深入解析强化学习中的 Generalized Advantage Estimation (GAE)
中文版
深入解析强化学习中的 Generalized Advantage Estimation (GAE)
1. 什么是 Generalized Advantage Estimation (GAE)?
在强化学习中,计算策略梯度的关键在于 优势函数(Advantage Function) 的设计。优势函数 ( A ( s , a ) A(s, a) A(s,a) ) 衡量了执行某动作 ( a a a ) 比其他动作的相对价值。然而,优势函数的估计往往面临以下两大问题:
- 高方差问题:由于强化学习中的样本通常有限,直接使用单步回报或 Monte Carlo 方法计算优势值会导致高方差。
- 偏差问题:使用引入近似函数(如值函数 ( V ( s ) V(s) V(s) ))会降低方差,但可能引入偏差。
为了平衡 偏差和方差,Schulman 等人在 2016 年提出了 Generalized Advantage Estimation (GAE) 方法,它是一种在偏差和方差之间权衡的优势函数估计方法,被广泛应用于强化学习中的近端策略优化(PPO)等算法。
2. GAE 的数学原理
GAE 的核心思想是通过时间差分(Temporal Difference, TD)误差的加权和,估计优势函数:
TD 残差(Temporal Difference Residuals):
δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st)
GAE 的递归定义:
A t GAE = ∑ l = 0 ∞ ( γ λ ) l δ t + l A_t^\text{GAE} = \sum_{l=0}^\infty (\gamma \lambda)^l \delta_{t+l} AtGAE=l=0∑∞(γλ)lδt+l
其中:
- ( γ \gamma γ ) 是折扣因子,用于控制未来回报的权重。
- ( λ \lambda λ ) 是 GAE 的衰减系数,控制长期和短期偏差的平衡。
- ( δ t \delta_t δt ) 是每一步的 TD 残差,反映即时回报和值函数的差异。
GAE 的公式可以通过递归形式表示为:
A t GAE = δ t + ( γ λ ) ⋅ A t + 1 GAE A_t^\text{GAE} = \delta_t + (\gamma \lambda) \cdot A_{t+1}^\text{GAE} AtGAE=δt+(γλ)⋅At+1GAE
通过 ( λ \lambda λ ) 的调节,GAE 可以在单步 TD 估计(低方差高偏差)和 Monte Carlo 估计(高方差低偏差)之间找到一个平衡点。
3. GAE 在 PPO 中的应用
PPO paper:https://arxiv.org/pdf/1707.06347
在近端策略优化(PPO)算法中,策略梯度的更新依赖于优势函数 ( A t A_t At ) 的估计,而 GAE 为优势函数的估计提供了一个高效的工具。
PPO 的 损失函数 包括两部分:
-
策略更新(Actor Loss):
L actor = E t [ min ( r t ( θ ) ⋅ A t GAE , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) ⋅ A t GAE ) ] L^\text{actor} = \mathbb{E}_t \left[ \min(r_t(\theta) \cdot A_t^\text{GAE}, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \cdot A_t^\text{GAE}) \right] Lactor=Et[min(rt(θ)⋅AtGAE,clip(rt(θ),1−ϵ,1+ϵ)⋅AtGAE)]
其中 ( r t ( θ ) r_t(\theta) rt(θ) ) 是当前策略与旧策略的概率比。 -
值函数更新(Critic Loss):
L critic = E t [ ( R t − V ( s t ) ) 2 ] L^\text{critic} = \mathbb{E}_t \left[ (R_t - V(s_t))^2 \right] Lcritic=Et[(Rt−V(st))2]
PPO 使用 GAE 来高效估计 ( A t A_t At ),从而使得梯度更新既稳定又高效。
4. GAE 的代码实现
以下是 GAE 的核心代码实现:
import numpy as npdef compute_gae(rewards, values, gamma=0.99, lam=0.95):"""使用 GAE 计算优势函数Args:rewards: 每一步的即时奖励 (list or array)values: 每一步的状态值函数估计 (list or array)gamma: 折扣因子lam: GAE 的衰减系数Returns:advantages: 每一步的优势函数估计"""advantages = np.zeros_like(rewards)gae = 0 # 初始化 GAEfor t in reversed(range(len(rewards))):delta = rewards[t] + gamma * (values[t + 1] if t < len(rewards) - 1 else 0) - values[t]gae = delta + gamma * lam * gaeadvantages[t] = gaereturn advantages# 示例数据
rewards = [1, 1, 1, 1, 1] # 即时奖励
values = [0.5, 0.6, 0.7, 0.8, 0.9] # 状态值函数估计
advantages = compute_gae(rewards, values)
print("GAE 计算结果:", advantages)
5. 数值模拟
假设我们有以下场景:
- 即时奖励:玩家在每一步获得固定奖励 ( r t = 1 r_t = 1 rt=1 )。
- 状态值估计:模型估计的值函数逐步递增。
我们将模拟不同 ( λ \lambda λ ) 值对优势函数估计的影响。
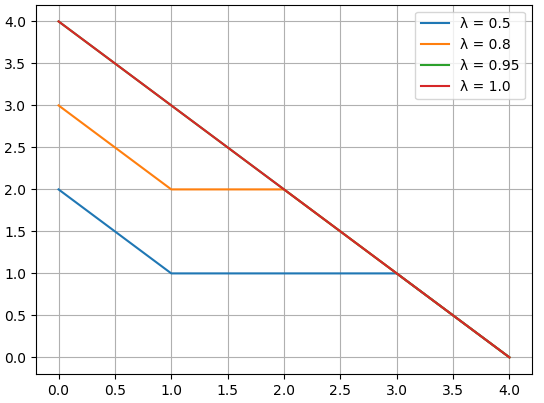
import matplotlib.pyplot as plt# 参数设置
gamma = 0.99
rewards = [1, 1, 1, 1, 1]
values = [0.5, 0.6, 0.7, 0.8, 0.9]# 不同 lambda 值的 GAE
lambda_values = [0.5, 0.8, 0.95, 1.0]
results = {}for lam in lambda_values:advantages = compute_gae(rewards, values, gamma, lam)results[lam] = advantages# 绘图
for lam, adv in results.items():plt.plot(adv, label=f"λ = {lam}")plt.xlabel("时间步 (t)")
plt.ylabel("优势函数 (A_t)")
plt.title("不同 λ 对 GAE 的影响")
plt.legend()
plt.grid()
plt.show()
绘图结果
6. 总结
-
GAE 的优势:
- 低方差:通过 ( λ \lambda λ ) 控制,引入更多的短期回报,减少方差。
- 高效率:兼顾短期 TD 和长期 Monte Carlo 的优点。
- 灵活性:可以根据任务需求调整偏差和方差的权衡。
-
PPO 中的应用:
GAE 是 PPO 算法中计算优势函数的重要工具,其估计结果直接影响策略梯度和价值函数的更新效率。
通过本文的介绍,我们可以更深入地理解 GAE 的数学原理、代码实现以及其在实际场景中的应用,希望对强化学习爱好者有所帮助!
英文版
Deep Dive into Generalized Advantage Estimation (GAE) in Reinforcement Learning
1. What is Generalized Advantage Estimation (GAE)?
In reinforcement learning, estimating the advantage function ( A ( s , a ) A(s, a) A(s,a) ) is a crucial step in computing the policy gradient. The advantage function measures how much better a specific action ( a ) is compared to others in a given state ( s s s ). However, estimating this function poses two main challenges:
- High variance: Direct computation using one-step rewards or Monte Carlo rollouts often results in high variance, which makes optimization unstable.
- Bias: Introducing approximations (e.g., using value functions ( V ( s ) V(s) V(s) )) reduces variance but introduces bias.
To balance bias and variance, Schulman et al. introduced Generalized Advantage Estimation (GAE) in 2016. GAE is an efficient method that adjusts the advantage function estimate using a weighted sum of temporal difference (TD) residuals.
2. Mathematical Foundation of GAE
