Elasticsearch:什么是信息检索?
信息检索定义
信息检索 (IR) 是一种有助于从大量非结构化或半结构化数据中有效、高效地检索相关信息的过程。信息(IR)检索系统有助于搜索、定位和呈现与用户的搜索查询或信息需求相匹配的信息。
作为信息访问的主要形式,信息检索是每天使用搜索引擎的数十亿人的依靠。信息检索系统部署了各种模型、算法和日益先进的技术(例如:向量搜索),使搜索访问范围广泛且不断增长的来源成为可能,包括文档、文档中的项目、元数据以及文本、图像、视频和声音的数据库。
信息检索简史
信息检索的起源可以追溯到古代,当时人们建立了图书馆和档案馆来组织和存储信息,包括对学术作品进行索引和字母排序。到了 19 世纪,人们开始使用打孔卡来处理信息,1931 年,伊曼纽尔·戈德堡 (Emanuel Goldberg) 获得了第一台成功的机电文档检索设备的专利,该设备被称为 “统计机(Statistical Machine)”,旨在搜索胶片上编码的数据。
随着现代计算机的发展,信息检索在 20 世纪中叶开始正式化为一门科学学科。杰拉德·萨尔顿 (Gerard Salton) 和汉斯·彼得·卢恩 (Hans Peter Luhn) 开创了自动文档检索的早期模型。 20 世纪 60 年代,Salton 和康奈尔大学的同事创建了 SMART 信息检索系统,这是该领域的一个里程碑,为现代 IR 技术和关键概念奠定了基础,包括术语文档矩阵、向量空间模型、相关反馈和 Rocchio 分类。
到 20 世纪 70 年代,随着更先进的检索技术、概率模型和完全清晰的向量处理框架的出现,该领域取得了长足的进步。随着 20 世纪 90 年代末搜索引擎的出现,曾经主要属于学术界、机构和图书馆领域的 IR 系统和模型开始得到广泛应用。
信息检索模型的类型
不同类型的信息检索模型旨在应对特定挑战并建立检索相关信息的流程。有经典模型构成该领域的基础,有非经典模型试图解决传统方法的局限性,还有替代 IR 模型走得更远,通常通过集成机器学习和语言模型等先进技术。一般来说,最常见的信息检索模型类型包括:
布尔模型
布尔模型是最简单和最早的信息检索模型之一,它基于布尔逻辑,使用包括 AND、OR 和 NOT 在内的运算符来组合查询词。文档表示为术语集,查询经过处理以识别符合指定条件的文档。虽然布尔模型对于精确查询匹配很有效,但它无法根据相关性对文档进行排名或提供部分匹配。
向量空间模型
在此模型中,文档和查询表示为多维空间中的向量。每个维度对应一个唯一的术语,每个维度的值表示该术语在文档或查询中的重要性和频率。计算查询向量和文档向量之间的余弦相似度来确定文档与查询的相关性。向量空间模型的部分开发目的是为了解决布尔模型的缺点,它可以根据相关性分数提供排名结果,并广泛用于文本检索。
概率模型
此模型估计文档与给定查询相关的概率。它考虑术语频率和文档长度等因素来计算相关性概率。它在处理大量数据时特别有用。由于它与加权统计数据一起工作,因此该模型非常适合提供排名结果。
潜在语义索引 (Latent Semantic Indexing - LSI)
LSI 使用奇异值分解 (Singular Value Decomposition, SVD) 来捕捉术语与文档之间的语义关系。与语义搜索类似,语义索引利用意图和上下文来识别概念上相关的文档,即使它们并不共享完全相同的术语。这一关键能力使 LSI 能够有效提取文本主体中词语的上下文意义。
Okapi BM25
BM25 是概率模型中比较流行的变体之一,是一种搜索相关性排名函数。搜索引擎使用它来估计文档与搜索查询的相关性。它根据出现在每个文档中的查询词对一组文档进行排名,而不考虑文档中词之间的相互关系,它由许多具有不同组件和参数的评分函数组成。BM 代表 “最佳匹配 - best matching.”。
信息检索为何如此重要?
在信息时代,每秒都会生成数据,其规模曾经令人难以想象。如果没有可行的信息访问方式,数据实际上就是无用的。IR 系统可确保用户在信息过载的噪声不断增加的情况下获得所需的相关信息。
信息检索在现代世界的几乎所有行业和领域都发挥着至关重要的作用,从学术界和电子商务到医疗保健和国防。它是一种人机界面,可帮助企业和个人进行决策、研究和知识发现。从搜索本地桌面到发现世界新闻,从基因组研究到垃圾邮件过滤,信息检索几乎是我们生活的方方面面的基础。
搜索引擎依靠信息检索模型来提供准确的搜索结果。电子商务平台使用检索模型根据用户偏好和行为推荐产品。数字图书馆依靠信息检索科学来帮助用户进行研究。在医疗保健领域,信息检索系统可帮助在数据库中搜索相关患者记录、医学研究和治疗方案。法律专业人士则使用信息检索来梳理大量法律案件,寻找先例。
信息检索系统如何工作?
信息检索过程通常在用户向系统输入正式查询以说明其信息需求时触发。IR 系统在内容集合或信息数据库中创建文档索引。数据对象(包括来自文本文档、图像、音频和视频的数据对象)经过处理以提取相关术语和替代数据,并使用数据结构有效地存储和检索这些实体。
当用户提交查询时,系统会对其进行处理以识别相关术语并确定其重要性。然后,系统根据文档与查询的相关性对其进行排名。在许多情况下,IR 模型和算法用于根据集合或数据库中的每个对象与查询的匹配程度来计算数字分数。许多查询不会完全匹配:最相关的文档以排名列表的形式呈现给用户。这些排名结果代表了信息检索搜索和数据库搜索之间的一个主要区别。
信息检索系统的主要组件
信息检索系统由几个关键组件组成:
- 文档集合
- 系统可以从中检索信息的文档集。
- 索引组件
- 处理源数据和文档以创建索引,将术语和数据映射到包含它们的文档 — 通常采用专用的、优化的数据结构。
- 查询处理器
- 查询处理器分析用户查询和关键字,并准备将它们与索引实体进行匹配。
- 排名算法
- 排名算法确定文档与查询的相关性并为其分配分数。最常见的是 BM25(最佳匹配 25)排名算法,该算法以其对词频的改进方法而闻名,可避免文档中充斥过多的关键字和重复术语。
- 用户界面
- UI 是用户与系统交互、提交查询和显示结果的显示界面。在这里,可以根据结果对用户查询的响应程度对其进行调整。在某些情况下,机制可能允许用户对检索到的文档的相关性提供反馈,这可用于改进未来的检索。
信息检索的好处
信息检索模型的显著好处包括:
- 高效的信息访问:最重要的是,信息检索系统为人们节省了大量的时间和精力。信息检索使用户能够快速访问相关信息,而无需手动搜索大量文档和数据。
- 知识发现:信息检索是一种强大的工具,可以让我们理解数据。借助信息检索,用户可以识别数据中最初可能不明显的趋势、模式和关系。
- 个性化:一些信息检索系统可以根据个人用户的偏好和行为以有意义的方式定制结果。
- 决策支持:专业人士能够在需要时访问最相关的信息,从而做出明智的决策。
信息检索的挑战和局限性
尽管取得了重大进展,但信息检索从来都不完美。已知的问题、挑战和局限性仍然存在,包括:
- 模糊性自然语言本质上是模糊的,因此很难准确解释用户查询。类似的模糊性和不确定性问题会影响索引和评估过程,尤其是对于图像和视频等对象。
- 相关性确定相关性是主观的,可能会因用户上下文和意图而异。用于确定价值和重要性的标准可能受一组不完善的通用标准的支配,这些标准不能反映个人用户的特定需求。
- 语义差距由于文本表示和人类理解之间的差距,检索系统可能难以捕捉内容的深层含义。信息和用户表达的不清晰是成功进行 IR 的主要障碍。由人工智能驱动的高级自然语言处理旨在弥合这些语义和模糊性差距。
- 可扩展性随着数据量的增加,维持高效、有效的检索和索引变得更加复杂,需要越来越多的资源和计算能力。
信息检索的未来趋势
随着生成式人工智能和机器学习的最新突破,我们所熟知的信息检索可能即将迎来变革。
先进的机器学习技术已经通过从用户交互中学习并适应不断变化的环境、位置和偏好来增强检索。改进的自然语言处理和语义分析可以更好地理解用户查询和文档内容。检索系统也在不断发展,以更有效地处理不断增长的多媒体内容。
生成式人工智能对信息检索的影响具有革命性的潜力。我们将收到问题的实际答案,而不是我们习惯的结果排序列表,这需要手动对现有链接和文档进行排序才能找到我们正在寻找的内容。上下文将从一个问题传递到另一个问题,允许进行复杂、对话式、多步骤的查询,几乎消除了人类语言处理和意图的障碍。搜索引擎无需我们自己拼凑答案,而是会替我们完成工作,将信息综合成原创内容形式的具体定制结果,提供我们真正需要的内容,而不会提供我们不需要的内容。

