深度学习之目标检测——RCNN
Selective Search
-
背景:事先不知道需要检测哪个类别,且候选目标存在层级关系与尺度关系
-
常规解决方法:穷举法·,在原始图片上进行不同尺度不同大小的滑窗,获取每个可能的位置
- 弊端:计算量大,且尺度不能兼顾
-
Selective Search:通过视觉特征减少分类可能性

-
算法步骤
- 基于图的图像分割方法初始化区域(图像分割为很多很多小块)
- 循环
- 使用贪心策略计算相邻区域相似度,每次合并相似的两块
- 直到剩下一块
- 结束
-
如何保证特征多样性
-
颜色空间变换,RGB,i,Lab,HSV,
-
距离计算方式
-
颜色距离

- 计算每个通道直方图
- 取每个对应bins的直方图最小值
- 直方图大小加权区域/总区域
-
纹理距离

- 计算每个区域的快速sift特征(方向个数为8)
- 每个通道bins为2
- 其他用颜色距离
-
优先合并小区域
- 单纯通过颜色和纹理合并
- 合并区域会不断吞并,造成多尺度应用在局部问题上,无法全局多尺度
- 解决方法:给小区域更多权重
- 单纯通过颜色和纹理合并
-
.区域的合适度度距离
- 除了考虑每个区域特征的吻合程度,还要考虑区域吻合度(合并后的区域尽量规范,不能出现断崖式的区域)
- 直接需求就是区域的外接矩形的重合面积要大

