【C++】CUDA线程在全局索引中的计算方式
文章目录
- 1. 一维网格一维线程块
- 2. 二维网格二维线程块
- 3. 三维网格三维线程块
- 4. 不同组合形式
- 4.1 一维网格一维线程块
- 4.2 一维网格二维线程块
- 4.3 一维网格三维线程块
- 4.4 二维网格一维线程块
- 4.5 二维网格二维线程块
- 4.6 二维网格三维线程块
- 4.7 三维网格一维线程块
- 4.8 三维网格二维线程块
- 4.9 三维网格三维线程块
1. 一维网格一维线程块
定义grid与block尺寸:
dim3 grid_size(4);
dim3 block_size(8);
调用核函数:
kernal_fun<<<grid_size, block_size>>>(...);
具体索引方式如下图所示, b l o c k I d x . x blockIdx.x blockIdx.x 从0~3, t h r e a d I d x . x threadIdx.x threadIdx.x 从0~7
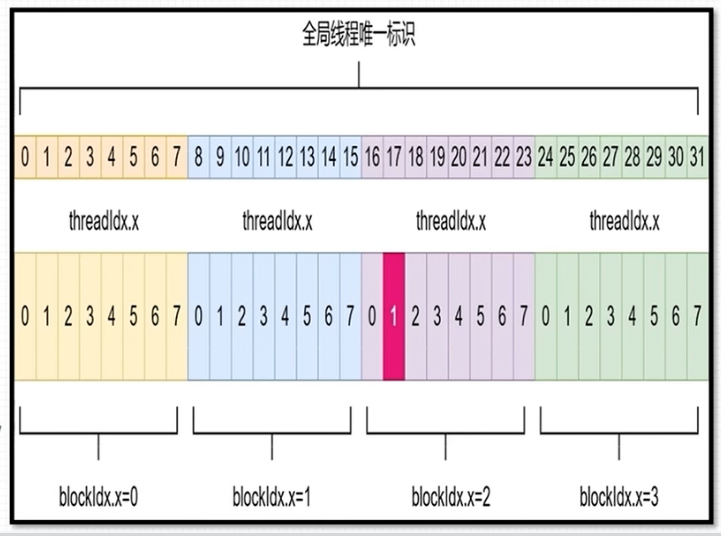
计算方式:
i n t i d = b l o c k I d x . x ∗ b l o c k D i m . x + t h r e a d I d x . x int \ id = blockIdx.x * blockDim.x + threadIdx.x int id=blockIdx.x∗blockDim.x+threadIdx.x
2. 二维网格二维线程块
定义grid与block尺寸
dim3 grid_size(2,2);
dim3 block_size(4,4);
调用核函数:
kernal_fun<<<grid_size, block_size>>>(...);
具体线程索引方式如下图所示, b l o c k I d x . x blockIdx.x blockIdx.x 和 b l o c k I d x . y blockIdx.y blockIdx.y 从0到1, t h r e a d I d x . x threadIdx.x threadIdx.x 和 t h r e a d I d x . y threadIdx.y threadIdx.y从0到3:
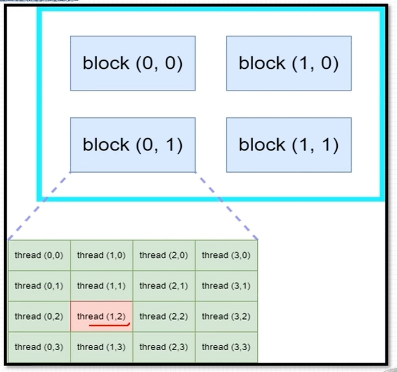
计算方式:
i n t b l o c k I d = b l o c k I d x . x + b l o c k I d . y ∗ g i r d D i m . x i n t t h r e a d I d = t h r e a d I d x . y ∗ b l o c k D i m . x + t h r e a d I d x . x i n t i d = b l o c k I d ∗ ( b l o c k D i m . x ∗ b l o c k D i m . y ) + t h r e a d I d \begin{align*} &int \ blockId = blockIdx.x + blockId.y*girdDim.x \\ &int \ threadId = threadIdx.y * blockDim.x + threadIdx.x \\ &int \ id = blockId*(blockDim.x*blockDim.y) + threadId \end{align*} int blockId=blockIdx.x+blockId.y∗girdDim.xint threadId=threadIdx.y∗blockDim.x+threadIdx.xint id=blockId∗(blockDim.x∗blockDim.y)+threadId
3. 三维网格三维线程块
定义grid和block尺寸:
dim3 grid_size(2,2,2);
dim3 block_size(4,4,2);
调用核函数:
kernal_fun<<<grid_size, block_size>>>(...);
具体线程索引方式如图所示:

