如何在 Spring Boot 微服务中设置和管理多个数据库
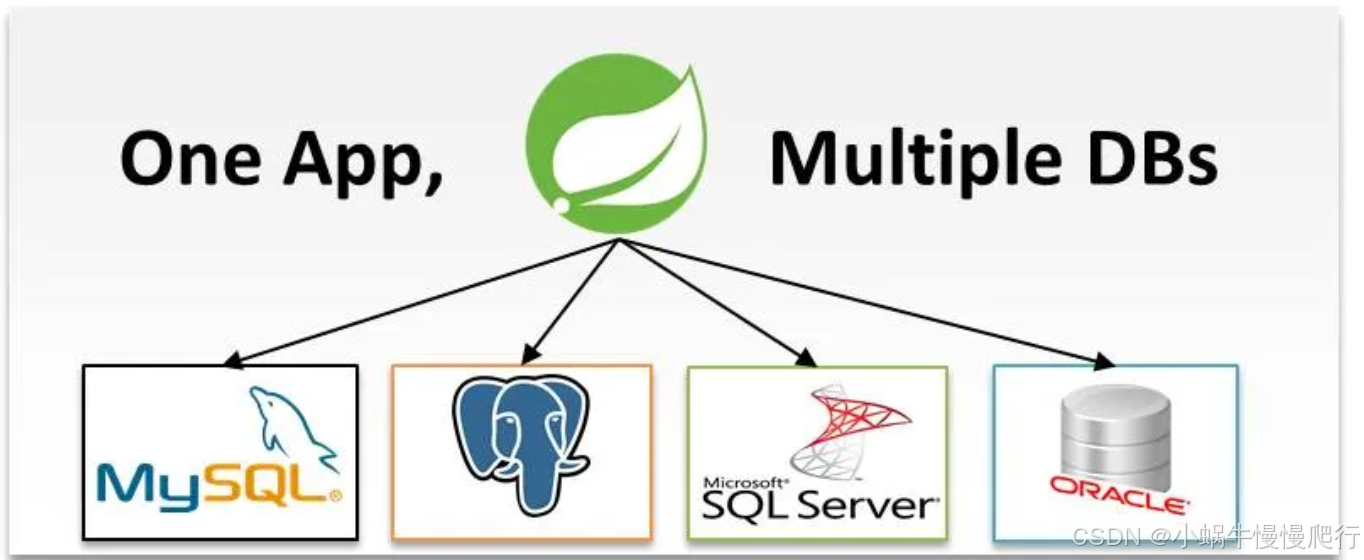 在现代微服务架构中,通常需要与多个数据库交互的服务。这可能是由于各种原因,例如遗留系统集成、不同类型的数据存储需求,或者仅仅是为了优化性能。Spring Boot 具有灵活的配置和强大的数据访问库,可以轻松配置多个数据库。在本综合指南中,我们将探讨如何在 Spring Boot 微服务中设置和管理多个数据库连接。
在现代微服务架构中,通常需要与多个数据库交互的服务。这可能是由于各种原因,例如遗留系统集成、不同类型的数据存储需求,或者仅仅是为了优化性能。Spring Boot 具有灵活的配置和强大的数据访问库,可以轻松配置多个数据库。在本综合指南中,我们将探讨如何在 Spring Boot 微服务中设置和管理多个数据库连接。
1. 简介
微服务通常需要与各种数据库交互。每个微服务可能需要不同类型的数据库,例如用于事务数据的 SQL 数据库和用于非结构化数据的 NoSQL 数据库。Spring Boot 为配置和管理多个数据源提供了出色的支持,使其成为现代微服务架构的理想选择。
2.为什么要使用多个数据库?
您可能需要在微服务中使用多个数据库的原因如下:
- 遗留系统集成:与遗留系统的现有数据库集成。
- 优化性能:使用针对特定类型的数据(例如关系型与非关系型)优化的不同数据库。
- 数据隔离:出于安全、合规或组织原因分离数据。
- 可扩展性:在不同的数据库之间分配数据负载以提高性能。
3.设置 Spring Boot 项目
首先,创建一个新的 Spring Boot 项目。您可以使用 Spring Initializr 或您喜欢的 IDE 来设置项目。
Maven 依赖项
在您的 中pom.xml包含 Spring Data JPA 和您将使用的数据库的依赖项(例如,内存中的 H2、PostgreSQL、MySQL 等)。
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>com.h2database</groupId><artifactId>h2</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><scope>runtime</scope></dependency>
</dependencies>4.配置多个数据源
在application.yml或application.properties文件中,配置每个数据库的连接属性。
application.yml
spring:datasource:primary:url: jdbc:h2:mem:primarydbdriver-class-name: org.h2.Driverusername: sapassword: passwordsecondary:url: jdbc:postgresql://localhost:5432/secondarydbdriver-class-name: org.postgresql.Driverusername: postgrespassword: password
jpa:primary:database-platform: org.hibernate.dialect.H2Dialecthibernate:ddl-auto: updatesecondary:database-platform: org.hibernate.dialect.PostgreSQLDialecthibernate:ddl-auto: update5.创建数据源配置类
接下来,为每个数据源创建单独的配置类。
主数据源配置
package com.example.config;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.orm.jpa.JpaTransactionManager;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
import org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter;
import org.springframework.transaction.PlatformTransactionManager;
import javax.persistence.EntityManagerFactory;
import javax.sql.DataSource;
@Configuration
@EnableJpaRepositories(basePackages = "com.example.primary.repository",entityManagerFactoryRef = "primaryEntityManagerFactory",transactionManagerRef = "primaryTransactionManager"
)
public class PrimaryDataSourceConfig {@Bean(name = "primaryDataSource")@ConfigurationProperties(prefix = "spring.datasource.primary")public DataSource primaryDataSource() {return DataSourceBuilder.create().build();}@Bean(name = "primaryEntityManagerFactory")public LocalContainerEntityManagerFactoryBean primaryEntityManagerFactory(@Qualifier("primaryDataSource") DataSource dataSource) {LocalContainerEntityManagerFactoryBean em = new LocalContainerEntityManagerFactoryBean();em.setDataSource(dataSource);em.setPackagesToScan(new String[] { "com.example.primary.entity" });HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();em.setJpaVendorAdapter(vendorAdapter);return em;}@Bean(name = "primaryTransactionManager")public PlatformTransactionManager primaryTransactionManager(@Qualifier("primaryEntityManagerFactory") EntityManagerFactory entityManagerFactory) {return new JpaTransactionManager(entityManagerFactory);}
}辅助数据源配置
package com.example.config;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.orm.jpa.JpaTransactionManager;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
import org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter;
import org.springframework.transaction.PlatformTransactionManager;
import javax.persistence.EntityManagerFactory;
