Hive其一,简介、体系结构和内嵌模式、本地模式的安装
目录
一、Hive简介
二、体系结构
三、安装
1、内嵌模式
2、测试内嵌模式
3、本地模式--最常使用的模式
一、Hive简介
Hive 是一个框架,可以通过编写sql的方式,自动的编译为MR任务的一个工具。
在这个世界上,会写SQL的人远远大于会写java代码的人,所以假如可以将MR通过sql实现,这个将是一个巨大的市场,FaceBook就这么干。(脸书)
FaceBook --> Meta (元宇宙) --> 社交网站(校内网)
在大数据中,发展趋势:所有的技术全部都变为SQL。1、Hive是一个数据仓库工具
2、可以将数据加载到表中,编写sql进行分析
3、底层依赖Hadoop,所以每一次都需要启动hadoop(hdfs以及yarn)
4、Hive的底层计算框架可以使用MR、也可以使用Spark、TEZ
5、Hive不是数据库,而是一个将MR包了一层壳儿。类似于一个中介。Hive官网地址:Apache Hive
GitHub地址: GitHub - apache/hive: Apache Hive
文档查看地址:GettingStarted - Apache Hive - Apache Software Foundation

目前最新的版本稳定版(realease):3.1.2
beta版本正在开发4.0
Hive天然的就是当做数据仓库使用的。什么是数据仓库?
数据仓库:数据的仓库,一般只要能存数据的软件都可以当做数据仓库。
比如:开了一个超市,必须有一个仓库,这个仓库是不是可大可小。以前数据量特别小的时候,一般都使用Oracle当做数据仓库,现在企业中一般都使用大数据技术中 的Hive或者跟Hive类似的技术当做数据仓库。
普通的仓库:一般也是分类的,比如食品区、衣服区、电子产品区
数据仓库:也是需要搭建的(分层),方便使用者从仓库中快速的获取想要的数据。仓库搭建的好不好,就叫做建模。
二、体系结构
注意:
- 包含*的全表查询,比如select * from table 不会生成MapRedcue任务
- 包含*的limit查询,比如select * from table limit 3 不会生成MapRedcue任务

三、安装
分为三种:内嵌模式、本地模式、远程模式
Hive会自动检测Hadoop的环境变量,如有就必须启动Hadoop
将现在的高可用,进行一次快照,将整个集群恢复到高可用之前的状态,方便学习。
1、内嵌模式
上传 压缩包 /opt/modules
解压:
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/installs/
重命名:
mv apache-hive-3.1.2-bin/ hive
配置环境变量:vi /etc/profileexport HIVE_HOME=/opt/installs/hiveexport PATH=$HIVE_HOME/bin:$PATH
刷新环境变量:
source /etc/profile
配置hive-env.sh
进入这个文件夹下:/opt/installs/hive/conf
cp hive-env.sh.template hive-env.sh
修改hive-env.sh 中的内容:
export HIVE_CONF_DIR=/opt/installs/hive/conf
export JAVA_HOME=/opt/installs/jdk
export HADOOP_HOME=/opt/installs/hadoop
export HIVE_AUX_JARS_PATH=/opt/installs/hive/lib进入到conf 文件夹下,修改这个文件hive-site.xml
cp hive-default.xml.template hive-site.xml
接着开始修改:
把Hive-site.xml 中所有包含${system:java.io.tmpdir}替换成/opt/installs/hive/tmp。如果系统默认没有指定系统用户名,那么要把配置${system:user.name}替换成当前用户名root。使用nodepad++,打开该文件,进行替换:
一个替换了4处

一个替换了3处

启动集群:
start-all.sh给hdfs创建文件夹:
[root@yunhe01 conf] # hdfs dfs -mkdir -p /user/hive/warehouse
[root@yunhe01 conf] # hdfs dfs -mkdir -p /tmp/hive/
[root@yunhe01 conf] # hdfs dfs -chmod 750 /user/hive/warehouse
[root@yunhe01 conf] # hdfs dfs -chmod 777 /tmp/hive初始化元数据,因为是内嵌模式,所以使用的数据库是derby
schematool --initSchema -dbType derby在hive-site.xml中,3215行,96列的地方有一个非法字符


将这个非法字符,删除,保存即可。
需要再次进行元数据的初始化操作:
schematool --initSchema -dbType derby提示初始化成功!
初始化操作要在hive的家目录执行,执行完毕之后,会出现一个文件夹:

测试是否成功:
输入hive 进入后,可以编写sql
hive> show databases;
OK
default2、测试内嵌模式
-- 进入后可以执行下面命令进行操作:
hive>show databases; -- 查看数据库
hive>show tables; -- 查看表
-- 创建表
hive> create table dog(id int,name string);
hive> select * from dog;
hive> insert into dog values(1,'wangcai');
hive> desc dog; -- 查看表结构
hive> quit; -- 退出但是内嵌模式有一个弊端:假如有一个窗口在使用你的hive,另一个窗口能进入,但是会报错!

