数据分析实战—IMDB电影数据分析
1.实战内容

1.加载数据到movies_df,输出前5行,输出movies_df.info(),movies_df.describe()
# (1)加载数据集,输出前5行
#导入库
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
matplotlib.rcParams['font.family'] = 'SimHei'
matplotlib.rcParams['axes.unicode_minus'] = Falsemovies_df=pd.read_csv('movie_metadata.csv')
movies_df.head(5)#输出前5行此为运行结果部分内容

movies_df.info() # 输出了27列特征的名称,非空数据个数,数据类型
movies_df.describe()#输出movies_df的基本统计量和分位数等值此为运行结果部分内容

2.数据清洗:统计每列缺失值个数;删除任何含有缺失值的行;删除重复数据;查看数据清洗后的数据集(movies_df_new)信息。
#(4)统计缺失值个数并打印
column_null_number = movies_df.isnull().sum()
print('每列缺失值个数','\n',column_null_number)
# (5)删除有缺失值的行,并将结果保存到数据集(movies_df_nonull)
movies_df_nonull = movies_df.dropna()
print('每列缺失值个数','\n',movies_df_nonull.isnull().sum())
print('数据个数',movies_df_nonull.shape)
# (6)删除重复数据,并将结果保存到数据集(movies_df_new)
movies_df_new = movies_df_nonull.drop_duplicates(keep='first')
movies_df_new.count()
movies_df_new.info() #验证一下结果
3.数据分析及与视化
# (7)统计每个国家及地区出品的电影数量并打印
country_group = movies_df_new.groupby('country').size()
country_group
# (8)显示电影出品数量排名前10位的国家及地区
group_head_10=country_group.sort_values(ascending=False).head(10)
group_head_10
#(9)绘制电影出品数量排名前10位的柱形图,本题5分
group_head_10.plot(kind = 'bar')
plt.xlabel("country/area")
# (10) 按年份统计每年的电影数量
group_year= movies_df_new.groupby('title_year').size()
group_year
#(11)绘制每年的电影数量图形
group_year.plot()
# (12)按年份统计每年电影总数量、彩色影片数量和黑白影片数量并绘制图形
movies_df_new['title_year'].value_counts().sort_index().\
plot(kind='line',label='total number')
movies_df_new[movies_df_new['color']=='Color']['title_year'].\
value_counts().sort_index().plot(kind='line',\
c='red',label='color number')
movies_df_new[movies_df_new['color']!='Color']['title_year'].\
value_counts().sort_index().plot(kind='line',c='black',\
label='Black White number')
plt.legend(loc='upper left')
# (13)计算不同类型的电影数量
# 提示:根据电影题材(Genres)列,进行统计。如某个电影的题材包含在|Action|Adventure|Fantasy|Sci-Fi这四类中。
# 提示:先读取movies_df_new['genres'],然后再用split进行分割读取。
types = []
for tp in movies_df_new['genres']:sp = tp.split('|')for x in sp:types.append(x)
types_df = pd.DataFrame({'genres':types})
types_df
types_df_counts = types_df['genres'].value_counts()
types_df_counts
types_df_counts.plot(kind='bar')
plt.xlabel('genres')
plt.ylabel('number')
plt.title('genres&number')
4.电影票房统计及电影票房相关因素的分析
# (14)每年票房统计并打印
year_gross = movies_df_new.groupby('title_year')['gross'].sum()
year_gross
# (15)绘制每年的票房统计图,本题5分
year_gross.plot(figsize=(10,5))
plt.xticks(range(1915,2018,5))
plt.xlabel('year')
plt.ylabel('gross')
plt.title('year&gross')
# (16)查看票房收入排名前20位的电影片名和类型
movie_grose_20 = movies_df_new.sort_values(['gross'],\
ascending=False).head(20)
movie_grose_20[['movie_title','gross','genres']]
# (17)电影评分与票房的关系散点图
# 提示:纵坐标要除以1000000000
plt.scatter(x= movies_df_new.imdb_score,y=movies_df_new.gross/1000000000)
plt.xlabel('imdb_score')
plt.ylabel('gross')
plt.title('imdb_score&gross')
# (18)电影时长与票房的关系的散点图
# 提示:纵坐标要除以1000000000
plt.scatter(x= movies_df_new.duration,y=movies_df_new.gross/1000000000)
plt.xlabel('duration')
plt.ylabel('gross')
plt.title('duration&gross')
2.数据集下载
https://gitee.com/qxh200000/c_-code/commit/5e5f95f930dfc03b587c20768e82cb4ecbda96fb
相关文章:
数据分析实战—IMDB电影数据分析
1.实战内容 1.加载数据到movies_df,输出前5行,输出movies_df.info(),movies_df.describe() # (1)加载数据集,输出前5行 #导入库 import pandas as pd import numpy as np import matplotlib import matplotlib.pyplo…...
)
Google guava 最佳实践 学习指南之08 `BiMap`(双向映射)
guava 最佳实践 学习指南 Google Guava 库中的 BiMap(双向映射)是一种特殊的映射类型,它维护了映射的反向视图,并确保不存在重复值,且始终可以安全地使用值获取对应的键。以下是关于 Guava BiMap 的一些介绍和用法&am…...