import javax.sql.DataSource;
@Configuration
@EnableJpaRepositories(basePackages = "com.example.secondary.repository",entityManagerFactoryRef = "secondaryEntityManagerFactory",transactionManagerRef = "secondaryTransactionManager"
)
public class SecondaryDataSourceConfig {@Bean(name = "secondaryDataSource")@ConfigurationProperties(prefix = "spring.datasource.secondary")public DataSource secondaryDataSource() {return DataSourceBuilder.create().build();}@Bean(name = "secondaryEntityManagerFactory")public LocalContainerEntityManagerFactoryBean secondaryEntityManagerFactory(@Qualifier("secondaryDataSource") DataSource dataSource) {LocalContainerEntityManagerFactoryBean em = new LocalContainerEntityManagerFactoryBean();em.setDataSource(dataSource);em.setPackagesToScan(new String[] { "com.example.secondary.entity" });HibernateJpaVendorAdapter vendorAdapter = new HibernateJpaVendorAdapter();em.setJpaVendorAdapter(vendorAdapter);return em;}@Bean(name = "secondaryTransactionManager")public PlatformTransactionManager secondaryTransactionManager(@Qualifier("secondaryEntityManagerFactory") EntityManagerFactory entityManagerFactory) {return new JpaTransactionManager(entityManagerFactory);}
}6. 定义实体管理器
为每个数据库定义实体类。确保将它们放在配置类中指定的相应包中。
主数据库实体
package com.example.primary.entity;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class PrimaryEntity {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String name;// getters and setters
}辅助数据库实体
package com.example.secondary.entity;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class SecondaryEntity {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String description;// getters and setters
}7. 创建存储库
为每个数据库创建存储库接口,确保它们按照配置放置在正确的包中。
主存储库
package com.example.primary.repository;
import com.example.secondary.entity.SecondaryEntity;
import org.springframework.data.jpa.repository.JpaRepository;
public interface SecondaryRepository extends JpaRepository<SecondaryEntity, Long> {
}二级存储库
package com.example.secondary.repository;
import com.example.secondary.entity.SecondaryEntity;
import org.springframework.data.jpa.repository.JpaRepository;
public interface SecondaryRepository extends JpaRepository<SecondaryEntity, Long> {
}8.测试配置
最后,创建一个简单的 REST 控制器来测试设置。此控制器将使用两个存储库来执行 CRUD 操作。
package com.example.controller;
import com.example.primary.entity.PrimaryEntity;
import com.example.primary.repository.PrimaryRepository;
import com.example.secondary.entity.SecondaryEntity;
import com.example.secondary.repository.SecondaryRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class TestController {@Autowiredprivate PrimaryRepository primaryRepository;@Autowiredprivate SecondaryRepository secondaryRepository;@GetMapping("/test")public String test() {PrimaryEntity primaryEntity = new PrimaryEntity();primaryEntity.setName("Primary Entity");primaryRepository.save(primaryEntity);SecondaryEntity secondaryEntity = new SecondaryEntity();secondaryEntity.setDescription("Secondary Entity");secondaryRepository.save(secondaryEntity);return "Entities saved!";}
}相关文章:
如何在 Spring Boot 微服务中设置和管理多个数据库
在现代微服务架构中,通常需要与多个数据库交互的服务。这可能是由于各种原因,例如遗留系统集成、不同类型的数据存储需求,或者仅仅是为了优化性能。Spring Boot 具有灵活的配置和强大的数据访问库,可以轻松配置多个数据库。在本综…...
Ubuntu20.04安装Foxit Reader 福昕阅读器
Ubuntu20.04安装Foxit Reader 福昕阅读器 文章目录 Ubuntu20.04安装Foxit Reader 福昕阅读器 先更新一下源 sudo apt update sudo apt upgrade下载Foxit Reader的稳定版本 wget https://cdn01.foxitsoftware.com/pub/foxit/reader/desktop/linux/2.x/2.4/en_us/FoxitReader.e…...

