kube-proxy的iptables工作模式分析
系列文章目录
iptables基础知识
文章目录
- 系列文章目录
- 前言
- 一、kube-proxy介绍
- 1、kube-proxy三种工作模式
- 2、iptables中k8s相关的链
- 二、kube-proxy的iptables模式剖析
- 1.集群内部通过clusterIP访问到pod的流程
- 1.1.流程分析
- 2.从外部访问内部service clusterIP后端pod的流程
- 2.1. 流程分析
- 3、外部通过nodeport访问后端pod的流程
- 3.1.当externalTrafficPolicy默认为cluster配置时且从本机访问后端pod流程
- 3.2.当externalTrafficPolicy为Local配置时且从本机访问后端pod流程
- 三、iptables与ipvs区别
前言
在一个k8s集群中,微服务以 Pod形式 运行在我们的集群中,这些 Pod 的副本通过Service 服务暴露,当一个外部请求到达 Service 的虚拟 IP 时,如何将请求转发到其中一个底层 Pod?这便是本篇文章的核心思想。
一、kube-proxy介绍

kube-proxy是k8s网络代理核心组件,部署在每个Node节点上,主要维护节点上的网络规则。它是实现service的通信与负载均衡机制的重要组件
kube-proxy负责为pod创建代理服务,通过watch机制会根据 service 和 endpoints,node资源对象的改变来实时刷新iptables或者ipvs规则
使发往 Service 的流量(通过ClusterIP和NodePort)负载均衡到正确的后端Pod。
1、kube-proxy三种工作模式
userspace(目前已经弃用)请求是从用户态-->内核态-->用户态,转发是在用户态进行的,效率不高且容易丢包
iptables(默认工作模式)相比于userspace免去了一次内核态-->用户态的切换1、kube-proxy通过Api-server的watch接口实时监测service和endpoint对象的变化,当有service创建时,kube-proxy在iptables中追加新的规则2、在该模式下,kube-proxy为service后端的每个pod创建对应的iptables规则,直接将发向cluster ip的请求重定向到一个pod ip3、在该模式下,kube-proxy不承担四层代理的角色,只负责创建iptables规则补充:在iptables模式下,会根据service以及endpoints对象的改变来实时刷新规则,kube-proxy使用了iptables的filter表和nat表,并对 iptables 的链进行了扩充,自定义了 KUBE-SERVICES、KUBE-EXTERNAL-SERVICES、KUBE-NODEPORTS、KUBE-POSTROUTING、KUBE-MARK-MASQ、KUBE-MARK-DROP、KUBE-FORWARD 七条链。另外还新增了以“KUBE-SVC-xxx”和“KUBE-SEP-xxx”开头的数个链,除了创建自定义的链以外还将自定义链插入到已有链的后面以便劫持数据包。
ipvs1、kube-proxy ipvs模式是基于NAT实现的,对访问k8s service的请求进行虚拟ip到pod ip的转发工作原理:当创建一个svc后,ipvs模式的kube-proxy会做以下三件事:1、确保kube-ipvs0网卡的存在。因为ipvs的netfilter钩子挂载input链.需要把svc的访问IP绑定在该网卡上让内核觉得虚IP就是本机IP,从而进入input链。2、把svc的访问ip绑定在该网卡上3、通过socket调用,创建ipvs的虚拟服务和真实服务,分别对应svc和endpoints注意事项:ipvs用于流量转发,无法处理kube-proxy中的其他问题,例如把包过滤、SNAT等。因此在以下四种情况下kube-proxy依赖iptables:1、kube-proxy配置启动参数masquerade-all=true,即集群中所有经过kube-proxy的包都做一次SNAT;2、kube-proxy启动参数指定集群IP地址范围;3、支持loadbalance类型的服务4、支持nodeport类型的服务
2、iptables中k8s相关的链
| 名称 | 含义 |
|---|---|
| KUBE-SERVICES | 是服务数据包的入口点。它的作用是匹配 目标 IP:port 并将数据包分派到对应的 KUBE-SVC-* 链 |
| KUBE-SVC-* | 充当负载均衡器,将数据包分发到 KUBE-SEP-* 链。KUBE-SEP-* 的数量等于后面的端点数量 服务。选择哪个 KUBE-SEP-* 是随机决定的 |
| KUBE-SEP-* | 表示 Service EndPoint。它只是执行 DNAT,将 服务 IP:端口,以及 Pod 的端点 IP:端口 |
| KUBE-MARK-MASQ | 将 Netfilter 标记添加到发往该服务的数据包中,该标记 源自集群网络之外。带有此标记的数据包将被更改 在 POSTROUTING 规则中使用源网络地址转换 (SNAT) 和 node 的 IP 地址作为其源 IP 地址 |
| KUBE-MARK-DROP | 为没有目的地的数据包添加 Netfilter 标记 此时已启用 NAT。这些数据包将在 KUBE-FIREWALL 中被丢弃 链 |
| KUBE-FW-* | chain 在 service 部署时执行 LoadBalancer 类型,则 将目标 IP 与服务的负载均衡器 IP 匹配,并分配 数据包到对应的 KUBE-SVC-* 链或 KUBE-XLB-* 链的 KEY-XLB-* 链 |
| KUBE-NODEPORTS | 发生在服务部署在 NodePort 和 LoadBalancer 的 LoadPort 共享 LoadPort 和 LoadBalancer 的有了它,外部源可以访问该服务 按 Node Port 的 NODE 端口。它匹配节点端口并分发 数据包到对应的 KUBE-SVC-* 链或 KUBE-XLB-* 链 的 KEY-XLB-* 链 的 |
| KUBE-XLB-* | 在 externalTrafficPolicy 设置为 Local 时工作。有了这个 链式编程,如果节点没有相关端点,则数据包将被丢弃 保留 |
二、kube-proxy的iptables模式剖析
首先请查看顶部文章链接iptables基本知识,对出入栈、四表五链有个认知,然后再看下文
包含整改service模式的流程图