The key idea of GAE is to compute the advantage function using a combination of short-term and long-term rewards, weighted by a decay factor.
Temporal Difference (TD) Residual:
δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st)
GAE Recursive Formula:
A t GAE = ∑ l = 0 ∞ ( γ λ ) l δ t + l A_t^\text{GAE} = \sum_{l=0}^\infty (\gamma \lambda)^l \delta_{t+l} AtGAE=l=0∑∞(γλ)lδt+l
Where:
- ( γ \gamma γ ) is the discount factor, controlling the weight of future rewards.
- ( λ \lambda λ ) is the GAE decay factor, balancing short-term and long-term contributions.
- ( δ t \delta_t δt ) is the TD residual, representing the difference between immediate rewards and value estimates.
Alternatively, GAE can be written recursively:
A t GAE = δ t + ( γ λ ) ⋅ A t + 1 GAE A_t^\text{GAE} = \delta_t + (\gamma \lambda) \cdot A_{t+1}^\text{GAE} AtGAE=δt+(γλ)⋅At+1GAE
By adjusting ( λ \lambda λ ), GAE can interpolate between:
- Low variance, high bias: ( λ = 0 \lambda = 0 λ=0 ) (one-step TD residual).
- High variance, low bias: ( λ = 1 \lambda = 1 λ=1 ) (Monte Carlo return).
3. Application of GAE in PPO
In Proximal Policy Optimization (PPO), GAE plays a critical role in estimating the advantage function, which is used in both the policy update and value function update.
PPO Loss Function:
-
Actor Loss (Policy Update):
L actor = E t [ min ( r t ( θ ) ⋅ A t GAE , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) ⋅ A t GAE ) ] L^\text{actor} = \mathbb{E}_t \left[ \min(r_t(\theta) \cdot A_t^\text{GAE}, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \cdot A_t^\text{GAE}) \right] Lactor=Et[min(rt(θ)⋅AtGAE,clip(rt(θ),1−ϵ,1+ϵ)⋅AtGAE)]
Where ( r t ( θ ) r_t(\theta) rt(θ) ) is the probability ratio between the new and old policies. -
Critic Loss (Value Function Update):
L critic = E t [ ( R t − V ( s t ) ) 2 ] L^\text{critic} = \mathbb{E}_t \left[ (R_t - V(s_t))^2 \right] Lcritic=Et[(Rt−V(st))2]
PPO relies on GAE to provide a stable and accurate advantage estimate ( A t GAE A_t^\text{GAE} AtGAE ), ensuring efficient policy gradient updates.
4. Code Implementation
Below is a Python implementation of GAE:
import numpy as npdef compute_gae(rewards, values, gamma=0.99, lam=0.95):"""Compute Generalized Advantage Estimation (GAE).Args:rewards: List of rewards at each timestep.values: List of value function estimates at each timestep.gamma: Discount factor.lam: GAE decay factor.Returns:advantages: GAE-based advantage estimates."""advantages = np.zeros_like(rewards)gae = 0 # Initialize GAEfor t in reversed(range(len(rewards))):delta = rewards[t] + gamma * (values[t + 1] if t < len(rewards) - 1 else 0) - values[t]gae = delta + gamma * lam * gaeadvantages[t] = gaereturn advantages# Example usage
rewards = [1, 1, 1, 1, 1] # Reward at each timestep
values = [0.5, 0.6, 0.7, 0.8, 0.9] # Value function estimates
advantages = compute_gae(rewards, values)
print("GAE Advantages:", advantages)
# GAE 计算结果: [4 3 2 1 0]
5. Numerical Simulation
We can simulate how different values of ( λ \lambda λ ) impact the GAE estimates using the following script:
import matplotlib.pyplot as plt# Parameters
gamma = 0.99
rewards = [1, 1, 1, 1, 1]
values = [0.5, 0.6, 0.7, 0.8, 0.9]# Compute GAE for different lambda values
lambda_values = [0.5, 0.8, 0.95, 1.0]
results = {}for lam in lambda_values:advantages = compute_gae(rewards, values, gamma, lam)results[lam] = advantages# Plot the results
for lam, adv in results.items():plt.plot(adv, label=f"λ = {lam}")plt.xlabel("Time Step (t)")
plt.ylabel("Advantage (A_t)")
plt.title("Impact of λ on GAE")
plt.legend()
plt.grid()
plt.show()
6. Summary
-
What GAE Solves:
- GAE balances the bias-variance trade-off in advantage estimation, making it a key tool in reinforcement learning.
-
GAE in PPO:
- GAE ensures stable and efficient policy updates by providing accurate advantage estimates for the actor-critic framework.
-
Key Takeaways:
- ( λ \lambda λ ) is a critical hyperparameter in GAE, allowing control over the trade-off between bias and variance.
- GAE is widely adopted in modern reinforcement learning algorithms, particularly in on-policy methods like PPO.
This blog post illustrates the importance of GAE in reinforcement learning, along with its implementation and impact on training stability. By leveraging GAE, algorithms like PPO achieve superior performance in complex environments.
后记
2024年12月12日21点38分于上海,在GPT4o大模型辅助下完成。
相关文章:
深入解析强化学习中的 Generalized Advantage Estimation (GAE)
中文版 深入解析强化学习中的 Generalized Advantage Estimation (GAE) 1. 什么是 Generalized Advantage Estimation (GAE)? 在强化学习中,计算策略梯度的关键在于 优势函数(Advantage Function) 的设计。优势函数 ( A ( s , a ) A(s, a…...