学习threejs,THREE.CircleGeometry 二维平面圆形几何体
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️THREE.CircleGeometry 圆形…...

Tonghttpserver6.0.1.3 使用整理(by lqw)
文章目录 1.声明2.关于单机版控制台和集中管理控制台3.单机版控制台3.1安装,启动和查看授权信息3.2一些常见的使用问题(单机控制台)3.3之前使用的是nginx,现在要配nginx.conf上的配置,在THS上如何配置3.4如何配置密码过…...

redis开发与运维-redis0401-补充-redis流水线与Jedis执行流水线
文章目录 【README】【1】redis流水线Pipeline【1.1】redis流水线概念【1.2】redis流水线性能测试【1.2.1】使用流水线与未使用流水线的性能对比【1.2.2】使用流水线与redis原生批量命令的性能对比【1.2.3】流水线缺点 【1.3】Jedis客户端执行流水线【1.3.1】Jedis客户端执行流…...

OPPO Java面试题及参考答案
Java 语言的特点 Java 是一种面向对象的编程语言,它具有以下显著特点。 首先是简单性。Java 的语法相对简单,它摒弃了 C 和 C++ 语言中一些复杂的特性,比如指针操作。这使得程序员能够更专注于业务逻辑的实现,而不是陷入复杂的语法细节中。例如,Java 的内存管理是自动进行…...

Ubuntu 22.04 升级 24.04 问题记录
一台闲置笔记本使用的 ubuntu 还是 18.04,最近重新使用,发现版本过低,决定升级,于是完成了 18.04 -> 20.04 -> 22. 04 -> 24.04 的三连跳。 一、升级过程中黑屏 主要问题是在 22.04 升级到 24.04 过程中出现了黑屏仅剩…...
:Redis)
Java重要面试名词整理(五):Redis
文章目录 Redis高级命令Redis持久化RDB快照(snapshot)**AOF(append-only file)****Redis 4.0 混合持久化** 管道(Pipeline)**StringRedisTemplate与RedisTemplate详解**Redis集群方案gossip脑裂 Redis LuaR…...