- b l o c k I d x . x blockIdx.x blockIdx.x 从0到1
- b l o c k I d x . y blockIdx.y blockIdx.y 从0到1
- b l o c k I d x . z blockIdx.z blockIdx.z 从0到1
- t h r e a d I d x . x threadIdx.x threadIdx.x 从0到3
- t h r e a d I d x . y threadIdx.y threadIdx.y 从0到3
- t h r e a d I d x . z threadIdx.z threadIdx.z 从0到1
计算方式:
i n t b l o c k I d = b l o c k I d x . x + b l o c k I d x . y ∗ g i r d D i m . x + g r i d D i m . x ∗ g r i d D i m . y ∗ b l o c k I d x . z i n t t h r e a d I d = t h r e a d I d x . z ∗ b l o c k D i m . x ∗ b l o c k D i m . y + t h r e a d I d x . y ∗ b l o c k D i m . x + t h r e a d I d x . x i n t i d = b l o c k I d ∗ ( b l o c k D i m . x ∗ b l o c k D i m . y ∗ b l o c k D i m . z ) + t h r e a d I d \begin{align*} &int \ blockId = blockIdx.x + blockIdx.y*girdDim.x + gridDim.x * gridDim.y*blockIdx.z \\ &int \ threadId = threadIdx.z * blockDim.x * blockDim.y+ threadIdx.y * blockDim.x + threadIdx.x \\ &int \ id = blockId*(blockDim.x*blockDim.y*blockDim.z) + threadId \end{align*} int blockId=blockIdx.x+blockIdx.y∗girdDim.x+gridDim.x∗gridDim.y∗blockIdx.zint threadId=threadIdx.z∗blockDim.x∗blockDim.y+threadIdx.y∗blockDim.x+threadIdx.xint id=blockId∗(blockDim.x∗blockDim.y∗blockDim.z)+threadId
4. 不同组合形式
4.1 一维网格一维线程块
i n t b l o c k I d = b l o c k I d x . x i n t i d = b l o c k I d x . x ∗ b l o c k D i m . x + t h r e a d I d x . x \begin{align*} &int \ blockId = blockIdx.x \\ &int \ id = blockIdx.x*blockDim.x + threadIdx.x \end{align*} int blockId=blockIdx.xint id=blockIdx.x∗blockDim.x+threadIdx.x
4.2 一维网格二维线程块
i n t b l o c k I d = b l o c k I d x . x i n t i d = b l o c k I d x . x ∗ b l o c k D i m . x ∗ b l o c k D i m . y + t h r e a d I d x . y ∗ b l o c k D i m . x + t h r e a d I d x . x \begin{align*} &int \ blockId = blockIdx.x \\ &int \ id = blockIdx.x*blockDim.x*blockDim.y + threadIdx.y*blockDim.x + threadIdx.x \end{align*} int blockId=blockIdx.xint id=blockIdx.x∗blockDim.x∗blockDim.y+threadIdx.y∗blockDim.x+threadIdx.x
4.3 一维网格三维线程块
i n t b l o c k I d = b l o c k I d x . x i n t i d = b l o c k I d x . x ∗ b l o c k D i m . x ∗ b l o c k D i m . y ∗ b l o c k D i m . z + t h r e a d I d x . z ∗ b l o c k D i m . y ∗ b l o c k D i m . x + t h r e a d I d x . y ∗ b l o c k D i m . x + t h r e a d I d x . x int \ blockId = blockIdx.x \\ int \ id = blockIdx.x*blockDim.x*blockDim.y*blockDim.z +threadIdx.z*blockDim.y*blockDim.x +threadIdx.y*blockDim.x+threadIdx.x int blockId=blockIdx.xint id=blockIdx.x∗blockDim.x∗blockDim.y∗blockDim.z+threadIdx.z∗blockDim.y∗blockDim.x+threadIdx.y∗blockDim.x+threadIdx.x
4.4 二维网格一维线程块
i n t b l o c k I d = b l o c k I d x . x + b l o c k I d x . y ∗ g r i d D i m . x i n t i d = b l o c k I d ∗ b l o c k D i m . x + t h r e a d I d x . x int \ blockId=blockIdx.x+blockIdx.y∗gridDim.x \\ int \ id=blockId∗blockDim.x+threadIdx.x int blockId=blockIdx.x+blockIdx.y∗gridDim.xint id=blockId∗blockDim.x+threadIdx.x
4.5 二维网格二维线程块