【设计模式】空接口
(空)接口的用法总结 接口用于定义某个类的特定能力或特性。在工作流或任务管理系统中,接口可以帮助标识哪些任务可以在特定阶段执行。通过实现这些接口,任务类可以被标识为在相应的阶段可以执行,从而在验证和执行逻辑…...

Grad-CAM-解释CNN决策过程的可视化技术
Grad-CAM(Gradient-weighted Class Activation Mapping)是一种用于解释卷积神经网络(CNN)决策过程的可视化技术。其核心思想是通过计算分类分数相对于网络确定的卷积特征的梯度,来识别图像中哪些部分对分类结果最为重要…...

前后端学习中本周遇到的内容
一、RequiresPermissions注解 例如: RequiresPermissions("demo:staff:save") void saveStaff(); 权限控制,要求含有demo:staff:save的权限才能执行方法saveStaff()。 二、遇到的细节问题 在进行增删改查时,发送http请求时&…...

基于海思soc的智能产品开发(巧用mcu芯片)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 对于开发车规级嵌入式软件的同学来说,socmcu这样的组合,他们并不陌生。但是传统的工业领域,比如发动机、医疗或…...

批量DWG文件转dxf(CAD图转dxf)——c#插件实现
此插件可将指定文件夹及子文件夹下的dwg文件批量转为dxf文件。 (使用方法:命令行输入 “netload” 加载插件,然后输入“dwg2dxf”运行,选择文件夹即可。) 生成dxf在此新建的文件夹路径下,包含子文件夹内的…...