深入研究 2024 年技术搜索趋势。观看此网络研讨会,了解最佳实践、新兴方法以及顶级趋势如何影响 2024 年的开发人员。
使用 Elasticsearch 进行信息检索
Elastic 致力于不断改进 Elastic Stack 中可用的信息检索功能。我们最新的检索模型 Elastic Learned Sparse Encoder 通过预先训练的语言模型增强了 Elastic 的开箱即用检索功能。为了实现真正的一键式体验,我们将其与新的 Elasticsearch Relevance Engine 集成在一起。
Elasticsearch 还具有出色的词汇检索功能和丰富的工具,可用于组合不同查询的结果,这一概念称为混合检索。我们还通过 NLP 和向量搜索增强了聊天机器人功能,发布了用于文本嵌入的第三方自然语言处理模型,并使用 BEIR 的子集评估我们的性能。
你接下来应该做什么
只要你准备好了……我们可以通过以下四种方式帮助你从业务数据中获取见解:
- 开始免费试用,了解 Elastic 如何帮助你的业务。
- 浏览我们的解决方案,了解 Elasticsearch 平台的工作原理以及它们如何满足你的需求。
- 了解如何在企业中提供生成式 AI。
- 与你认识的喜欢阅读这篇文章的人分享这篇文章。通过电子邮件、LinkedIn、Twitter 或 Facebook 与他们分享。
原文:What is Information Retrieval? | A Comprehensive Information Retrieval (IR) Guide | Elastic
相关文章:
Elasticsearch:什么是信息检索?
信息检索定义 信息检索 (IR) 是一种有助于从大量非结构化或半结构化数据中有效、高效地检索相关信息的过程。信息(IR)检索系统有助于搜索、定位和呈现与用户的搜索查询或信息需求相匹配的信息。 作为信息访问的主要形式,信息检索是每天使用…...

