Mysql--基础篇--SQL(DDL,DML,窗口函数,CET,视图,存储过程,触发器等)
SQL(Structured Query Language,结构化查询语言)是用于管理和操作关系型数据库的标准语言。它允许用户定义、查询、更新和管理数据库中的数据。SQL是一种声明性语言,用户只需要指定想要执行的操作,而不需要详细说明如何实现这些操作。SQL被广泛应用于各种数据库系统,如MySQL、PostgreSQL、Oracle、SQL Server等。
为了更全面地理解SQL,我们可以将其分为以下几个主要部分:
- 数据定义语言(DDL)
- 数据操作语言(DML)
- 数据查询语言(DQL)
- 数据控制语言(DCL)
- 事务控制语言(TCL)
1、数据定义语言(DDL)
DDL用于定义和管理数据库的结构,包括创建、修改和删除数据库对象(如表、索引、视图等)。
常见的 DDL 操作包括:
- CREATE:创建数据库对象。
- ALTER:修改现有数据库对象的结构。
- DROP:删除数据库对象。
- TRUNCATE:清空表中的所有数据,但保留表结构。
- RENAME:重命名数据库对象。
使用示例:
- 创建数据库:
CREATE DATABASE mydatabase;
- 创建表:
CREATE TABLE employees (id INT PRIMARY KEY,name VARCHAR(100),age INT,department VARCHAR(50));
- 修改表结构:
ALTER TABLE employees ADD COLUMN salary DECIMAL(10, 2);
- 删除表:
DROP TABLE employees;
- 清空表数据:
TRUNCATE TABLE employees;
- 重命名表:
RENAME TABLE old_table_name TO new_table_name;
2、数据操作语言(DML)
DML用于插入、更新和删除数据库中的数据。
常见的DML操作包括:
- INSERT:向表中插入新数据。
- UPDATE:更新表中的现有数据。
- DELETE:从表中删除数据。
使用示例:
- 插入数据:
INSERT INTO employees (id, name, age, department) VALUES (1, 'Alice', 30, 'HR');
- 批量插入数据:
INSERT INTO employees (id, name, age, department) VALUES (2, 'Bob', 28, 'Engineering'),(3, 'Charlie', 35, 'Sales');
- 更新数据:
UPDATE employees SET salary = 60000 WHERE id = 1;
- 删除数据:
DELETE FROM employees WHERE id = 2;
- 删除所有数据:
DELETE FROM employees;
3、数据查询语言(DQL)
DQL用于从数据库中检索数据,最常见的DQL语句是SELECT。通过SELECT语句,用户可以查询表中的数据,并使用各种条件、排序、分组等功能来获取所需的结果。
使用示例:
- 基本查询:
SELECT * FROM employees;
- 选择特定列:
SELECT name, age FROM employees;
- 带条件的查询:
SELECT * FROM employees WHERE department = 'HR';
- 使用AND/OR组合条件:
SELECT * FROM employees WHERE department = 'HR' AND age > 30;
- 使用IN进行多值匹配:
SELECT * FROM employees WHERE department IN ('HR', 'Sales');
- 使用LIKE进行模糊匹配:
SELECT * FROM employees WHERE name LIKE 'A%'; -- 匹配以 'A' 开头的名字
- 使用BETWEEN进行范围查询:
SELECT * FROM employees WHERE age BETWEEN 25 AND 35;
- 使用ORDER BY排序:
SELECT * FROM employees ORDER BY age DESC; -- 按年龄降序排列
- 使用LIMIT限制结果数量:
SELECT * FROM employees LIMIT 5; -- 只返回前 5 条记录
- 使用GROUP BY分组:
SELECT department, COUNT() AS employee_count FROM employees GROUP BY department;
- 使用HAVING过滤分组结果:
SELECT department, COUNT() AS employee_count FROM employees GROUP BY department HAVING COUNT() > 2;
- 使用JOIN连接多个表:
SELECT e.name, d.department_name FROM employees e JOIN departments d ON e.department_id = d.id;
- 使用子查询:
SELECT * FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
4、数据控制语言(DCL)
DCL用于控制用户对数据库的访问权限。通过DCL,管理员可以授予或撤销用户的权限,确保数据的安全性和完整性。
常见的DCL操作包括:
- GRANT:授予用户权限。
- REVOKE:撤销用户权限。
使用示例:
- 授予用户权限:(这条语句的作用是授予用户user1在主机localhost上对employees表的 SELECT和INSERT权限。)
GRANT SELECT, INSERT ON employees TO 'user1'@'localhost';
- 授予所有权限:(常用用户权限包含SELECT, INSERT, UPDATE, DELETE四个,ALL PRIVILEGES是所有权限,包含更多的操作)
GRANT ALL PRIVILEGES ON *.* TO 'admin'@'localhost';
说明:
SELECT, INSERT, UPDATE, DELETE和ALL PRIVILEGES区别
-
SELECT:允许用户查询表中的数据。
-
INSERT:允许用户向表中插入新数据。
-
UPDATE:允许用户更新表中的现有数据。
-
DELETE:允许用户从表中删除数据。
这四个权限是数据库中最常用的权限,通常足以满足大多数用户的日常操作需求。它们只影响数据的操作,而不涉及数据库结构或系统级别的操作。ALL PRIVILEGES是一个更广泛的权限集合,它不仅包括SELECT, INSERT, UPDATE, DELETE,还包括以下权限: -
