【YOLOv5】源码(common.py)
该文件位于/models/common.py,提供了构建YOLOv5模型的各种基础模块,其中包含了常用的功能模块,如自动填充autopad函数、标准卷积层Conv、瓶颈层Bottleneck、C3、SPPF、Concat层等
参考笔记:【YOLOv3】 源码(common.py)-CSDN博客
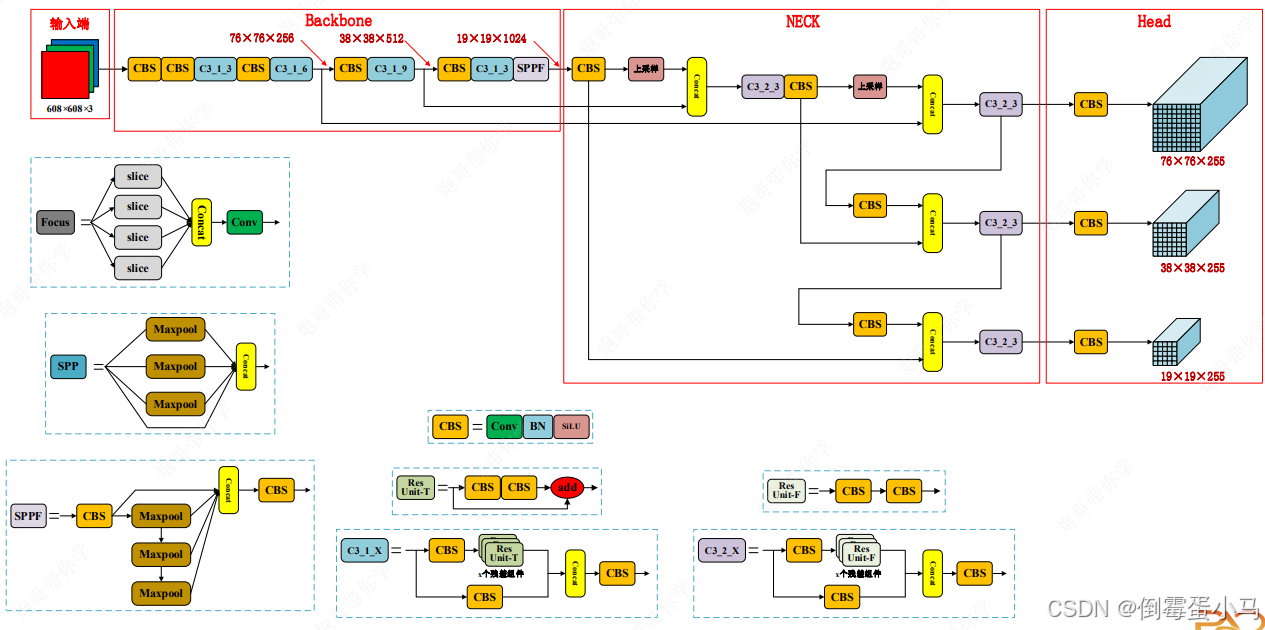
YOLOv5网络结构图
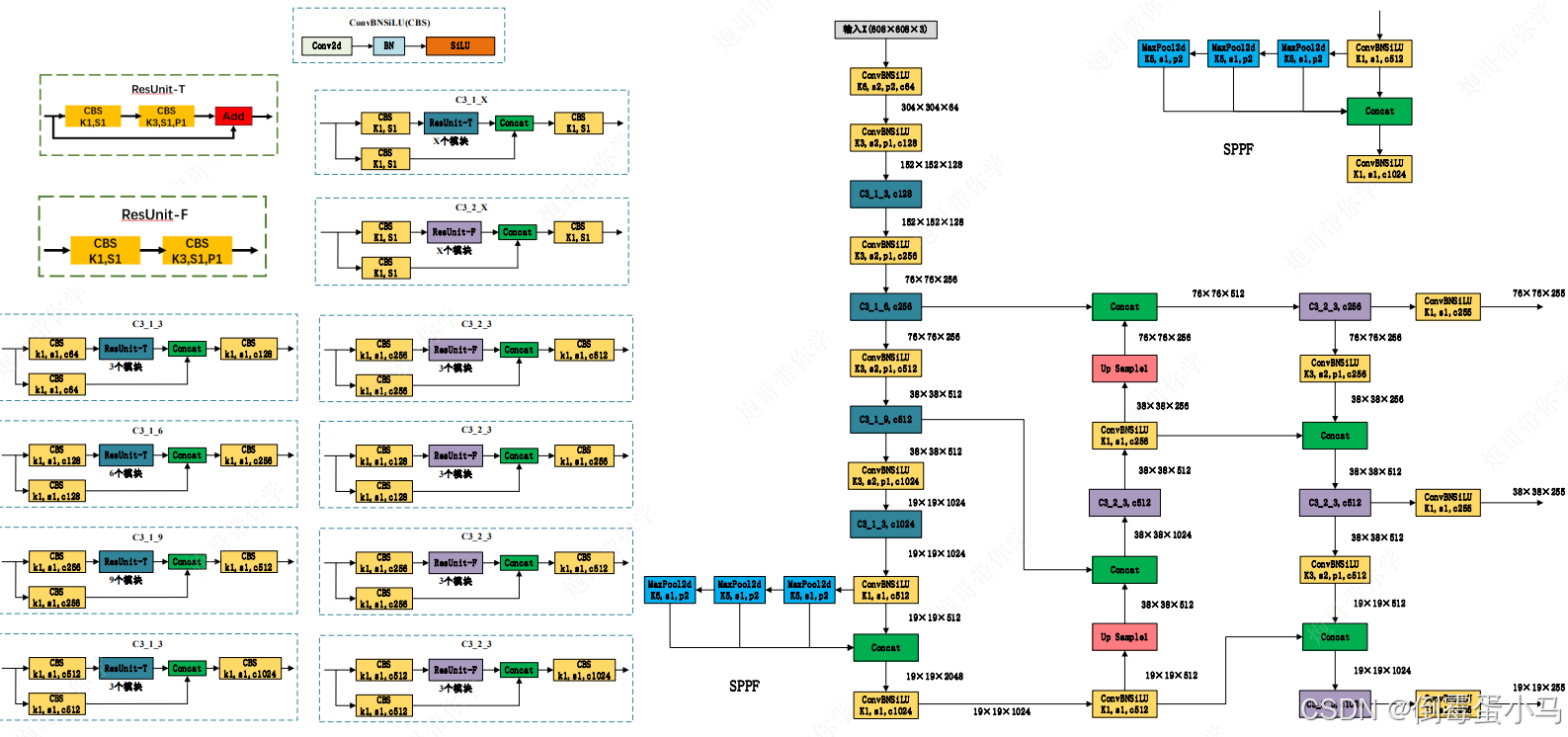
YOLOv5网络参数图
目录
1.自动填充(autopad函数)
2.标准卷积层(Conv类)
3.瓶颈层(Bottleneck类)
4.C3
5.SPPF
6.Concat层
1.自动填充(autopad函数)
该函数根据kernel_size自动计算需要填充的padding,使得输入和输出尺寸一致,需要注意的是使用这个自动填充函数时stride必须为1
'''
为卷积层自动计算填充Padding,保证输入和输出尺寸不变
k:kernel_size
p:padding
'''
def autopad(k, p=None):#如果未提供p,则进行自动填充if p is None:#如果k是整数,计算填充为k // 2;如果k是列表或其他可迭代对象,计算每个元素的填充为x // 2p = k // 2 if isinstance(k, int) else [x // 2 for x in k]#自动填充return p#返回计算的填充值2.标准卷积层(Conv类)
YOLOv5中主要有两种卷积,分别是下采样卷积、保持特征图尺寸不变的卷积
- 下采样卷积
YOLOv5的下采样卷积常用的是kernel_size=3,stride=2,padding=1,经过该下采样卷积层输出尺寸减半,通道数翻倍
YOLOv5中还有一种下采样卷积是kernel_size=6,stride=2,padding=2,同样经过该下采样卷积层输出尺寸减半,通道数翻倍,但是该下采样卷积在YOLOv5中只使用了1次
- 保持特征图尺寸不变的卷积
YOLOv5该类卷积使用的是kernel_size=1,stride=1,padding=0,经过该卷积层输出尺寸不变
下图是两种卷积在Backbone中的使用:
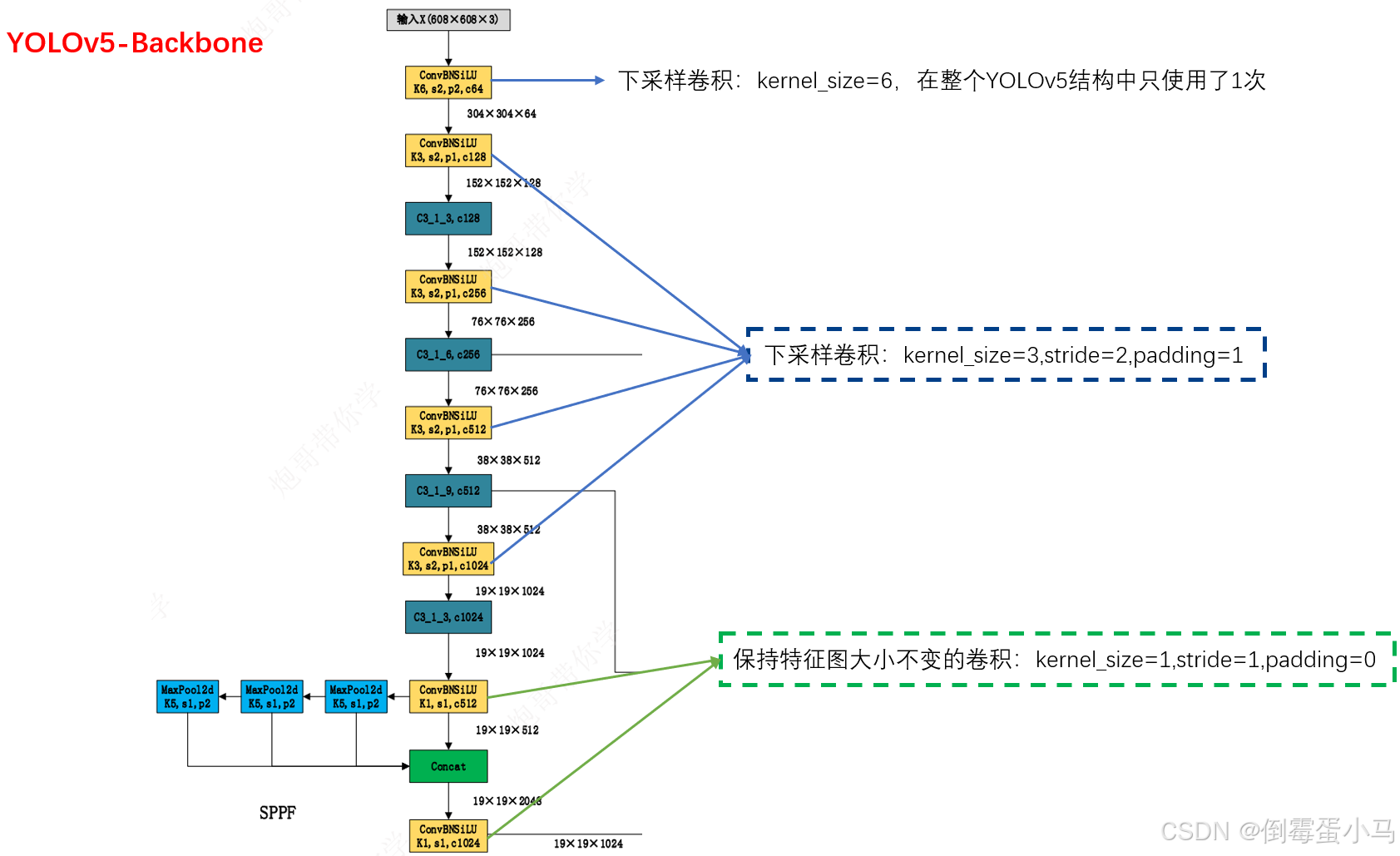
YOLOv5结构图中的CBS、ConvBNSiLU即由Conv类实现
'Conv即为YOLOv5中的CBS、ConvBNSiLU模块实现'
