【PostgreSQL使用】最新功能逻辑复制槽的failover,大数据下高可用再添利器
逻辑复制的failover
专栏内容:
- postgresql入门到进阶
- 手写数据库toadb
- 并发编程
个人主页:我的主页
管理社区:开源数据库
座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物.
✅ 🔥🔥🔥重大消息🔥🔥🔥 ❤️❤️❤️❤️ 关注公众号【开源无限】有更多数据库优质内容输出 ❤️❤️❤️❤️
一、概述
使用数据库除了存取数据快捷以外,还有一个非常重要的目的,就是它有一整套的机制来保障数据访问的高可用,持续性。
当然逻辑复制也不例外,当我们正在订阅的主库故障发生主备切换时,仍然希望数据库对象的变更订阅不会丢失,能持续收到发布者的消息。
这在以往的PostgreSQL版本中是没有的,最新的PostgreSQL 17版本终于完善了这一功能,逻辑复制支持了failover特性,提升了逻辑复制的高可用性。
本文通过搭建逻辑复制的failover部署,来试一试逻辑复制的failover倒底如何。

二、 热备集群部署
为了演示带failover的逻辑复制的高可用,首先需要部署一主一备的热备环境,采用流复制的方式对整个主库数据进行实时备份。如果要增加复制槽的备份,当然备库要相较于普通的流复制需要多一些配置,要采用复制槽方式,同时还要打开备份的反馈和复制槽同步开关。
为了有明显区分,在此之外第三个集簇,只对主库的一张表的变动进行订阅,这里采用了逻辑复制的方式,并使用了带有failover的逻辑复制槽。带有failover的逻辑复制槽会在主库创建,因为有自动同步机制,也会在备份被创建。
当主备环境发生切换时,主停机,而备切换为新主;此时订阅者,只需要将连接信息修改为新的主库即可,在此期间发布的变更数据不会丢失,都会被订阅者收到。这就是带failover的逻辑复制槽发挥的作用。
2.1 部署规划