i n t b l o c k I d = b l o c k I d x . x + b l o c k I d x . y ∗ g r i d D i m . x i n t i d = b l o c k I d ∗ b l o c k D i m . x ∗ b l o c k D i m . y + t h r e a d I d x . y ∗ b l o c k D i m . x + t h r e a d I d x . x int \ blockId=blockIdx.x+blockIdx.y∗gridDim.x \\ int \ id=blockId∗blockDim.x∗blockDim.y+threadIdx.y∗blockDim.x+threadIdx.x int blockId=blockIdx.x+blockIdx.y∗gridDim.xint id=blockId∗blockDim.x∗blockDim.y+threadIdx.y∗blockDim.x+threadIdx.x
4.6 二维网格三维线程块
i n t b l o c k I d = b l o c k I d x . x + b l o c k I d x . y ∗ g r i d D i m . x i n t i d = b l o c k I d ∗ b l o c k D i m . x ∗ b l o c k D i m . y ∗ b l o c k D i m . z + t h r e a d I d x . z ∗ b l o c k D i m . x ∗ b l o c k D i m . y + t h r e a d I d x . y ∗ b l o c k D i m . x + t h r e a d I d x . x int \ blockId=blockIdx.x+blockIdx.y∗gridDim.x \\ int \ id=blockId∗blockDim.x∗blockDim.y∗blockDim.z+threadIdx.z∗blockDim.x∗blockDim.y+threadIdx.y∗blockDim.x+threadIdx.x int blockId=blockIdx.x+blockIdx.y∗gridDim.xint id=blockId∗blockDim.x∗blockDim.y∗blockDim.z+threadIdx.z∗blockDim.x∗blockDim.y+threadIdx.y∗blockDim.x+threadIdx.x
4.7 三维网格一维线程块
i n t b l o c k I d = b l o c k I d x . x + b l o c k I d x . y ∗ g r i d D i m . x + b l o c k I d x . z ∗ g r i d D i m . x ∗ g r i d D i m . y i n t i d = b l o c k I d ∗ b l o c k D i m . x + t h r e a d I d x . x int \ blockId=blockIdx.x+blockIdx.y∗gridDim.x+blockIdx.z∗gridDim.x∗gridDim.y\\ int \ id=blockId∗blockDim.x+threadIdx.x int blockId=blockIdx.x+blockIdx.y∗gridDim.x+blockIdx.z∗gridDim.x∗gridDim.yint id=blockId∗blockDim.x+threadIdx.x
4.8 三维网格二维线程块
i n t b l o c k I d = b l o c k I d x . x + b l o c k I d x . y ∗ g r i d D i m . x + b l o c k I d x . z ∗ g r i d D i m . x ∗ g r i d D i m . y i n t i d = b l o c k I d ∗ b l o c k D i m . x ∗ b l o c k D i m . y + t h r e a d I d x . y ∗ b l o c k D i m . x + t h r e a d I d x . x int \ blockId=blockIdx.x+blockIdx.y∗gridDim.x+blockIdx.z∗gridDim.x∗gridDim.y \\ int \ id=blockId∗blockDim.x∗blockDim.y+threadIdx.y∗blockDim.x+threadIdx.x int blockId=blockIdx.x+blockIdx.y∗gridDim.x+blockIdx.z∗gridDim.x∗gridDim.yint id=blockId∗blockDim.x∗blockDim.y+threadIdx.y∗blockDim.x+threadIdx.x
4.9 三维网格三维线程块
i n t b l o c k I d = b l o c k I d x . x + b l o c k I d x . y ∗ g r i d D i m . x + b l o c k I d x . z ∗ g r i d D i m . x ∗ g r i d D i m . y i n t i d = b l o c k I d ∗ b l o c k D i m . x ∗ b l o c k D i m . y ∗ b l o c k D i m . z + t h r e a d I d x . z ∗ b l o c k D i m . x ∗ b l o c k D i m . y + t h r e a d I d x . y ∗ b l o c k D i m . x + t h r e a d I d x . x int \ blockId=blockIdx.x+blockIdx.y∗gridDim.x+blockIdx.z∗gridDim.x∗gridDim.y \\ int \ id=blockId∗blockDim.x∗blockDim.y∗blockDim.z+threadIdx.z∗blockDim.x∗blockDim.y+threadIdx.y∗blockDim.x+threadIdx.x int blockId=blockIdx.x+blockIdx.y∗gridDim.x+blockIdx.z∗gridDim.x∗gridDim.yint id=blockId∗blockDim.x∗blockDim.y∗blockDim.z+threadIdx.z∗blockDim.x∗blockDim.y+threadIdx.y∗blockDim.x+threadIdx.x
相关文章:
【C++】CUDA线程在全局索引中的计算方式
文章目录 1. 一维网格一维线程块2. 二维网格二维线程块3. 三维网格三维线程块4. 不同组合形式4.1 一维网格一维线程块4.2 一维网格二维线程块4.3 一维网格三维线程块4.4 二维网格一维线程块4.5 二维网格二维线程块4.6 二维网格三维线程块4.7 三维网格一维线程块4.8 三维网格二维…...