只包含cluster IP、NodePort模式的流程图

流程图结合iptables示例图

结合上述流程图,主要分两部分对kube-proxy的iptables模式进行剖析
1.集群内部通过clusterIP访问到pod的流程
资源准备,如下图所示

需求: 当在集群pod1访问curl http://10.102.172.63:8088时,请求是怎么到达后端pod2的?
1.1.流程分析
确定kube-proxy的工作模式两种方式
[root@master ~]# curl http://127.0.0.1:10249/proxyMode
iptables[root@master ~]# kubectl get configmaps -n kube-system kube-proxy -oyaml |grep modemode: "" #默认为空就是iptables模式
a、进入到pod1,执行curl请求
[root@master ~]# kubectl exec -it -n xx xx-xx-6c57d9ddc6-2495v bash
bash-4.2$ curl http://10.102.172.63:8088
xshell多开一个窗口,登录到pod1宿主机,查看iptables规则
b、因为从上述iptables流程图可知,当请求从集群内部发出时,先进入的是NAT表中的OUTPUT链---->到达KUBE-SERVICE自定义链
那么在pod1宿主机中查看output链规则如下所示
[root@xmhl-std12 ~]# iptables -t nat -S |grep -i output
-P OUTPUT ACCEPT
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES #此链就是入口链
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER
c、因为是clusterIP模式,因此在KUBE-SERVICES链查找到ClusterIP-10.102.172.63,然后根据结果将其转发到KUBE-SVC-*链
判断是否发生IP伪装(masquerade all)
从下面可以看到当数据包来自内部 Pod 时,即源 IP 仍然是pod ip。因此未发生转换,则直接到kube-svc-*链
bash-4.2$ curl -s 10.102.172.63:8088 | grep client
bash-4.2$ client_address=10.244.193.194#查看kube-svc-*链是否存在
[root@master ~]# iptables -nv -t nat -L KUBE-SERVICES |grep 'zz-trace'0 0 KUBE-SVC-LWBZJHXSVINAPFYY tcp -- * * 0.0.0.0/0 10.102.172.63 /* xos/zz-trace-analyze:web cluster IP */ tcp dpt:8088
d、访问 KUBE-SVC*链 使用随机数负载均衡,将请求转发到kube-sep-*链中
#注意事项假如这个KUBE-SVC-LWBZJHXSVINAPFYY链里面定义了3条规则第一条规则有0.33333333349的概率匹配,也就是1/3的概率命中,第一条没命中的话第二条规则有1/2的概率命中,也就是2/3 * 1/2 = 1/3,第二条没命中的话就去第3条了。很明显,这里是在做负载均衡,那我们可以确认这3条规则后面的target就是这个service代理的3个pod相关的规则了[root@master ~]# iptables -nv -t nat -L KUBE-SVC-LWBZJHXSVINAPFYY
Chain KUBE-SVC-LWBZJHXSVINAPFYY (1 references)pkts bytes target prot opt in out source destination 0 0 KUBE-SEP-SU7QRQC2MJZZVHTR all -- * * 0.0.0.0/0 0.0.0.0/0 /* xos/zz-trace-analyze:web */
e、每个 KUBE-SEP-* 链分别代表一个 Pod 或终端节点
重点
它包括两个操作:1) 从 Pod 转义的数据包是使用主机的 docker0 IP 进行源 NAT 处理的。 2) 进入 Pod 的数据包使用 Pod 的 IP 进行 DNAT 处理,然后路由到后端 Pod
查询如下所示: 从结果可以清晰的看到 pod1请求pod2的svc后,进入到pod2的数据包使用 Pod 的 IP 进行了 DNAT 处理,直接到达了pod2的目标pod
[root@master ~]# iptables -nv -t nat -L KUBE-SEP-SU7QRQC2MJZZVHTR
Chain KUBE-SEP-SU7QRQC2MJZZVHTR (1 references)pkts bytes target prot opt in out source destination 0 0 KUBE-MARK-MASQ all -- * * 10.244.8.182 0.0.0.0/0 /* xos/zz-trace-analyze:web */0 0 DNAT tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* xityos/zz-trace-analyze:web */ tcp to:10.244.8.182:18080
