Python字符串及正则表达式(十):字符串常用操作、字符串编码转换
前言:在编程的世界里,字符串无处不在。它们是构建用户界面、存储数据、进行通信的基础元素。无论是财务系统的总账报表、电子游戏的比赛结果,还是火车站的列车时刻表,这些信息最终都需要以文本的形式呈现给用户。这些文本的背后,是程序经过精确计算、逻辑判断和数据整理的结果,它们将复杂的数据转化为直观易懂的文本信息。正如一位经验丰富的程序员所说:“开发一个项目,基本上就是在不断地处理字符串。”
在本章节中,我们将详细介绍如何高效地操作字符串,包括但不限于字符串的分割、连接、替换和格式化等。同时,我们也会探讨字符串编码的转换,这对于处理不同语言和字符集的数据尤为重要。通过这些内容的学习,你将能够更加灵活地处理字符串数据,为你的项目开发提供强大的支持。让我们开始这段深入探索Python字符串吧。

一、字符串常用操作
Python 中的字符串操作是非常丰富和灵活的。以下是一些常用的字符串操作:
1、拼接字符串:
使用 + 操作符来拼接两个或多个字符串。
str1 = "Hello"
str2 = "World"
result = str1 + " " + str2
print(str1 + str2)# 结果为 "Hello World"
注意字符串不允许和其他类型的数据拼接,如使用下列的代码将字符串与数值拼接在一起将会报错
str1 = '我今天一共走了' # 定义字符串
num = 16058 # 定义一个整数
str2 = '步' # 定义字符串
print(str1 + num + str2) # 对字符串和整数进行拼接

改进后:
str1 = '我今天一共走了' # 定义字符串
num = 16058 # 定义一个整数
str2 = '步' # 定义字符串
print(str1 + str(num) + str2) # 对字符串和整数进行拼接

实例训练34 -使用字符串拼接输出一个关于程序员的笑话
programmer_1 = '程序员甲:搞IT太累了,我想换行......怎么办?'
programmer_2 = '程序员乙:敲以下回车键'
print(programmer_1 + '\n' + programmer_2)

2、计算字符串的长度:
由于不同的字符所占字节数不同,所以要计算字符串的长度,需要先了解各字符所占的字节数。在Python 中,数字、英文、小数点、下划线和空格占一个字节;一个汉字可能会占 2~4个字节,占几个字节取决于采用的编码。汉字在 GBK/GB2312编码中占2个字节,在 UTF-8humicode 编码中一般占用3个字节(或4个字节)。
使用 len() 函数来获取字符串的长度。
str = "Hello,World"
length = len(str)
print(length) # 结果为 11
中文字符串说明
str1 = '人生苦短,我用Ptyhon!' # 定义字符串
length = len(str1) # 计算字符串的长度
print(length) # 结果为 14
上面的代码在执行后,将输出结果14。从上面的结果中可以看出,在默认的情况下,通过len()函数计算字符串的长度时,不区分英文、数字、和汉字,所有字符都按一个字符计算。
在实际开发时,有时需要获取字符串实际所占的字节数,即如果采用UTF-8编码,汉字占3个字节,采用GBK或者GB2312时,汉字占2个字节。这时,可以通过使用encode()方法(进行编码后再进行获取。例如,如果要获取采用UTF-8编码的字符串的长度,可以使用下面的代码:
str1 = '人生苦短,我用Ptyhon!' # 定义字符串
length = len(str1.encode()) # 计算UTF-8编码的字符串的长度
print(length) # 结果为 28
上面的代码在执行后,将显示“28”。这是因为汉字加中文标点符号共7个,占21个字节,英文字母和英文的标点符号占7个字节,共28个字节。
如果要获取采用 GBK编码的字符串的长度,可以使用下面的代码:
str1 = '人生苦短,我用Ptyhon!' # 定义字符串
length = len(str1.encode('gbk')) # 计算UTF-8编码的字符串的长度
print(length) # 结果为 21
上面的代码在执行后,将显示“21”。这是因为汉字加中文标点符号共7个,占14个字节,英文字母和英文的标点符号占7个字节,共28个字节。
3、截取字符串:
由于字符串也属于序列,所以要截取字符串,可以采用切片方法实现。通过切片方法截取字符串的语法格式如下:
string[start : end : step]
参数说明:
string:表示要截取的字符串。start:表示要截取的第一个字符的索引(包括该字符),如果不指定,则默认为0。end:表示要截取的最后一个字符的索引(不包括该字符),如果不指定则默认为字符串的长度step:表示切片的步长,如果省略,则默认为1,当省略该步长时,最后一个冒号也可以省略。
使用切片操作来截取字符串的一部分。str = "Hello World" substr = str[0:5] # 结果为 "Hello"
拓展:
| 索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 字符 | 人 | 生 | 苦 | 短 | , | 我 | 用 | P | y | t | h | o | n | ! |
在编程中,字符串通常以0作为第一个字符的索引,这在大多数编程语言中都是通用的。在上表中,“人” 是字符串的第一个字符,其索引为0,而 “!” 是最后一个字符,其索引为13。
str1 = '人生苦短,我用Ptyhon!' # 定义字符串
substr1 = str1[1] # 截取第2个(索引1)字符
substr2 = str1[5:] # 从第6个(索引5)字符截取
substr3 = str1[:5] # 从左边开始截取5个(索引4)字符
substr4 = str1[2:5] # 截取第3个(索引2)到第5个(索引4)字符
print('原字符串: ',str1)
print(substr1 + '\n' + substr2 + '\n' + substr3 + '\n' + substr4)

