深度学习助力股市预测:LSTM、RNN和CNN模型实战解析
作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:众所周知,传统的股票预测模型有着各种各样的局限性。但在我的最新研究中,探索了一些方法来高效预测股市走势,即CNN、RNN和LSTM这些深度学习模型。这种方法在揭示金融数据的复杂性和变化趋势方面取得了一些成效。在本文中,我将带大家一步步了解如何利用特斯拉股票的案例,通过这些模型进行数据预处理、模型构建、训练和预测,希望这样一个新的股市预测工具模板,能助力您的投资决策。
一、股票价格预测方法的问题与发展
股票市场,尤其是股票价格预测,是一个备受研究人员和从业人员关注的领域。传统的时间序列预测方法,如自回归(AR)、自回归移动平均(ARMA)和自回归综合移动平均(ARIMA)模型在这方面发挥了重要作用。这些方法依赖于预定义的数学公式来模拟单变量时间序列,由于其简单性和可解释性而被广泛接受。

然而,AR、ARMA 和 ARIMA 有其固有的局限性,因此不适合捕捉金融时间序列数据的潜在动态特征。其中一个限制是,为一个时间序列确定的模型不能很好地推广到其他时间序列,从而降低了其通用性。此外,这些模型难以识别数据中蕴含的复杂模式,限制了其有效性。
近年来,卷积神经网络(CNN)、循环神经网络(RNN)等先进的机器学习模型及其变体(如长短期记忆(LSTM))引起了广泛关注。这些模型利用其从历史数据中学习的能力,不需要预定义的方程式,因此非常适合揭示隐藏的关系和依赖性。它们将金融数据建模为多维问题,从而实现了更准确、更稳健的预测。
本文将探讨 CNN、RNN 和基于注意力的 LSTM 在预测特斯拉股票价格中的应用。目的是展示每种方法的优缺点,并深入探讨深度学习模型如何超越传统线性模型。
二、为什么选择特斯拉股票?
特斯拉公司 (TSLA) 是最吸引分析师和投资者的股票之一,是评估 LSTM、RNN 和 CNN 等高级预测模型性能的理想选择。该公司是高风险、高回报投资的代表,因其技术创新以及围绕其领导地位和市场动态的争议而备受关注。
该公司创始人埃隆-马斯克(Elon Musk)是科技行业中最两极分化的人物之一,他一直在推动对特斯拉业绩的猜测。他支持唐纳德-特朗普总统参加 2024 年美国大选,进一步加剧了不确定性,加剧了该股的波动性,如下图所示。

