黑马Java面试教程_P7_常见集合_P4_HashMap
系列博客目录
文章目录
- 系列博客目录
- 4. HashMap相关面试题
- 4.4 面试题-HashMap的put方法的具体流程 频5
- 4.4.1 hashMap常见属性
- 4.4.2 源码分析 HashMap的构造函数
- 面试文稿:
- 4.5 讲一讲HashMap的扩容机制 难3频4
- 面试文稿:
- 4.6 面试题-hashMap的寻址算法 难4频4
- 面试文稿
- 4.7 面试题-hashmap在1.7情况下的多线程死循环问题 难4频3
- 面试文稿
4. HashMap相关面试题
4.4 面试题-HashMap的put方法的具体流程 频5
4.4.1 hashMap常见属性

size是存储元素的个数。
注意这个table,他是由hashMap的内部类Node组成的数组,Node里面有哈希值(用来记录存储的位置)、key和value,还有next,因为发生冲突的时候会用到链表以及红黑树。
4.4.2 源码分析 HashMap的构造函数
Map<String, String> map = new HashMap<>();
map.put("name","itheima");
按住Ctrl,左键点进HashMap中,
public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted 默认加载因子 0.75
}
上方代码说明了以下两点:
- HashMap是懒惰加载,在创建对象时并没有初始化数组
- 在无参的构造函数中,设置了默认的加载因子是0.75
为了更好理解源码,先看一下添加数据的流程图
第一次添加数据流程图(涉及到了初始化,添加数据以及如果大于阈值调用resize())如下:

以下是非第一次,发现key存在时候的流程图

以下是发现key不存在的时候的流程图。

以下是针对上面流程图的JDK1.8的带注释的源码。
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;//判断数组是否未初始化if ((tab = table) == null || (n = tab.length) == 0)//如果未初始化,调用resize方法 进行初始化n = (tab = resize()).length;//通过 & 运算求出该数据(key)的数组下标并判断该下标位置是否有数据if ((p = tab[i = (n - 1) & hash]) == null)//如果没有,直接将数据放在该下标位置tab[i] = newNode(hash, key, value, null);//该数组下标有数据的情况else {Node<K,V> e; K k;//判断该位置数据的key和新来的数据是否一样if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))//如果一样,证明为修改操作,该节点的数据赋值给e,后边会用到e = p;//判断是不是红黑树else if (p instanceof TreeNode)//如果是红黑树的话,进行红黑树的操作e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//新数据和当前数组既不相同,也不是红黑树节点,证明是链表else {//遍历链表for (int binCount = 0; ; ++binCount) {//判断next节点,如果为空的话,证明遍历到链表尾部了if ((e = p.next) == null) {//把新值放入链表尾部p.next = newNode(hash, key, value, null);//因为新插入了一条数据,所以判断链表长度是不是大于等于8if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st//如果是,进行转换红黑树操作treeifyBin(tab, hash);break;}//判断链表当中有数据相同的值,如果一样,证明为修改操作if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;//把下一个节点赋值为当前节点p = e;}}//判断e是否为空(e值为修改操作存放原数据的变量)if (e != null) { // existing mapping for key//不为空的话证明是修改操作,取出老值V oldValue = e.value;//一定会执行 onlyIfAbsent传进来的是falseif (!onlyIfAbsent || oldValue == null)//将新值赋值当前节点e.value = value;afterNodeAccess(e);//返回老值return oldValue;}}//计数器,计算当前节点的修改次数++modCount;//当前数组中的数据数量如果大于扩容阈值 16* 0.75 = 12if (++size > threshold)//进行扩容操作resize();//空方法afterNodeInsertion(evict);//添加操作时 返回空值return null;
}
面试文稿:
- 判断键值对数组table是否为空或为null,否则执行resize()进行扩容(初始化)
- 根据键值key计算hash值得到数组索引
- 判断table[i]==null,条件成立,直接新建节点添加
- 如果table[i]==null ,不成立
4.1 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
4.2 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对
4.3 遍历table[i],链表的尾部插入数据,然后判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操 作,遍历过程中若发现key已经存在直接覆盖value - 插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
4.5 讲一讲HashMap的扩容机制 难3频4
扩容的流程
第一次初始化数组的流程如下:

第一次存储数量大于12时流程如下:

//扩容、初始化数组
final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;//如果当前数组为null的时候,把oldCap老数组容量设置为0int oldCap = (oldTab == null) ? 0 : oldTab.length;//老的扩容阈值int oldThr = threshold;int newCap, newThr = 0;//判断数组容量是否大于0,大于0说明数组已经初始化if (oldCap > 0) {//判断当前数组长度是否大于最大数组长度if (oldCap >= MAXIMUM_CAPACITY) {//如果是,将扩容阈值直接设置为int类型的最大数值并直接返回threshold = Integer.MAX_VALUE;return oldTab;}//如果在最大长度范围内,则需要扩容 OldCap << 1等价于oldCap2//运算过后判断是不是最大值并且oldCap需要大于16else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY)
* newThr = oldThr << 1; // double threshold 等价于oldThr*2}//如果oldCap<0,但是已经初始化了,像把元素删除完之后的情况,那么它的临界值肯定还存在, 如果是首次初始化,它的临界值则为0else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr;//数组未初始化的情况,将阈值和扩容因子都设置为默认值else { // zero initial threshold signifies using defaultsnewCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}//初始化容量小于16的时候,扩容阈值是没有赋值的if (newThr == 0) {//创建阈值float ft = (float)newCap * loadFactor;//判断新容量和新阈值是否大于最大容量newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}//计算出来的阈值赋值threshold = newThr;@SuppressWarnings({"rawtypes","unchecked"})//根据上边计算得出的容量 创建新的数组 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];//赋值table = newTab;//扩容操作,判断不为空证明不是初始化数组if (oldTab != null) {//遍历数组for (int j = 0; j < oldCap; ++j) {Node<K,V> e;//判断当前下标为j的数组如果不为空的话赋值个e,进行下一步操作if ((e = oldTab[j]) != null) {//将数组位置置空oldTab[j] = null;//判断是否有下个节点if (e.next == null)//如果没有,就重新计算在新数组中的下标并放进去newTab[e.hash & (newCap - 1)] = e;//有下个节点的情况,并且判断是否已经树化else if (e instanceof TreeNode)//进行红黑树的操作((TreeNode<K,V>)e).split(this, newTab, j, oldCap);//有下个节点的情况,并且没有树化(链表形式)else {//比如老数组容量是16,那下标就为0-15//扩容操作*2,容量就变为32,下标为0-31//低位:0-15,高位16-31//定义了四个变量// 低位头 低位尾Node<K,V> loHead = null, loTail = null;// 高位头 高位尾Node<K,V> hiHead = null, hiTail = null;//下个节点Node<K,V> next;//循环遍历do {//取出next节点next = e.next;//通过 与操作 计算得出结果为0if ((e.hash & oldCap) == 0) {//如果低位尾为null,证明当前数组位置为空,没有任何数据if (loTail == null)//将e值放入低位头loHead = e;//低位尾不为null,证明已经有数据了else//将数据放入next节点loTail.next = e;//记录低位尾数据loTail = e;}//通过 与操作 计算得出结果不为0else {//如果高位尾为null,证明当前数组位置为空,没有任何数据if (hiTail == null)//将e值放入高位头hiHead = e;//高位尾不为null,证明已经有数据了else//将数据放入next节点hiTail.next = e;//记录高位尾数据hiTail = e;}}//如果e不为空,证明没有到链表尾部,继续执行循环while ((e = next) != null);//低位尾如果记录的有数据,是链表if (loTail != null) {//将下一个元素置空loTail.next = null;//将低位头放入新数组的原下标位置newTab[j] = loHead;}//高位尾如果记录的有数据,是链表if (hiTail != null) {//将下一个元素置空hiTail.next = null;//将高位头放入新数组的(原下标+原数组容量)位置newTab[j + oldCap] = hiHead;}}}}}//返回新的数组对象return newTab;}
面试文稿:
- 在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据初始化数组长度为16,以后每次每次扩容都是达到了扩容阈值(数组长度 * 0.75)
- 每次扩容的时候,都是扩容之前容量的2倍;
- 扩容之后,会新创建一个数组,需要把老数组中的数据挪动到新的数组中
- 没有hash冲突的节点,则直接使用 e.hash & (newCap - 1) 计算新数组的索引位置
- 如果是红黑树,走红黑树的添加
- 如果是链表,则需要遍历链表,可能需要拆分链表,判断(e.hash & oldCap)是否为0,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上
4.6 面试题-hashMap的寻址算法 难4频4
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}
在putVal方法中,有一个hash(key)方法,这个方法就是来去计算key的hash值的,看下面的代码
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
首先获取key的hashCode值,然后右移16位 异或运算 原来的hashCode值,主要作用就是使原来的hash值更加均匀,减少hash冲突。
GPT:通常情况下,hashCode 的低位信息可能有某些模式或偏向,而高位的信息可能没有充分地分布到低位。为了避免这些模式导致哈希值不均匀,HashMap 会对哈希值进行调整,使得低位和高位信息更加混合,从而避免过多元素落在哈希表的同一桶中。右移操作 (h >>> 16) 将原始 hashCode 的高 16 位移到低 16 位。
然后,使用 异或 (^) 操作将这两部分合并在一起。这是为了将 hashCode 的低位和高位信息都引入到哈希计算中。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict)
{。。。。。if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);。。。。
(n-1)&hash : 得到数组中的索引,代替取模,性能更好,数组长度必须是2的n次幂
面试文稿
关于hash值的其他面试题:为何HashMap的数组长度一定是2的次幂?
- 计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
- 扩容时重新计算索引效率更高: hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap
4.7 面试题-hashmap在1.7情况下的多线程死循环问题 难4频3
jdk7的的数据结构是:数组+链表
在数组进行扩容的时候,因为链表是头插法,在进行数据迁移的过程中,有可能导致死循环