捕获异常范例
str1 = '人生苦短,我用Ptyhon!' # 定义字符串
substr1 = str1[15] # 截取第15个字符
print(substr1)

解决方法:采用try...except语句捕获异常:
str1 = '人生苦短,我用Ptyhon!' # 定义字符串
try:substr1 = str1[15] # 截取第15个字符
except IndexError:print('指定的索引不存在')

4、分割字符串:
字符串对象的 split() 方法用于将一个字符串按照指定的分隔符切分为字符串列表。该列表中的元素不包括分隔符。split() 方法的语法格式如下:
str.split(sep, maxsplit)
参数说明:
① str: 需要进行分割的字符串。
② sep: 指定的分隔符,可以是多个字符。默认为 None,即会将所有空字符(包括空格、换行符 \n、制表符 \t 等)作为分隔符。
③ maxsplit: 可选参数,用于指定分割的次数。如果不指定或设为 -1,则表示分割次数没有限制;否则,返回结果列表的元素个数最多为 maxsplit + 1。
④ 返回值: 分隔后的字符串列表。该列表的元素是以分隔符为界限切分的字符串(不含分隔符)。如果分隔符前面(或与前一个分隔符之间)没有内容,则会返回一个空字符串元素。
注意: 在使用 split() 方法时,如果不指定 sep 参数,则不能同时指定 maxsplit 参数。
使用 split() 方法来分割字符串,返回一个字符串列表。
str = "Hello,World,Python"
parts = str.split(",")
print(parts) # 结果为 ['Hello', 'World', 'Python']
实例训练35 -输出被@的好友名称
str1 = '@马哥教育 @海瑞 @马斯克'
list1 = str1.split(' ') #用空格分割字符串
print('您@的好友有: ')
for item in list1:print(item[1:]) # 输出每个好友名时,去掉@符号

5、合并字符串:
合并字符串是将多个字符串通过一个固定的分隔符连接起来的过程。与拼接字符串不同,合并字符串会使用一个指定的分隔符来连接各个字符串。例如,如果我们有字符串列表 ['绮梦', '冷伊一', '香凝', '黛兰'],我们可以通过分隔符 "*" 将它们合并为一个字符串 "绮梦*冷伊一*香凝*黛兰"。
合并字符串的操作可以通过字符串对象的 join() 方法来实现。该方法的语法格式如下:
strnew = string.join(iterable)
参数说明:
-
strnew:表示合并后生成的新字符串。
-
string:字符串类型,用于指定合并时的分隔符。
-
iterable:可迭代对象,该迭代对象中的所有元素(字符串表示)将被合并为一个新的字符串。
string作为边界点分割这些元素。使用
join()方法来合并字符串列表或元组。
parts = ["Hello", "World", "Python"]
result = " ".join(parts)
print(result) # 结果为 Hello World Python
实例训练36 -通过好友列表生成全部被@的好友
list_friend = ['马哥教育','海瑞','马云','马斯克','俞洪敏'] # 好友列表
str_friend = ' @'.join(list_friend) # 用空格+@符号进行连接
at = '@'+str_friend # 由于使用join()方法时,第一个元素前不加分隔符,所以需要在前面加上@符号
print('您要@的好友: ',at)