这种猜测水平加上马斯克的公众形象,凸显了特斯拉作为旨在捕捉动态嘈杂数据的模型试验场的潜力。从 2010 年到 2024 年的收盘价就说明了这一点。

三、数据准备
3.1 数据收集
我们使用 yfinance 库中的特斯拉历史股价数据。
import yfinance as yf
import pandas as pddef fetch_tesla_stock_data():"""Fetch Tesla's historical stock data from Yahoo Finance.Returns:pd.DataFrame: DataFrame containing adjusted close prices indexed by date."""# Fetch data for Tesla (TSLA) from Yahoo Financeticker = "TSLA"start_date = "2010-01-01"end_date = "2024-11-17"tesla = yf.download(ticker, start=start_date, end=end_date)# Return a DataFrame with the adjusted close pricestesla_data = tesla[['Adj Close']].rename(columns={"Adj Close": "adjClose"})tesla_data.index.name = "date"return tesla_data# Fetch Tesla stock data
tesla_data = fetch_tesla_stock_data()# Display the first few rows of data
print(tesla_data.head(10))3.2 数据预处理
开发一个预处理管道,首先使用 MinMaxScaler 对特斯拉调整后的收盘价进行归一化处理。这一步骤可确保模型能有效处理数据,而不会受到原始值规模的影响。我们还使用滑动窗口创建历史股票价格序列。每个滑动窗口跨越 20 天(窗口大小)。最后,我们将数据重塑为适合 LSTM、RNN 和 CNN 的格式。重要的是,我们不对训练和测试数据进行洗牌,以保留股票价格的时间顺序。
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_absolute_percentage_error
from sklearn.model_selection import train_test_split
# Define the window size and prediction time
window_size = 20
prediction_steps = 10
# Function to create sequences
def create_sequences(data, window_size, prediction_steps):
X = []
y = []
for i in range(window_size, len(data) - prediction_steps):
X.append(data[i-window_size:i, 0]) # input sequence
y.append(data[i+prediction_steps-1, 0]) # target value (price at the next timestep)
return np.array(X), np.array(y)
# Fetch Tesla stock data
data = tesla_data[['adjClose']].values
# Normalize the data using MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(data)
# Create sequences for the model
X, y = create_sequences(scaled_data, window_size, prediction_steps)
# Reshape input data to be in the shape [samples, time steps, features]
X = X.reshape(X.shape[0], X.shape[1], 1)
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)
print(f"Training data shape: {X_train.shape}")
print(f"Testing data shape: {X_test.shape}")四、使用模型进行预测
4.1 使用 LSTM 预测
该模型包含一个自定义注意力层,以增强其捕捉特斯拉股票价格中关键时间模式的能力。该模型由 50 个单元组成,用于预处理输入序列,并通过内部记忆机制保留重要的时间依赖性。我们还加入了一个剔除层,通过在训练过程中随机禁用神经元来降低过度拟合的风险。训练结束后,我们将测试模型的性能,并绘制其预测结果与实际股票价格的对比图。
import numpy as np
import tensorflow as tf
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout, Attention, Add, LayerNormalization, Layer
from keras.callbacks import EarlyStopping
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_absolute_percentage_error# Define a custom attention layer
class AttentionLayer(Layer):def __init__(self, **kwargs):super(AttentionLayer, self).__init__(**kwargs)def build(self, input_shape):self.W = self.add_weight(shape=(input_shape[2], input_shape[2]), initializer='random_normal', trainable=True)self.b = self.add_weight(shape=(input_shape[1],), initializer='zeros', trainable=True)super(AttentionLayer, self).build(input_shape)def call(self, inputs):q = tf.matmul(inputs, self.W)a = tf.matmul(q, inputs, transpose_b=True)attention_weights = tf.nn.softmax(a, axis=-1)return tf.matmul(attention_weights, inputs)# LSTM model with attention and early stopping
def build_lstm_model_with_attention(input_shape):model = Sequential()model.add(LSTM(units=50, return_sequences=True, input_shape=input_shape))model.add(Dropout(0.2))# Attention layermodel.add(AttentionLayer())model.add(LayerNormalization())model.add(LSTM(units=50, return_sequences=False))model.add(Dropout(0.2))model.add(Dense(units=1)) # Output layer for predictionmodel.compile(optimizer='adam', loss='mean_squared_error')return model# Build the LSTM model with attention
model = build_lstm_model_with_attention(X_train.shape[1:])# Implement EarlyStopping to prevent overfitting
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)# Train the model with EarlyStopping and 50 epochs
history = model.fit(X_train, y_train, epochs=70, batch_size=32, validation_data=(X_test, y_test), callbacks=[early_stopping])# Evaluate the model
predicted_stock_price = model.predict(X_test)
predicted_stock_price = scaler.inverse_transform(predicted_stock_price)# Inverse scale the actual stock prices
y_test_scaled = scaler.inverse_transform(y_test.reshape(-1, 1))# Calculate MAPE
mape = mean_absolute_percentage_error(y_test_scaled, predicted_stock_price)
print(f"Mean Absolute Percentage Error (MAPE): {mape:.2f}%")# Plot the results
plt.figure(figsize=(10, 6))
plt.plot(y_test_scaled, label="Actual Tesla Stock Price", color='blue')
plt.plot(predicted_stock_price, label="Predicted Tesla Stock Price", color='red')
plt.title('Tesla Stock Price Prediction with LSTM', fontsize=14)
plt.xlabel('Time', fontsize=12)
plt.ylabel('Scaled Stock Price (USD)', fontsize=12)
plt.legend()
plt.grid(True)
plt.show()
该模型从数值上看良好,平均百分比误差为 0.17%。
4.2 使用 RNN(递归神经网络)预测
LSTM 在处理顺序数据方面表现相当出色。然后,我们整合了一个 RNN,以检验它是否能捕捉时间依赖性。此外,我们还使用双向 RNN 来考虑过去和未来的输入。
from keras.models import Sequential
from keras.layers import SimpleRNN, Dense, Dropout# Define the RNN model
def build_rnn_model(input_shape):model = Sequential()model.add(SimpleRNN(units=50, return_sequences=True, input_shape=input_shape))model.add(Dropout(0.2))model.add(SimpleRNN(units=50, return_sequences=False))model.add(Dropout(0.2))model.add(Dense(units=1)) # Output layer for predictionmodel.compile(optimizer='adam', loss='mean_squared_error')return model# Build the RNN model
rnn_model = build_rnn_model(X_train.shape[1:])# Train the model
rnn_history = rnn_model.fit(X_train, y_train, epochs=70, batch_size=32, validation_data=(X_test, y_test))# Evaluate the model
predicted_stock_price_rnn = rnn_model.predict(X_test)
predicted_stock_price_rnn = scaler.inverse_transform(predicted_stock_price_rnn)# Inverse scale the actual stock prices
y_test_scaled = scaler.inverse_transform(y_test.reshape(-1, 1))# Calculate MAPE for RNN
mape_rnn = mean_absolute_percentage_error(y_test_scaled, predicted_stock_price_rnn)
print(f"Mean Absolute Percentage Error (MAPE) for RNN: {mape_rnn:.2f}%")
# Plot the results for RNN model
plt.figure(figsize=(12, 6))
plt.plot(y_test_scaled, label="Actual Tesla Stock Price", color='blue')
plt.plot(predicted_stock_price_rnn, label="Predicted Tesla Stock Price", color='red')
plt.title('Tesla Stock Price Prediction with RNN', fontsize=14)
plt.xlabel('Time', fontsize=12)
plt.ylabel(' Scaled Stock Price (USD)', fontsize=12)
plt.legend()
plt.grid(True)
plt.show()下图是RNN 的预测结果:

这是 LSTM 与 RNN的比较图:

如图所示, RNN 模型的平均绝对百分比误差和 LSTM 相近。
4.3 使用 CNN(卷积神经网络)预测
最后,我们使用 CNN 来研究它在预测特斯拉股价方面的表现。该模型的结构是自动学习数据中的空间层次和模式。我们应用了多个卷积层,使用过滤器来检测输入数据中的重要特征。此外,我们还使用池化层来降低特征图的维度,并保留最重要的信息。由于我们使用全连接层,因此输出是预测未来股价的回归值。
from keras.models import Sequential
from keras.layers import Conv1D, MaxPooling1D, Flatten, Dense, Dropout, BatchNormalization
from keras.callbacks import EarlyStopping,ReduceLROnPlateau
from sklearn.metrics import mean_absolute_percentage_error
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_splitdef build_cnn_model(input_shape):model = Sequential()model.add(Conv1D(filters=64, kernel_size=3, activation='relu', input_shape=input_shape))model.add(BatchNormalization())model.add(MaxPooling1D(pool_size=2))model.add(Conv1D(filters=64, kernel_size=3, activation='relu'))model.add(BatchNormalization())# Change pool_size to avoid reducing dimensions to zeromodel.add(MaxPooling1D(pool_size=2))# Add a condition to avoid further reduction if dimensions are too smallmodel.add(Conv1D(filters=64, kernel_size=3, activation='relu'))model.add(BatchNormalization())model.add(MaxPooling1D(pool_size=1)) # Adjusted pool sizemodel.add(Flatten())model.add(Dropout(0.4))model.add(Dense(units=100, activation='relu'))model.add(Dropout(0.2))model.add(Dense(units=1)) # Output layer for predictionmodel.compile(optimizer='adam', loss='mean_squared_error')return modelcnn_model = build_cnn_model(X_train.shape[1:])
early_stopping = EarlyStopping(monitor='val_loss', patience=30, restore_best_weights=True)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=10, min_lr=1e-6)cnn_history = cnn_model.fit(X_train, y_train, epochs=200, batch_size=32, validation_data=(X_test, y_test), callbacks=[early_stopping, reduce_lr]
)# Build the CNN model
cnn_model = build_cnn_model(X_train.shape[1:])# Define EarlyStopping callback
early_stopping = EarlyStopping(monitor='val_loss', patience=30, restore_best_weights=True)# Train the model with early stopping and 100 epochs
cnn_history = cnn_model.fit(X_train, y_train, epochs=100, batch_size=32, validation_data=(X_test, y_test), callbacks=[early_stopping])# Evaluate the model
predicted_stock_price_cnn = cnn_model.predict(X_test)
predicted_stock_price_cnn = scaler.inverse_transform(predicted_stock_price_cnn)# Inverse scale the actual stock prices
y_test_scaled = scaler.inverse_transform(y_test.reshape(-1, 1))# Calculate MAPE for CNN
mape_cnn = mean_absolute_percentage_error(y_test_scaled, predicted_stock_price_cnn)
print(f"Mean Absolute Percentage Error (MAPE) for CNN: {mape_cnn:.2f}%")# Plot the results for CNN model
plt.figure(figsize=(12, 6))
plt.plot(y_test_scaled, label="Actual Tesla Stock Price", color='blue')
plt.plot(predicted_stock_price_cnn, label="Predicted Tesla Stock Price (CNN)", color='red')
plt.title('Tesla Stock Price Prediction with CNN', fontsize=14)
plt.xlabel('Time', fontsize=12)
plt.ylabel('Scaled Stock Price (USD)', fontsize=12)
plt.legend()
plt.grid(True)
plt.show()下图是 CNN 的预测结果:

这是 CNN 与LSTM 、RNN的比较图:

CNN 模型的平均绝对百分比误差为 0.14%,优于 LSTM 和 RNN。
4.4 比较结果
三种模型的平均绝对误差百分比如下:
import matplotlib.pyplot as plt
mape_scores = [mape, mape_rnn, mape_cnn]
models = ['LSTM', 'RNN', 'CNN']
# Create the bar chart
plt.figure(figsize=(6, 4))
plt.bar(models, mape_scores, color=['blue', 'green', 'orange'])
# Add labels and title
plt.title('MAPE Comparison for LSTM, RNN, and CNN', fontsize=14)
plt.xlabel('Models', fontsize=12)
plt.ylabel('MAPE (%)', fontsize=12)
# Show the MAPE values on top of the bars
for i, v in enumerate(mape_scores):
plt.text(i, v + 0.1, f'{v:.2f}%', fontsize=12)
# Display the plot
plt.show()性能比较图如下:

基于深度学习的股票预测方法采用三种不同的神经架构,能够很好地捕捉隐藏的动态变化。虽然特斯拉股票波动性很大,但我们的模型实现了非常低的平均绝对百分比误差(MAPE):LSTM和RNN 都是 0.17%,CNN 为 0.14%。
这证明了深度学习模型能有效捕捉时间差和隐藏模式,而 CNN 能有效捕捉股票价格的突然变化和趋势。
五、观点总结
- 传统时间序列预测模型存在局限性:AR、ARMA 和 ARIMA 等传统模型在金融数据的预测中表现出模型泛化能力差和难以捕捉复杂模式的问题。
- 深度学习模型在股票预测中的优势:CNN、RNN 和 LSTM 等深度学习模型能够从历史数据中自动学习,无需预设的数学方程,更适合处理金融时间序列数据的复杂性。
- 特斯拉股票的特殊性:特斯拉股票的高波动性和与其相关的公众关注度,使其成为测试股票预测模型的理想案例。
- 模型性能比较:通过对比 LSTM、RNN 和 CNN 模型在特斯拉股票预测上的表现,得出 CNN 模型在本次实验中具有最佳的预测能力。
精选10篇和股票预测相关的文章推荐:
- 仅需八步,打造私人专属智能股票预测模型
- 手把手教会你用 AI 和 Python 进行股票交易预测(完整代码干货)
- 揭秘:如何用思想增强型LSTM网络精准预测股价?
- 震惊金融界!三大深度学习模型联袂,竟创出66,941.5%逆天回报率!
- 美国大选后,用HMM模型做特斯拉股价波动解析
- 使用堆叠 LSTM 模型预测市场趋势
- 获得简街市场预测大赛金牌的预测策略模型
- 融合篇:用 OpenAI o1 草莓模型和 Python 预测股市行情
- 【Python时序预测系列】基于LSTM实现多输入多输出单步预测(案例+源码)
- 用 Python 中的量子机器学习预测股票价格
谢谢您阅读到最后,希望本文能给您带来新的收获。祝您投资顺利!如果对文中的内容有任何疑问,请给我留言,必复。
本文内容仅限技术探讨和学习,不构成任何投资建议。
相关文章:
深度学习助力股市预测:LSTM、RNN和CNN模型实战解析
作者:老余捞鱼 原创不易,转载请标明出处及原作者。 写在前面的话:众所周知,传统的股票预测模型有着各种各样的局限性。但在我的最新研究中,探索了一些方法来高效预测股市走势,即CNN、RNN和LSTM这些深度学习…...

