string类函数的手动实现
在上一篇文章中,我们讲解了一些string类的函数,但是对于我们要熟练掌握c++是远远不够的,今天,我将手动实现一下这些函数~
注意:本篇文章中会大量应用复用,这是一种很巧妙的方法
和以往一样,还是分为string.h string.cpp test.cpp三个文件
为了保证完整性,string.h我统一放在这
1.string.h文件
#pragma once
#include<iostream>
#include<assert.h>
#include<string.h>
using namespace std;
namespace my_string
{class string{public:typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}string(const char* str = "");string(size_t n, char ch);string(const string& s);string& operator=(const string& s);~string();void clear(){_str[0] = '\0';_size = 0;}const char* c_str() const{return _str;}void reserve(size_t n);void push_back(char ch);void append(const char* str);string& operator+=(char ch);string& operator+=(const char* str);void insert(size_t pos, size_t n, char ch);void insert(size_t pos, const char* str);void erase(size_t pos = 0, size_t len = npos);size_t find(char ch, size_t pos = 0);size_t find(const char* str, size_t pos = 0);size_t size()const{return _size;}size_t capacity()const{return _size;}char& operator[](size_t pos) const{assert(pos < _size);return _str[pos];}string substr(size_t pos, size_t len = npos);bool operator==(const string& s)const;bool operator!=(const string& s)const;bool operator<(const string& s)const;bool operator<= (const string & s)const;bool operator>(const string& s)const;bool operator>=(const string& s)const;private:char* _str;size_t _size;size_t _capacity;const static size_t npos;};//cout<<s1ostream& operator<<(ostream& out, const string& s);//cin>>s1istream& operator<<(istream& in, string& s);istream& getline(istream& is, string& s, char delim = '#');}2. 增加类函数(append\insert\push_back\+=)
这是string.cpp文件
void string::push_back(char ch){if (_size + 1 > _capacity){//意味着此时已经满了,需要扩容才能插入//扩容,建议使用函数复用//还要讨论原来容量是不是0reserve(_capacity == 0 ? 4 : _capacity * 2);}//此时已经完成扩容,容量足够用_str[_size] = ch;_size++;_str[_size] = '\0'; //别忘了把\0也考过来}void string::append(const char* str){//注:我们这里是直接按照库里的思路去实现的 // 在这里扩容_size+len也是可以的 只不过思路不一样// 也可能官方认为追加直接扩二倍 后面人继续使用的时候可以少调几次开空间吧size_t len = strlen(str);if (_size + len > _capacity){//意味着此时已经满了,需要扩容才能插入//扩容,与push_back不同的是,// 默认使用append是认为你这个字符串原先就是有内容才追加的// 如果害怕有人确实会直接使用这个接口 可以加上_capacity=0的情况size_t newcapacity = 2 * _capacity;//考虑到可能插入的字符串过长,2倍扩容都可能不够//为防止越界的产生,我们再严谨的讨论一下if (_size + len > 2 * _capacity){newcapacity = _size + len;}reserve(newcapacity);}//strcpy在拷贝时会从第一个字符出发找\0,// 为了节约编译器运行时间,我们直接手动让他从\0出发strcpy(_str + _size, str); _size += len; }void string::insert(size_t pos, size_t n, char ch){assert(pos <= _size);assert(n > 0);//还是要考虑扩容问题if (_size + n > _capacity){size_t newcapacity = 2 * _capacity;if (_size + n > 2 * _capacity){newcapacity = _size + n;}reserve(newcapacity);}size_t end = _size + n; //一切以\0为准while (end > pos + n - 1) //准备挪动数据,这是需要挪动的数据范围{_str[end] = _str[end - n];//最后一个数据先动end--;}//挪完了,有地方了,但是要插入的数还没进来呢!for (size_t i = 0; i < n; i++){_str[pos + i] = ch;}_size += n;}void string::insert(size_t pos, const char* str){assert(pos <= _size);size_t n = strlen(str);if (_size + n > _capacity){size_t newCapacity = 2 * _capacity;if (_size + n > 2 * _capacity){newCapacity = _size + n;}reserve(newCapacity);}size_t end = _size + n;while (end > pos + n - 1){_str[end] = _str[end - n];--end;}for (size_t i = 0; i < n; i++){_str[pos + i] = str[i];}}
string& string::operator+=(char ch)
{push_back(ch);return *this;
}
string& string::operator+=(const char* str)
{append(str);return *this;
}这是test.cpp文件
#include"string.h"
void test_string1()
{string s1("hello world");cout << s1.c_str() << endl;s1 += ' ';cout << s1.c_str() << endl;s1 += '+';cout << s1.c_str() << endl;s1 += "hello everybody";cout << s1.c_str() << endl;s1.push_back(',');cout << s1.c_str() << endl;s1.append("welcome!");cout << s1.c_str() << endl;s1.insert(6,1, 't');cout << s1.c_str() << endl;s1.insert(7, "he ");cout << s1.c_str() << endl;s1.insert(41, "nice to meet you");cout << s1.c_str() << endl;s1.insert(0, "good morning!");cout << s1.c_str() << endl;
}
int main()
{test_string1();return 0;
}结果如下:

2.find和erase
这是string.cpp文件
size_t string::find(char ch, size_t pos){for (size_t i = pos; i < _size; i++){if (_str[i] == ch){return i;}}return npos;}size_t string::find(const char* str, size_t pos){const char* p = strstr(_str + pos, str); //strstr() 函数的作用是在一个字符串(str1)中查找另一个字符串(str2)的出现位置。//如果找到,它返回一个指向 str1 中第一次出现的 str2 的指针;// 如果找不到,则返回空指针(NULL)。if (p == nullptr){return npos;}else{return p - _str; //两个指针相减,结果得到这个元素的下标}}void string::erase(size_t pos, size_t len){if (len > _size - pos){_str[pos] = '\0';_size = pos;}else{size_t end = pos + len;{while (end <= _size){_str[end - len] = _str[end];++end;}_size -= len;}}}这是test.cpp文件
void test_string_find_erase()
{string s1("hello world");cout << s1.c_str() << endl;s1.erase(6,2);cout << s1.c_str() << endl;s1.erase(6, 20);cout << s1.c_str() << endl;s1.erase(3);cout << s1.c_str() << endl;string s2("welcome to guangzhou!");cout << s2.find('o') << endl;cout << s2.find("guangzh") << endl;}
int main()
{test_string_find_erase();return 0;
}结果如下:

3.迭代器
这是test.cpp文件
void test_string_iterator()
{string s1("hello world");for (size_t i = 0; i < s1.size(); i++){s1[i]++;cout << s1[i] << " ";}cout << endl;string::iterator it = s1.begin();while (it != s1.end()){cout << *it << " ";++it;}cout << endl;for (auto e : s1){cout << e;}cout << endl;}
int main()
{test_string_iterator();return 0;
}运行结果:

4.substr()
string string::substr(size_t pos, size_t len)
{size_t leftlen = _size - pos; //求出要截取部分长度if (len > leftlen){len = leftlen;}string tmp;tmp.reserve(len);for (size_t i = 0; i < len; i++){tmp += _str[pos + i];}return tmp;
}void test_string5()
{string s1("hello world");string sub1 = s1.substr(6, 3);cout << sub1.c_str() << endl;string sub2 = s1.substr(6, 300);cout << sub2.c_str() << endl;string sub3 = s1.substr(6);cout << sub3.c_str() << endl;string s2("hello bitxxxxxxxxxxxxxxxxxx");s1 = s2;cout << s1.c_str() << endl;cout << s2.c_str() << endl;s1 = s1;cout << s1.c_str() << endl;
}
int main()
{//test_string_add();//test_string_find_erase();//test_string_iterator();test_string5();return 0;
}
5.流插入和提取
ostream& operator<<(ostream& out, const string& s){for (auto ch : s){out << ch;}return out;}istream& operator>>(istream& in, string& s){s.clear(); //此举是为了防止s原有内容对输入的影响//类比我们要接满一个大水桶,但是我们不知道需要到底具体有多少水// 正好手里有一个可以装N升水的小盆,我们可以用这个小盆装水,满了后导入大桶里// 这样可以使得:// 输入短串,不会浪费空间// 输入长串,避免不断扩容const size_t N = 1024;char buff[N];int i = 0;char ch = in.get(); //获取首个单个字符while (ch != ' ' && ch != '\n');{buff[i++] = ch;if (i == N - 1){buff[i] = '\0';s += buff;i = 0;}ch = in.get(); //获取其余诸多单个字符}//此时有两种情况:1是输入字符串的字符个数正好为N的整数倍,此时i==0;(盆里面没有水了)//2是输入字符串的字符个数不为N的整数倍,此时i>0;(盆里面还有水)if (i > 0){buff[i] = '\0';s += buff;}return in;}istream& getline(istream& in, string& s, char delim){s.clear();const size_t N = 1024;char buff[N];int i = 0;char ch = in.get();while (ch != delim){buff[i++] = ch;if (i == N - 1){buff[i] = '\0';s += buff;i = 0;}ch = in.get();}if (i > 0){buff[i] = '\0';s += buff;}return in;}
void test_string6()
{string s1, s2;cin >> s1 >> s2;cout << s1 << endl;cout << s2 << endl;string s3;//getline(cin, s3);getline(cin, s3, '!');cout << s3 << endl;
}
int main()
{//test_string_add();//test_string_find_erase();//test_string_iterator();//test_string5();test_string6();return 0;
}6.汇总:
这是string.h文件
#pragma once
#include<iostream>
#include<assert.h>
#include<string.h>
using namespace std;
namespace my_string
{class string{public:typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}const_iterator begin() const{return _str;}const_iterator end() const{return _str + _size;}string(const char* str = "");string(size_t n, char ch);string(const string& s);string& operator=(const string& s);~string();void clear(){_str[0] = '\0';_size = 0;}const char* c_str() const{return _str;}void reserve(size_t n);void push_back(char ch);void append(const char* str);string& operator+=(char ch);string& operator+=(const char* str);void insert(size_t pos, size_t n, char ch);void insert(size_t pos, const char* str);void erase(size_t pos = 0, size_t len = npos);size_t find(char ch, size_t pos = 0);size_t find(const char* str, size_t pos = 0);size_t size()const{return _size;}size_t capacity()const{return _size;}char& operator[](size_t pos) const{assert(pos < _size);return _str[pos];}string substr(size_t pos, size_t len = npos);bool operator==(const string& s)const;bool operator!=(const string& s)const;bool operator<(const string& s)const;bool operator<= (const string & s)const;bool operator>(const string& s)const;bool operator>=(const string& s)const;private:char* _str;size_t _size;size_t _capacity;const static size_t npos;};//cout<<s1ostream& operator<<(ostream& out, const string& s);//cin>>s1istream& operator<<(istream& in, string& s);istream& getline(istream& is, string& s, char delim = '#');}
这是string.cpp文件
#define _CRT_SECURE_NO_WARNINGS 1
#include"string.h"
namespace my_string
{const size_t string::npos = -1;string::string(size_t n, char ch):_str(new char[n + 1]), _size(n), _capacity(n){for (size_t i = 0; i < n; i++){_str[i] = ch;}_str[_size] = '\0';}string::string(const char* str):_size(strlen(str)){_capacity = _size;_str = new char[_size + 1]; //多开一个空间放\0strcpy(_str, str);}//s2(s1)string::string(const string& s){_str = new char[s._capacity + 1]; //永远都记得多开一个strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}//s1=s2//s1=s1(不建议这样做)string& string::operator=(const string& s){//this :s1 s:s2if (this != &s) //避免s1=s1这种事件发生{//这里由于我们之前在构造_str的时候使用new[]了,但为了我们之后将s2拷贝给s1,//我们要开一个能装下s2的空间,所以这里我们先delete[],再new[]一个,用于拷贝s2,//注意,strcpy不能变插边扩容,这才是我们这么做的根本原因delete[] _str;_str = new char[s._capacity + 1];strcpy(_str, s._str);_size = s._size;_capacity = s._capacity;}return *this; //我们要通过s2构造s1,故返回*this}string::~string(){delete[] _str;_str = nullptr;_size = _capacity = 0;}void string::reserve(size_t n){if (n > _capacity){char* tmp = new char[n + 1];strcpy(tmp, _str);delete[] _str;_str = tmp;_capacity = n;}}void string::push_back(char ch){if (_size + 1 > _capacity){//意味着此时已经满了,需要扩容才能插入//扩容,建议使用函数复用//还要讨论原来容量是不是0reserve(_capacity == 0 ? 