【笔记】C语言转C++
网课链接:【C语言 转 C 简单教程】 https://www.bilibili.com/video/BV1UE411j7Ti/?p27&share_sourcecopy_web&vd_source4abe1433c2a7ef632aeed6a3d5c0b22a 网课老师B站id:别喷我id 视频总时长:01:55:27 以下笔记是我通过此网课整理 建议先…...

锂电池SOH预测 | 基于BiGRU双向门控循环单元的锂电池SOH预测,附锂电池最新文章汇集
锂电池SOH预测 | 基于BiGRU双向门控循环单元的锂电池SOH预测,附锂电池最新文章汇集 目录 锂电池SOH预测 | 基于BiGRU双向门控循环单元的锂电池SOH预测,附锂电池最新文章汇集预测效果基本描述程序设计参考资料 预测效果 基本描述 锂电池SOH预测 | 基于Bi…...

半导体器件与物理篇5 1~4章课后习题
热平衡时的能带和载流子浓度 例 一硅晶掺入每立方厘米10^{16}个砷原子,求室温下(300K)的载流子浓度与费米能级。 需要用到的公式包括1.本征载流子浓度公式 2.从导带底算起的本征费米能级 2.从本征费米能级算起的费米能级 载流子输运现象 例1:计算在300K下&#x…...

Pytest-Bdd-Playwright 系列教程(16):标准化JSON报告Gherkin格式命令行报告
Pytest-Bdd-Playwright 系列教程(16):标准化JSON报告&Gherkin格式命令行报告 前言一、创建Feature文件二、创建步骤定义文件三、生成Cucumber格式的JSON报告四、使用Gherkin格式的命令行报告五、将BDD报告集成到Jenkins中总结 前言 在自动…...

机器学习之学习范式
机器学习的四种主要范式分别是:监督学习、非监督学习、强化学习和半监督学习。以下是每种范式的详细介绍: 1. 监督学习(Supervised Learning) 定义: 通过已标注的数据训练模型,以预测或分类未知数据。 目…...

PHPstudy中的数据库启动不了
法一 netstat -ano |findstr "3306" 查看占用该端口的进程号 taskkill /f /pid 6720 杀死进程 法二 sc delete mysql...

鸿蒙开发-ArkTS 创建自定义组件
在 ArkTS 中创建自定义组件是一个相对简单但功能强大的过程。以下是如何在 ArkTS 中创建和使用自定义组件的详细步骤: 一、定义自定义组件 使用Component注解:为了注册一个组件,使其能够在其他文件中被引用,你需要使用Component…...

记录学习《手动学习深度学习》这本书的笔记(五)
这一章是循环神经网络,太难了太难了,有很多卡壳的地方理解了好久,比如隐藏层和隐状态的区别、代码的含义(为此专门另写了一篇【笔记】记录对自主实现一个神经网络的步骤的理解)、梯度计算相关(【笔记】记录…...

【Qt】Qt+Visual Studio 2022环境开发
在使用Qt Creator的过程中,项目一大就会卡,所以我一般都是用VS开发Cmake开发, 在上一篇文章中,我已经安装了CMake,如果你没有安装就自己按一下。 记得配置Qt环境变量,不然CMake无法生成VS项目:…...