组件库TDesign的表格<t-table>的使用,行列合并以及嵌入插槽实现图标展示,附踩坑
碎碎念:有点难用,不丝滑(以下介绍的难点不是真的难,只是有点点点难用) 背景:需要实现表格的行列合并以及图标的嵌入,想到使用组件库组件来方便开发 链接:TDesign Web Vue Next 难点…...

jwt在express中token的加密解密实现方法
在我们前面学习了 JWT认证机制在Node.js中的详细阐述 之后,今天来详细学习一下token是如何生成的,secret密钥的加密解密过程是怎么样的。 安装依赖 express:用于创建服务器jsonwebtoken:用于生成和验证JWTbody-parser࿱…...

结构体、共用体的字节对齐
结构体 结构体嵌套时:先算一下嵌套的结构体大小 嵌套进来的结构体大小为16字节,仍然进行,8字节对齐 typedef struct {char name[20];//20字节//000开始 20字节 019 struct{int day; //000开始 4字节 003char swx; //004开始 1…...

【YOLOv3】源码(train.py)
概述 主要模块分析 参数解析与初始化 功能:解析命令行参数,设置训练配置项目经理制定详细的施工计划和资源分配日志记录与监控 功能:初始化日志记录器,配置监控系统项目经理使用监控和记录工具,实时跟踪施工进度和质量…...

帧缓存的分配
帧缓存实际上就是一块内存。在 Android 系统中分配与回收帧缓存,使用的是一个叫 ION 的内核模块,App 使用 ioctl 系统调用后,会在内核内存中分配一块符合要求的内存,用户态会拿到一个 fd(有的地方也称之为 handle&…...

基于顺序表实现队列循环队列的处理
文章目录 1.假溢出的现象2.循环队列3.顺序表实现队列架构4.顺序表模拟实现队列5.设计循环队列(校招难度) 1.假溢出的现象 下面的这个就是我们的假溢出的这个现象的基本的来源: 我们的这个队列里面是有9个位置的,我们知道这个队列…...

磁珠选型规范
根据不同的应用场景,磁珠可以分为普通型磁珠,大电流型磁珠和尖峰型磁珠。 (1)普通型磁珠:主要用于电流比较小(小于600mA).无特殊要求的场景,普通型磁珠的直流电阻一般不超过1Ω&…...

linux 点对点语音通话及直播推流实践一: linux USB声卡或耳机 基本配置
inux USB声卡或耳机 基本配置 工具安装查看设备录放音操作录音放音声音配置获取控制信息音量配置本文介绍 linux下alsa声音原件 工具使用方法,包括设备查询、声卡基本配置、录音放音等。 保证 alsa套件可正常操作和配置声卡,是实现SIP语音通话、音视频 采集及推拉流功能的基础…...