3、本地模式--最常使用的模式
使用本地模式的最大特点是:将元数据从derby数据库,变为mysql数据库,并且支持多窗口同时使用。

第一步:检查你的mysql是否正常
systemctl status mysqld第二步:删除以前的derby数据
进入到hive中,删除
rm -rf metastore_db/ derby.log第三步:修改配置文件 hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--Licensed to the Apache Software Foundation (ASF) under one or morecontributor license agreements. See the NOTICE file distributed withthis work for additional information regarding copyright ownership.The ASF licenses this file to You under the Apache License, Version 2.0(the "License"); you may not use this file except in compliance withthe License. You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License.
--><configuration><!--配置MySql的连接字符串-->
<property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value><description>JDBC connect string for a JDBC metastore</description>
</property>
<!--配置MySql的连接驱动-->
<property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value><description>Driver class name for a JDBC metastore</description>
</property>
<!--配置登录MySql的用户-->
<property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>username to use against metastore database</description>
</property>
<!--配置登录MySql的密码-->
<property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value><description>password to use against metastore database</description>
</property>
<!-- 以下两个不需要修改,只需要了解即可 -->
<!-- 该参数主要指定Hive的数据存储目录 -->
<property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property>
<!-- 该参数主要指定Hive的临时文件存储目录 --><property><name>hive.exec.scratchdir</name><value>/tmp/hive</value></property></configuration>将mysql的驱动包,上传至 hive 的lib 文件夹下
初始化元数据(本质就是在mysql中创建数据库,并且添加元数据)
schematool --initSchema -dbType mysql测试:同时打开两个窗口都可以使用, 支持多个会话。
create database mydb01;
use mydb01;create table stu (id int,name string);insert 语句 走MR任务
insert into stu values(1,'wangcai');
select * from stu;
select * from stu limit 10;
不走MR任务。
创建表的时候,varchar类型需要指定字符长度,否则报错!相关文章:
Hive其一,简介、体系结构和内嵌模式、本地模式的安装
目录 一、Hive简介 二、体系结构 三、安装 1、内嵌模式 2、测试内嵌模式 3、本地模式--最常使用的模式 一、Hive简介 Hive 是一个框架,可以通过编写sql的方式,自动的编译为MR任务的一个工具。 在这个世界上,会写SQL的人远远大于会写ja…...
LSTM-SVM时序预测 | Matlab基于LSTM-SVM基于长短期记忆神经网络-支持向量机时间序列预测
LSTM-SVM时序预测 | Matlab基于LSTM-SVM基于长短期记忆神经网络-支持向量机时间序列预测 目录 LSTM-SVM时序预测 | Matlab基于LSTM-SVM基于长短期记忆神经网络-支持向量机时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.LSTM-SVM时序预测 | Matlab基于LSTM…...