flask flask-socketio创建一个网页聊天应用
应用所需环境: python 3.11.11 其他 只需要通过这个命令即可 pip install flask3.1.0 Flask-SocketIO5.4.1 -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple 最好是用conda创建一个新的虚拟环境来验证 完整的pip list如下 Package Version ----…...
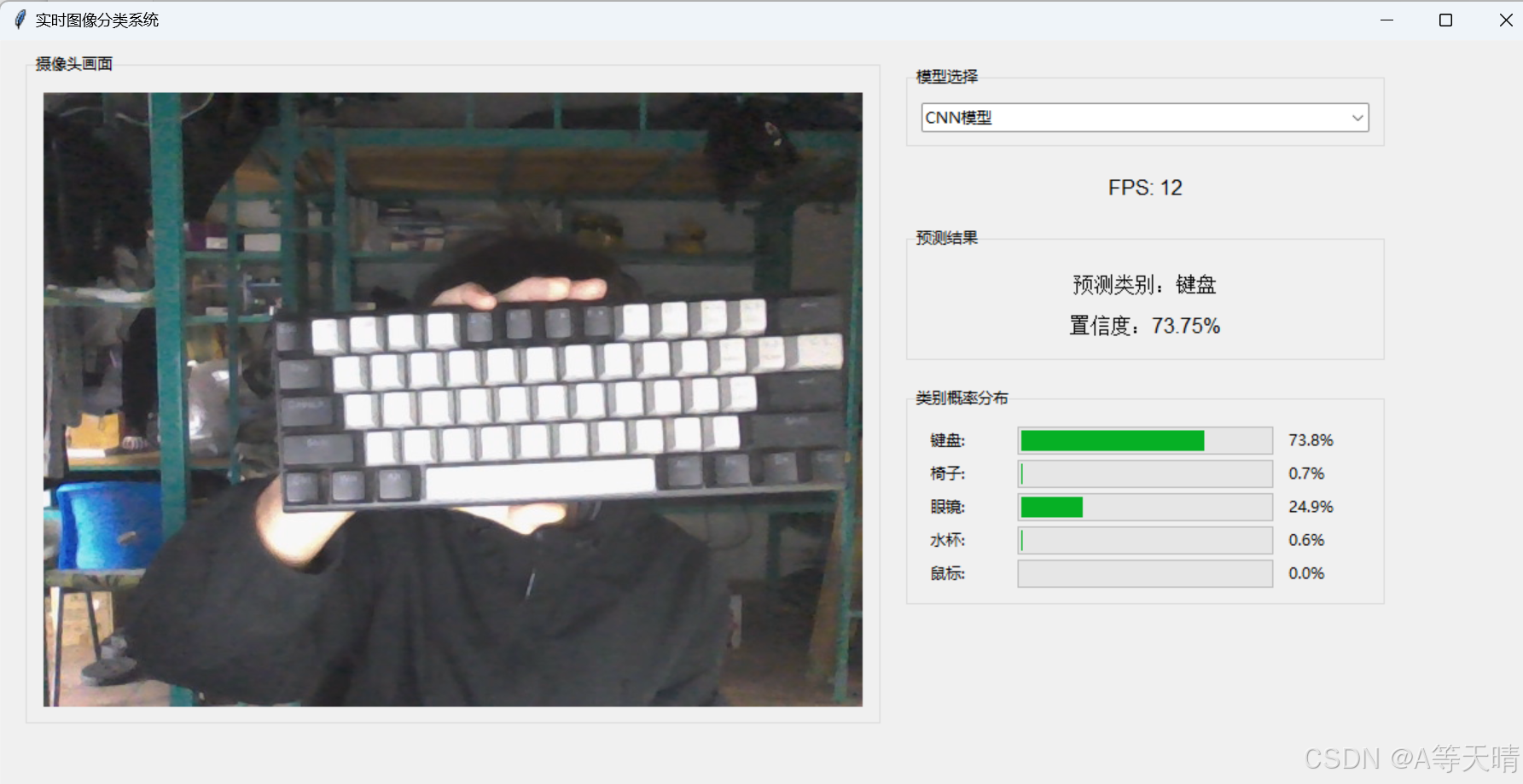
使用CNN模型训练图片识别(键盘,椅子,眼镜,水杯,鼠标)
首先是环境: 我是在Anaconda3中的Jupyter Notebook (tensorflow)中进行训练,环境各位自行安装 数据集: 本次数据集五个类型(键盘,椅子,眼镜,水杯,鼠标)我收集了每个接近两…...
Gitlab 数据备份全攻略:命令、方法与注意事项
文章目录 1、备份命令2、备份目录名称说明3、手工备份配置文件3.1 备份配置文件3.2 备份ssh文件 4、备份注意事项4.1 停止puma和sicdekiq组件4.2 copy策略需要更多磁盘空间 5、数据备份方法5.1 docker命令备份5.2 kubectl命令备份5.3 参数说明5.4、选择性备份5.5、非tar备份5.6…...

Vue|scoped样式
在 Vue.js 中,scoped 是一个非常有用的特性,允许你将样式限制在当前组件的作用域内,避免样式泄漏到其他组件。它是通过 Vue 的单文件组件(.vue 文件)中的 <style> 标签实现的。 目录 案例演示创建多个vue文件如何…...
)
eBPF试一下(TODO)
eBPF程序跟踪linux内核软中断 eBPF (Extended Berkeley Packet Filter) 是一种强大的 Linux 内核技术,最初用于网络数据包过滤,但现在它已经扩展到了多个领域,如性能监控、安全性、跟踪等。eBPF 允许用户在内核中执行代码(以一种安…...
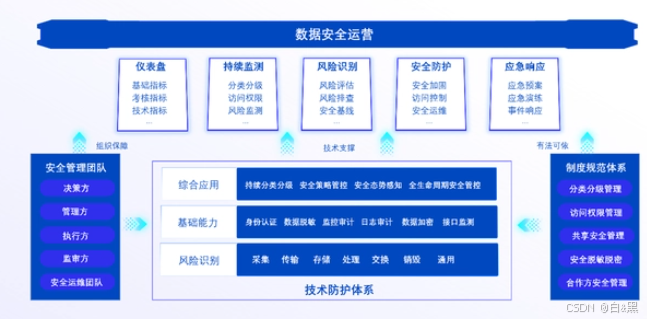
【数据安全】如何保证其安全
数据安全风险 数字经济时代,数据已成为重要的生产要素。智慧城市、智慧政务的建设,正以数据为核心,推动城市管理的智能化和公共服务的优化。然而,公共数据开放共享与隐私保护之间的矛盾日益凸显,如何在确保数据安全的…...