离开wordpress
wordpress确实挺好用的 插件丰富 主题众多 收费的插件也很多 国内的做主题的也挺好 但是服务器跑起来各种麻烦伤脑筋 需要花在维护的时间太多了 如果你的网站持续盈利 你就会更担心访问质量访问速度 而乱七八糟的爬虫黑客 让你的服务器不堪重负 突然有一天看到了静态站…...

Python的3D可视化库【vedo】1-4 (visual模块) 体素可视化、光照控制、Actor2D对象
文章目录 6. VolumeVisual6.1 关于体素6.2 显示效果6.2.1 遮蔽6.2.2 木纹或磨砂效果 6.3 颜色和透明度6.3.1 透明度衰减单位6.3.2 划分透明度标量梯度6.3.3 设置颜色或渐变6.3.4 标量的计算模式6.3.5 标量的插值方式 6.4 过滤6.4.1 按单元格id隐藏单元格6.4.2 按二进制矩阵设置…...
使用html和JavaScript实现一个简易的物业管理系统
码实现了一个简易的物业管理系统,主要使用了以下技术和功能: 1.主要技术 使用的技术: HTML: 用于构建网页的基本结构。包括表单、表格、按钮等元素。 CSS: 用于美化网页的外观和布局。设置字体、颜色、边距、对齐方式等样式。 JavaScript…...