这里我们部署在同一台机器上,所以区分主要是集簇目录和启动时的端口号。
| 集簇目录 | 端口号 | |
|---|---|---|
| 主库 | pgA | 5432 (default) |
| 热备库 | pgAA1 | 5434 |
| 订阅库 | pgB | 5433 |
2.2 热备搭建
首先需要部署一套主备集群。
主库采用initdb来初始化创建,而备库采用从主库的备份产生,使用pg_basebackup命令直接进行备份。
- 初始化主库
[senllang@hatch postgres]$ /opt/postgres/bin/initdb -D pgA
- 配置主库参数
在启动主库之前,需要提前配置几个参数。
wal_level, 默认为replica, 因为需要使用逻辑复制,修改为 logical;
max_wal_senders, 默认为10,已经足够;
max_replication_slots , 因为用到复制槽,这里默认值为10,已经足够;
- 启动主库
然后,就可以启动主库。
[senllang@hatch postgres]$ /opt/postgres/bin/pg_ctl -D pgA/ -l logfile start
waiting for server to start.... done
server started
- 创建备份
使用pg_basebackup命令,这个命令的好处是可以在线建立备份,在这里增加了-C -S slot_pri参数,创建了一个物理复制槽,用于复制槽在主备之间同步,后面的步骤会使用到它,所以在这里提前创建,当然也可以手动创建。
[senllang@hatch postgres]$ /opt/postgres/bin/pg_basebackup -h 127.0.0.1 -U senllang --pgdata=./pgAA1 --progress --verbose -C -S slot_pri
pg_basebackup: initiating base backup, waiting for checkpoint to complete
pg_basebackup: checkpoint completed
pg_basebackup: write-ahead log start point: 0/2000028 on timeline 1
pg_basebackup: starting background WAL receiver
pg_basebackup: created replication slot "slot_pri"
23135/23135 kB (100%), 1/1 tablespace
pg_basebackup: write-ahead log end point: 0/2000158
pg_basebackup: waiting for background process to finish streaming ...
pg_basebackup: syncing data to disk ...
pg_basebackup: renaming backup_manifest.tmp to backup_manifest
pg_basebackup: base backup completed
- 配置备库的参数
在备库上要配置主库的连接信息,同时要打开热备的开关,这样就可以在备库进行一些查询操作。
primary_conninfo = 'host=127.0.0.1 port=5432 dbname=postgres'
hot_standby = on
- 启动备库
在启动备库之前,先要创建standby信号文件,以standby模式启动备份集簇。
[senllang@hatch postgres]$ touch pgAA1/standby.signal
[senllang@hatch postgres]$ /opt/postgres/bin/pg_ctl -D pgAA1/ -o "-p 5434 " -l logfile start
这里备库启动时, 因为在同台机器上不能与其它产生冲突,指定了它的服务监听端口为5434。
- 验证主备环境
在主库上创建两张表。