f、之后nat表的OUTPUT链中的规则结束,进入filter的OUTPUT链
[root@master ~]# iptables -t filter -S |grep OUTPUT
-P OUTPUT ACCEPT
-A OUTPUT -m conntrack --ctstate NEW -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT -j KUBE-FIREWALL #即nat表的OUTPUT链完成后进入到filter表中的OUTPUT链
g、可以看到所有新建的连接(ctstate NEW)都会匹配第一条规则KUBE-SERVICES,而当查看filter表中的KUBE-SERVICES链时,会发现这是一条空链。所以重点看第二条规则KUBE-FIREWALL
[root@master ~]# iptables -nv -t filter -L KUBE-FIREWALL
Chain KUBE-FIREWALL (2 references)pkts bytes target prot opt in out source destination 0 0 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes firewall for dropping marked packets */ mark match 0x8000/0x80000 0 DROP all -- * * !127.0.0.0/8 127.0.0.0/8 /* block incoming localnet connections */ ! ctstate RELATED,ESTABLISHED,DNAT可以看到,所有被标记了0x8000/0x8000的数据包都会被直接DROP掉,而我们的数据包一路走过来没有被标记,所以不会被DROP。
这样一来filter的OUTPUT规则也走完了,终于进入了下一个阶段 -- POSTROUTRING链
h、POSTROUTING链涉及到2个表:mangle和nat,mangle表一般不使用,所以只需要关注nat表的POSTROUTING规则
[root@master ~]# iptables -nv -t nat -L |grep POSTROUTING
Chain POSTROUTING (policy ACCEPT 26679 packets, 2287K bytes)11M 982M KUBE-POSTROUTING all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes postrouting rules */
Chain KUBE-POSTROUTING (1 references)
i、先进入target,KUBE-POSTROUTING
[root@master ~]# iptables -nv -t nat -L KUBE-POSTROUTING
Chain KUBE-POSTROUTING (1 references)pkts bytes target prot opt in out source destination
27635 2364K RETURN all -- * * 0.0.0.0/0 0.0.0.0/0 mark match ! 0x4000/0x400047 2820 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 MARK xor 0x400047 2820 MASQUERADE all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service traffic requiring SNAT */此时会发现这条规则会把所有标记了0x4000/0x4000的数据包全部MASQUERADE SNAT,由于我们的数据包没有被标记过,所以不匹配这条规则。
当数据包匹配到MASQUERADE的话,当前表的剩余规则将不再匹配。
至此,集群内部通过clusterIP访问到pod的链路流程剖析完成,整理一下整个过程
数据包经历的链路:数据包 --> nat的OUTPUT--> nat的KUBE-SERVICES --> nat的KUBE-SVC-LWBZJHXSVINAPFYY--> nat的KUBE-SEP-SU7QRQC2MJZZVHTR(多选1,随机负载均衡,被DNAT)--> filter的OUTPUT --> filter的KUBE-SERVICES -->filter的KUBE-FIREWALL --> nat的POSTROUTING --> nat的KUBE-POSTROUTING --> 没有被NAT
语言描述:0、当集群内部通过clusterIP访问到pod时,会发生以下过程1、对于进入 NAT表的OUTPUT 链的都转到 KUBE-SERVICES 链进行处理2、在 KUBE-SERVICES 链,对于访问 clusterIP 为 10.102.172.63 的转发到 KUBE-SVC-LWBZJHXSVINAPFYY3、访问 KUBE-SVC-LWBZJHXSVINAPFYY 的使用随机数负载均衡,并转发到 KUBE-SEP-SU7QRQC2MJZZVHTR上4、KUBE-SEP-SU7QRQC2MJZZVHTR对应 endpoint 中的 pod 10.244.8.182,设置 mark 标记,进行 DNAT 并转发到具体的 pod 上5、当nat表中的output链完成后,会进入filter表中OUTPUT链中的KUBE-FIREWALL自定义链,可以看到,所有被标记了0x8000/0x8000的数据包都会被直接DROP掉,反之则不会被drop6、最后进入到NAT表中的POSTROUTING链,此时会发现这条规则会把所有标记了0x4000/0x4000的数据包全部MASQUERADE SNAT,由于我们的数据包没有被标记过,所以不匹配这条规则。当数据包匹配到MASQUERADE的话,当前表的剩余规则将不再匹配7、至此,剖析结束