-
加权综合衡量距离
-
给予各种距离整合一些区域建议,加权综合考虑

-
-
参数初始化多样性
- 通过多种参数初始化图像分割
-
区域打分
-
-
-
-
代码实现
# -*- coding: utf-8 -*-
from __future__ import divisionimport cv2 as cv
import skimage.io
import skimage.feature
import skimage.color
import skimage.transform
import skimage.util
import skimage.segmentation
import numpy# "Selective Search for Object Recognition" by J.R.R. Uijlings et al.
#
# - Modified version with LBP extractor for texture vectorizationdef _generate_segments(im_orig, scale, sigma, min_size):"""segment smallest regions by the algorithm of Felzenswalb andHuttenlocher"""# open the Imageim_mask = skimage.segmentation.felzenszwalb(skimage.util.img_as_float(im_orig), scale=scale, sigma=sigma,min_size=min_size)# merge mask channel to the image as a 4th channelim_orig = numpy.append(im_orig, numpy.zeros(im_orig.shape[:2])[:, :, numpy.newaxis], axis=2)im_orig[:, :, 3] = im_maskreturn im_origdef _sim_colour(r1, r2):"""calculate the sum of histogram intersection of colour"""return sum([min(a, b) for a, b in zip(r1["hist_c"], r2["hist_c"])])def _sim_texture(r1, r2):"""calculate the sum of histogram intersection of texture"""return sum([min(a, b) for a, b in zip(r1["hist_t"], r2["hist_t"])])def _sim_size(r1, r2, imsize):"""calculate the size similarity over the image"""return 1.0 - (r1["size"] + r2["size"]) / imsizedef _sim_fill(r1, r2, imsize):"""calculate the fill similarity over the image"""bbsize = ((max(r1["max_x"], r2["max_x"]) - min(r1["min_x"], r2["min_x"]))* (max(r1["max_y"], r2["max_y"]) - min(r1["min_y"], r2["min_y"])))return 1.0 - (bbsize - r1["size"] - r2["size"]) / imsizedef _calc_sim(r1, r2, imsize):return (_sim_colour(r1, r2) + _sim_texture(r1, r2)+ _sim_size(r1, r2, imsize) + _sim_fill(r1, r2, imsize))def _calc_colour_hist(img):"""calculate colour histogram for each regionthe size of output histogram will be BINS * COLOUR_CHANNELS(3)number of bins is 25 as same as [uijlings_ijcv2013_draft.pdf]extract HSV"""BINS = 25hist = numpy.array([])for colour_channel in (0, 1, 2):# extracting one colour channelc = img[:, colour_channel]# calculate histogram for each colour and join to the resulthist = numpy.concatenate([hist] + [numpy.histogram(c, BINS, (0.0, 255.0))[0]])# L1 normalizehist = hist / len(img)return histdef _calc_texture_gradient(img):"""calculate texture gradient for entire imageThe original SelectiveSearch algorithm proposed Gaussian derivativefor 8 orientations, but we use LBP instead.output will be [height(*)][width(*)]"""ret = numpy.zeros((img.shape[0], img.shape[1], img.shape[2]))for colour_channel in (0, 1, 2):ret[:, :, colour_channel] = skimage.feature.local_binary_pattern(img[:, :, colour_channel], 8, 1.0)# LBP特征return retdef _calc_texture_hist(img):"""calculate texture histogram for each regioncalculate the histogram of gradient for each coloursthe size of output histogram will beBINS * ORIENTATIONS * COLOUR_CHANNELS(3)"""BINS = 10hist = numpy.array([])for colour_channel in (0, 1, 2):# mask by the colour channelfd = img[:, colour_channel]# calculate histogram for each orientation and concatenate them all# and join to the resulthist = numpy.concatenate([hist] + [numpy.histogram(fd, BINS, (0.0, 1.0))[0]])# L1 Normalizehist = hist / len(img)return histdef _extract_regions(img):R = {}# get hsv imagehsv = skimage.color.rgb2hsv(img[:, :, :3])# pass 1: count pixel positionsfor y, i in enumerate(img):for x, (r, g, b, l) in enumerate(i):# initialize a new regionif l not in R:R[l] = {"min_x": 0xffff, "min_y": 0xffff,"max_x": 0, "max_y": 0, "labels": [l]}# bounding boxif R[l]["min_x"] > x:R[l]["min_x"] = xif R[l]["min_y"] > y:R[l]["min_y"] = yif R[l]["max_x"] < x:R[l]["max_x"] = xif R[l]["max_y"] < y:R[l]["max_y"] = y# pass 2: calculate texture gradienttex_grad = _calc_texture_gradient(img)# pass 3: calculate colour histogram of each regionfor k, v in list(R.items()):# colour histogrammasked_pixels = hsv[:, :, :][img[:, :, 3] == k]R[k]["size"] = len(masked_pixels / 4)R[k]["hist_c"] = _calc_colour_hist(masked_pixels)# texture histogramR[k]["hist_t"] = _calc_texture_hist(tex_grad[:, :][img[:, :, 3] == k])return Rdef _extract_neighbours(regions):def intersect(a, b):if (a["min_x"] < b["min_x"] < a["max_x"]and a["min_y"] < b["min_y"] < a["max_y"]) or (a["min_x"] < b["max_x"] < a["max_x"]and a["min_y"] < b["max_y"] < a["max_y"]) or (a["min_x"] < b["min_x"] < a["max_x"]and a["min_y"] < b["max_y"] < a["max_y"]) or (a["min_x"] < b["max_x"] < a["max_x"]and a["min_y"] < b["min_y"] < a["max_y"]):return