- 变量e指向的是需要迁移的对象
- 变量next指向的是下一个需要迁移的对象 (e迁移完毕后,next把自己赋值给e)
- Jdk1.7中的链表采用的头插法
- 在数据迁移的过程中并没有新的对象产生,只是改变了对象的引用
产生死循环的过程:
线程1和线程2的变量e和next都引用了这个两个节点。

线程2扩容后,由于头插法,链表顺序颠倒,但是线程1的临时变量e和next还引用了这两个节点

第一次循环
由于线程2迁移的时候,已经把B的next执行了A

第二次循环

第三次循环

面试文稿
参考回答:
在jdk1.7的hashmap中在数组进行扩容的时候,因为链表是头插法,在进行数据迁移的过程中,有可能导致死循环
比如说,现在有两个线程
线程一:读取到当前的hashmap数据,数据中一个链表,在准备扩容时,线程二介入
线程二:也读取hashmap,直接进行扩容。因为是头插法,链表的顺序会进行颠倒过来。比如原来的顺序是AB,扩容后的顺序是BA,线程二执行结束。
线程一:继续执行的时候就会出现死循环的问题。
线程一先将A移入新的链表,再将B插入到链头,由于另外一个线程的原因,B的next指向了A,
所以B->A->B,形成循环。
当然,JDK 8 将扩容算法做了调整,不再将元素加入链表头(而是保持与扩容前一样的顺序),使用尾插法,就避免了jdk7中死循环的问题。
相关文章:
黑马Java面试教程_P7_常见集合_P4_HashMap
系列博客目录 文章目录 系列博客目录4. HashMap相关面试题4.4 面试题-HashMap的put方法的具体流程 频54.4.1 hashMap常见属性4.4.2 源码分析 HashMap的构造函数面试文稿: 4.5 讲一讲HashMap的扩容机制 难3频4面试文稿: 4.6 面试题-hashMap的寻址算法 难4…...

使用 CFD 加强水资源管理:全面概述
探索 CFD(计算流体动力学)在增强保护人类健康的土木和水利工程实践方面的重大贡献。 挑战 水资源管理是指规划、开发、分配和管理水资源最佳利用的做法。它包括广泛的活动,旨在确保水得到有效和可持续的利用,以满足各种需求&…...