4 : _capacity * 2);}//此时已经完成扩容,容量足够用_str[_size] = ch;_size++;_str[_size] = '\0'; //别忘了把\0也考过来}void string::append(const char* str){//注:我们这里是直接按照库里的思路去实现的 // 在这里扩容_size+len也是可以的 只不过思路不一样// 也可能官方认为追加直接扩二倍 后面人继续使用的时候可以少调几次开空间吧size_t len = strlen(str);if (_size + len > _capacity){//意味着此时已经满了,需要扩容才能插入//扩容,与push_back不同的是,// 默认使用append是认为你这个字符串原先就是有内容才追加的// 如果害怕有人确实会直接使用这个接口 可以加上_capacity=0的情况size_t newcapacity = 2 * _capacity;//考虑到可能插入的字符串过长,2倍扩容都可能不够//为防止越界的产生,我们再严谨的讨论一下if (_size + len > 2 * _capacity){newcapacity = _size + len;}reserve(newcapacity);}//strcpy在拷贝时会从第一个字符出发找\0,// 为了节约编译器运行时间,我们直接手动让他从\0出发strcpy(_str + _size, str); _size += len; }string& string::operator+=(char ch){push_back(ch);return *this;}string& string::operator+=(const char* str){append(str);return *this;}void string::insert(size_t pos, size_t n, char ch){assert(pos <= _size);assert(n > 0);//还是要考虑扩容问题if (_size + n > _capacity){size_t newcapacity = 2 * _capacity;if (_size + n > 2 * _capacity){newcapacity = _size + n;}reserve(newcapacity);}size_t end = _size + n; //一切以\0为准while (end > pos + n - 1) //准备挪动数据,这是需要挪动的数据范围{_str[end] = _str[end - n];//最后一个数据先动end--;}//挪完了,有地方了,但是要插入的数还没进来呢!for (size_t i = 0; i < n; i++){_str[pos + i] = ch;}_size += n;}void string::insert(size_t pos, const char* str){assert(pos <= _size);size_t n = strlen(str);if (_size + n > _capacity){size_t newCapacity = 2 * _capacity;if (_size + n > 2 * _capacity){newCapacity = _size + n;}reserve(newCapacity);}size_t end = _size + n;while (end > pos + n - 1){_str[end] = _str[end - n];--end;}for (size_t i = 0; i < n; i++){_str[pos + i] = str[i];}}void string::erase(size_t pos, size_t len){if (len > _size - pos){_str[pos] = '\0';_size = pos;}else{size_t end = pos + len;{while (end <= _size){_str[end - len] = _str[end];++end;}_size -= len;}}}size_t string::find(char ch, size_t pos){for (size_t i = pos; i < _size; i++){if (_str[i] == ch){return i;}}return npos;}size_t string::find(const char* str, size_t pos){const char* p = strstr(_str + pos, str); //strstr() 函数的作用是在一个字符串(str1)中查找另一个字符串(str2)的出现位置。//如果找到,它返回一个指向 str1 中第一次出现的 str2 的指针;// 如果找不到,则返回空指针(NULL)。if (p == nullptr){return npos;}else{return p - _str; //两个指针相减,结果得到这个元素的下标}}string string::substr(size_t pos, size_t len){size_t leftlen = _size - pos; //求出要截取部分长度if (len > leftlen){len = leftlen;}string tmp;tmp.reserve(len);for (size_t i = 0; i < len; i++){tmp += _str[pos + i];}return tmp;}bool string::operator==(const string& s)const{return strcmp(_str, s._str) == 0;}bool string::operator!=(const string& s)const{return !(*this == s);}bool string::operator<(const string& s)const{return strcmp(_str, s._str) < 0;}bool string::operator<=(const string& s)const{return *this < s || *this == s;}bool string::operator>(const string& s)const{return !(*this <= s);}bool string::operator>=(const string& s)const{return *this == s || *this > s;}ostream& operator<<(ostream& out, const string& s){for (auto ch : s){out << ch;}return out;}istream& operator>>(istream& in, string& s){s.clear(); //此举是为了防止s原有内容对输入的影响//类比我们要接满一个大水桶,但是我们不知道需要到底具体有多少水// 正好手里有一个可以装N升水的小盆,我们可以用这个小盆装水,满了后导入大桶里// 这样可以使得:// 输入短串,不会浪费空间// 输入长串,避免不断扩容const size_t N = 1024;char buff[N];int i = 0;char ch = in.get(); //获取首个单个字符while (ch != ' ' && ch != '\n');{buff[i++] = ch;if (i == N - 1){buff[i] = '\0';s += buff;i = 0;}ch = in.get(); //获取其余诸多单个字符}//此时有两种情况:1是输入字符串的字符个数正好为N的整数倍,此时i==0;(盆里面没有水了)//2是输入字符串的字符个数不为N的整数倍,此时i>0;(盆里面还有水)if (i > 0){buff[i] = '\0';s += buff;}return in;}istream& getline(istream& in, string& s, char delim){s.clear();const size_t N = 1024;char buff[N];int i = 0;char ch = in.get();while (ch != delim){buff[i++] = ch;if (i == N - 1){buff[i] = '\0';s += buff;i = 0;}ch = in.get();}if (i > 0){buff[i] = '\0';s += buff;}return in;}
}这是test.cpp文件
#include"string.h"
#include<string>
void test_string_add()
{string s1("hello world");cout << s1.c_str() << endl;s1 += ' ';cout << s1.c_str() << endl;s1 += '+';cout << s1.c_str() << endl;s1 += "hello everybody";cout << s1.c_str() << endl;s1.push_back(',');cout << s1.c_str() << endl;s1.append("welcome!");cout << s1.c_str() << endl;s1.insert(6,1, 't');cout << s1.c_str() << endl;s1.insert(7, "he ");cout << s1.c_str() << endl;s1.insert(41, "nice to meet you");cout << s1.c_str() << endl;s1.insert(0, "good morning!");cout << s1.c_str() << endl;
}
void test_string_find_erase()
{string s1("hello world");cout << s1.c_str() << endl;s1.erase(6,2);cout << s1.c_str() << endl;s1.erase(6, 20);cout << s1.c_str() << endl;s1.erase(3);cout << s1.c_str() << endl;string s2("welcome to guangzhou!");cout << s2.find('o') << endl;cout << s2.find("guangzh") << endl;}
void test_string_iterator()
{string s1("hello world");for (size_t i = 0; i < s1.size(); i++){s1[i]++;cout << s1[i] << " ";}cout << endl;string::iterator it = s1.begin();while (it != s1.end()){cout << *it << " ";++it;}cout << endl;for (auto e : s1){cout << e;}cout << endl;}
void test_string5()
{string s1("hello world");string sub1 = s1.substr(6, 3);cout << sub1.c_str() << endl;string sub2 = s1.substr(6, 300);cout << sub2.c_str() << endl;string sub3 = s1.substr(6);cout << sub3.c_str() << endl;string s2("hello bitxxxxxxxxxxxxxxxxxx");s1 = s2;cout << s1.c_str() << endl;cout << s2.c_str() << endl;s1 = s1;cout << s1.c_str() << endl;
}
void test_string6()
{string s1, s2;cin >> s1 >> s2;cout << s1 << endl;cout << s2 << endl;string s3;//getline(cin, s3);getline(cin, s3, '!');cout << s3 << endl;
}
int main()
{//test_string_add();//test_string_find_erase();//test_string_iterator();//test_string5();test_string6();return 0;
}相关文章:
string类函数的手动实现
在上一篇文章中,我们讲解了一些string类的函数,但是对于我们要熟练掌握c是远远不够的,今天,我将手动实现一下这些函数~ 注意:本篇文章中会大量应用复用,这是一种很巧妙的方法 和以往一样,还是…...