Spark-Streaming容错语义
一、背景 为了理解Spark Streaming提供的语义,我们先回顾西Spark RDD的基本容错语义学。 RDD是一个不可变的、确定性可重新计算的分布式数据集。每个RDD都记住在容错输入数据集上用于创建它的确定性操作的沿袭。如果RDD的任何分区由于工作节点故障而丢失ÿ…...

2024年12月陪玩系统-仿东郊到家约玩系统是一种新兴的线上预约线下社交、陪伴系统分享-优雅草央千澈-附带搭建教程
2024年12月陪玩系统-仿东郊到家约玩系统是一种新兴的线上预约线下社交、陪伴系统分享-优雅草央千澈-附带搭建教程 产品介绍 仿东郊到家约玩系统是一种新兴的线上预约,线下社交、陪伴、助娱、助攻、分享、解答、指导等服务模式,范围涉及电竞、运动、音乐…...

GUI07-学工具栏,懂MVC
MVC模式,是天底下编写GUI程序最为经典、实效的一种软件架构模式。当一个人学完菜单栏、开始学习工具栏时,就是他的一生中,最适合开始认识 MVC 模式的好时机之一。这节将安排您学习: Model-View-Controller 模式如何创建工具栏以及…...

【进程篇】04.进程的状态与优先级
一、进程的状态 1.1 进程的状态 1.1.1 并行与并发 • 并行: 多个进程在多个CPU下分别,同时进行运行 • 并发: 多个进程在一个CPU下采用进程切换的方式,在一个时间片内,让多个进程都得以推进 1.1.2 时间片的概念 LInux/windows这些民用级别…...

