深度学习blog- 数学基础(全是数学)
矩阵:矩阵是一个二维数组,通常由行和列组成,每个元素可以通过行索引和列索引进行访问。
张量:张量是一个多维数组的抽象概念,可以具有任意数量的维度。除了标量(0D张量)、向量(1D张量)和矩阵(2D张量)外,张量还可以表示更高维度的数组。例如,一个3x3x2的三维张量
它是标量、向量、矩阵的高维扩展,属于一个数据容器。
张量由三个概念定义:
轴的个数(阶)
形状(shape):为一个整数元组,表示张量沿每个轴的维度大小(元素个数)。
数据类型(dtype):这是整个张量中数据元素的数据类型,张量的类型可以是 float32 、 uint8 、 float64 等。
向量,是由n个数,构成的有序数组。有n个数,就有n维,称之为n维向量。向量可以横着写,称之为行向量,也可以竖着写,称之为列向量。向量是一种特殊的矩阵。
向量之中的数,称之为该向量的分量,但是这些数,必须以有序的方式排列。为什么要以有序的方式呢?是因为数是有其特定内涵的。
而列向量是可以通过转置,变成行向量,行向量也可以通过转置变成列向量。
而如果所有的分量,都是0,称之为零向量。

矩阵A可逆,A必须是方阵(行数与列数相等的矩阵)。一个矩阵可逆的必要条件是它的行列式不为0,而行列式只对方阵定义。因此,只有方阵才有可能是可逆的。
如果n阶方阵A有n个线性无关的特征向量,那么矩阵A可以被相似对角化,且存在一个对角矩阵D(对角线上的元素是特征值)和一个可逆矩阵P(列是特征向量),使得:

这说明A与对角矩阵D相似。若特征向量的数量小于n,A就不能被对角化。
什么是矩阵的特征分解?
矩阵的特征分解是指将一个方阵表达为特征向量和特征值的组合形式。具体来说,对于一个n×n的可对角化矩阵A,有:

其中,D是一个对角矩阵,其对角线上的元素是A的特征值,而P是一个由A的特征向量构成的矩阵。
矩阵的特征分解实质上是一种矩阵的相似对角化形式,它表达矩阵的性质及其在特征向量基下的行为。
特征分解可以被视为一种特定的相似变换,其中主要关注的是特征值和对应特征向量。
求矩阵行列式和特征向量,逆矩阵、正交矩阵、伴随矩阵
高斯-约当消元法(初等变换法):
通过初等行变换(交换行或线性计算)将矩阵转换为行最简形式(单位矩阵)。
同时对这些变换应用到单位矩阵上,最终得到的矩阵就是原矩阵的逆矩阵。
适用于任何可逆矩阵,但计算过程可能较为繁琐。
行列式法:
对于2x2矩阵,可以直接通过计算其行列式及其逆行列式来写出逆矩阵。
对于3x3或更高阶的矩阵,可以使用克莱姆法则来求解,但计算量通常较大。
需要注意的是,行列式为零的矩阵不可逆。
伴随矩阵法:
首先计算原矩阵的行列式。
如果行列式不为零,则计算原矩阵的每个元素的代数余子式。
将代数余子式矩阵转置,得到原矩阵的伴随矩阵。
最后,根据公式“逆矩阵 = 1/行列式 * 伴随矩阵”来计算逆矩阵。
矩阵分解法:
如LU分解、QR分解、特征值分解和奇异值分解(SVD)等。
这些方法将矩阵分解为更简单的矩阵形式,然后分别对这些矩阵求逆,最后将得到的逆矩阵相乘得到原矩阵的逆。
适用于大规模矩阵或稀疏矩阵,计算更为稳定和高效。
上三角矩阵的行列式计算非常直接,主要是找出对角线上元素的乘积。
NumPy库中的矩阵运算
首先确保你安装了NumPy库,如果没有安装,可以通过以下命令安装:
pip install numpy
import numpy as np # 创建一个全0的3x3矩阵
zero_matrix = np.zeros((3, 3))
print("全0矩阵:\n", zero_matrix) # 初始化一个上三角矩阵
upper_triangle = np.triu(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]))
print("上三角矩阵:\n", upper_triangle) # 初始化一个下三角矩阵
lower_triangle = np.tril(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]))
print("下三角矩阵:\n", lower_triangle) # 初始化单位矩阵
identity_matrix = np.eye(3)
print("单位矩阵:\n", identity_matrix)#a. 求矩阵的行列式
import numpy as np # 创建一个2x2矩阵
A = np.array([[4, 2], [3, 1]]) # 计算行列式
det_A = np.linalg.det(A)
print("行列式:", det_A) #b. 矩阵的转置
# 矩阵转置
A_transpose = A.T
print("转置矩阵:\n", A_transpose) #c. 矩阵的逆
# 计算逆矩阵
inv_A = np.linalg.inv(A)
print("逆矩阵:\n", inv_A)#d. 特征分解
# 特征值和特征向量
eigenvalues, eigenvectors = np.linalg.eig(A)
print("特征值:", eigenvalues)
print("特征向量:\n", eigenvectors)#e. 矩阵的仿射变换(例如线性变换)
# 线性变换
B = np.array([1, 2]) # 输入向量
affine_transform = np.dot(A, B)
print("仿射变换结果:", affine_transform)
PyTorch库中的矩阵运算
确保你安装了PyTorch,这里使用的是CPU版本,如果你有GPU,可以选择相应版本:
pip install torch
import numpy as np
import torch # PyTorch中的张量初始化
# 创建一个全0的3x3张量
zero_tensor = torch.zeros((3, 3))
print("全0张量:\n", zero_tensor) # 创建一个上三角张量
upper_triangle_tensor = torch.triu(torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]]))
print("上三角张量:\n", upper_triangle_tensor) # 创建一个下三角张量
lower_triangle_tensor = torch.tril(torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]]))
print("下三角张量:\n", lower_triangle_tensor) # 创建一个单位张量
identity_tensor = torch.eye(3)
print("单位张量:\n", identity_tensor) # 创建一个具有随机值的3x3张量
random_tensor = torch.rand((3, 3))
print("随机张量:\n", random_tensor) # 创建一个全1的3x3矩阵
ones_matrix = np.ones((3, 3))
print("全1矩阵:\n", ones_matrix) #a. 张量转置
# 创建一个张量
A_torch = torch.tensor([[4, 2], [3, 1]]) # 张量的转置
A_transpose_torch = A_torch.t()
print("转置张量:\n", A_transpose_torch)#b. 张量的逆
# 计算逆张量
inv_A_torch = torch.inverse(A_torch.float())
print("逆张量:\n", inv_A_torch)#c. 特征分解
# 特征值和特征向量
eigenvalues_torch, eigenvectors_torch = torch.linalg.eigvals(A_torch.float())
print("特征值:\n", eigenvalues_torch)
print("特征向量:\n", eigenvectors_torch) #d. 张量重塑 (view)
# 创建一个3x4的张量
C = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]) # 重塑为2x6的张量
C_view = C.view(2, 6)
print("重塑后的张量:\n", C_view) #e. 张量的广播和加法
# 创建两个张量
D = torch.tensor([[1, 2, 3], [4, 5, 6]]) # 张量加法
E = D + 10 # 广播机制
print("加法结果:\n", E) #其他常见运算
#a. 张量的散射(scatter)# 创建一个全0的3x5张量
F = torch.zeros(3, 5) # 确保索引在范围内
# 这里的indices需要在0到5之间,因为F有5列
indices = torch.tensor([[0, 1, 2], [0, 1, 2]]) # 合法索引
values = torch.tensor(np.ones((2, 3)), dtype=torch.float32) # 创建一个全1的2x3张量 # 尝试通过scatter_函数进行散射
# 1. 使用整数常量进行散射
F.scatter_(0, indices, 2) # 在第0维(行)进行散射
print("散射结果(使用常量2):\n", F) # 2. 使用values进行散射
F.scatter_(1, indices, values) # 在第1维(列)上进行散射
print("散射结果(使用values):\n", F) # 第一个参数表示维度,如果0表示行,那么第二个参数张量中的元素值表示行索引,元素所在的列表示列索引,
# 如果第一个参数是1,那么那么第二个参数张量中的元素值表示列索引,元素所在的行表示行索引,
# 用第三个参数去填充,如果第三个参数是张量,则从第三个参数张量中,取与第二参数张量相同位置的元素作为填充数据# unsqueeze 用于在指定维度上增加一个维度。它的常见用法包括:1将一维张量转换为二维张量。2在需要维度匹配时,调整张量的形状。
x = torch.tensor([1, 2, 3]) # 形状为 (3,)
y = x.unsqueeze(0) # 形状变为 (1, 3)
z = x.unsqueeze(1) # 形状变为 (3, 1)
还有两个函数在张量的处理和变换中非常常用:
view 用于更改张量的形状,而不改变数据。
cat 用于将多个张量在指定维度上连接成一个新的张量。
- tensor.view(shape): 张量重塑
函数功能
view 函数用于重塑张量的形状,不过它不改变张量的实际数据,只是改变它的表示方式。这个操作是包含在 PyTorch 的计算图中,因此它是可微分的。
变换规则
必须满足条件:重塑后的大小必须等于原始张量的元素总数。你不能随意改变张量的大小;重塑后的形状的元素个数必须等于重塑前的元素个数。
支持负值:使用 -1 可以让 PyTorch 自动推断该维度的大小。例如,如果你想重塑一个张量为二维张量,而不知道其中一维的大小,可以用 view 函数中的 -1 作为占位符,PyTorch 会自动计算出相应的维度。
示例代码
import torch # 创建一个一维张量
x = torch.tensor([1, 2, 3, 4, 5, 6]) # 原始张量的形状
print("原始张量形状:", x.shape) # 重塑为2行3列
y = x.view(2, 3)
print("重塑为2x3张量的形状:", y.shape) # 使用-1自动推断大小
z = x.view(-1, 2) # 把第一个维度自动推断为3,因为6/2=3
print("重塑为3x2张量的形状:", z.shape) # 打印重塑后的张量内容
print("重塑后的张量:\n", z)
- torch.cat(tensors, dim): 张量拼接
函数功能
cat 函数用于将多个张量沿指定的维度拼接(连接)在一起。这个函数用于组合多个张量,而不是改变张量的维度。
变换规则
维度一致:除了拼接的维度外,其他维度的大小必须相等。也就是说,拼接的张量在拼接维度之外的所有维度上都需要有相同的长度。
拼接维度:dim 参数指定了在哪个维度上进行拼接。0 代表按照行拼接,1 代表按照列拼接。
import torch # 创建两个相同维度的张量
a = torch.tensor([[1, 2, 3], [4, 5, 6]])
b = torch.tensor([[7, 8, 9], [10, 11, 12]]) # 打印原始张量
print("张量A:\n", a)
print("张量B:\n", b) # 沿第0维(行)拼接
c = torch.cat((a, b), dim=0)
print("沿第0维拼接的结果:\n", c) # 沿第1维(列)拼接
d = torch.cat((a, b), dim=1)
print("沿第1维拼接的结果:\n", d)