3DMAX镂空星花球建模插件FloralStarBall使用方法
3DMAX镂空星花球建模插件FloralStarBall使用教程 就是那个3DMAX镂空星花球建模,再也不用手动做了,使用3DMAX镂空星花球建模FloralStarBall插件可以一键生成! 3DMAX镂空星花球建模插件FloralStarBall,经典星形球体的美丽变体。星形…...
window 安装 nodejs
方式一:使用 fnm 可能会出现 cmd 找不到 nodejs 和 npm 的情况,并且包也可能不知道哪一个 参考链接 Node.js — Download Node.js 使用 powershell 操作,要不然可能有些执行不了 # 安裝 fnm (快速 Node 管理器) winget install Schniz.fnm# …...

Autoware Universe 安装记录
前提: ubuntu20.04,英伟达显卡。 ROS2-Galactic安装 wget http://fishros.com/install -O fishros && . fishros 选择galactic(ROS2)版本,桌面版 ROS2-dev-tools安装 sudo apt install python3-testresources sudo apt update …...

每天40分玩转Django:Django部署概述
一、Django部署概述 在开发阶段,我们通常使用Django内置的轻量级开发服务器runserver。但在生产环境中,为了应对大量并发请求,需要使用高性能的WSGI服务器,如Gunicorn、uWSGI等。同时还要配置Nginx等Web服务器作为反向代理,实现负载均衡、静态文件处理等。下面是Django部署的整…...

使用VS Code开发ThinkPHP项目
【图书介绍】《ThinkPHP 8高效构建Web应用》-CSDN博客 《ThinkPHP 8高效构建Web应用 夏磊 编程与应用开发丛书 清华大学出版社》【摘要 书评 试读】- 京东图书 ThinkPHP 8开发环境安装-CSDN博客 安装ThinkPHP项目的IDE 常用的集成开发环境(IDE)包括P…...
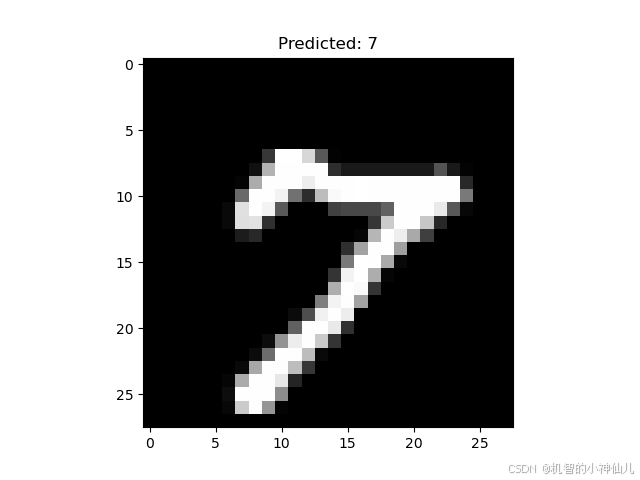
基于深度可分离卷积的MNIST手势识别
基于深度可分离膨胀卷积的MNIST手写体识别 Github链接 项目背景: MNIST手写体数据集是深度学习领域中一个经典的入门数据集,包含了从0到9的手写数字图像,用于评估不同模型在图像分类任务上的性能。在本项目中,我们通过设计一种基…...

Linux服务器pm2 运行chatgpt-on-wechat,搭建微信群ai机器人
安装 1.拉取项目 项目地址: chatgpt-on-wechat 2.安装依赖 pip3 install -r requirements.txt pip3 install -r requirements-optional.txt3、获取API信息 当前免费的有百度的文心一言,讯飞的个人认证提供500万token的额度。 控制台-讯飞开放平台 添加链接描述…...

Word批量更改题注
文章目录 批量更改批量去除空格 在写文章的时候,往往对图片题注有着统一的编码要求,例如以【图 1- xx】。一般会点击【引用】->【插入题注】来插入题注,并且在引用的时候,点击【引用】->【交叉引用】,并且在交叉…...