6、检索字符串:
检索字符串是编程中用于查找和统计特定字符或子串在字符串中出现的次数、位置的方法。以下是几种常用的字符串检索方法:
① count()
count() 方法用于统计指定子串在字符串中出现的次数。如果子串不存在于字符串中,则返回0。
语法格式:
count = str.count(sub[, start[, end]])
- str: 原始字符串。
- sub: 需要统计的子串。
- start: 可选参数,统计的起始位置,默认为字符串的开始。
- end: 可选参数,统计的结束位置,默认为字符串的结束。
举例:
count() 方法用于统计指定子串在字符串中出现的次数:
text = "moonshot moonshot"
count_moonshot = text.count("moonshot")
print(count_moonshot) # 输出: 2
② find()
find()方法用于查找子串在字符串中第一次出现的索引,如果未找到则返回-1。
语法格式:
position = str.find(sub[, start[, end]])
- str: 原始字符串。
- sub: 需要查找的子串。
- start: 可选参数,查找的起始位置,默认为字符串的开始。
- end: 可选参数,查找的结束位置,默认为字符串的结束。
举例
find() 方法用于查找子串在字符串中第一次出现的索引:
text = "hello world"
index = text.find("world")
print(index) # 输出: 6
如果子串不存在,返回-1:
index = text.find("python")
print(index) # 输出: -1
③ index()
index() 方法与find()类似,用于查找子串在字符串中第一次出现的索引。不同的是,如果子串未找到,index()会抛出一个异常。
语法格式:
position = str.index(sub[, start[, end]])
- str: 原始字符串。
- sub: 需要查找的子串。
- start: 可选参数,查找的起始位置,默认为字符串的开始。
- end: 可选参数,查找的结束位置,默认为字符串的结束。
举例:
index() 方法与find()类似,但若子串不存在则抛出异常:
text = "hello world"
index = text.index("world")
print(index) # 输出: 6
如果子串不存在,会抛出ValueError:
# 这将抛出异常,因为"python"不在文本中
index = text.index("python")
④ startswith()
startswith() 方法用于检查字符串是否以指定的子串开始,如果是,则返回True,否则返回False。
语法格式:
bool = str.startswith(prefix[, start[, end]])
- str: 原始字符串。
- prefix: 需要检查的子串。
- start: 可选参数,检查的起始位置,默认为字符串的开始。
- end: 可选参数,检查的结束位置,默认为字符串的结束。
举例:
startswith() 方法用于检查字符串是否以指定的子串开始:
text = "hello world"
starts_with_hello = text.startswith("hello")
print(starts_with_hello) # 输出: True
⑤ endswith()
endswith() 方法用于检查字符串是否以指定的子串结束,如果是,则返回True,否则返回False。
语法格式:
bool = str.endswith(suffix[, start[, end]])
- str: 原始字符串。
- suffix: 需要检查的子串。
- start: 可选参数,检查的起始位置,默认为字符串的开始。
- end: 可选参数,检查的结束位置,默认为字符串的结束。
举例
endswith() 方法用于检查字符串是否以指定的子串结束:
text = "hello world"
ends_with_world = text.endswith("world")
print(ends_with_world) # 输出: True
这些方法为字符串的检索提供了灵活且强大的工具,使得在处理文本数据时更加高效和准确。通过这些方法,开发者可以轻松地实现对字符串内容的检索和统计,从而满足各种编程需求。
7、字母的大小写转换:
在编程中,经常需要对字符串中的字母进行大小写转换,以满足不同的格式要求或进行不区分大小写的比较。以下是两种常用的字符串大小写转换方法:
① lower()
lower() 方法用于将字符串中的所有大写字母转换为小写字母。
语法格式:
lower_str = str.lower()
- str: 原始字符串。
举例:
text = "Hello World"
lower_text = text.lower()
print(lower_text) # 输出: "hello world"
② upper()
upper() 方法用于将字符串中的所有小写字母转换为大写字母。
语法格式:
upper_str = str.upper()
- str: 原始字符串。
举例:
text = "hello world"
upper_text = text.upper()
print(upper_text) # 输出: "HELLO WORLD"
实例训练37 -不区分大小写验证会员名是否唯一
username_1 = '|MingRi|mr|mingrisoft|WGH|MRSoft|' #假设已经注册的会员名称保存在一个字符串中,以“|”进行分隔
username_2 = username_1.lower() #将会员名称字符串全部转换为小写
regname_1 = input('输入要注册的会员名称:')
regname_2 = '|' + regname_1.lower() + '|' #将要注册的会员名称全部转换为小写
if regname_2 in username_2: #判断输入的会员名称是否存在print('会员名',regname_1,'已经存在! ')
else:print('会员名',regname_1,'可以注册! ')