XXE练习
pikachu-XXE靶场 1.POC:攻击测试 <?xml version"1.0"?> <!DOCTYPE foo [ <!ENTITY xxe "a">]> <foo>&xxe;</foo> 2.EXP:查看文件 <?xml version"1.0"?> <!DOCTYPE foo [ <!ENTITY xxe SY…...

R语言读取hallmarks的gmt文档的不同姿势整理
不同格式各有所用 1.读取数据框格式的 hallmarks <- clusterProfiler::read.gmt("~/genelist/h.all.v7.4.symbols.gmt") #返回的是表格 hallmarks$term<- gsub(HALLMARK_,"",hallmarks$term)适配Y叔的clusterProfiler的后续分析,比如整理后geneli…...

【Nginx-4】Nginx负载均衡策略详解
在现代Web应用中,随着用户访问量的增加,单台服务器往往难以承受巨大的流量压力。为了解决这一问题,负载均衡技术应运而生。Nginx作为一款高性能的Web服务器和反向代理服务器,提供了多种负载均衡策略,能够有效地将请求分…...

Python 的 Decimal的错误计算
摘要 阐述在使用 Python的 Decimal类时,可能产生的错误计算。 在 详述 BigDecimal 的错误计算 中,笔者较为详细地说明了 Java的 BigDecimal可能出错的原因。类似地,Python的 decimal模块中有个 Decimal类,也可用于高精度的十进制…...

【韩顺平 Java满汉楼项目 控制台版】MySQL+JDBC+druid
文章目录 功能界面用户登录界面显示餐桌状态预定显示所有菜品点餐查看账单结账退出满汉楼 程序框架图项目依赖项目结构方法调用图功能实现登录显示餐桌状态订座显示所有菜品点餐查看账单结账退出满汉楼 扩展思考多表查询如果将来字段越来越多怎么办? 员工信息字段可…...

【HAL库】STM32CubeMX开发----STM32F407----Time定时器中断实验
STM32CubeMX 下载和安装 详细教程 【HAL库】STM32CubeMX开发----STM32F407----目录 前言 本次实验以 STM32F407VET6 芯片为MCU,使用 25MHz 外部时钟源。 实现定时器TIM3中断,每1s进一次中断。 定时器计算公式如下: arr 是自动装载值&#x…...
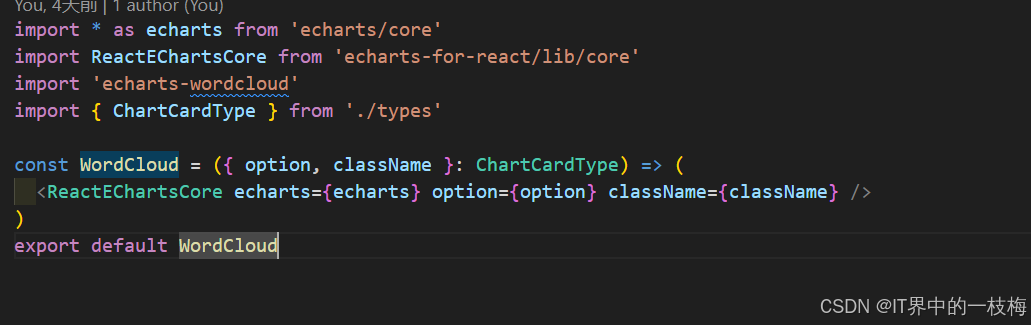
react18+ts 封装图表及词云组件
react18ts 封装图表及词云组件 1.下载依赖包 "echarts": "^5.5.1","echarts-for-react": "^3.0.2","echarts-wordcloud": "^2.1.0",2.创建目录结构 3.代码封装 ChartCard.tsx Wordcloud.tsx 4.调用 import Rea…...

图像根据mask拼接时,边缘有色差 解决
目录 渐变融合(Feathering) 沿着轮廓线模糊: 代码: 泊松融合 效果比较好: 效果图: 源代码: 泊松融合,mask不扩大试验 效果图: 源代码: 两个图像根据mask拼接时,边缘有色差 渐变融合(Feathering) import numpy as np import cv2# 假设 img1, img2 是两个…...