Oceanbase离线集群部署
准备工作 两台服务器 服务器的配置参照官网要求来 服务器名配置服务器IPoceanbase116g8h192.168.10.239oceanbase216g8h192.168.10.239 这里选oceanbase1作为 obd机器 oceanbase安装包 选择社区版本的时候自己系统的安装包 ntp时间同步rpm包 联网机器下载所需的软件包 …...

transformers生成式对话机器人
简介 生成式对话机器人是一种先进的人工智能系统,它能够通过学习大量的自然语言数据来模拟人类进行开放、连贯且创造性的对话。与基于规则或检索式的聊天机器人不同,生成式对话机器人并不局限于预定义的回答集,而是可以根据对话上下文动态地…...

WPF中的VisualState(视觉状态)
以前在设置控件样式或自定义控件时,都是使用触发器来进行样式更改。触发器可以在属性值发生更改时启动操作。 像这样: <Style TargetType"ListBoxItem"><Setter Property"Opacity" Value"0.5" /><Setter …...
)
C#设计模式--状态模式(State Pattern)
状态模式是一种行为设计模式,它允许对象在其内部状态发生变化时改变其行为。这种模式的核心思想是将状态封装在独立的对象中,而不是将状态逻辑散布在整个程序中。 用途 简化复杂的条件逻辑:通过将不同的状态封装在不同的类中,可…...
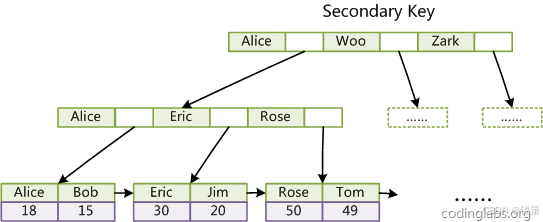
〔 MySQL 〕索引
目录 1. 没有索引,可能会有什么问题 2. 认识磁盘 MySQL与存储 先来研究一下磁盘: 在看看磁盘中一个盘片编辑 扇区 定位扇区编辑 结论 磁盘随机访问(Random Access)与连续访问(Sequential Access) 3. MySQL 与磁盘交互基本单位 4. 建立共识…...
计算机网络研究实训室建设方案
一、概述 本方案旨在规划并实施一个先进的计算机网络研究实训室,旨在为学生提供一个深入学习、实践和研究网络技术的平台。实训室将集教学、实验、研究于一体,覆盖网络基础、网络架构、网络安全、网络管理等多个领域,以培养具备扎实理论基础…...

韩企研学团造访图为科技:共探人工智能创新前沿
今日,一支由韩国知名企业研学专家组成的代表团莅临图为科技深圳总部,展开了一场深度技术交流与研讨活动。 此次访问旨在通过实地探访中国领先的科技企业,促进中韩两国在科技创新领域的深入合作与交流。 韩国游学团合影 图为科技作为一家在人…...

html button 按钮单选且 高亮
<DIV class"middle"> <div class"containerTarget"> <span class"hover-target1" οnclick"btn(1);">韵达 </span> <span class"hover-target2" οnclick"btn(2);">中通 </span…...

图片上传HTML
alioss sky:jwt:# 设置jwt签名加密时使用的秘钥admin-secret-key: itcast# 设置jwt过期时间admin-ttl: 7200000# 设置前端传递过来的令牌名称admin-token-name: tokenalioss:endpoint: ${sky.alioss.endpoint}access-key-id: ${sky.alioss.access-key-id}access-key-secret: $…...