什么是纯虚函数?什么是抽象类?纯虚函数和抽象类在面向对象编程中的意义是什么?
纯虚函数 纯虚函数是一个在基类中声明但不实现的虚函数。它的声明方式是在函数声明的末尾添加 0。这意味着这个函数没有提供具体的实现,任何继承这个基类的派生类都必须提供这个函数的实现,否则它们也会变成抽象类,无法实例化。 示例&#…...

#Ts篇: Record<string, number> 是 TypeScript 中的一种类型定义,它表示一个键值对集合
Record<string, number> 是 TypeScript 中的一种类型定义,它表示一个键值对集合,其中键的类型是 string,而值的类型是 number。具体来说,Record<K, T> 是 TypeScript 的一个内置高级类型,用于根据传入的键…...
Exp 智能协同管理系统前端首页框架开发
一、 需求分析 本案例的主要目标是开发一个智能学习辅助系统的前端界面,涵盖以下功能模块: 首页:显示系统的总体概览和关键功能介绍。 班级学员管理:实现班级管理和学员管理。 系统信息管理:管理部门和员工信息。 …...

C# 备份文件夹
C# 备份目标文件夹 方法1:通过 递归 或者 迭代 结合 C# 方法 参数说明: sourceFolder:源文件夹路径destinationFolder:目标路径excludeNames:源文件夹中不需备份的文件或文件夹路径哈希表errorLog:输出错…...