这些方法使得在处理字符串时,可以轻松地进行大小写转换,以适应不同的应用场景,如用户输入的规范化、文件命名的统一等。通过这些简单的方法,可以提高代码的可读性和健壮性。
8、去除字符串中的空格和特殊字符:
在编程中,经常需要对字符串进行清理,去除不需要的空格或特殊字符。以下是几种常用的字符串清理方法:
① strip()
strip() 方法用于去除字符串两端的空格和特殊字符。默认情况下,它去除空白字符,包括空格、换行符(\n)、制表符(\t)等。也可以指定一个字符集合,去除两端的这些字符。
语法格式:
cleaned_str = str.strip([chars])
- str: 原始字符串。
- chars: 可选参数,指定要去除的字符集合。
举例:
text = " Hello, World! "
cleaned_text = text.strip()
print(cleaned_text) # 输出: "Hello, World!"
② lstrip()
lstrip() 方法与strip()类似,但它只去除字符串左侧(开头)的空格和特殊字符。
语法格式:
cleaned_str = str.lstrip([chars])
举例:
text = " Hello, World! "
cleaned_text = text.lstrip()
print(cleaned_text) # 输出: "Hello, World! "
③ rstrip()
rstrip() 方法与strip()类似,但它只去除字符串右侧(结尾)的空格和特殊字符。
语法格式:
cleaned_str = str.rstrip([chars])
举例:
text = " Hello, World! "
cleaned_text = text.rstrip()
print(cleaned_text) # 输出: " Hello, World!"
这些方法使得在处理字符串时,可以轻松地去除两端的不必要字符,从而提高数据的清洁度和可用性。通过这些简单的方法,可以确保字符串数据在进一步处理或展示前达到预期的格式。
9、格式化字符串:
格式化字符串是编程中用于生成具有特定格式的字符串的方法。以下是两种常用的字符串格式化方法:
① %
% 操作符用于格式化字符串,它允许你在字符串中嵌入变量的值。
语法格式:
formatted_str = "%s%d%f" % (var1, var2, var3)
- %s: 字符串格式化占位符。
- %d: 整数格式化占位符。
- %f: 浮点数格式化占位符。
- var1, var2, var3: 要格式化的变量。
常用格式化字符表
| 格式化字符 | 说明 | 格式化字符 | 说明 |
|---|---|---|---|
%s | 字符串(采用 str() 显示) | %r | 字符串(采用 repr() 显示) |
%c | 单个字符 | %o | 八进制整数 |
%d 或 %i | 十进制整数 | %e | 指数(基底写为 e) |
%x | 十六进制整数 | %E | 指数(基底写为 E) |
%f 或 %g | 浮点数 | %% | 字符 % |
说明
m: 可选参数,表示占有宽度。用于指定输出的最小宽度。.n: 可选参数,表示小数点后保留的位数。用于控制浮点数的精度。- 格式化字符用于指定类型,其值如表所示。
举例1
# 使用 %s 格式化字符串
name = "Alice"
print("Name: %s" % name) # 输出: Name: Alice# 使用 %d 格式化十进制整数
age = 30
print("Age: %d" % age) # 输出: Age: 30# 使用 %f 格式化浮点数
height = 165.5
print("Height: %.1f" % height) # 输出: Height: 165.5# 使用 %x 格式化十六进制整数
number = 255
print("Number in hex: %x" % number) # 输出: Number in hex: ff# 使用 %e 格式化指数
value = 123.456
print("Value in scientific notation: %e" % value) # 输出: Value in scientific notation: 1.234560e+02# 使用 %% 转义字符 %
print("Percentage: %%" % 0) # 输出: Percentage: %
举例2:
name = "Alice"
age = 30
height = 165.5
formatted_text = "Name: %s, Age: %d, Height: %.1f" % (name, age, height)
print(formatted_text) # 输出: "Name: Alice, Age: 30, Height: 165.5"
这些格式化字符在Python中用于控制字符串的输出格式,使得在生成具有特定格式的字符串时更加灵活和精确。通过这些格式化字符,可以轻松地对数字、字符串等进行格式化,以满足各种编程需求。
② format()
format()方法提供了一种更现代的字符串格式化方式,它允许你使用大括号 {} 作为占位符,并可以指定变量的格式。
语法格式:
formatted_str = "{}{}{}".format(var1, var2, var3)
- {}: 格式化占位符。
- var1, var2, var3: 要格式化的变量。
format()方法常用格式化字符表
| 格式化字符 | 说明 | 格式化字符 | 说明 |
|---|---|---|---|