C++学习-函数
C 函数 目录 函数默认参数引用传参函数重载 数量不同类型不同 内联函数 函数默认参数 #include<iostream>using std::cout; using std::endl;int power(int n, int x2); // x2 是默认参数int main() {cout << power(5) << endl; // 没有传 x 的值&#x…...

spring boot 测试 mybatis mapper类
spring boot 测试 mybatis mapper类 针对 mybatis plus不启动 webserver指定加载 xml 【过滤 “classpath*:/mapper/**/*.xml” 下的xml】, mapper xml文件名和mapper java文件名称要一样,是根据文件名称过滤的。默认情况加载和解析所有mapper.xml 自定义 MapperT…...

远程游戏新体验!
在这个数字化的时代,游戏已经不仅限于家里的电视或书房的电脑了。远程游戏,也就是通过远程控制软件在不同地点操作游戏设备,给玩家带来了前所未有的自由和灵活性。RayLink远程控制软件,凭借其出色的性能和专为游戏设计的功能&…...
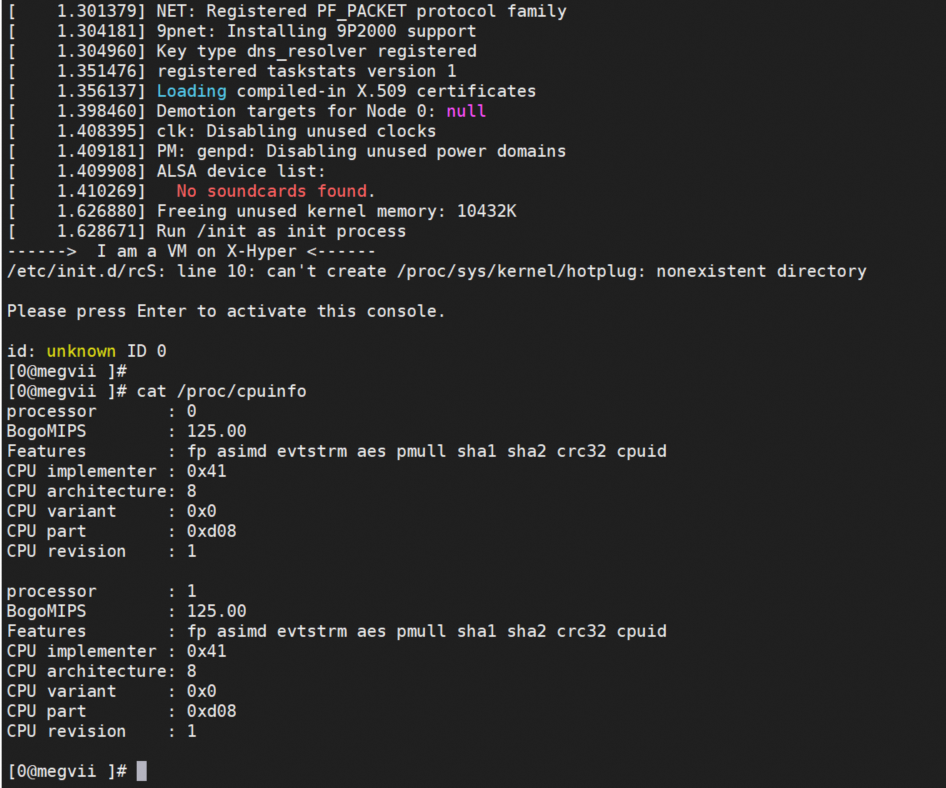
Let up bring up a linux.part2 [十一]
之前的篇幅中我们已经将 Linux 内核 bringup 起来了,不知道大家有没有去尝试将根文件系统运行起来,今天我就带领大家完成这个事情,可以跟着下面的步骤一步步来完成: 在这里我们使用 busybox 构建 rootfs: 下载 busyb…...

调用大模型api 批量处理图像 保存到excel
最近需要调用大模型,并将结果保存到excel中,效果如下: 代码: import base64 from zhipuai import ZhipuAI import os import pandas as pd from openpyxl import Workbook from openpyxl.drawing.image import Image from io i…...
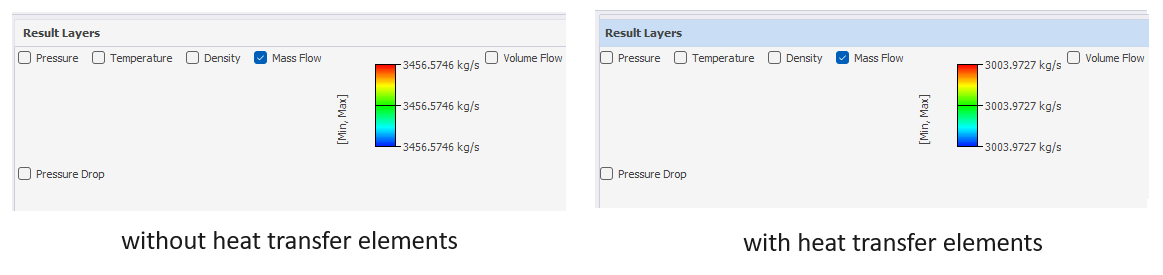
使用 Flownex 模拟热环境对原油运输的影响
石油和天然气行业经常使用管道仿真来模拟原油的流动。为了准确估计管道容量,必须考虑环境对管道的热影响以及环境温度如何影响油品特性。本博客介绍了如何通过将传热元件集成到管道流网中,以及使用新的工作液材料 Flownex 来模拟各种传热机制。 使用 Fl…...