17、ConvMixer模型原理及其PyTorch逐行实现
文章目录 1. 重点2. 思维导图 1. 重点 patch embedding : 将图形分割成不重叠的块作为图片样本特征depth wise point wise new conv2d : 将传统的卷积转换成通道隔离卷积和像素空间隔离两个部分,在保证精度下降不多的情况下大大减少参数量 2. 思维导图 后续再整…...

Spring整合Redis基本操作步骤
Spring 整合 Redis 操作步骤总结 1. 添加依赖 首先,在 pom.xml 文件中添加必要的 Maven 依赖。Redis 相关的依赖包括 Spring Boot 的 Redis 启动器和 fastjson(如果需要使用 Fastjson 作为序列化工具): <!-- Spring Boot Re…...

STM32使用SFUD库驱动W25Q64
SFUD简介 SFUD是一个通用SPI Flash驱动库,通过SFUD可以库轻松完成对SPI Flash的读/擦/写的基本操作,而不用自己去看手册,写代码造轮子。但是SFUD的功能不仅仅于此:①通过SFUD库可以实现在一个项目中对多个Flash的同时驱动&#x…...

ArKTS基础组件
一.AlphabetIndexer 可以与容器组件联动用于按逻辑结构快速定位容器显示区域的组件。 子组件 color:设置文字颜色。 参数名类型必填说明valueResourceColor是 文字颜色。 默认值:0x99182431。 selectedColor:设置选中项文字颜色。 参数名类型必填说明valueRes…...

如何理解TCP/IP协议?如何理解TCP/IP协议是什么?
理解TCP/IP协议 1. 什么是TCP/IP协议? TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议)是一组用于实现网络通信的协议,广泛用于互联网和局域网中。TCP/IP协议栈由一系列协议组成,规定了计算机如何在网络中发送和接收数据。它通常被用来…...

如何使用 Python 连接 SQLite 数据库?
SQLite是一种轻量级的嵌入式数据库,广泛应用于各种应用程序中。 Python提供了内置的sqlite3模块,使得连接和操作SQLite数据库变得非常简单。 下面我将详细介绍如何使用sqlite3模块来连接SQLite数据库,并提供一些实际开发中的建议和注意事项…...
【博弈模型】古诺模型、stackelberg博弈模型、伯特兰德模型、价格领导模型
博弈模型 1、古诺模型(cournot)(1)假设(2)行为分析(3)经济后果(4)例题 2、stackelberg博弈模型(产量领导模型)(1ÿ…...
)
单片机:实现花样灯数码管的显示(附带源码)
单片机实现花样灯数码管显示 数码管(七段数码管)广泛用于数字显示,例如时钟、计数器、温度计等设备。在本项目中,我们将使用单片机实现花样灯数码管的显示效果。所谓花样灯显示是指通过控制数码管上的各个段位,以不同…...
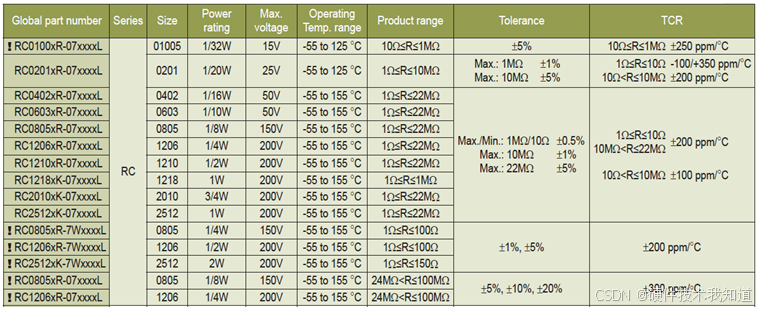
什么是芯片电阻
有人把Chip Resistor翻译成“芯片电阻”,我觉得翻译成“贴片电阻”或“片状电阻”更合适。有些厂商也称之为”电阻片”,英文写作Resistor Chip。比如:Thick film resistor chips(厚膜电阻片)、Thin film resistor chip…...
和(2D 直线\3D 平面)转换函数 (五))
【C++】sophus : geometry.hpp 位姿(SE2 和 SE3)和(2D 直线\3D 平面)转换函数 (五)
这段代码定义了一系列在位姿(SE2 和 SE3)和几何实体(2D 直线和 3D 平面)之间进行转换的函数。它利用了 Sophus 库中已有的旋转表示(SO2 和 SO3)。 以下是函数的详细解释: 1. SO2 与直线…...