CREATE:允许用户创建新的数据库、表、索引等。
-
DROP:允许用户删除数据库、表、索引等。
-
ALTER:允许用户修改表结构(如添加或删除列)。
-
INDEX:允许用户创建和删除索引。
-
GRANT OPTION:允许用户将自己拥有的权限授予其他用户。
-
REFERENCES:允许用户创建外键约束。
-
CREATE VIEW:允许用户创建视图。
-
SHOW VIEW:允许用户查看视图的定义。
-
CREATE ROUTINE:允许用户创建存储过程和函数。
-
ALTER ROUTINE:允许用户修改存储过程和函数。
-
EXECUTE:允许用户执行存储过程和函数。
-
FILE:允许用户读取和写入文件(例如通过LOAD DATA INFILE和SELECT … INTO OUTFILE)。
-
RELOAD:允许用户执行FLUSH操作,刷新服务器缓存。
-
SHUTDOWN:允许用户关闭MySQL服务器。
-
PROCESS:允许用户查看所有线程的状态。
-
SUPER:允许用户执行一些管理操作,如更改全局变量、杀死其他用户的线程、使用CHANGE MASTER TO等。
-
REPLICATION SLAVE:允许用户从主服务器复制数据。
-
REPLICATION CLIENT:允许用户获取主服务器和从服务器的状态信息。
-
撤销用户权限:
REVOKE SELECT, INSERT ON employees FROM 'user1'@'localhost';
- 撤销所有权限:
REVOKE ALL PRIVILEGES ON *.* FROM 'admin'@'localhost';
附用户相关操作语句
- 创建用户:
CREATE USER 'user1'@'localhost' IDENTIFIED BY 'password123';
- 修改用户密码:
ALTER USER 'user1'@'localhost' IDENTIFIED BY 'new_password';
- 删除用户:
DROP USER 'user1'@'localhost';
- 重命名用户:
RENAME USER 'user1'@'localhost' TO 'user2'@'localhost';
- 查看当前用户:
SELECT CURRENT_USER();
- 查看所有用户:
SELECT User, Host FROM mysql.user;
附:角色管理(Role Management)
从MySQL 8.0开始,MySQL引入了角色(Role)的概念,允许你将一组权限分配给一个角色,然后将该角色分配给多个用户。角色可以简化权限管理,特别是在有大量用户和复杂权限需求的情况下。
- 创建角色:
CREATE ROLE 'data_analyst';
- 为角色分配权限:
GRANT SELECT, INSERT, UPDATE ON mydatabase.* TO 'data_analyst';
- 将角色分配给用户:
GRANT 'data_analyst' TO 'user1'@'localhost';
- 激活角色(角色授权):
SET DEFAULT ROLE 'data_analyst' TO 'user1'@'localhost';
- 查看用户的角色:
SHOW GRANTS FOR 'user1'@'localhost';
- 删除角色:
DROP ROLE 'data_analyst';
5、事务控制语言(TCL)
TCL用于管理事务,确保一组相关的数据库操作要么全部成功,要么全部失败。事务的四个特性(ACID)保证了数据的一致性和可靠性。
常见的TCL操作包括:
- BEGIN/START TRANSACTION:开始一个事务。
- COMMIT:提交事务,使所有更改永久生效。
- ROLLBACK:回滚事务,撤销所有未提交的更改。
- SAVEPOINT:设置保存点,允许部分回滚。
使用示例:
- 开始事务:
START TRANSACTION;
- 提交事务:
COMMIT;
- 回滚事务:
ROLLBACK;
- 设置保存点:
SAVEPOINT my_savepoint;
- 回滚到保存点:
ROLLBACK TO SAVEPOINT my_savepoint;
- 释放保存点:
RELEASE SAVEPOINT my_savepoint;
6、SQL的高级功能
除了上述基本功能,SQL还提供了许多高级功能,用于处理复杂的数据操作和查询优化。以下是一些常见的高级SQL功能:
1、窗口函数(Window Functions)
窗口函数(Window Functions)是SQL中一种强大的工具,允许你在查询结果集中进行复杂的聚合计算,而不需要使用子查询或自连接。窗口函数可以在每一行数据上应用聚合操作,并且可以基于特定的分组、排序和范围来计算结果。MySQL从8.0版本开始支持窗口函数,极大地增强了其处理复杂查询的能力。
窗口函数的语法结构:
window_function([expression]) OVER ([PARTITION BY partition_expression][ORDER BY sort_expression][frame_clause]
)
说明:
- window_function:指定要使用的窗口函数,如ROW_NUMBER()、RANK()、SUM()、AVG()等。
- PARTITION BY:将结果集划分为多个分区(类似于GROUP BY),每个分区独立计算窗口函数的结果。
- ORDER BY:在每个分区内对行进行排序,影响窗口函数的计算顺序。
- frame_clause:定义窗口框架,指定窗口函数作用的行范围(可选)。常见的框架类型包括:
- ROWS BETWEEN … AND …
- RANGE BETWEEN … AND …
窗口函数示例:
窗口函数常用于在查询结果集中进行复杂的聚合计算,而不需要使用子查询或自连接。
(1)、ROW_NUMBER()
ROW_NUMBER()为每一行分配一个唯一的行号,行号从1开始,按ORDER BY指定的顺序递增。如果使用了PARTITION BY,则每个分区内的行号从1开始重新计数。
示例:为每个部门的员工分配行号
SELECT department, name, salary, ROW_NUMBER() OVER (PARTITION BY department ORDER BY salary DESC) AS row_num
FROM employees;
解释:
- PARTITION BY department:按部门划分分区。
- ORDER BY salary DESC:在每个部门内按工资降序排列。
- ROW_NUMBER():为每个部门的员工分配行号,行号从1开始。
输出结果:

(2)、RANK()
RANK()为每一行分配一个排名,排名从1开始,按ORDER BY指定的顺序递增。如果有并列的行(即相同的排序值),它们会获得相同的排名,后续行的排名会跳过相应的数字。
示例:为每个部门的员工按工资排名
别名不要用关键字rank,否则语法执行错误。
SELECT department, name, salary, RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS rank1
FROM employees;
解释:
- PARTITION BY department:按部门划分分区。
- ORDER BY salary DESC:在每个部门内按工资降序排列。
- RANK():为每个部门的员工按工资排名,如果有并列的行,排名会跳过。
输出结果:

(3)、DENSE_RANK()
DENSE_RANK()类似于RANK(),但它不会跳过排名。即使有并列的行,后续行的排名也不会跳过。在上面的RANK示例中我们看到排名为(1,2,2,4,没有第3名),而DENSE_RANK()则会展示出第3名。
示例:为每个部门的员工按工资排名(不跳过)
别名不要用关键字dense_rank,否则语法执行错误。
SELECT department, name, salary, DENSE_RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS dense_rank1
FROM employees;
解释:
- PARTITION BY department:按部门划分分区。
- ORDER BY salary DESC:在每个部门内按工资降序排列。
- DENSE_RANK():为每个部门的员工按工资排名,即使有并列的行,排名也不会跳过。
输出结果:

(4)、NTILE(n)
NTILE(n)将结果集划分为n个桶(或分组),并为每一行分配一个桶编号。桶的大小尽可能均匀分布。
示例:将员工按工资分为4个等级
SELECT name, salary, NTILE(4) OVER (ORDER BY salary DESC) AS salary_grade
FROM employees;
解释:
- ORDER BY salary DESC:按工资降序排列。
- NTILE(4):将员工按工资分为4个等级,每个等级分配一个桶编号。
输出结果:

(5)、LAG()和LEAD()
LAG()和LEAD()用于访问当前行之前的行或之后的行的数据。LAG()访问前一行,LEAD()访问后一行。你可以指定偏移量(默认为1),并提供默认值(当没有前/后行时返回)。
示例:比较员工与其前一名员工的工资差额
SELECT name, salary, LAG(salary, 1, 0) OVER (ORDER BY salary DESC) AS prev_salary,salary - LAG(salary, 1, 0) OVER (ORDER BY salary DESC) AS salary_diff
FROM employees;
解释:
- LAG(salary, 1, 0):获取前一行的工资,如果没有前一行则返回0。
- salary - LAG(salary, 1, 0):计算当前行与前一行的工资差额。
输出结果:


(6)、FIRST_VALUE()和LAST_VALUE()
FIRST_VALUE()返回窗口中第一个值,LAST_VALUE()返回窗口中最后一个值。你可以通过ORDER BY控制窗口中的排序顺序。
示例:获取每个部门中最高和最低工资的员工
SELECT department, name, salary, FIRST_VALUE(salary) OVER (PARTITION BY department ORDER BY salary DESC) AS highest_salary,LAST_VALUE(salary) OVER (PARTITION BY department ORDER BY salary DESC RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lowest_salary
FROM employees;
解释:
- FIRST_VALUE(salary):获取每个部门中工资最高的员工的工资。
- LAST_VALUE(salary):获取每个部门中工资最低的员工的工资。为了确保LAST_VALUE()返回最后一个值,我们使RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING 来定义窗口框架。
窗口框架常用范围说明: - UNBOUNDED PRECEDING:表示从窗口的最开始(第一行)。
- UNBOUNDED FOLLOWING:表示到窗口的最后(最后一行)。
- CURRENT ROW:表示当前行。
- n PRECEDING 或 n FOLLOWING:表示从前/后n行开始或结束。
输出结果:

(7)、SUM()、AVG()、MIN()、MAX()
这些聚合函数也可以作为窗口函数使用,允许你在每个分区或整个结果集中进行聚合计算,而不需要使用GROUP BY。
示例:计算每个部门的累计工资
SELECT department, name, salary, SUM(salary) OVER (PARTITION BY department ORDER BY salary DESC) AS cumulative_salary
FROM employees;
解释:
- SUM(salary):计算每个部门的累计工资。
- PARTITION BY department:按部门划分分区。
- ORDER BY salary DESC:在每个部门内按工资降序排列,确保累计工资按工资从高到低累加。
输出结果:

以上示例展示了聚合函数在窗口函数中的使用。聚合函数也可以不使用窗口函数,直接使用。
示例:求出每个部门的工资总和
SELECTdepartment,SUM(salary)
FROMemployees
GROUP BYdepartment;
运行结果:

2、窗口框架(Frame Clause)
窗口框架允许你进一步控制窗口函数的作用范围。你可以指定窗口函数作用的行范围。
常用的框架类型包括:
- ROWS BETWEEN … AND …:基于行数定义窗口框架。
- RANGE BETWEEN … AND …:基于值的范围定义窗口框架。
(1)、ROWS BETWEEN
ROWS BETWEEN基于行数定义窗口框架。你可以指定窗口函数作用的前几行或后几行。
示例:计算每个员工及其前两行的平均工资
SELECT name, salary, AVG(salary) OVER (ORDER BY salary DESC ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS avg_salary
FROM employees;
解释:
- ROWS BETWEEN 2 PRECEDING AND CURRENT ROW:窗口框架范围为前2行到当前行。
- AVG(salary):计算当前行及其前两行的平均工资。
常用范围说明: - UNBOUNDED PRECEDING:表示从窗口的最开始(第一行)。
- UNBOUNDED FOLLOWING:表示到窗口的最后(最后一行)。
- CURRENT ROW:表示当前行。
- n PRECEDING 或 n FOLLOWING:表示从前/后n行开始或结束。
输出结果:

(2)、RANGE BETWEEN
RANGE BETWEEN基于值的范围定义窗口框架。它适用于数值类型的列,窗口框架基于值的差异而不是行数。
示例:计算每个员工及其工资相同或相差不超过5000的其他员工的平均工资
SELECT name, salary, AVG(salary) OVER (ORDER BY salary DESC RANGE BETWEEN 5000 PRECEDING AND 5000 FOLLOWING) AS avg_salary
FROM employees;
解释:
- RANGE BETWEEN 5000 PRECEDING AND 5000 FOLLOWING:窗口框架包括当前行及其工资相差不超过5000的其他行。
- AVG(salary):计算当前行及其工资相差不超过5000的其他行的平均工资。
输出结果:

如果只是和高于自己最高5000的工资一起求平均值,如下:

窗口函数总结:
窗口函数是MySQL 8.0及更高版本中非常强大的功能,能够让你在查询结果集中进行复杂的聚合计算,而不需要使用子查询或自连接。
常见的窗口函数包括:
- ROW_NUMBER():为每一行分配唯一的行号。
- RANK()和DENSE_RANK():为每一行分配排名。
- NTILE(n):将结果集划分为n个桶。
- LAG()和LEAD():访问前一行或后一行的数据。
- FIRST_VALUE()和LAST_VALUE():获取窗口中的第一个或最后一个值。
- SUM()、AVG()、MIN()、MAX():在窗口中进行聚合计算。
此外,窗口框架(ROWS BETWEEN和RANGE BETWEEN)允许你进一步控制窗口函数的作用范围,使你能够更灵活地定义计算的上下文。
3、公用表表达式(CTE)
用于将复杂的查询分解为多个简单的步骤,提高可读性和维护性。CTE可以递归使用,适用于处理层次结构数据(如组织结构图、树形结构等)。
示例:
WITH RECURSIVE org_tree AS (SELECT id, name, manager_idFROM employeesWHERE manager_id IS NULLUNION ALLSELECT e.id, e.name, e.manager_idFROM employees eINNER JOIN org_tree ot ON e.manager_id = ot.id)SELECT * FROM org_tree;
运行结果:

4、临时表(Temporary Tables)
用于存储中间结果,避免重复计算。临时表只在当前会话中可见,会话结束后自动删除。
示例:创建一个临时表并使用临时表
CREATE TEMPORARY TABLE temp_employees ASSELECT * FROM employees WHERE department = 'HR';
select * from temp_employees;
运行结果:

5、索引(Indexes)
用于加速查询操作,特别是在大表上。索引可以显著提高查询性能,但也会影响插入、更新和删除操作的速度。常见的索引类型包括B-tree索引、哈希索引、全文索引等。
创建索引示例:
CREATE INDEX idx_name ON employees (name);
6、视图(Views)
用于创建虚拟表,封装复杂的查询逻辑。视图可以简化查询,隐藏底层表的复杂性,并提供数据抽象。
示例:
CREATE VIEW hr_employees ASSELECT * FROM employees WHERE department = 'HR';
7、存储过程(Stored Procedures)
用于封装一组SQL语句,作为可复用的代码块。存储过程可以接受参数、执行复杂的业务逻辑,并返回结果。
示例:创建一个存储过程,指定id查询对应的数据
DELIMITER //CREATE PROCEDURE get_employee_by_id(IN emp_id INT)BEGINSELECT * FROM employees WHERE id = emp_id;END //DELIMITER ;
解释:
- DELIMITER //:更改MySQL的语句分隔符为//。默认情况下,MySQL使用分号;作为语句的结束符。然而,在创建存储过程时,存储过程体内部可能包含多个SQL语句,每个语句以分号结束。为了避免MySQL将这些内部的分号误认为是整个存储过程定义的结束,我们需要临时更改分隔符。这样MySQL会将整个存储过程定义视为一个完整的语句,直到遇到//才执行。
- CREATE PROCEDURE get_employee_by_id(IN emp_id INT):创建一个名称为get_employee_by_id的存储过程。定义了一个输入参数emp_id,类型为INT。IN表示这是一个输入参数,即调用存储过程时需要传递的值。emp_id是你要查询的员工ID。
- BEGIN和END:用于包裹存储过程的主体部分。在BEGIN和END之间的所有SQL语句都属于该存储过程的逻辑。本例中,存储过程体只包含一条SELECT语句,用于从employees表中查询与emp_id匹配的员工信息。
- DELIMITER ; :将分隔符恢复为默认的分号;。这一步是为了确保后续的SQL语句使用默认的分隔符。
运行结果:

调用存储过程示例:
CALL get_employee_by_id(10001);

8、触发器(Triggers)
用于在特定事件发生时自动执行一组SQL语句。触发器通常用于实现数据完整性约束、审计日志记录等功能。
示例:创建触发器(校验employees表新增的数据,age小于18岁时提示报错)
CREATE TRIGGER before_insert_employeeBEFORE INSERT ON employeesFOR EACH ROWBEGINIF NEW.age < 18 THENSIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Employee must be at least 18 years old';END IF;END;
解释:
- CREATE TRIGGER before_insert_employee:创建一个名称为before_insert_employee的触发器。
- BEFORE INSERT ON employees:指定触发器的执行时机。在employees表执行Insert语句之前触发。
- FOR EACH ROW:指定触发器的执行粒度。FOR EACH ROW表示触发器会为每一行插入操作单独执行一次。也就是说,如果你一次性插入多条记录,触发器会为每一条记录分别检查条件。
- BEGIN和END:用于包裹触发器的主体部分。在BEGIN和END之间的所有逻辑都属于该触发器的执行内容。在这个例子中,触发器体包含一个IF语句,用于检查新插入的员工年龄是否小于18岁。如果条件成立,则抛出一个错误,阻止插入操作。
- IF NEW.age < 18 THEN:在触发器中,NEW是一个特殊的关键字,表示即将插入的新记录。它允许你在触发器中访问新记录的各个字段值。如果IF条件成立(即NEW.age < 18),则执行THEN后面的逻辑。
- SIGNAL SQLSTATE ‘45000’ SET MESSAGE_TEXT = ‘Employee must be at least 18 years old’; : SIGNAL语句可以让你在触发器或存储过程中显式地抛出错误,从而中断当前的操作。45000是MySQL中的一个通用错误代码,表示“未分类的SQL状态”(unclassified SQL state)。你可以使用这个代码来抛出自定义的错误。SET MESSAGE_TEXT = 'Employee must be at least 18 years old’设置错误消息的内容。当触发器抛出错误时,MySQL会返回这条消息给客户端,告知用户具体的错误原因。
- END IF;:结束IF语句的逻辑块。如果没有抛出错误,触发器将继续执行后续的逻辑(如果有)。
执行结果:

验证触发器功能:
INSERT INTO employees VALUES ('10009', 'Alice', '16', 'HR', '70000', NULL)

7、SQL的优化技巧
为了提高SQL查询的性能,以下是几种常见的优化技巧:
- 使用索引:为经常用于查询条件的列创建索引,以加速查询操作。避免在频繁更新的列上创建索引,因为索引会增加写操作的开销。
- 避免全表扫描:尽量使用索引覆盖查询,确保查询只访问必要的数据。避免使用 SELECT *,只选择需要的列。
- 合理使用JOIN:尽量减少JOIN的数量,避免不必要的连接。如果可能,使用子查询代替复杂的JOIN。
- 使用合适的数据类型:选择合适的数据类型可以减少存储空间并提高查询性能。例如,使用INT代替VARCHAR存储数字,使用DATE代替VARCHAR存储日期。
- 分页查询:对于大数据集,使用LIMIT和OFFSET进行分页查询,避免一次性加载过多数据。也可以考虑使用键集分页(Keyset Pagination)来提高分页性能。
- 使用缓存:对于频繁执行的查询,可以使用查询缓存(如MySQL的查询缓存或应用层缓存)来减少数据库的压力。
- 分析查询计划:使用EXPLAIN语句分析查询的执行计划,找出潜在的性能瓶颈。根据分析结果调整查询语句或索引。
示例:
EXPLAIN SELECT * FROM employees WHERE department = 'HR';
8、SQL总结
SQL是一种强大且灵活的查询语言,广泛应用于关系型数据库的管理和操作。通过掌握SQL的各个组成部分(DDL、DML、DQL、DCL 和 TCL),你可以有效地创建、修改、查询和管理数据库中的数据。此外,SQL 还提供了许多高级功能,如窗口函数、CTE、索引、视图等,帮助你处理复杂的业务需求和优化查询性能。
仰天大笑出门去,我辈岂是蓬蒿人!!!
相关文章:
Mysql--基础篇--SQL(DDL,DML,窗口函数,CET,视图,存储过程,触发器等)
SQL(Structured Query Language,结构化查询语言)是用于管理和操作关系型数据库的标准语言。它允许用户定义、查询、更新和管理数据库中的数据。SQL是一种声明性语言,用户只需要指定想要执行的操作,而不需要详细说明如何…...