2.从外部访问内部service clusterIP后端pod的流程
2.1. 流程分析
需求: 从外部机器中访问http://10.102.172.63:8088 这个clusterip svc的后端pod
a、因为从上述iptables流程图可知,当请求从外部发出时,先进入的是NAT表中的PREROUTING链---->到达KUBE-SERVICE自定义链
[root@master ~]# iptables -t nat -S |grep PREROUTING
-P PREROUTING ACCEPT
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER
b、因为是clusterIP模式,因此在KUBE-SERVICES链查找到ClusterIP-10.102.172.63,然后根据结果将其转发到KUBE-SVC-*链
判断是否发生IP伪装(masquerade all)
从下面我们可以看到,当从外部(而不是从 pod)访问服务时,源 IP 替换为 nodeIP;
cactus@master01:~$ curl --interface 外部地址 -s 10.102.172.63:8088 | grep client
client_address=10.244.1.0
[root@master ~]# conntrack -L -d 10.102.172.63
tcp 6 56 TIME_WAIT src=10.8.21.231 dst=10.102.172.63 sport=56688 dport=8088 src=10.244.8.182 dst=10.244.1.0 sport=18080 dport=50534 [ASSURED] mark=0 use=1#查看kube-svc-*链是否存在
[root@xmhl-std24 ~]# iptables -nvL -t nat |egrep -i 'kube-mark-masq' |grep zz-trace0 0 KUBE-MARK-MASQ all -- * * 10.244.8.182 0.0.0.0/0 /* cityos/zz-trace-analyze:web */[root@master ~]# iptables -nv -t nat -L KUBE-SERVICES |grep 'zz-trace'0 0 KUBE-SVC-LWBZJHXSVINAPFYY tcp -- * * 0.0.0.0/0 10.102.172.63 /* xos/zz-trace-analyze:web cluster IP */ tcp dpt:8088
接下来的分析步骤和集群内部通过clusterIP访问到pod的流程中c-i过程一致,在此不做过多描述
至此,集群内部通过clusterIP访问到pod的链路流程剖析完成,整理一下整个过程
数据包经历的链路:数据包 --> nat的PREROUTING--> nat的KUBE-SERVICES --> nat的KUBE-SVC-LWBZJHXSVINAPFYY--> nat的KUBE-SEP-SU7QRQC2MJZZVHTR(多选1,随机负载均衡,被DNAT)--> filter的OUTPUT --> filter的KUBE-SERVICES -->filter的KUBE-FIREWALL --> nat的POSTROUTING --> nat的KUBE-POSTROUTING --> 没有被NAT
语言描述:0、当集群内部通过clusterIP访问到pod时,会发生以下过程1、对于进入 NAT表的PREROUTING 链的都转到 KUBE-SERVICES 链进行处理2、在 KUBE-SERVICES 链,对于访问 clusterIP 为 10.102.172.63 的转发到 KUBE-SVC-LWBZJHXSVINAPFYY3、访问 KUBE-SVC-LWBZJHXSVINAPFYY 的使用随机数负载均衡,并转发到 KUBE-SEP-SU7QRQC2MJZZVHTR上4、KUBE-SEP-SU7QRQC2MJZZVHTR对应 endpoint 中的 pod 10.244.8.182,设置 mark 标记,进行 DNAT 并转发到具体的 pod 上5、当nat表中的output链完成后,会进入filter表中OUTPUT链中的KUBE-FIREWALL自定义链,可以看到,所有被标记了0x8000/0x8000的数据包都会被直接DROP掉,反之则不会被drop6、最后进入到NAT表中的POSTROUTING链,此时会发现这条规则会把所有标记了0x4000/0x4000的数据包全部MASQUERADE SNAT,由于我们的数据包没有被标记过,所以不匹配这条规则。当数据包匹配到MASQUERADE的话,当前表的剩余规则将不再匹配7、至此,剖析结束
3、外部通过nodeport访问后端pod的流程
将根据上述图1分析两种类型的 NodePort 服务:1、默认服务 (externalTrafficPolicy: Cluster)2、externalTrafficPolicy:local