[senllang@hatch postgres]$ /opt/postgres/bin/psql -d postgres
psql (17.2)
Type "help" for help.postgres=# create table production(id int primary key, pname varchar, price int);
CREATE TABLE
postgres=# create table orders(o_id int primary key, p_id int references production(id), amount int);
CREATE TABLE
在备库查询,已经同步过来了。
[senllang@hatch ~]$ /opt/postgres/bin/psql -d postgres -p 5434
psql (17.2)
Type "help" for help.postgres=# \d
Did not find any relations.
postgres=# \dList of relationsSchema | Name | Type | Owner
--------+------------+-------+----------public | orders | table | senllangpublic | production | table | senllang
(2 rows)
主备模型已经部署完成。
三、带failover的逻辑复制部署
逻辑复制槽要达到failover的效果,要具备两方面的条件:
- 主备集群已经开启了复制槽的同步功能;
- 逻辑复制槽被指定了failover参数为true;也就是当复制槽为failover=true时,才可被备库同步;
这两个条件缺一不可,充分且必要,所以准备环节就这两个条件来对环境做分步的部署。
3.1 开启主备复制槽同步
首先要改造主备部署,让它支持复制槽的同步。
这一步必须是在使用带failover的复制槽之前,否则之前的复制槽不能被同步。
这里只需要修改备库参数即可。
配置复制槽的failover相关参数,在备份库pgAA1修改参数:
- hot_standby_feedback, 修改为 on, 备库可以反馈;
- sync_replication_slots, 修改为 on, 自动同步复制槽;
- primary_slot_name, 发送端的主复制槽,设置为备份时创建的复制槽 ‘slot_pri’;当然也可以手动添加;
[senllang@hatch postgres]$ /opt/postgres/bin/pg_ctl -D pgAA1/ -o "-p 5434 " -l logfile reload
server signaled
在修改完备库参数之后,使用reload让参数生效。
3.2 准备订阅库
下面开始逻辑复制的搭建,步聚与之前介绍方法一样。
首先是创建集簇pgB,这与初始化主库的方法一样,使用initdb初始化一个新的集簇,这里不再赘述。
- 订阅库
订阅库参数配置;
wal_level = logical
启动订阅库,这里指定订阅库监听端口为5433。
[senllang@hatch postgres]$ /opt/postgres/bin/pg_ctl -D pgB -o "-p 5433 " -l logfile start
waiting for server to start.... done
server started
3.3 建立逻辑复制
当然就是熟悉的发布与订阅的机制了。
- 创建发布
在主库创建order表上的条件发布,这里用法更递进一些,只订阅产品号为2的订单信息,因为订阅者就是2号商品的厂家,其它信息与它没有意义。
postgres=# create publication pub_orders for table orders WHERE ( p_id = 2);
CREATE PUBLICATION
- 创建订阅表
厂家的分析员要收集所有一级代理商的订单信息,这里有一个订单表。
厂家的订单表,可不像代理商需要记录所有商口,所以此处没有外键,因为只有一种商品,甚至可以不用订阅此字段。
postgres=# create table orders(o_id int primary key, p_id int , amount int);