以下是一些常用的 PyTorch 张量操作函数:
a. 张量创建
torch.zeros(size):创建全0张量。
torch.ones(size):创建全1张量。
torch.empty(size):创建未初始化的张量。
torch.rand(size):创建随机值张量。
torch.eye(n):创建单位矩阵。
b. 张量形状操作
tensor.view(shape):重塑张量。
tensor.unsqueeze(dim):在指定维度上增加一个维度。
tensor.squeeze(dim):去除指定维度的大小为1的维度。
tensor.permute(dims):改变张量的维度顺序。
torch.cat(tensors, dim):沿指定维度拼接多个张量。
c. 张量运算
torch.matmul(a, b):矩阵乘法。
torch.add(a, b):张量加法。
torch.subtract(a, b):张量减法。
torch.multiply(a, b):张量逐元素相乘。
torch.divide(a, b):张量逐元素相除。
d. 张量统计
tensor.mean(dim):计算均值。
tensor.sum(dim):计算和。
tensor.max(dim):计算最大值。
tensor.min(dim):计算最小值。
e. 张量索引与切片
tensor[index]:索引单个元素。
tensor[start:end]:切片操作。
f. 其他操作
transpose(dim0, dim1):交换两个维度。
transpose(-2, -1)交换最后两个维度,负数表示从里层开始算,正数表示从外层开始算。
torch.stack(tensors, dim):在新维度上堆叠多个张量。
tensor.clone():克隆一个张量。
泛化误差可分解为偏差、方差与噪声。
偏差:度量了模型算法的计算值与真值的偏离程度,反映模型算法的拟合能力。
方差:度量了同样大小的训练集的变动所导致的学习性能的变化,数据扰动所造成的影响。
噪声:表达了在当前任务上任何学习算法所能够达到的期望泛化误差的下界,即学习问题本身的难度。
1、训练集的错误率较小,而验证集/测试集的错误率较大,说明模型存在较大方差,可能出现了过拟合(未考虑到所有情况)。
2、训练集和测试集的错误率都较大,且两者相近,说明模型存在较大偏差,可能出现了欠拟合(算法不合适)。
3、训练集和测试集的错误率都较小,且两者相近,说明方差和偏差都较小,这个模型效果比较好,这是我们追求的。
损失函数,度量了模型算法的计算值与真值的误差,
1 均方误差(Mean Squared Error, MSE)
定义:MSE 是回归问题中常用的损失函数,其计算方式为预测值与真实值之间差异的平方的平均值。
公式:
用途:广泛应用于回归问题,能够惩罚大误差(因为平方),但对异常值敏感。
2 交叉熵损失(Cross-Entropy Loss)
定义:交叉熵损失主要用于分类问题,尤其是多分类和二分类问题。它衡量了真实分布与预测分布之间的差异。
公式:

对于多分类:
广泛应用于分类问题,尤其是深度学习模型中的神经网络。
3 绝对误差(Mean Absolute Error, MAE)
定义:MAE 是另一种常用的回归损失函数,计算预测值与真实值之间绝对差的平均值。
公式:

梯度:求导数或偏导数
梯度下降法:往梯度方向的相反方向更新参数。
1、动量梯度下降(Gradient Descent with Momentum)
动量梯度下降的核心理念是,通过引入动量来加速梯度下降,提高收敛速度,尤其在高曲率的区域中。动量使得参数更新不仅依赖于当前的梯度,还与之前的梯度有关系。

总结动量梯度下降的公式

2、RMSProp(Root Mean Square Prop)
RMSProp是由Geoff Hinton提出的一种自适应学习率的梯度下降方法,它通过计算梯度的平方的指数衰减平均值来调整学习率。这种方法在处理稀疏梯度和不同特征尺度时表现出色。
计算过程:

总结RMSProp的公式

动量梯度下降:通过引入历史梯度的动量,加快收敛速度,尤其在坡度较大的位置。
RMSProp:通过对每个参数的梯度平方进行指数加权平均,自适应调整学习率,有效应对稀疏数据和不同特征尺度的问题。
3、Adam算法
Adam(Adaptive Moment Estimation)优化算法结合了动量法(Momentum)和RMSProp算法的优点,能够自适应地调整每个参数的学习率。
算法步骤:

Adam更新公式总结:
参数更新的最终公式为:

防止过拟合的方法:
正则化,即在损失函数中加入一个正则化项(惩罚项),惩罚模型的复杂度,防止网络过拟合。
Droupout:随机的对神经网络每一层进行丢弃部分神经元操作。保证损失函数是单调下降的droupout才会有效。
数据增强,
指通过剪切、旋转/反射/翻转变换、缩放变换、平移变换、尺度变换、对比度变换、噪声扰动、颜色变换等一种或多种组合数据增强变换的方式来增加数据集的大小。
降维算法:
降维(Dimensionality Reduction)是机器学习中用来减少数据集特征数量的技术,其目的是在尽可能保留原始数据信息的同时降低数据的复杂度。降维不仅可以加速模型训练、减少计算资源消耗,还能帮助消除噪声、提高模型性能,并且有助于可视化高维数据。
- 主成分分析 (PCA)
通过对数据进行线性变换,找到新的正交基(主成分),以便在保留数据中最大方差的同时减少维度。PCA通过主成分分析找到数据的主要变化方向。
通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的k个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。
由于得到协方差矩阵的特征值特征向量有两种方法:特征值分解协方差矩阵、奇异值分解协方差矩阵,所以PCA算法有两种实现方法:基于特征值分解协方差矩阵实现PCA算法、基于SVD分解协方差矩阵实现PCA算法。
步骤

import numpy as np
from scipy import linalg
from sklearn.datasets import load_irisX,y = load_iris(return_X_y = True)
# 1、去中心化
B = X - X.mean(axis = 0)
B[:5]# 2、协方差
# 方差是协方差特殊形式
# 协方差矩阵
V = np.cov(B,rowvar=False,bias = True)
print(V)
# 3、协方差矩阵的特征值和特征向量
# 特征值和特征向量矩阵的概念
eigen,ev = np.linalg.eig(V)# 4、降维标准,2个特征,选取两个最大的特征值所对应的特征的特征向量
# 百分比,计算各特征值,占权重,累加可以
cond = (eigen/eigen.sum()).cumsum() >= 0.98
index = cond.argmax()
ev = ev[:,:index + 1]# 5、进行矩阵运算
pca_result = B.dot(ev)# 6、标准化
pca_result = (pca_result -pca_result.mean(axis = 0))/pca_result.std(axis = 0)
pca_result[:5]
import numpy as np
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris# 加载数据
data = load_iris()
X = data.data# PCA 降维到2维
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)print("降维后的数据:\n", X_reduced)
- 线性判别分析 (LDA)
LDA 是一种监督学习的方法,适用于分类问题。LDA 的目标在于通过最大化类间散度与类内散度之比,找到最佳的特征子空间,以区分不同类别的样本。
步骤