s | 对字符串类型格式化 | b | 将十进制整数自动转换成二进制表示再格式化 |
d | 十进制整数 | o | 将十进制整数自动转换成八进制表示再格式化 |
c | 将十进制整数自动转换成对应的Unicode字符 | x 或 X | 将十进制整数自动转换成十六进制表示再格式化 |
e 或 E | 转换为科学计数法表示再格式化 | f 或 F | 转换为浮点数(默认小数点后保留6位)再格式化 |
g 或 G | 自动在 e 和 f 或 E 和 F 中切换 | % | 显示百分比(默认显示小数点后6位) |
说明
#: 可选参数,对于二进制数、八进制数和十六进制数,如果加上#,表示会显示0b/0o/0x前缀,否则不显示前缀。width: 可选参数,用于指定所占宽度。.precision: 可选参数,用于指定保留的小数位数。type: 可选参数,用于指定类型。
举例:
name = "Bob"
age = 25
weight = 70.3
formatted_text = "Name: {0}, Age: {1}, Weight: {2:.1f}".format(name, age, weight)
print(formatted_text) # 输出: "Name: Bob, Age: 25, Weight: 70.3"
使用变量位置:
name = "Bob"
age = 25
weight = 70.3
formatted_text = "Name: {1}, Age: {0}, Weight: {2:.1f}".format(age, name, weight)
print(formatted_text) # 输出: "Name: Bob, Age: 25, Weight: 70.3"
使用关键字参数:
name = "Bob"
age = 25
weight = 70.3
formatted_text = "Name: {name}, Age: {age}, Weight: {weight:.1f}".format(name=name, age=age, weight=weight)
print(formatted_text) # 输出: "Name: Bob, Age: 25, Weight: 70.3"
这些方法为字符串的格式化提供了灵活且强大的工具,使得在生成具有特定格式的字符串时更加高效和准确。通过这些方法,可以轻松地将变量嵌入到字符串中,满足各种编程需求。
以上是 Python 中处理字符串时最常用的一些操作。Python 的字符串是不可变的,这意味着一旦创建,就不能被改变。每次对字符串的操作都会生成一个新的字符串。
二、字符串编码转换
字符串编码转换是编程中用于将字符串转换为不同编码格式的字节序列,或将字节序列解码回字符串的方法。以下是两种常用的字符串编码转换方法:
1、 使用encode()方法编码
encode()方法用于将字符串编码为字节序列。默认情况下,它使用UTF-8编码,但可以指定其他编码格式。
语法格式:
byte_sequence = str.encode([encoding])
- str: 原始字符串。
- encoding: 可选参数,指定编码格式,默认为UTF-8。
举例:
text = "Hello, World!"
encoded_text = text.encode('utf-8')
print(encoded_text) # 输出: b'Hello, World!'
2、使用decode()方法解码
decode() 方法用于将字节序列解码回字符串。它需要指定字节序列的编码格式。
语法格式:
str = byte_sequence.decode([encoding])
- byte_sequence: 字节序列。
- encoding: 指定字节序列的编码格式。
举例:
byte_sequence = b'\xe4\xbd\xa0\xe5\xa5\xbd'
decoded_text = byte_sequence.decode('utf-8')
print(decoded_text) # 输出: "你好"
这些方法为字符串的编码和解码提供了灵活的工具,使得在处理不同编码格式的数据时更加高效和准确。通过这些方法,可以轻松地在字符串和字节序列之间进行转换,以满足各种编程需求。
相关文章:
Python字符串及正则表达式(十):字符串常用操作、字符串编码转换
前言:在编程的世界里,字符串无处不在。它们是构建用户界面、存储数据、进行通信的基础元素。无论是财务系统的总账报表、电子游戏的比赛结果,还是火车站的列车时刻表,这些信息最终都需要以文本的形式呈现给用户。这些文本的背后&a…...
:错误和异常处理策略及最佳实践)
前端的Python入门指南(完):错误和异常处理策略及最佳实践
《前端的 Python 入门指南》系列文章: (一):常用语法和关键字对比(二):函数的定义、参数、作用域对比(三):数据类型对比 - 彻底的一切皆对象实现和包装对象异…...
LeetCode 2475 数组中不等三元组的数目
问题描述: 给定一个下标从 0 开始的正整数数组 nums,我们的目标是找出并统计满足下述条件的三元组 (i, j, k) 的数目: 0 < i < j < k < nums.length,这确保了三元组索引的顺序性。nums[i]、nums[j] 和 nums[k] 两…...
【和春笋一起学C++】字符串比较
目录 C语言字符串比较 C语言字符比较 C字符串比较 C语言字符串比较 在C语言中用于比较字符串的函数为strcmp函数,该函数定义在头文件<string.h>中,是一个标准库函数。strcmp函数的工作原理是逐字符比较两个字符串,直到找到不同的字符…...