class Conv(nn.Module):#标准卷积模块def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):''':params c1: in_channle:params c2: out_channel:params k: kernel_size:params s: stride:params p: padding:params g: 卷积的groups数 =1就是普通的卷积 >1就是深度可分离卷积,也就是分组卷积:params act: 激活函数类型 True就是SiLU() False就是不使用激活函数类型是nn.Module就使用传进来的激活函数类型'''super().__init__()#定义卷积层,自动计算填充,禁用偏置以配合批归一化层self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)#定义批归一化层,归一化输出self.bn = nn.BatchNorm2d(c2)#定义激活函数,默认为SiLUself.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())#训练时的前向传播,卷积->归一化->激活def forward(self, x):return self.act(self.bn(self.conv(x)))#推理时的前向传播def forward_fuse(self, x):#直接通过卷积和激活函数,省略批归一化以提高推理速度return self.act(self.conv(x))3.瓶颈层(Bottleneck类)
YOLOv5网络结构中ResUnit-T、ResUnit-F即由Bottleneck实现,T、F可以理解为是否开启残差连接
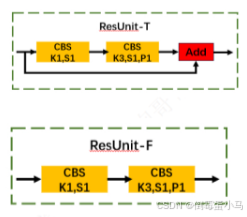
YOLOv5中的ResUnit-T、ResUnit-F
该类包括两个卷积层(CBS模块)和一个可选的shortcut(残差)连接,如果shortcut为True且in_channel=out_channel,则在输出中添加原始输入,实现残差连接。这样可以帮助模型在深层网络中缓解梯度消失问题,提高训练稳定性和模型性能
'即YOLOv5中的ResUnit组件,该函数将ResUnit-T和ResUnit-F集成到一起'