from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA # 加载数据
data = load_iris()
X = data.data
y = data.target # LDA 降维
lda = LDA(n_components=2)
X_reduced = lda.fit_transform(X, y) print("LDA 降维后的数据:\n", X_reduced)- 核主成分分析 (KPCA)
KPCA 是 PCA 的扩展,通过使用核函数将数据映射到高维空间,在新的特征空间中执行 PCA,以捕捉数据中的非线性结构。
步骤

from sklearn.datasets import load_iris
from sklearn.decomposition import KernelPCA # 加载数据
data = load_iris()
X = data.data # KPCA 降维到2维
kpca = KernelPCA(n_components=2, kernel='rbf')
X_reduced = kpca.fit_transform(X) print("KPCA 降维后的数据:\n", X_reduced)
- 局部线性嵌入 (LLE)
LLE是一种非线性降维算法,假设数据点可以通过其最近邻的线性组合表示。LLE致力于保持这种局部线性结构。
步骤

from sklearn.manifold import LocallyLinearEmbedding # 加载数据
data = load_iris()
X = data.data # LLE 降维到2维
lle = LocallyLinearEmbedding(n_components=2, n_neighbors=10)
X_reduced = lle.fit_transform(X) print("LLE 降维后的数据:\n", X_reduced)
- t-分布随机邻域嵌入 (t-SNE)
t-SNE 是一种基于概率的降维方法,旨在保留相似数据点之间的距离关系,特别适合用于数据可视化。它通过将高维空间中的数据点相似性转换为低维表示。
步骤

from sklearn.manifold import TSNE # 加载数据
data = load_iris()
X = data.data # t-SNE 降维到2维
tsne = TSNE(n_components=2, random_state=42)
X_reduced = tsne.fit_transform(X) print("t-SNE 降维后的数据:\n", X_reduced)
- 自编码器 (Autoencoder)
自编码器是一种神经网络架构,旨在通过编码和解码结构来学习高效的低维表示,无监督学习的方式进行数据降维。网络的中间层实现降维。
步骤
构建自编码器:定义一个编码器(将输入压缩到隐藏层)和解码器(从隐藏层重构输入)。
训练网络:使用重构误差(如均方误差)作为损失函数进行训练。
提取表示:使用训练好的编码器将输入数据映射到低维空间。
import numpy as np
from keras.layers import Input, Dense
from keras.models import Model # 构造自编码器
input_dim = 4 # 输入数据维度
encoding_dim = 2 # 降维后的维度 # 输入层
input_data = Input(shape=(input_dim,))
# 编码层
encoded = Dense(encoding_dim, activation='relu')(input_data)
# 解码层
decoded = Dense(input_dim, activation='sigmoid')(encoded) # 自编码器模型
autoencoder = Model(input_data, decoded)
autoencoder.compile(optimizer='adam', loss='mean_squared_error') # 训练自编码器
data = load_iris().data
autoencoder.fit(data, data, epochs=100, batch_size=10) # 获取编码器部分
encoder = Model(input_data, encoded)
X_reduced = encoder.predict(data) print("自编码器降维后的数据:\n", X_reduced)
- 随机投影 (Random Projection)
随机投影是基于Johnson-Lindenstrauss引理的一种简单而高效的降维方法。它通过将高维数据乘以一个随机生成的低维投影矩阵,将数据保留在低维空间中。
步骤