ElasticSearch 数据聚合与运算
1、数据聚合 聚合(aggregations)可以让我们极其方便的实现数据的统计、分析和运算。实现这些统计功能的比数据库的 SQL 要方便的多,而且查询速度非常快,可以实现近实时搜索效果。 注意: 参加聚合的字段必须是 keywor…...
科研学习|论文解读——智能体最新研究进展
从2024-12-13到2024-12-18的45篇文章中精选出5篇优秀的工作分享 Can Modern LLMs Act as Agent Cores in Radiology~Environments? Achieving Collective Welfare in Multi-Agent Reinforcement Learning via Suggestion Sharing A systematic review of norm emergence in …...

面试小札:Java后端闪电五连鞭_8
1. Kafka消息模型及其组成部分 - 消息(Message):是Kafka中最基本的数据单元。消息包含一个键(key)、一个值(value)和一个时间戳(timestamp)。键可以用于对消息进行分区等…...
保存时间带时分秒,回显时分秒变成00:00:00)
java error(2)保存时间带时分秒,回显时分秒变成00:00:00
超简单,顺带记录一下 1.入参实体类上使用注释:JsonFormat(pattern “yyyy-MM-dd”) 导致舍弃了 时分秒的部分。 2.数据库字段对应的类型是 date。date就是日期,日期就不带时分秒。 3.返参实体类使用了JsonFormat(pattern “yyyy-MM-dd”) 导…...