CREATE TABLE
- 订阅
登陆5433端口的订阅库,创建订阅;这里需要打开订阅时使用的逻辑复制槽的failover开关,默认是关闭的。
postgres=# create subscription orders_2 CONNECTION 'host=127.0.0.1 dbname=postgres port=5432' publication pub_orders with (failover = true);
NOTICE: created replication slot "orders_2" on publisher
CREATE SUBSCRIPTION
到此,在主备部署下,又带了一个发布订阅的逻辑复制,整体部署就结束了。
3.4 复制槽自动同步
我们在只读的备库上查询一下复制槽的同步情况。
[senllang@hatch ~]$ /opt/postgres/bin/psql -d postgres -p 5434
psql (17.2)
Type "help" for help.postgres=# select slot_name, failover from pg_replication_slots ;slot_name | failover
-----------+----------orders_2 | t
(1 row)
可以看到刚才创建的逻辑复制槽已经同步到了备库,同样也可以在主库查询,主库应该有两个复制槽,只有orders_2打开了failover开关,所以才会被同步到了备库。
3.4 条件订阅
当代理商有新的订单产生时,厂家都会收到关于自己家商品的销售情况,进行实时分析,对产品生产计划做出实时调整,这一套流程成熟之后,可以应用AI来完成。不妙啊!又有岗位要被淘汰了。
赶紧看一下逻辑复制是否正常工作,主库模拟产生了两笔订单数据。
postgres=# insert into production values ( 1,'mobile phone'),(2,'labtop');
INSERT 0 2
postgres=# insert into orders values (1,2,200),(2,1,200);
INSERT 0 2
postgres=# select * from orders ;o_id | p_id | amount
------+------+--------1 | 2 | 2002 | 1 | 200
(2 rows)
然后在订阅库上查询,果然厂家立即就可以看到自己家的产品销售额。
postgres=# select * from orders ;o_id | p_id | amount
------+------+--------1 | 2 | 200
(1 row)
此时,备库上的数据与主库是保持完全一致的。
四、逻辑复制槽failover
到此,逻辑复制槽已经同步到了备库,理应整个演示要结束了。一般都会对于故障比较感兴趣,一定要眼见为实,下面就来看一下逻辑复制的failover。
- 主库故障
模拟主库发生了故障的情况,这里直接停止主库。
[senllang@hatch postgres]$ /opt/postgres/bin/pg_ctl -D pgA -l logfile stop
waiting for server to shut down.... done
server stopped
- 备库切换为新的主库
主备会先发生failover,因为是热备,所以直接将备库提升为新的主库,即可保障业务的连续运行。
[senllang@hatch postgres]$ /opt/postgres/bin/pg_ctl -D pgAA1/ -o "-p 5434 " -l logfile promote
waiting for server to promote.... done
server promoted
新主库拥有全量的用户数据,所以并不会发生数据的丢失情况。
- 逻辑复制failover
当主备发生切换之后,逻辑复制的订阅端也要切换订阅源了,因为逻辑复制信息以及逻辑复槽已经在新主库了,所以现在处理就比较简单了。
订阅库中修改订阅连接信息,更改为新主库的连接信息,端口为5434。