HTTP 协议报文结构 | 返回状态码详解
注:本文为 “HTTP 历史 | 协议报文结构 | 返回状态码” 相关文章合辑。 未整理去重。 HTTP 历史 wangjunliang 最后更新: 2024/3/16 上午10:29 超文本传输协议(英语:HyperTextTransferProtocol,缩写:HTTP)是 万维网(World Wide Web)的基础协议。自 蒂姆…...

.net winform 实现CSS3.0 泼墨画效果
效果图 代码 private unsafe void BlendImages1(Bitmap img1, Bitmap img2) {// 确定两个图像的重叠区域Rectangle rect new Rectangle(0, 0,Math.Min(img1.Width, img2.Width),Math.Min(img1.Height, img2.Height));// 创建输出图像,尺寸为重叠区域大小Bitmap b…...

LearnOpenGL学习(高级OpenGL - - 实例化,抗锯齿)
实例化 对于在同一场景中使用相同顶点数据的对象(如草地中的草),可以使用实例化(Instancing)技术,用一个绘制函数让OpenGL绘制多个物体,而非循环(Drawcall: N->1)。 …...
大数据与AI:从分析到预测的跃迁
引言:数据时代的新纪元 从每天的社交分享到企业的运营决策,数据早已成为现代社会不可或缺的资源。我们正置身于一个数据爆炸的时代,数以亿计的信息流实时生成,为人类带来了前所未有的洞察能力。然而,数据的价值并不仅限…...

【CC2530开发基础篇】继电器模块使用
一、前言 1.1 开发背景 本实验通过使用CC2530单片机控制继电器的吸合与断开,深入了解单片机GPIO的配置与应用。继电器作为一种常见的电气控制元件,广泛用于自动化系统中,用于控制大功率负载的开关操作。在本实验中,将通过GPIO口…...

C05S07-Tomcat服务架设
一、Tomcat 1. Tomcat概述 Tomcat也是一个Web应用程序,具有三大核心功能。 Java Servlet:Tomcat是一个Servlet容器,负责管理和执行Java Servlet、服务端的Java程序,处理客户端的HTTP请求和响应。Java Server:服务端…...

Java stream groupingBy sorted 实现多条件排序与分组的最佳实践
1. 数据初始化 这一部分代码用于创建 Product 对象并将它们添加到 result 列表中。 // 初始化数据 List<Product> result new ArrayList<>(); List<Product> resp new ArrayList<>();// 添加产品数据 result.add(new Product("手机A", 1…...

JAVA:代理模式(Proxy Pattern)的技术指南
1、简述 代理模式(Proxy Pattern)是一种结构型设计模式,用于为其他对象提供一种代理,以控制对这个对象的访问。通过代理模式,我们可以在不修改目标对象代码的情况下扩展功能,满足特定的需求。 设计模式样例:https://gitee.com/lhdxhl/design-pattern-example.git 2、什…...

爬取Q房二手房房源信息
文章目录 1. 实战概述2. 网站页面分析3. 编写代码爬取Q房二手房房源信息3.1 创建项目与程序3.2 运行程序,查看结果 4. 实战小结 1. 实战概述 本次实战项目旨在通过编写Python爬虫程序,抓取深圳Q房网上的二手房房源信息。我们将分析网页结构,…...

Ansible自动化运维(五) 运维实战
Ansible自动化运维这部分我将会分为五个部分来为大家讲解 (一)介绍、无密钥登录、安装部署、设置主机清单 (二)Ansible 中的 ad-hoc 模式 模块详解(15)个 (三)Playbook 模式详解 …...