Truereturn FalseR = list(regions.items())neighbours = []for cur, a in enumerate(R[:-1]):for b in R[cur + 1:]:if intersect(a[1], b[1]):neighbours.append((a, b))return neighboursdef _merge_regions(r1, r2):new_size = r1["size"] + r2["size"]rt = {"min_x": min(r1["min_x"], r2["min_x"]),"min_y": min(r1["min_y"], r2["min_y"]),"max_x": max(r1["max_x"], r2["max_x"]),"max_y": max(r1["max_y"], r2["max_y"]),"size": new_size,"hist_c": (r1["hist_c"] * r1["size"] + r2["hist_c"] * r2["size"]) / new_size,"hist_t": (r1["hist_t"] * r1["size"] + r2["hist_t"] * r2["size"]) / new_size,"labels": r1["labels"] + r2["labels"]}return rtdef selective_search(im_orig, scale=1.0, sigma=0.8, min_size=50):'''Selective SearchParameters----------im_orig : ndarrayInput imagescale : intFree parameter. Higher means larger clusters in felzenszwalb segmentation.sigma : floatWidth of Gaussian kernel for felzenszwalb segmentation.min_size : intMinimum component size for felzenszwalb segmentation.Returns-------img : ndarrayimage with region labelregion label is stored in the 4th value of each pixel [r,g,b,(region)]regions : array of dict[{'rect': (left, top, width, height),'labels': [...],'size': component_size},...]'''# 期待输入3通道图片assert im_orig.shape[2] == 3, "3ch image is expected"# load image and get smallest regions# region label is stored in the 4th value of each pixel [r,g,b,(region)]# 基于图方法生成图的最小区域,img = _generate_segments(im_orig, scale, sigma, min_size)# (512, 512, 4)# print(img.shape)# cv2.imshow("res1", im_orig)# print(type(img))# # img = cv2.cvtColor(img,cv2.COLOR_RGB2BGR)# cv2.imshow("res",img)# cv2.waitKey(0)# # print(img)# exit()if img is None:return None, {}imsize = img.shape[0] * img.shape[1]# 拓展区域R = _extract_regions(img)# extract neighbouring informationneighbours = _extract_neighbours(R)# calculate initial similaritiesS = {}for (ai, ar), (bi, br) in neighbours:S[(ai, bi)] = _calc_sim(ar, br, imsize)# hierarchal searchwhile S != {}:# get highest similarityi, j = sorted(S.items(), key=lambda i: i[1])[-1][0]# merge corresponding regionst = max(R.keys()) + 1.0R[t] = _merge_regions(R[i], R[j])# mark similarities for regions to be removedkey_to_delete = []for k, v in list(S.items()):if (i in k) or (j in k):key_to_delete.append(k)# remove old similarities of related regionsfor k in key_to_delete:del S[k]# calculate similarity set with the new regionfor k in [a for a in key_to_delete if a != (i, j)]:n = k[1] if k[0] in (i, j) else k[0]S[(t, n)] = _calc_sim(R[t], R[n], imsize)regions = []for k, r in list(R.items()):regions.append({'rect': (r['min_x'], r['min_y'],r['max_x'] - r['min_x'], r['max_y'] - r['min_y']),'size': r['size'],'labels': r['labels']})return img, regions
- 测试
# -*- coding: utf-8 -*-
from __future__ import (division,print_function,
)
import cv2 as cvimport skimage.data
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import selectivesearchdef main():# loading astronaut imageimg = skimage.data.astronaut()# print(type(img))# img = cv.cvtColor(img,cv.COLOR_RGB2BGR)# cv.imshow("res",img)# cv.waitKey(0)# # print(img)# exit()# perform selective searchimg_lbl, regions = selectivesearch.selective_search(img, scale=500, sigma=0.9, min_size=10)candidates = set()for r in regions:# excluding same rectangle (with different segments)if r['rect'] in candidates:continue# excluding regions smaller than 2000 pixelsif r['size'] < 2000:continue# distorted rectsx, y, w, h = r['rect']if w / h > 1.2 or h / w > 1.2:continuecandidates.add(r['rect'])# draw rectangles on the original imagefig, ax = plt.subplots(ncols=1, nrows=1, figsize=(6, 6))ax.imshow(img)for x, y, w, h in candidates:print(x, y, w, h)rect = mpatches.Rectangle((x, y), w, h, fill=False, edgecolor='red', linewidth=1)ax.add_patch(rect)plt.show()if __name__ == "__main__":main()-
测试结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wzyOzF2v-1629643779520)(C:\Users\SWPUCWF\AppData\Roaming\Typora\typora-user-images\image-20210822203355879.png)]](https://i-blog.csdnimg.cn/blog_migrate/bc06927aae328797fad142bf285a5dc2.png)
RCNN
算法步骤
-
产生目标区域候选
-
CNN目标特征提取
- 使用的AlexNet
- imageNet预训练迁移学习,只训练全连接层
- 采用的全连接层输出(导致输入大小必须固定)
-
目标种类分类器
-
SVM困难样本挖掘方法,正样本—>正样本 ,iou>0.3 == 负样本
-
贪婪非极大值抑制 NMS
-
根据分类器的类别分类概率做排序,假设从小到大属于正样本的概率 分别为A、B、C、D、E、F。
-
从最大概率矩形框F开始,分别判断A~E与F的重叠度IOU是否大于某个设定的阈值
-
假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
-
从剩下的矩形框A、C、E中,选择概率最大的E,然后判断E与A、C的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
就这样一直重复,找到所有被保留下来的矩形框。
-
-
BoundingBox回归
-
微调回归框
-
一个区域位置
-