3.1.当externalTrafficPolicy默认为cluster配置时且从本机访问后端pod流程
a、从本机访问首先进入NAT表的OUTPUT链,然后进入到kube-nodeports链
所有访问端口 64438的数据包,首先要进行 SNAT 处理,然后才能进行kube-svc-*链进行负载均衡
[root@master ~]# iptables -t nat -S |grep OUTPUT
-P OUTPUT ACCEPT
-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER[root@master ~]# iptables -nv -t nat -L KUBE-NODEPORTS |grep 'xx-flow'0 0 KUBE-MARK-MASQ tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* xos/xx-flow:debug-port */ tcp dpt:644380 0 KUBE-SVC-UFDICDG36KRBVVWD tcp -- * * 0.0.0.0/0 0.0.0.0/0 /* xos/xx-flow:debug-port */ tcp dpt:64438
b、可以看到数据包先会命中第一条规则KUBE-MARK-MASQ,然后是第二条规则到达
[root@master ~]# iptables -t nat -L KUBE-MARK-MASQ
Chain KUBE-MARK-MASQ (165 references)
target prot opt source destination
MARK all -- anywhere anywhere MARK or 0x4000在这里数据包会被标记上0x4000标记,然后回到KUBE-NODEPORTS链中继续匹配下一条规则,下一条规则就是KUBE-SVC-UFDICDG36KRBVVWD[root@master ~]# iptables -t nat -L KUBE-SVC-BCUGWLTE6RKBKCZT
Chain KUBE-SVC-BCUGWLTE6RKBKCZT (2 references)
target prot opt source destination
KUBE-SEP-2SQRA2EPJ5ESOFTW all -- anywhere anywhere /* xos/xx-flow:web */ statistic mode random probability 0.50000000000
KUBE-SEP-QUKANZ2W6FTD6P23 all -- anywhere anywhere /* xos/xx-flow:web */
c、接下来一路到nat的POSTROUTING为止都与ClusterIP模式相同,但在接下来的nat的KUBE-POSTROUTING阶段,由于我们的数据包在KUBE-MARK-MASQ被打上了0x4000标记,在这里会命中这条规则,从而被MASQUERADE(SNAT)
[root@xmhl-std11 ~]# iptables -nv -t nat -L KUBE-POSTROUTING
Chain KUBE-POSTROUTING (1 references)pkts bytes target prot opt in out source destination
41065 3455K RETURN all -- * * 0.0.0.0/0 0.0.0.0/0 mark match ! 0x4000/0x400022 1320 MARK all -- * * 0.0.0.0/0 0.0.0.0/0 MARK xor 0x400022 1320 MASQUERADE all -- * * 0.0.0.0/0 0.0.0.0/0 /* kubernetes service traffic requiring SNAT */
至此,当externalTrafficPolicy默认为cluster配置时且从本机访问后端pod流程剖析完成
数据包经历的链路:
数据包 --> nat的OUTPUT --> nat的KUBE-SERVICES --> nat的KUBE-NODEPORTS --> nat的KUBE-MARK-MASQ (被标记) --> nat的KUBE-SVC-GKN7Y2BSGW4NJTYL--> nat的KUBE-SEP-ISPQE3VESBAFO225(3选1,被DNAT)--> filter的OUTPUT --> filter的KUBE-SERVICES -->filter的KUBE-FIREWALL --> nat的POSTROUTING --> nat的KUBE-POSTROUTING --> 被SNAT
3.2.当externalTrafficPolicy为Local配置时且从本机访问后端pod流程
三、iptables与ipvs区别