class Bottleneck(nn.Module):# 标准瓶颈层,常用于减少参数并提高模型的计算效率def __init__(self, c1, c2, shortcut=True, g=1, e=0.5):super().__init__()''':params c1: in_channle:params c2: out_channel:params shortcut: 是否开启残差连接,如果启用,则原始输入x会与经过两个卷积层之后的输出相加:params g: 卷积的groups数 =1就是普通的卷积 >1就是深度可分离卷积,也就是分组卷积:params e: 通道扩展比例,决定第一个卷积的输出通道数。扩展比例为'e',则第一个卷积的输出通道数为 `e * c2`'''#根据扩展比例计算第一个卷积的输出通道数c_ = int(c2 * e)# 第一个卷积层:1x1卷积,将输入通道数 `c1` 缩减到 `c_`,减少计算量self.cv1 = Conv(c1, c_, 1, 1)# 第二个卷积层:3x3卷积,将通道数从 `c_` 恢复到 `c2`,用于特征提取self.cv2 = Conv(c_, c2, 3, 1, g=g)#如果启用shortcut连接,且输入和输出通道数相同(c1 == c2),则创建shortcut连接#shortcut连接有助于缓解深层网络中的梯度消失问题self.add = shortcut and c1 == c2 #如果启用shortcut且输入输出通道数相同,shortcut为True#前向传播def forward(self, x):#如果add为True,则返回残差连接结果if self.add:return x + self.cv2(self.cv1(x))#如果add为False,仅返回卷积后的输出return self.cv2(self.cv1(x))
Bottleneck不是简单的类似于ResNet中的跳跃连接机制,而是其增强版本,其中涉及了压缩和拓展提高相应效率
跳跃连接类似于一个项目管理团队需要完成一个复杂的任务,团队中有人已经有了基本的解决方案(输入信息)。跳跃连接就像保留了这个基本解决方案,同时允许团队成员对其进行优化。如果最终的优化方案有问题,原始的解决方案仍然可以用作备选
Bottleneck 进一步优化了这个过程。团队会先对已有的解决方案进行压缩处理(1x1 卷积),提取最重要的部分(删除冗余)。然后团队成员进行深入的讨论(3x3 卷积),生成更详细的解决方案。最终,这个优化过的方案会与原始方案一起汇总,形成最终输出
这种流程既节省了资源(减少计算量),又提高了效率(保留原始信息,提取更深层特征)
4.C3