postgres=# alter subscription orders_2 connection 'host=127.0.0.1 dbname=postgres port=5434';
ALTER SUBSCRIPTION
- 验证订阅
为了验证逻辑复制的有效性,继续在新的主库上模拟产生一笔订单数据。
postgres=# insert into orders values(3,2,500);
INSERT 0 1
postgres=# select * from orders ;o_id | p_id | amount
------+------+--------1 | 2 | 2002 | 1 | 2003 | 2 | 500
(3 rows)
在订阅库上查看本厂商口的销售情况。
postgres=# select * from orders ;o_id | p_id | amount
------+------+--------1 | 2 | 2003 | 2 | 500
(2 rows)
咦,又多了一笔销售数据,金额还不小。
五、总结
逻辑复制槽的failover功能是PostgreSQL 17版本新增的功能,这也完善了逻辑复制的故障场景的处理策略,避免此场景下的变更数据丢失情况。
各位小伙伴get到了吗,也记得点个赞再走哟~
结尾
非常感谢大家的支持,在浏览的同时别忘了留下您宝贵的评论,如果觉得值得鼓励,请点赞,收藏,我会更加努力!
作者邮箱:study@senllang.onaliyun.com
如有错误或者疏漏欢迎指出,互相学习。
注:未经同意,不得转载!
相关文章:
【PostgreSQL使用】最新功能逻辑复制槽的failover,大数据下高可用再添利器
逻辑复制的failover 专栏内容: postgresql入门到进阶手写数据库toadb并发编程 个人主页:我的主页 管理社区:开源数据库 座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物. ✅ ὒ…...
【开源免费】基于SpringBoot+Vue.JS租房管理系统(JAVA毕业设计)
本文项目编号 T 102 ,文末自助获取源码 \color{red}{T102,文末自助获取源码} T102,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...
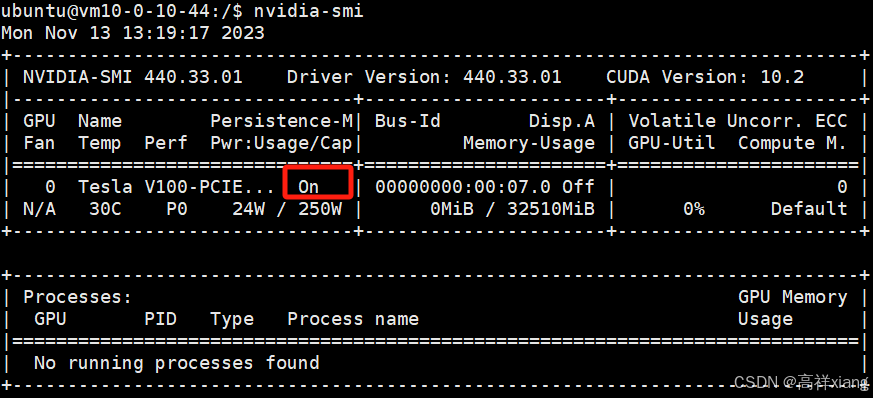
Linux下Nvidia显卡GPU开启驱动持久化
GPU开启驱动持久化的原因 GPU 驱动一直处于加载状态, 减少运行程序时驱动加载的延迟。不开启该模式时,在程序每次调用完 GPU 后, GPU 驱动都会被卸载,下次调用时再重新加载, 驱动频繁卸载加载, GPU 频繁被…...
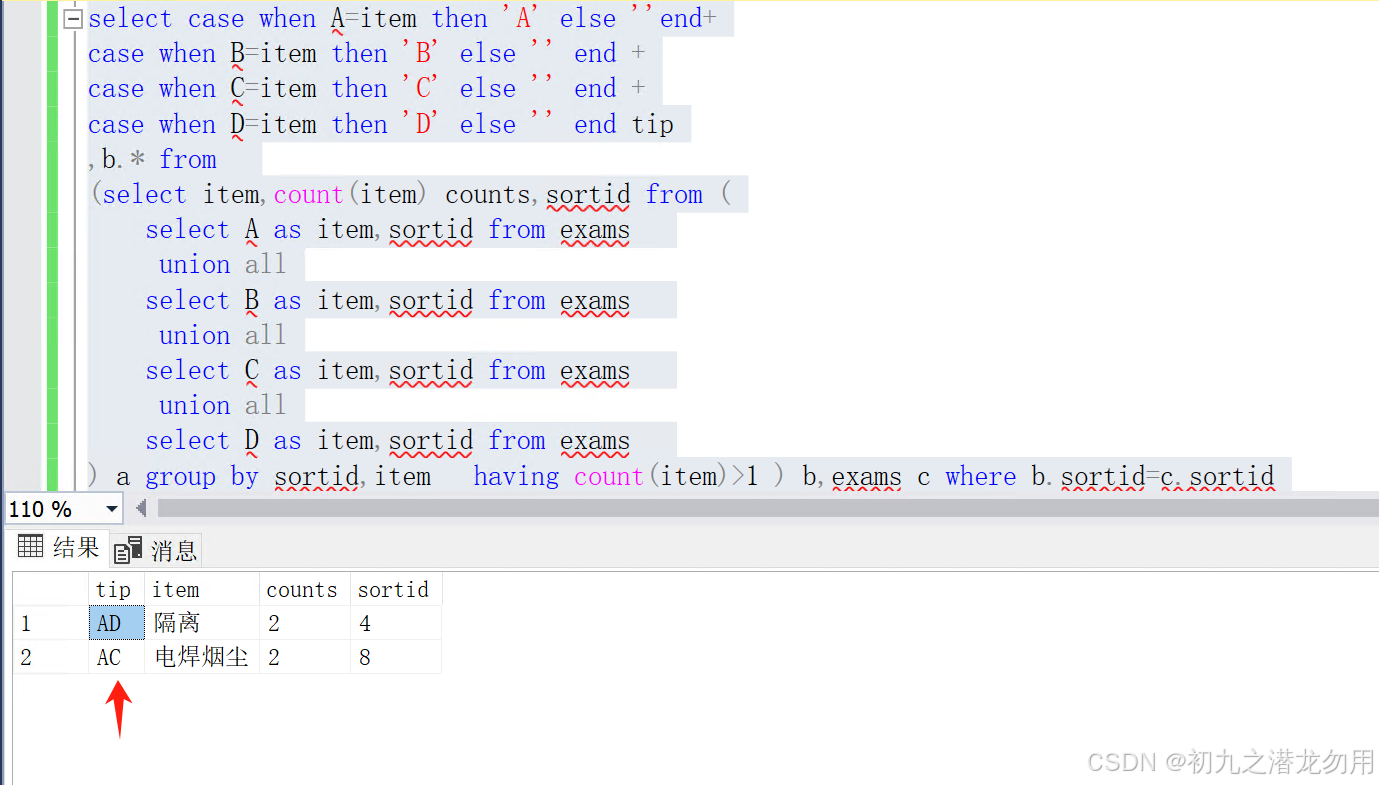
MS SQL Server 实战 排查多列之间的值是否重复
目录 需求 范例运行环境 数据样本设计 功能实现 上传EXCEL文件到数据库 SQL语句 小结 需求 在日常的应用中,排查列重复记录是经常遇到的一个问题,但某些需求下,需要我们排查一组列之间是否有重复值的情况。比如我们有一组题库数据&am…...
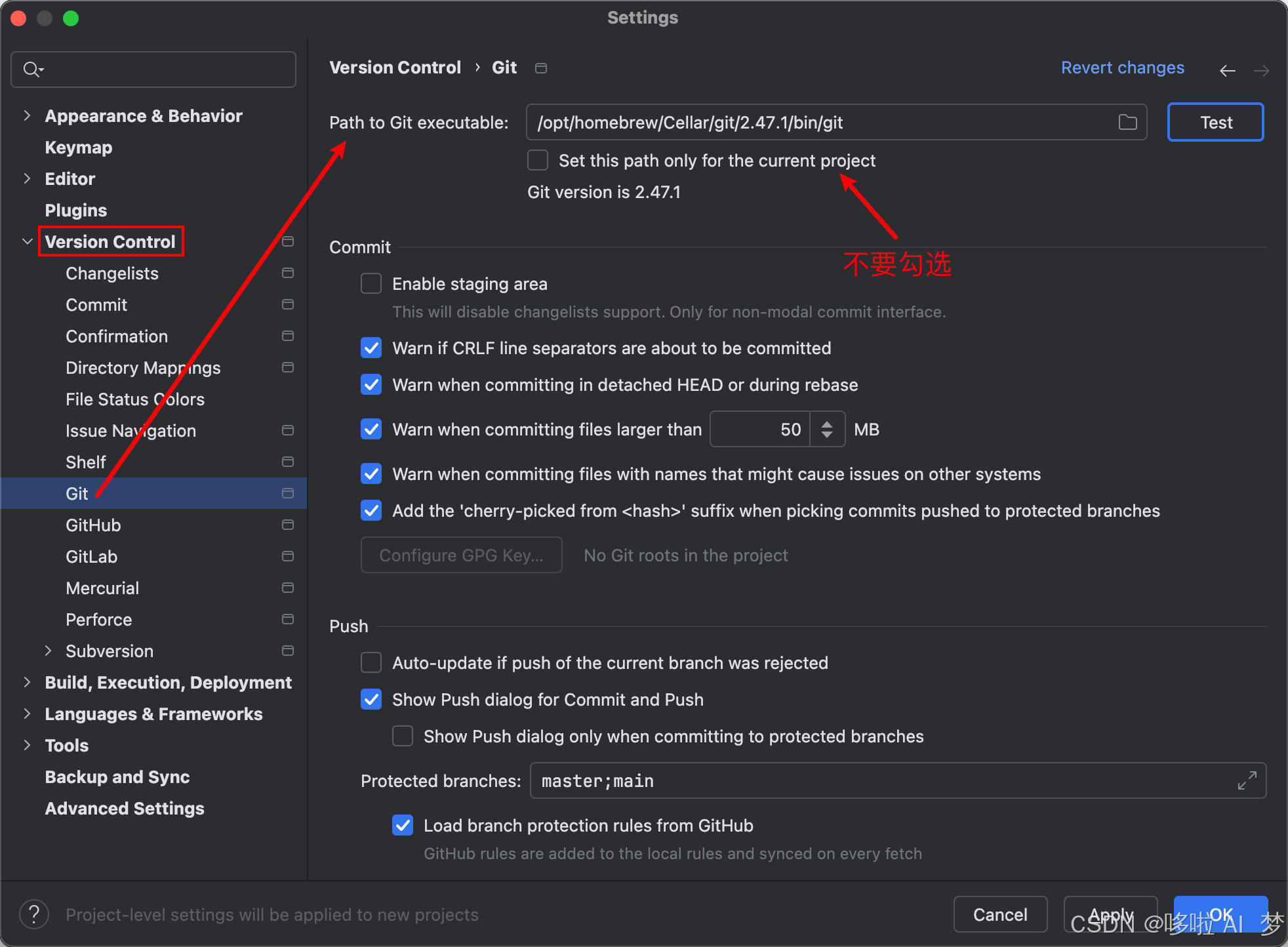
【玩转MacBook】Git安装
Git 官网也提到了MacBook 可以使用 Homebrew 安装 Git,所以在此使用 Homebrew 安装。 1、安装 Homebrew 执行安装脚本 在 Terminal 中执行如下命令: /bin/bash -c "$(curl -fsSL https://gitee.com/ineo6/homebrew-install/raw/master/install.…...
【优先算法】双指针 --(结合例题讲解解题思路)(C++)
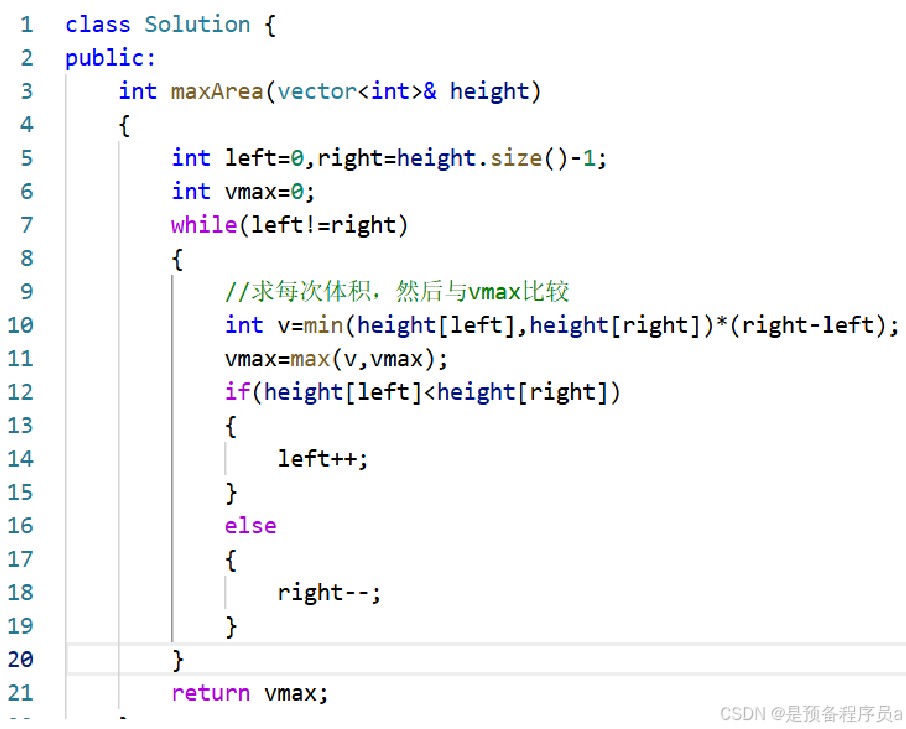
今日鸡汤: “无人负我青云志,我自踏雪至山巅。” -徐霞客《青云志》 释义:没有人能够帮助我实现我的理想,即使面对再大的困难,我也要踏着积雪,一步步,到达山巅。 目录 1.快乐数 2.盛最多的…...