-
位置映射真实位置

-
转换偏移量参数

-
映射关系式

-
选用pool5层

-
最小化w

-
-
-
不使用全连接的输出作为非极大抑制的输入,而是训练很多的SVM。
-
因为CNN需要大量的样本,当正样本设置为真实BoundingBox时效果很差,而IOU>0.5相当于30倍的扩充了样本数量。而我们近将CNN结果作为一个初选,然后用困难负样本挖掘的SVM作为第二次筛选就好多了
-
缺点:时间代价太高了
相关文章:
深度学习之目标检测——RCNN
Selective Search 背景:事先不知道需要检测哪个类别,且候选目标存在层级关系与尺度关系 常规解决方法:穷举法,在原始图片上进行不同尺度不同大小的滑窗,获取每个可能的位置 弊端:计算量大,且尺度不能兼顾 Selective …...
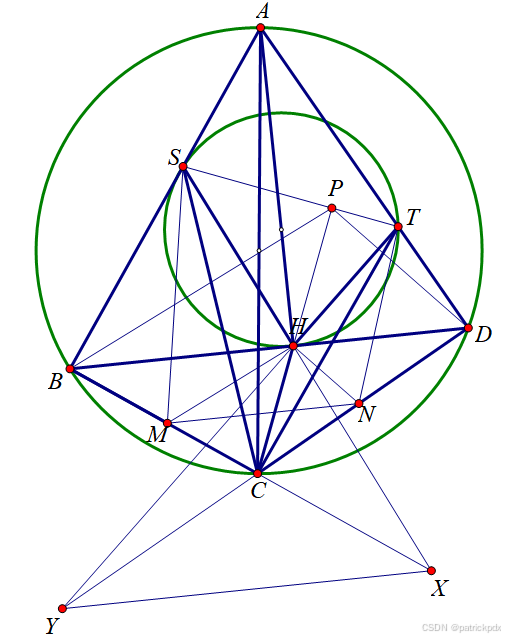
2014年IMO第3题
在凸四边形 A B C D ABCD ABCD 中, ∠ A B C = ∠ A D C = π 2 \angle ABC=\angle ADC=\frac{\pi}{2} ∠ABC=∠ADC=2π, H H H 为 A A A 在 B D BD BD 上的投影, 在边 A B AB AB 上有一点 S S S, ∠ C H S − ∠ C S B = π 2 \angle CHS-\angle CSB=\frac{\pi}{2} …...

国高材服务 | 高分子结晶动力学表征——高低温热台偏光显微镜
众所周知,聚合物制品的实际使用性能(如光学透明性、硬度、模量等)与材料内部的结晶形态、晶粒大小及完善程度有着密切的联系,因此,对聚合物结晶形态等的研究具有重要的理论和实际意义。 随着结晶条件的不用,…...

跨站请求伪造之基本介绍
一.基本概念 1.定义 跨站请求伪造(Cross - Site Request Forgery,缩写为 CSRF)漏洞是一种网络安全漏洞。它是指攻击者通过诱导用户访问一个恶意网站,利用用户在被信任网站(如银行网站、社交网站等)的登录状…...

Hadoop集群(HDFS集群、YARN集群、MapReduce计算框架)
一、 简介 Hadoop主要在分布式环境下集群机器,获取海量数据的处理能力,实现分布式集群下的大数据存储和计算。 其中三大核心组件: HDFS存储分布式文件存储、YARN分布式资源管理、MapReduce分布式计算。 二、工作原理 2.1 HDFS集群 Web访问地址&…...
经验总结(gtest+gmock))
单元测试(UT,C++版)经验总结(gtest+gmock)
最近做了一段测试工作,其中包括单元测试,编程语言是C。这里提供一些基本知识总结,方便入门单元测试。 1.单元测试介绍 单元测试(Unit Testing, 简称UT)是软件测试的一种方法,目的是通过对单个软件组件&am…...
)
Mysql高级部分总结(二)
MySQL的内部日志 binlog记载的是update/delete/insert这样的SQL语句,而redo log记载的是物理修改的内容(xxxx页修改了xxx)。 binlog无论MySQL用什么引擎,都会有,而redo log是MySQL的InnoDB引擎所产生的。 redo log事务开始的时候,就开始记录每次的变更信息,而binlog是在…...

纠正一下网络管理
先找到那个hrStorageType 这里我的值是 后面的值.1.3.6.1.2.1.25.2.1.4代表磁盘 我只有2个盘 C盘和D盘 所以这里只有2个 你们有E盘F盘的话 这里会多 .1.3.6.1.2.1.25.2.1.2 代表内存 .1.3.6.1.2.1.25.2.1.2 前面是 hrStorageType.4 所以 这里面.4后缀是表示内存的 之前…...

homebrew,gem,cocoapod 换源,以及安装依赖
安装homebrew /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" 再按照成功提示配置环境变量 ruby 更新ruby到最新 brew install ruby 如果安装了会自动升级 安装完成后根据提示配置环境变量 再执行命令使其生效 s…...