YOLOv5中有两种C3模块,分别是C3_1_X,C3_2_X,其中X指的是该C3模块中有多少个ResUnit组件
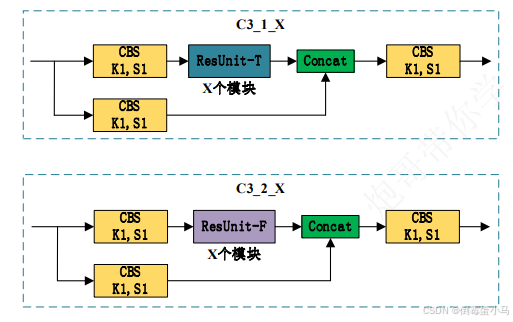
C3_1_X、C3_2_X结构
'C3模块,该函数将C3_1_X和C3_2_X集成到一起'
class C3(nn.Module):# CSP(Cross Stage Partial)瓶颈结构,带有3个卷积层def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):super().__init__()''':param c1:in_channel:param c2:out_channel:param n:n个Bottleneck模块(ResUnit组件):param shortcut:Bottleneck是否开启残差连接:param g::param e:通道扩展比例'''# 根据扩展比例计算两个分支上第一个卷积层的输出通道数c_ = int(c2 * e)#第一分支的1x1卷积层,用于降维self.cv1 = Conv(c1, c_, 1, 1)#第二分支的1x1卷积层,用于降维self.cv2 = Conv(c1, c_, 1, 1)#创建`n`个Bottleneck层(ResUnit组件),使用nn.Sequential进行顺序连接self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])#concat之后的1x1卷积层,输出通道数为c2self.cv3 = Conv(2 * c_, c2, 1)#前向传播过程def forward(self, x):branch_1=self.m(self.cv1(x))#第一个分支的前向传播branch_2=self.cv2(x)#第二个分支的前向传播return self.cv3(torch.cat((branch_1,branch_2),dim=1))#两个分支拼接之后再做最后一次卷积5.SPPF
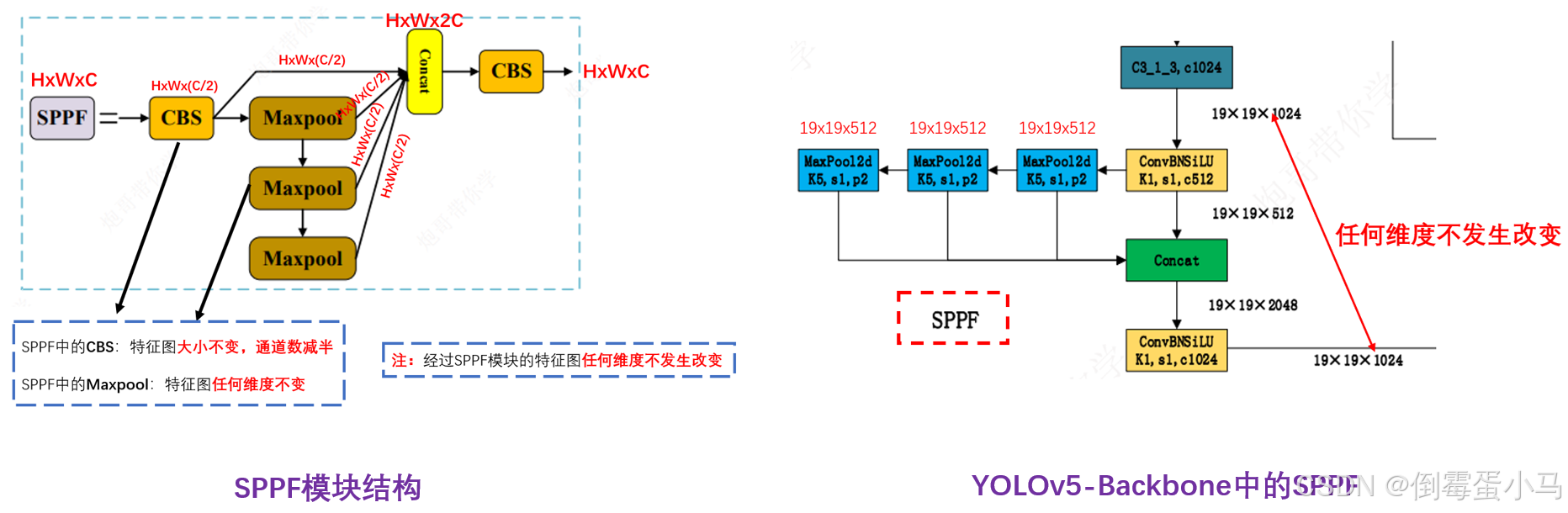
'SPPF模块'