相关文章:
kube-proxy的iptables工作模式分析
系列文章目录 iptables基础知识 文章目录 系列文章目录前言一、kube-proxy介绍1、kube-proxy三种工作模式2、iptables中k8s相关的链 二、kube-proxy的iptables模式剖析1.集群内部通过clusterIP访问到pod的流程1.1.流程分析 2.从外部访问内部service clusterIP后端pod的流程2.1…...

xiaolin coding 图解 MySQL笔记——锁篇
1. 全局锁是怎么用的? flush tables with read lock 执行以后,整个数据库就处于只读状态了,这时其他线程执行对数据的增删改操作(insert、delete、update);对表结构的更改操作(alter table、dr…...
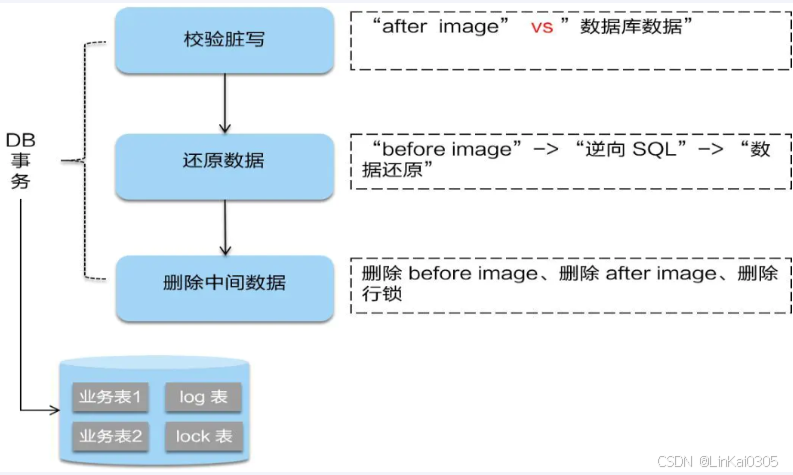
11-SpringCloud Alibaba-Seata处理分布式事务
一、Seata基本介绍 官网:https://seata.apache.org/zh-cn/ Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。 我…...
)
更换 Git 项目的远程仓库地址(五种方法)
更换 Git 项目的远程仓库地址有几种不同的方法,下面是详细的步骤和一些额外的方法来完成这个任务。 方法1:使用 git remote set-url 这是最直接的方法。假设你想要更改名为 origin 的远程仓库地址到新的 URL。 查看当前的远程仓库配置: git…...

3大模块助力学生会视频自动评审系统升级
一、项目背景 传统的学生会视频作品或电子申请材料评审由老师线下逐一面审完成。面对大量学生提交的作品,评审效率低、耗时长,且主观性较强。为此,客户希望开发一个基于AI的线上自动面审系统,从语法正确性、演讲流利度和发音准确…...

鸿蒙开发——使用ArkTs处理XML文本
1、概 述 XML(可扩展标记语言)是一种用于描述数据的标记语言,旨在提供一种通用的方式来传输和存储数据,特别是Web应用程序中经常使用的数据。XML并不预定义标记。因此,XML更加灵活,并且可以适用于广泛的应…...