比较 FreeSWITCH 的 asr 事件和回调函数
用 lua 来描述,是这样的 第一种做法: session:setVariable("fire_asr_events", "true") session:execute("detect_speech", "start-input-timers") 识别到结果之后可以收到 DETECTED_SPEECH 事件 另外一个做法…...

基于ffmpeg和sdl2的简单视频播放器制作
基于ffmpeg和sdl2的简单视频播放器制作 前言一、视频播放器开发的基础1.1 视频播放原理1.2 开发所需的库 二、FFmpeg库详解2.1 FFmpeg库的组成2.2 关键数据结构2.3 打开视频文件并获取流信息2.4 查找视频流和解码器2.5 初始化解码器 三、SDL库详解3.1 SDL库的功能3.2 初始化SDL…...

卫星导航信号的形成及解算
引言 卫星导航信号是现代导航技术的核心,它利用卫星发射的信号实现全球范围内的精确定位和导航。本文将详细介绍卫星导航信号的形成及解算过程。 一、卫星导航信号的形成 卫星导航信号的形成主要包括信号的生成、调制和传播三个步骤。 1. 信号的生成 卫星导航信号主…...

硬件-射频-PCB-常见天线分类-ESP32实例
文章目录 一:常见天线1.1 PCB天线①蓝牙模块的蛇形走线-天线②倒F天线-IFA:③蛇形倒F天线-MIFA④立体的倒F天线-PIFA 1.2 实例示意图1.21 对数周期天线(LPDA):1.22 2.4GHZ的八木天线:1.23 陶瓷天线:1.24 外接天线: 二&…...

salesforce 验证规则判断一个picklist是否为none
在 Salesforce 验证规则中,如果你想判断一个 Picklist 字段是否等于 None,可以使用 ISPICKVAL 函数。 以下是具体的公式: ISPICKVAL(Picklist_Field__c, "None")示例解释: Picklist_Field__c: 是你的自定义 Picklist…...
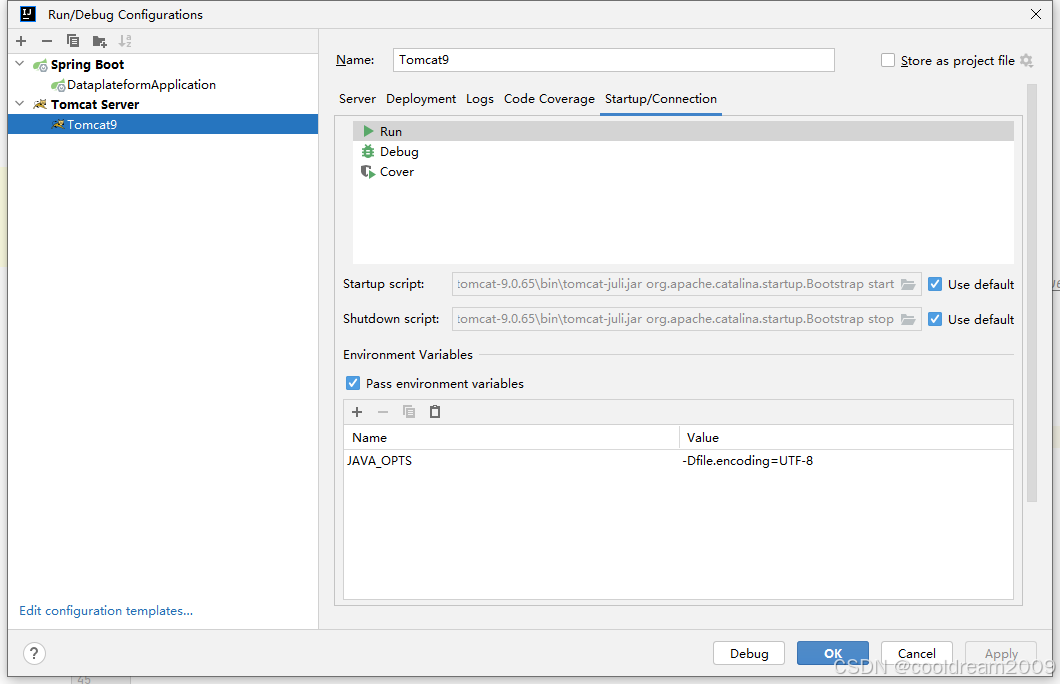
解决 IntelliJ IDEA 中 Tomcat 日志乱码问题的详细指南
目录 前言1. 分析问题原因2. 解决方案 2.1 修改 IntelliJ IDEA 的 JVM 选项2.2 配置 Tomcat 实例的 VM 选项 2.2.1 设置 Tomcat 的 VM 选项2.2.2 添加环境变量 3. 进一步优化 3.1 修改 Tomcat 的 logging.properties3.2 修改操作系统默认编码 3.2.1 Windows 系统3.2.2 Linux …...