互联网信息泄露与安全扫描工具汇总
文章目录 1. 代码托管平台渠道泄露2. 网盘渠道泄露3. 文章渠道泄露4. 文档渠道泄露5. 暗网渠道泄露6. 互联网IP信誉度排查7. 网站挂马暗链扫描8. 互联网IP端口扫描9. 互联网资产漏洞扫描 1. 代码托管平台渠道泄露 https://github.com/ https://gitee.com/ https://gitcode.co…...

主导极点,传递函数零极点与时域模态
运动模态 控制系统的数学建模,可以采用微分方程或传递函数,两者具有相同的特征方程。在数学上,微分方程的解由特解和通解组成,具体求解过程可以参考:微分方程求解的三种解析方法。 如果 n n n阶微分方程,具…...

永恒之蓝漏洞利用什么端口
永恒之蓝(EternalBlue)是一个著名的漏洞,影响了 Windows 操作系统的 SMBv1 服务。它的漏洞编号是 CVE-2017-0144,该漏洞被用于 WannaCry 等勒索病毒的传播。 永恒之蓝漏洞利用的端口 永恒之蓝漏洞利用的是 SMB(Server…...

网络安全与防范
1.重要性 随着互联网的发达,各种WEB应用也变得越来越复杂,满足了用户的各种需求,但是随之而来的就是各种网络安全的问题。了解常见的前端攻击形式和保护我们的网站不受攻击是我们每个优秀fronter必备的技能。 2.分类 XSS攻击CSRF攻击网络劫…...

Navicat 17 功能简介 | SQL 开发
Navicat 17 功能简介 | SQL 开发 随着 17 版本的发布,Navicat 也带来了众多的新特性,包括兼容更多数据库、全新的模型设计、可视化智能 BI、智能数据分析、可视化查询解释、高质量数据字典、增强用户体验、扩展 MongoDB 功能、轻松固定查询结果、便捷URI…...

嵌入式系统中的并行编程模型:汇总解析与应用
概述:随着嵌入式系统处理能力的不断提升,并行编程在其中的应用愈发广泛。本文深入探讨了多种专门为嵌入式设计的并行编程模型,包括任务队列模型、消息传递模型、数据并行模型、异构多核并行模型、实时任务调度模型以及函数式并行模型。详细阐…...

VulkanSamples编译记录
按照BUILD.md说明,先安装依赖项 sudo apt-get install git build-essential libx11-xcb-dev \libxkbcommon-dev libwayland-dev libxrandr-dev 然后创建一个新文件夹build,在该目录下更新依赖项 cd VulkanSamples mkdir build cd build python ../scr…...
)
使用FabricJS对大图像应用滤镜(巨坑)
背景:我司在canvas的渲染模板的宽高都大于2048px 都几乎接近4000px,就导致使用FabricJS的滤镜功能图片显示异常 新知识:滤镜是对图片纹理的处理 FabricJS所能支持的最大图片纹理是2048的 一但图片超出2048的纹理尺寸 当应用滤镜时,图像会被剪切或者是缩…...

网页502 Bad Gateway nginx1.20.1报错与解决方法
目录 网页报错的原理 查到的502 Bad Gateway报错的原因 出现的问题和尝试解决 问题 解决 网页报错的原理 网页显示502 Bad Gateway 报错原理是用户访问服务器时,nginx代理服务器接收用户信息,但无法反馈给服务器,而出现的报错。 查到…...

Spring基础分析02-BeanFactory与ApplicationContext
大家好,今天和大家一起学习整理一下Spring 的BeanFactory和ApplicationContext内容和区别~ BeanFactory和ApplicationContext是Spring IoC容器的核心组件,负责管理应用程序中的Bean生命周期和配置。我们深入分析一下这两个接口的区别、使用场景及其提供…...

