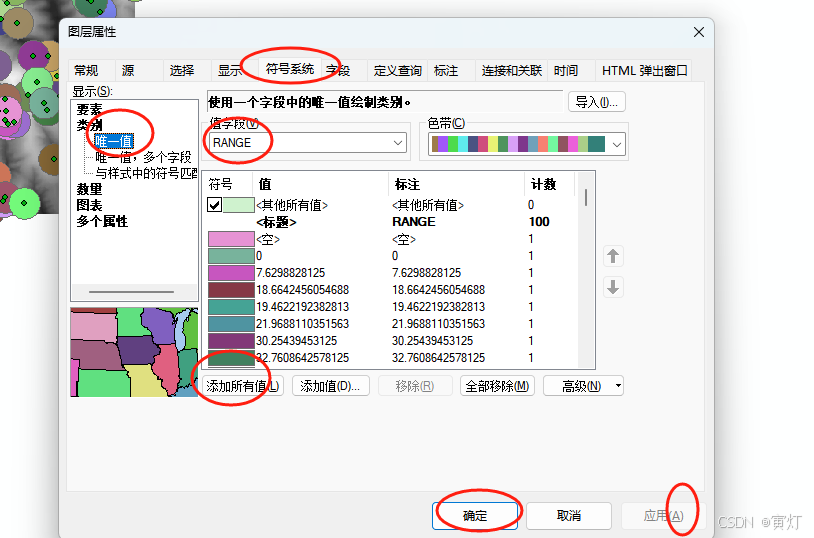
ArcMap 分享统计点要素、路网、降雨量等功能操作
ArcMap 分享统计点要素、路网等功能等功能操作今天进行 一、按格网统计点要素 1、创建公里网格统计单元 点击确定后展示 打开连接 点击后 展示 2、处理属性 1)查看属性表 每个小格都统计出了点的数量 2)查看属性 符号系统 点击应用后展示结果&#x…...

概率论——假设检验
解题步骤: 1、提出假设H0和H1 2、定类型,摆公式 3、计算统计量和拒绝域 4、定论、总结 Z检验 条件: 对μ进行检验,并且总体方差已知道 例题: 1、假设H0为可以认为是570N,H1为不可以认为是570N 2、Z…...

爬虫项目练手
python抓取优美图库小姐姐图片 整体功能概述 这段 Python 代码定义了一个名为 ImageDownloader 的类,其主要目的是从指定网站(https://www.umei.cc)上按照不同的图片分类,爬取图片并保存到本地相应的文件夹中。不过需要注意&…...

C程序设计:解决Fibonacci.数列问题
‘ 斐波那契数列(Fibonacci sequence),又称黄金分割数列,因数学家莱昂纳多斐波那契(Leonardo Fibonacci)以兔子繁殖为例子而引入,故又称“兔子数列”,其数值为:1、1、2、…...

《ROS 2机器人开发从入门到实践》 2.3 使用功能包组织C++节点
简介: 上一小节我们用功能包组织了python节点,这节我们把C节点也装进功能包。 参考资料: 参考资料均来自于鱼香ROS社区创始人小鱼,资源如下: ①:【《ROS 2机器人开发从入门到实践》 2.3 使用功能包组织…...
)
为什么顶级策展人不用Google搜文化新闻?Perplexity文化垂直搜索的5层语义增强架构(含可复用prompt工程模板)
更多请点击: https://kaifayun.com 第一章:为什么顶级策展人不用Google搜文化新闻? 顶级策展人并非排斥搜索引擎,而是早已构建起一套高度结构化、语义化、可验证的信息摄取系统——它绕过关键词匹配的偶然性,直击文化…...

终极跨平台KVM解决方案:3分钟掌握Input Leap键盘鼠标共享
终极跨平台KVM解决方案:3分钟掌握Input Leap键盘鼠标共享 【免费下载链接】input-leap Open-source KVM software 项目地址: https://gitcode.com/gh_mirrors/in/input-leap 还在为多台电脑设备间频繁切换键盘鼠标而烦恼吗?Input Leap跨平台KVM软…...

2026 AI 技术生态全景指南:从 LLM 到 Agent,从 MCP 到 A2A
AI 技术生态指南 整合 AI/ML/DL 核心概念、模型对比、基础设施与工具链的完整参考。 你是否也有这些困惑? 🤔 GPT、Claude、Gemini、DeepSeek、Qwen…20 模型到底怎么选? 🤔 MCP 和 A2A 这两个新协议有什么区别?谁提出…...

如何用AI语音修复工具VoiceFixer拯救你的受损录音:终极指南
如何用AI语音修复工具VoiceFixer拯救你的受损录音:终极指南 【免费下载链接】voicefixer General Speech Restoration 项目地址: https://gitcode.com/gh_mirrors/vo/voicefixer 还在为那些珍贵的录音因为各种原因变得模糊不清而烦恼吗?VoiceFixe…...

FPGA时序约束避坑指南:Set Bus Skew与Set Max Delay到底有什么区别?
FPGA时序约束深度解析:Set Bus Skew与Set Max Delay的核心差异与工程实践 在FPGA设计的时序收敛过程中,工程师们常常面临一个关键抉择:何时使用Set Max Delay,何时又该选择Set Bus Skew?这两种约束看似都与路径延迟相关…...

3步永久激活Windows和Office:开源智能脚本的完整指南
3步永久激活Windows和Office:开源智能脚本的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为电脑屏幕上频繁弹出的"需要激活"提示而烦恼吗?Offi…...

90%的人只用了Superpowers 10%的能力,实战案例带你走通全流程
装了Superpowers还是不会用?这套完整工作流,让你的AI从“工具”变“搭档”你可能已经在 GitHub 上给 Superpowers 点过 Star 了,甚至在本地环境里跑了一遍安装流程。但说实话,你大概率只触发了其中一两个 Skill——写代码时偶尔触…...

深度解析:实战掌握神经网络架构可视化完整方案
深度解析:实战掌握神经网络架构可视化完整方案 【免费下载链接】Neural-Network-Architecture-Diagrams Diagrams for visualizing neural network architecture 项目地址: https://gitcode.com/gh_mirrors/ne/Neural-Network-Architecture-Diagrams 在深度学…...

MarkdownViewer++:Notepad++终极Markdown实时预览插件完整指南
MarkdownViewer:Notepad终极Markdown实时预览插件完整指南 【免费下载链接】MarkdownViewerPlusPlus A Notepad Plugin to view a Markdown file rendered on-the-fly 项目地址: https://gitcode.com/gh_mirrors/ma/MarkdownViewerPlusPlus 你是否曾在Notepa…...