计算机毕业设计python+spark+hive动漫推荐系统 漫画推荐系统 漫画分析可视化大屏 漫画爬虫 漫画推荐系统 漫画爬虫 知识图谱 大数据毕设
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片! 作者简介:Java领…...
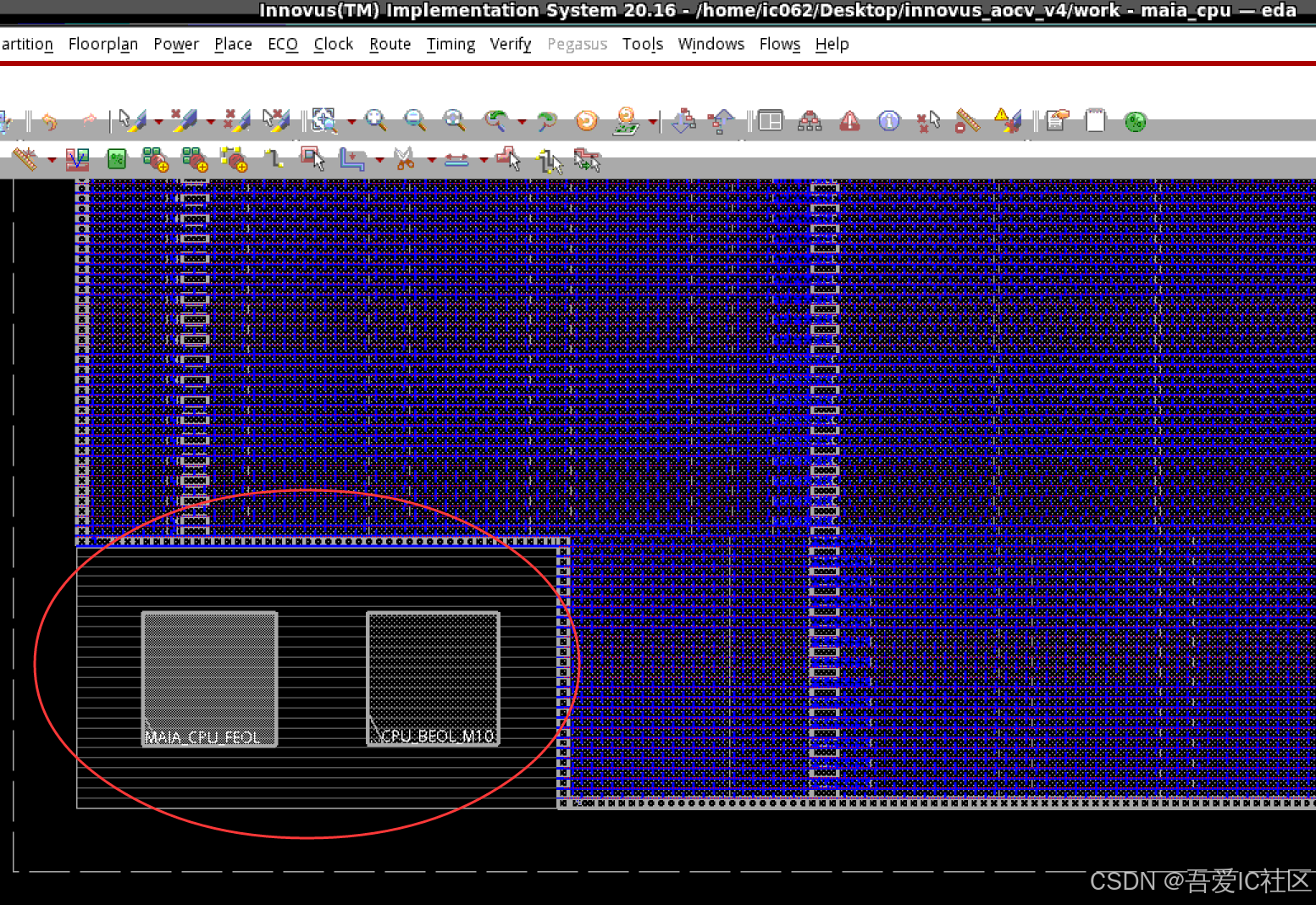
数字IC后端设计实现篇之TSMC 12nm TCD cell(Dummy TCD Cell)应该怎么加?
TSMC 12nm A72项目我们需要按照foundary的要求提前在floorplan阶段加好TCD Cell。这个cell是用来做工艺校准的。这个dummy TCD Cell也可以等后续Calibre 插dummy自动插。但咱们项目要求提前在floorplan阶段就先预先规划好位置。 TSCM12nm 1P9M的metal stack结构图如下图所示。…...
(8)YOLOv6算法基本原理
一、YOLOv6 模型原理 发布日期:2022年6月 作者:美团技术团队 骨干网络:参考了 RepVGG 的设计,将重参数化能力进行补强,增强了模型结构的重参数化能力。使用了深度可分离卷积和跨阶段连接等技术,旨在提升…...
LNMP+discuz论坛
0.准备 文章目录 0.准备1.nginx2.mysql2.1 mysql82.2 mysql5.7 3.php4.测试php访问mysql5.部署 Discuz6.其他 yum源: # 没有wget,用这个 # curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo[rootlocalhost ~]#…...
在linux系统的docker中安装GitLab
一、安装GitLab: 在安装了docker之后就是下载安装GitLab了,在linux系统中输入命令:docker search gitlab就可以看到很多项目,一般安装第一个,它是英文版的,如果英文不好可以安装twang2218/gitlab-ce-zh。 …...

Python面试常见问题及答案12
问题: 请解释Python中的GIL(全局解释器锁)是什么? ○ 答案: GIL是Python解释器中的一种机制,用于确保任何时候只有一个线程在执行Python字节码。这在多线程场景下可能影响性能优化,但对于单线程…...
从0-1开发一个Vue3前端系统页面-9.博客页面布局
本节主要实现了博客首页界面的基本布局并完善了响应式布局,因为完善了响应式布局故对前面的页面布局有所改动,这里会将改动后的源码同步上传。 1.对页面头部的用户信息进行设计和美化 布局设计参考 :通常初级前端的布局会通过多个div划分区域…...

[手机Linux] 六,ubuntu18.04私有网盘(NextCloud)安装
一,LNMP介绍 LNMP一键安装包是一个用Linux Shell编写的可以为CentOS/RHEL/Fedora/Debian/Ubuntu/Raspbian/Deepin/Alibaba/Amazon/Mint/Oracle/Rocky/Alma/Kali/UOS/银河麒麟/openEuler/Anolis OS Linux VPS或独立主机安装LNMP(Nginx/MySQL/PHP)、LNMPA(Nginx/MySQ…...