MacPorts 中安装高/低版本软件方式,以 RabbitMQ 为例
查询信息 这里以 RabbitMQ 为例,通过搜索得到默认安装版本信息: port search rabbitmq-server结果 ~/Downloads> port search rabbitmq-server rabbitmq-server 3.11.15 (net)The RabbitMQ AMQP Server ~/Downloads>获取二进制文件 但当前官网…...
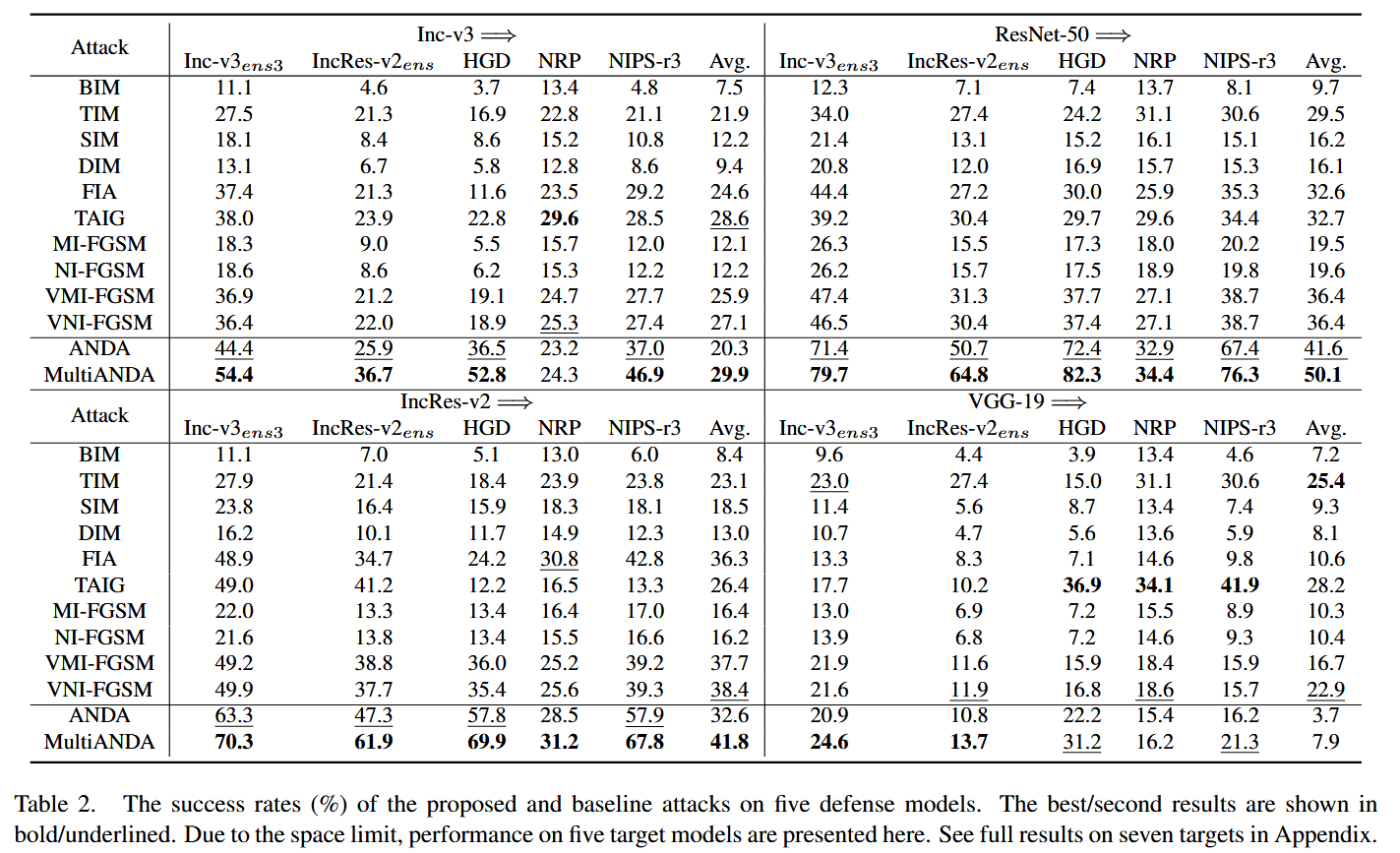
CVPR2024 | 通过集成渐近正态分布学习实现强可迁移对抗攻击
Strong Transferable Adversarial Attacks via Ensembled Asymptotically Normal Distribution Learning 摘要-Abstract引言-Introduction相关工作及前期准备-Related Work and Preliminaries1. 黑盒对抗攻击2. SGD的渐近正态性 提出的方法-Proposed Method随机 BIM 的渐近正态…...

建投数据与腾讯云数据库TDSQL完成产品兼容性互认证
近日,经与腾讯云联合测试,建投数据自主研发的人力资源信息管理系统V3.0、招聘管理系统V3.0、绩效管理系统V2.0、培训管理系统V3.0通过腾讯云数据库TDSQL的技术认证,符合腾讯企业标准的要求,产品兼容性良好,性能卓越。 …...

群晖利用acme.sh自动申请证书并且自动重载证书的问题解决
前言 21年的时候写了一个在群晖(黑群晖)下利用acme.sh自动申请Let‘s Encrypt的脚本工具 群晖使用acme自动申请Let‘s Encrypt证书脚本,自动申请虽然解决了,但是自动重载一直是一个问题,本人也懒,一想到去…...