如何分析 Nginx 日志
分析 Nginx 日志可以帮助我们了解服务器性能、流量来源、用户行为,以及诊断问题(如错误和攻击)。以下是详细的分析方法: 1. 日志类型 Nginx 有两种主要日志: 访问日志 (Access Log):记录客户端对服务器的…...

Kubernetes Gateway API-5-后端协议和网关基础设置标签
1 后端协议 自 v1.2.0 开始支持 并非所有网关API实现都支持自动协议选择。在某些情况下,协议在没有明确选择加入的情况下被禁用。 当 Route 的后端引用Kubernetes Service 时,应用程序开发人员可以使用 ServicePort appProtocol 字段指定协议。 例如…...

大数据架构演变
一、离线数仓 缺点: ETL计算、存储、时间成本高数据处理链路过长无法支持实时、近实时的数据分析数据采集对业务库造成影响 二、Lambda架构,离线实时分开 缺点: 组件多,不方便管理很难保证数据一致数据探查困难,出现…...

Bash语言的软件工程
Bash语言的软件工程 1. 引言 Bash(Bourne Again SHell)是一个Unix Shell和命令语言解释器,最初由Brian Fox为GNU项目编写。Bash不仅是Linux和macOS等现代操作系统的标准Shell,同时也是很多开发者和系统管理员进行自动化任务、开…...

OpenGL —— 流媒体播放器 - ffmpeg解码rtsp流,opengl渲染yuv视频(附源码,glfw+glad)
效果 说明 FFMpeg和OpenGL作为两大技术巨头,分别在视频解码和图形渲染领域发挥着举足轻重的作用。本文将综合两者实战视频播放器,大概技术流程为:ffmpeg拉取rtsp协议视频流,并经过解码、尺寸格式转换为yuv420p后,使用opengl逐帧循环渲染该yuv实时视频。 核心源码 vertexSh…...

CE中注册的符号地址如何通过编程获取
我的方式是先执行lua申请共享内存,内存名称是进程id,这样多开也不受影响,然后通过共享内存的名字就可以读到地址了。之后的人造指针的地址也都可以放这里集中管理。 -- 申请内存 local size 1024 -- 申请 1024 字节(1 KB&#…...

Math Reference Notes: 积分因子
在求解一阶线性微分方程时,积分因子(Integrating Factor)是一个非常重要的工具,它能够将复杂的微分方程转化为一个可以直接积分的形式。通过使用积分因子,我们可以简化微分方程的结构,使得求解过程更加直接…...
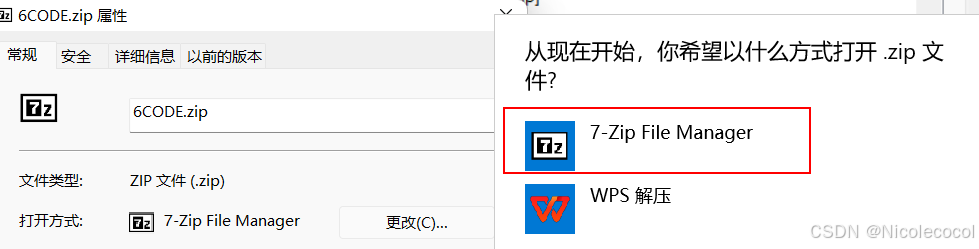
解决7-Zip图标更换问题
手动美化7-Zip图标,告别Win95风格 之前下载的7z压缩的文件图标都是软件的黑白图形,但是电脑重置了默认应用后再改回7z,压缩的文件就变成黄色的图标了,试过很多问题,尝试过手动更改图标,或者代码更改&#…...

Java 性能监控工具详解:JConsole、VisualVM 和 Java Mission Control
在 Java 应用程序的开发和维护过程中,性能监控和故障诊断是至关重要的。本文将详细介绍三款常用的 Java 性能监控工具:JConsole、VisualVM 和 Java Mission Control(JMC),并探讨它们的功能和使用方法。 1 JConsole 1…...