Java字符串的|分隔符转List实现方案
字符串处理 问题背景代码实现代码优化原因分析实现方案 注意事项异常处理Maven未识别异常 问题背景 在项目组对账流程中,接收对方系统的对账文件,数据以|为分隔符,读取文件内容,分条入库。 代码实现 Java中将字符串转给list&am…...

Kafka可视化工具 Offset Explorer (以前叫Kafka Tool)
数据的存储是基于 主题(Topic) 和 分区(Partition) 的 Kafka是一个高可靠性的分布式消息系统,广泛应用于大规模数据处理和实时, 为了更方便地管理和监控Kafka集群,开发人员和运维人员经常需要使用可视化工具…...
DeepWalk 原理详解
概述: DeepWalk 是一种流行的图嵌入方法,用于学习图结构数据中节点的低维表示。它通过将图的节点视作序列数据,利用自然语言处理中的技术(类似于word2vec算法)来捕捉节点间的关系,可以帮助我们理解和利用图…...

GitLab安装|备份数据|迁移数据及使用教程
作者: 宋发元 最后更新时间:2024-12-24 GitLab安装及使用教程 官方教程 https://docs.gitlab.com/ee/install/docker.html Docker安装GitLab 宿主机创建容器持久化目录卷 mkdir -p /docker/gitlab/{config,data,logs}拉取GitLab镜像 docker pull gi…...
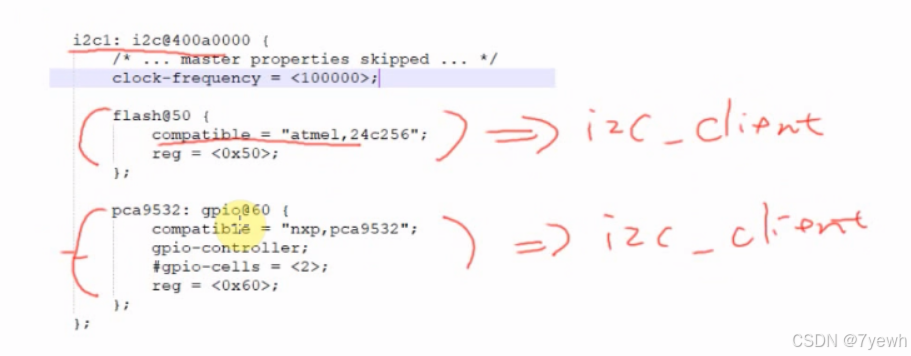
嵌入式linux驱动框架 I2C系统驱动程序模型分析
引言:在嵌入式 Linux 系统中,I2C(Inter-Integrated Circuit)是一种常用的通信协议,用于连接低速设备(如传感器、显示器、存储器等)与主控制器。I2C 系统驱动程序模型通过层次化的设计࿰…...

深度学习实验十七 优化算法比较
目录 一、优化算法的实验设定 1.1 2D可视化实验(被优化函数为) 1.2 简单拟合实验 二、学习率调整 2.1 AdaGrad算法 2.2 RMSprop算法 三、梯度修正估计 3.1 动量法 3.2 Adam算法 四、被优化函数变为的2D可视化 五、不同优化器的3D可视化对比 …...

一个双非选手的秋招总结
个人bg介绍 25届双非本硕(非杭电深大,垫底双非),两段实习经历,本科没学过Java,有c语言和408基础;2023年10月份中途转语言,Java速成选手。 战绩总结:实习秋招面试总论次…...

如何提高永磁电动机的节电效果
在现代工业和家庭应用中,永磁电动机因其优越的性能和节能特性,逐渐成为主流选择。随着能源日益紧缺和环境问题的日益严重,寻求高效的电动机节能方案显得尤为重要。 一、永磁电动机的基本原理 永磁电动机的核心是永磁体,这些永磁…...

在一个服务器上抓取 Docker 镜像并在另一个服务器上运行
要在一个服务器上抓取 Docker 镜像并在另一个服务器上运行,您可以按照以下步骤进行操作: 1. 保存 Docker 镜像 在源服务器上,您可以使用 docker save 命令将 Docker 镜像保存为一个 tar 文件。例如,如果您的镜像名称是 face_det…...