Rerender A Video 技术浅析(五):对象移除与自动配色
Rerender A Video 是一种基于深度学习和计算机视觉技术的视频处理工具,旨在通过智能算法对视频进行重新渲染和优化。 一、对象移除模块 1. 目标检测 1.1 概述 目标检测是对象移除的第一步,旨在识别视频中需要移除的对象并生成相应的掩码(m…...

Java项目实战II基于微信小程序的小区租拼车管理信息系统 (开发文档+数据库+源码)
目录 一、前言 二、技术介绍 三、系统实现 四、核心代码 五、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。 一、前言 随着城市化进程的加速,小区居民对于出行方…...

大语言模型百科全书:LLMSurvey项目解析与QLoRA微调实战
1. 项目概述:一份关于大语言模型的“百科全书”如果你最近在关注人工智能,特别是大语言模型(LLM)领域,那么你很可能已经感受到了信息过载的冲击。每天都有新的模型发布、新的评测榜单刷新、新的技术论文涌现。对于研究…...

7种智能提取方案深度解析:网盘直链下载助手的跨平台文件管理革命
7种智能提取方案深度解析:网盘直链下载助手的跨平台文件管理革命 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云…...

京东自动抢购工具完整指南:5分钟学会Python自动化购物
京东自动抢购工具完整指南:5分钟学会Python自动化购物 【免费下载链接】autobuy-jd 使用python语言的京东平台抢购脚本 项目地址: https://gitcode.com/gh_mirrors/au/autobuy-jd 还在为京东秒杀抢不到心仪商品而烦恼吗?想要在促销活动中轻松抢购…...
)
保姆级教程:用Docker部署Jenkins时,如何搞定Agent节点的50000端口映射(附避坑点)
深度解析Docker化Jenkins部署:50000端口映射全攻略与实战避坑指南 Jenkins作为持续集成领域的标杆工具,其容器化部署已成为现代DevOps实践的标配。但当Master节点运行在Docker环境中时,Agent节点连接失败的场景屡见不鲜——其中80%的问题根源…...
)
别再死记硬背参数了!用Amesim HCD库手把手教你搭建一个真实的溢流阀模型(附避坑指南)
从物理本质出发:用Amesim HCD库构建高保真溢流阀模型的实践指南 液压系统工程师常常陷入一个困境:软件操作熟练,参数设置却总凭感觉;仿真结果看似合理,却与物理直觉相悖。这种"黑箱式"建模不仅限制了问题排…...
)
智慧航运主题汇总(2026-05-13更新)
智慧航运主要包括利用区块链、大数据、5G、卫星通讯等技术手段,以“数字化、智能化”的理念,实现航运各个业务“提升效率、提升安全、降低风险、提高收益、提升客户体验”等目标。比如利用人工智能手段,实现船舶更加安全运行(防海…...
)
上海国际航运研究中心:全球绿色航运发展报告(2024-2025)
本报告由上海国际航运研究中心与世界海事大学联合编制,聚焦 2024 年 1 月至 2025 年 9 月全球绿色航运发展,围绕政策、机制、清洁能源、减排技术、发展趋势五大核心展开,全面呈现航运业低碳转型的全球格局、关键进展与挑战。一、核心政策&…...

AI赋能效率革命:用ChatGPT+Markdown一键生成Xmind/ProcessOn专业流程图
1. 为什么需要AI辅助图表制作? 在日常工作和学习中,我们经常需要制作各种图表来梳理思路或展示信息。传统方式要么依赖专业软件操作(比如反复拖拽图形元件),要么需要手动调整格式排版,整个过程往往要花费半…...

Aviator表达式引擎:从编译优化到规则引擎实战
1. Aviator表达式引擎初探 第一次接触Aviator是在一个电商风控项目中,当时系统需要处理大量实时交易规则判断。传统的if-else代码已经膨胀到难以维护的程度,每次业务规则变更都需要重新发布。这时候技术负责人推荐了Aviator,一个基于Java的高…...

微信网页版访问终极指南:如何用wechat-need-web插件轻松解锁微信网页版
微信网页版访问终极指南:如何用wechat-need-web插件轻松解锁微信网页版 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信网页版无…...