K-means算法的python实现
K-means算法步骤 初始化质心:输入初始的质心位置。分配样本:将每个数据点分配到离它最近的质心对应的簇中。更新质心:对每个簇中的所有数据点,计算它们的均值,并将均值更新为新的质心。重复步骤2和3,直到质…...
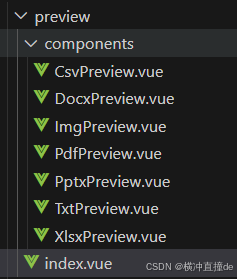
客户端(浏览器)vue3本地预览txt,doc,docx,pptx,pdf,xlsx,csv,
预览文件 1、入口文件preview/index.vue2、预览txt3、预览doc4、预览pdf5、预览pptx6、预览xlsx7、预览csv 1、入口文件preview/index.vue 预览样式,如pdf 文件目录如图所示: 代码如下 <template><div class"preview-wrap" ref&…...
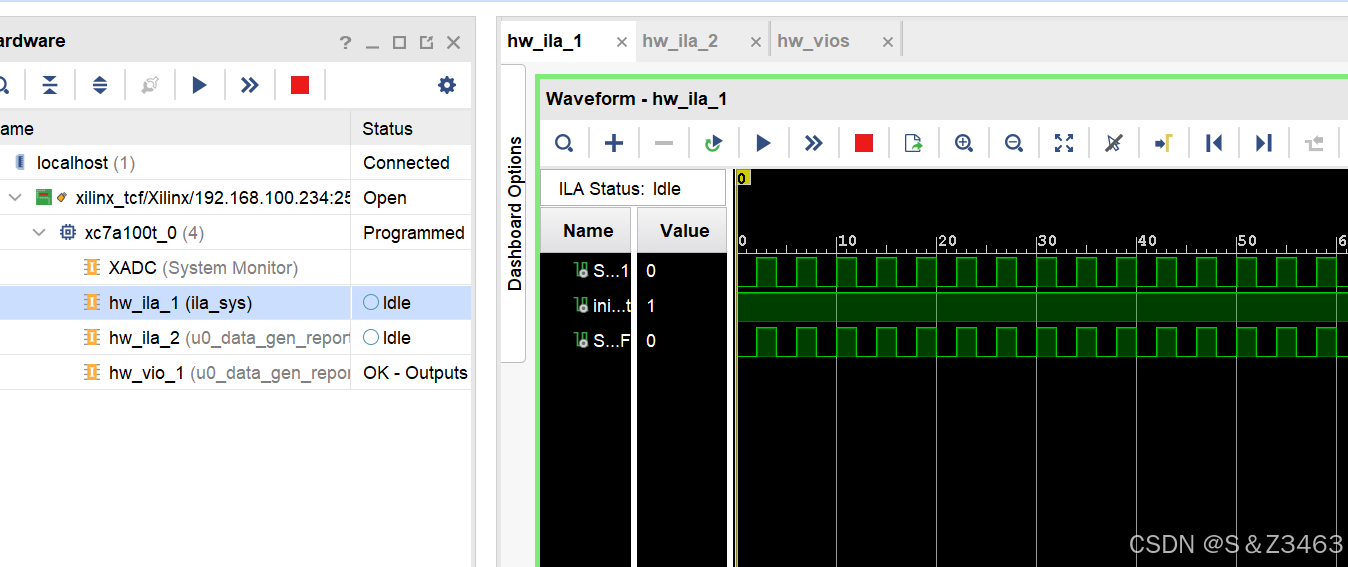
[SZ901]JTAG高速下载设置(53Mhz)
SZ901最高支持JTAG 53MHz的时钟频率,下载bit文件和固化程序的速度提升非常明显。 首先设置参数 1,将JTAG0 分频系数修改为3 2,设置参数,更新参数。(完成) 打开VIVADO VIVADO 正常识别FPGA,速…...

docker springboot 运维部署详细实例
环境安装 [rootiZbp1dcnzq7pzpg9607m6pZ ~]# docker -v Docker version 26.1.4, build 5650f9b镜像构建 Dockerfile 文件内容 FROM openjdk:8 # Author Info 创建人信息 MAINTAINER ratelcloudfoxmail.com ENV PORT20001 EXPOSE 20001 RUN mkdir /usr/local/ratel-boot-serv…...

Linux 查看目录命令 ls 详细介绍
Linux 和 Unix 系统中 ls 命令是用于列出目录内容。用户可以查看指定目录下的文件和子目录,还可以获取有关这些文件和子目录的详细信息。 基本语法: ls [选项] [目录]如果不指定目录,ls 将列出当前工作目录下的内容。 01、-a 或 --all ls…...