云计算HCIP-OpenStack04
书接上回: 云计算HCIP-OpenStack03-CSDN博客 12.Nova计算管理 Nova作为OpenStack的核心服务,最重要的功能就是提供对于计算资源的管理。 计算资源的管理就包含了已封装的资源和未封装的资源。已封装的资源就包含了虚拟机、容器。未封装的资源就是物理机提…...
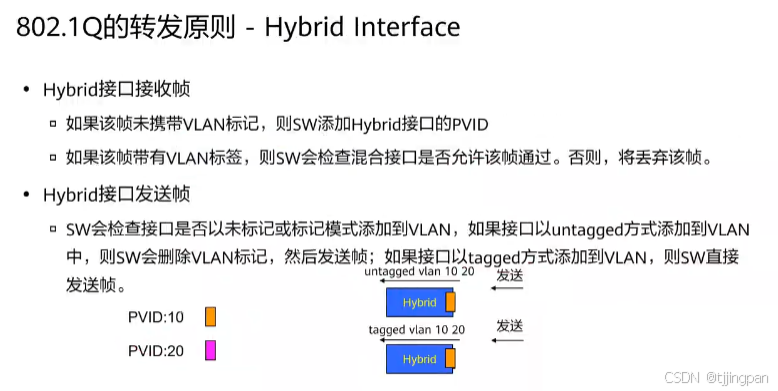
HCIA-Access V2.5_3_2_VLAN数据转发
802.1Q的转发原则--Access-Link 首先看一下Access,对于Access端口来说, 它只属于一个VLAN,它的VLANID等于PVID。 首先看一下接收方向,前面说过交换机内部一定要带标签转发,所以当交换机接收到一个不带tag的数据帧时,会给它打上端…...
transformer学习笔记-导航
本系列专栏,主要是对transformer的基本原理做简要笔记,目前也是主要针对个人比较感兴趣的部分,包括:神经网络基本原理、词嵌入embedding、自注意力机制、多头注意力、位置编码、RoPE旋转位置编码等部分。transformer涉及的知识体系…...

功能篇:JAVA后端实现跨域配置
在Java后端实现跨域配置(CORS,Cross-Origin Resource Sharing)有多种方法,具体取决于你使用的框架。如果你使用的是Spring Boot或Spring MVC,可以通过以下几种方式来配置CORS。 ### 方法一:全局配置 对于所…...

防火墙内局域网特殊的Nginx基于stream模块进行四层协议转发模块的监听443 端口并将所有接收转发到目标服务器
在一些特殊场合下, 公司内部网络防火墙限制, 不能做端口映射, 此时可以使用nginx的做从四层协议转发, 只走tcp/ip协议, 而不走http方式, 可以做waf设置, 就可以做443, 或其它端口, 从而达到被直接转发到远程服务器效果 机房只映射了一个IP:22280, 而需求是这个SDK只能通过…...
)
【Hive】-- hive 3.1.3 伪分布式部署(单节点)
1、环境准备 1.1、版本选择 apache hive 3.1.3 apache hadoop 3.1.0 oracle jdk 1.8 mysql 8.0.15 操作系统:Mac os 10.151.2、软件下载 https://archive.apache.org/dist/hive/ https://archive.apache.org/dist/hadoop/ 1.3、解压 tar -zxvf apache-hive-4.0.0-bin.tar…...

C++ STL 队列queue详细使用教程
序言 我们平常写广搜什么,上来就是一句 queue<XXX> qu; 说明队列时很重要的。 STL库中的queue把队列的各种操作封装成一个类,非常方便,信奥中使用它也是很有优势的。 目录 一、队列的定义 二、创建队列对象 三、队列的初始化 四、常…...

【前端】JavaScript 中的 filter() 方法的理论与实践深度解析
博客主页: [小ᶻ☡꙳ᵃⁱᵍᶜ꙳] 本文专栏: 前端 文章目录 💯前言💯filter() 方法的概念与原理1. 什么是 filter()?2. 基本工作原理3. 方法特点4. 用法格式参数解析 💯代码案例详解示例:筛选有效数字并…...

【机器学习算法】——决策树之集成学习:Bagging、Adaboost、Xgboost、RandomForest、XGBoost
集成学习 **集成学习(Ensemble learning)**是机器学习中近年来的一大热门领域。其中的集成方法是用多种学习方法的组合来获取比原方法更优的结果。 使用于组合的算法是弱学习算法,即分类正确率仅比随机猜测略高的学习算法,但是组合之后的效果仍可能高于…...