class SPPF(nn.Module):def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))super().__init__()''':param c1:in_channel:param c2:out_channel:param k:最大池化层的卷积核大小,默认为5'''#第一个卷积层的输出通道数为c1//2c_ = c1 // 2#第一个卷积层self.cv1 = Conv(c1, c_, 1, 1)#第二个卷积层,将拼接后的通道数转换为输出通道数c2self.cv2 = Conv(c_ * 4, c2, 1, 1)#最大池化层,kernel_size=k,stride=1,padding=k//2self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)#前向传播def forward(self, x):x = self.cv1(x)#通过第一层卷积处理输入特征图y1 = self.m(x)#第一次最大池化y2 = self.m(y1)#第二次最大池化y3 = self.m(y2)#第三次最大池化#将原始特征图和3次池化的结果进行拼接,然后通过第二层卷积进行处理return self.cv2(torch.cat([x, y1, y2,y3], 1))
6.Concat层
这个类的作用是将不同层的特征图进行合并,增强特征表示,从而进一步提高模型的预测能力
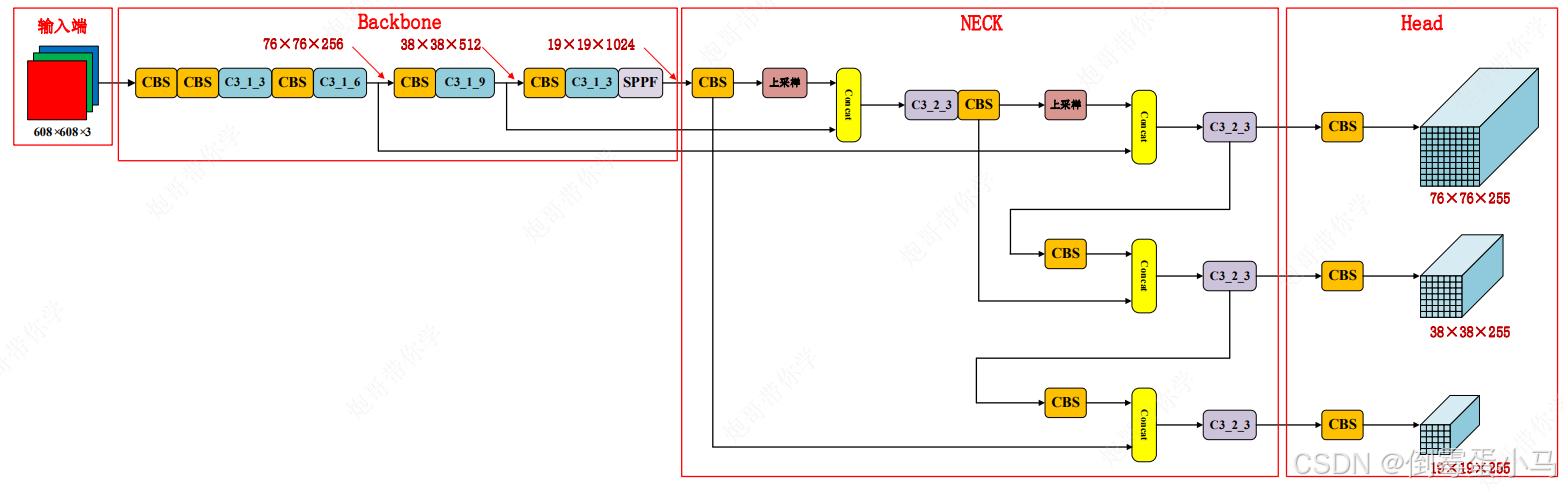
如YOLOv5网络结构图中黄色部分,Concat操作主要发生在Neck阶段,配合完成YOLOv5颈部的FPN+PAN流程
class Concat(nn.Module):#该类实现了沿指定维度连接多个张量的功能def __init__(self, dimension=1):super().__init__()''':param dimension:指定特征拼接的维度,默认为1,即在第一个维度(通常是通道维度)上进行特征拼接。'''self.d = dimension #保存要连接的维度,默认为1#前向传播方法,执行张量连接操作def forward(self, x):''':param x: x是一个张量列表,存放来自不同层的特征图张量,除拼接维度外,特征图的其他维度需要相同'''return torch.cat(x, self.d)#使用torch.cat沿self.d维度连接输入的张量列表x相关文章:
【YOLOv5】源码(common.py)
该文件位于/models/common.py,提供了构建YOLOv5模型的各种基础模块,其中包含了常用的功能模块,如自动填充autopad函数、标准卷积层Conv、瓶颈层Bottleneck、C3、SPPF、Concat层等 参考笔记:【YOLOv3】 源码(common.py…...