如何用5个步骤构建企业级智能SQL工具?自然语言转SQL全攻略
如何用5个步骤构建企业级智能SQL工具?自然语言转SQL全攻略 【免费下载链接】sqlcoder SoTA LLM for converting natural language questions to SQL queries 项目地址: https://gitcode.com/gh_mirrors/sq/sqlcoder 在数据驱动决策的时代,自然语言…...

3种突破窗口限制的高效方案:WindowResizer让桌面管理更自由
3种突破窗口限制的高效方案:WindowResizer让桌面管理更自由 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 在数字化办公环境中,窗口尺寸管理直接影响工作效…...

gcc编译与gdb使用
一、GCC介绍1.1 GNU工具集GNU 工具集是由自由软件基金会发起的 GNU 项目孕育而生,始于20世纪80年代初,旨在构建完全自由的操作系统,其核心原则强调用户自由使用、修改和分发软件的权利,极大推动了自由软件运动和开源生态系统发展&…...

OpenClaw安全实验室:SecGPT-14B+Metasploit自动化漏洞验证环境
OpenClaw安全实验室:SecGPT-14BMetasploit自动化漏洞验证环境 1. 为什么需要自动化漏洞验证环境 作为安全研究员,我每天要处理大量漏洞扫描报告。最头疼的不是发现漏洞,而是验证这些漏洞的真实性——手动复现每个漏洞需要反复切换工具、整理…...

P4084 [USACO17DEC] Barn Painting G 题解
题目描述Farmer John 有一个大农场,农场上有 N 个谷仓(1≤N≤105),其中一些已经涂色,另一些尚未涂色。Farmer John 想要为这些剩余的谷仓涂色,使得所有谷仓都被涂色,但他只有三种可用的油漆颜色…...
)
【仅开放72小时】C++27实验性parallel_unstable_sort_view深度评测:多核排序吞吐达1.2GB/s的编译器flag调优矩阵(附Intel Xeon W9-3400实测数据)
第一章:C27实验性parallel_unstable_sort_view概览parallel_unstable_sort_view 是 C27 标准提案(P2903R3)中引入的实验性范围适配器,旨在为无序、高性能的并行排序提供轻量级视图封装。它不保证相等元素的相对顺序(即…...

Phi-4-mini-reasoning镜像免配置:预置Prometheus监控指标暴露配置
Phi-4-mini-reasoning镜像免配置:预置Prometheus监控指标暴露配置 1. 模型简介与部署概述 Phi-4-mini-reasoning是一个基于合成数据构建的轻量级开源模型,专注于高质量、密集推理的数据处理能力。作为Phi-4模型家族的一员,它特别针对数学推…...

GHelper完整指南:为华硕笔记本卸载臃肿控制软件的最佳替代方案
GHelper完整指南:为华硕笔记本卸载臃肿控制软件的最佳替代方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, S…...

张毕贺的音乐故事《越说越明》
张毕贺的音乐故事,始于一把吉他,成于不懈创作,最终汇成一条连接梦想与大众的河流。他的音乐历程,既是个人才华的绽放,也是对音乐教育与本土文化推广的坚定投入。 音乐之路:从翻唱走红到原创深耕 张毕贺的…...

Unity中如何通过Shader与Bounds控制实现视锥体外物体渲染
1. 为什么需要控制视锥体外物体渲染 在Unity的默认渲染流程中,摄像机只会渲染位于视锥体(Frustum)范围内的物体,这个机制被称为视锥体剔除(Frustum Culling)。这个优化手段能显著提升渲染效率,避…...