from sklearn.random_projection import GaussianRandomProjection
from sklearn.datasets import load_iris # 加载数据
data = load_iris()
X = data.data # 随机投影降维到2维
rp = GaussianRandomProjection(n_components=2)
X_reduced = rp.fit_transform(X) print("随机投影降维后的数据:\n", X_reduced)
- 多维尺度分析 (MDS)
原理
MDS是一种基于距离矩阵的降维方法,它试图保持原始空间中数据点之间的距离关系。在新的低维空间中,各点之间的距离尽可能接近原始空间中的距离。
步骤
计算距离矩阵:输入数据点之间的距离(或相似度)。
多维尺度映射:通过经典的MDS算法,将距离矩阵转换为低维坐标。
优化:最小化指定的损失函数(如应保留的距离差)。
from sklearn.manifold import MDS # 加载数据
data = load_iris()
X = data.data # 使用MDS降维到2维
mds = MDS(n_components=2, random_state=42)
X_reduced = mds.fit_transform(X) print("MDS 降维后的数据:\n", X_reduced)
- Isomap
Isomap 是一种保持测地距离的非线性降维方法。它结合了经典的多维尺度分析和最短路径算法,捕捉数据在高维空间中的内在几何形状。
步骤
构建邻接图:确定每个点的 k 个最近邻,形成图。
计算最短路径:使用 Dijkstra 算法计算所有点对之间的最短路径。
构建距离矩阵:形成新的距离矩阵。
应用经典 MDS:对新的距离矩阵使用经典 MDS 进行降维。
from sklearn.manifold import Isomap # 加载数据
data = load_iris()
X = data.data # 使用 Isomap 降维到2维
isomap = Isomap(n_components=2, n_neighbors=5)
X_reduced = isomap.fit_transform(X) print("Isomap 降维后的数据:\n", X_reduced)
激活函数



相关文章:
深度学习blog- 数学基础(全是数学)
矩阵:矩阵是一个二维数组,通常由行和列组成,每个元素可以通过行索引和列索引进行访问。 张量:张量是一个多维数组的抽象概念,可以具有任意数量的维度。除了标量(0D张量)、向量(…...

最后100米配送
1. 项目概述 1.1 项目目标 集成无人机与电动车:设计并实现将无人机固定在电动车上,利用电动车的电源进行飞行,实现高楼内部从电动车位置到用户办公/居住地点的最后100米精准配送。低成本实现:通过利用电动车现有的电源和结构&am…...
Linux的进程替换以及基础IO
进程替换 上一篇草率的讲完了进程地址空间的组成结构和之间的关系,那么我们接下来了解一下程序的替换。 首先,在进程部分我们提过了,其实文件可以在运行时变成进程,而我们使用的Linux软件其实也是一个进程,所以进一步…...

《计算机网络A》单选题-复习题库
1. 计算机网络最突出的优点是(D) A、存储容量大B、将计算机技术与通信技术相结合C、集中计算D、资源共享 2. RIP 路由协议的最大跳数是(C) A、13B、14C、15D、16 3. 下面哪一个网络层次不属于 TCP/IP 体系模型(D&a…...

闲谭Scala(2)--安装与环境配置
1. 概述 Java开发环境安装,需要两步,第一安装JDK,第二配置环境变量。 Scala的话,也是两步,第一安装Scale环境,第二配置环境变量。 需要注意的是,配置环境变量,主要是想让windows操…...
Python基于卷积神经网络的车牌识别系统开发与实现
1. 简介 车牌识别是人工智能在交通领域的重要应用,广泛用于高速违章检测、停车场管理和智能交通系统等场景。本系统通过基于卷积神经网络(CNN)的深度学习算法,结合 Python 和 MySQL 实现车牌的快速识别与管理。 系统特点&#x…...
)
Spring Boot集成Netty创建一个TCP服务器,接收16进制数据(自定义解码器和编码器)
Netty Netty是一个高性能、异步事件驱动的网络应用程序框架,它提供了对并发和异步编程的抽象,使得开发网络应用程序变得更加简单和高效。 在Netty中,EventLoopGroup是处理I/O操作的多线程事件循环器。在上面的示例中,我们创建了两个EventLoopGroup实例:bossGroup和worker…...

Python 中的 with open:文件操作的最佳实践
在 Python 中,文件操作是最常用的一项任务,无论是读取文件内容,还是将数据写入文件。传统的文件操作方式使用 open() 和 close() 函数来处理文件,但在实际开发中,我们推荐使用 with open() 语句来进行文件操作。本文将…...

哪些框架、软件、中间件使用了netty? 哪些中间件、软件底层使用了epoll?
使用 Netty 的软件、中间件和框架 Netty 是一个异步事件驱动的网络应用框架,广泛应用于构建高性能的网络应用程序。以下是一些使用了 Netty 的知名软件、中间件和框架: 1. Elasticsearch 描述:Elasticsearch 是一个分布式的搜索和分析引擎…...
AI 智能助手对话系统
一个基于 React 和 Tailwind CSS 构建的现代化 AI 对话系统,提供流畅的用户体验和丰富的交互功能。 项目链接:即将开放… 功能特点 🤖 智能对话:支持与 AI 助手实时对话,流式输出回答📁 文件处理ÿ…...
2024年秋词法分析作业(满分25分)
【问题描述】 请根据给定的文法设计并实现词法分析程序,从源程序中识别出单词,记录其单词类别和单词值,输入输出及处理要求如下: (1)数据结构和与语法分析程序的接口请自行定义;类别码需按下表格…...