【Linux】文件查找 find grep
文章目录 1. 引言简介Linux文件系统的基本概念为什么文件查找命令在日常使用中非常重要 2. find 命令基本用法常见选项和参数高级用法和技巧实际示例 3. locate 命令如何工作与find命令的区别安装和使用locate实际示例 4. grep 结合文件查找使用grep进行内容查找结合find命令使…...

Go学习笔记之运算符号
算数运算符 运算符描述相加-相减*相乘/相除%求余自增–自减 代码示例: package mainimport "fmt"func main() {// 算数运算符a : 1b : 2fmt.Println(a b) // 加 3fmt.Println(a - b) // 减 -1fmt.Println(a * b) // 乘 2fmt.Println(a / b) // 除 0fm…...

npm : 无法加载文件 D:\nodejs\npm.ps1,因为在此系统上禁止运行脚本
要以管理员身份打开PowerShell,请按照以下步骤操作: 在Windows搜索框中查找PowerShell: 在任务栏上,点击左下角的Windows徽标(或按Win S键)以打开搜索框。输入“PowerShell”以查找PowerShell应用程序。右…...

YOLOv8-ultralytics-8.2.103部分代码阅读笔记-torch_utils.py
torch_utils.py ultralytics\utils\torch_utils.py 目录 torch_utils.py 1.所需的库和模块 2.def torch_distributed_zero_first(local_rank: int): 3.def smart_inference_mode(): 4.def autocast(enabled: bool, device: str "cuda"): 5.def get_cpu_i…...

Java中的数据存储结构解析与应用
一、引言 在Java编程中,数据存储结构是程序设计的基础。合理选择和使用数据结构可以提高程序的性能和可维护性。本文将带您了解Java中的各种数据存储结构,并探讨其优缺点及适用场景。 二、基本数据类型 Java提供了8种基本数据类型,分别是b…...

【链表】力扣 141. 环形链表
一、题目 二、思路 龟兔进行赛跑 龟的速度是 1,兔的速度是 2龟兔从同一起点出发,若 龟追上兔 则说明 有环 存在;若追不上,则说明无环。 三、代码 /*** Definition for singly-linked list.* class ListNode {* int val;* …...

Hbase整合Mapreduce案例2 hbase数据下载至hdfs中——wordcount
目录 整合结构准备数据下载pom.xmlMain.javaReduce.javaMap.java操作 总结 整合结构 和案例1的结构差不多,Hbase移动到开头,后面跟随MR程序。 因此对于输入的K1 V1会进行一定的修改 准备 在HBASE中创建表,并写入数据 create "wunaii…...

diff算法
vue的diff算法详解 vue: diff 算法是一种通过同层的树节点进行比较的高效算法 其有两个特点: 比较只会在同层级进行, 不会跨层级比较 在diff比较的过程中,循环从两边向中间比较 diff 算法在很多场景下都有应用,在 vue 中&…...
最新AI问答创作运营系统(SparkAi系统),GPT-4.0/GPT-4o多模态模型+联网搜索提问+问答分析+AI绘画+管理后台系统
目录 一、人工智能 系统介绍文档 二、功能模块介绍 系统快速体验 三、系统功能模块 3.1 AI全模型支持/插件系统 AI大模型 多模态模型文档分析 多模态识图理解能力 联网搜索回复总结 3.2 AI智能体应用 3.2.1 AI智能体/GPTs商店 3.2.2 AI智能体/GPTs工作台 3.2.3 自…...

docker应用
docker version docker info docker images# 查看主机所以镜像 docker search# 搜索镜像 docker pull# 下载镜像 docker rmi# 删除镜像 docker tag 镜像名:版本 新镜像名:版本 # 复制镜像并改名 docker commit # 提交镜像 docker load -i /XXX/XXX.tar # 导入镜像 docker sav…...

COCO数据集理解
COCO(Common Objects in Context)数据集是一个用于计算机视觉研究的广泛使用的数据集,特别是在物体检测、分割和图像标注等任务中。COCO数据集由微软研究院开发,其主要特点包括: 丰富的标签:COCO数据集包含…...

C# 向上取整多种实现方法
1.使用 Math.Ceiling 方法: 在 C# 中,可以利用 System.Math 类下的 Math.Ceiling 方法来实现向上取整。它接受一个 double 或 decimal 类型的参数,并返回大于或等于该参数的最小整数(以 double 或 decimal 类型表示)。…...