单元测试中创建多个线程测试 ThreadLocal
单元测试中创建多个线程测试 ThreadLocal 在单元测试中,可以通过以下方式创建多个线程来测试 ThreadLocal 的行为。 目标 验证 ThreadLocal 在多线程环境下是否能正确隔离每个线程的数据。 实现步骤 定义需要测试的类 包含 ThreadLocal 对象的类,提供…...

iDP3复现代码数据预处理全流程(二)——vis_dataset.py
vis_dataset.py 主要作用在于点云数据的可视化,并可以做一些简单的预处理 关键参数基本都在 vis_dataset.sh 中定义了,需要改动的仅以下两点: 1. 点云图像保存位置,因为 dataset_path 被设置为了绝对路径,因此需要相…...

容器化部署服务全流程
系列文章目录 文章目录 系列文章目录前言一、什么是容器?二、如何安装docker三、如何写dockerfile四、如何启动服务五、常见命令总结总结 前言 这篇文章,主要目的是通过容器化技术简化应用程序的部署、运行和管理,提高开发、测试和生产环境…...

Flutter DragTarget拖拽控件详解
文章目录 1. DragTarget 控件的构造函数主要参数: 2. DragTarget 的工作原理3. 常见用法示例 1:实现一个简单的拖拽目标解释:示例 2:与 Draggable 结合使用解释: 4. DragTarget 的回调详解5. 总结 DragTarget 是 Flutt…...
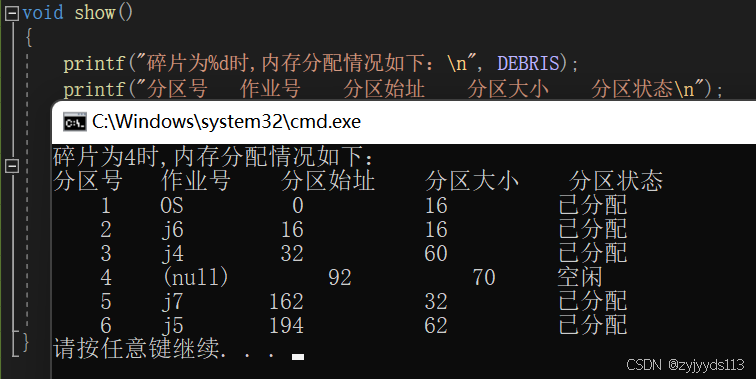
操作系统动态分区分配算法-首次适应算法c语言实现
目录 一、算法原理 二、算法特点 1.优先利用低址空闲分区: 2.查找开销: 3.内存碎片: 三、内存回收四种情况 1.回收区上面(或后面)的分区是空闲分区: 2.回收区下面(或前面)的…...

mybatis-plus自动填充时间的配置类实现
mybatis-plus自动填充时间的配置类实现 在实际操作过程中,我们并不希望创建时间、修改时间这些来手动进行,而是希望通过自动化来完成,而mybatis-plus则也提供了自动填充功能来实现这一操作,接下来,就来了解一下mybatis…...

Vite内网ip访问,两种配置方式和修改端口号教程
目录 问题 两种解决方式 结果 总结 preview.host preview.port 问题 使用vite运行项目的时候,控制台会只出现127.0.0.1(localhost)本地地址访问项目。不可以通过公司内网ip访问,其他团队成员无法访问,这是因为没…...

【星海随笔】删除ceph
cephadm shell ceph osd set noout ceph osd set norecover ceph osd set norebalance ceph osd set nobackfill ceph osd set nodown ceph osd set pause参考文献: https://blog.csdn.net/lyf0327/article/details/90294011 systemctl stop ceph-osd.targetyum re…...
HarmonyOS NEXT实战:自定义封装多种样式导航栏组件
涉及知识点和装饰器 ComponentV2,Local, Builder,BuilderParam,Extend, Require ,Param,Event等第三方库:ZRouter ,如项目中本来就用了ZRouter路由库,案例中…...
大数据面试笔试宝典之Flink面试
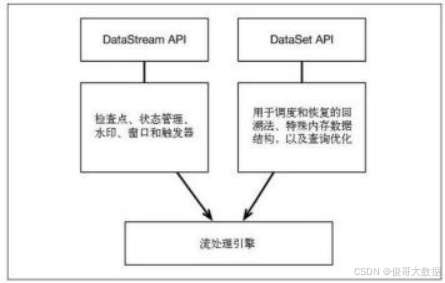
1.Flink 是如何支持批流一体的? F link 通过一个底层引擎同时支持流处理和批处理. 在流处理引擎之上,F link 有以下机制: 1)检查点机制和状态机制:用于实现容错、有状态的处理; 2)水印机制:用于实现事件时钟; 3)窗口和触发器:用于限制计算范围,并定义呈现结果的…...

pytorch整体环境打包安装到另一台电脑上
步骤一:安装conda-pack 首先利用 pip list 指令检查conda环境安装在哪里,在系统环境(base)下,于是我是使用的conda指令完成的。 # 使用Conda安装(如果已安装conda) conda install conda-pack …...