质量小议51 - 茧房
茧房:茧房是指蚕茧所建的住所或空间,由一个蚕丝囊完全包裹住的一个密封的空间。 -- CSDN创作助手 信息茧房 - 指通过互联网和数字技术,将个人封闭在一个虚拟的信息环境中,使其只接收来自特定渠道的信息,而屏蔽其他信息…...

【C++图论】2359. 找到离给定两个节点最近的节点|1714
本文涉及知识点 C图论 打开打包代码的方法兼述单元测试 LeetCode2359. 找到离给定两个节点最近的节点 给你一个 n 个节点的 有向图 ,节点编号为 0 到 n - 1 ,每个节点 至多 有一条出边。 有向图用大小为 n 下标从 0 开始的数组 edges 表示,…...

重拾设计模式-外观模式和适配器模式的异同
文章目录 目的不同适配器模式:外观模式: 结构和实现方式不同适配器模式:外观模式: 对客户端的影响不同适配器模式:外观模式: 目的不同 适配器模式: 主要目的是解决两个接口不兼容的问题&#…...

51c自动驾驶~合集42
我自己的原文哦~ https://blog.51cto.com/whaosoft/12888355 #DriveMM 六大数据集全部SOTA!最新DriveMM:自动驾驶一体化多模态大模型(美团&中山大学) 近年来,视觉-语言数据和模型在自动驾驶领域引起了广泛关注…...

34 Opencv 自定义角点检测
文章目录 cornerEigenValsAndVecscornerMinEigenVal示例 cornerEigenValsAndVecs void cornerEigenValsAndVecs(InputArray src, --单通道输入8位或浮点图像OutputArray dst, --输出图像,同源图像或CV_32FC(6)int blockSize, --邻域大小值int ape…...

信创技术栈发展现状与展望:机遇与挑战并存
一、引言 在信息技术应用创新(信创)战略稳步推进的大背景下,我国信创技术栈已然在诸多关键层面收获了亮眼成果,不过也无可避免地遭遇了一系列亟待攻克的挑战。信创产业作为我国达成信息技术自主可控这一目标的关键一招,…...

跟我学c++中级篇——C++中的缓存利用
一、缓存 学习过计算机知识的一般都知道缓存这个概念,大约也知道缓存是什么。但是如果是程序员,如何更好的利用缓存,可能就有很多人不太清楚了。其实缓存的目的非常简单,就是了更高效的操作数据。大家都听说过“局部性原理”&…...

二叉树_堆
目录 一. 树(非线性结构) 1.1 树的概念与结构 1.2 树的表示 二. 二叉树 2.1 二叉树的概念与结构 2.2 特殊的二叉树 2.3 二叉树的存储结构 三. 实现顺序结构的二叉树 3.1 堆的概念与结构 一. 树(非线性结构) 1.1 树的概念与结构 概念ÿ…...

word文档中有大量空白行删除不掉,怎么办?
现象: 分页之间的空白行太多了( 按回车没用。删除也删除不掉 ) 解决办法: 按ctrl a 全选这个文档右击鼠标,点击【段落】选择【换行和分页】,然后把【分页】里的选项全部勾掉,然后点击【确定】…...

python rabbitmq实现简单/持久/广播/组播/topic/rpc消息异步发送可配置Django
windows首先安装rabbitmq 点击参考安装 1、环境介绍 Python 3.10.16 其他通过pip安装的版本(Django、pika、celery这几个必须要有最好版本一致) amqp 5.3.1 asgiref 3.8.1 async-timeout 5.0.1 billiard 4.2.1 celery 5.4.0 …...

构建高性能异步任务引擎:FastAPI + Celery + Redis
在现代应用开发中,异步任务处理是一个常见的需求。无论是数据处理、图像生成,还是复杂的计算任务,异步执行都能显著提升系统的响应速度和吞吐量。今天,我们将通过一个实际项目,探索如何使用 FastAPI、Celery 和 Redis …...

永磁同步电机无速度算法--全阶滑模观测器
一、原理介绍 在采用传统滑模观测器求取电机角度时通常存在系统抖振、低通滤波器导致角度相位滞后、角度的求取等问题。针对上述问题,本文采用全阶滑模观测器,该全阶滑模观测器具有二阶低通滤波器的特性,能有效滤除反电动势中的高频噪声&…...