React Native状态管理器Redux、MobX、Context API、useState
Redux、MobX、Context API、useState都是React中用于状态管理的工具,但它们各自有不同的特点和使用场景。 Redux 介绍: Redux是一个JavaScript状态管理库,最初由Dan Abramov和Andrew Clark于2015年开发。它基于Flux架构,强调状态…...

嵌入式开发中的静态代码分析工具实战指南
1. 嵌入式代码静态分析工具概述作为一名嵌入式开发工程师,我深知在资源受限的MCU环境中,代码质量直接决定了产品的稳定性和可靠性。传统的C语言编译器虽然能发现语法错误,但对代码设计缺陷和潜在风险往往无能为力。这正是静态代码分析工具的价…...

零代码!用Qwen-Image-2512-ComfyUI轻松制作中文电商配图与营销素材
零代码!用Qwen-Image-2512-ComfyUI轻松制作中文电商配图与营销素材 1. 为什么选择Qwen-Image-2512-ComfyUI 电商运营和内容创作者经常面临一个共同难题:如何快速制作高质量的中文营销素材。传统设计工具需要专业技能,而普通AI绘画工具又难以…...

人工智能应用快速原型开发:基于PyTorch 2.8和Gradio构建交互式Demo
人工智能应用快速原型开发:基于PyTorch 2.8和Gradio构建交互式Demo 1. 为什么需要快速原型开发工具 在人工智能领域,一个好想法从诞生到落地往往需要经历漫长的验证过程。传统方式下,即使训练出了一个效果不错的模型,想要展示给…...

短视频 SEO 推广与视频广告投放的区别是什么_短视频 SEO 优化需要结合网站整体 SEO 策略吗
短视频 SEO 推广与视频广告投放的区别是什么_短视频 SEO 优化需要结合网站整体 SEO 策略吗 在当前数字化营销的浪潮中,短视频平台和视频广告投放已经成为许多企业和创作者推广内容、吸引观众的重要手段。对于SEO策略的理解和应用却常常存在误解。今天,我…...

seo网络推广专员有哪些发展前景
SEO网络推广专员的职业发展前景分析 在当今数字经济时代,网络推广已经成为企业营销的核心手段之一。而在网络推广的诸多角色中,SEO网络推广专员(Search Engine Optimization网络推广专员)无疑是其中最为关键的一环。作为一个SEO网…...

FastAPI + TinyDB并发陷阱与实战:告别数据错乱的解决方案
核心摘要本文针对在FastAPI框架下使用TinyDB(JSON文件数据库)时遇到的并发写入数据冲突、错乱问题,深入浅出地解释了问题根源,并提供了从“文件锁”到“内存队列”再到“乐观锁”的三种由浅入深的实战解决方案,帮助你根…...

腾讯云轻量服务器+宝塔面板:新手零代码搭建个人网站的保姆级避坑指南
腾讯云轻量服务器宝塔面板:新手零代码搭建个人网站的保姆级避坑指南 你是否曾经想过拥有一个属于自己的网站,却因为不懂代码和服务器运维而望而却步?现在,即使你没有任何技术背景,也能轻松实现这个梦想。本文将带你一步…...

小米智能家居跨区域协同控制技术指南
小米智能家居跨区域协同控制技术指南 【免费下载链接】ha_xiaomi_home Xiaomi Home Integration for Home Assistant 项目地址: https://gitcode.com/GitHub_Trending/ha/ha_xiaomi_home 随着智能家居设备数量的快速增长,多区域设备协同工作已成为提升居住体…...

【Java外部函数性能优化黄金法则】:20年JVM专家亲授JNI/FFM调优的7大致命误区与3步极速修复方案
第一章:Java外部函数优化的演进脉络与性能本质Java平台对外部函数调用(Foreign Function & Memory API,即JEP 454/464/471/472)的演进,标志着JVM从“纯Java世界”迈向系统级互操作的新纪元。其性能本质并非单纯降低…...

Cocos Creator 屏幕适配实战:从设计分辨率到完美适配的完整指南
1. 理解屏幕适配的核心概念 第一次用Cocos Creator做横屏游戏时,我盯着iPad和手机上完全变形的UI界面愣了半天。这才明白为什么老司机们总说:"屏幕适配不做,上线火葬场"。屏幕适配的本质是解决设计分辨率(美术产出资源时…...