Springboot配置嵌入式服务器
一.如何定制和修改Servlet容器的相关配置 修改和server有关的配置(ServerProperties); server.port8081 server.context‐path/tx server.tomcat.uri‐encodingUTF‐8 在yml配置文件的写法: server:port: 8081servlet:context-pa…...
正交三角函数全面阐述
目录 1. 正交性定义 2. 正交三角函数 常见的正交三角函数 3. 正交三角函数的特性 4. 正交三角函数在傅里叶分析中的应用 5. 正交三角函数的应用领域 6. 总结 正交三角函数是指在特定条件下,三角函数之间的内积为零。更具体地说,在数学分析、信号处…...

《Vue3 四》Vue 的组件化
组件化:将一个页面拆分成一个个小的功能模块,每个功能模块完成自己部分的独立的功能。任何应用都可以被抽象成一棵组件树。 Vue 中的根组件: Vue.createApp() 中传入对象的本质上就是一个组件,称之为根组件(APP 组件…...

Qwen3.5-2B部署实操:CentOS 7兼容性处理与依赖库降级方案
Qwen3.5-2B部署实操:CentOS 7兼容性处理与依赖库降级方案 1. 模型简介 Qwen3.5-2B是阿里云推出的轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。该模型主打低功耗、低门槛部署特性,特别适配端侧和边…...

Qwen3-VL-8B系统资源管理:监控与清理GPU显存和C盘空间
Qwen3-VL-8B系统资源管理:监控与清理GPU显存和C盘空间 长期运行像Qwen3-VL-8B这样的大模型服务,就像养了一头“数字大象”——它能力强大,但胃口也不小,尤其能吃GPU显存和硬盘空间。很多朋友刚开始部署时一切顺利,但跑…...

高效智能转换方案:B站缓存视频一键处理实战指南
高效智能转换方案:B站缓存视频一键处理实战指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在B站视频频繁下架的当下,…...

深耕纪实创作 AVG Media 以专业能力赋能纪录片产业发展
在全球内容产业快速迭代的当下,纪录片凭借真实的叙事力量、深厚的人文价值与多元的传播场景,成为内容领域中兼具艺术价值与商业价值的重要载体。国内纪录片行业历经多年发展,形成了多元主体参与、创作方向细分、国际合作深化的行业格局&#…...
的跨模态融合应用)
Mirage Flow 与卷积神经网络(CNN)的跨模态融合应用
Mirage Flow 与卷积神经网络(CNN)的跨模态融合应用 你有没有想过,让机器不仅能“看见”图片,还能像人一样“理解”并“描述”图片里的故事?比如,给一张复杂的医学影像,它不仅能圈出病灶&#x…...
)
保姆级教程:用CST 2023的RLC求解器搞定空心电感仿真(附网格优化技巧)
从零到精通的CST空心电感仿真实战指南:RLC求解器与网格优化全解析 在电磁兼容设计和高频电路开发中,空心电感作为无磁芯干扰的理想元件,其精确建模一直是工程师的痛点。传统手工计算难以应对复杂的高频效应,而商业仿真软件的门槛…...

终极指南:Redaxios参数序列化完全掌握,自定义查询字符串生成逻辑如此简单
终极指南:Redaxios参数序列化完全掌握,自定义查询字符串生成逻辑如此简单 【免费下载链接】redaxios The Axios API, as an 800 byte Fetch wrapper. 项目地址: https://gitcode.com/gh_mirrors/re/redaxios Redaxios是一个轻量级的Fetch封装库&a…...

EasyAnimateV5-7b-zh-InP一键部署教程:基于Linux系统的快速安装指南
EasyAnimateV5-7b-zh-InP一键部署教程:基于Linux系统的快速安装指南 1. 引言 想快速在Linux系统上部署一个强大的视频生成模型吗?EasyAnimateV5-7b-zh-InP是一个22GB的图生视频模型,支持多分辨率视频生成,还能用中英文双语进行预…...

Sunshine开源游戏串流:打造你的专属云游戏服务器终极指南
Sunshine开源游戏串流:打造你的专属云游戏服务器终极指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在任何设备上畅玩PC游戏?厌倦了被商业云游戏平…...

如何用Nucleus Co-Op实现本地多人游戏:5个维度解析开源工具的技术突破与应用价值
如何用Nucleus Co-Op实现本地多人游戏:5个维度解析开源工具的技术突破与应用价值 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 当你和…...