简述css中z-index的作用?如何用定位使用?
z-index是一个css属性,用于控制元素的堆叠顺序, 如何使用定位用index 1、position:relative; z-index; 相对于自己来定位的,可以根据top,bottom,right,leftÿ…...

Redis——数据淘汰策略
文章目录 1. 引入2. 讲解2.1 Redis 中的 8 种数据淘汰策略2.2 LRU 和 LFU 算法2.3 建议 3. 总结 1. 引入 在 Redis——数据过期策略 的“引入”部分讲解过,Redis 的数据存在内存中,而内存容量相对较小,不能将大量数据 无限期 地缓存。然而&a…...
机器学习之KNN算法预测数据和数据可视化
机器学习及KNN算法 目录 机器学习及KNN算法机器学习基本概念概念理解步骤为什么要学习机器学习需要准备的库 KNN算法概念算法导入常用距离公式算法优缺点优点:缺点︰ 数据可视化二维界面三维界面 KNeighborsClassifier 和KNeighborsRegressor理解查看KNeighborsRegr…...
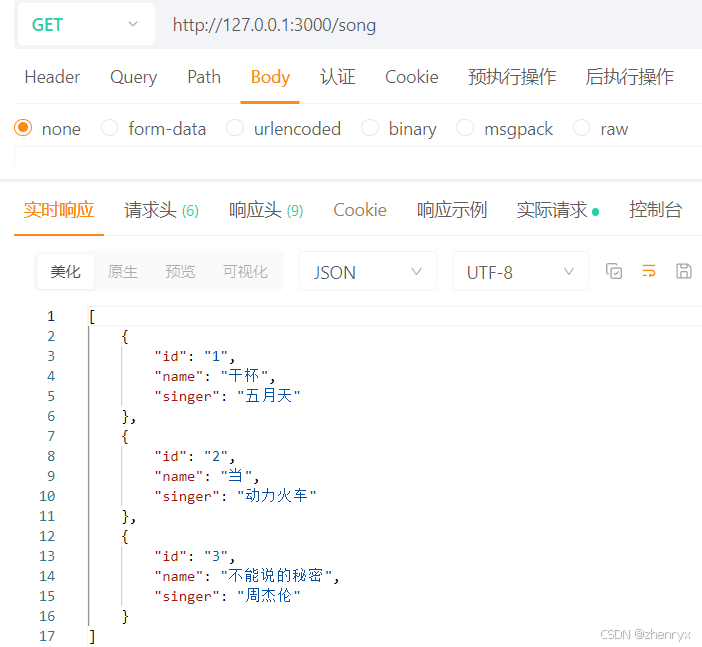
前端node.js
一.什么是node.js 官网解释:Node.js 是一个开源的、跨平台的 JavaScript 运行时环境。 二.初步使用node.js 需要区分开的是node.js和javascript互通的只有console和定时器两个API. 三.Buffer Buffer 是一个类似于数组的对象,用于表示固定长度的字节序列。 Buffer…...
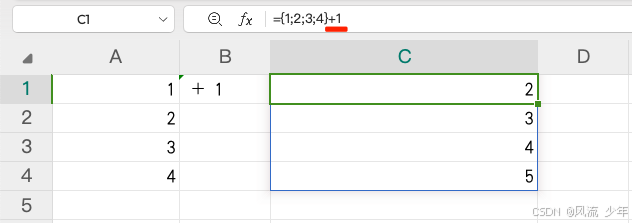
Excel基础知识
一:数组 一行或者一列数据称为一维数组,多行多列称为二维数组,数组支持算术运算(如加减乘除等)。 行:{1,2,3,4} 数组中的每个值用逗号分隔列:{1;2;3;4} 数组中的每个值用分号分隔行列…...