部署开源大模型的硬件配置全面指南
目录 第一章:理解大型模型的硬件需求 1.1 模型部署需求分析 第二章:GPU资源平台 2.1 免费GPU资源 2.1.1 阿里云人工智能PAI 2.1.2 阿里天池实验室 2.1.3 Kaggle 2.1.4 Google Colab 2.2 付费GPU服务 2.2.1 AutoDL 2.2.2 Gpushare Cloud 2.2.3 Featurize 2.2.4 A…...

三、使用langchain搭建RAG:金融问答机器人--检索增强生成
经过前面2节数据准备后,现在来构建检索 加载向量数据库 from langchain.vectorstores import Chroma from langchain_huggingface import HuggingFaceEmbeddings import os# 定义 Embeddings embeddings HuggingFaceEmbeddings(model_name"m3e-base")#…...

Qwen2.5-7B微调保姆级教程:单卡十分钟快速上手,小白也能搞定
Qwen2.5-7B微调保姆级教程:单卡十分钟快速上手,小白也能搞定 1. 前言:为什么选择Qwen2.5-7B进行微调 大模型微调听起来很高深?其实没那么复杂。今天我要带大家用最简单的方式,在单张显卡上10分钟内完成Qwen2.5-7B模型…...

高级CMB2技巧:可重复字段组和动态条件显示
高级CMB2技巧:可重复字段组和动态条件显示 【免费下载链接】CMB2 CMB2 is a developers toolkit for building metaboxes, custom fields, and forms for WordPress that will blow your mind. 项目地址: https://gitcode.com/gh_mirrors/cm/CMB2 CMB2是Word…...

Python 3.14 JIT编译器性能调优,深度解析_pyltopt.c中6处可调优位点与GCC/Clang后端适配策略
第一章:Python 3.14 JIT编译器性能调优概览Python 3.14 引入了实验性内置 JIT(Just-In-Time)编译器,基于 LLVM 后端实现,旨在对热点函数进行动态编译优化,显著提升数值计算、循环密集型及递归场景的执行效率…...
)
Python打包神器大PK:Nuitka vs PyInstaller,谁才是你的菜?(附实测数据)
Python打包工具深度评测:Nuitka与PyInstaller的终极对决 当开发者需要将Python项目分发给没有Python环境的用户时,打包工具的选择往往成为关键决策。本文将深入分析两大主流工具Nuitka和PyInstaller在多个维度的表现,帮助开发者根据项目需求做…...

Rust Web开发:ActixWeb实战指南
1. 为什么选择ActixWeb进行Rust Web开发 我第一次接触ActixWeb是在三年前的一个电商项目里,当时团队需要处理每秒上万次的库存查询请求。测试了多个Rust框架后,ActixWeb凭借其卓越的性能表现脱颖而出——在同等硬件条件下,它的QPS(…...
)
LeetCode Hot 100 | 滑动窗口专题(C++ 题解)
LeetCode Hot 100 | 滑动窗口专题(C 题解) 滑动窗口是处理连续子数组/子字符串问题的核心技巧,通过维护一个可变窗口来避免重复计算,将 O(n) 的暴力枚举优化到 O(n)。本文涵盖 LeetCode Hot 100 中 2 道经典滑动窗口题目ÿ…...

运算放大器与比较器的本质区别及应用指南
1. 运算放大器与比较器的本质区别在电子电路设计中,运算放大器(Op-Amp)和电压比较器(Comparator)是两种极为常见却又经常被混淆的器件。它们在外观符号上几乎一模一样:都有五个引脚——正负电源端、同相与反…...

Nacos服务实例权重设置详解:如何根据服务器性能动态调整流量分配
Nacos服务实例权重设置详解:如何根据服务器性能动态调整流量分配 在分布式系统架构中,服务实例的性能差异是不可避免的现实问题。新采购的服务器与运行多年的老旧设备并存,不同配置的云主机混合部署,这些场景都要求我们能够智能地…...
)
新手避坑指南:从GEO数据库下载单细胞测序数据的5个关键步骤(附实操截图)
单细胞测序数据下载实战:5个避坑技巧与决策逻辑 第一次打开GEO数据库时,满屏的测序数据就像走进了一个没有地图的迷宫。作为刚接触单细胞转录组分析的研究生,我花了整整两周时间才搞明白哪些数据值得下载——期间踩过的坑包括下载了样本命名混…...

7大维度测评:2023年开源付费墙绕过工具终极选择指南
7大维度测评:2023年开源付费墙绕过工具终极选择指南 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在数字内容访问需求日益增长的今天,选择一款高效可靠的开源…...