【WRF-Urban】WPS中有关Urban的变量设置
【WRF-Urban】WPS中有关Urban的变量设置 地理数据源的配置WRF-Urban所需静态地理数据1、LANDUSE:包含城市地表分类的土地利用数据。2、URB_PARAM:城市参数数据集。3、FRC_URB2D:城市覆盖度数据集WRF默认设置(美国)数据集1-National urban dataset in China NUDC(中国)数…...
Socket编程-tcp
1. 前言 在tcp套接字编程这里,我们将完成两份代码,一份是基于tcp实现普通的对话,另一份加上业务,client输入要执行的命令,server将执行结果返回给client 2. tcp_echo_server 与udp类似,前两步࿱…...
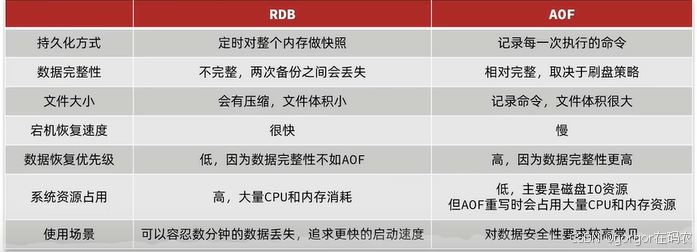
Redis 之持久化
目录 介绍 RDB RDB生成方式 自动触发 手动触发 AOF(append-only file) Redis 4.0 混合持久化 Redis主从工作原理 总结 介绍 Redis提供了两个持久化数据的能力,RDB Snapshot 和 AOF(Append Only FIle)…...
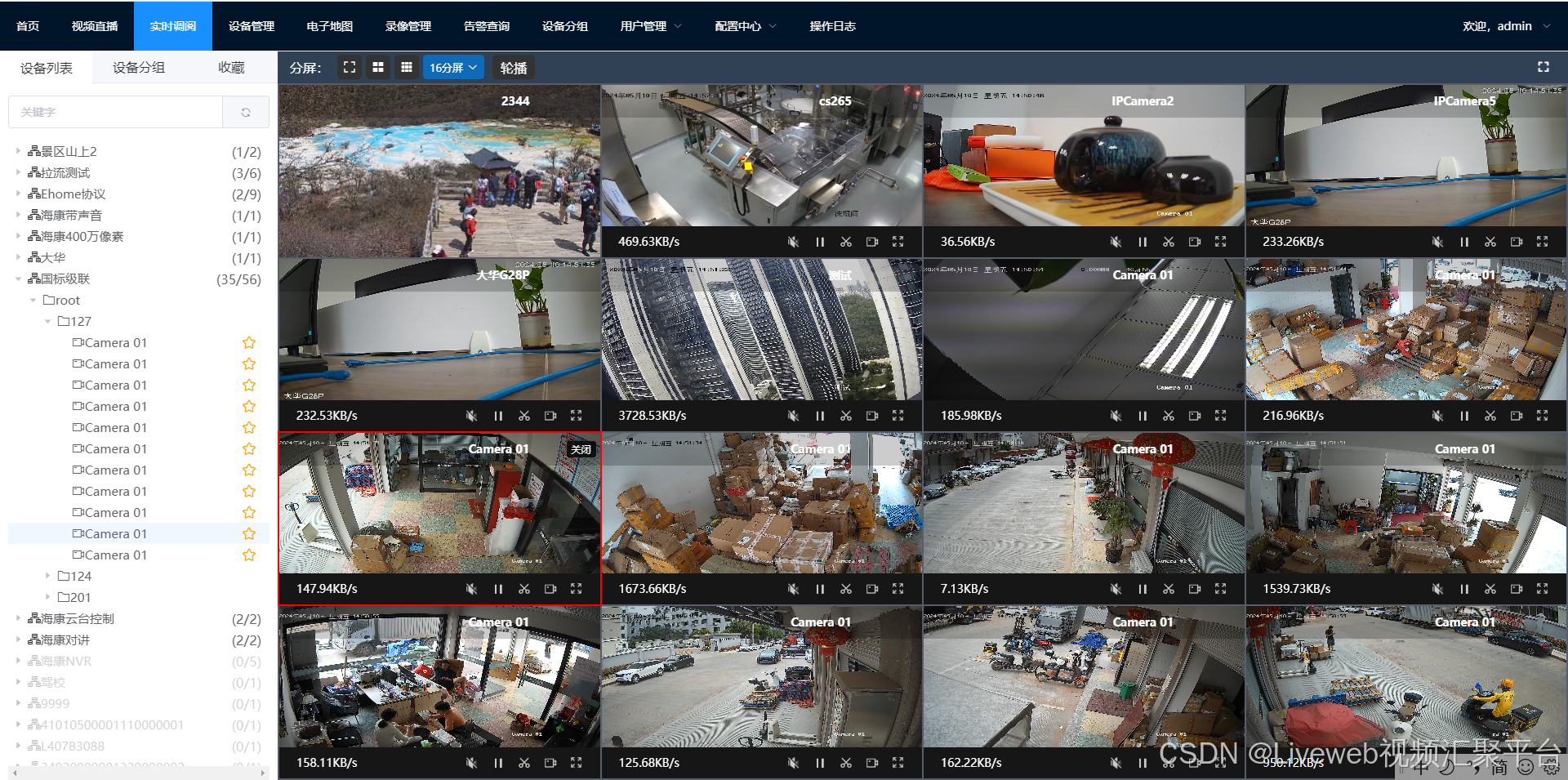
视频监控汇聚平台:Liveweb安防监控平台实现接入监控视频集中管理方案
随着各行业数字化转型的不断推进,视频监控技术在行业内的安防应用及管理支撑日益增多。然而,由于前期规划不清晰、管理不到位等问题,视频监管系统普遍存在以下问题: 1. 各部门单位在视频平台建设中以所属领域为单位,导…...