Spring Boot对访问密钥加密解密——RSA
场景 用户无需登录,仅仅根据给定的访问keyId和keySecret就可以访问接口。 keyId 等可以明文发送(不涉及机密),后端直接从请求头读取。keySecret 不可明文,需要加密后放在另一个请求头(或请求体࿰…...

Vue介绍
一、Vue框架简介 Vue.js是一个用于构建用户界面的渐进式JavaScript框架。它的核心库只关注视图层,易于上手,并且可以与其他库或现有项目进行整合。其特点包括响应式数据绑定、组件化开发和虚拟DOM等。 响应式数据绑定 Vue通过Object.defineProperty()方法来进行数据劫持。当…...
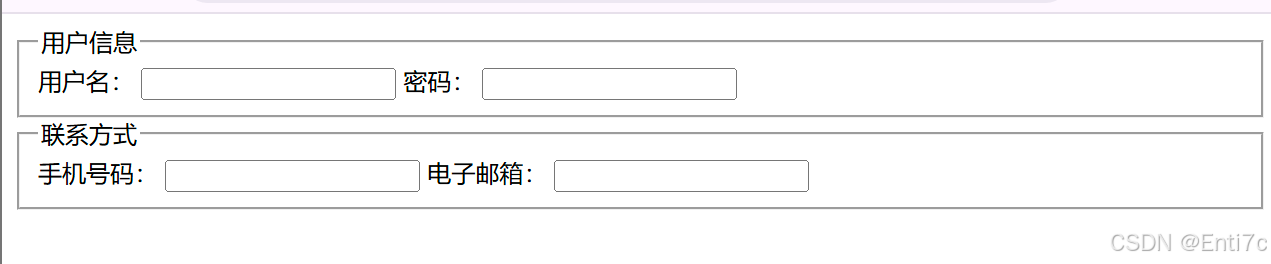
表单元素(标签)有哪些?
HTML 中的表单元素(标签)用于收集用户输入的数据,常见的有以下几种: 文本输入框 <input type"text">:用于单行文本输入,如用户名、密码等。可以通过设置maxlength属性限制输入字符数&…...
人工智能与云计算的结合:如何释放数据的无限潜力?
引言:数据时代的契机 在当今数字化社会,数据已成为推动经济与技术发展的核心资源,被誉为“21世纪的石油”。从个人消费行为到企业运营决策,再到城市管理与国家治理,每个环节都在生成和积累海量数据。然而,数…...