Docker镜像瘦身:从1.43G到22.4MB
Docker镜像瘦身:从1.43G到22.4MB 背景1、创建项目2、构建第一个镜像3、修改基础镜像4、多级构建5、使用Nginx背景 在使用 Docker 时,镜像大小至关重要。我们从 create-react-app (https://reactjs.org/docs/create-a-new-react-app.html)获得的样板项目通常都超过 1.43 GB…...
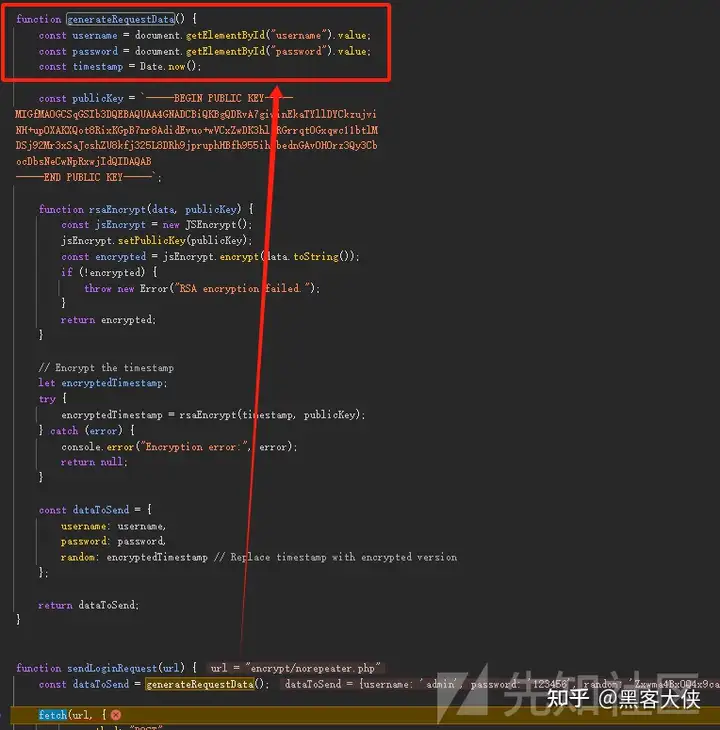
前端加解密对抗encrypt-labs
前言 项目地址:https://github.com/SwagXz/encrypt-labs 作者:SwagXz 现在日子越来越不好过了,无论攻防、企业src还是渗透项目,总能看到大量的存在加密的网站,XZ师傅的前端加密靶场还是很值得做一做的,环…...
)
Android Notification 问题:Invalid notification (no valid small icon)
问题描述与处理策略 1、问题描述 java.lang.RuntimeException: Unable to start activity ComponentInfo{com.my.notifications/com.my.notifications.MainActivity}: java.lang.IllegalArgumentException: Invalid notification (no valid small icon): Notification(chan…...

Python爬虫教程——7个爬虫小案例(附源码)_爬虫实例
本文介绍了7个Python爬虫小案例,包括爬取豆瓣电影Top250、猫眼电影Top100、全国高校名单、中国天气网、当当网图书、糗事百科段子和新浪微博信息,帮助读者理解并实践Python爬虫基础知识。 包含编程资料、学习路线图、源代码、软件安装包等!【…...

Log4j2的Policies详解、SizeBasedTriggeringPolicy、TimeBasedTriggeringPolicy
文章目录 一、Policies二、SizeBasedTriggeringPolicy:基于文件大小的滚动策略2.1、文件达到指定大小就归档 三、TimeBasedTriggeringPolicy:基于时间间隔的滚动策略3.1、验证秒钟归档场景3.2、验证分钟场景3.3、验证小时场景 四、多策略组合使用五、扩展知识5.1、S…...