低压电工-电子技术常识
一、导体、绝缘体、半导体(按电阻率划分)1. 划分标准单位是 Ω・cm(欧姆・厘米),不是单纯欧姆 (Ω),是电阻率专用单位:欧姆・厘米 Ω⋅cm,也可以用 Ω⋅m(欧姆・米&#…...

开源硬件性能遥测工具openclaw_telemetry:从数据采集到可视化实战
1. 项目概述:从开源遥测数据中洞察硬件性能在硬件开发和性能调优的领域,数据是驱动决策的基石。我们常常需要实时监控CPU、GPU、内存、温度、功耗等一系列关键指标,以评估系统稳定性、定位性能瓶颈或验证优化效果。然而,构建一套稳…...

【无人机路径规划】基于K-means 聚类和遗传算法实现多架无人机任务区域进行划分,并优化各区域内的访问路径附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

基于RAG与向量数据库的智能知识库系统构建实战
1. 项目概述:当AI成为你的“第二大脑”最近在折腾一个挺有意思的开源项目,叫IIMS-By-AI。这个名字乍一看有点唬人,IIMS是“Intelligent Information Management System”的缩写,翻译过来就是“智能信息管理系统”。但它的核心玩法…...

魔兽世界宏编辑器终极指南:5分钟掌握GSE高级宏编译工具
魔兽世界宏编辑器终极指南:5分钟掌握GSE高级宏编译工具 【免费下载链接】GSE-Advanced-Macro-Compiler GSE is an alternative advanced macro editor and engine for World of Warcraft. 项目地址: https://gitcode.com/gh_mirrors/gs/GSE-Advanced-Macro-Compi…...

从零到一:ESP8266-12F最小系统板MQTT固件烧录实战
1. 为什么选择ESP8266-12F最小系统板? 很多朋友刚开始接触物联网开发时,都会选择NodeMCU这样的开发板。确实,NodeMCU自带USB转串口芯片,插上电脑就能直接烧录程序,对新手特别友好。但当你真正想把项目做成产品时&#…...

如何5分钟掌握QRemeshify:Blender四边形网格重构终极指南
如何5分钟掌握QRemeshify:Blender四边形网格重构终极指南 【免费下载链接】QRemeshify A Blender extension for an easy-to-use remesher that outputs good-quality quad topology 项目地址: https://gitcode.com/gh_mirrors/qr/QRemeshify 你是否曾被Blen…...

SillyTavern角色卡片系统:打造属于你的AI灵魂伴侣
SillyTavern角色卡片系统:打造属于你的AI灵魂伴侣 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 你是否曾经幻想过,能有一个真正理解你、陪伴你的AI伙伴࿱…...

从BERT到GPT-4:大语言模型的技术演进与应用实践
1. 从单向到双向:大语言模型如何重塑AI的认知边界如果你在2018年之前问我,一个AI模型能不能同时理解一句话里每个词的前后文关系,我会告诉你这很难。那时的主流模型,比如OpenAI的GPT初代,就像一个只能从左到右阅读的读…...

终极指南:FigmaCN中文插件让设计师告别英文障碍
终极指南:FigmaCN中文插件让设计师告别英文障碍 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的全英文界面而烦恼吗?Figma中文插件FigmaCN正是为你…...