Node 如何生成 RSA 公钥私钥对
一、引入crypto模块 crypto 为node 自带模块,无需安装 const crypto require(crypto);二、封装生成方法 async function generateRSAKeyPair() {return new Promise((resolve, reject) > {crypto.generateKeyPair(rsa, {modulusLength: 2048, // 密钥长度为 …...

瑞_Linux中部署配置Java服务并设置开机自启动
文章目录 背景Linux服务配置步骤并设置开机自启动附-Linux服务常用指令 🙊 前言:由于博主在工作时,需要将服务部署到 Linux 服务器上运行,每次通过指令启动服务非常麻烦,所以将 jar 包部署的服务设置开机自启动&#x…...

javaEE-多线程进阶-JUC的常见类
juc:指的是java.util.concurrent包,该包中加载了一些有关的多线程有关的类。 目录 一、Callable接口 FutureTask类 参考代码: 二、ReentrantLock 可重入锁 ReentrantLock和synchronized的区别: 1.ReentantLock还有一个方法:…...

Flume拦截器的实现
Flume conf文件编写 vim file_to_kafka.conf#定义组件 a1.sources r1 a1.channels c1#配置source a1.sources.r1.type TAILDIR a1.sources.r1.filegroups f1 a1.sources.r1.filegroups.f1 /Users/zhangjin/model/project/realtime-flink/applog/log/app.* # 设置断点续传…...
:操作符 Operator)
Swift Combine 学习(四):操作符 Operator
Swift Combine 学习(一):Combine 初印象Swift Combine 学习(二):发布者 PublisherSwift Combine 学习(三):Subscription和 SubscriberSwift Combine 学习(四&…...