PostgreSQL 数据库连接
title: PostgreSQL 数据库连接 date: 2024/12/29 updated: 2024/12/29 author: cmdragon excerpt: PostgreSQL是一款功能强大的开源关系数据库管理系统,在现代应用中广泛应用于数据存储和管理。连接到数据库是与PostgreSQL进行交互的第一步,这一过程涉及到多个方面,包括连…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...
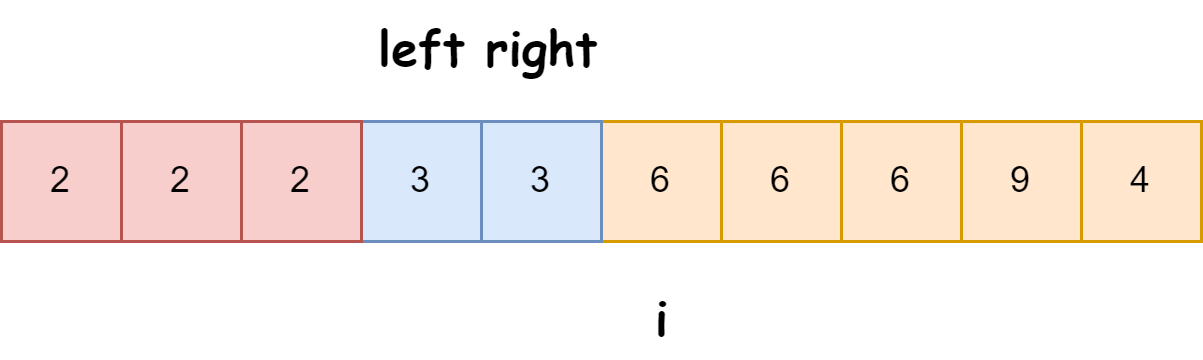
快速排序算法改进:随机快排-荷兰国旗划分详解
随机快速排序-荷兰国旗划分算法详解 一、基础知识回顾1.1 快速排序简介1.2 荷兰国旗问题 二、随机快排 - 荷兰国旗划分原理2.1 随机化枢轴选择2.2 荷兰国旗划分过程2.3 结合随机快排与荷兰国旗划分 三、代码实现3.1 Python实现3.2 Java实现3.3 C实现 四、性能分析4.1 时间复杂度…...
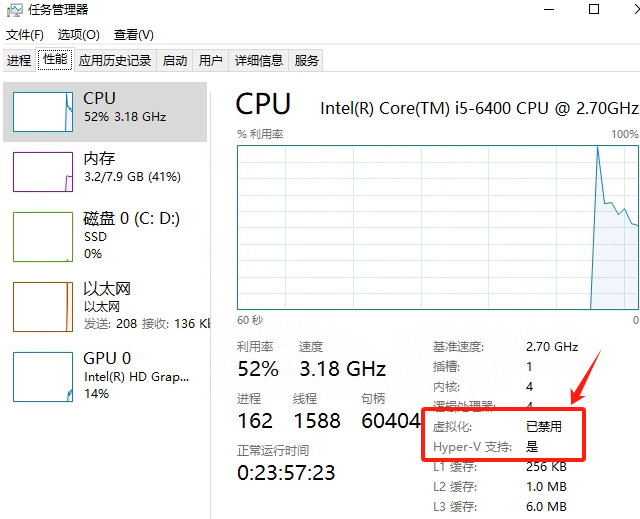
Windows电脑能装鸿蒙吗_Windows电脑体验鸿蒙电脑操作系统教程
鸿蒙电脑版操作系统来了,很多小伙伴想体验鸿蒙电脑版操作系统,可惜,鸿蒙系统并不支持你正在使用的传统的电脑来安装。不过可以通过可以使用华为官方提供的虚拟机,来体验大家心心念念的鸿蒙系统啦!注意:虚拟…...