JVM运行时数据区内部结构
VM内部结构 对于jvm来说他的内部结构主要分成三个部分,分别是类加载阶段,运行时数据区,以及垃圾回收区域,类加载我们放到之后来总结,今天先复习一下类运行区域 首先这个区域主要是分成如下几个部分 下面举个例子来解释…...

Cursor设备标识重置技术:3分钟解决试用限制的完整方案
Cursor设备标识重置技术:3分钟解决试用限制的完整方案 【免费下载链接】go-cursor-help 解决Cursor在免费订阅期间出现以下提示的问题: Your request has been blocked as our system has detected suspicious activity / Youve reached your trial request limit. …...

VSCode里Code Runner跑Python总报9009?别慌,检查一下你的setting.json文件
VSCode中Code Runner执行Python报错9009的终极排查指南 当你第一次在VSCode中用Code Runner插件运行Python脚本,满心期待看到输出结果时,终端却弹出"Process exited with code 9009"的红色错误提示——这种挫败感我深有体会。这个看似神秘的错…...
)
别再死记硬背公式了!用VHDL和Quartus II手把手教你玩转一位全加器(附完整源码与仿真)
从零实现数字逻辑:用VHDL在Quartus II中构建全加器的完整指南 当第一次接触数字逻辑设计时,那些抽象的真值表和逻辑表达式常常让人望而生畏。作为一名曾经同样困惑的工程师,我深刻理解初学者面对理论知识与实际工程实现之间的鸿沟。本文将带你…...

2026年运动木地板厂家口碑排行榜,谁是真正王者?
随着体育产业的蓬勃发展,运动木地板的需求日益增长。作为体育场馆的重要组成部分,运动木地板的质量直接影响到运动员的表现和观众的体验。那么,在众多运动木地板厂家中,哪家才是真正的王者呢?本文将从产品质量、工艺技…...
——从寄存器到子系统:驱动演进之路)
嵌入式Linux驱动开发pinctrl篇(1)——从寄存器到子系统:驱动演进之路
嵌入式Linux驱动开发pinctrl篇(1)——从寄存器到子系统:驱动演进之路 仓库已经开源!所有教程,主线内核移植,跑新版本imx-linux/uboot都在这里,或者一起来尝试跑7.0的Linux!欢迎各位大…...
)
文献综述怎么写?研一萌新用Scholaread三天搞定开题文献综述(附100+篇文献整合方法)
开题在即,你面对电脑屏幕上50个PDF发呆,复制粘贴了20页摘要却被导师批"毫无逻辑"。问题不在于你不努力,而在于缺少系统化的文献综述工具链。本文拆解用Scholaread完成高质量文献综述的完整流程,让你从"不知道怎么开…...

[题材选股] 商业航天、人形机器人双主线高位震荡,低位氟化工、光伏迎补涨机会!股票量化分析工具QTYX-V3.4.8
前言我们的股票量化系统QTYX在实战中不断迭代升级!!!分享QTYX系统目的是提供给大家一个搭建量化系统的模版,帮助大家搭建属于自己的系统。因此我们提供源码,可以根据自己的风格二次开发。关于QTYX的使用攻略可以查看链接:QTYX使用攻略QTYX一直…...

ArcGIS新手避坑指南:批量拼接栅格时,Mosaic和Mosaic To New Raster到底该选哪个?
ArcGIS栅格拼接工具深度对比:Mosaic与Mosaic To New Raster实战解析 当你第一次在ArcGIS的ArcToolbox中搜索栅格拼接工具时,很可能会被两个名称相似的工具搞得一头雾水——Mosaic和Mosaic To New Raster。这两个工具都位于Data Management Tools下的Rast…...

MIPI CSI调试实战:从时序不稳到稳定传输,我调了这三个关键点
MIPI CSI调试实战:从时序不稳到稳定传输的三大关键突破 调试MIPI CSI接口就像在解一道复杂的物理方程,每一个变量都可能成为图像花屏或数据丢包的罪魁祸首。去年在为一款工业摄像头模组开发驱动时,我遇到了令人抓狂的随机性图像撕裂问题——在…...

别再只调库了!手写KNN算法识别MNIST数字,从距离计算到加权投票的完整实现与性能对比
从零构建KNN算法:MNIST手写数字识别的底层实现与深度优化 在机器学习入门阶段,K最近邻(KNN)算法往往是第一个接触的经典分类方法。大多数教程止步于调用sklearn的几行代码,却忽略了算法底层的精妙设计。本文将带您从数…...