leetcode 173.二叉搜索树迭代器栈绝妙思路
以上算法题中一个比较好的实现思路就是利用栈来进行实现,以下方法三就是利用栈来进行实现的,思路很好,很简练。进行next的时候,先是一直拿到左边的子树,直到null为止,这一步比较好思考一点,下一…...
, ‘Buyer‘]).sum())
df.groupby([pd.Grouper(freq=‘1M‘, key=‘Date‘), ‘Buyer‘]).sum()
df.groupby([pd.Grouper(freq1M, keyDate), Buyer]).sum() 用于根据特定的时间频率和买家(Buyer)对 DataFrame 进行分组,然后计算每个分组的总和。下面是对这行代码的逐步解释: df.groupby([...]):这个操作会根据传入的…...

LLM - 使用 LLaMA-Factory 部署大模型 HTTP 多模态服务 (4)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/144881432 大模型的 HTTP 服务,通过网络接口,提供 AI 模型功能的服务,允许通过发送 HTTP 请求,交互…...
icp备案网站个人备案与企业备案的区别
个人备案和企业备案是在进行ICP备案时需要考虑的两种不同情况。个人备案是指个人拥有的网站进行备案,而企业备案则是指企业或组织名下的网站进行备案。这两者在备案过程中有一些明显的区别。 首先,个人备案相对来说流程较为简单。个人备案只需要提供个人…...

如何不修改模型参数来强化大语言模型 (LLM) 能力?
前言 如果你对这篇文章感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。 大语言模型 (Large Language Model, LLM, e.g. ChatGPT) 的参数量少则几十亿,多则上千亿,对其的训…...