Elastic Cloud Serverless:深入探讨大规模自动扩展和性能压力测试
作者:来自 Elastic David Brimley, Jason Bryan, Gareth Ellis 及 Stewart Miles 深入了解 Elasticsearch Cloud Serverless 如何动态扩展以处理海量数据和复杂查询。我们探索其在实际条件下的性能,深入了解其可靠性、效率和可扩展性。 简介 Elastic Cl…...

新一代零样本无训练目标检测
🏡作者主页:点击! 🤖编程探索专栏:点击! ⏰️创作时间:2024年12月2日21点02分 神秘男子影, 秘而不宣藏。 泣意深不见, 男子自持重, 子夜独自沉。 论文链接 点击开启你的论文编程之旅h…...

嵌入式开发实战:基于RZ/G2L异构处理器与Linux的工业物联网平台深度体验
1. 项目概述:一次“零成本”的嵌入式开发深度体验最近在嵌入式开发圈里,一个消息引起了不小的讨论:米尔电子联合瑞萨,推出了基于RZ/G2L高性能处理器的开发板免费试用活动。简单来说,就是开发者可以申请免费借用这块开发…...
从Pooling到MetaFormer:深入解析PoolFormer如何用极简算子重塑视觉Transformer架构
1. 为什么说PoolFormer是Transformer的"极简主义革命"? 第一次看到PoolFormer的论文时,我正坐在咖啡馆调试一个复杂的Vision Transformer模型。当读到"用平均池化替代注意力机制"的设计时,差点把咖啡喷在键盘上——这简…...

无人机开发平台全解析:从开源飞控到厂商SDK的选型与应用实战
1. 项目概述:为什么无人机开发平台变得如此重要?几年前,当我第一次尝试给一台消费级无人机增加一个简单的自动航线功能时,我发现自己面对的是一个完全封闭的“黑箱”。飞控固件是加密的,传感器数据无法实时获取&#x…...

3个核心功能+5个实战技巧:用B站神奇弹幕彻底解放你的直播双手
3个核心功能5个实战技巧:用B站神奇弹幕彻底解放你的直播双手 【免费下载链接】MagicalDanmaku 本仓库及所有相关项目已永久停止开发、维护和任何形式的分发。 项目地址: https://gitcode.com/gh_mirrors/bi/MagicalDanmaku 你是否还在直播时手忙脚乱地回复弹…...

Windows桌面终极整理方案:NoFences免费开源桌面分区工具完全指南
Windows桌面终极整理方案:NoFences免费开源桌面分区工具完全指南 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否每天都在混乱的Windows桌面上寻找需要的文…...

可视化AI工作流:从零开始构建智能应用的46个实战模板
可视化AI工作流:从零开始构建智能应用的46个实战模板 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Awesome-Dify-W…...

别再只用在线版了!手把手教你用Docker在本地服务器搭建私有Draw.io图表库
私有化部署Draw.io:用Docker打造企业级安全图表库 当团队需要处理敏感数据时,将核心工具部署在本地环境已成为刚需。以Draw.io为例,虽然其在线版功能完善,但数据经过第三方服务器的风险始终存在。本文将带你用Docker构建一个完全自…...

Realtime-VLA V2——从让π0实时抓取下落的钢笔到让 VLA 运行得更快、更平滑且更精确
前言今天在朋友圈刷到一则新闻,称《开普勒机器人被A股公司收购,前任CEO已离职创业》我仔细看了全文,还是多有感慨其实对双足,3-5家今年可继续卷跳舞 跑步 打拳及比赛/陪练(乒乓球/网球/羽毛球等)而3-5家之外的双足,得另…...

5种架构模式解析:Awesome-Dify-Workflow的可视化AI工作流技术实现
5种架构模式解析:Awesome-Dify-Workflow的可视化AI工作流技术实现 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Aw…...

大学生会计师证书怎么考?2026年小白必看:从入门到进阶的考证通关指南
👋 嗨,亲爱的同学们!如果你点开了这篇文章,我猜你现在可能正坐在图书馆的某个角落,对着满桌的教材发愁,或者是在寝室里刷着手机,看着网上铺天盖地的“会计劝退论”和“考证焦虑”瑟瑟发抖。别慌…...