浏览器报错:您的连接不是私密连接,Kubernetes Dashboard无法打开
问题描述 部署完成Kubernetes Dashboard后,打开HTTPS的web页面,Chrome和Edge浏览器都无法正常加载页面,会提示您的连接不是私密连接的报错。 原因: 浏览器不信任这些自签名的ssl证书,为了…...

用Python进行大数据处理:如何使用pandas和dask处理海量数据
《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 随着数据量的爆炸式增长,大数据处理成为现代数据科学和工程领域的核心挑战。Python作为数据分析的重要工具,其生态系统中的pandas和dask库…...

机器人手眼标定
机器人手眼标定 一、机器人手眼标定1. 眼在手上标定基本原理2. 眼在手外标定基本原理 二、眼在手外标定实验三、标定精度分析 一、机器人手眼标定 要实现由图像目标点到实际物体上抓取点之间的坐标转换,就必须拥有准确的相机内外参信息。其中内参是相机内部的基本参…...

基于Springboot + vue实现的校园失物招领系统
🥂(❁◡❁)您的点赞👍➕评论📝➕收藏⭐是作者创作的最大动力🤞 💖📕🎉🔥 支持我:点赞👍收藏⭐️留言📝欢迎留言讨论 🔥🔥&…...

3大技术突破:nanoMODBUS如何重塑嵌入式工业通信的轻量化标准
3大技术突破:nanoMODBUS如何重塑嵌入式工业通信的轻量化标准 【免费下载链接】nanoMODBUS A compact MODBUS RTU/TCP C library for embedded/microcontrollers 项目地址: https://gitcode.com/gh_mirrors/na/nanoMODBUS 在工业物联网和边缘计算蓬勃发展的今…...

Makerbase VESC遥控设置避坑指南:PPM信号范围校准不对?可能是这3个原因
Makerbase VESC遥控设置深度排障:PPM信号异常三大根源与精准修复方案 当你按照教程一步步设置Makerbase VESC的PPM遥控功能,却在最后发现电机响应异常——要么纹丝不动,要么只朝单一方向运转,甚至控制曲线完全非线性。这种挫败感我…...
)
从零到一:在uni-app中构建低功耗蓝牙设备通信全流程(微信小程序通用)
1. 低功耗蓝牙开发基础认知 第一次接触低功耗蓝牙开发时,我盯着文档里那些UUID、特征值之类的术语发懵,这感觉就像突然要和一个说外星语的外星人交流。后来才发现,理解蓝牙通信的关键在于建立正确的认知模型。 低功耗蓝牙(BLE&…...

实战EuroSAT遥感分类:3步构建高精度土地利用识别系统 [特殊字符]
实战EuroSAT遥感分类:3步构建高精度土地利用识别系统 🚀 【免费下载链接】EuroSAT EuroSAT: Land Use and Land Cover Classification with Sentinel-2 项目地址: https://gitcode.com/gh_mirrors/eu/EuroSAT EuroSAT数据集为遥感图像分类提供了标…...

GHelper完整指南:告别臃肿控制软件,3步打造你的专属华硕笔记本性能管家
GHelper完整指南:告别臃肿控制软件,3步打造你的专属华硕笔记本性能管家 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zep…...

Seedance 2.0全面开放API服务
4月14日,字节跳动旗下的火山引擎正式向企业及个人开发者开放了Seedance 2.0系列API服务,这是其视频生成模型迈向全面商业化的关键一步。该模型定位为全球性能领先(SOTA)的多模态视频生成模型,此次开放不仅意味着将顶尖…...
)
保姆级教程:在uni-app微信小程序里跑起你的第一个Three.js 3D模型(附避坑清单)
零基础实战:在uni-app微信小程序中集成Three.js 3D模型的完整指南 第一次尝试在微信小程序里展示3D模型时,我遇到了一个令人沮丧的问题——直接从npm安装的Three.js官方包在小程序环境中完全无法运行。控制台不断报出document.createElementNS的错误&…...

小白友好教程:用PyTorch 2.8镜像轻松完成深度学习实验
小白友好教程:用PyTorch 2.8镜像轻松完成深度学习实验 1. 为什么选择PyTorch 2.8镜像? 深度学习实验常常因为环境配置问题而变得复杂。PyTorch 2.8镜像解决了这个痛点,它预装了完整的PyTorch环境和CUDA工具包,让你可以立即开始实…...

如何高效使用LaserGRBL:7大专业技巧完整指南
如何高效使用LaserGRBL:7大专业技巧完整指南 【免费下载链接】LaserGRBL Laser optimized GUI for GRBL 项目地址: https://gitcode.com/gh_mirrors/la/LaserGRBL LaserGRBL是一款专为GRBL控制器优化的激光雕刻软件,通过直观的图形界面让用户轻松…...

多模态AI:下一波技术浪潮的机遇与挑战
测试工程师的转型临界点 2026年,多模态人工智能(MMAI)技术进入爆发期。其核心能力在于整合文本、图像、语音、视频等多源数据,实现跨模态推理与决策。对软件测试从业者而言,这既是颠覆传统工作模式的冲击波,…...