AF3 AtomAttentionEncoder类的init_pair_repr方法解读
AlphaFold3 的 AtomAttentionEncoder 类中,init_pair_repr 方法方法负责为原子之间的关系计算成对表示(pair representation),这是原子转变器(atom transformer)模型的关键组成部分,直接影响对蛋白质/分子相互作用的建模。 init_pair_repr源代码: def init_pair_repr(…...

DDoS攻击防御方案大全
1. 引言 随着互联网的迅猛发展,DDoS(分布式拒绝服务)攻击成为了网络安全领域中最常见且危害严重的攻击方式之一。DDoS攻击通过向目标网络或服务发送大量流量,导致服务器过载,最终使其无法响应合法用户的请求。本文将深…...

Vue中常用指令
一、内容渲染指令 1.v-text:操作纯文本,用于更新标签包含的文本,但是使用不灵活,无法拼接字符串,会覆盖文本,可以简写为{{}},{{}}支持逻辑运算。 用法示例: //把name对应的值渲染到…...

Servlet解析
概念 Servlet是运行在服务端的小程序(Server Applet),可以处理客户端的请求并返回响应,主要用于构建动态的Web应用,是SpringMVC的基础。 生命周期 加载和初始化 默认在客户端第一次请求加载到容器中,通过反射实例化…...

带虚继承的类对象模型
文章目录 1、代码2、 单个虚继承3、vbptr是什么4、虚继承的多继承 1、代码 #include<iostream> using namespace std;class Base { public:int ma; };class Derive1 :virtual public Base { public:int mb; };class Derive2 :public Base { public:int mc; };class Deri…...

深度学习中的离群值
文章目录 深度学习中有离群值吗?深度学习中的离群值来源:处理离群值的策略:1. 数据预处理阶段:2. 数据增强和鲁棒模型:3. 模型训练阶段:4. 异常检测集成模型: 如何处理对抗样本?总结…...

如何利用Logo设计免费生成器创建专业级Logo
在当今的商业世界中,一个好的Logo是品牌身份的象征,它承载着公司的形象与理念。设计一个专业级的Logo不再需要花费大量的金钱和时间,尤其是当我们拥有Logo设计免费生成器这样的工具时。接下来,让我们深入探讨如何利用这些工具来创…...
)
Mysql SQL 超实用的7个日期算术运算实例(10k)
文章目录 前言1. 加上或减去若干天、若干月或若干年基本语法使用场景注意事项运用实例分析说明2. 确定两个日期相差多少天基本语法使用场景注意事项运用实例分析说明3. 确定两个日期之间有多少个工作日基本语法使用场景注意事项运用实例分析说明4. 确定两个日期相隔多少个月或多…...

运算指令(PLC)
加 ADD 减 SUB 乘 MUL 除 DIV 浮点运算 整数运算...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 [特殊字符]
Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 🚀 【免费下载链接】spring-cloud-aws The New Home for Spring Cloud AWS 项目地址: https://gitcode.com/gh_mirrors/sp/spring-cloud-aws Spring Cloud AWS 是一个强大的开源框架&…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

Hirschmann RS20-0800M4M4SDAE工业以太网交换机
Hirschmann RS20-0800M4M4SDAE 工业以太网交换机产品特点:端口配置:共8个端口,含6个RJ45电口和2个ST光纤接口。端口速率:所有端口均为100Mbps快速以太网。光纤类型:2个光纤端口为多模、ST接头。管理类型:二…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...

照着用就行:2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

Codex使用API Key授权无法使用插件?
小伙伴们,大家好,我是小溪,见字如面。对于没有ChatGPT账号的小伙伴来说,虽然可以通过API Key授权的方式使用Codex桌面端,但是会有一些限制。比如无法使用插件功能,无法使用Codex移动端进行远程控制等。为了…...

【2026实测】怎么提高论文原创度?盘点8款主流降AI工具,附结构级优化指南
写文章最怕碰到什么,是辛辛苦苦自己码出来的字,却被标了极高的AI值。目前很多文本审核机制对内容的原创度要求极高,纯手写的初稿也可能因为句式太工整被判定为机器生成的。 为了帮几个快被这事折腾疯了的学弟学妹找条出路,我花了…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...