ES中查询中参数的解析
目录 query中参数match参数match_allmatch:匹配指定参数match_phrase query中其他的参数query_stringprefix前缀查询:wildcard通配符查询:range范围查询:fuzzy 查询: 组合查询bool参数mustmust_notshould条件 其他参数 query中参数 词条查询term:它仅匹配在给定字段…...
学习笔记:使用 pandas 和 Seaborn 绘制柱状图
学习笔记:使用 pandas 和 Seaborn 绘制柱状图 前言 今天在使用 pandas 对数据进行处理并在 Python 中绘制可视化图表时,遇到了一些关于字体设置和 Seaborn 主题覆盖的小问题。这里将学习到的方法和注意事项做个总结,以便之后的项目中可以快…...

【每日学点鸿蒙知识】placement设置top、组件携带自定义参数、主动隐藏输入框、Web设置字体、对话框设置全屏宽
1、popup组件placement设置top没有生效? 可以用offset属性将popup往下边偏移一下 来规避 2、组件携带自定义参数的接口是哪个? 参考链接:https://developer.huawei.com/consumer/cn/doc/harmonyos-references-V5/ts-universal-attributes-…...
后端开发-Maven
环境说明: windows系统:11版本 idea版本:2023.3.2 Maven 介绍 Apache Maven 是一个 Java 项目的构建管理和理解工具。Maven 使用一个项目对象模型(POM),通过一组构建规则和约定来管理项目的构建…...

Tsuru容器网络终极性能测试指南:7大CNI插件深度对比与优化策略
Tsuru容器网络终极性能测试指南:7大CNI插件深度对比与优化策略 【免费下载链接】tsuru Open source and extensible Platform as a Service (PaaS). 项目地址: https://gitcode.com/gh_mirrors/ts/tsuru Tsuru作为开源可扩展的PaaS平台,其容器网络…...

MATLAB App Designer打包实战:从GUI到独立安装包的完整部署指南
1. MATLAB App Designer打包前的准备工作 第一次把MATLAB开发的GUI程序打包成独立安装包时,我踩了不少坑。记得当时给合作方演示算法,对方电脑没有MATLAB环境,只能干着急。后来花了三天时间才搞明白整个打包流程,现在把这些经验系…...
)
解决pnpm安装esbuild时ELIFECYCLE错误的3种方法(附详细步骤)
彻底解决pnpm安装esbuild时ELIFECYCLE错误的实战指南 最近在Vite项目中使用pnpm安装esbuild时,不少开发者遇到了令人头疼的ELIFECYCLE错误。这个错误通常伴随着exit code 1,导致构建流程突然中断。作为一名长期使用pnpm的前端工程师,我深刻理…...

基于单细胞测序技术的细胞通讯分析方法及其应用
一、细胞通讯与单细胞测序技术的研究意义多细胞生物由不同类型的细胞构成一个开放的社会。在这一社会中,单个细胞之间必须协调其行为,因此建立有效的通讯联络机制至关重要。细胞通讯是指一个细胞发出的信息通过介质传递至另一个细胞,并引发相…...
)
SEO_新手必看的SEO优化入门教程与核心方法(271 )
SEO优化入门教程:新手必看的核心方法 在当今的数字时代,搜索引擎优化(SEO)已经成为了每一个想要在互联网上站稳脚跟的人必不可少的技能。无论你是一个小企业的网站管理员,还是一个内容创作者,了解和掌握SE…...

【Git 内部原理】`.git` 是怎么记住所有版本的
每次 git commit,Git 都说"已记录"。但你有没有想过:改了几十次、几百次,Git 是怎么全记住的?难道每次提交,它都复制一份完整项目? 这篇文章不讲命令,也不背概念。 我们直接打开…...

百度网盘直链解析技术:突破下载限制的Python解决方案
百度网盘直链解析技术:突破下载限制的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在数字资源共享日益频繁的今天,百度网盘作为国内主…...

WSL2 子系统配置 SSH 并实现 VSCode 远程开发
1. 为什么要在WSL2中配置SSH服务? 作为一个长期使用WSL2进行开发的程序员,我发现直接通过终端操作WSL2虽然方便,但在某些场景下还是存在局限性。比如当需要同时管理多个项目时,终端窗口切换就显得不够高效;再比如团队协…...

企业级消息保留技术实现:3大核心机制深度解析与完整部署方案
企业级消息保留技术实现:3大核心机制深度解析与完整部署方案 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitc…...

AnimateDiff问题解决手册:常见生成问题与提示词调整方案
AnimateDiff问题解决手册:常见生成问题与提示词调整方案 1. 常见视频生成问题诊断 1.1 视频卡顿或跳帧问题 当生成的视频出现卡顿或帧间不连贯时,通常与以下因素有关: 显存不足:虽然优化版最低支持8G显存,但复杂场…...