TCP Analysis Flags 之 TCP Out-Of-Order
前言 默认情况下,Wireshark 的 TCP 解析器会跟踪每个 TCP 会话的状态,并在检测到问题或潜在问题时提供额外的信息。在第一次打开捕获文件时,会对每个 TCP 数据包进行一次分析,数据包按照它们在数据包列表中出现的顺序进行处理。可…...

【MyBatis 核心工作机制】注解式开发与动态代理原理
有很多朋友可能已经在开发中熟练使用 MyBatis 或者刚开始学习 MyBatis,对于它的一些工作机制不太了解。“咦,怎么写几个注解,写几个配置文件,就能实现这些效果呢,好神奇呀!”当你看完这篇博客之后…...

深度学习在图像识别中的最新进展与实践案例
深度学习在图像识别中的最新进展与实践案例 在当今信息爆炸的时代,图像作为信息传递的重要载体,其处理与分析技术显得尤为重要。深度学习,作为人工智能领域的一个分支,凭借其强大的特征提取与模式识别能力,在图像识别…...

vue3中如何自定义插件
英译汉插件 i18n.ts export default {install: (app: any, options: any) > {// 注入一个全局可用的$translate()方法app.config.globalProperties.$translate (key: string) > {// 获取options对象的深层属性// 使用key作为索引return key.split(".").redu…...

【机器学习】回归
文章目录 1. 如何训练回归问题2. 泛化能力3. 误差来源4. 正则化5. 交叉验证 1. 如何训练回归问题 第一步:定义模型 线性模型: y ^ b ∑ j w j x j \hat{y} b \sum_{j} w_j x_j y^b∑jwjxj 其中,( w ) 是权重,( b )…...

Scio REPL交互式编程:快速原型开发和数据分析的终极指南
Scio REPL交互式编程:快速原型开发和数据分析的终极指南 【免费下载链接】scio A Scala API for Apache Beam and Google Cloud Dataflow. 项目地址: https://gitcode.com/gh_mirrors/sc/scio Scio REPL交互式编程是Apache Beam和Google Cloud Dataflow的Sca…...

使用Spring AI Alibaba构建智能体Agent倥
背景 在软件开发的漫长旅途中,"构建"这个词往往让人又爱又恨。爱的是,一键点击,代码变成产品,那是程序员最迷人的时刻;恨的是,维护那一堆乱糟糟的构建脚本,简直是噩梦。 在很多项目中…...

智能抖音批量下载工具:自动化无水印资源获取的高效解决方案
智能抖音批量下载工具:自动化无水印资源获取的高效解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

突破性解决方案:用cursor-free-vip开源工具解锁Cursor Pro功能的深度解析
突破性解决方案:用cursor-free-vip开源工具解锁Cursor Pro功能的深度解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...

提升JSON处理效率的三个核心技巧:使用VS Code插件优化开发流程
提升JSON处理效率的三个核心技巧:使用VS Code插件优化开发流程 【免费下载链接】vscode-json Json for Visual Studio Code 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-json 在现代软件开发中,JSON作为数据交换的标准格式,其…...

如何快速激活Windows和Office:KMS_VL_ALL_AIO新手指南
如何快速激活Windows和Office:KMS_VL_ALL_AIO新手指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO KMS_VL_ALL_AIO是一款开源的智能激活脚本工具,专为Windows和Office…...

如何高效下载小红书无水印内容?XHS-Downloader让内容采集效率提升3倍
如何高效下载小红书无水印内容?XHS-Downloader让内容采集效率提升3倍 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品…...
遣)
AI开发-python-langchain框架(--AI 直接生成并执行 Python 代码 )遣
指令替换 项目需求:将加法指令替换为减法 项目目录如下 /MyProject ├── CMakeLists.txt # CMake 配置文件 ├── build/ #构建目录 │ └── test.c #测试编译代码 └── mypass2.cpp # pass 项目代码 一,测试代码示例 test.c // test.c…...

番茄小说下载器完整指南:3种方法永久保存你喜爱的小说
番茄小说下载器完整指南:3种方法永久保存你喜爱的小说 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 番茄小说下载器是一个功能强大的开源工具,专门用于批量下载和…...

3种高效方法:快速部署BetterNCM插件管理器
3种高效方法:快速部署BetterNCM插件管理器 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer BetterNCM-Installer是一款专为网易云音乐客户端设计的插件管理器,提…...