[创业之路-196]:华为成功经验的总结与教训简单总结
目录 前言: 成功经验 教训归纳 前言: 华为作为世界领先的通信设备制造商,其成功经验与教训值得深入探讨。 以下是对华为成功经验的总结与教训的归纳: 成功经验 战略定位明确: 华为始终坚持“死死抓住核心技术”…...

使用 NVIDIA DALI 计算视频的光流
引言 光流(Optical Flow)是计算机视觉中的一种技术,主要用于估计视频中连续帧之间的运动信息。它通过分析像素在时间维度上的移动来预测运动场,广泛应用于目标跟踪、动作识别、视频稳定等领域。 光流的计算传统上依赖 CPU 或 GP…...
【UE5】pmx导入UE5,套动作。(防止“气球人”现象。
参考视频:UE5Animation 16: MMD模型與動作導入 (繁中自動字幕) 问题所在: 做法记录(自用) 1.导入pmx,删除这两个。 2.转换给blender,清理节点。 3.导出时,内嵌贴图,选“复制”。 …...
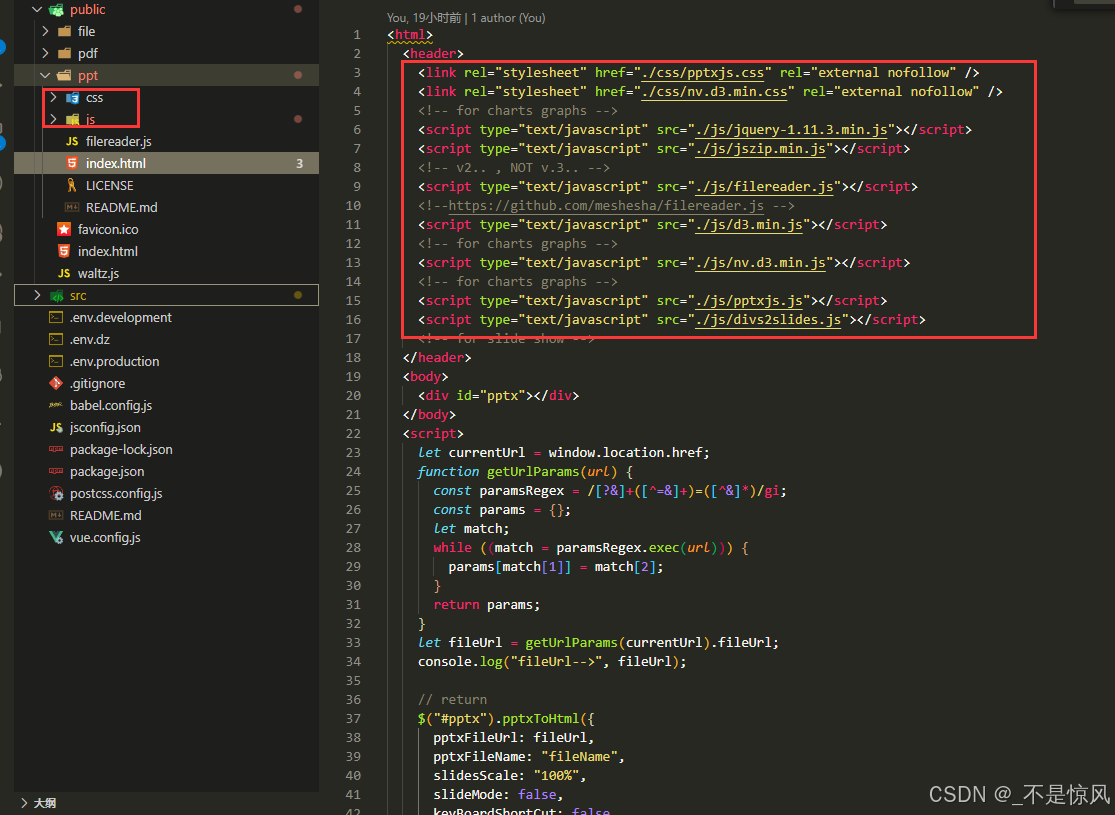
vue预览和下载 pdf、ppt、word、excel文档,文件类型为链接或者base64格式或者文件流,
** 方法1:word、xls、ppt、pdf 这些文件, 如果预览的文件是链接可以直接打开,可用微软官方的预览地址 ** <iframe width"100%" :src"textVisibleURl " id"myFramePPT" style"border: none;backgroun…...