开源轮子 - Logback 和 Slf4j
spring boot内置:Logback 文章目录 spring boot内置:Logback一:Logback强在哪?二:简单使用三:把 log4j 转成 logback四:日志门面SLF4J1:什么是SLF4J2:SLF4J 解决了什么痛…...

内部知识库的未来展望:技术融合与用户体验的双重升级
在当今数字化飞速发展的时代,企业内部知识库作为知识管理的关键载体,正站在变革的十字路口,即将迎来技术融合与用户体验双重升级的崭新时代,这一系列变化将深度重塑企业知识管理的格局。 一、技术融合:开启知识管理新…...

OpenClaw故障排查大全:千问3.5-27B接口连接7类错误解决
OpenClaw故障排查大全:千问3.5-27B接口连接7类错误解决 1. 为什么需要这份排查指南 上周我在本地部署千问3.5-27B模型时,OpenClaw死活连不上模型接口。那天晚上我对着ECONNREFUSED错误折腾到凌晨两点,试了各种方法才发现是网关端口被占用了…...

拆穿名词诈骗!用大白话理解晦涩难懂的AI概念媳
1. 架构背景与演进动力 1.1 从单体到碎片化:.NET 的开源征程 在.NET Framework 时代,构建系统主要围绕 Windows 操作系统紧密集成,采用传统的封闭式开发模式。然而,随着.NET Core 的推出,微软开启了彻底的开源与跨平台…...

Arduino Portenta H7低功耗库深度解析:Sleep/Deep Sleep/Standby三模式实战
1. 项目概述Arduino Portenta H7 Low Power Library 是专为 Arduino Portenta H7 开发板设计的底层功耗管理库,其核心目标是为嵌入式开发者提供对 STM32H747XI 双核微控制器(Cortex-M7 Cortex-M4)全层级低功耗模式的细粒度控制能力。该库并非…...

OpenCV踩坑记:为什么cv2.imread读‘坏图’不返回None?深度解析JPEG文件结构与解码陷阱
OpenCV图像读取陷阱:JPEG文件损坏时cv2.imread为何不返回None? 在计算机视觉项目开发中,处理JPEG图像时经常会遇到这样的场景:明明系统提示"Premature end of JPEG file"警告,但cv2.imread()却依然返回了一个…...

学术PDF处理术:OpenClaw+Qwen3-32B实现论文关键图表提取
学术PDF处理术:OpenClawQwen3-32B实现论文关键图表提取 1. 为什么需要自动化PDF图表提取 作为一名经常需要阅读大量学术论文的研究者,我长期被一个问题困扰:如何高效地从PDF论文中提取关键图表和数据。传统方法要么依赖手动截图和转录&…...

查公司法人信息,别踩这3个坑
查公司法人信息,很多人都踩过坑——要么信息分散得切换5平台,要么解读不了风险,要么用了非合规工具泄露隐私。我之前帮朋友做尽调时就遇到过,查了一下午才凑齐信息,还差点漏掉法人关联的失信记录。其实用对方法和工具&…...

基于转子磁链模型的滑模观测器改进:自适应反馈增益拓宽低速运行区间仿真研究
基于转子磁链模型的改进滑模观测器 1.对滑模观测器进行改进,采用与转速相关的自适应反馈增益,避免恒定增益导致的低速下抖振明显的问题; 2.区别传统滑模从反电势中提取位置和转速信息,改进滑模观测器中利用转子磁链来提取相关信息…...

职场人AI生存指南:10个核心技能,让你不被AI淘汰反而被赋能
掌握AI工具的基础应用职场人需要熟悉主流AI工具的操作,如ChatGPT、Copilot、Notion AI等。了解这些工具的基本功能,如文本生成、数据分析、自动化流程等,能够提升工作效率。定期关注AI工具的更新,学习新功能的应用场景。培养数据思…...

面向“实时空间孪生系统”在煤化工行业落地应用:专家质询18问18答
《专家质询18问18答(煤化工专用版)》——面向“实时空间孪生系统”在煤化工行业落地应用的专家答辩标准话术一、系统定位类质询1. 专家问:你们这个系统和传统数字孪生到底有什么本质区别?不要泛泛而谈。答: 传统数字孪…...

P1094 [NOIP 2007 普及组] 纪念品分组 总结与反思
这题想了好久好久,但还是不能全部AC,最终还是找AI要了提示——用双指针,才发现这题用双指针的话其实一点都不难(一开始我就是硬解,也是双指针的逻辑,但用了两层循环,更复杂难懂,特殊…...