白话java设计模式
创建模式 单例模式(Singleton Pattern): 就是一次创建多次使用,它的对象不会重复创建,可以全局来共享状态。 工厂模式(Factory Method Pattern): 可以通过接口来进行实例化创建&a…...
助力 Tuanjie OpenHarmony 开发:如何使用工具包 Hilog 和 SDK Kits Package?
随着团结引擎从 1.0.0 迭代至 1.3.0,越来越多的开发者开始使用团结引擎开发 OpenHarmony 应用。 在开发的过程中,我们也收到了大量反馈,尤其是在日志、堆栈和性能数据方面,这些信息对开发和调试过程至关重要。同时,我…...

NSDT 3DConvert:高效实现大模型文件在线预览与转换
NSDT 3DConvert 作为一个 WebGL 展示平台,能够实现多种模型格式免费在线预览,并支持大于1GB的OBJ、STL、GLTF、点云等模型进行在线查看与交互,这在3D模型展示领域是一个相当强大的功能。 平台特点 多格式支持 NSDT 3DConvert兼容多种3D模型…...

基于vLLM与OpenAI API的LLM生产部署框架实战指南
1. 项目概述:一个面向生产环境的LLM部署框架最近在折腾大语言模型(LLM)的部署,发现了一个挺有意思的项目:run-llama/llama_deploy。这名字乍一看,可能会让人以为它只是用来部署Meta的Llama系列模型的&#…...

AI应用开发实战:从RAG系统到多模型API调用的开源项目解析
1. 项目概述:一个AI项目的开源实践最近在GitHub上看到一个名为“hferello/ai”的项目,这个标题非常简洁,甚至可以说有些“神秘”。乍一看,它可能是一个关于人工智能的通用仓库,但点进去之后,你会发现它远不…...

3分钟掌握FanControl:Windows风扇控制终极指南
3分钟掌握FanControl:Windows风扇控制终极指南 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/FanCon…...

2025最权威的五大降重复率方案推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 处于学术探索的终点之处,一篇出色的毕业论文乃是知识跟汗水所凝结而成的&#x…...

AI 测试用例审核 Skill:把用例评审从“凭经验”变成“可评分”
导读测试用例写完以后,最怕的不是数量不够,而是评审会上被连续追问:“这个前置条件是什么?” “这里为什么直接跳到下一步?” “预期结果怎么算出来的?” “边界值有没有覆盖?” “PRD 里这个互…...

Gitee领跑本土化开发体验:深度解析国内代码托管平台的选择之道
在数字化转型浪潮中,代码托管平台已成为开发者团队不可或缺的基础设施。国内市场经过多年发展,已经从单一的海外平台依赖,逐步形成了多元化的平台选择生态。其中,Gitee凭借其本土化优势脱颖而出,成为众多国内开发团队的…...

【开源实践】从零构建Voronoi泡沫结构:多胞材料建模的简易路径
1. Voronoi泡沫结构:从自然现象到工程应用 第一次看到Voronoi结构是在一块龟甲上——那些不规则的六边形图案让我着迷。后来才知道,这种被称为"泰森多边形"的几何结构不仅存在于生物组织中,从蜂巢到干燥的泥地,从植物细…...

书成紫微动,律定凤凰驯:一破一立,铁哥的两部作品如何构成完整的文化闭环
书成紫微动,律定凤凰驯。 —— 唐《开元占经》卷一〇三 引言:千年谶语里的文明算法 无破则旧局不死,无立则新局不生。 一句千古古句,藏着文明迭代最严谨的底层逻辑: 先破后立,破立相生,方能形成…...

RL78/G13单片机定时器外部事件捕获与中断控制LED实践
1. 项目概述与核心思路最近在折腾瑞萨的RL78/G13系列单片机,手头正好有块开发板,就想用它来实现一个基础的定时器功能。这听起来是个老生常谈的话题,但实际动手时,你会发现从选型、配置到调试,每一步都有不少细节值得琢…...

从协议到实践:国密TLCP协议深度解析与Nginx国密化改造实战
1. 国密TLCP协议的前世今生 第一次接触国密TLCP协议是在2018年参与某金融机构的安全改造项目。当时客户明确提出要使用国产密码算法,但在实际部署过程中发现,现有的国际标准SSL/TLS协议对国密算法支持非常有限。这就是TLCP协议诞生的背景 - 为了解决国产…...