前端如何实现大文件上传
在前端实现大文件上传的主要方法包括分片上传、断点续传、WebSocket上传和通过第三方服务上传。 分片上传:将大文件切割成多个小片段,然后分别上传。可以使用HTML5的File API和Blob对象,通过FileReader读取文件内容,然后使…...

如何评估并持续优化AI呼入机器人的使用效果
如何评估并持续优化AI呼入机器人的使用效果 作者:开源呼叫中心FreeIPCC 随着人工智能技术的快速发展,AI呼入机器人在客户服务、技术支持等多个领域得到了广泛应用。这些智能系统不仅提高了工作效率,降低了运营成本,还显著改善了…...

找不同,找原因
Yes, you can use “by the time I get back to it” instead of “get around to it,” but there’s a slight difference in tone and meaning: • “Get around to it” implies finally finding the time or motivation to do something after delaying or procrastina…...

LFM2.5-1.2B-Thinking-GGUF集成Python爬虫实战:智能数据采集与清洗
LFM2.5-1.2B-Thinking-GGUF集成Python爬虫实战:智能数据采集与清洗 1. 当爬虫遇上大模型:数据采集的新思路 传统爬虫开发就像在迷宫里摸索前行——你需要手动解析每个网站的HTML结构,针对不同反爬机制编写特定规则,还要处理杂乱…...

如何用RecastNavigation构建完整的游戏AI导航系统:从入门到实战
如何用RecastNavigation构建完整的游戏AI导航系统:从入门到实战 【免费下载链接】recastnavigation Navigation-mesh Toolset for Games 项目地址: https://gitcode.com/gh_mirrors/re/recastnavigation 想要为你的游戏打造智能的AI导航系统吗?Re…...

掌握通达信数据接口:量化分析从入门到精通
掌握通达信数据接口:量化分析从入门到精通 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 解决量化数据获取难题:MOOTDX的技术方案与实战应用 如何突破量化分析的数据获取…...
)
保姆级教程:在PX4 1.13.1固件下,从零开始编写一个自定义控制模块(附完整代码)
PX4 1.13.1固件下自定义控制模块开发全流程指南 当你第一次打开PX4的源码目录,面对层层嵌套的文件夹和复杂的编译系统,是否感到无从下手?作为一款开源的无人机飞控系统,PX4的强大之处在于其高度模块化的设计,允许开发者…...

语音识别模型Conformer实战:如何用夹心饼干结构提升ASR效果
Conformer模型实战:用"夹心饼干"架构打造工业级语音识别系统 语音识别技术正在经历从传统DNN-HMM到端到端深度学习的范式转移,而Conformer凭借其创新的"CNNTransformer"混合架构,正在成为新一代ASR系统的标配。这种被开发…...

探索开源字体商用解决方案:思源宋体TTF的多场景应用与价值解析
探索开源字体商用解决方案:思源宋体TTF的多场景应用与价值解析 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 副标题:免费商用授权与多场景适配的专业中文字体…...

比话降AI使用教程:从注册到拿到合格检测报告全流程详解
比话降AI使用教程:从注册到拿到合格检测报告全流程详解 不少同学找到比话降AI,是因为看到了那个承诺:AI率大于15%全额退款,还退检测费。 这个承诺确实不一样。其他工具一般只说"效果不好可重做",但重做了几…...

Go Context 取消信号机制剖析
Go Context 取消信号机制剖析 在Go语言中,Context是控制并发任务生命周期的重要工具,其取消信号机制尤其关键。通过Context,开发者可以优雅地终止协程、释放资源,避免资源泄漏和无效计算。本文将深入剖析Go Context的取消信号机制…...

ssm+java2026年毕设桃花新村社区【源码+论文】
本系统(程序源码)带文档lw万字以上 文末可获取一份本项目的java源码和数据库参考。系统程序文件列表开题报告内容一、选题背景关于新闻资讯管理系统的研究,现有研究主要以传统门户网站的新闻发布系统为主,专门针对中小型组织、企业…...

Kimi-VL-A3B-Thinking开源大模型实操:模型微调适配垂直领域数据
Kimi-VL-A3B-Thinking开源大模型实操:模型微调适配垂直领域数据 1. 引言:为什么你需要关注这个模型? 如果你正在寻找一个既能看懂图片,又能像人一样思考的多模态模型,那么Kimi-VL-A3B-Thinking绝对值得你花时间了解。…...